第01篇_编程通识
第01章_计算机基础
第一节 操作系统
1. 操作系统概述
什么是操作系统?
操作系统是计算机的核心软件,是底层硬件和其他软件之间的桥梁,为用户提供一个高效、方便、安全的操作环境。
它的组成如下:
内核:直接与硬件交互的核心程序,提供最基本的服务和功能,如进程管理、内存管理、设备驱动程序等。
系统程序:用于完成特定任务的程序,如文件管理工具、设备管理工具、网络管理工具等。
用户界面:用户与操作系统交互的桥梁,分为命令行界面(CLI)和图形用户界面(GUI)。
什么是用户态和内核态?
用户态和内核态是操作系统中定义的两种运行级别:
用户态(User Mode) : 操作系统为普通应用程序提供的运行状态,只能访问有限的系统资源,并且受到操作系统的严格限制。
内核态(Kernel Mode):操作系统内核运行的状态,具有完全的硬件和系统资源访问权限,可以执行任何操作。
用于区分程序运行时的权限和对系统资源的访问能力,是现代操作系统实现安全性和稳定性的关键机制之一。
用户态切换到内核态的 3 种方式?
系统调用(Trap):用户态程序通过系统调用请求操作系统服务,如文件操作、进程控制、通信等。
中断(Interrupt):当硬件设备产生中断时,操作系统需要从用户态切换到内核态来处理中断,如键盘输入事件等。
异常(Exception):当用户态程序出现异常时,操作系统需要从用户态切换到内核态来处理异常,如缺页异常。
2. 进程和线程
进程 vs 线程?
进程:进程是操作系统分配资源的最小单位,在启动Java应用时,就是启动了一个JVM进程,它包括主线程(main)和其它线程。
线程:线程是CPU调度和执行的最小单位,线程之间共享进程的堆和方法区(元空间),但是有各自的方法栈和程序计数器等,更适合任务协作和高并发性能的场景。
进程的5种状态
创建状态(new):进程正在创建。
就绪状态(ready):进程准备就绪,只等待CPU资源。
运行状态(running):进程正在运行。
阻塞状态(waiting):等待某一事件而暂停运行,如等待IO操作完成。
结束状态(terminated):进程正常结束或其他原因中断退出运行。
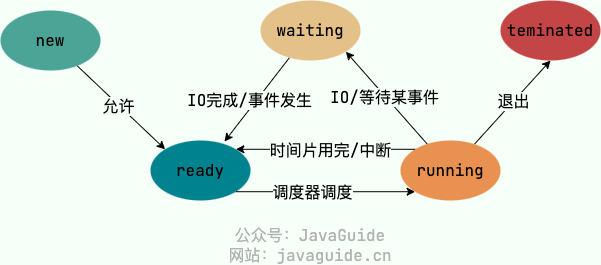
进程的调度算法有哪些?
时间片轮转调度算法(RR,Round-Robin) : 最常用的进程调度算法,为每个进程分配一个允许执行的时间段。
其它:先到先服务、短作业优先、优先级调度、多级反馈队列调度算法等
进程间的通信方式有哪些?
管道/有名管道(pipe):最基本的进程间通信方式,是半双工的,即数据只能在一个方向上流动,一般用于父子进程之间的通信。
消息队列(msgget/mq_open):在内核中维护一个队列,进程可以向队列中发送消息,也可以从队列中读取消息,是全双工的。
共享内存(shmget):在内核中分配一块内存区域,多个进程可以映射这块内存,从而实现数据共享,但需要注意数据竞争问题。
内存映射文件(mmap):在内核中创建一个文件映射,然后将文件的内容映射到多个进程的地址空间,也可以实现跨进程的通信。
文件交互:一个进程可以将数据写入一个文件,另一个进程可以读取该文件。
网络通信:通过网络协议(如 TCP/IP 或 UDP)进行通信。
PCB 是什么?包含哪些信息?
PCB(Process Control Block) 是进程控制块,是操作系统中用来管理和跟踪进程的数据结构,主要包含内容如下:
进程描述信息:进程的名称、标识符等。
进程调度信息:进程阻塞原因、进程状态(就绪、运行、阻塞等)、进程优先级(标识进程的重要程度)等。
进程其它信息:进程对资源的需求情况、进程打开的文件信息等
什么是僵尸进程和孤儿进程?
僵尸进程:指已结束但未清理进程表项的进程(父进程尚未读取其状态信息),该类进程不能被杀死,因为它已经“死亡”。
孤儿进程:指其父进程已结束,但子进程仍在运行的进程,该类进程会被
init进程(进程 ID 为 1)收养。
x1# 查看僵尸进程2ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'3
4# 查看孤儿进程5ps -A -o ppid,pid,cmd | awk '$1 == 1 {print}'
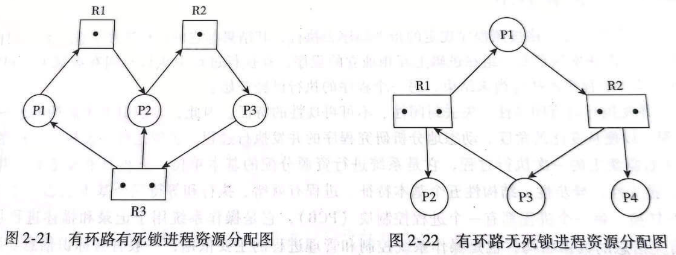
进程死锁?如何检测?
死锁指多个进程/线程之间循环等待互斥资源的现象,检测方式如下:
1) 检查是否存在依赖环路。
2) 检查环路中的每个资源是否无限阻塞。
3. 内存管理
内存管理包括哪些内容?
内存的分配与回收:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
地址转换:将程序中的虚拟地址转换成内存中的物理地址。
内存扩充:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
内存映射:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
内存优化:通过调整内存分配策略和回收算法来优化内存使用效率。
内存安全:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
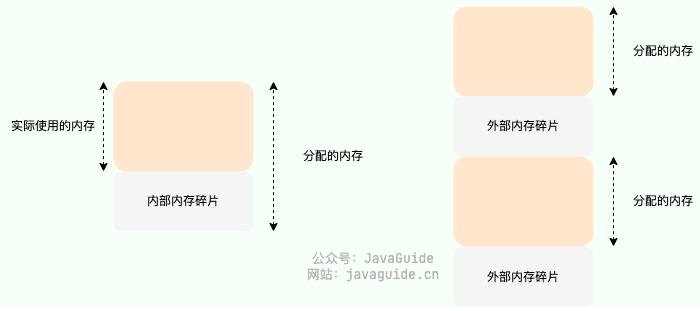
什么是内存碎片?
内存碎片主要分为两种类型:
外部碎片:由于频繁的内存分配和释放,可用内存被分割成许多不连续的小块,导致部分内存无法被有效利用。
内部碎片:指在分配内存时,分配的内存块大小通常会大于实际请求的大小,导致内存块内部存在未被利用的空间。
什么是虚拟内存?有什么用?
虚拟内存(Virtual Memory)是一种内存管理技术,它通过内存管理单元(MMU)将物理内存(RAM)进行映射,使每个进程都有一份自己的虚拟地址空间。
主要作用如下:
隔离程序的地址空间:每个程序都有独立的虚拟地址空间,程序之间无法直接访问彼此的内存,提高系统的稳定性和安全性。
简化内存管理:程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
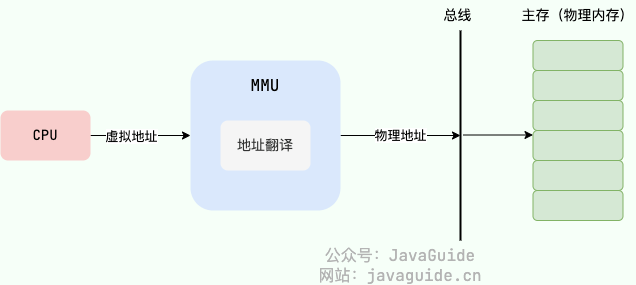
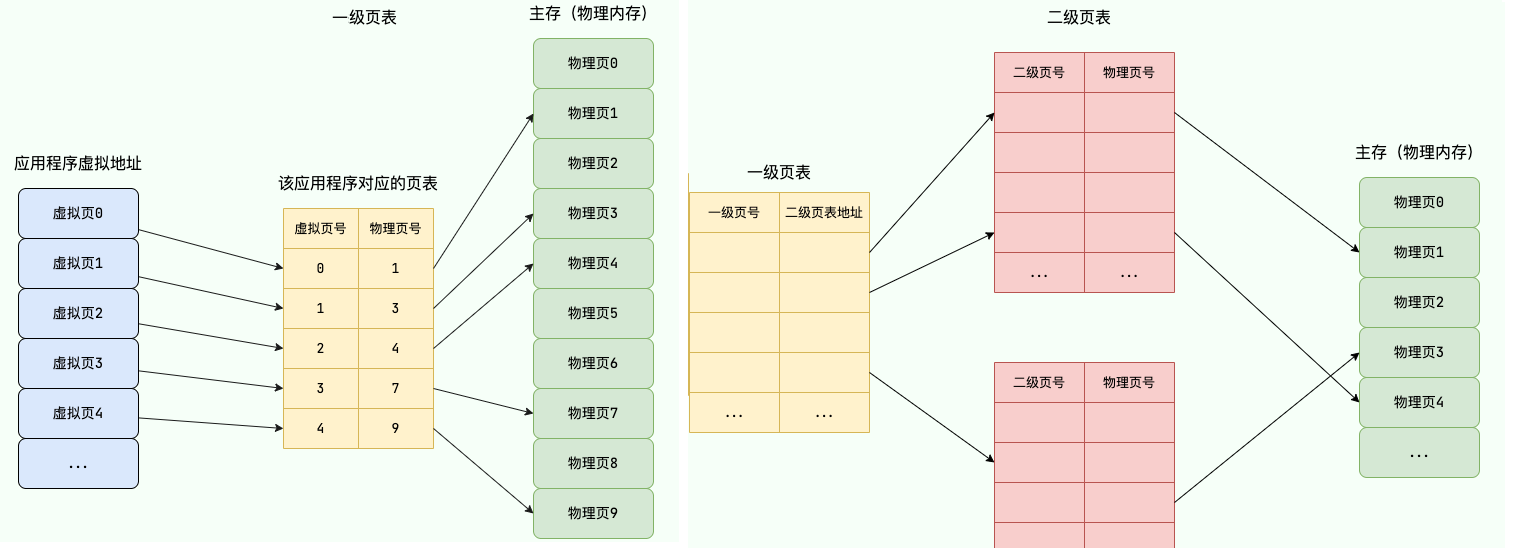
虚拟地址与物理内存地址是如何映射的?
现代操作系统广泛采用分页机制将虚拟地址翻译为物理地址:
将物理内存和虚拟内存分为连续等长的物理页。
通过 多级页表(Page Table) 映射虚拟地址和物理地址(虚拟地址即为页号+页内偏移量)。
引入快表(TLB,转址旁路缓存)提高虚拟地址到物理地址的转换速度。
使用换页机制利用磁盘这种较低廉的存储设备扩展的物理内存。
4. 文件系统
文件系统的主要功能?
文件系统主要负责管理和组织计算机存储设备上的文件和目录,其功能包括以下几个方面:
存储管理:将文件数据存储到物理存储介质中,并避免文件之间发生冲突。
文件管理:文件的创建、删除、移动、重命名、压缩、加密、共享等。
目录管理:目录的创建、删除、移动、重命名等。
访问控制:管理不同用户或进程对文件的访问权限,保证文件的安全性和保密性。
Linux的文件系统
Linux 使用一种称为目录树的层次结构来组织文件和目录。目录树由根目录(/)作为起始点,向下延伸,形成一系列的目录和子目录。
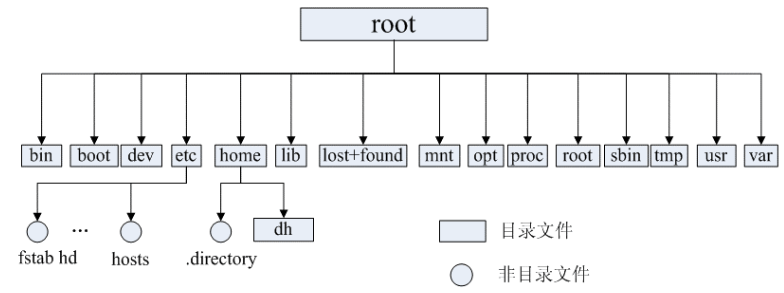
/bin: 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
/etc: 存放系统管理和配置文件;
/home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user表示;
/usr: 用于存放系统应用程序;
/opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
/proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
/root: 超级用户(系统管理员)的主目录;
/sbin: 存放二进制可执行文件,一般 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序,如 ifconfig 等;
/dev: 用于存放设备文件;
/mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
/boot: 存放用于系统引导时使用的各种文件;
/lib 和/lib64: 存放着和系统运行相关的库文件 ;
/tmp: 用于存放各种临时文件,是公用的临时文件存储点;
/var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件等;
/lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
Linux的文件类型
在Linux系统中,文件类型主要分为以下几种:
普通文件:最常见的文件类型,用于存储数据、文本文件、图片、视频、可执行文件、硬链接等。
目录文件:用于组织和存储其他文件和目录,它是一个特殊的文件,记录了文件名和 inode 号的映射关系。
符号链接:一个指向其他文件或目录的引用,类似于Windows中的快捷方式,可以跨文件系统。
字符设备文件:用于访问硬件设备,数据以字符流的形式读写,例如键盘、鼠标、串行端口等。
块设备文件:用于访问硬件设备,数据以块的形式读写,例如硬盘、光驱等。
命名管道:用于进程间通信,允许一个进程写入数据,另一个进程读取数据。
套接字:用于网络通信,允许不同主机或同一主机上的进程之间进行通信。
硬链接和软链接有什么区别?
在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。
硬链接:使用
ln命令创建,源文件和链接文件是对等的关系,索引节点号(inode)相同,节省磁盘空间,但不能跨文件系统,也不能指向目录或不存在的文件。软链接:使用
ln -s命令创建,链接文件指向一个文件路径,两者 inode 不同,类似于Windows的快捷方式。
5. I/O模型
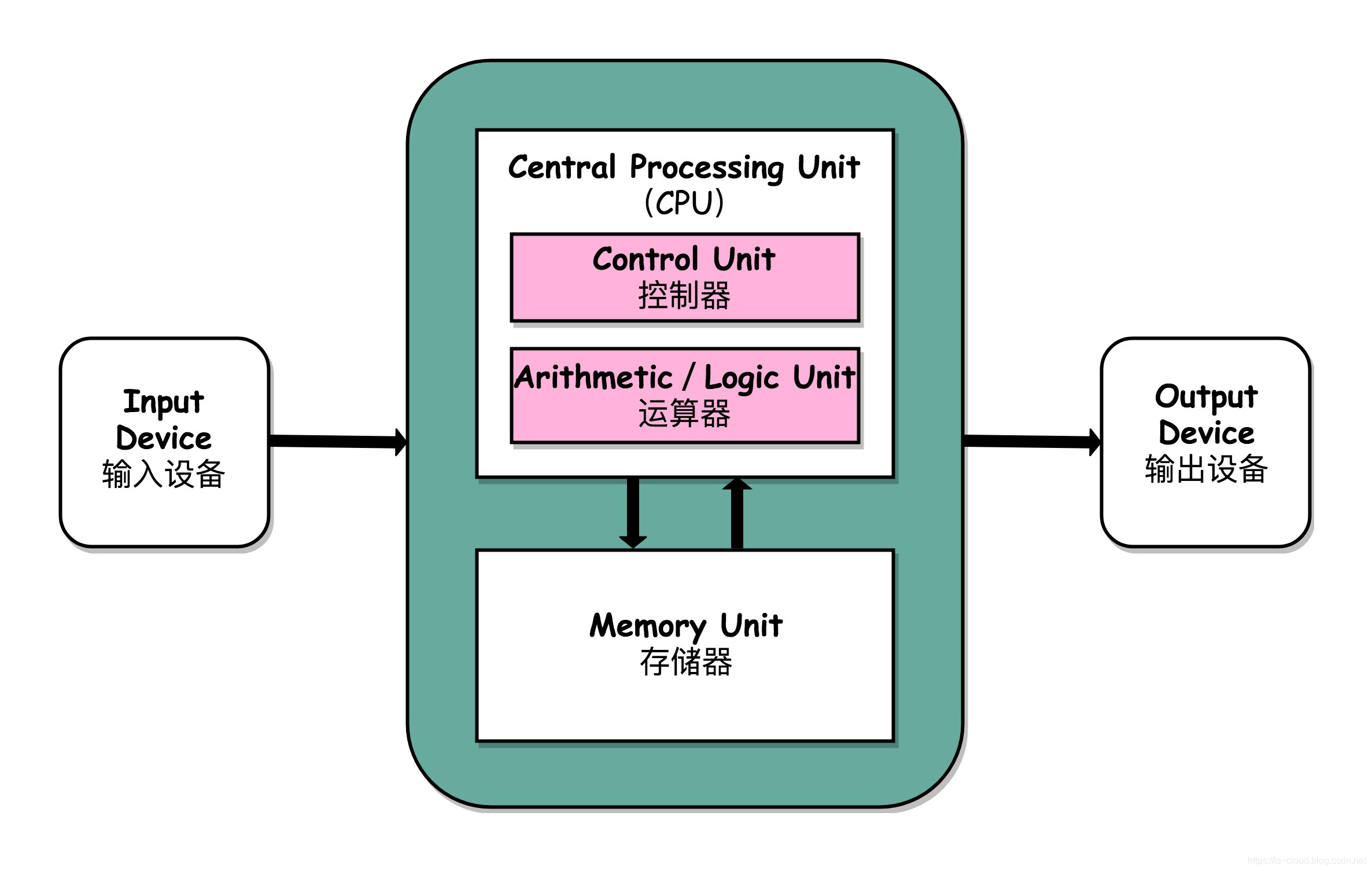
什么是I/O?常见I/O模型有哪些?
根据冯.诺依曼结构,计算机分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备,I/O 即输入/输出 。
在 UNIX 系统下, I/O 模型一共有 5 种:同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。
BIO (Blocking I/O)
BIO 属于同步阻塞 I/O 模型,应用程序发起系统调用 read() 后,会一直阻塞等待,直到内核把数据拷贝到用户空间。
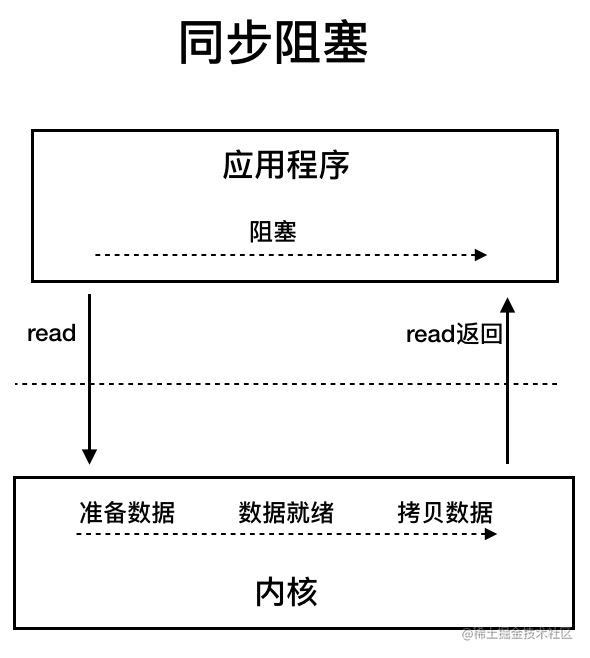
在客户端连接数量不高的情况下,是没问题的,如果并发量较高,则不推荐。
NIO (Non-blocking/New I/O)
NIO 既可以通过同步非阻塞 I/O模型实现,也可以通过I/O 多路复用模型实现,也可两者结合使用。
同步非阻塞 I/O 模型:在数据准备阶段,通过长轮询操作,避免了一直阻塞,但在拷贝数据时,依然是阻塞的。
I/O 多路复用模型:先发起 select/epoll 调用,询问数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。
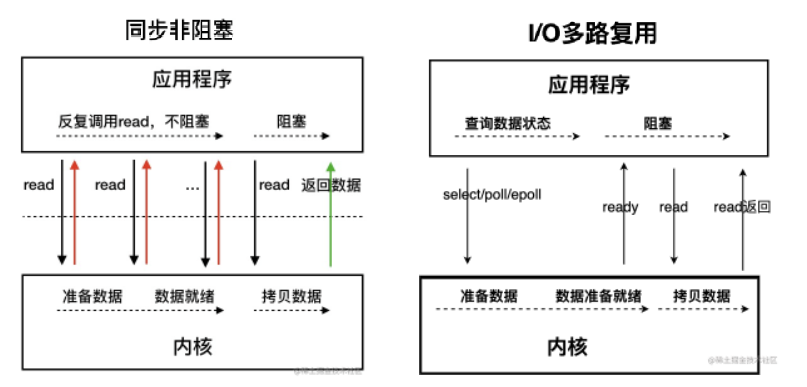
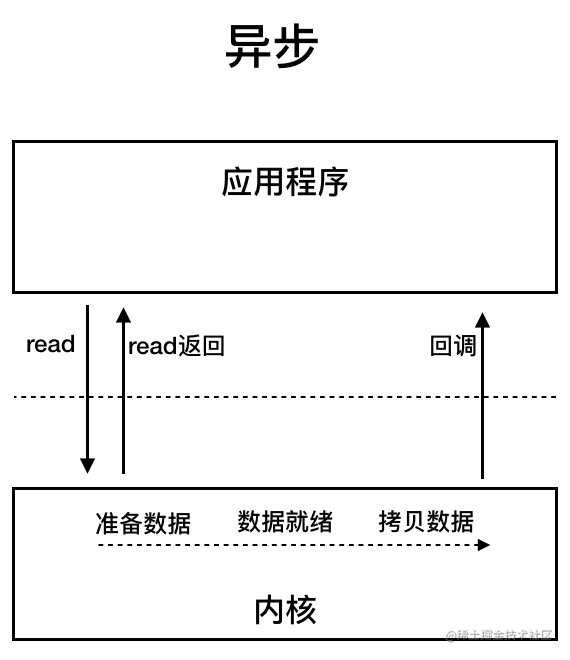
AIO (Asynchronous I/O)
AIO 是基于事件和回调机制实现的异步 IO 模型,应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
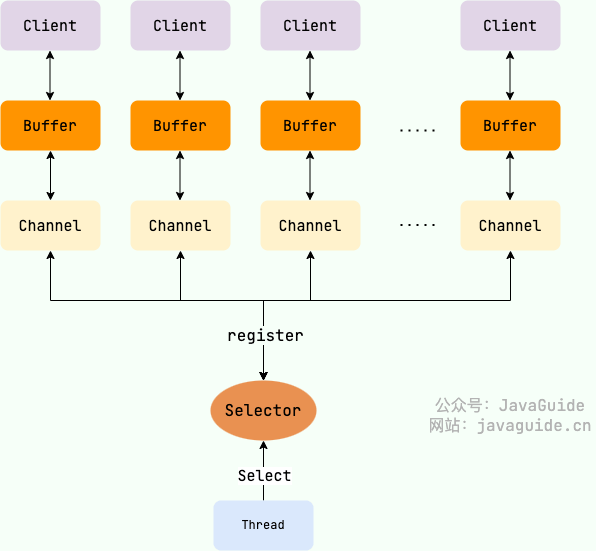
NIO的核心组件有哪些?
