第03篇_常见分布式组件
第01章_Nginx
第一节 Nginx简介
1. 什么是Nginx?
Nginx (engine x) 是一个高性能的HTTP和反向代理服务器,支持高达 50,000 个并发连接数,此外,也提供了IMAP/POP3/SMTP等服务。
2. Nginx应用场景
1) 反向代理
正向代理:在客户端配置代理服务器进行指定网站访问,如在中国大陆通过香港的代理服务器访问外网。
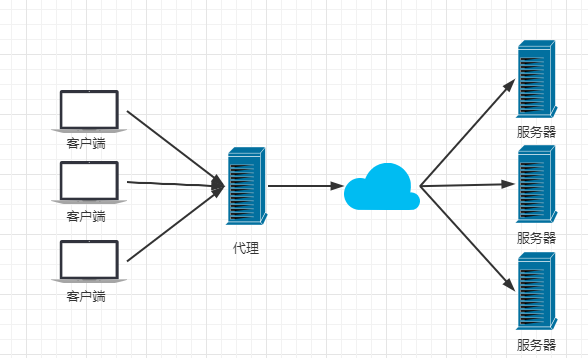
反向代理:在服务端配置代理服务器统一接收客户端请求,然后路由到内部隐藏的真实服务器。
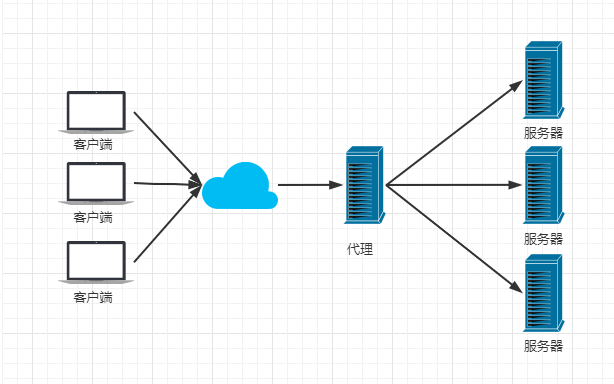
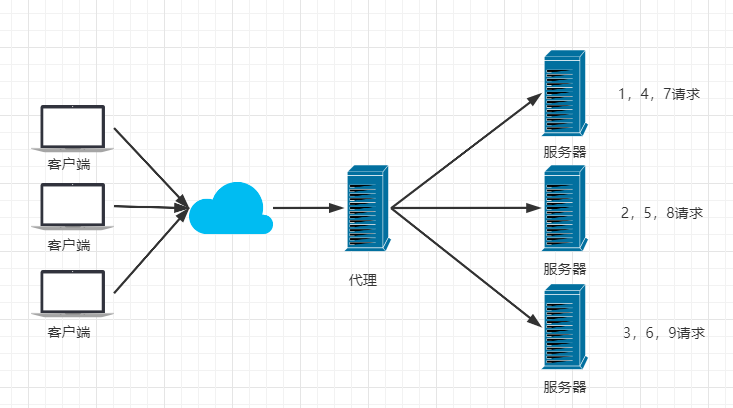
2) 负载均衡
负载均衡指将客户端请求按指定策略分配到不同服务器,以达到平衡负载的效果。Nginx默认支持轮询、加权轮询、IpHash等负载均衡策略,也支持自定义扩展策略,如fair-根据服务器响应时间来均衡负载。
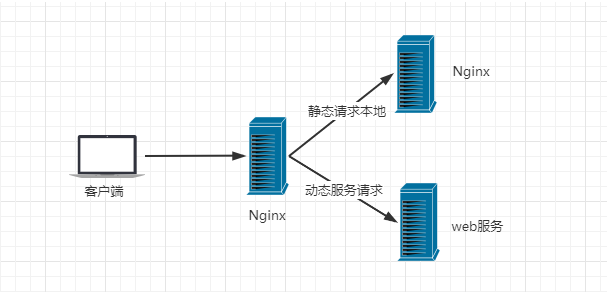
3) 动静分离
动静分离指将静态文件(如css、html、jpg、js等等文件)直接通过nginx返回,不再经过后台处理,提高资源响应的速度。
第二节 安装部署
1. Windows
31- 下载:https://nginx.org/en/download.html # nginx/Windows-1.25.4 2- 启动:./nginx.exe3- 访问:http://localhost:80 # 默认端口为80,如果启动成功,访问时将会出现 Welcome to nginx 提示。
2. Linux
x1# 扩展:一步式安装命令2yum install -y make cmake gcc gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel && wget http://nginx.org/download/nginx-1.25.4.tar.gz && tar zxvf nginx-1.25.4.tar.gz && cd nginx-1.25.4 && ./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --with-file-aio --with-http_realip_module && make && make install && ln -s /usr/local/nginx/sbin/nginx /usr/bin/nginx3
4# 安装依赖库5yum install gcc-c++ # 源码编译使用6yum install -y pcre pcre-devel # Perl库,主要用于解析正则表达式 wget http://downloads.sourceforge.net/project/pcre/pcre/8.37/pcre-8.37.tar.gz7yum install -y zlib zlib-devel # Nginx使用 zlib 对 http 包的内容进行 gzip8yum install -y openssl openssl-devel # 用于支持 https9
10# 下载&解压安装包11https://nginx.org/en/download.html # nginx-1.25.412tar -zxvf nginx-1.25.4.tar.gz13cd nginx-1.25.414
15# 配置&编译&安装16./configure17make18make install # 安装后通过 whereis nginx 查看安装位置19
20# 开机自启21vi /etc/rc.local # 增加一行 /usr/local/nginx/sbin/nginx22chmod 755 /etc/rc.local23
3. 关于防火墙
201# 防火墙服务开启&关闭&重启2service firewalld start3service firewalld stop4service firewalld restart5
6# 查看防火墙规则7firewall-cmd --list-all8
9# 查询端口是否开放10firewall-cmd --query-port=8080/tcp # firwall-cmd是Linux提供操作firewall的一个工具11
12# 开放80端口13firewall-cmd --permanent --add-port=80/tcp # --permanent:表示设置为持久配置14