Java NIO(New Input/Output)的核心组件主要包括以下三个部分:
Buffer(缓冲区):是数据的容器,用于存储从通道(Channel)读取的数据,或者将数据写入通道。
常见的缓冲区类型包括:
ByteBuffer、CharBuffer、IntBuffer、LongBuffer、DoubleBuffer等。
Channel(通道):用于数据传输的通道,类似于传统I/O中的流,但功能更强大,可以在非阻塞模式同时支持读取和写入操作。
常见的通道类型包括:
FileChannel、SocketChannel、ServerSocketChannel、DatagramChannel等。
Selector(选择器):基于事件驱动的 I/O 多路复用模型,支持在 1 个线程监控多个通道的事件(如连接打开、数据到达等)。
关于零拷贝技术
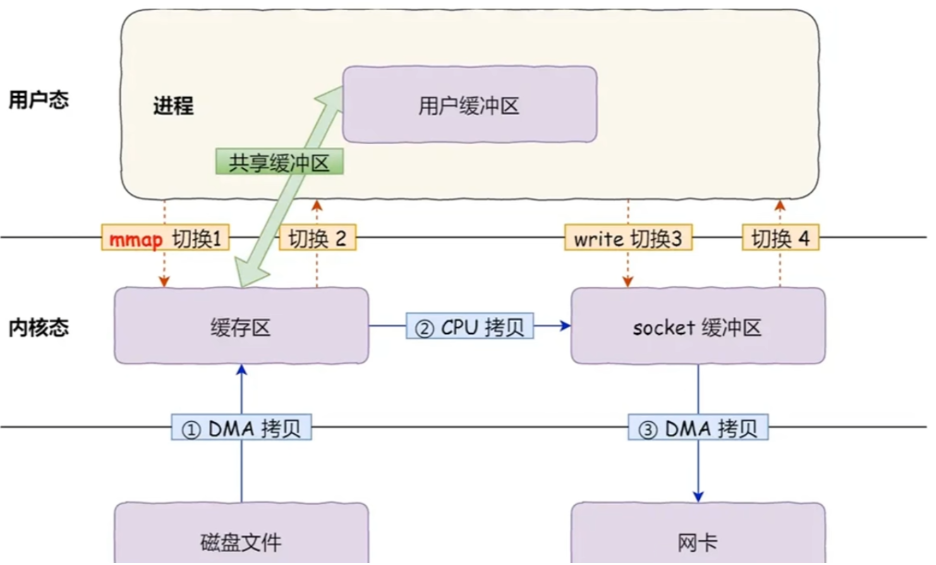
传统的文件传输,一般使用 read + write 方式实现,需要进行 2 次 CPU 拷贝和 4 次运行级别切换。
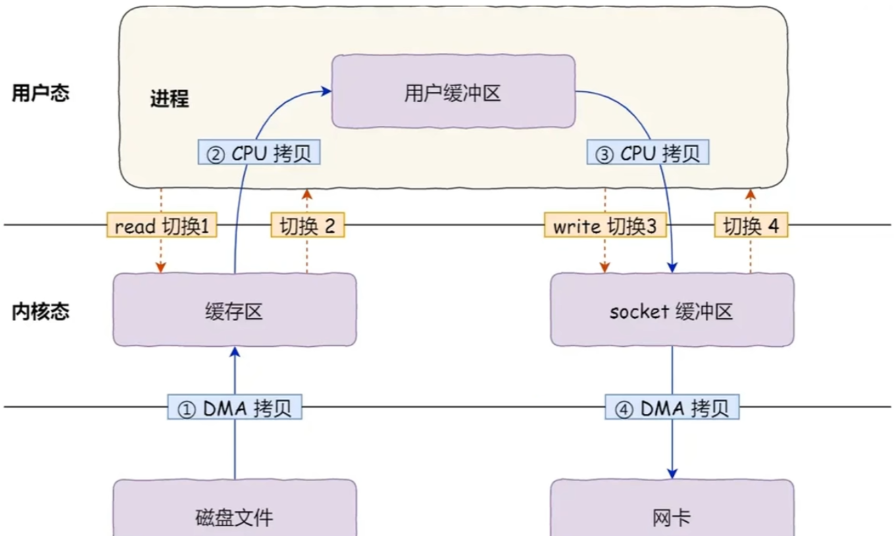
零拷贝指0次CPU拷贝,是提升 I/O 操作性能的一个常用技术手段,最基础的方式通过mmap+write实现。首先使用 mmap 对磁盘文件进行映射,然后在write 时就可以直接从内核缓冲区拷贝到 Socket 缓冲区了,节省了1次CPU拷贝消耗,但仍有4次运行级别切换。
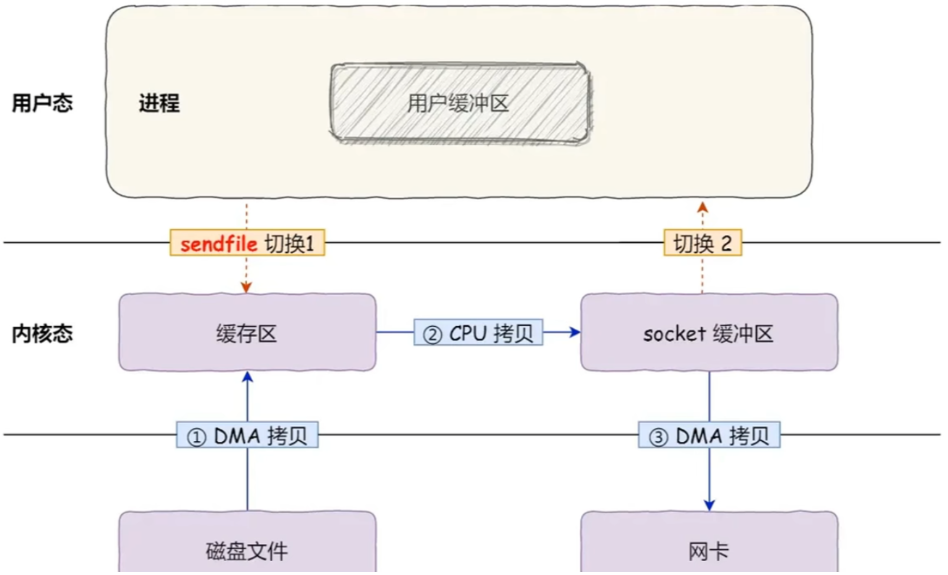
在 Linux 2.1 后,引入了sendfile方式支持零拷贝,直接在内核进行拷贝操作,又节省了2次运行级别切换。
在 Linux2.4 后,如果网卡支持SG-DMA技术,还可以直接从内核缓冲区发送到网卡,真正实现0拷贝。
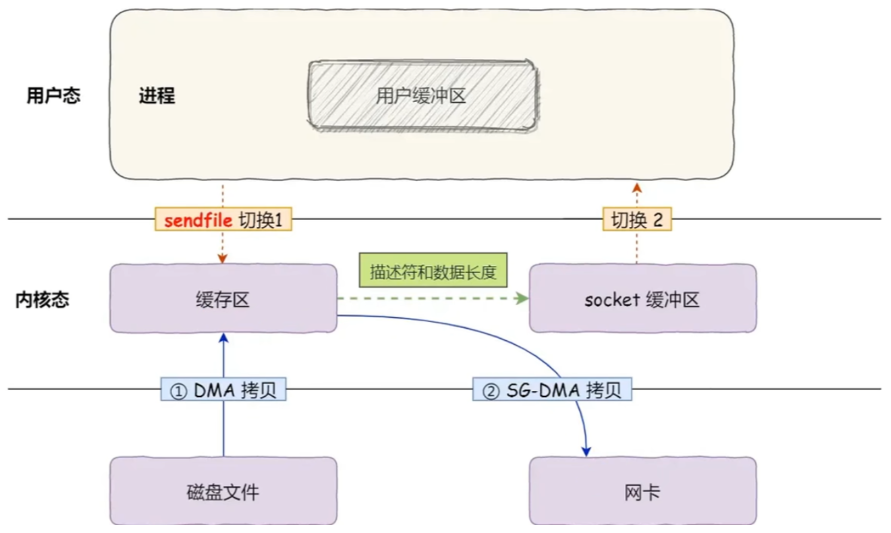
在 Java 中, MappedByteBuffer和FileChannel.transferTo()/transferFrom()分别用于支持上述两种方式。
第二节 网络通信
1. 网络通信概述
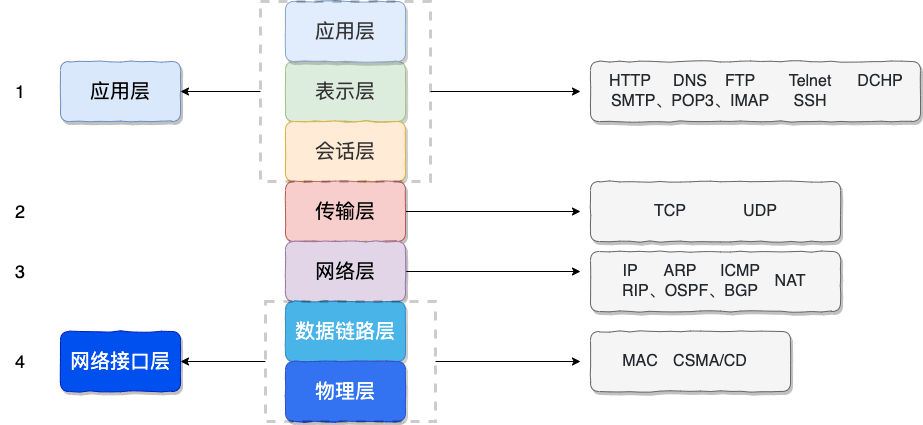
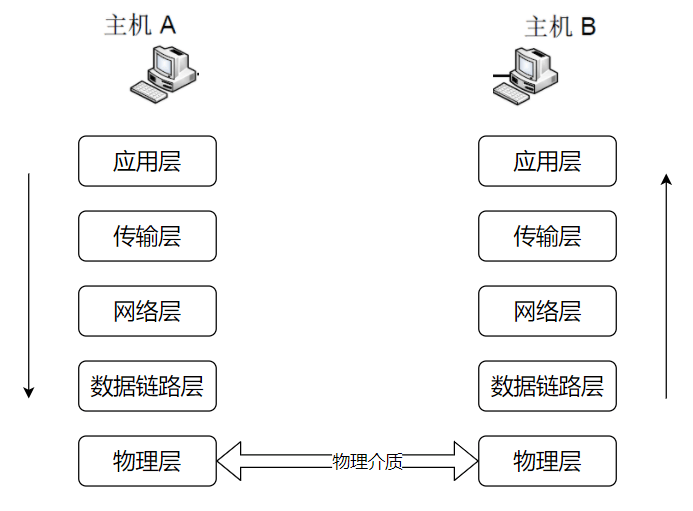
OSI七层模型
OSI 七层模型是由国际标准化组织(ISO)提出的一个用于计算机或网络系统互联的参考模型,它将网络通信的工作分为7个层次:
应用层:提供应用程序之间的通信服务,直接面向用户,常见协议有:HTTP/HTTPS、SMTP/POP3/IMAP、FTP、DNS等。
表示层:负责数据的表示和转换,确保数据在不同系统之间能够正确理解和解释,常见协议有:SSL/TLS、MIME等。
会话层:负责建立、管理和终止会话,常见协议有:RPC、NetBIOS等。
传输层:负责端到端的通信,确保数据的可靠传输,常见协议有:TCP、UDP等,一般在主机上实现,不涉及具体网络设备。
网络层:负责在多个网络之间进行数据的转发和路由选择,常见协议有:IP、ARP、ICMP等,常见设备有:路由器等。
链路层:负责处理帧的同步、流量控制和差错检测与纠正,常见协议有:Ethernet、PPP等,常见设备有:网桥、交换机等。
物理层:负责在物理介质上建立、维护和拆除物理链路,常见设备有:中继器、集线器等。
注意:
OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。
TCP/IP四层模型
TCP/IP 四层模型 是目前被广泛采用的一种模型,可以看作是 OSI 七层模型的精简版本,由以下 4 层组成:
应用层:对应于 OSI 模型的应用层、表示层和会话层,负责会话管理和数据表示等功能。
传输层:与 OSI 模型的传输层功能基本一致,负责端到端的通信和数据的可靠传输。
网络层:与 OSI 模型的网络层功能基本一致,负责数据包的路由选择和逻辑寻址。
链路层:对应于 OSI 模型的数据链路层和物理层,负责物理介质管理和帧传输功能。
常见的网络协议
应用层常见的网络协议有:
HTTP: 超文本传输协议(Hypertext Transfer Protocol),多用于 Web 环境传输超文本和多媒体内容。
HTTPS:HTTP 的加强安全版本,基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。
SMTP:简单邮件发送协议,用于发送电子邮件。
POP3/IMAP:邮件接收协议,用于接收电子邮件。其中 IMAP 是高级版本,支持邮件搜索、标记、分类、归档等高级功能。
FTP/SFTP:文件传输协议,用于传输文件,并兼容不同的操作系统和文件存储方式。其中 SFTP 协议对传输文件进行了加密。
Telnet:远程登陆协议,通过一个终端登陆到其他服务器,但用户名和密码等都是明文传输,不安全,很少用。
SSH:安全的网络传输协议(Secure Shell Protocol),通过加密和认证机制实现安全的访问和文件传输等业务。
RTP:实时传输协议,通常基于 UDP 协议,但也支持 TCP 协议,提供了端到端的实时传输数据的功能。
DNS:域名管理系统(Domain Name System),基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
传输层常见的网络协议有:
TCP:传输控制协议(Transmission Control Protocol),提供 面向连接 的,可靠 的数据传输服务。
UDP:用户数据协议(User Datagram Protocol),提供 无连接 的,尽最大努力 的数据传输服务,不保证数据传输的可靠性。
网络层常见的网络协议有:
IP:网际协议(Internet Protocol),定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。
ARP:地址解析协议(Address Resolution Protocol),解决的是网络层地址(IP地址)和链路层地址(MAC地址)之间的转换问题。
ICMP:互联网控制报文协议(Internet Control Message Protocol),用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
NAT:网络地址转换协议(Network Address Translation),用于内部网到外部网的地址转换过程中。
OSPF/RIP:内部网关协议(IGP),前者适合中大型网络,后者适合小型网络。
BGP:外部网关协议(EGP),用于互联网骨干网和 ISP 之间的路由选择。
链路层常见的网络协议有:
Ethernet:以太网协议,最常见的链路层协议,广泛应用于局域网(LAN)。
WLAN:无线局域网协议,用于家庭、企业、公共场所的无线网络,如Wi-Fi。
PPP:用于点对点连接,如拨号上网或串行连接。
网页浏览数据流程
在浏览器中输入指定网页的 URL。
浏览器通过 DNS 协议,获取域名对应的 IP 地址。
浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求
URL 的组成结构
*URL(Uniform Resource Locator):是统一资源定位符,是可以提供该资源的路径,就像人的联系住址。

协议:指定应用层协议,如
http://、https://、ftp://等。域名:指定访问的网址,这里也有可能是网址的 IP 地址。
端口:指定访问的端口,大部分协议都有默认端口,如http的80端口,https的443端口,ftp的21端口等。
资源路径:指定访问的资源。
参数:在向服务器提交请求时,在 URL 中附带的参数,以
?开头,键值对形式,使用=和&隔开。锚点:指定访问的页面上的一个锚,相当于一个小书签。锚点以
#开头,并且不会作为请求的一部分发送给服务端。
注意:
URI(Uniform Resource Identifier): 是 统一资源标识符,可以唯一标识一个资源,就像人的身份证号。
常见协议的默认端口
| 协议名称 | 默认端口 | 协议类型 | 功能描述 |
|---|---|---|---|
| HTTP | 80 | TCP | 超文本传输协议,用于Web浏览 |
| HTTPS | 443 | TCP | 安全超文本传输协议,加密的Web通信 |
| FTP | 21 | TCP | 文件传输协议,用于文件传输 |
| SMTP | 25/465/587 | TCP | 简单邮件传输协议,用于发送邮件 |
| POP3 | 110/995 | TCP | 邮局协议版本3,用于接收邮件 |
| IMAP | 143/993 | TCP | 互联网消息访问协议,用于管理邮件 |
| DNS | 53 | TCP/UDP | 域名系统,用于域名解析 |
| Telnet | 23 | TCP | 远程登录协议 |
| SSH | 22 | TCP | 安全外壳协议,用于安全远程登录 |
| SNMP | 161/162 | UDP | 简单网络管理协议,用于网络设备管理 |
| NTP | 123 | UDP | 网络时间协议,用于时间同步 |
| TFTP | 69 | UDP | 简单文件传输协议 |
| DHCP | 67/68 | UDP | 动态主机配置协议,自动分配IP地址 |
| SIP | 5060 | TCP/UDP | 会话初始化协议,用于VoIP |
| RDP | 3389 | TCP | 远程桌面协议,用于远程桌面访问 |
常见应用的默认端口
| 协议名称 | 默认端口 | 协议类型 | 功能描述 |
|---|---|---|---|
| MySQL | 3306 | TCP | 数据库管理系统 |
| PostgreSQL | 5432 | TCP | 数据库管理系统 |
| Redis | 6379 | TCP | 内存数据库 |
| MongoDB | 27017 | TCP | NoSQL数据库 |
| RabbitMQ | 5672 | TCP | 消息队列 |
| Memcached | 11211 | TCP/UDP | 分布式缓存系统 |
| Docker | 2375/2376 | TCP | 容器化平台 |
| Kafka | 9092 | TCP | 分布式消息系统 |
| Elasticsearch | 9200 | TCP | 搜索引擎 |
| Consul | 8500 | TCP | 服务发现和配置工具 |
| Prometheus | 9090 | TCP | 监控系统 |
| Grafana | 3000 | TCP | 可视化工具 |
| Jenkins | 8080 | TCP | 持续集成工具 |
| Tomcat | 8080 | TCP | Java应用服务器 |
| Nginx | 80/443 | TCP/UDP | Web服务器 |
| Zookeeper | 2181 | TCP | 分布式协调服务 |
2. DNS协议
什么是DNS 协议?
DNS(Domain Name System)域名管理系统,是用户浏览网页时用到的第一个重要协议,主要用于解决域名和 IP 地址的映射问题。

注意:
DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,默认端口为 53。
DNS 解析路径
本地缓存 -> 本地hosts文件 -> 本地DNS服务器 -> 根域名服务器(13组) -> 顶级域名服务器 -> 权威DNS服务器。
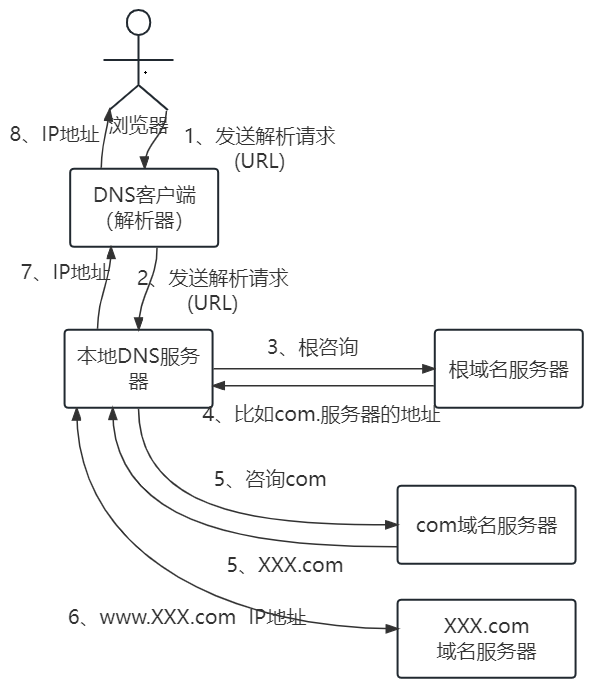
注意:
域名解析过程可通过
nslookup命令来模拟。
常见DNS记录类型?
| 记录类型 | 用途 | 示例 |
|---|---|---|
| A | 将域名映射到IPv4地址 | example.com. IN A 192.0.2.1 |
| AAAA | 将域名映射到IPv6地址 | example.com. IN AAAA 2001:db8::1 |
| CNAME | 将一个域名(别名)指向另一个域名(规范名) | www.example.com. IN CNAME example.com. |
| MX | 指定域名的邮件服务器 | example.com. IN MX 10 mail.example.com. |
| NS | 指定域名的权威DNS服务器 | example.com. IN NS ns1.example.com. |
| TXT | 存储任意文本信息,常用于SPF、DKIM和DMARC等 | example.com. IN TXT "test" |
DNS 劫持了解吗?如何应对?
DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。
提示:
DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。
3. HTTP协议
HTTP 协议通信过程
HTTP 是应用层协议,它以 TCP 作为传输层协议,默认端口为 80,通信过程主要如下:
地址解析:当用户在浏览器地址栏输入一个URL或点击一个链接时,浏览器会通过DNS解析获取服务器的IP地址。
建立连接:浏览器向服务器的80端口(HTTP默认端口)发起TCP连接请求,并通过三次握手建立TCP连接。
发送请求:一旦TCP连接建立,浏览器就可以发送HTTP请求到服务器。
处理请求:服务器接收到请求后,会根据请求行和请求头中的信息处理请求,访问相应的资源。
发送响应:服务器将处理结果封装成HTTP响应,发送给浏览器。
关闭连接:如果使用短连接,服务器在发送完响应后关闭连接;如果使用长连接,则保持连接直到客户端或服务器关闭连接。
HTTP请求方式有哪些?
GET:主要用于查询资源,查询参数拼接在URL后面,有一定的长度限制,且不安全。
POST:主要用于修改资源,请求参数放在请求体,一般无长度限制,且相对较安全。
PUT:用于更新或新创建资源。
PATCH:用于对资源进行局部修改,例如更新用户的部分信息(如邮箱地址)
DELETE:用于删除指定的资源。
HEAD:获取指定资源的响应头信息,但不返回响应体,一般用于检查资源是否存在。
OPTIONS:请求服务器返回该资源所支持的 HTTP 方法列表。
注意:
GET 请求的响应结果可能会被浏览器或其它中间件(如代理、网关)缓存起来,而POST请求一般不会。
HTTP请求头中常见的字段有哪些?
HTTP 头部用于在客户端和服务器之间传递额外的信息,下面是请求头中常见的字段:
Host:请求的服务器的域名和端口号(HTTP/1.1),如:
Host: example1.org。User-Agent:请求者信息,如浏览器类型、版本、操作系统等,服务器可以根据这个字段来调整响应的内容。
Accept:告知服务器客户端能够处理的媒体类型,如
text/html,、application/json等。Accept-Language:告知服务器客户端希望响应内容的语言偏好,例如
en-US表示美国英语。Accept-Encoding:告知服务器客户端支持的内容编码方式,如
gzip;deflate等。Authorization:用于 HTTP 身份验证,通常包含用户凭据,如:Bearer xxxx。
Content-Length:表示请求体的长度(以字节为单位),在发送POST或PUT请求时,如果请求体包含数据,需要指定这个字段。
Content-Type:表示请求体的媒体类型,例如在发送JSON格式的数据时,值为
application/json;charset=UTF-8。Cookie:包含之前由服务器设置的 Cookie 值,用于跟踪用户会话等信息。
Origin: 是 CORS 机制中的关键字段,用于控制跨域请求的安全性,只包含协议、域名和端口号。
Referer:用于记录请求的来源页面,包含完整的 URL(协议、域名、路径和查询参数),主要用于日志分析和防盗链等。
Connection:控制是否保持连接,常见的值有
keep-alive(保持连接)和close(关闭连接)。
HTTP响应头中常见的字段有哪些?
下面是响应头中常见的字段:
Content-Type:告知客户端响应内容的媒体类型,例如
text/html、application/json等。Content-Length:表示响应体的长度(以字节为单位),帮助客户端预估响应内容的大小。
Content-Encoding:告知客户端响应内容的编码方式,如
gzip;deflate等,客户端可以根据这个字段来解码响应内容。Content-Language:告知客户端响应内容的语言,例如
en-US。Content-Disposition:用于控制浏览器如何处理响应内容,例如
attachment; filename="example.zip"会提示用户下载文件。Set-Cookie:服务器用来设置Cookie的字段,客户端会将这些Cookie存储起来,并在后续请求中发送给服务器。
Last-Modified:表示资源的最后修改时间,用于缓存控制。
ETag:表示资源的唯一标识符,用于缓存验证,如果资源未发生变化,服务器可以返回304状态码(Not Modified)。
Expires:表示响应内容的过期时间,用于控制缓存的有效期。
Cache-Control:用于控制缓存的行为,例如
no-cache表示禁止缓存,max-age=3600表示缓存有效期为3600秒。Location:用于重定向,告知客户端新的资源位置,通常与
3xx状态码一起使用。Server:包含服务器软件的相关信息,如服务器名称和版本。
Access-Control-Allow-Origin:用于跨域资源共享(CORS),指定允许访问资源的来源,例如
*表示允许所有来源访问。Connection:控制是否保持连接,常见的值有
keep-alive和close。
HTTP 状态码有哪些?
HTTP 状态码用于描述 HTTP 请求的结果,分类如下:
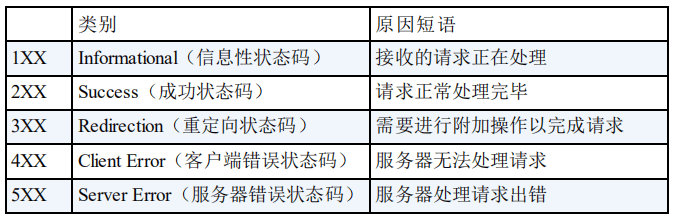
最常见的几种状态码和含义如下:
| 状态码 | 英文简称 | 中文解释 |
|---|---|---|
| 200 | OK | 请求成功 |
| 301/302 | Moved Permanently/Found | 重定向错误。资源已被永久/临时重定向。 |
| 400 | Bad Request | 错误的请求。发送的 HTTP 请求存在问题,比如请求参数不合法、请求方法错误等。 |
| 401 | Unauthorized | 未授权。在未认证时,请求需要认证之后才能访问的资源。 |
| 403 | Forbidden | 被禁止。直接拒绝 HTTP 请求,不处理,一般用来针对非法请求。 |
| 404 | Not Found | 不存在。请求的资源在服务器不存在。 |
| 500 | Internal Server Error | 服务器内部错误。服务器遇到无法处理的异常。 |
| 502 | Bad Gateway | 网关错误。网关收到无效或无法理解的服务器响应。 |
HTTP 不同版本之间有什么区别?
HTTP/1.0版本:1996年发布,每次请求/响应都会重新建立新的连接,性能较差,主要用于一些简单的、对性能要求不高的场景。
HTTP/1.1版本:1997年发布,默认开启持久连接,新增多种请求头/响应头和响应码,并优化了传输带宽和加强了缓存的处理,是目前最广泛使用的协议版本,适用于大多数Web应用。
HTTP/2.0版本:2015年发布,支持多路复用(在一个连接上并行传输多个请求和响应),并将报文格式改为二进制帧形式,此外,还提供了头部压缩(HPACK)和服务器推送等功能。
HTTP/3.0版本:2022年发布,使用基于 UDP 的 QUIC 协议,默认支持加密(基于TLS),适用于对性能和安全性要求极高的场景。
关于HTTP 队头阻塞?
HTTP队头阻塞指前面的请求/响应延迟,导致后续请求/响应也延迟的现象,这是由于请求/响应的顺序处理机制造成的。
在 HTTP/1.1 中,服务器必须按请求发送的顺序返回响应,如果某个请求的响应延迟,后续请求的响应也会被阻塞。
在 HTTP/2.0 中,在同一个 TCP 连接上并发传输多个请求和响应,解决了HTTP层面的问题,但 TCP 层面的队头阻塞问题仍然存在。
在 HTTP/3.0 中,使用基于 UDP 的 QUIC 协议,允许在同一个连接上并发传输多个数据流,从根本上解决了队头阻塞问题。
HTTP 请求如何保存用户状态?
HTTP 是一种无状态(stateless)协议,需要通过 Session 机制在服务端标识并跟踪用户。
通常来说,会在 Cookie 中附加一个 Session ID 的方式来跟踪。
如果 Cookie 被禁用,可以利用 URL 重写把 Session ID 直接附加在 URL 路径的后面。
HTTP 和 HTTPS 有什么区别?
HTTPS 协议(Hyper Text Transfer Protocol Secure)是 HTTP 的加强安全版本,是运行在 SSL/TLS 之上的 HTTP 协议,其传输内容采用了对称加密,对称加密的密钥用服务器方的证书进行了非对称加密。
对称加密:客户端和服务端使用相同的密码对报文内容进行加密和解密。
非对称加密:客户端使用公钥(服务器公开)对上述内容密码进行加密,服务器使用私钥(服务器独有)进行解密,安全性高。
此外,公钥可能被拦截伪造,在向服务器发送 HTTPS 请求时,一定要先获取目标服务器的证书,并根据证书上的信息(证书颁发机构(CA,Certificate Authority)的电子签名等),检验证书的合法性。
注意:
HTTP 采用
http://前缀和80端口,HTTPS 采用https://前缀和443端口。
4. WebSocket协议
什么是WebSocket协议?
WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据,前缀为:ws:// 或 wss://,用于弥补 HTTP 协议在持久通信能力上的不足,常用场景如:即时通讯、视频弹幕、游戏对战、协同编辑等等。
WebSocket 和 HTTP 有什么区别?
两者都是基于 TCP 的应用层协议,都可以在网络中传输数据,主要区别如下:
WebSocket 是一种双向实时通信协议,而 HTTP 协议下的通信一般只能由客户端发起,服务器无法主动通知客户端。
WebSocket 数据包头部相对较小,而 HTTP 通信每次都要携带完整的头部用于协议控制,网络开销较大。
扩展:
在HTTP协议下,可通过服务器发送事件(Server-Sent Events,SSE) 实现服务端向客户端发送文本数据。
WebSocket 的工作过程是什么样的?
WebSocket 的工作过程可以分为以下几个步骤:
客户端向服务器发送一个 HTTP 请求,请求头中包含
Upgrade: websocket和Sec-WebSocket-Key等字段,表示要求升级协议为 WebSocket;服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP
101状态码,响应头中包含 ,Connection: Upgrade和Sec-WebSocket-Accept: xxx等字段,表示成功升级到 WebSocket 协议。客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。
数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
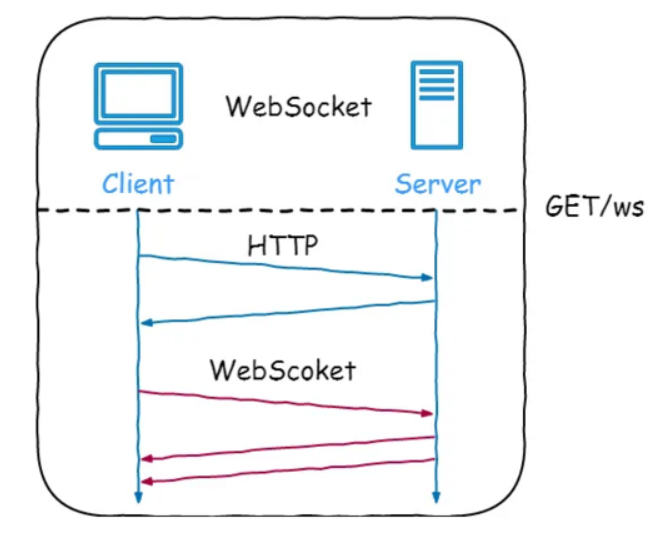
另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
5. TCP与UDP协议
TCP与UDP的区别?
是否面向连接:UDP发送数据之前不需要建立连接,而TCP发送数据前需要建立连接且发送结束后需释放连接。
是否可靠传输:UDP协议不保证数据完整性和有序性,而TCP协议保证数据完整性、正确性、有序性。
是否维护状态:UDP协议不维护任何状态,TCP协议则需记录消息是否发送成功,是否接收成功。
传输效率:UPD无需建立连接、消息确认、丢包重传等,且包头更小(8字节 vs 20~60字节),因此传输效率比TCP更高。
传输形式:UDP 是面向报文的,各个报文之间相互独立,而 TCP 是面向字节流的,有严格的先后顺序。
是否支持广播/多播:UDP 支持一对一、一对多、多对一、多对多,而 TCP 只支持点对点通信。
适用场景:UDP 一般用于即时通信,比如:语音、 视频、直播等等;TCP 用于对传输准确性要求特别高的场景,比如文件传输、发送和接收邮件、远程登录等等。
基于TCP/UDP的应用层协议
TCP:HTTTP/2.0协议、FTP/SFTP协议、SMTP/POP3/IMAP协议、Telnet协议、SSH协议等。
UDP:HTTP/3.0协议、DNS协议、DHCP协议(动态主机配置协议)、RTP协议(实时传输协议)等。
HTTP协议基于TCP还是UDP?
在 HTTP/3.0 之前是基于 TCP 协议的,而在 HTTP/3.0 及之后改用 基于 UDP 的 QUIC 协议 。
基于 UDP 的 QUIC 协议,可以解决 HTTP/2.0 中的 TCP 队头阻塞问题,并且建立连接的时间更短。
TCP三次握手(重要)
建立一个 TCP 连接需要“三次握手”,才能确认双方都正常通信,缺一不可:
一次握手:客户端发送带有 SYN(SEQ=x) 标志的数据包给服务端,然后客户端进入 SYN_SEND 状态,等待服务端的确认;
二次握手:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 SYN_RECV 状态;
三次握手:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务端都进入ESTABLISHED 状态;
当建立了 3 次握手之后,客户端和服务端就可以传输数据啦!
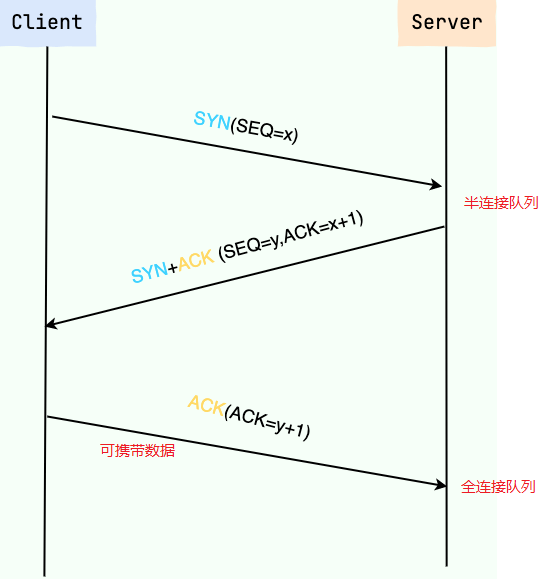
注意:
当服务端收到客户端的 SYN 请求时,会把半连接状态的连接放在半连接队列。
当服务端收到客户端的 ACK 响应时,会将该连接从半连接队列移动到全连接队列,或者重传N次后从半连接队列删除。
在 TCP 三次握手过程中,第三次握手是可以携带数据的(客户端发送完 ACK 确认包之后就进入
ESTABLISHED状态了)。
TCP四次挥手(重要)
断开一个 TCP 连接则需要“四次挥手”,才能确认双方都断开连接,缺一不可:
第一次挥手:客户端发起关闭请求,即发送一个 FIN(SEQ=x) 标志的数据包到服务端,然后进入 FIN-WAIT-1 状态。
第二次挥手:服务端确认关闭请求,即回复一个 ACK (ACK=x+1)标志的数据包给客户端,此时服务端进入 CLOSE-WAIT 状态,客户端进入 FIN-WAIT-2 状态。
第三次挥手:服务端在数据发送完毕后,同样发起关闭请求,即发送一个 FIN (SEQ=y) 标志的数据包到客户端,然后进入 LAST-ACK 状态。
第四次挥手:客户端确认关闭请求,即发送 ACK (ACK=y+1) 标志的数据包,然后客户端进入TIME-WAIT状态,服务端在收到 ACK (ACK=y+1) 标志的数据包后进入 CLOSE 状态。此时如果客户端等待 2MSL 后依然没有收到回复,就证明服务端已正常关闭,随后客户端也可以关闭连接了。
只要四次挥手没有结束,客户端和服务端就可以继续传输数据!
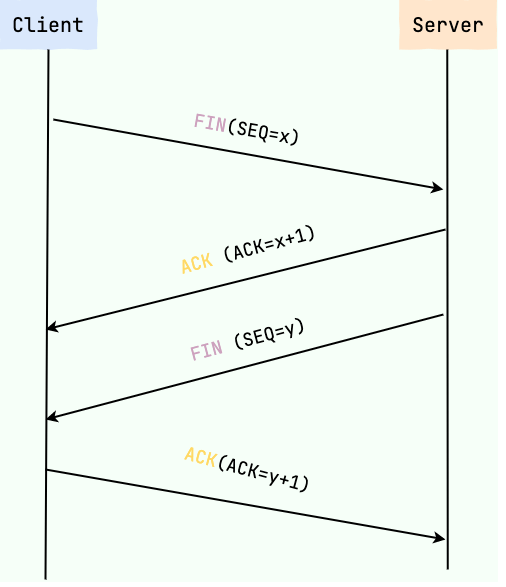
注意:
关闭连接时交互次数由三次拆分成了四次,因为在服务端ACK时,还需将剩余数据包发完,等一下再发送FIN关闭连接。
第四次挥手时,客户端发送给服务端的 ACK 有可能丢失,因此需要等待2MSL ,应答服务器重传过来的FIN请求。
TCP如何保证传输的可靠性?
数据包序号:给数据包进行编号,在收到后进行排序和去重,并检查是否存在丢包。
校验和:TCP 将保持它首部和数据的检验和。
重传机制:在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。
流量控制:TCP接收端可通过滑动窗口协议控制发送端发送速率,保证接收方来得及接收,防止缓冲区溢出丢包。
拥塞控制:发送端根据拥塞窗口控制发送速率,当网络拥塞时,减少数据的发送。
6. 其它网络协议
IP协议
IP(Internet Protocol,互联网协议) 属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。
IP地址是在互联网上唯一标识设备的逻辑地址,通常用于跨网络通信,可以静态分配或基于 DHCP 协议动态分配。
它有两种主流版本:
IPV4:使用 32 位地址,通常表示为点分十进制形式(如:192.168.1.1),可用地址总数为2³²,约43亿个地址。
IPV6:使用 128 位地址,通常表示为冒号分隔的十六进制形式(如:2001:0db8:85a3:0000:0000:8a2e:0370:7334),表示范围非常大。
在发送数据包时,网络设备根据目的IP地址将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
NAT协议
NAT(Network Address Translation,网络地址转换) 主要用于公有 IP 和私有 IP 之间的映射,从而实现局域网内的多个设备通过一个公有 IP 地址访问互联网。
主要作用如下:
缓解 IPv4 地址资源短缺的问题。
隐藏内部网络的实际拓扑结构,使得外部网络无法直接访问内部网络中的设备,从而提高了内部网络的安全性。
ARP协议
ARP 协议,地址解析协议(Address Resolution Protocol),解决的是网络层地址(IP地址)和链路层地址(MAC地址)之间的转换问题。
解析流程如下:
首先检查本地的ARP缓存表,查看是否已经存储了目标 IP 地址对应的 MAC 地址。
如果缓存中没有目标 IP 的 MAC 地址,则构造一个 ARP 请求报文(包括源IP、源MAC、目的IP等)在当前局域网进行广播问询。
局域网内的所有主机都会收到ARP请求,并检查请求中的目标IP地址是否与自己的IP地址匹配,如果匹配则进行单播响应。
请求主机收到 ARP 响应后,更新自己的 ARP 缓存表中,并使用目标主机的 MAC 地址封装数据帧,然后发送数据。
注意:
如果目标IP地址不在同一子网,则以类似方式获取目标IP子网所在路由器MAC地址,再进行发送。
MAC地址是在局域网中唯一标识设备的硬件地址,通常用于局域网内的通信,由网络设备的制造商在生产时预先分配。
MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
ICMP协议
互联网控制报文协议(Internet Control Message Protocol)是一种用于传输网络状态和错误消息的网络层协议,它的报文类型可分为:
查询报文类型:向目标主机发送请求并期望得到响应。
差错报文类型:向源主机发送错误信息,用于报告网络中的错误情况。
PING 命令是一种基于ICMP协议的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
71C:\Users\Administrator>ping www.baidu.com2
3正在 Ping www.a.shifen.com [183.240.99.169] 具有 32 字节的数据:4来自 183.240.99.169 的回复: 字节=32 时间=14ms TTL=525来自 183.240.99.169 的回复: 字节=32 时间=14ms TTL=526来自 183.240.99.169 的回复: 字节=32 时间=13ms TTL=527来自 183.240.99.169 的回复: 字节=32 时间=14ms TTL=52注意:
其中
TTL指生存时间(Time To Live),用于控制数据包在网络中的最大跳数,防止数据包在网络中无限循环。PING 命令会向目标主机发送 ICMP Echo Request(报文类型为 8 ),如果两个主机的连通性正常,目标主机会返回一个对应的 ICMP Echo Reply(报文类型为 0)。
7. 常见网络攻击手段
IP欺骗
IP欺骗指通过伪造IP地址和目标主机进行通信,该IP地址一般是受信任的IP地址。
攻击手段:如发送 RST 数据包使服务端断开与该 IP 的连接等。
防御措施:在内部网络的入口和出口进行过滤,检查数据包源标头,防止伪造数据包渗透网络。
DDos攻击
DDos(Distributed Denial of Service),分布式拒绝服务,指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,是一种分布的、协同的大规模攻击方式。
攻击手段:无效HTTP请求;无效UDP数据包;无效 SYN 报文,使服务端创建大量半连接等。
防御措施:高防服务器;IP黑名单;CDN加速;DDos清洗(清洗异常流量)等。
中间人攻击
中间人攻击指攻击者与通信双方建立连接,并在中间修改传输内容,常见防御措施有:引入第三方机构验证数字证书和签名。
第02章_数据结构
第一节 线性表
1. 数组与链表
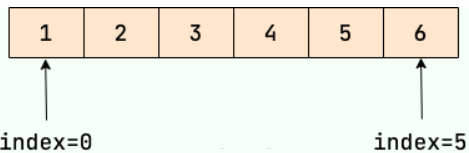
什么是数组?
数组(Array)是一种基本的数据结构,它由一组相同类型的数据元素组成,这些元素在内存中是连续存储的。
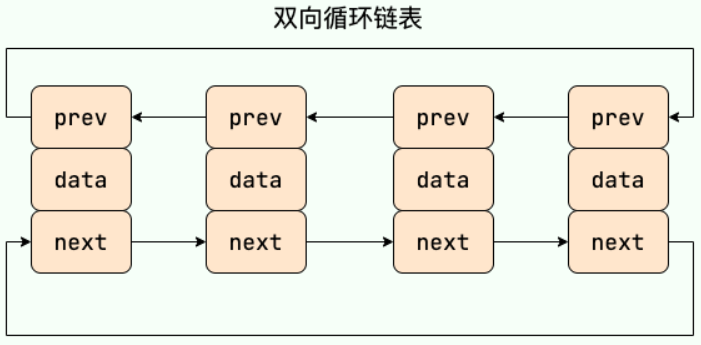
什么是链表?
链表(Linked List)是一种通过指针将节点连接起来的线性数据结构,支持动态存储和高效的插入与删除操作。
链表可分为:单向链表、双向链表、循环链表、双向循环链表等。
数组 vs 链表
| 特性/指标 | 数组 | 链表 |
|---|---|---|
| 内存分配 | 静态分配,大小固定,连续存储 | 动态分配,大小可变,分散存储 |
| 访问效率 | 随机访问,时间复杂度 O(1) | 顺序访问,时间复杂度 O(n) |
| 插入/删除 | 需要移动大量元素,时间复杂度 O(n) | 修改指针即可,时间复杂度 O(1) |
| 内存利用 | 内存利用率高,可能浪费部分内存 | 内存利用率低,额外的指针开销 |
| 适用场景 | 频繁随机访问元素,固定大小数据存储 | 频繁插入和删除操作,动态大小数据存储 |
| 不适用场景 | 频繁插入和删除操作 | 频繁随机访问元素 |
实现一个动态数组
991// 【动态数组】实现关键点:2// 1. 定义一个存放数组元素的数组,并记录最大容量、当前已用容量。3// 2. 每次入栈之前先判断数组的容量是否够用,如果不够用就用 Arrays.copyOf() 进行扩容。4public class SimpleDynamicArray {5 private int[] array; // 底层数组6 private int size; // 当前数组中存储的元素数量7 private int capacity; // 数组的容量8
9 // 构造函数,初始化动态数组10 public SimpleDynamicArray() {11 this.capacity = 10; // 初始容量为1012 this.array = new int[capacity];13 this.size = 0;14 }15
16 // 添加元素17 public void add(int value) {18 if (size == capacity) {19 resize(); // 如果数组已满,扩容20 }21 array[size++] = value;22 }23
24 // 获取元素25 public int get(int index) {26 if (index < 0 || index >= size) {27 throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);28 }29 return array[index];30 }31
32 // 设置元素33 public void set(int index, int value) {34 if (index < 0 || index >= size) {35 throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);36 }37 array[index] = value;38 }39
40 // 删除元素41 public void remove(int index) {42 if (index < 0 || index >= size) {43 throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);44 }45 for (int i = index; i < size - 1; i++) {46 array[i] = array[i + 1];47 }48 size--;49 }50
51 // 获取数组大小52 public int size() {53 return size;54 }55
56 // 扩容机制57 private void resize() {58 int newCapacity = capacity * 2; // 新容量为当前容量的两倍59 int[] newArray = new int[newCapacity];60 for (int i = 0; i < size; i++) {61 newArray[i] = array[i];62 }63 array = newArray;64 capacity = newCapacity;65 }66
67 // 打印数组68 public void printArray() {69 for (int i = 0; i < size; i++) {70 System.out.print(array[i] + " ");71 }72 System.out.println();73 }74
75 // 主函数,用于测试动态数组76 public static void main(String[] args) {77 SimpleDynamicArray dynamicArray = new SimpleDynamicArray();78
79 dynamicArray.add(10);80 dynamicArray.add(20);81 dynamicArray.add(30);82 dynamicArray.add(40);83
84 System.out.println("Array after adding elements:");85 dynamicArray.printArray();86
87 System.out.println("Element at index 2: " + dynamicArray.get(2));88
89 dynamicArray.set(2, 300);90 System.out.println("Array after setting element at index 2 to 300:");91 dynamicArray.printArray();92
93 dynamicArray.remove(1);94 System.out.println("Array after removing element at index 1:");95 dynamicArray.printArray();96
97 System.out.println("Current size: " + dynamicArray.size());98 }99}
实现一个双向循环链表
1211// 【双向循环链表】实现关键点:2// 1. 定义一个节点类、头节点,节点类包括:目标类型的data、Node类型的前驱节点和后继节点3// 2. 注意边界条件处理:链表为空、链表元素为单个、链表元素为多个时处理情况可能不同。4public class DoublyCircularLinkedList {5 // 定义节点类6 private class Node {7 int data;8 Node prev;9 Node next;10
11 Node(int data) {12 this.data = data;13 this.prev = null;14 this.next = null;15 }16 }17
18 // 定义链表的头节点19 private Node head;20
21 // 构造函数22 public DoublyCircularLinkedList() {23 this.head = null;24 }25
26 // 在链表尾部插入节点27 public void insert(int data) {28 Node newNode = new Node(data);29 if (head == null) {30 head = newNode;31 head.next = head;32 head.prev = head;33 } else {34 Node tail = head.prev;35 tail.next = newNode;36 newNode.prev = tail;37 newNode.next = head;38 head.prev = newNode;39 }40 }41
42 // 删除指定值的节点43 public void delete(int data) {44 if (head == null) {45 System.out.println("List is empty");46 return;47 }48
49 Node current = head;50 do {51 if (current.data == data) {52 if (current == current.next) { // 只有一个节点53 head = null;54 } else {55 current.prev.next = current.next;56 current.next.prev = current.prev;57 if (current == head) { // 如果删除的是头节点58 head = head.next;59 }60 }61 System.out.println("Deleted: " + data);62 return;63 }64 current = current.next;65 } while (current != head);66
67 System.out.println("Element not found");68 }69
70 // 查找指定值的节点71 public boolean find(int data) {72 if (head == null) {73 return false;74 }75
76 Node current = head;77 do {78 if (current.data == data) {79 return true;80 }81 current = current.next;82 } while (current != head);83
84 return false;85 }86
87 // 打印链表88 public void printList() {89 if (head == null) {90 System.out.println("List is empty");91 return;92 }93
94 Node current = head;95 do {96 System.out.print(current.data + " ");97 current = current.next;98 } while (current != head);99 System.out.println();100 }101
102 // 主函数,用于测试双向循环链表103 public static void main(String[] args) {104 DoublyCircularLinkedList list = new DoublyCircularLinkedList();105
106 list.insert(10);107 list.insert(20);108 list.insert(30);109 list.insert(40);110
111 System.out.println("List after insertion:");112 list.printList();113
114 list.delete(20);115 System.out.println("List after deleting 20:");116 list.printList();117
118 System.out.println("Find 30: " + list.find(30));119 System.out.println("Find 50: " + list.find(50));120 }121}
2.栈与队列
什么是栈?
栈是一种后进先出(LIFO)的线性数据结构,支持在栈顶进行元素的插入和删除操作,常用一维数组或链表来实现。
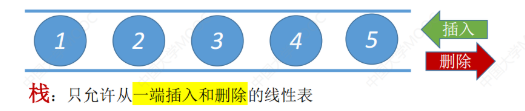
常见的应用场景有:函数调用、表达式解析、撤销/重做功能、回溯算法、深度优先搜索(DFS)等。
什么是队列?
队列是一种先进先出(FIFO)的线性数据结构,支持在队尾插入元素和在队头删除元素,常用一维数组或链表来实现。
队列可分为:单队列、循环队列、双端队列、优先级队列(堆,非线性)等。

常见的应用场景有:消息传递、对象池(线程池、连接池)、模拟栈、广度优先算法(BFS)等。
实现一个栈
691// 【栈】实现关键点:2// 1. 定义一个存放栈元素的数组,并记录最大容量、当前已用容量。3// 2. 每次入栈之前先判断栈的容量是否够用,如果不够用就用 Arrays.copyOf() 进行扩容。4public class MyStack {5 private int[] storage;//存放栈中元素的数组6 private int capacity;//栈的容量7 private int count;//栈中元素数量8 private static final int GROW_FACTOR = 2;9
10 //不带初始容量的构造方法。默认容量为811 public MyStack() {12 this.capacity = 8;13 this.storage=new int[8];14 this.count = 0;15 }16
17 //带初始容量的构造方法18 public MyStack(int initialCapacity) {19 if (initialCapacity < 1)20 throw new IllegalArgumentException("Capacity too small.");21
22 this.capacity = initialCapacity;23 this.storage = new int[initialCapacity];24 this.count = 0;25 }26
27 //入栈28 public void push(int value) {29 if (count == capacity) {30 ensureCapacity();31 }32 storage[count++] = value;33 }34
35 //确保容量大小36 private void ensureCapacity() {37 int newCapacity = capacity * GROW_FACTOR;38 storage = Arrays.copyOf(storage, newCapacity);39 capacity = newCapacity;40 }41
42 //返回栈顶元素并出栈43 private int pop() {44 if (count == 0)45 throw new IllegalArgumentException("Stack is empty.");46 count--;47 return storage[count];48 }49
50 //返回栈顶元素不出栈51 private int peek() {52 if (count == 0){53 throw new IllegalArgumentException("Stack is empty.");54 }else {55 return storage[count-1];56 }57 }58
59 //判断栈是否为空60 private boolean isEmpty() {61 return count == 0;62 }63
64 //返回栈中元素的个数65 private int size() {66 return count;67 }68
69}
实现一个双端队列
1291// 【双端队列】实现关键点:2// 1. 定义一个节点类、头节点、尾节点,节点类包括:目标类型的data、Node类型的前驱节点和后继节点3// 2. 注意边界条件处理:队列为空、队列元素为单个、队列元素为多个时处理情况可能不同。4public class Deque {5 // 定义节点类6 private class Node {7 int data;8 Node prev;9 Node next;10
11 Node(int data) {12 this.data = data;13 this.prev = null;14 this.next = null;15 }16 }17
18 // 双端队列的头节点和尾节点19 private Node head;20 private Node tail;21
22 // 在队头插入元素23 public void addFirst(int data) {24 Node newNode = new Node(data);25 if (head == null) {26 head = tail = newNode; // 如果队列为空,头尾节点都指向新节点27 } else {28 newNode.next = head; // 新节点的下一个指向当前头节点29 head.prev = newNode; // 当前头节点的上一个指向新节点30 head = newNode; // 更新头节点为新节点31 }32 }33
34 // 在队尾插入元素35 public void addLast(int data) {36 Node newNode = new Node(data);37 if (tail == null) {38 head = tail = newNode; // 如果队列为空,头尾节点都指向新节点39 } else {40 newNode.prev = tail; // 新节点的上一个指向当前尾节点41 tail.next = newNode; // 当前尾节点的下一个指向新节点42 tail = newNode; // 更新尾节点为新节点43 }44 }45
46 // 从队头删除元素47 public int removeFirst() {48 if (isEmpty()) {49 throw new IllegalStateException("Deque is empty");50 }51 int data = head.data; // 获取队头元素52 if (head == tail) {53 head = tail = null; // 如果队列只有一个元素,清空队列54 } else {55 head = head.next; // 移动头节点指针56 head.prev = null; // 清除旧头节点的引用57 }58 return data;59 }60
61 // 从队尾删除元素62 public int removeLast() {63 if (isEmpty()) {64 throw new IllegalStateException("Deque is empty");65 }66 int data = tail.data; // 获取队尾元素67 if (head == tail) {68 head = tail = null; // 如果队列只有一个元素,清空队列69 } else {70 tail = tail.prev; // 移动尾节点指针71 tail.next = null; // 清除旧尾节点的引用72 }73 return data;74 }75
76 // 查看队头元素77 public int peekFirst() {78 if (isEmpty()) {79 throw new IllegalStateException("Deque is empty");80 }81 return head.data;82 }83
84 // 查看队尾元素85 public int peekLast() {86 if (isEmpty()) {87 throw new IllegalStateException("Deque is empty");88 }89 return tail.data;90 }91
92 // 检查双端队列是否为空93 public boolean isEmpty() {94 return head == null;95 }96
97 // 打印双端队列98 public void printDeque() {99 Node current = head;100 while (current != null) {101 System.out.print(current.data + " ");102 current = current.next;103 }104 System.out.println();105 }106
107 // 主函数,用于测试双端队列108 public static void main(String[] args) {109 Deque deque = new Deque();110
111 deque.addFirst(10);112 deque.addLast(20);113 deque.addFirst(5);114 deque.addLast(30);115
116 System.out.println("Deque after adding elements:");117 deque.printDeque();118
119 System.out.println("Remove from front: " + deque.removeFirst());120 System.out.println("Remove from rear: " + deque.removeLast());121 System.out.println("Deque after removing elements:");122 deque.printDeque();123
124 System.out.println("Peek front: " + deque.peekFirst());125 System.out.println("Peek rear: " + deque.peekLast());126 System.out.println("Deque after peeking:");127 deque.printDeque();128 }129}
第二节 树
1. 树
什么是树?