15# 移除端口16firewall-cmd --permanent --remove-port=8080/tcp17
18#重启防火墙(修改配置后要重启防火墙)19firewall-cmd --reload20
4. 常用命令
201# 启动Nginx2./nginx3
4# 关闭Nginx5nginx -s stop # 快速停止nginx6nginx -s quit # 完整有序的停止nginx7taskkill /f /t /im nginx.exe # 直接杀死进程(仅Windos可用,/f表示强制终止进程,/t表示终止指定的进程和任何由此启动的子进程,/im用于指定的进程名称)8
9# 重新加载配置文件10./nginx -s reload 11
12# 查看nginx进程13ps aux|grep nginx # Linux14
15# 查看nginx端口16 netstat -ntlp | grep nginx17
18# 查看nginx版本号19./nginx -v20
第三节 配置介绍
1. 配置总览
361# 一、全局块:服务器整体运行相关配置2worker_processes 1;3
4# 二、events块:用户网络连接相关选项5events {6 worker_connections 1024;7}8
9# 三、http块:功能模块配置10http {11
12 # http块全局配置13 include mime.types; # 文件扩展名与文件类型映射表14 default_type application/octet-stream; # 访问到未定义的扩展名的时候,就默认为下载该文件15 sendfile on;16 keepalive_timeout 65;17
18 # server块(多个)19 # 一个http块可以包含多个server块,而一个server块就等于一个虚拟主机20 server {21 22 # server块全局配置23 listen 80; # 目前监听的端口号24 server_name notes.huangyuanxin.com; # 主机名称 25 charset utf-8;26
27 # location块(多个)28 location / {29 root /data/notes/;30 autoindex on; 31 }32 33 }34
35}36
2. 全局配置
191# 启动用户2user root;3
4# 设置 worker 数量5# Nginx采用1Master+N*Worker的架构,Worker数一般为CPU数6worker_processes 47# Worker绑定Cpu8worker_cpu_affinity 0001 0010 0100 1000 # 4Worker绑定4Cpu9worker_cpu_affinity 0000001 00000010 00000100 00001000 # 4Worker绑定8Cpu的其中4个10
11# 日志文件12error_log logs/error.log error; # notice、error13
14# 进程文件15pid logs/nginx.pid;16
17# worker 进程的最大文件打开数限制18worker_rlimit_nofile 204800;19
3. Events配置
51# 每个Worker进程所能建立连接的最大值2# 一个Nginx服务器的总连接数为 worker_processes*worker_connections3# 一个静态资源访问请求占用2个连接,一个动态资源访问请求占4个连接4worker_connections 1024;5
4. http块配置
161# 日志格式2log_format main '$remote_addr - $remote_user [$time_local] "$request" '3'$status $body_bytes_sent "$http_referer" '4'"$http_user_agent" "$http_x_forwarded_for"';5
6# 访问日志7access_log logs/access.log main;8
9# 性能优化选项10# Nginx 直接将文件内容发送给客户端,而不需要将文件内容先读入内存再发送。这样可以减少 CPU 和内存的使用,提高文件传输的效率11sendfile on;12# 在 sendfile 打开的状态下才会生效,主要是用来提升网络包的传输效率13tcp_nopush on;14# 在keep-alive连接开启的情况下才生效,来提高网络包传输的实时性15tcp_nodelay on;16
5. server块配置