树是一种非线性数据结构,它由一个或多个节点组成,用于表示具有层次关系的数据。它的组成元素如下:
节点:每个元素即为一个节点,没有父节点的节点为根节点,没有子节点的节点为叶子节点,相同父节点的节点互称为兄弟节点。
度:一个节点含有的子树的个数称为该节点的度,树内各节点的度的最大值称为树的度。
深度:节点的深度指根节点到该节点的路径所包含的边数,树的深度是根节点到最远叶子节点的路径所包含的边数。
高度:节点的高度指该节点到叶子节点的最长路径所包含的边数,树的高度是根节点的高度。
树的分类
树可分为:
二叉树:每个节点最多有两个子节点,通常称为左子节点和右子节点。
二叉搜索树:对于任意节点,其左子树的值
<=该节点,右子树的值>=该节点。二叉查找树可能演变为斜树,如下。
平衡二叉树:对于任意节点,其左右子树的高度差不超过
N,常用实现方法有: 红黑树、AVL 树、加权平衡树、伸展树 等。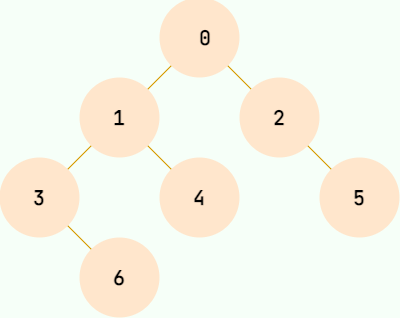
完全二叉树:从根节点到倒数第二层满足满二叉树的条件,且最后一层的节点从左到右连续分布。
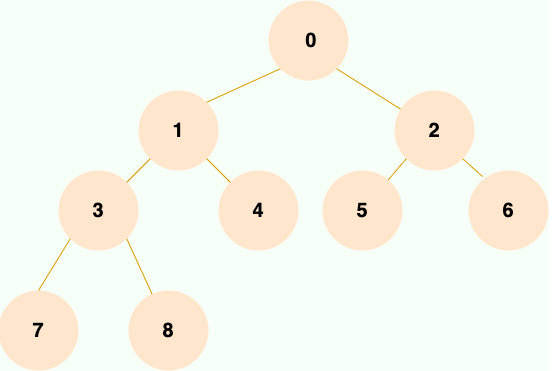
满二叉树:除了叶子节点外,每个节点都有两个子节点,并且所有叶子节点都在同一层。
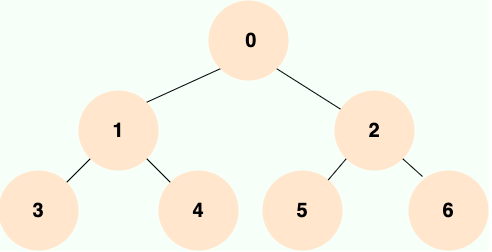
多叉树:每个节点可以有多个子节点,子节点的数量没有限制。
B树:每个节点存储多个键值,并且所有叶子节点都在同一层,可以保证在查找、插入和删除操作时,磁盘I/O操作次数较少,主要用于数据库和文件系统的索引。
B+树:是B树的一种变体,所有键值都存储在叶子节点中,叶子节点之间通过指针相连,形成一个有序链表。在数据库索引和文件系统索引中应用广泛,它更适合范围查询操作。
其它树:
T树:一种平衡二叉树,每个节点可以存储多个键值以减少树的高度,从而提高查找效率,主要用于内存数据库和缓存系统中。
字典树:每个节点表示一个字符,从根到某节点的路径表示一个字符串,常用于字符串匹配、前缀查找等。
后缀树:用于存储字符串所有后缀的树形结构,支持高效的子串查找和模式匹配,常用于文本处理和生物信息学。
决策树:通过树形结构表示决策规则,每个节点表示一个特征的判断条件,常用于数据挖掘和机器学习。
线段树:每个节点表示一个区间,常用于处理数组的区间求和、区间最大值等问题。
霍夫曼树:用于数据压缩的树形结构,通过频率构建最优二叉树,常用于霍夫曼编码。
区间树:用于存储和查询区间的数据结构,常用于几何问题和时间表问题。
并查集树:用于处理不相交集合的数据结构,支持快速的查找和合并操作,常用于图的连通性问题。
提示:
B+树相对于比B树,查询次数更少、查询效率更文档,且更适合范围查询(B树需要通过中序遍历进行范围查询)。
树的存储
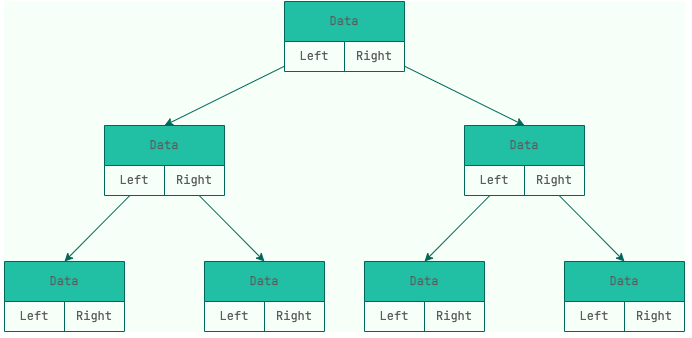
树的存储主要分为:
链式存储:依靠指针将各个节点串联起来,不需要连续的存储空间。
顺序存储:使用数组存储节点数据,通过数组下标来定位子节点的位置。根结点索引为
1,左节点为2i,右节点为2i+1。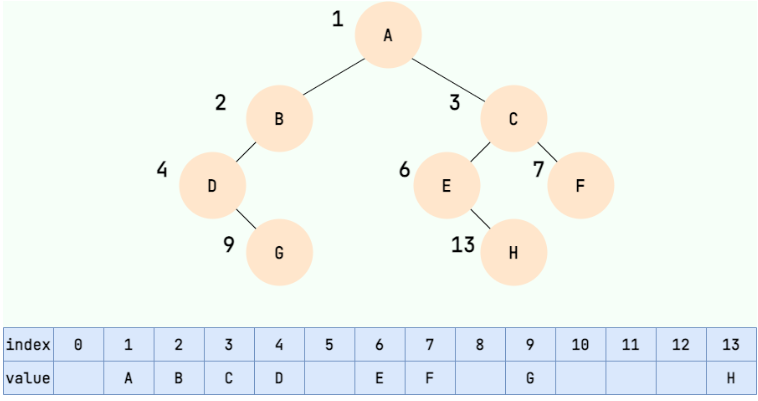
注意:
顺序存储一般用于二叉树,且是完全二叉树(如:堆等),否则数组中就会出现空隙,导致内存利用率降低。
树的遍历
树的遍历主要分为:
先序遍历:先输出根结点,再遍历左子树,最后遍历右子树,遍历左子树和右子树的时候,同样遵循先序遍历的规则。
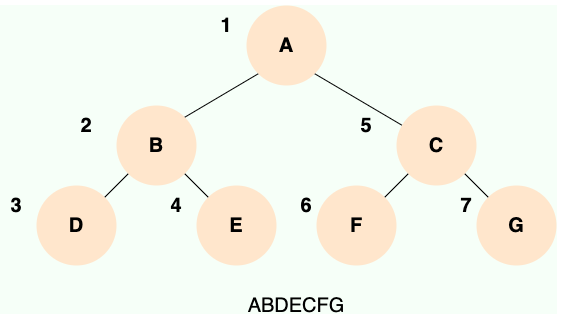 81
81public void preOrder(TreeNode root){2if(root == null){3return;4}5system.out.println(root.data);6preOrder(root.left);7preOrder(root.right);8}中序遍历:先递归中序遍历左子树,再输出根结点的值,再递归中序遍历右子树。
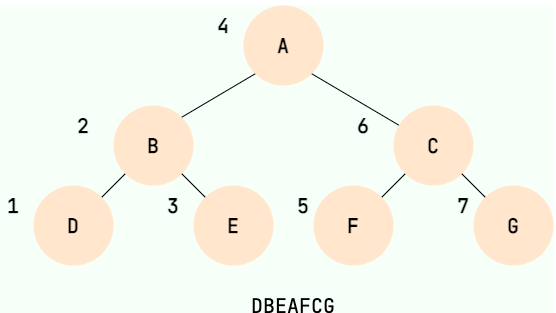 81
81public void inOrder(TreeNode root){2if(root == null){3return;4}5inOrder(root.left);6system.out.println(root.data);7inOrder(root.right);8}后序遍历:先递归后序遍历左子树,再递归后序遍历右子树,最后输出根结点的值。
 81
81public void postOrder(TreeNode root){2if(root == null){3return;4}5postOrder(root.left);6postOrder(root.right);7system.out.println(root.data);8}
注意:
先序/中序/后序指的是根节点先遍历,或中间遍历,或最后遍历。
树的遍历还可以通过循环来实现,可以是基于栈的深度优先遍历或基于队列的广度优先遍历。
2. 平衡二叉树
AVL树和红黑树的区别?
AVL树:任意节点的左右子树高度差的绝对值不超过
1,适用于对查找效率要求较高的场景,例如数据库索引、字典等。红黑树:通过在节点上添加颜色属性(红色或黑色)来保证树的平衡性,如C++中的
std::map、Java中的TreeMap等。
红黑树的特性
除了满足二叉搜索树的基本前提外,还需额外满足如下条件,以维持二叉树的平衡:
根叶红:*根节点和叶子节点(空节点)必须是黑色*,中间节点可以是黑色或红色。
不红红:不能有两个连续的红色节点,即红色节点的两个子节点都必须是黑色。
黑路同:从任意节点到其每个叶子的所有路径都包含相同数量的黑色节点。
注意:
红黑树可以保证:最长路径不超过最短路径的两倍,即任意节点左右子树的高度差不超过两倍。
为什么红黑树插入节点默认为红色?
当插入黑色节点时,由于多了一个黑色节点,必然会破坏黑路同特性,则必须调整红黑树。
但当插入红色节点时,由于黑色节点数不变,必不会破坏黑路同特性,只可能会破坏根叶黑或不红红,调整起来更加方便。
红黑树破坏后怎么调整?
破坏了根叶黑:即插入节点是根节点,根节点直接变黑即可。
破坏了不红红:
红色叔叔: 叔父爷变色,爷爷变插入节点,递归判断。
黑色叔叔:旋转(LL、RR、LR、RL),然后变色。
实现一个红黑树
视频讲解:https://www.bilibili.com/video/BV1Xm421x7Lg?vd_source=c27a4551ddd1aa07c2454e0df15bc296
1161// 【红黑树】实现关键点:2// 1. 定义一个节点类和根节点,节点类包括:键值、颜色以及左右子节点指针3// 2. 在插入操作时通过调色和旋转维持平衡。4public class RedBlackTree {5 // 节点颜色6 private static final boolean RED = true;7 private static final boolean BLACK = false;8
9 // 节点类10 private class Node {11 int key;12 boolean color; // RED 或 BLACK13 Node left, right;14
15 public Node(int key) {16 this.key = key;17 this.color = RED; // 新节点默认为红色18 this.left = null;19 this.right = null;20 }21 }22
23 // 根节点24 private Node root;25
26 // 判断节点颜色27 private boolean isRed(Node node) {28 if (node == null) return false;29 return node.color == RED;30 }31
32 // 左旋操作33 private Node rotateLeft(Node h) {34 Node x = h.right;35 h.right = x.left;36 x.left = h;37 x.color = h.color;38 h.color = RED;39 return x;40 }41
42 // 右旋操作43 private Node rotateRight(Node h) {44 Node x = h.left;45 h.left = x.right;46 x.right = h;47 x.color = h.color;48 h.color = RED;49 return x;50 }51
52 // 翻转颜色53 private void flipColors(Node h) {54 h.color = RED;55 h.left.color = BLACK;56 h.right.color = BLACK;57 }58
59 // 插入操作60 public void insert(int key) {61 root = insert(root, key);62 root.color = BLACK; // 根节点必须是黑色63 }64
65 private Node insert(Node h, int key) {66 if (h == null) return new Node(key);67
68 if (key < h.key) {69 h.left = insert(h.left, key);70 } else if (key > h.key) {71 h.right = insert(h.right, key);72 } else {73 h.key = key; // 如果键已存在,更新键值74 }75
76 // 修复红黑树性质77 if (isRed(h.right) && !isRed(h.left)) {78 h = rotateLeft(h);79 }80 if (isRed(h.left) && isRed(h.left.left)) {81 h = rotateRight(h);82 }83 if (isRed(h.left) && isRed(h.right)) {84 flipColors(h);85 }86
87 return h;88 }89
90 // 中序遍历(用于测试)91 public void inorderTraversal() {92 inorderHelper(root);93 System.out.println();94 }95
96 private void inorderHelper(Node node) {97 if (node == null) return;98 inorderHelper(node.left);99 System.out.print(node.key + " ");100 inorderHelper(node.right);101 }102
103 // 测试代码104 public static void main(String[] args) {105 RedBlackTree rbTree = new RedBlackTree();106 rbTree.insert(10);107 rbTree.insert(20);108 rbTree.insert(30);109 rbTree.insert(40);110 rbTree.insert(50);111 rbTree.insert(25);112
113 System.out.println("Inorder traversal of the constructed Red-Black Tree:");114 rbTree.inorderTraversal();115 }116}
3. B+树
B+树的特性
每个节点最多有 M 个子节点(M 是阶数)。
每个节点最少有 ⌈M/2⌉ 个子节点,除了根节点。
所有叶子节点都位于同一层,并且通过指针连接。
非叶子节点不存储数据,只存储键值用于索引。
叶子节点存储实际数据。
实现一个B+树
1751// 【B+树】实现关键点:2// 1. 定义一个节点类和根节点,节点类包括:键值、颜色以及左右子节点指针3// 2. 在插入操作时通过调色和旋转维持平衡。4import java.util.ArrayList;5import java.util.List;6
7public class BPlusTree {8 private static final int M = 4; // 阶数,每个节点最多有 M 个子节点9 private Node root;10
11 // 节点类12 private abstract class Node {13 int keyCount; // 当前节点的键值数量14 List<Integer> keys; // 键值列表15
16 Node() {17 keyCount = 0;18 keys = new ArrayList<>();19 }20
21 // 插入键值22 abstract void insert(int key);23
24 // 中序遍历25 abstract void inorderTraversal();26 }27
28 // 内部节点类29 private class InternalNode extends Node {30 List<Node> children; // 子节点列表31
32 InternalNode() {33 super();34 children = new ArrayList<>();35 }36
37 38 void insert(int key) {39 int i = 0;40 while (i < keyCount && key > keys.get(i)) {41 i++;42 }43
44 // 插入到子节点45 if (children.get(i) instanceof LeafNode) {46 children.get(i).insert(key);47 } else {48 children.get(i).insert(key);49 }50
51 // 如果子节点分裂,处理分裂后的节点52 if (children.get(i) instanceof LeafNode && ((LeafNode) children.get(i)).keyCount > M - 1) {53 splitLeaf((LeafNode) children.get(i), i);54 } else if (children.get(i) instanceof InternalNode && ((InternalNode) children.get(i)).keyCount > M - 1) {55 splitInternal((InternalNode) children.get(i), i);56 }57 }58
59 60 void inorderTraversal() {61 for (int i = 0; i < keyCount; i++) {62 children.get(i).inorderTraversal();63 System.out.print(keys.get(i) + " ");64 }65 children.get(keyCount).inorderTraversal();66 }67
68 // 分裂叶子节点69 private void splitLeaf(LeafNode leaf, int index) {70 LeafNode newLeaf = new LeafNode();71 newLeaf.keys.addAll(leaf.keys.subList(M / 2, leaf.keyCount));72 newLeaf.keyCount = M / 2;73 leaf.keys.subList(M / 2, leaf.keyCount).clear();74 leaf.keyCount = M / 2;75
76 keys.add(index, leaf.keys.get(M / 2 - 1));77 keyCount++;78
79 children.add(index + 1, newLeaf);80
81 if (leaf.next != null) {82 newLeaf.next = leaf.next;83 leaf.next = newLeaf;84 }85 }86
87 // 分裂内部节点88 private void splitInternal(InternalNode internal, int index) {89 InternalNode newInternal = new InternalNode();90 newInternal.keys.addAll(internal.keys.subList(M / 2, internal.keyCount));91 newInternal.children.addAll(internal.children.subList(M / 2 + 1, internal.children.size()));92 newInternal.keyCount = M / 2;93
94 internal.keys.subList(M / 2, internal.keyCount).clear();95 internal.children.subList(M / 2 + 1, internal.children.size()).clear();96 internal.keyCount = M / 2;97
98 keys.add(index, internal.keys.get(M / 2 - 1));99 keyCount++;100
101 children.add(index + 1, newInternal);102 }103 }104
105 // 叶子节点类106 private class LeafNode extends Node {107 LeafNode next; // 指向下一个叶子节点108
109 LeafNode() {110 super();111 }112
113 114 void insert(int key) {115 int i = 0;116 while (i < keyCount && key > keys.get(i)) {117 i++;118 }119 keys.add(i, key);120 keyCount++;121 }122
123 124 void inorderTraversal() {125 for (int key : keys) {126 System.out.print(key + " ");127 }128 }129 }130
131 // 插入操作132 public void insert(int key) {133 if (root == null) {134 root = new LeafNode();135 }136
137 root.insert(key);138
139 // 如果根节点分裂,创建新的根节点140 if (root instanceof LeafNode && ((LeafNode) root).keyCount > M - 1) {141 InternalNode newRoot = new InternalNode();142 LeafNode oldRoot = (LeafNode) root;143 newRoot.splitLeaf(oldRoot, 0);144 root = newRoot;145 } else if (root instanceof InternalNode && ((InternalNode) root).keyCount > M - 1) {146 InternalNode newRoot = new InternalNode();147 InternalNode oldRoot = (InternalNode) root;148 newRoot.splitInternal(oldRoot, 0);149 root = newRoot;150 }151 }152
153 // 中序遍历154 public void inorderTraversal() {155 if (root != null) {156 root.inorderTraversal();157 }158 System.out.println();159 }160
161 // 测试代码162 public static void main(String[] args) {163 BPlusTree bPlusTree = new BPlusTree();164 bPlusTree.insert(10);165 bPlusTree.insert(20);166 bPlusTree.insert(30);167 bPlusTree.insert(40);168 bPlusTree.insert(50);169 bPlusTree.insert(60);170 bPlusTree.insert(70);171
172 System.out.println("Inorder traversal of the constructed B+ Tree:");173 bPlusTree.inorderTraversal();174 }175}
4. 堆(存于数组的逻辑树)
什么是堆?
堆是基于数组顺序存储的,在逻辑上近似完全二叉树的非线性数据结构,可分为:
大顶堆:堆中的每一个节点的值都大于等于子树中所有节点的值。
小顶堆:堆中的每一个节点的值都小于等于子树中所有节点的值。
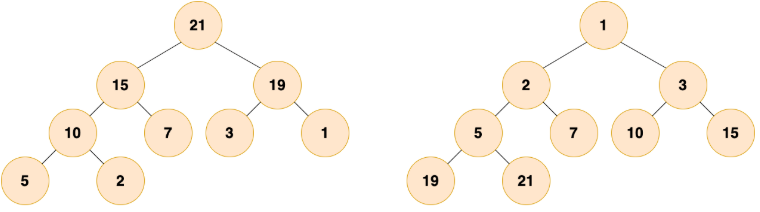
堆常用于:实现优先级队列或解决最大值或最小值问题。
实现一个堆
1181// 【B+树】实现关键点:2// 1. 定义一个数组存储数据,并记录堆的最大容量和当前已用容量3// 2. 在尾部插入操作时进行上浮操作,在头部删除时进行下沉操作,确保堆的性质4// 3. 根节点的索引为1,根结点索引为 1,左节点为2i,右节点为2i+1。5public class MaxHeap {6 private int[] heap; // 用数组表示堆7 private int size; // 堆的当前大小8 private int capacity; // 堆的最大容量9
10 // 构造函数11 public MaxHeap(int capacity) {12 this.capacity = capacity;13 this.size = 0;14 this.heap = new int[capacity];15 }16
17 // 插入元素18 public void insert(int value) {19 if (size == capacity) {20 throw new IllegalStateException("Heap is full");21 }22
23 // 将新元素添加到堆的末尾24 heap[size] = value;25 size++;26
27 // 上浮操作,确保堆的性质28 heapifyUp(size - 1);29 }30
31 // 删除最大元素(堆顶元素)32 public int deleteMax() {33 if (size == 0) {34 throw new IllegalStateException("Heap is empty");35 }36
37 int max = heap[0]; // 堆顶元素是最大值38 heap[0] = heap[size - 1]; // 将最后一个元素移到堆顶39 size--;40 heapifyDown(0); // 下沉操作,确保堆的性质41
42 return max;43 }44
45 // 上浮操作46 private void heapifyUp(int index) {47 while (index > 0) {48 int parentIndex = (index - 1) / 2;49 if (heap[index] > heap[parentIndex]) {50 // 如果当前节点大于父节点,交换它们51 swap(index, parentIndex);52 index = parentIndex;53 } else {54 break;55 }56 }57 }58
59 // 下沉操作60 private void heapifyDown(int index) {61 while (true) {62 int leftChildIndex = 2 * index + 1;63 int rightChildIndex = 2 * index + 2;64 int largestIndex = index;65
66 // 比较左子节点67 if (leftChildIndex < size && heap[leftChildIndex] > heap[largestIndex]) {68 largestIndex = leftChildIndex;69 }70
71 // 比较右子节点72 if (rightChildIndex < size && heap[rightChildIndex] > heap[largestIndex]) {73 largestIndex = rightChildIndex;74 }75
76 // 如果当前节点不是最大值,交换77 if (largestIndex != index) {78 swap(index, largestIndex);79 index = largestIndex;80 } else {81 break;82 }83 }84 }85
86 // 交换两个节点的值87 private void swap(int i, int j) {88 int temp = heap[i];89 heap[i] = heap[j];90 heap[j] = temp;91 }92
93 // 打印堆的内容94 public void printHeap() {95 for (int i = 0; i < size; i++) {96 System.out.print(heap[i] + " ");97 }98 System.out.println();99 }100
101 // 测试代码102 public static void main(String[] args) {103 MaxHeap maxHeap = new MaxHeap(10);104
105 maxHeap.insert(10);106 maxHeap.insert(20);107 maxHeap.insert(15);108 maxHeap.insert(30);109 maxHeap.insert(40);110
111 System.out.println("Heap after insertions:");112 maxHeap.printHeap();113
114 System.out.println("Deleted max element: " + maxHeap.deleteMax());115 System.out.println("Heap after deletion:");116 maxHeap.printHeap();117 }118}
第三节 图
1. 图的基本概念
什么是图?
图是一种由顶点和边组成的非线性数据结构,用于表示对象之间的复杂关系。它的组成元素如下:
顶点:每个元素即为一个顶点,图至少有一个顶点。
边:顶点之间的关系用边表示。
度:一个顶点包含多少条边则表示多少度,有向图还分出度和入度。
图的分类与应用
图可分为:无向图和有向图、无权图和带权图,下面是一张带权有向图。
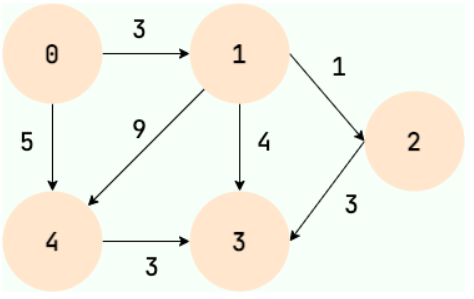
常见的应用场景有:同学关系图(无向图)、抖音关注关系图(有向图)、城市交通图(带权有向图,使用距离作为权)等。
图的存储方式
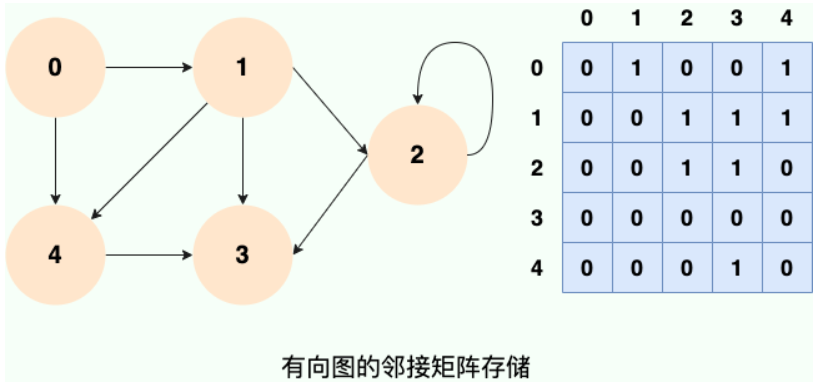
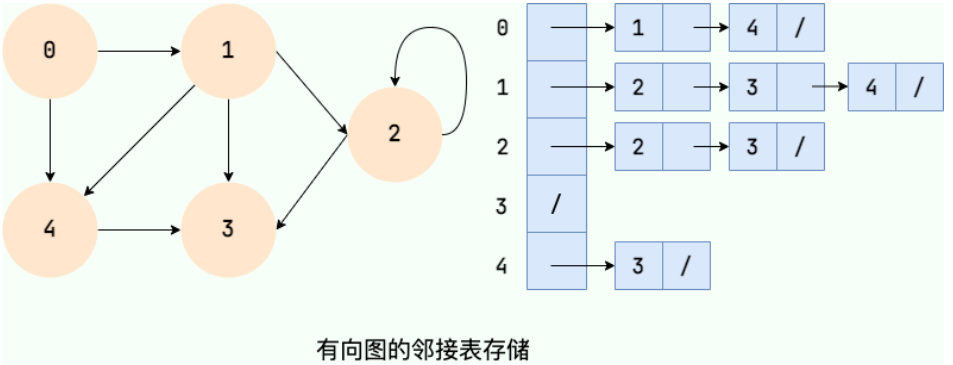
图的常见存储方式有:
邻接矩阵:用二维数组存储,数组的值表示顶点之间的边,可以快速判断边的存在,但浪费空间,适合顶点少、边多的稠密图。
邻接表:用数组存储顶点,每个顶点对应一个链表,链表存储相邻顶点,节省空间,但查找边较慢,适合顶点多、边少的稀疏图。
边列表:用列表存储所有边,每条边由两个顶点组成,简单直观,节省空间,但查找邻接顶点效率低,适合边较少的图。
邻接字典:用哈希表存储顶点,每个顶点对应一个子哈希表,存储邻接顶点及其权重,可以快速访问邻接顶点,支持动态扩展,但实现复杂,需要快速访问邻接顶点且支持动态扩展的图。
稀疏矩阵:用稀疏矩阵(如CSR或CSC)存储邻接矩阵,节省空间,但实现复杂,适合大规模稀疏图。
2. 图的搜索
深度优先搜索(DFS)
深度优先搜索(Depth-First Search,DFS)是一种用于遍历或搜索图或树的算法,它的核心思想是从起始节点出发,沿着图的分支一路深入,直到无法继续深入为止,然后回溯到最近的分支点,继续深入其他路径,直到所有节点都被访问。
一般使用使用栈(或递归)实现,适合于路径探索和回溯问题,如解决迷宫问题。
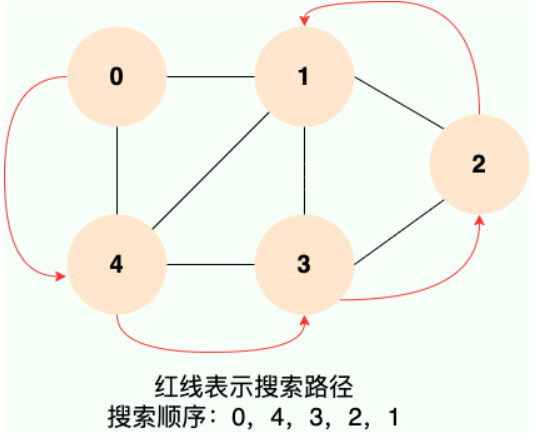
广度优先搜索(BFS)
广度优先搜索(Breadth-First Search,BFS)是一种用于遍历或搜索图或树的算法,它的核心思想是从起始节点开始,逐层向外扩散,先访问所有邻接节点,再依次访问这些邻接节点的邻接节点,直到所有节点都被访问。
一般使用队列实现,适合于最短路径和层级遍历,如计算图中两点之间的最短路径、社交网络分析、网络爬虫等。
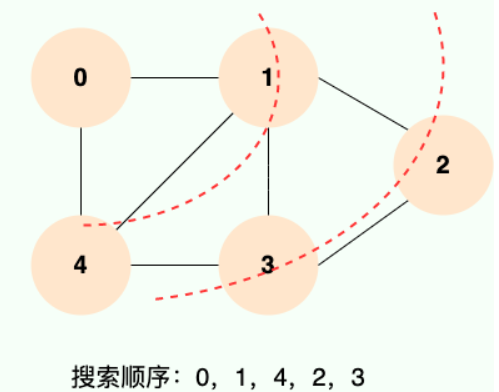
深度优先 vs 广度优先
DFS:从一个节点出发,沿着路径深入,直到无法继续,然后回溯。
BFS:从一个节点出发,逐层访问所有邻接节点。
第四节 其它结构
1. 布隆过滤器
什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种空间效率很高的概率型数据结构,主要是为了解决海量数据的存在性问题。
它的核心思想是通过多个哈希函数将元素映射到一个位数组中,可以判断某个数据大概率存在或一定不存在。
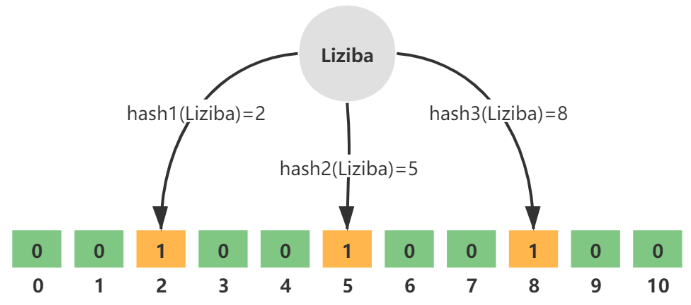
注意:
布隆过滤器中的元素一旦被插入,就无法单独删除(除非使用计数型布隆过滤器)。
实现一个布隆过滤器
761import java.util.BitSet;2
3public class MyBloomFilter {4
5 /**6 * 位数组的大小7 */8 private static final int DEFAULT_SIZE = 2 << 24;9 /**10 * 通过这个数组可以创建 6 个不同的哈希函数11 */12 private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};13
14 /**15 * 位数组。数组中的元素只能是 0 或者 116 */17 private BitSet bits = new BitSet(DEFAULT_SIZE);18
19 /**20 * 存放包含 hash 函数的类的数组21 */22 private SimpleHash[] func = new SimpleHash[SEEDS.length];23
24 /**25 * 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样26 */27 public MyBloomFilter() {28 // 初始化多个不同的 Hash 函数29 for (int i = 0; i < SEEDS.length; i++) {30 func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);31 }32 }33
34 /**35 * 添加元素到位数组36 */37 public void add(Object value) {38 for (SimpleHash f : func) {39 bits.set(f.hash(value), true);40 }41 }42
43 /**44 * 判断指定元素是否存在于位数组45 */46 public boolean contains(Object value) {47 boolean ret = true;48 for (SimpleHash f : func) {49 ret = ret && bits.get(f.hash(value));50 }51 return ret;52 }53
54 /**55 * 静态内部类。用于 hash 操作!56 */57 public static class SimpleHash {58
59 private int cap;60 private int seed;61
62 public SimpleHash(int cap, int seed) {63 this.cap = cap;64 this.seed = seed;65 }66
67 /**68 * 计算 hash 值69 */70 public int hash(Object value) {71 int h;72 return (value == null) ? 0 : Math.abs((cap - 1) & seed * ((h = value.hashCode()) ^ (h >>> 16)));73 }74
75 }76}
Guava包的布隆过滤器
首先我们需要在项目中引入 Guava 的依赖:
51<dependency>2 <groupId>com.google.guava</groupId>3 <artifactId>guava</artifactId>4 <version>28.0-jre</version>5</dependency>使用如下:
121// 创建布隆过滤器对象(最多存放1500个整数,误差为0.01)2BloomFilter<Integer> filter = BloomFilter.create(3 Funnels.integerFunnel(),4 1500,5 0.01);6
7// 将元素添加进布隆过滤器8filter.put(1);9
10// 判断指定元素是否存在11System.out.println(filter.mightContain(1));12System.out.println(filter.mightContain(2));
Redis的布隆过滤器
Redis v4.0 之后有了 Module(模块/插件) 功能,可以添加一个布隆过滤器模块,如:https://github.com/RedisBloom/RedisBloom。
2. 散列表
什么是散列表?