41# 日志2error_log logs/error.log crit;3access_log logs/access.log main;4
6. location块配置
91# 后缀匹配2location ^~ /baseapp {3 if ($uri ~* \.(html|htm|gif|jpg|jpeg|bmp|png|ico|txt|js|css|tff|woff|swf|svg|xls|xlsx)$) {4 rewrite ^\/baseapp\/(.*)$ /$1;5 root D:\KingDom\web\web\base;6 break;7 }8 rewrite ^\/baseapp\/(.*)$ /$1;9}| 匹配选项 | 含义 |
|---|---|
| = | 普通匹配,当请求URL与字符串完全一致时匹配成功 |
| ~ | 正则匹配,当请求URL包含正则字符串时匹配成功,区分大小写 |
| ~* | 正则匹配,当请求URL包含正则字符串时匹配成功,不区分大小写 |
| ^~ | 普通匹配 |
第四节 配置示例
1. 反向代理配置
181server {2 3 # 监听80端口的http请求(Host=106.53.120.230)4 listen 80;5 server_name 106.53.120.230;6 7 # 转发url与/order/匹配的请求8 location ~ /order/ {9 proxy_pass http://localhost:8001;10 }11 12 # 转发url与/pay/匹配的请求13 location ~ /pay/ {14 proxy_pass http://localhost:8002;15 }16 17}18
2. 负载均衡配置
311http {2
3 # 服务列表,默认为轮询策略4 upstream OrderServer_LX{5 server 106.53.120.230;6 server 106.53.120.231;7 }8 9 # 服务列表,修改为加权轮询策略10 upstream OrderServer_JQLX{11 server 106.53.120.230 weight=10;12 server 106.53.120.231 weight=5;13 }14 15 # 服务列表,修改为 IpHash 策略16 upstream OrderServer_IpHash{17 ip_hash;18 server 106.53.120.230;19 server 106.53.120.231;20 }21 22 server{23 location / {24 # 使用轮询策略转发25 proxy_pass http://OrderServer_LX;26 proxy_connect_timeout 10;27 }28 }29
30}31
3. 动静分离配置
271server {2 listen 80;3 server_name 106.53.120.230;4 charset utf-8;5
6 # 动态资源7 location ~ /order/ {8 # 转发到http://localhost:8001(tomcat)9 proxy_pass http://localhost:8001;10 }11 12 # 静态资源13 location ~ /image/ {14 # 转发到本地/data/目录,可访问/data/image/目录中的文件15 root /data/;16 autoindex on; 17 }18 19 # 静态资源20 location ~ /css/ {21 # 转发到本地/data/目录,可访问/data/css/目录中的文件22 root /data/;23 autoindex on; 24 }25
26}27
4. 高可用主备配置
Nginx可基于KeppAlived进行主备配置,当主服务器不可访问时,备服务器将自动接管虚拟IP,处理接入请求。
1) 安装KeppAlived
31# 安装2yum install keepalived –y3
2) KeepAlived配置
441# 全局配置2global_defs {3 # 告警邮箱配置4 notification_email {5 .loc6 .loc7 .loc8 }9 notification_email_from Alexandre..loc10 smtp_server 192.168.17.129 11 smtp_connect_timeout 30 12 13 # 运行Keepalived的机器的路由标识,主备机应保持一致14 router_id LVS_DEVEL 15}16