散列表(Hash Table)是一种通过散列函数将键映射到存储位置的数据结构,用于实现快速的插入、删除和查找操作。
如何解决散列表的冲突
链地址法:最常用的冲突解决方法之一,每个散列位置存储一个链表,所有映射到该位置的键值对都存储在链表中。
开放寻址法:将所有键值对存储在散列表的数组中,当发生冲突时,会寻找下一个空闲位置。
实现一个散列表
1121// 【散列表】实现关键点:2// 1. 定义一个存储桶数组,一般为List<LinkedList<Entry>>类型。3// 2. 定义一个散列函数,用于确定使用哪个桶存储。4// 3. 每个桶是一个链表,可以存储多个元素,以解决冲突问题。5import java.util.LinkedList;6import java.util.List;7
8public class HashTable {9 private static final int INITIAL_CAPACITY = 16; // 初始容量10 private List<LinkedList<Entry>> buckets; // 存储桶数组11
12 // 散列表的键值对条目13 private static class Entry {14 int key;15 String value;16
17 public Entry(int key, String value) {18 this.key = key;19 this.value = value;20 }21 }22
23 // 构造函数24 public HashTable() {25 this.buckets = new LinkedList<>();26 for (int i = 0; i < INITIAL_CAPACITY; i++) {27 buckets.add(new LinkedList<>());28 }29 }30
31 // 散列函数32 private int hash(int key) {33 return key % buckets.size();34 }35
36 // 插入键值对37 public void put(int key, String value) {38 int index = hash(key);39 LinkedList<Entry> bucket = buckets.get(index);40
41 // 检查是否已经存在该键42 for (Entry entry : bucket) {43 if (entry.key == key) {44 entry.value = value; // 更新值45 return;46 }47 }48
49 // 如果不存在,添加新的键值对50 bucket.add(new Entry(key, value));51 }52
53 // 获取键对应的值54 public String get(int key) {55 int index = hash(key);56 LinkedList<Entry> bucket = buckets.get(index);57
58 for (Entry entry : bucket) {59 if (entry.key == key) {60 return entry.value;61 }62 }63
64 return null; // 键不存在65 }66
67 // 删除键值对68 public void remove(int key) {69 int index = hash(key);70 LinkedList<Entry> bucket = buckets.get(index);71
72 for (Entry entry : bucket) {73 if (entry.key == key) {74 bucket.remove(entry);75 return;76 }77 }78 }79
80 // 遍历散列表81 public void printHashTable() {82 for (int i = 0; i < buckets.size(); i++) {83 LinkedList<Entry> bucket = buckets.get(i);84 System.out.print("Bucket " + i + ": ");85 for (Entry entry : bucket) {86 System.out.print("(" + entry.key + ", " + entry.value + ") ");87 }88 System.out.println();89 }90 }91
92 // 测试代码93 public static void main(String[] args) {94 HashTable hashTable = new HashTable();95
96 hashTable.put(10, "Value10");97 hashTable.put(20, "Value20");98 hashTable.put(30, "Value30");99 hashTable.put(40, "Value40");100 hashTable.put(15, "Value15");101
102 System.out.println("HashTable after insertions:");103 hashTable.printHashTable();104
105 System.out.println("Get value for key 20: " + hashTable.get(20));106 System.out.println("Get value for key 50: " + hashTable.get(50));107
108 hashTable.remove(20);109 System.out.println("HashTable after removing key 20:");110 hashTable.printHashTable();111 }112}
第03章_常见算法
第一节 基本算法思想
1. 贪心算法
什么是贪心算法?
贪心算法的本质是选择每一阶段的局部最优,从而达到全局最优。其一般步骤如下:
将问题分解为若干个子问题
找出适合的贪心策略
求解每一个子问题的最优解
将局部最优解堆叠成全局最优解
贪心算法的典型案例
买卖股票的最佳时机:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/
买卖股票的最佳时机 II:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-ii/
2. 动态规划
什么是动态规划?
动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的。
确定 dp 数组(dp table)以及下标的含义
确定递推公式
dp 数组如何初始化
确定遍历顺序
举例推导 dp 数
动态规划的典型案例
使用最小花费爬楼梯:https://leetcode.cn/problems/min-cost-climbing-stairs/
分割等和子集:https://leetcode.cn/problems/partition-equal-subset-sum/
最长回文子序列:https://leetcode.cn/problems/longest-palindromic-subsequence/
3. 回溯算法
什么是回溯算法?
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径,其本质就是穷举。
针对所给问题,定义问题的解空间,它至少包含问题的一个(最优)解。
确定易于搜索的解空间结构,使得能用回溯法方便地搜索整个解空间 。
以深度优先的方式搜索解空间,并且在搜索过程中用剪枝函数避免无效搜索。
回溯算法的典型案例
组合:https://leetcode.cn/problems/combinations/
39.组合总和:https://leetcode.cn/problems/combination-sum/
40.组合总和 II:https://leetcode.cn/problems/combination-sum-ii/
78.子集:https://leetcode.cn/problems/subsets/
90.子集 II:https://leetcode.cn/problems/subsets-ii/
51.N 皇后:https://leetcode.cn/problems/n-queens/
4. 分治算法
什么是分治算法?
分治算法指将一个规模为 N 的问题分解为 K 个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,就可得到原问题的解。
将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
将各个子问题的解合并为原问题的解。
分治算法的典型案例
将有序数组转换成二叉搜索数:https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/
合并 k 个升序链表:https://leetcode.cn/problems/merge-k-sorted-lists/
第二节 经典算法
1. 排序算法
交换排序-冒泡排序 (Bubble Sort)
冒泡排序的基本思路:通过N-1轮比较,每轮将1个最大(最小)的元素移至未排序序列末尾。
在冒泡过程中,每经过 1 轮,后续轮次的比较次数就会减 1 。
如果某一轮中,没有发生元素交换,则表示数组已经有序,可以跳过后续轮次。
只有元素逆序时才会交换位置,因此冒泡排序是稳定的。
时间复杂度最坏为
O(n^2),在数据初始有序的情况下为O(1),平均为O(n^2)。
视频讲解:https://www.bilibili.com/video/BV181421876R
201public static void bubbleSort(int[] arr) {2 int n = arr.length;3 boolean swapped;4 for (int i = 0; i < n - 1; i++) {5 swapped = false; // 用于标记是否发生了交换6 for (int j = 0; j < n - 1 - i; j++) {7 if (arr[j] > arr[j + 1]) {8 // 交换相邻两个元素9 int temp = arr[j];10 arr[j] = arr[j + 1];11 arr[j + 1] = temp;12 swapped = true; // 发生了交换13 }14 }15 // 如果在这一轮中没有发生交换,说明数组已经有序,可以提前结束排序16 if (!swapped) {17 break;18 }19 }20}
插入排序-插入排序 (Insertion Sort)
插入排序的基本思路:依次将第2-N个元素插入到前面有序的部分。
初始状态,只有元素0是有序的,需遍历第
2-N个元素,在已排序数组中进行插入。插入位置可以顺序查找,称作直接插入排序,也可通过二分查找,称为折半插入排序。
元素插入前,需要将该位置及之后的元素进行后移,以腾出位置进行插入。
插入排序也是稳定的,时间复杂度最坏为
O(n^2),在数据初始有序的情况下为O(1),平均为O(n^2)。
视频讲解:https://www.bilibili.com/video/BV1tf421Q7eh
451// 直接插入排序2public static void insertionSort(int[] arr) {3 int n = arr.length;4 for (int i = 1; i < n; i++) {5 // 当前要插入的元素6 int current = arr[i];7 // 从已排序部分的最后一个元素开始向前扫描8 int j = i - 1;9 // 将大于current的元素向后移动一位10 while (j >= 0 && arr[j] > current) {11 arr[j + 1] = arr[j];12 j--;13 }14 // 将current插入到正确的位置15 arr[j + 1] = current;16 }17}18
19// 折半插入排序20public static void binaryInsertionSort(int[] arr) {21 int n = arr.length;22 for (int i = 1; i < n; i++) {23 int temp = arr[i]; // 当前要插入的元素24 int left = 0;25 int right = i - 1;26
27 // 使用折半查找确定插入位置28 while (left <= right) {29 int mid = left + (right - left) / 2;30 if (temp < arr[mid]) {31 right = mid - 1;32 } else {33 left = mid + 1;34 }35 }36
37 // 将从插入位置到当前位置的元素向后移动一位38 for (int j = i - 1; j >= left; j--) {39 arr[j + 1] = arr[j];40 }41
42 // 插入当前元素43 arr[left] = temp;44 }45}
选择排序-选择排序 (Selection Sort)
简单选择排序的基本思路:每轮都在剩下的数里选最小的换到前面,每轮排好一个元素,总共n-1轮。
在第N轮时,对于第N-1个元素,可能会被后面更大(小)的元素调换位置,因此简单选择排序是不稳定的。
无论什么情况下,所需的比较次数都是固定的,因此最好和最差的时间复杂度都是
O(n^2)。
视频讲解:https://www.bilibili.com/video/BV1kjsuenE8v
181 public static void selectionSort(int[] arr) {2 int n = arr.length;3 for (int i = 0; i < n - 1; i++) { // 总共进行n-1轮4 int minIndex = i; // 假设当前轮次的最小值索引为i5 // 在未排序部分寻找最小值的索引6 for (int j = i + 1; j < n; j++) {7 if (arr[j] < arr[minIndex]) {8 minIndex = j;9 }10 }11 // 将找到的最小值与未排序部分的第一个元素交换12 if (minIndex != i) {13 int temp = arr[i];14 arr[i] = arr[minIndex];15 arr[minIndex] = temp;16 }17 }18}
交换排序-快速排序 (Quick Sort)
快速排序的基本思路:任取一元素作为枢轴,多次交换元素,使得左边元素都小于枢轴,右边元素都大于枢轴, 然后递归处理左右子数组,直到子数组元素为空或只剩1个。
枢轴可以选择下标为
0的元素,使用left指向数组左端,right指向数组右端,right 从右往左找比枢轴小的元素去填 left 的坑,left 从左往右找比枢轴大的元素去填 right 的坑,直到 left 和 right 相等。当每次枢轴都选到中值时,交换元素后,两边子数组长度基本等长,类似于折半查找,时间复杂度为
O(nlogn),空间复杂度为递归处理次数O(logn)。当每次都选到最大(最小)元素时,交换元素后,元素都在某一边子数组,时间复杂度为
O(n^2),空间复杂度为递归次数O(n)。
视频讲解:https://www.bilibili.com/video/BV1y4421Z7hK
361public class QuickSort {2 public static void quickSort(int[] arr, int left, int right) {3 if (left >= right) {4 return; // 递归结束条件:子数组为空或只剩1个元素5 }6 int pivot = arr[left]; // 选择下标为0的元素作为枢轴7 int i = left, j = right;8 while (i < j) {9 // right从右往左找比枢轴小的元素10 while (i < j && arr[j] >= pivot) {11 j--;12 }13 if (i < j) {14 arr[i] = arr[j]; // 填left的坑15 }16 // left从左往右找比枢轴大的元素17 while (i < j && arr[i] <= pivot) {18 i++;19 }20 if (i < j) {21 arr[j] = arr[i]; // 填right的坑22 }23 }24 arr[i] = pivot; // 枢轴元素归位25 quickSort(arr, left, i - 1); // 递归处理左子数组26 quickSort(arr, i + 1, right); // 递归处理右子数组27 }28
29 public static void main(String[] args) {30 int[] arr = {3, 5, 2, 6, 9, 1, 8, 7, 4};31 quickSort(arr, 0, arr.length - 1);32 for (int num : arr) {33 System.out.print(num + " ");34 }35 }36}
插入排序-希尔排序 (Shell Sort)
希尔排序(Shell Sort)是一种基于插入排序的改进算法,也叫做缩小增量排序,它通过将记录按不同的步长分组,对每组使用直接插入排序算法排序,随着步长逐渐缩小,整个序列向有序状态演进,最后步长为1时,整个序列变为有序。
增量大的时候,分组多,但组内元素少,效率较高。
随着增量越来越小,虽然组内元素越来越多,但是也越来越有序,效率也较高。
时间复杂度与增量序列有关,目前尚无明确定论,但一般认为是:
O(n) ~ O(n^) ~ O(n^2)。
视频讲解:https://www.bilibili.com/video/BV1bm42137UZ/
201public static void shellSort(int[] arr) {2 int n = arr.length;3 // 初始步长4 for (int gap = n / 2; gap > 0; gap /= 2) {5 // 对每个步长进行插入排序6 for (int i = gap; i < n; i++) {7 // 当前要插入的元素8 int temp = arr[i];9 // 从已排序部分的最后一个元素开始向前扫描10 int j = i;11 // 将大于temp的元素向后移动一位12 while (j >= gap && arr[j - gap] > temp) {13 arr[j] = arr[j - gap];14 j -= gap;15 }16 // 将temp插入到正确的位置17 arr[j] = temp;18 }19 }20}
选择排序-堆排序 (Heap Sort)
堆排序(Heap Sort)是一种基于二叉堆的比较排序算法。它利用了堆这种数据结构的特性,通过构建最大堆(最小堆)来实现排序。
建堆:从最后一个非叶结点开始依次向下调整,使其及其子树满足堆的特性。
排序:将堆顶换到最后,再向下调整新的堆顶,重复N-1轮。
由于每轮都要将堆顶元素置换末尾元素,因此堆排序是不稳定的,且时间复杂度始终为
O(nlogn),但空间复杂度只有O(1)。
视频讲解:https://www.bilibili.com/video/BV1HYtseiEQ8
611public class HeapSort {2 public static void main(String[] args) {3 int[] arr = {4, 10, 3, 5, 1};4 heapSort(arr);5 for (int num : arr) {6 System.out.print(num + " ");7 }8 }9
10 // 堆排11 public static void heapSort(int[] arr) {12 // 构建最大堆13 buildMaxHeap(arr);14
15 // 进行n-1轮排序16 for (int i = arr.length - 1; i > 0; i--) {17 // 将堆顶元素与最后一个元素交换18 swap(arr, 0, i);19 // 调整新的堆顶20 heapify(arr, 0, i);21 }22 }23
24 // 构建最大堆25 private static void buildMaxHeap(int[] arr) {26 // 从最后一个非叶结点开始向下调整27 for (int i = arr.length / 2 - 1; i >= 0; i--) {28 heapify(arr, i, arr.length);29 }30 }31
32 // 调整堆33 private static void heapify(int[] arr, int i, int heapSize) {34 int largest = i; // 当前节点35 int left = 2 * i + 1; // 左子节点36 int right = 2 * i + 2; // 右子节点37
38 // 如果左子节点大于当前节点39 if (left < heapSize && arr[left] > arr[largest]) {40 largest = left;41 }42
43 // 如果右子节点大于当前最大值44 if (right < heapSize && arr[right] > arr[largest]) {45 largest = right;46 }47
48 // 如果最大值不是当前节点,交换并递归调整49 if (largest != i) {50 swap(arr, i, largest);51 heapify(arr, largest, heapSize);52 }53 }54
55 // 交换数组中的两个元素56 private static void swap(int[] arr, int i, int j) {57 int temp = arr[i];58 arr[i] = arr[j];59 arr[j] = temp;60 }61}
归并排序-归并排序 (Merge Sort)
归并排序是一种分治算法,它将数组分成两半,通过递归分别对这两半进行排序,然后将排序后的两半合并成一个有序数组。
需要排序的轮次为
O(logn),时间复杂度始终为O(nlogn),空间复杂度为O(1)。
视频讲解:https://www.bilibili.com/video/BV1em1oYTEFf
531public class MergeSort {2 public static void main(String[] args) {3 int[] arr = {38, 27, 43, 3, 9, 82, 10};4 mergeSort(arr, 0, arr.length - 1);5 for (int num : arr) {6 System.out.print(num + " ");7 }8 }9
10 // 归并排序主函数11 public static void mergeSort(int[] arr, int left, int right) {12 if (left < right) {13 // 找到中间位置14 int mid = left + (right - left) / 2;15
16 // 递归地对左右两半进行排序17 mergeSort(arr, left, mid);18 mergeSort(arr, mid + 1, right);19
20 // 合并两个有序的子数组21 merge(arr, left, mid, right);22 }23 }24
25 // 合并两个有序子数组26 private static void merge(int[] arr, int left, int mid, int right) {27 // 创建临时数组存储左右两半28 int[] leftArray = new int[mid - left + 1];29 int[] rightArray = new int[right - mid];30
31 // 复制数据到临时数组32 System.arraycopy(arr, left, leftArray, 0, mid - left + 1);33 System.arraycopy(arr, mid + 1, rightArray, 0, right - mid);34
35 // 合并临时数组36 int i = 0, j = 0, k = left;37 while (i < leftArray.length && j < rightArray.length) {38 if (leftArray[i] <= rightArray[j]) {39 arr[k++] = leftArray[i++];40 } else {41 arr[k++] = rightArray[j++];42 }43 }44
45 // 复制剩余的元素46 while (i < leftArray.length) {47 arr[k++] = leftArray[i++];48 }49 while (j < rightArray.length) {50 arr[k++] = rightArray[j++];51 }52 }53}
非比较排序-计数排序 (Counting Sort)
计数排序(Counting Sort)是一种非比较型的排序算法,适用于一定范围内的整数排序。
在数组索引对应位置统计该整数出现的次数,然后根据这些统计信息来输出有序的整数序列。
时间复杂度为
O(n+s),空间复杂度为O(s),其中 n 指元素个数, s 指最大值和最小值的跨度。
视频讲解:https://www.bilibili.com/video/BV1sU4y1R7pm
431public static void countingSort(int[] arr) {2 if (arr == null || arr.length == 0) {3 return;4 }5
6 // 找到数组中的最大值和最小值7 int max = arr[0];8 int min = arr[0];9 for (int num : arr) {10 if (num > max) {11 max = num;12 }13 if (num < min) {14 min = num;15 }16 }17
18 // 创建计数数组19 int range = max - min + 1;20 int[] countArray = new int[range];21
22 // 统计每个元素出现的次数23 for (int num : arr) {24 countArray[num - min]++;25 }26
27 // 累加计数数组,使其包含每个元素的最终位置28 for (int i = 1; i < range; i++) {29 countArray[i] += countArray[i - 1];30 }31
32 // 创建输出数组33 int[] output = new int[arr.length];34
35 // 根据计数数组将元素放入输出数组36 for (int i = arr.length - 1; i >= 0; i--) {37 output[countArray[arr[i] - min] - 1] = arr[i];38 countArray[arr[i] - min]--;39 }40
41 // 将输出数组复制回原数组42 System.arraycopy(output, 0, arr, 0, arr.length);43}
非比较排序-桶排序 (Bucket Sort)
桶排序(Bucket Sort)是一种基于分而治之思想的排序算法,它将数组分到有限数量的桶里,每个桶再分别排序(通常使用其他排序算法或递归使用桶排序),适用于输入数据服从均匀分布的情况。
时间复杂度为
O(n+k),空间复杂度为O(k),其中 n 指元素个数,k 指桶的个数。
视频讲解:https://www.bilibili.com/video/BV1QT411u7MA
451public static void bucketSort(float[] arr) {2 if (arr == null || arr.length <= 1) {3 return;4 }5
6 // 找到数组中的最大值和最小值7 float max = arr[0];8 float min = arr[0];9 for (float num : arr) {10 if (num > max) {11 max = num;12 }13 if (num < min) {14 min = num;15 }16 }17
18 // 计算桶的数量和每个桶的范围19 int bucketCount = arr.length;20 float bucketRange = (max - min) / bucketCount;21
22 // 创建桶23 List<List<Float>> buckets = new ArrayList<>();24 for (int i = 0; i < bucketCount; i++) {25 buckets.add(new ArrayList<>());26 }27
28 // 将元素分配到各个桶中29 for (float num : arr) {30 int bucketIndex = (int)((num - min) / bucketRange);31 if (bucketIndex == bucketCount) { // 处理最大值的情况32 bucketIndex--;33 }34 buckets.get(bucketIndex).add(num);35 }36
37 // 对每个桶进行排序38 int index = 0;39 for (List<Float> bucket : buckets) {40 Collections.sort(bucket); // 使用内置排序算法对每个桶排序41 for (float num : bucket) {42 arr[index++] = num;43 }44 }45}
非比较排序-基数排序 (Radix Sort)
基数排序(Radix Sort)是一种非比较型的排序算法,它通过按位排序的方式对整数进行排序。
基数排序有两种实现方式:最低位优先(LSD,Least Significant Digit)和最高位优先(MSD,Most Significant Digit),一般使用前者。
分配:按个位的数值依次将每个数放到
0~9号桶中,桶使用链式队列存储各个元素。收集:再依次将每个桶里的元素拿出来,此时元素按个位有序。
重复:切换十位、百位、千位等重复上述操作,最终得到一个有序的整数序列。
时间复杂度始终为:
O(d*(n+k)),空间复杂度为:O(k),其中 d 指最大数的位数,n 指元素个数,k 指桶的个数,一般为10。
视频讲解:https://www.bilibili.com/video/BV1KrzrYeEDw
511import java.util.LinkedList;2import java.util.Queue;3
4public class RadixSort {5 public static void main(String[] args) {6 int[] arr = {170, 45, 75, 90, 802, 24, 2, 66};7 radixSort(arr);8 for (int num : arr) {9 System.out.print(num + " ");10 }11 }12
13 public static void radixSort(int[] arr) {14 // 找到最大值,确定最大位数15 int max = arr[0];16 for (int num : arr) {17 if (num > max) {18 max = num;19 }20 }21 int maxDigits = String.valueOf(max).length();22
23 // 每一位进行排序24 for (int digit = 0; digit < maxDigits; digit++) {25 // 使用10个队列作为桶26 Queue<Integer>[] buckets = new LinkedList[10];27 for (int i = 0; i < 10; i++) {28 buckets[i] = new LinkedList<>();29 }30
31 // 将数字放入对应的桶32 for (int num : arr) {33 int digitValue = getDigit(num, digit);34 buckets[digitValue].add(num);35 }36
37 // 将桶中的数字依次取出,放回原数组38 int index = 0;39 for (Queue<Integer> bucket : buckets) {40 while (!bucket.isEmpty()) {41 arr[index++] = bucket.poll();42 }43 }44 }45 }46
47 // 获取数字在指定位置的值48 private static int getDigit(int num, int digit) {49 return (num / (int) Math.pow(10, digit)) % 10;50 }51}
排序算法总结
| 排序算法 | 最好时间 | 最坏时间 | 平均时间 | 空间 | 排序方式 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 内部排序 | 稳定 | 基本有序的小规模数据 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 内部排序 | 稳定 | 基本有序的小规模数据 |
| 选择排序 | O(n^2) | ~ | ~ | O(1) | 内部排序 | 不稳定 | 对交换操作敏感的小规模数据 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | 内部排序 | 不稳定 | 数据随机性较好的大规模数据 |
| 希尔排序 | O(n) | O(n^2) | O(n^1.3) | O(1) | 内部排序 | 不稳定 | 基本有序的中规模数据 |
| 堆排序 | O(nlogn) | ~ | ~ | O(1) | 内部排序 | 不稳定 | 需要快速选择最大(或最小)元素的场景 |
| 归并排序 | O(nlogn) | ~ | ~ | O(n) | 外部排序 | 稳定 | 超大规模数据的稳定排序 |
| 计数排序 | O(n+s) | ~ | ~ | O(s) | 外部排序 | 稳定 | 范围跨度小的整数 |
| 桶排序 | O(n+k) | ~ | ~ | O(n+k) | 外部排序 | 稳定 | 分布均匀的数据 |
| 基数排序 | O(d(n+r)) | ~ | ~ | O(n+k) | 外部排序 | 稳定 | 位数较少、分布均匀的整数 |
注意:
内部排序:指通过内存完成排序。外部排序:一般是对大规模数据在磁盘排序。
稳定:如果 A 原本在 B 前面,而 A = B,排序之后 A 仍然在 B 的前面。
时间复杂度:定性描述一个算法执行所耗费的时间。空间复杂度:定性描述一个算法执行所需内存的大小。
比较类排序:通过比较来决定元素间的顺序,其时间复杂度不能突破
O(nlogn)。
2. 查找算法
顺序查找(线性查找)
顺序查找是一种简单的查找算法,适用于无序数组或链表。
它从数组或链表的起始位置开始,逐个比较每个元素,直到找到目标元素或遍历完所有元素。
81public static int linearSearch(int[] arr, int target) {2 for (int i = 0; i < arr.length; i++) {3 if (arr[i] == target) {4 return i; // 返回目标元素的索引5 }6 }7 return -1; // 如果未找到目标元素,返回-18}
二分查找(折半查找)
二分查找是一种高效的查找算法,适用于有序数组。
它通过不断将数组分成两半,逐步缩小查找范围,直到找到目标元素或查找范围为空。
171public static int binarySearch(int[] arr, int target) {2 int low = 0;3 int high = arr.length - 1;4
5 while (low <= high) {6 int mid = low + (high - low) / 2;7
8 if (arr[mid] == target) {9 return mid; // 返回目标元素的索引10 } else if (arr[mid] < target) {11 low = mid + 1; // 目标在右半部分12 } else {13 high = mid - 1; // 目标在左半部分14 }15 }16 return -1; // 如果未找到目标元素,返回-117}
插值查找
插值查找是一种改进的二分查找算法,适用于数据分布较为均匀的有序数组。
它通过估计目标元素的位置,而不是简单地取中间位置,从而可能更快地找到目标元素。
251public static int interpolationSearch(int[] arr, int target) {2 int low = 0;3 int high = arr.length - 1;4
5 while (low <= high && target >= arr[low] && target <= arr[high]) {6 if (low == high) {7 if (arr[low] == target) {8 return low;9 }10 return -1;11 }12
13 // 估计目标元素的位置14 int pos = low + ((high - low) / (arr[high] - arr[low]) * (target - arr[low]));15
16 if (arr[pos] == target) {17 return pos; // 返回目标元素的索引18 } else if (arr[pos] < target) {19 low = pos + 1; // 目标在右半部分20 } else {21 high = pos - 1; // 目标在左半部分22 }23 }24 return -1; // 如果未找到目标元素,返回-125}
跳跃查找
跳跃查找是一种适用于有序数组的查找算法。
它通过跳跃式地前进,逐步缩小查找范围,然后在范围内进行线性查找。
221public static int jumpSearch(int[] arr, int target) {2 int n = arr.length;3 int step = (int) Math.sqrt(n); // 跳跃步长4 int prev = 0;5
6 // 找到目标元素所在的块7 while (prev < n && arr[Math.min(step, n) - 1] < target) {8 prev = step;9 step += (int) Math.sqrt(n);10 if (prev >= n) {11 return -1; // 如果超出数组范围,返回-112 }13 }14
15 // 在块内进行线性查找16 for (int i = prev; i < Math.min(step, n); i++) {17 if (arr[i] == target) {18 return i; // 返回目标元素的索引19 }20 }21 return -1; // 如果未找到目标元素,返回-122}
哈希表查找
哈希表查找是一种基于哈希表的数据结构,适用于快速查找。它通过哈希函数将键映射到哈希表中的位置,从而实现快速查找。
151public static void main(String[] args) {2 Map<Integer, String> hashTable = new HashMap<>();3 hashTable.put(10, "Ten");4 hashTable.put(20, "Twenty");5 hashTable.put(30, "Thirty");6 hashTable.put(40, "Forty");7 hashTable.put(50, "Fifty");8
9 int target = 30;10 if (hashTable.containsKey(target)) {11 System.out.println("元素 " + target + " 在哈希表中,值为:" + hashTable.get(target));12 } else {13 System.out.println("哈希表中未找到元素 " + target);14 }15}
深度优先搜索(DFS)
从图的某个起始顶点开始,沿着一条路径尽可能深入地访问图中的所有顶点,直到不能继续为止,然后返回并探索其他路径。
时间复杂度为O(V+E),空间复杂度为O(V),其中V是顶点数,E是边数。
311import java.util.*;2
3public class DFS {4 private static void dfsUtil(int v, boolean[] visited, Map<Integer, List<Integer>> graph) {5 visited[v] = true;6 System.out.print(v + " ");7
8 List<Integer> neighbors = graph.getOrDefault(v, Collections.emptyList());9 for (int neighbor : neighbors) {10 if (!visited[neighbor]) {11 dfsUtil(neighbor, visited, graph);12 }13 }14 }15
16 public static void dfs(int start, Map<Integer, List<Integer>> graph) {17 boolean[] visited = new boolean[graph.size()];18 dfsUtil(start, visited, graph);19 }20
21 public static void main(String[] args) {22 Map<Integer, List<Integer>> graph = new HashMap<>();23 graph.put(0, Arrays.asList(1, 2));24 graph.put(1, Arrays.asList(2));25 graph.put(2, Arrays.asList(0, 3));26 graph.put(3, Arrays.asList(3));27
28 System.out.println("深度优先搜索结果:");29 dfs(2, graph);30 }31}
广度优先搜索(BFS)
从图的某个起始顶点开始,先依次访问这个顶点的所有邻居顶点,然后再按照距离逐层遍历图中的所有顶点。
时间复杂度和空间复杂度均为O(V+E)。
351import java.util.*;2
3public class BFS {4 public static void bfs(int start, Map<Integer, List<Integer>> graph) {5 boolean[] visited = new boolean[graph.size()];6 Queue<Integer> queue = new LinkedList<>();7
8 visited[start] = true;9 queue.add(start);10
11 while (!queue.isEmpty()) {12 int v = queue.poll();13 System.out.print(v + " ");14
15 List<Integer> neighbors = graph.getOrDefault(v, Collections.emptyList());16 for (int neighbor : neighbors) {17 if (!visited[neighbor]) {18 visited[neighbor] = true;19 queue.add(neighbor);20 }21 }22 }23 }24
25 public static void main(String[] args) {26 Map<Integer, List<Integer>> graph = new HashMap<>();27 graph.put(0, Arrays.asList(1, 2));28 graph.put(1, Arrays.asList(2));29 graph.put(2, Arrays.asList(0, 3));30 graph.put(3, Arrays.asList(3));31
32 System.out.println("广度优先搜索结果:");33 bfs(2, graph);34 }35}
A*算法
结合了Dijkstra算法的广度优先搜索和贪婪最佳优先搜索的优点,通过估计从当前节点到目标节点的成本来指导搜索方向,从而在较短时间内找到最优解。时间复杂度和空间复杂度取决于启发函数和搜索树的大小。
821import java.util.*;2
3class Node implements Comparable<Node> {4 int id;5 int cost; // 从起点到当前节点的实际成本6 int heuristic; // 启发式估计值7 int totalCost; // 总成本 = cost + heuristic8
9 public Node(int id, int cost, int heuristic) {10 this.id = id;11 this.cost = cost;12 this.heuristic = heuristic;13 this.totalCost = cost + heuristic;14 }15
16 17 public int compareTo(Node other) {18 return Integer.compare(this.totalCost, other.totalCost);19 }20}21
22public class AStar {23 public static void aStar(int start, int goal, Map<Integer, List<Node>> graph) {24 PriorityQueue<Node> openList = new PriorityQueue<>();25 openList.add(new Node(start, 0, heuristic(start, goal)));26
27 Map<Integer, Integer> cameFrom = new HashMap<>();28 Map<Integer, Integer> costSoFar = new HashMap<>();29 costSoFar.put(start, 0);30
31 while (!openList.isEmpty()) {32 Node current = openList.poll();33
34 if (current.id == goal) {35 System.out.println("找到目标节点:" + goal);36 reconstructPath(cameFrom, start, goal);37 return;38 }39
40 List<Node> neighbors = graph.getOrDefault(current.id, Collections.emptyList());41 for (Node neighbor : neighbors) {42 int newCost = costSoFar.get(current.id) + neighbor.cost;43 if (!costSoFar.containsKey(neighbor.id) || newCost < costSoFar.get(neighbor.id)) {44 costSoFar.put(neighbor.id, newCost);45 neighbor.heuristic = heuristic(neighbor.id, goal);46 neighbor.totalCost = newCost + neighbor.heuristic;47 openList.add(neighbor);48 cameFrom.put(neighbor.id, current.id);49 }50 }51 }52
53 System.out.println("未找到目标节点:" + goal);54 }55
56 private static int heuristic(int a, int b) {57 // 简单的启发式函数,这里假设节点编号越接近,距离越短58 return Math.abs(a - b);59 }60
61 private static void reconstructPath(Map<Integer, Integer> cameFrom, int start, int goal) {62 List<Integer> path = new ArrayList<>();63 for (int at = goal; at != start; at = cameFrom.get(at)) {64 path.add(at);65 }66 path.add(start);67 Collections.reverse(path);68
69 System.out.println("路径:" + path);70 }71
72 public static void main(String[] args) {73 Map<Integer, List<Node>> graph = new HashMap<>();74 graph.put(0, Arrays.asList(new Node(1, 1, 0), new Node(2, 4, 0)));75 graph.put(1, Arrays.asList(new Node(2, 1, 0), new Node(3, 5, 0)));76 graph.put(2, Arrays.asList(new Node(3, 1, 0)));77 graph.put(3, Collections.emptyList());78
79 System.out.println("A*算法搜索结果:");80 aStar(0, 3, graph);81 }82}
3. 字符串算法
KMP算法(Knuth-Morris-Pratt)
KMP算法是一种高效的字符串匹配算法,用于在一个主字符串中查找一个子字符串的首次出现位置。
它通过预处理子字符串,避免了暴力匹配中的重复比较。
541public class KMP {2 public static int[] computeLPSArray(String pattern) {3 int[] lps = new int[pattern.length()];4 int len = 0;5 int i = 1;6
7 while (i < pattern.length()) {8 if (pattern.charAt(i) == pattern.charAt(len)) {9 len++;10 lps[i] = len;11 i++;12 } else {13 if (len != 0) {14 len = lps[len - 1];15 } else {16 lps[i] = 0;17 i++;18 }19 }20 }21 return lps;22 }23
24 public static int kmpSearch(String text, String pattern) {25 int[] lps = computeLPSArray(pattern);26 int i = 0; // index for text27 int j = 0; // index for pattern28
29 while (i < text.length()) {30 if (pattern.charAt(j) == text.charAt(i)) {31 i++;32 j++;33 }34
35 if (j == pattern.length()) {36 return i - j; // match found37 } else if (i < text.length() && pattern.charAt(j) != text.charAt(i)) {38 if (j != 0) {39 j = lps[j - 1];40 } else {41 i++;42 }43 }44 }45 return -1; // no match found46 }47
48 public static void main(String[] args) {49 String text = "ABABDABACDABABCABAB";50 String pattern = "ABABCABAB";51 int result = kmpSearch(text, pattern);52 System.out.println("Pattern found at index: " + result);53 }54}
第三节 分布式算法
1. 分布式理论基础
CAP理论
CAP 理论是分布式系统领域的一个重要理论,它用于描述一致性、可用性和分区容错性三者之间的权衡关系。
一致性(Consistency):在分布式系统中,所有节点在任何时刻看到的数据都是相同的。
可用性(Availability):在部分节点出现故障的情况下,系统仍然能够为用户提供可靠服务。
分区容错性(Partition tolerance):当出现网络分区故障(即网络中的部分节点之间无法通信)时,系统仍然能够正常运行。
CAP理论指出,分布式系统在一致性(C)、可用性(A)和分区容错性(P)这三者之间最多只能同时满足两个。
注意:
ZooKeeper保证的是一致性(CP),在Leader选举时整个集群不可用,在极端环境下可能会丢弃一些请求,需要用户重新请求。
Eruka保证的是可用性,部分节点数据可能出现短暂不一致;Nacos 两者都支持,可以通过配置进行选择。
BASE理论
BASE 理论是对 CAP 理论 的延伸和补充,它强调通过适当放宽对一致性的要求,来换取系统的可用性和分区容错性。
基本可用(Basically Available):系统在出现故障时,仍然能够提供服务,只是服务的性能可能下降或功能受限。
软状态(Soft State):系统中的数据可以存在中间状态,即数据在不同时间点可能不一致,但最终会趋于一致。
最终一致性(Eventually Consistent):系统经过一定时间后,所有节点的数据最终会达到一致状态。
2. 分布式一致性算法
两阶段提交(2PC)
阶段一(准备阶段):协调者向所有参与者发送“prepare”请求,参与者执行事务操作并将结果暂存,同时返回是否准备就绪。
阶段二(提交阶段):如果所有参与者均返回“yes”,协调者发送“commit”命令;否则,发送“rollback”命令,所有参与者回滚事务。
优点:实现简单、直观。
缺点:存在同步阻塞问题,协调者或参与者故障可能导致事务长时间处于不确定状态。
三阶段提交(3PC)
CanCommit阶段:协调者询问参与者是否可以提交事务。
PreCommit阶段:协调者通知各参与者预提交,参与者将操作结果写入日志,但还未真正提交。
DoCommit阶段:在确认所有参与者已进入预提交状态后,协调者下达提交命令,参与者正式提交。
优点:设计上引入了非阻塞特性,可以降低由于单点故障导致的长时间等待。
缺点:协议更加复杂,状态转换和超时管理要求更高。
TCC模式(Try-Confirm-Cancel)
TCC模式将事务划分为三个阶段:Try(尝试预留资源)、Confirm(确认并提交)、Cancel(取消预留资源)。在Try阶段提前锁定资源,确保后续的 Confirm 阶段可以成功执行,若失败则执行Cancel。
优点:非阻塞,适合长时间运行的业务场景。
缺点:业务场景要求设计较为谨慎,确保事务拆分合理
Saga模式
Saga模式将一个全局事务拆分成多个独立的本地事务,每个本地事务成功后都会触发下一步操作。如果某个步骤失败,则通过执行补偿操作来撤销之前已执行的本地事务。
优点:非阻塞,适合长时间运行的业务场景。
缺点:补偿逻辑较为复杂,需要保证补偿操作能够完全抵消之前的操作。
Paxos算法
Paxos算法是一种基于共识的分布式一致性算法,用于解决分布式系统中多个节点之间如何达成最终一致的问题。
涉及的角色如下:
Proposer(提议者):发起提案的节点,负责提出一个值(如某个操作或数据)。
Acceptor(接受者):对提案进行投票的节点,负责接受或拒绝提议。
Learner(学习者):最终学习到最终一致值的节点,负责实际执行操作或存储数据。
主要步骤如下:
准备阶段:提议者选择一个提案编号,向所有接受者发送Prepare请求,接受者响应Prepare请求,并告知提议者它已接受的最高提案编号及其值(如果有的话)。
接受阶段:提议者根据接受者的响应选择一个值,向所有接受者发送Accept请求,接受者如果收到的Accept请求的提案编号大于或等于它之前响应的Prepare请求的提案编号,则接受该提案。
学习阶段:当一个提案被多数接受者接受后,该提案被选中,所有学习者最终学习到这个值并执行相应操作。
注意:
在网络复杂的情况下,Paxos算法可能很久都无法收敛,甚至陷入活锁,因此一般会选择一个 Leader 负责进行提案。
ZAB算法
ZAB(Zookeeper Atomic Broadcast)算法是Zookeeper中使用的一种基于共识的一致性协议,用于解决分布式系统中的数据一致性问题。
主要角色如下:
Leader(领导者):负责协调和管理事务的提交。
Follower(跟随者):跟随Leader的指令,参与投票和事务的提交。
Observer(观察者):不参与投票,但可以接收广播的消息,用于扩展系统的读取能力。
主要步骤如下:
选举阶段(Leader Election):当Zookeeper集群启动或Leader节点故障时,会触发Leader选举,通过投票机制选出一个新的Leader。
广播阶段(Atomic Broadcast):Leader接收客户端的事务请求,将其封装成提案并广播给所有Follower节点。Follower节点处理提案并返回确认,Leader在收到足够多的确认后提交事务,并通知所有Follower节点提交事务。
注意:
ZAB 算法能在部分节点故障的情况下保证事务的原子性和顺序性,但 Leader 故障时,会影响系统的可用性。
Raft算法
Raft 算法是一种用于分布式系统中实现一致性(Consensus)的算法,它主要用于解决分布式系统中的数据复制和故障恢复问题。
Gossip协议
Gossip协议是一种基于Epidemic算法的去中心化的一致性协议,主要用于最终一致性模型,常见于分布式数据库和分布式缓存系统。
第04章_设计模式
第一节 设计模式概述
1. 设计模式是什么?
设计模式是软件开发中的最佳实践,帮助开发者在面对复杂设计问题时提供有效的解决方案。
2. 面向对象设计原则
面向对象设计原则为支持可维护性复用而诞生,这些原则蕴含在很多设计模式中,它们是从许多设计方案中总结出的指导性原则。
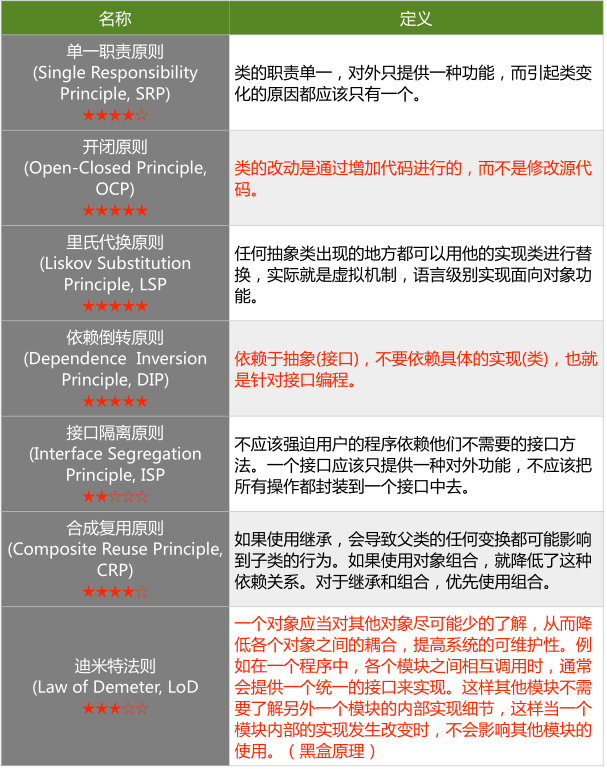
注意:
面向对象设计原则英文首字母组合为一个单词“Soild”(两个L折叠为1个),表示稳定的。
单一职责原则注重类的职责是否单一,而接口隔离原则更注重对接口的依赖是否隔离。
3. 设计模式的分类
1) 创建型模式

2) 结构型模式

3) 行为型模式

第二节 创建型模式(Creational Patterns)
创建型模式关注于对象的创建,提供了更灵活的对象创建方式。
1. 单例模式(Singleton Pattern)
单例模式指一个类只有一个实例,并提供一个全局访问点。下面是 Java 中的一些实现方式:
1) 饿汉式(静态常量)【可用】
优点:这种写法比较简单,就是在类装载的时候就完成实例化,避免了线程同步问题。
缺点:在类装载的时候就完成实例化,没有达到 Lazy Loading 的效果。如果从始至终从未使用过这个实例,则会造成内存的浪费。
141public class Singleton {2 3 // 在类加载时就创建实例4 private static final Singleton instance = new Singleton();5
6 // 私有构造函数,防止外部实例化7 private Singleton() {}8
9 // 提供全局访问点10 public static Singleton getInstance() {11 return instance;12 }13}14
2) 饿汉式(静态代码块)【可用】
这种方式和上面的方式类似,只不过将类实例化的过程放在了静态代码块中,也是在类装载的时候执行静态代码块中的代码,初始化类的实例。优缺点和上面一样。
181public class Singleton {2 // 在类加载时创建实例3 private static final Singleton instance;4
5 // 静态代码块,在类加载时执行6 static {7 instance = new Singleton();8 }9
10 // 私有构造函数,防止外部实例化11 private Singleton() {}12
13 // 提供全局访问点14 public static Singleton getInstance() {15 return instance;16 }17}18
3) 懒汉式(线程不安全)【不可用】
这种写法起到了 Lazy Loading 的效果,但是只能在单线程下使用。如果在多线程下,一个线程进入了 if (instance == null) 判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。所以在多线程环境下不可使用这种方式。
161public class Singleton {2 // 类加载时不创建实例3 private static Singleton instance;4
5 // 私有构造函数,防止外部实例化6 private Singleton() {}7
8 // 提供全局访问点9 public static Singleton getInstance() {10 if (instance == null) {11 instance = new Singleton();12 }13 return instance;14 }15}16
4) 懒汉式(线程安全,同步方法)【不推荐用】
解决上面线程不安全问题的方式是对 getInstance() 方法进行同步。但这种方式效率太低,每个线程在想获得类的实例时,执行getInstance() 方法都要进行同步。其实这个方法只需执行一次实例化代码,后面直接 return 实例化对象即可。
161public class Singleton {2 // 类加载时不创建实例3 private static Singleton instance;4
5 // 私有构造函数,防止外部实例化6 private Singleton() {}7
8 // 提供全局访问点,使用同步方法保证线程安全9 public static synchronized Singleton getInstance() {10 if (instance == null) {11 instance = new Singleton();12 }13 return instance;14 }15}16
5) 双检锁(线程安全,同步代码块)【不可用】
这种方式尝试使用同步代码块来提高效率,但仍无法保证线程安全。如果一个线程进入了 if (instance == null) 判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。
201public class Singleton {2 // 类加载时不创建实例3 private static Singleton instance;4
5 // 私有构造函数,防止外部实例化6 private Singleton() {}7
8 // 提供全局访问点,尝试使用同步代码块9 public static Singleton getInstance() {10 if (instance == null) {11 synchronized (Singleton.class) {12 if (instance == null) {13 instance = new Singleton();14 }15 }16 }17 return instance;18 }19}20
6) 双检锁+volatile【推荐使用】
Double-Check 概念对于多线程开发者来说不会陌生,进行了两次 if (instance == null) 检查,这样就可以保证线程安全。实例化代码只需执行一次,后面再次访问时,判断 if (instance == null),直接 return 实例化对象。
优点:线程安全;延迟加载;效率较高。
211public class Singleton {2 3 // 类加载时不创建实例4 private static volatile Singleton instance; // 【注意】和上面的区别是加了 volatile 关键字5
6 // 私有构造函数,防止外部实例化7 private Singleton() {}8
9 // 提供全局访问点,使用双重检查锁定机制保证线程安全10 public static Singleton getInstance() {11 if (instance == null) {12 synchronized (Singleton.class) {13 if (instance == null) {14 instance = new Singleton();15 }16 }17 }18 return instance;19 }20}21
7) 静态内部类【推荐使用】
这种方式与饿汉式方式类似,都是采用类装载机制来保证实例化时只有一个线程。但不同的是,饿汉式在类装载时就实例化,没有 Lazy-Loading 效果,而静态内部类方式在需要实例化时才装载静态内部类,从而实例化 Singleton。类的静态属性只会在第一次加载类时初始化,所以这里JVM帮助保证了线程的安全性。
优点:避免了线程不安全,延迟加载,效率高。
151public class Singleton {2 // 私有构造函数,防止外部实例化3 private Singleton() {}4
5 // 静态内部类,负责持有单例实例6 private static class SingletonHolder {7 private static final Singleton INSTANCE = new Singleton();8 }9
10 // 提供全局访问点,通过静态内部类实现延迟加载和线程安全11 public static Singleton getInstance() {12 return SingletonHolder.INSTANCE;13 }14}15
8) 单元素枚举【推荐使用】
创建枚举默认就是线程安全的,不需要担心 double checked locking,并且还能防止反序列化导致重新创建新的对象。枚举让JVM保证线程安全和单一实例问题,是 JDK1.5 版本后最适合用于创建单例设计模式的方法,是唯一一种不会被反射破坏单例状态的模式。
231// 使用枚举实现单例模式2public enum Singleton {3 // 定义一个枚举元素,即为单例实例4 INSTANCE;5
6 // 可以定义其他方法7 public void someMethod() {8 // 实现方法逻辑9 }10}11
12// 测试枚举单例13public class TestSingleton {14 public static void main(String[] args) {15 16 // 获取单例实例17 Singleton singleton = Singleton.INSTANCE;18
19 // 调用单例的方法20 singleton.someMethod();21 }22}23
2. 原型模式(Prototype Pattern)
定义:指通过复制现有的实例来创建新实例,而不是通过构造函数。
原理:实现 Cloneable 接口并重写 clone() 方法来复制对象。
优点:
减少创建新对象的开销:通过复制现有对象创建新对象。
动态配置对象:可以在运行时配置对象状态。
451// 原型接口2public interface Prototype extends Cloneable {3 Prototype clone();4}5
6// 具体原型类7public class ConcretePrototype implements Prototype {8 private String data;9
10 public ConcretePrototype(String data) {11 this.data = data;12 }13
14 // 使用浅拷贝15 16 public Prototype clone() {17 try {18 return (Prototype) super.clone();19 } catch (CloneNotSupportedException e) {20 // 处理克隆不支持异常21 return null;22 }23 }24
25 public String getData() {26 return data;27 }28
29 public void setData(String data) {30 this.data = data;31 }32}33
34// 客户端代码35public class Client {36 public static void main(String[] args) {37 ConcretePrototype prototype = new ConcretePrototype("Prototype Data");38 ConcretePrototype clonedPrototype = (ConcretePrototype) prototype.clone();39 System.out.println(clonedPrototype.getData()); // 输出: Prototype Data40 clonedPrototype.setData("Modified Data");41 System.out.println(prototype.getData()); // 输出: Prototype Data42 System.out.println(clonedPrototype.getData()); // 输出: Modified Data43 }44}45
3. 建造者模式(Builder Pattern)
定义:使用多个简单的对象一步一步构建一个复杂的对象。
原理:定义一个建造者接口和具体建造者类,通过建造者类来创建复杂对象。
优点:
解耦:将复杂对象的构建与表示解耦。
灵活性:可以根据需要创建不同表示的复杂对象。
701// 产品类2public class Product {3 private String partA;4 private String partB;5
6 // 构造函数7 public Product(String partA, String partB) {8 this.partA = partA;9 this.partB = partB;10 }11
12 13 public String toString() {14 return "Product [partA=" + partA + ", partB=" + partB + "]";15 }16}17