17# 状态检查配置18vrrp_script chk_http_port {19
20 # 检查脚本21 script "/usr/local/src/nginx_check.sh"22 23 # 检查间隔(s)24 interval 225 26 # 27 weight 228}29
30# 虚拟服务器配置31vrrp_instance VI_1 {32 state MASTER # 主服务器(MASTER)|备服务器(BACKUP)33 interface ens33 # 网卡34 virtual_router_id 51 # 主、备机的 virtual_router_id 必须相同35 priority 90 # 主、备机取不同的优先级,主机值较大,备份机值较小36 advert_int 137 authentication {38 auth_type PASS39 auth_pass 111140 }41 virtual_ipaddress {42 192.168.17.50 # VRRP H 虚拟地址43 }44}
3) nginx_check.sh
91A=`ps -C nginx –no-header |wc -l`3if [ $A -eq 0 ];then4 /usr/local/nginx/sbin/nginx5 sleep 26 if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then7 killall keepalived8 fi9fi
4)启动测试
101# 启动主服务器和备服务器nginx2./nginx3
4# 启动主服务器和备服务器keepalived5systemctl start keepalived.service6
7# 测试81) 浏览器访问虚拟IP 192.168.17.50 ,路由到主服务器92) 关闭主服务器,备服务器的keepalived收不到主服务器信息时,将会自动选主,成为主服务器103) 继续访问虚拟IP 192.168.17.50,路由到新的主服务器
第五节 其它配置
1. 响应压缩
在http块内或者在单个server块里添加如下配置开启响应压缩:
51gzip on; # 开启压缩响应2gzip_http_version 1.1; # 只针对http1.1进行压缩3gzip_comp_level 9; # 压缩等级为94gzip_types text/plain; # 压缩类型为文本5
然后重载nginx配置文件,在响应报文头中看到 Content-Encoding:gzip 即表示配置成功。
2. 支持HTTPS
首先通过nginx -V确认是否安装SSL模块(–with-http_ssl_module),然后修改配置文件,添加server配置。
691user root;2worker_processes 1;3
4#error_log logs/error.log;5#error_log logs/error.log notice;6#error_log logs/error.log info;7
8events {9 worker_connections 1024;10}11
12
13http {14 include mime.types;15 default_type application/octet-stream;16 sendfile on;17 keepalive_timeout 65;18 #tcp_nopush on;19 #gzip on;20
21 # HTTP server22 server {23 listen 80;24 server_name huangyuanxin.com www.huangyuanxin.com;25 # charset koi8-r;26
27 # 重定向到HTTPS28 return 301 https://$server_name$request_uri;29 }30
31
32 # HTTPS server33 server {34 listen 443 ssl;35 server_name huangyuanxin.com www.huangyuanxin.com;36
37 # SSL证书和私钥路径38 ssl_certificate /usr/local/nginx/conf/cert.pem;39 ssl_certificate_key /usr/local/nginx/conf/cert.key;40
41 # SSL相关配置42 ssl_session_cache shared:SSL:1m;43 ssl_session_timeout 5m;44 ssl_ciphers HIGH:!aNULL:!MD5;45 ssl_prefer_server_ciphers on;46