18// 建造者接口19public interface Builder {20 void buildPartA();21 void buildPartB();22 Product getResult();23}24
25// 具体建造者类26public class ConcreteBuilder implements Builder {27 private String partA;28 private String partB;29
30 31 public void buildPartA() {32 partA = "Part A";33 }34
35 36 public void buildPartB() {37 partB = "Part B";38 }39
40 41 public Product getResult() {42 return new Product(partA, partB);43 }44}45
46// 指导者类47public class Director {48 private Builder builder;49
50 public Director(Builder builder) {51 this.builder = builder;52 }53
54 public void construct() {55 builder.buildPartA();56 builder.buildPartB();57 }58}59
60// 客户端代码61public class Client {62 public static void main(String[] args) {63 Builder builder = new ConcreteBuilder();64 Director director = new Director(builder);65 director.construct();66 Product product = builder.getResult();67 System.out.println(product);68 }69}70
注意:
工厂模式用来创建不同但相关类型的对象,构建者模式用来创建复杂对象,原型模式用来创建“new成本大”对象。
4. 简单工厂模式
定义:通过一个静态方法,根据传入的参数,返回不同类型的对象。
优点:客户端不需要知道具体产品类的类名,只需要知道一个参数即可创建产品实例,降低了客户端与具体产品类的耦合。
缺点:
增加新的产品时需要修改工厂类,违反了开放-关闭原则(OCP)。
简单工厂模式中的工厂类集中了所有产品的创建逻辑,职责过重,不利于代码维护。
使用场景:
当工厂类负责创建的对象比较少时。
客户端只需知道传入工厂类的参数即可创建对象时。
典型实现:
Spring框架中的
BeanFactory,通过beanName获取多种不同对象。
491// 产品接口2public interface Product {3 void use();4}5
6// 具体产品A7public class ProductA implements Product {8 9 public void use() {10 System.out.println("Using Product A");11 }12}13
14// 具体产品B15public class ProductB implements Product {16 17 public void use() {18 System.out.println("Using Product B");19 }20}21
22// 工厂类23public class SimpleFactory {24 // 静态方法,根据传入的参数创建不同的产品对象25 public static Product createProduct(String type) {26 switch (type) {27 case "A":28 return new ProductA();29 case "B":30 return new ProductB();31 default:32 throw new IllegalArgumentException("Unknown product type");33 }34 }35}36
37// 使用示例38public class Main {39 public static void main(String[] args) {40 // 创建产品A41 Product productA = SimpleFactory.createProduct("A");42 productA.use();43
44 // 创建产品B45 Product productB = SimpleFactory.createProduct("B");46 productB.use();47 }48}49
5. 工厂方法模式(Factory Method Pattern)
定义:定义一个创建对象的接口,但由子类决定实例化哪个类。
原理:将对象的创建逻辑放在子类中,而不是在客户端代码中。
优点:
遵循开放-关闭原则,新增产品时只需增加相应的具体产品类和具体工厂类。
遵循单一职责原则,每个具体工厂类只负责创建对应的产品。
缺点:
增加了系统的复杂性,增加了类的数量。
使用场景:
一个类不知道它所需要的对象的类时。
一个类通过其子类来指定创建哪个对象时。
将创建对象的职责委托给多个工厂子类中的某一个,客户端在使用时通过具体工厂类来创建对象。
典型应用:
Spring框架中的各种
FactoryBean,每种FactoryBean可用于创建对应类型的复杂对象。
381// 工厂接口2public interface Factory {3 Product createProduct();4}5
6// 具体工厂A7public class FactoryA implements Factory {8 9 public Product createProduct() {10 return new ProductA();11 }12}13
14// 具体工厂B15public class FactoryB implements Factory {16 17 public Product createProduct() {18 return new ProductB();19 }20}21
22// 使用示例23public class Main {24 public static void main(String[] args) {25 // 创建具体工厂A26 Factory factoryA = new FactoryA();27 // 通过工厂A创建产品A28 Product productA = factoryA.createProduct();29 productA.use();30
31 // 创建具体工厂B32 Factory factoryB = new FactoryB();33 // 通过工厂B创建产品B34 Product productB = factoryB.createProduct();35 productB.use();36 }37}38
6. 抽象工厂模式(Abstract Factory Pattern)
定义:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
原理:通过定义多个工厂接口,每个接口负责创建一组相关的对象。
优点:
分离了具体类的生成,符合开放-关闭原则。
可以在不修改已有代码的情况下增加新的产品系列。
通过一个工厂创建多个相关的产品对象,保证产品对象的一致性。
缺点:
增加了系统的复杂性,增加了类的数量。
使用场景:
一个系统需要独立于其产品创建、组合和表示时。
一个系统需要配置多个产品系列中的一个时。
需要强调一系列相关的产品对象一起使用时。
典型应用:
JDBC 中的
Driver接口,Connection、Statement等接口是其产品族成员,各数据库厂商对工厂和产品进行实现。
981// 抽象产品12public interface Product1 {3 void use();4}5
6// 抽象产品27public interface Product2 {8 void use();9}10
11// 具体产品A112public class ProductA1 implements Product1 {13 14 public void use() {15 System.out.println("Using Product A1");16 }17}18
19// 具体产品A220public class ProductA2 implements Product2 {21 22 public void use() {23 System.out.println("Using Product A2");24 }25}26
27// 具体产品B128public class ProductB1 implements Product1 {29 30 public void use() {31 System.out.println("Using Product B1");32 }33}34
35// 具体产品B236public class ProductB2 implements Product2 {37 38 public void use() {39 System.out.println("Using Product B2");40 }41}42
43// 抽象工厂44public interface AbstractFactory {45 Product1 createProduct1();46 Product2 createProduct2();47}48
49// 具体工厂A50public class FactoryA implements AbstractFactory {51 52 public Product1 createProduct1() {53 return new ProductA1();54 }55
56 57 public Product2 createProduct2() {58 return new ProductA2();59 }60}61
62// 具体工厂B63public class FactoryB implements AbstractFactory {64 65 public Product1 createProduct1() {66 return new ProductB1();67 }68
69 70 public Product2 createProduct2() {71 return new ProductB2();72 }73}74
75// 使用示例76public class Main {77 public static void main(String[] args) {78 // 创建具体工厂A79 AbstractFactory factoryA = new FactoryA();80 81 // 通过工厂A创建产品A1和A282 Product1 productA1 = factoryA.createProduct1();83 Product2 productA2 = factoryA.createProduct2();84 productA1.use();85 productA2.use();86
87 // 创建具体工厂B88 AbstractFactory factoryB = new FactoryB();89 90 // 通过工厂B创建产品B1和B291 Product1 productB1 = factoryB.createProduct1();92 Product2 productB2 = factoryB.createProduct2();93 productB1.use();94 productB2.use();95 }96}97
98
注意:
简单工厂指“一个工厂创建所有”,工厂方法指“一个工厂只创建一种”,抽象方法指“一个工厂创建一族”。
第三节 结构型模式(Structural Patterns)
结构型模式关注如何将类或对象组合成更大的结构,以便更好地实现功能。
1. 适配器模式(Adapter Pattern)
定义:将一个类的接口转换成客户希望的另一个接口。适配器模式使得原本接口不兼容的类可以合作。
原理:通过引入一个适配器类,将目标接口转换为适配者接口。
优点:
接口兼容:使得接口不兼容的类可以协作。
复用性:可以复用现有的类。
351// 目标接口2public interface Target {3 void request();4}5
6// 适配者类7public class Adaptee {8 public void specificRequest() {9 System.out.println("SpecificRequest");10 }11}12
13// 适配器类14public class Adapter implements Target {15 private Adaptee adaptee;16
17 public Adapter(Adaptee adaptee) {18 this.adaptee = adaptee;19 }20
21 22 public void request() {23 adaptee.specificRequest(); // 适配方法24 }25}26
27// 客户端代码28public class Client {29 public static void main(String[] args) {30 Adaptee adaptee = new Adaptee();31 Target target = new Adapter(adaptee);32 target.request(); // 通过适配器调用33 }34}35
2. 桥接模式(Bridge Pattern)
定义:将抽象部分与实现部分分离,使它们可以独立地变化。
原理:通过定义抽象类和实现类,将它们的变化解耦。
优点:
解耦:抽象和实现的解耦,使得它们可以独立变化。
灵活性:可以独立地扩展抽象和实现。
571// 实现接口2public interface Implementor {3 void operation();4}5
6// 具体实现A7public class ConcreteImplementorA implements Implementor {8 9 public void operation() {10 System.out.println("ConcreteImplementorA operation");11 }12}13
14// 具体实现B15public class ConcreteImplementorB implements Implementor {16 17 public void operation() {18 System.out.println("ConcreteImplementorB operation");19 }20}21
22// 抽象类23public abstract class Abstraction {24 protected Implementor implementor;25
26 public Abstraction(Implementor implementor) {27 this.implementor = implementor;28 }29
30 public abstract void operation();31}32
33// 扩展抽象类34public class RefinedAbstraction extends Abstraction {35 public RefinedAbstraction(Implementor implementor) {36 super(implementor);37 }38
39 40 public void operation() {41 implementor.operation(); // 委托给实现类42 }43}44
45// 客户端代码46public class Client {47 public static void main(String[] args) {48 Implementor implementorA = new ConcreteImplementorA();49 Abstraction abstraction = new RefinedAbstraction(implementorA);50 abstraction.operation();51
52 Implementor implementorB = new ConcreteImplementorB();53 abstraction = new RefinedAbstraction(implementorB);54 abstraction.operation();55 }56}57
注意:
桥接模式一般表现为抽象类组合接口的形式,如“遥控器”抽象类组合“电视”接口,实现任意遥控器操控任意电视。
3. 组合模式(Composite Pattern)
定义:将对象组合成树形结构以表示部分-整体层次结构,使得客户端对单个对象和组合对象的使用具有一致性。
原理:通过定义一个组件接口,将叶子节点和容器节点统一处理。
优点:
一致性:对单个对象和组合对象的一致性操作。
简化客户端代码:客户端代码可以统一处理叶子节点和容器节点。
典型应用:MyBatis动态SQL解析时构建的语法树,通过MixedNode组合其它节点。
501import java.util.ArrayList;2import java.util.List;3
4// 组件接口5public interface Component {6 void operation();7}8
9// 叶子节点10public class Leaf implements Component {11 12 public void operation() {13 System.out.println("Leaf operation");14 }15}16
17// 容器节点18public class Composite implements Component {19 private List<Component> children = new ArrayList<>();20
21 public void add(Component component) {22 children.add(component);23 }24
25 public void remove(Component component) {26 children.remove(component);27 }28
29 30 public void operation() {31 for (Component child : children) {32 child.operation();33 }34 }35}36
37// 客户端代码38public class Client {39 public static void main(String[] args) {40 Composite root = new Composite();41 Component leaf1 = new Leaf();42 Component leaf2 = new Leaf();43
44 root.add(leaf1);45 root.add(leaf2);46
47 root.operation(); // 统一调用48 }49}50
4. 装饰器模式(Decorator Pattern)
定义:动态地给一个对象添加一些额外的职责。装饰器模式提供了比继承更灵活的扩展功能的方式,常用于替代继承。
原理:通过定义装饰器类来扩展被装饰对象的功能。
优点:
灵活性:可以动态地扩展对象的功能。
避免子类爆炸:通过装饰器而不是继承来扩展功能。
531// 组件接口2public interface Component {3 void operation();4}5
6// 具体组件7public class ConcreteComponent implements Component {8 9 public void operation() {10 System.out.println("ConcreteComponent operation");11 }12}13
14// 装饰器抽象类15public abstract class Decorator implements Component {16 protected Component component;17
18 public Decorator(Component component) {19 this.component = component;20 }21
22 23 public void operation() {24 component.operation();25 }26}27
28// 具体装饰器29public class ConcreteDecorator extends Decorator {30 public ConcreteDecorator(Component component) {31 super(component);32 }33
34 35 public void operation() {36 super.operation();37 addedBehavior();38 }39
40 private void addedBehavior() {41 System.out.println("ConcreteDecorator addedBehavior");42 }43}44
45// 客户端代码46public class Client {47 public static void main(String[] args) {48 Component component = new ConcreteComponent();49 Component decorator = new ConcreteDecorator(component);50 decorator.operation(); // 执行装饰后的操作51 }52}53
5. 外观模式(Facade Pattern)
定义:为子系统中的一组接口提供一个一致的界面,使得子系统更容易使用。
原理:通过定义一个外观类来封装子系统的复杂性,提供简化的接口。
优点:
简化使用:提供简单的接口来访问复杂的子系统。
解耦:将客户端与子系统解耦。
381// 子系统类A2public class SubsystemA {3 public void operationA() {4 System.out.println("SubsystemA operationA");5 }6}7
8// 子系统类B9public class SubsystemB {10 public void operationB() {11 System.out.println("SubsystemB operationB");12 }13}14
15// 外观类16public class Facade {17 private SubsystemA subsystemA;18 private SubsystemB subsystemB;19
20 public Facade() {21 subsystemA = new SubsystemA();22 subsystemB = new SubsystemB();23 }24
25 public void operation() {26 subsystemA.operationA();27 subsystemB.operationB();28 }29}30
31// 客户端代码32public class Client {33 public static void main(String[] args) {34 Facade facade = new Facade();35 facade.operation(); // 通过外观类调用子系统36 }37}38
6. 享元模式(Flyweight Pattern)
定义:运用共享技术有效地支持大量细粒度的对象。
原理:通过将对象的共享部分与独享部分分开,将共享部分提取出来。
优点:
节省内存:通过共享来减少内存使用。
提高性能:减少对象创建和管理的开销。
471import java.util.HashMap;2import java.util.Map;3
4// 享元接口5public interface Flyweight {6 void operation(String extrinsicState);7}8
9// 具体享元类10public class ConcreteFlyweight implements Flyweight {11 private String intrinsicState;12
13 public ConcreteFlyweight(String intrinsicState) {14 this.intrinsicState = intrinsicState;15 }16
17 18 public void operation(String extrinsicState) {19 System.out.println("Intrinsic State: " + intrinsicState + ", Extrinsic State: " + extrinsicState);20 }21}22
23// 享元工厂24public class FlyweightFactory {25 private Map<String, Flyweight> flyweights = new HashMap<>();26
27 public Flyweight getFlyweight(String key) {28 Flyweight flyweight = flyweights.get(key);29 if (flyweight == null) {30 flyweight = new ConcreteFlyweight(key);31 flyweights.put(key, flyweight);32 }33 return flyweight;34 }35}36
37// 客户端代码38public class Client {39 public static void main(String[] args) {40 FlyweightFactory factory = new FlyweightFactory();41 Flyweight flyweight1 = factory.getFlyweight("A");42 Flyweight flyweight2 = factory.getFlyweight("B");43 flyweight1.operation("1");44 flyweight2.operation("2");45 }46}47
7. 代理模式(Proxy Pattern)
定义:为其他对象提供一种代理以控制对这个对象的访问。
原理:通过定义代理类来控制对真实对象的访问。
优点:
控制访问:可以在代理中实现对真实对象的控制。
增强功能:可以在代理中增加额外的功能,如延迟加载。
分类:
静态代理:为每一个真实角色编写对应的代理类,会导致类的数量倍增,维护成本提高。
动态代理:通过在内存生成虚拟类创建代理对象,可维护性好。
1) 静态代理
561/**2 * 抽象对象3 */4public interface UserDao {5 void save();6}7
8/**9 * 真实对象(目标对象)10 */11public class UserDaoImpl implements UserDao {12 13 public void save() {14 System.out.println("----保存数据----");15 }16}17
18/**19 * 代理对象(静态代理)20 */21public class UserDaoProxy implements UserDao {22 //接收保存目标对象23 private UserDao target;24
25 public UserDaoProxy(UserDao target) {26 this.target = target;27 }28
29 30 public void save() {31 System.out.println("开始事务...");32 target.save();33 System.out.println("提交事务...");34 }35}36
37/**38 * 测试类39 */40public class StaticProxyTest {41 public static void main(String[] args) {42 //目标对象43 UserDaoImpl target = new UserDaoImpl();44
45 //代理对象,把目标对象传给代理对象,建立代理关系46 UserDaoProxy proxy = new UserDaoProxy(target);47
48 // 通过代理对象执行方法49 proxy.save();50 }51}52
53开始事务...54----已经保存数据!----55提交事务...56
2) JDK动态代理
231public class JdkProxyTest {2
3 public static void main(String[] args) {4 // 目标对象5 UserDao target = new UserDaoImpl();6
7 // 给目标对象创建代理对象(com.sun.proxy.$Proxy0类型)8 UserDao proxy = (UserDao) Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), new InvocationHandler() {9 10 public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {11 System.out.println("开始事务...");12 Object returnValue = method.invoke(target, args);13 System.out.println("提交事务...");14
15 return returnValue;16 }17 });18
19 // 通过代理对象执行方法20 proxy.save();21 }22}23
3) CGLIB动态代理
221public class CGLibProxyTest {2
3 public static void main(String[] args) {4 // 目标对象5 UserDao target = new UserDaoImpl();6
7 // 给目标对象创建代理对象(UserDaoImpl@35bbe5e8类型)8 UserDao proxy = (UserDao) Enhancer.create(target.getClass(), new InvocationHandler() {9 10 public Object invoke(Object o, Method method, Object[] objects) throws Throwable {11 System.out.println("开始事务...");12 Object returnValue = method.invoke(target, args);13 System.out.println("提交事务...");14
15 return returnValue;16 }17 });18
19 // 通过代理对象执行方法20 proxy.save();21 }22}
第四节 行为型模式(Behavioral Patterns)
行为型模式关注对象之间的沟通和职责分配。
1. 责任链模式(Chain of Responsibility Pattern)
定义:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递请求,直到有一个对象处理它为止。
原理:通过定义处理请求的链,并逐步将请求传递给链中的各个对象,直到找到合适的处理者。
优点:
解耦:发送者和接收者解耦。
灵活性:可以动态地添加或修改处理者。
481// 处理者接口2public abstract class Handler {3 protected Handler nextHandler;4
5 public void setNextHandler(Handler nextHandler) {6 this.nextHandler = nextHandler;7 }8
9 public abstract void handleRequest(String request);10}11
12// 具体处理者A13public class ConcreteHandlerA extends Handler {14 15 public void handleRequest(String request) {16 if (request.equals("A")) {17 System.out.println("Handler A handling request A");18 } else if (nextHandler != null) {19 nextHandler.handleRequest(request);20 }21 }22}23
24// 具体处理者B25public class ConcreteHandlerB extends Handler {26 27 public void handleRequest(String request) {28 if (request.equals("B")) {29 System.out.println("Handler B handling request B");30 } else if (nextHandler != null) {31 nextHandler.handleRequest(request);32 }33 }34}35
36// 客户端代码37public class Client {38 public static void main(String[] args) {39 Handler handlerA = new ConcreteHandlerA();40 Handler handlerB = new ConcreteHandlerB();41 handlerA.setNextHandler(handlerB);42
43 handlerA.handleRequest("A"); // 处理请求A44 handlerA.handleRequest("B"); // 处理请求B45 handlerA.handleRequest("C"); // 无处理者46 }47}48
注意:
典型应用场景如SpringMVC中的视图解析器,挨个尝试是否能够处理。
2. 命令模式(Command Pattern)
定义:将请求封装成一个对象,从而使你能够用不同的请求对客户进行参数化、队列化请求、以及支持可撤销操作。
原理:通过定义命令接口和具体命令类,将请求封装为对象,并将其传递给调用者。
优点:
解耦:发送者和接收者解耦。
灵活性:可以动态地创建、撤销请求。
501// 命令接口2public interface Command {3 void execute();4}5
6// 具体命令类7public class ConcreteCommand implements Command {8 private Receiver receiver;9
10 public ConcreteCommand(Receiver receiver) {11 this.receiver = receiver;12 }13
14 15 public void execute() {16 receiver.action(); // 将请求委托给接收者17 }18}19
20// 接收者类21public class Receiver {22 public void action() {23 System.out.println("Receiver action");24 }25}26