47 # 静态文件48 location / {49 root /root/htmls;50 index index.html index.htm;51 }52 53 # API接口54 location ~/api/notes/ {55 proxy_pass https://localhost:8001;56 }57 location ~/api/ai/ {58 proxy_pass https://localhost:9001;59 }60
61 # 错误页面62 error_page 500 502 503 504 /50x.html;63 location = /50x.html {64 root html;65 }66 }67
68}69
3. 路径重写
在Nginx中,可以使用rewrite指令进行URL路径的重写:
141server {2 listen 80;3 server_name example.com;4 5 location /oldpath/ {6 # 将所有以/oldpath/开头的URL重定向到以/newpath/开头的URL7 # last 表示完成rewrite步骤,并继续在新的URI上执行location匹配8 rewrite ^/oldpath/(.*)$ /newpath/$1 last;9 }10 11 location /newpath/ {12 # 这里是处理新路径的配置13 }14}如果你想要内部重定向而不改变浏览器的URL,可以使用internal标识符:
121server {2 listen 80;3 server_name example.com;4 5 location /oldpath/ {6 rewrite ^/oldpath/(.*)$ /newpath/$1 internal;7 }8 9 location /newpath/ {10 # 这里是处理新路径的配置11 }12}这样,重写操作对用户来说是透明的,浏览器的地址栏不会显示新的URL路径。
第六节 常用插件
Nginx 的插件主要分为以下几类:
1. HTTP 模块插件
HTTP 模块插件扩展了 Nginx 的 HTTP 功能,包括添加新的 HTTP 模块、自定义请求处理流程等。
ngx_http_rewrite_module
提供 URL 重写功能,可以实现 URL 的重定向、重写等操作。
71server {2 ...3 location / {4 rewrite ^/old-url$ /new-url permanent;5 }6 ...7}ngx_http_access_module
提供访问控制功能,可以限制特定 IP 或者网络的访问。
81server {2 ...3 location / {4 deny 192.168.1.1;5 allow all;6 }7 ...8}
2. 过滤器插件
过滤器插件对请求和响应进行过滤和处理,如压缩、重写、限速等。
ngx_http_gzip_module
提供 Gzip 压缩功能,可以减小 HTTP 响应的大小,加快页面加载速度。
61http {2 ...3 gzip on;4 gzip_types text/plain text/css application/json;5 ...6}ngx_http_ssl_module
提供 SSL/TLS 加密功能,可以保护 HTTP 通信的安全性。
71server {2 ...3 listen 443 ssl;4 ssl_certificate /path/to/cert.pem;5 ssl_certificate_key /path/to/key.pem;6 ...7}
3. 负载均衡插件
负载均衡插件实现了负载均衡功能,将请求分发到多个后端服务器,实现高可用性和性能的提升。
ngx_http_upstream_module
提供负载均衡功能。
151http {2 ...3 upstream backend {4 server 127.0.0.1:8080;5 server 127.0.0.1:8081;6 }7 server {8 ...9 location / {10 proxy_pass http://backend;11 }12 ...13 }14 ...15}ngx_http_upstream_ip_hash_module
提供 IP 地址哈希负载均衡功能,将同一 IP 的请求分发到同一个后端服务器。
91http {2 ...3 upstream backend {4 ip_hash;5 server 192.168.1.10;6 server 192.168.1.11;7 }8 ...9}