27// 调用者类28public class Invoker {29 private Command command;30
31 public void setCommand(Command command) {32 this.command = command;33 }34
35 public void invoke() {36 command.execute();37 }38}39
40// 客户端代码41public class Client {42 public static void main(String[] args) {43 Receiver receiver = new Receiver();44 Command command = new ConcreteCommand(receiver);45 Invoker invoker = new Invoker();46 invoker.setCommand(command);47 invoker.invoke(); // 执行命令48 }49}50
3. 迭代器模式(Iterator Pattern)
定义:提供一种方法访问一个容器对象中各个元素,而又不暴露该对象的内部表示。
原理:通过定义迭代器接口和具体迭代器类来遍历集合对象中的元素。
优点:
简化访问:提供统一的访问方式。
解耦:容器和迭代器解耦。
561import java.util.ArrayList;2import java.util.List;3
4// 迭代器接口5public interface Iterator {6 boolean hasNext();7 Object next();8}9
10// 具体迭代器类11public class ConcreteIterator implements Iterator {12 private List<Object> items;13 private int position;14
15 public ConcreteIterator(List<Object> items) {16 this.items = items;17 }18
19 20 public boolean hasNext() {21 return position < items.size();22 }23
24 25 public Object next() {26 return items.get(position++);27 }28}29
30// 聚合类31public class Aggregate {32 private List<Object> items = new ArrayList<>();33
34 public void add(Object item) {35 items.add(item);36 }37
38 public Iterator iterator() {39 return new ConcreteIterator(items);40 }41}42
43// 客户端代码44public class Client {45 public static void main(String[] args) {46 Aggregate aggregate = new Aggregate();47 aggregate.add("Item 1");48 aggregate.add("Item 2");49
50 Iterator iterator = aggregate.iterator();51 while (iterator.hasNext()) {52 System.out.println(iterator.next());53 }54 }55}56
4. 中介者模式(Mediator Pattern)
定义:定义一个对象来封装一组对象之间的交互,使得对象之间的耦合松散,从而使得它们可以独立地改变。
原理:通过定义中介者接口和具体中介者类来协调对象之间的交互。
优点:
降低耦合:将对象间的交互集中在中介者中。
易于维护:中介者可以集中处理复杂的交互逻辑。
831// 中介者接口2public interface Mediator {3 void notify(Component sender, String event);4}5
6// 具体中介者类7public class ConcreteMediator implements Mediator {8 private ComponentA componentA;9 private ComponentB componentB;10
11 public void setComponentA(ComponentA componentA) {12 this.componentA = componentA;13 }14
15 public void setComponentB(ComponentB componentB) {16 this.componentB = componentB;17 }18
19 20 public void notify(Component sender, String event) {21 if (sender == componentA) {22 componentB.handleEvent(event);23 } else if (sender == componentB) {24 componentA.handleEvent(event);25 }26 }27}28
29// 组件接口30public abstract class Component {31 protected Mediator mediator;32
33 public Component(Mediator mediator) {34 this.mediator = mediator;35 }36
37 public abstract void handleEvent(String event);38}39
40// 具体组件A41public class ComponentA extends Component {42 public ComponentA(Mediator mediator) {43 super(mediator);44 }45
46 47 public void handleEvent(String event) {48 System.out.println("ComponentA handling event: "49
50 + event);51 }52
53 public void triggerEvent(String event) {54 mediator.notify(this, event);55 }56}57
58// 具体组件B59public class ComponentB extends Component {60 public ComponentB(Mediator mediator) {61 super(mediator);62 }63
64 65 public void handleEvent(String event) {66 System.out.println("ComponentB handling event: " + event);67 }68}69
70// 客户端代码71public class Client {72 public static void main(String[] args) {73 ConcreteMediator mediator = new ConcreteMediator();74 ComponentA componentA = new ComponentA(mediator);75 ComponentB componentB = new ComponentB(mediator);76 mediator.setComponentA(componentA);77 mediator.setComponentB(componentB);78
79 componentA.triggerEvent("Event A");80 componentB.handleEvent("Event B");81 }82}83
5. 备忘录模式(Memento Pattern)
定义:在不暴露对象内部状态的情况下,捕获一个对象的内部状态,并在该对象外部保存这个状态。可以在以后将对象恢复到保存的状态。
原理:通过定义备忘录类来保存对象的状态,并通过发起人类和恢复者类来实现状态的恢复。
优点:
状态恢复:可以在需要的时候恢复对象的状态。
封装性:不暴露对象的内部状态。
641// 备忘录类2public class Memento {3 private String state;4
5 public Memento(String state) {6 this.state = state;7 }8
9 public String getState() {10 return state;11 }12}13
14// 发起人类15public class Originator {16 private String state;17
18 public void setState(String state) {19 this.state = state;20 }21
22 public String getState() {23 return state;24 }25
26 public Memento saveStateToMemento() {27 return new Memento(state);28 }29
30 public void getStateFromMemento(Memento memento) {31 state = memento.getState();32 }33}34
35// 管理者类36public class Caretaker {37 private Memento memento;38
39 public void saveMemento(Memento memento) {40 this.memento = memento;41 }42
43 public Memento retrieveMemento() {44 return memento;45 }46}47
48// 客户端代码49public class Client {50 public static void main(String[] args) {51 Originator originator = new Originator();52 Caretaker caretaker = new Caretaker();53
54 originator.setState("State1");55 caretaker.saveMemento(originator.saveStateToMemento());56
57 originator.setState("State2");58 System.out.println("Current State: " + originator.getState());59
60 originator.getStateFromMemento(caretaker.retrieveMemento());61 System.out.println("Restored State: " + originator.getState());62 }63}64
6. 解释器模式(Interpreter Pattern)
定义:给定一个语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
原理:通过定义解释器类和表达式类,将文法规则和解释逻辑分开。
优点:
易于扩展:可以通过增加新的终结符和非终结符来扩展语法。
灵活性:可以定义复杂的语言规则。
481import java.util.HashMap;2import java.util.Map;3
4// 表达式接口5public interface Expression {6 int interpret(Map<String, Integer> context);7}8
9// 终结符表达式10public class NumberExpression implements Expression {11 private int number;12
13 public NumberExpression(int number) {14 this.number = number;15 }16
17 18 public int interpret(Map<String, Integer> context) {19 return number;20 }21}22
23// 非终结符表达式24public class PlusExpression implements Expression {25 private Expression left;26 private Expression right;27
28 public PlusExpression(Expression left, Expression right) {29 this.left = left;30 this.right = right;31 }32
33 34 public int interpret(Map<String, Integer> context) {35 return left.interpret(context) + right.interpret(context);36 }37}38
39// 客户端代码40public class Client {41 public static void main(String[] args) {42 Expression expression = new PlusExpression(new NumberExpression(5), new NumberExpression(3));43 Map<String, Integer> context = new HashMap<>();44 int result = expression.interpret(context);45 System.out.println("Result: " + result); // 输出结果 846 }47}48
7. 状态模式(State Pattern)
定义:允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类。
原理:通过定义状态接口和具体状态类,将对象的状态和行为分开,使得状态改变时可以改变行为。
优点:
状态独立:每个状态都有自己的行为。
易于扩展:可以增加新的状态而不改变现有代码。
491// 状态接口2public interface State {3 void handle(Context context);4}5
6// 具体状态A7public class ConcreteStateA implements State {8 9 public void handle(Context context) {10 System.out.println("Handling state A");11 context.setState(new ConcreteStateB()); // 切换到状态B12 }13}14
15// 具体状态B16public class ConcreteStateB implements State {17 18 public void handle(Context context) {19 System.out.println("Handling state B");20 context.setState(new ConcreteStateA()); // 切换到状态A21 }22}23
24// 上下文类25public class Context {26 private State state;27
28 public Context(State state) {29 this.state = state;30 }31
32 public void setState(State state) {33 this.state = state;34 }35
36 public void request() {37 state.handle(this);38 }39}40
41// 客户端代码42public class Client {43 public static void main(String[] args) {44 Context context = new Context(new ConcreteStateA());45 context.request(); // 处理状态A46 context.request(); // 处理状态B47 }48}49
8. 策略模式(Strategy Pattern)
定义:定义一系列算法,将每一个算法封装起来,并使它们可以相互替换。策略模式让算法独立于使用它的客户而独立变化。
原理:通过定义策略接口和具体策略类,将算法封装为对象,并在运行时选择使用。
优点:
灵活性:可以动态选择算法。
易于扩展:可以新增策略而不影响现有代码。
461// 策略接口2public interface Strategy {3 void execute();4}5
6// 具体策略A7public class ConcreteStrategyA implements Strategy {8 9 public void execute() {10 System.out.println("Executing strategy A");11 }12}13
14// 具体策略B15public class ConcreteStrategyB implements Strategy {16 17 public void execute() {18 System.out.println("Executing strategy B");19 }20}21
22// 上下文类23public class Context {24 private Strategy strategy;25
26 public void setStrategy(Strategy strategy) {27 this.strategy = strategy;28 }29
30 public void executeStrategy() {31 strategy.execute();32 }33}34
35// 客户端代码36public class Client {37 public static void main(String[] args) {38 Context context = new Context();39 context.setStrategy(new ConcreteStrategyA());40 context.executeStrategy(); // 执行策略A41
42 context.setStrategy(new ConcreteStrategyB());43 context.executeStrategy(); // 执行策略B44 }45}46
9. 模板方法模式(Template Method Pattern)
定义:定义一个操作中的算法的骨架,将一些步骤延迟到子类中。模板方法使得子类可以在不改变算法结构的情况下重新定义算法中的某些步骤。
原理:通过定义模板方法在父类中,并将一些步骤的实现延迟到子类中。
优点:
复用性:将公共算法逻辑放在父类中。
灵活性:子类可以改变某些步骤的实现而不改变算法结构。
501// 抽象类2public abstract class AbstractClass {3 // 模板方法4 public final void templateMethod() {5 step1();6 step2();7 step3();8 }9
10 // 具体步骤111 private void step1() {12 System.out.println("Step 1");13 }14
15 // 具体步骤2,留给子类实现16 protected abstract void step2();17
18 // 具体步骤319 private void step3() {20 System.out.println("Step 3");21 }22}23
24// 具体类A25public class ConcreteClassA extends AbstractClass {26 27 protected void step2() {28 System.out.println("ConcreteClassA Step 2");29 }30}31
32// 具体类B33public class ConcreteClassB extends AbstractClass {34 35 protected void step2() {36 System.out.println("ConcreteClassB Step 2");37 }38}39
40// 客户端代码41public class Client {42 public static void main(String[] args) {43 AbstractClass concreteClassA = new ConcreteClassA();44 concreteClassA.templateMethod(); // 执行具体类A的模板方法45
46 AbstractClass concreteClassB = new ConcreteClassB();47 concreteClassB.templateMethod(); // 执行具体类B的模板方法48 }49}50
10. 访问者模式(Visitor Pattern)
定义:表示一个作用于某对象结构中的各元素的操作,它可以在不改变元素类的前提下定义作用于这些元素的新操作。
原理:通过定义访问者接口和具体访问者类,将操作和对象结构分离,使得可以在不改变对象结构的情况下增加新的操作。
优点:
扩展性:可以在不改变对象结构的情况下增加新的操作。
操作集中:操作被集中在访问者中,使得相关操作更易于维护。
861import java.util.ArrayList;2import java.util.List;3
4// 访问者接口5public interface Visitor {6 void visit(ConcreteElementA elementA);7 void visit(ConcreteElementB elementB);8}9
10// 具体访问者A11public class ConcreteVisitorA implements Visitor {12 13 public void visit(ConcreteElementA elementA) {14 System.out.println("Visitor A visiting Element A");15 }16
17 18 public void visit(ConcreteElementB elementB) {19 System.out.println("Visitor A visiting Element B");20 }21}22
23// 具体访问者B24public class ConcreteVisitorB implements Visitor {25 26 public void visit(ConcreteElementA elementA) {27 System.out.println("Visitor B visiting Element A");28 }29
30 31 public void visit(ConcreteElementB elementB) {32 System.out.println("Visitor B visiting Element B");33 }34}35
36// 元素接口37public interface Element {38 void accept(Visitor visitor);39}40
41// 具体元素A42public class ConcreteElementA implements Element {43 44 public void accept(Visitor visitor) {45 visitor.visit(this);46 }47}48
49// 具体元素B50public class ConcreteElementB implements Element {51 52 public void accept(Visitor visitor) {53 visitor.visit(this);54 }55}56
57// 对象结构58public class ObjectStructure {59 private List<Element> elements = new ArrayList<>();60
61 public void addElement(Element element) {62 elements.add(element);63 }64
65 public void accept(Visitor visitor) {66 for (Element element : elements) {67 element.accept(visitor);68 }69 }70}71
72// 客户端代码73public class Client {74 public static void main(String[] args) {75 ObjectStructure structure = new ObjectStructure();76 structure.addElement(new ConcreteElementA());77 structure.addElement(new ConcreteElementB());78
79 Visitor visitorA = new ConcreteVisitorA();80 structure.accept(visitorA); // Visitor A visiting elements81
82 Visitor visitorB = new ConcreteVisitorB();83 structure.accept(visitorB); // Visitor B visiting elements84 }85}86
11. 观察者模式(Observer Pattern)
定义:定义对象之间的一对多依赖,使得当一个对象改变状态时,所有依赖于它的对象都得到通知并被自动更新。
原理:通过定义观察者接口和被观察者类来实现一对多的通知机制。
优点:
解耦:观察者和被观察者之间的解耦。
动态更新:自动更新所有观察者。
661import java.util.ArrayList;2import3
4 java.util.List;5
6// 观察者接口7public interface Observer {8 void update(String message);9}10
11// 被观察者接口12public interface Subject {13 void addObserver(Observer observer);14 void removeObserver(Observer observer);15 void notifyObservers(String message);16}17
18// 具体被观察者19public class ConcreteSubject implements Subject {20 private List<Observer> observers = new ArrayList<>();21
22 23 public void addObserver(Observer observer) {24 observers.add(observer);25 }26
27 28 public void removeObserver(Observer observer) {29 observers.remove(observer);30 }31
32 33 public void notifyObservers(String message) {34 for (Observer observer : observers) {35 observer.update(message);36 }37 }38}39
40// 具体观察者41public class ConcreteObserver implements Observer {42 private String name;43
44 public ConcreteObserver(String name) {45 this.name = name;46 }47
48 49 public void update(String message) {50 System.out.println(name + " received: " + message);51 }52}53
54// 客户端代码55public class Client {56 public static void main(String[] args) {57 ConcreteSubject subject = new ConcreteSubject();58 Observer observer1 = new ConcreteObserver("Observer1");59 Observer observer2 = new ConcreteObserver("Observer2");60 subject.addObserver(observer1);61 subject.addObserver(observer2);62
63 subject.notifyObservers("Hello Observers!");64 }65}66
第五节 UML图
1. UML简介
UML 是 Unified Model Language 的缩写,中文是统一建模语言,是由一整套图表组成的标准化建模语言。分类如下:
2. 类图(Class Diagram)
类图是面向对象系统建模中最常用和最重要的图,是定义其它图的基础,主要用来表示类、接口以及它们之间的静态结构和关系。
在类图中,常见的有以下几种关系:
1) 泛化/继承(Generalization)
泛化关系是一种继承关系(is A),表示子类继承父类的所有特征和行为。
箭头指向:带三角箭头的实线,箭头指向父类。

2) 实现(Realization)
实现关系是一种类与接口的实现关系(is A),表示类是接口所有特征和行为的实现。
箭头指向:带三角箭头的虚线表示,箭头指向接口。
3) 组合(Composition)
组合关系是一种整体与部分的关系,且部分不能离开整体而单独存在。组合关系是关联关系的一种,是比聚合关系还要强的关系。
代码体现:成员变量。
箭头指向:带实心菱形和普通箭头的实线,实心菱形指向整体。
鸟是整体,翅膀是部分。鸟死了,翅膀也就不能飞了。所以是组合。
4) 聚合(Aggregation)
聚合关系是一种整体与部分的关系(has A),但部分可以离开整体而单独存在。聚合关系是关联关系的一种,是较强的关联关系;
代码体现:成员变量。
箭头指向:带空心菱形的实线,空心菱形指向整体。

电脑有键盘才能输入信息,电脑是整体,键盘是部分,键盘也可以离开电脑,单纯的拿去敲,所以是聚合。
5) 关联(Association)
关联关系是一种拥有关系(has A),它使得一个类知道另一个类的属性和方法。
代码体现:成员变量。
箭头指向:带普通箭头的实线,指向被拥有者。双向的关联可以有两个箭头,或者没有箭头。单向的关联有一个箭头。
车是车,人是人,没有整体与部分的关系。
6) 依赖(Dependency)
依赖关系是一种使用关系(use A),即一个类的实现需要另一个类的协助。
代码体现:方法参数
箭头指向:带普通箭头的虚线,普通箭头指向被使用者。
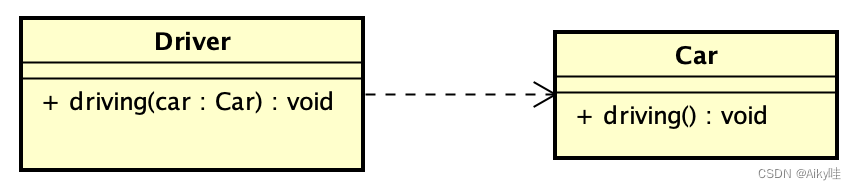
老司机只管开车,车是谁的不重要,给什么车开什么车。
3. 其它UML图
1) 组件图
【概念】描绘了系统中组件提供的、需要的接口、端口等,以及它们之间的关系。
【目的】用来展示各个组件之间的依赖关系。

订单系统组件依赖于客户资源库和库存系统组件。中间的虚线箭头表示依赖关系。另外两个符号,表示组件连接器,一个提供接口,一个需要接口。
2) 部署图
【概念】描述了系统内部的软件如何分布在不同的节点上。
【目的】用来表示软件和硬件的映射关系。
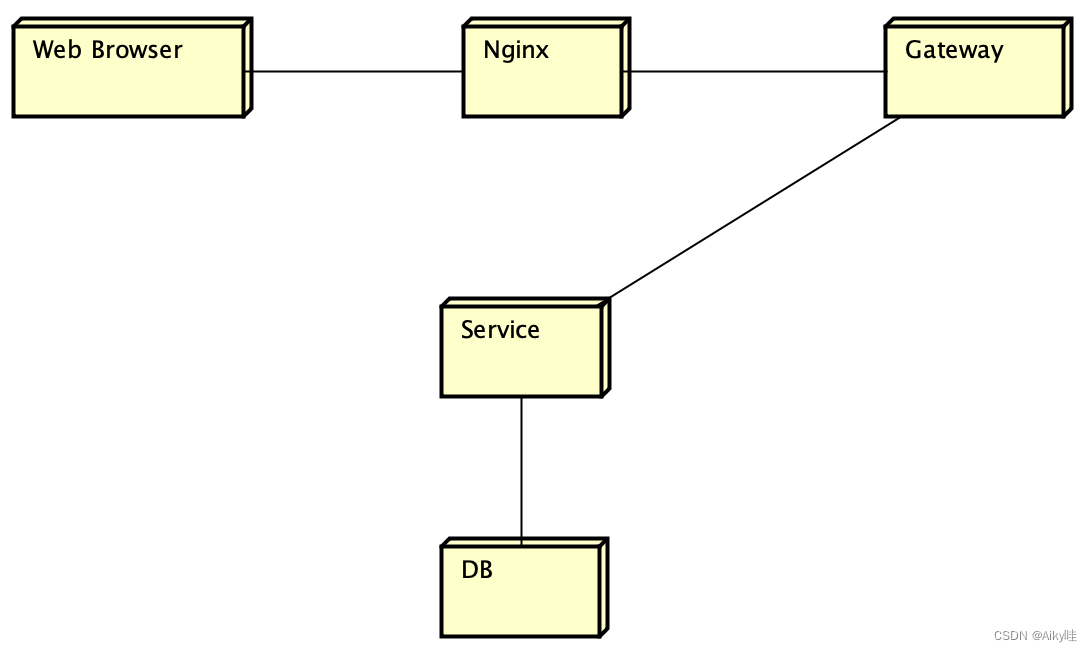
图中简单的表示,不同机器上面部署的不同软件。
3) 对象图
【概念】对象图是类图的一个实例,是系统在某个时间点的详细状态的快照。
【目的】用来表示两个或者多个对象之间在某一时刻之间的关系。
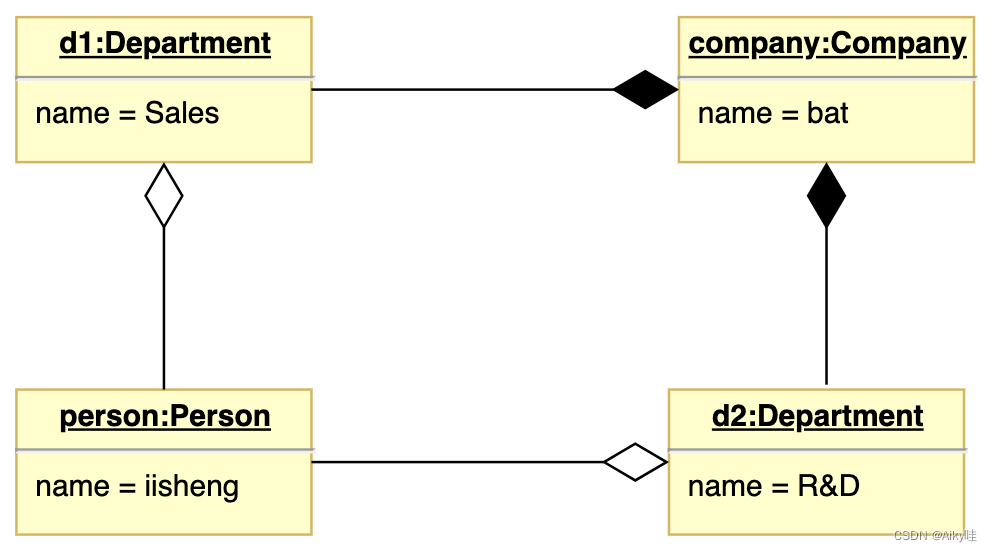
图中就是描述的,某时间点 bat 这个公司有一个研发部,一个销售部,两个部门只有一个人iisheng。
4) 包图
【概念】描绘了系统在包层面上的结构设计。
【目的】用来表示包和包之间的依赖关系。
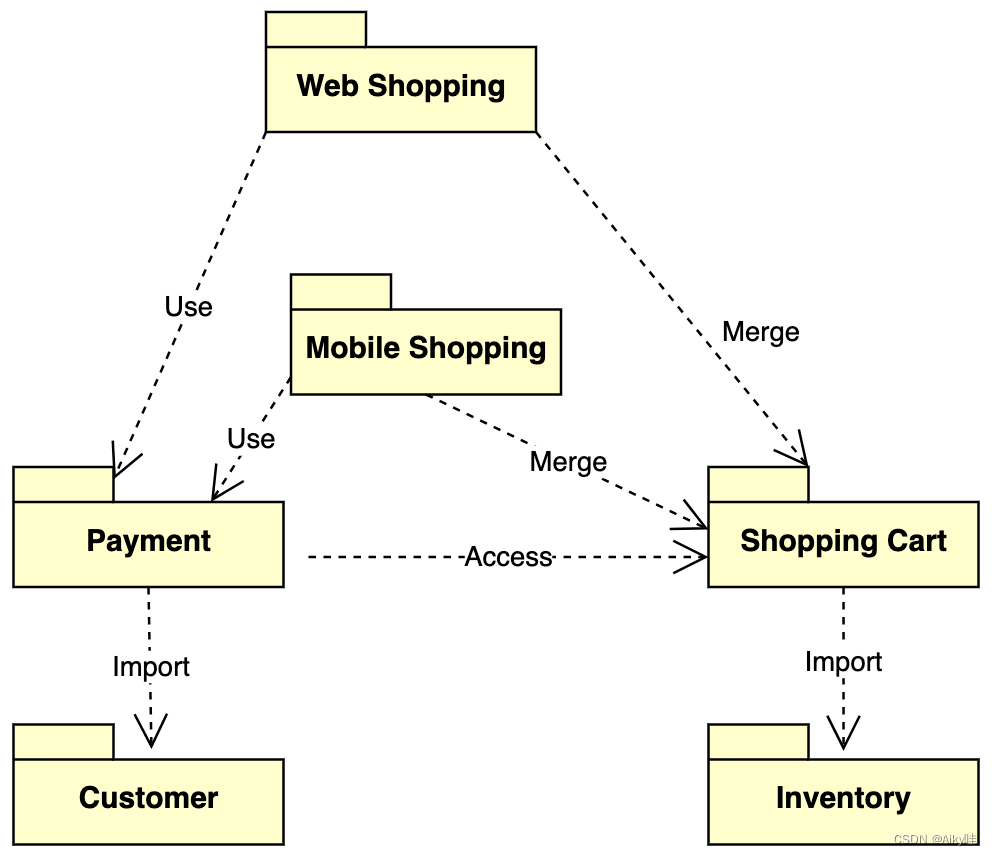
“Use”关系:表示使用依赖,
Web Shopping依赖Payment“Merge”关系:表示合并,
Web Shopping合并了Shopping Cart就拥有了Shopping Cart的功能“Access”关系:表示私有引入,比如代码中的指定包名类名
“Import”关系:表示公共引入,比如Java中的
import之后,就可以直接使用import包中的类了。
5) 组合结构图
【概念】描述了一个"组合结构"的内部结构,以及他们之间的关系。这个"组合结构"可以是系统的一部分,或者一个整体。
【目的】用来表示系统中逻辑上的"组合结构"。
图中描述了Car是由车轴连接着的两个前面轮子、两个后面轮子,和引擎组合的。
6) 轮廓图
【概念】轮廓图提供了一种通用的扩展机制,用于为特定域和平台定制UML模型。
【目的】用于在特定领域中构建UML模型。

图中我们定义了一个简易的EJB的概要图。Bean是从Component扩展来的。Entity Bean和Session Bean继承了Bean。EJB拥有Remote和Home接口,和JAR包。
7) 用例图
【概念】用例图是指由参与者、用例,边界以及它们之间的关系构成的用于描述系统功能的视图。
【目的】用来描述整个系统的功能。
用例图中包含以下三种关系:
包含关系使用符号include,想要查看订单列表,前提是需要先登录。
扩展关系使用符号extend,基于查询订单列表的功能,可以增加一个导出数据的功能
泛化关系,子用例继承父用例所有结构、行为和关系。
8) 活动图
【概念】描述了具体业务用例的实现流程。
【目的】用来表示用例实现的工作流程。
图中简单描述了,从开始到登录到查看订单列表,或者登录失败直接结束。
9) 状态图
【概念】状态机图对一个单独对象的行为建模,指明对象在它的整个生命周期里,响应不同事件时,执行相关事件的顺序。
【目的】用来表示指定对象,在整个生命周期,响应不同事件的不同状态。
图中描述了,门在其生命周期内所经历的状态。
10) 序列图
【概念】序列图根据时间序列展示对象如何进行协作。它展示了在用例的特定场景中,对象如何与其他对象交互。
【目的】通过描述对象之间发送消息的时间顺序显示多个对象之间的动态协作。
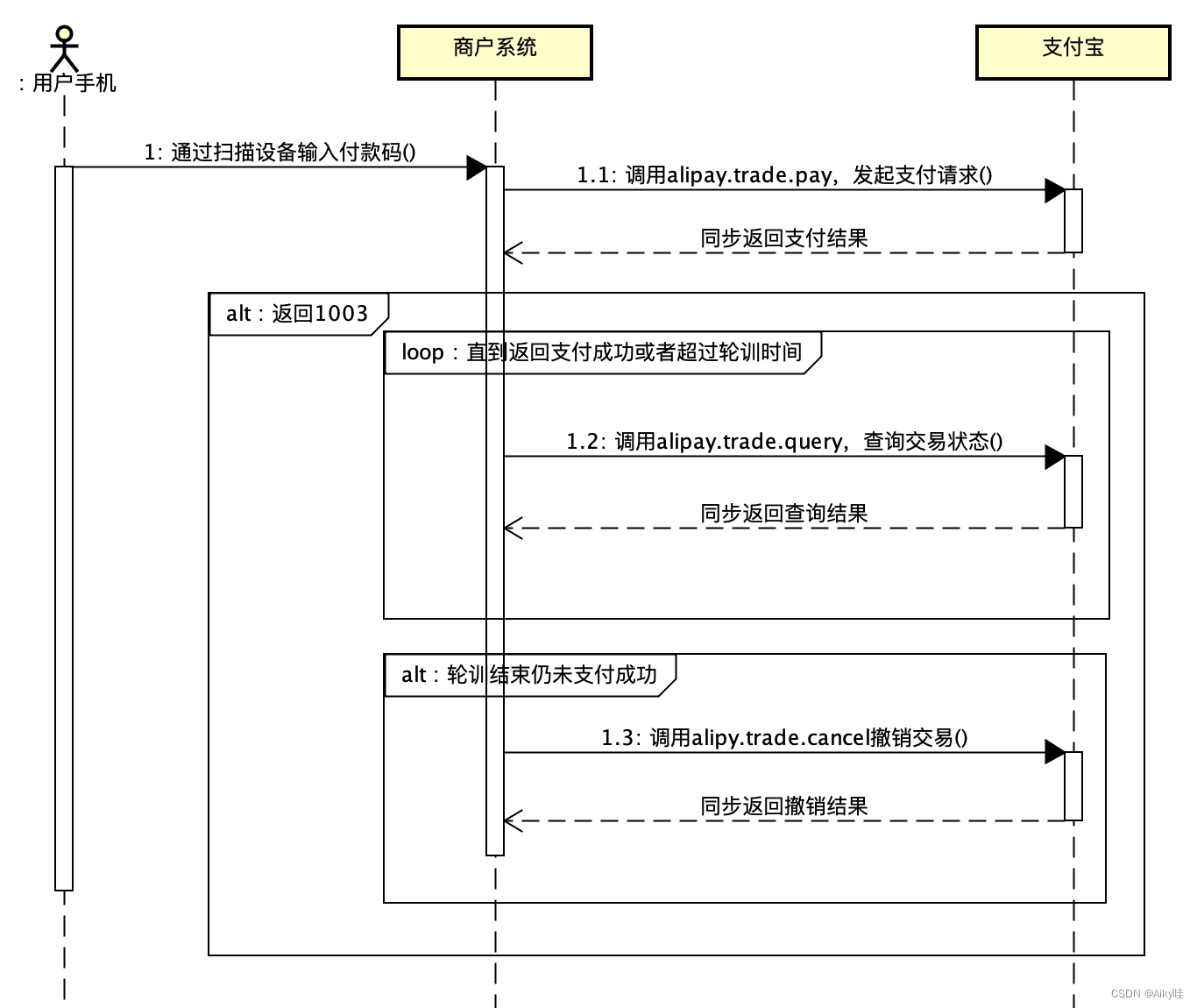
图中展示的是支付宝条码支付场景的序列图。其中,loop是循环,alt是选择,序列图的其他关系这里就不介绍了。
11) 通讯图/协作图
【概念】描述了收发消息的对象的组织关系,强调对象之间的合作关系而不是时间顺序。
【目的】用来显示不同对象的关系。
图中展示了一个线上书店的通讯图,方框和小人表示生命线,不同生命线之间可以传递消息,消息前面的数字可以表达序列顺序。
12) 交互概览图
【概念】交互概览图与活动图类似,但是它的节点是交互图。
【目的】提供了控制流的概述。
图中表示一个调度系统的交互概览图,跟活动图很像。其中sd的框代表具体的交互流程,ref框代表使用交互。
13) 时序图
【概念】时序图用来显示随时间变化的一个或多个元素值或状态的更改。也显示时控事件之间的交互和管理它们的时间和期限约束。
【目的】用来表示元素状态或者值随时间的变化而变化的视图。
图中展示了老年痴呆病人随着时间的变化病情的变化。