4. 安全插件
安全插件增强了 Nginx 的安全性,包括防火墙、反爬虫、反盗链等功能。
ngx_http_limit_req_module
提供请求速率限制功能,可以防止恶意请求对服务器造成过载。
121http {2 ...3 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;4 server {5 ...6 location / {7 limit_req zone=one burst=5;8 }9 ...10 }11 ...12}ngx_http_limit_conn_module
提供连接数限制功能,可以限制每个 IP 的并发连接数。
121http {2 ...3 limit_conn_zone $binary_remote_addr zone=addr:10m;4 server {5 ...6 location / {7 limit_conn addr 5;8 }9 ...10 }11 ...12}
5. 插件的安装和配置
下面以stub_status模块为例,简要说明Nginx插件的安装和配置:
151# 1. 查看插件是否已安装2./nginx -v 2>&1|grep stub_status 3
4# 2. 配置编译参数(在原来的参数上加 --with-http_stub_status_module)5./configure --prefix=/usr/local/nginx --pid-path=/var/local/nginx/nginx.pid --lock-path=/var/local/nginx/nginx.lock --error-log-path=/var/local/nginx/error.log --http-log-path=/var/local/nginx/access.log --with-http_gzip_static_module --with-http_stub_status_module --http-client-body-temp-path=/var/local/nginx/client --http-proxy-temp-path=/var/local/nginx/proxy --http-fastcgi-temp-path=/var/local/nginx/fastcgi --http-uwsgi-temp-path=/var/local/nginx/uwsgi --http-scgi-temp-path=/var/local/nginx/scgi6
7# 3. 备份原nginx命令8cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak9
10# 4. 编译11make12
13# 5. 替换掉原来的二进制nginx文件14cp /root/wr/nginx-1.20.2/objs/nginx /usr/local/nginx/sbin/15
stub_status模块主要用于实现监控功能,简单配置如下:
51# server块2location /nginx_status {3 stub_status;4 allow all;5}最后重载配置文件,访问 http://主机地址/nginx_status 即可测试。
11./nginx -s reload
第02章_ZooKeeper
第一节 ZooKeeper简介
1. 什么是ZooKeeper?
ZooKeeper 是一个基于观察者模式设计的开源分布式协调服务,它负责存储和管理大家都关心的数据,一旦这些数据发生变化,便会通知相应的观察者做出响应。
它数据模型结构如下,和Unix文件系统非常相似:
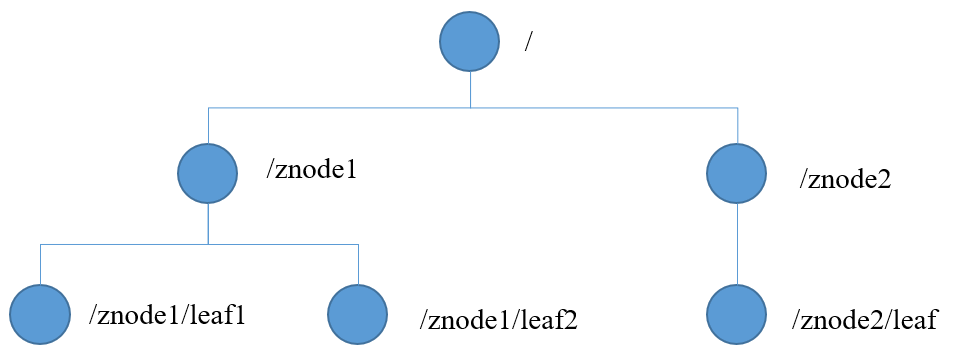
其中每个节点称为ZNode,可以通过其路径唯一标识,并存储不超过 1MB 的数据。
2. 基本特性
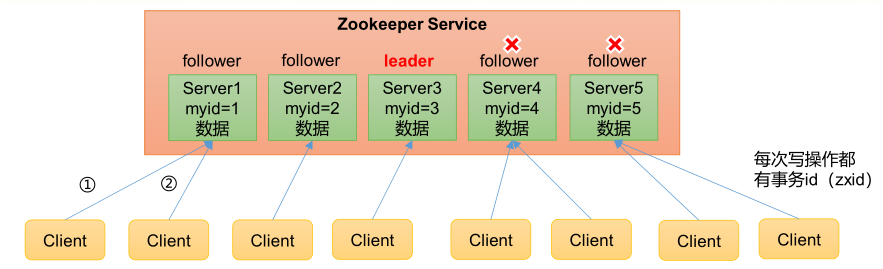
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
2)集群中只要有 半数以上 节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
3)全局数据一致:每个 Server 保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个 Client 的更新请求按其发送顺序依次执行。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据。
3. 选举机制
1) 第一次启动时
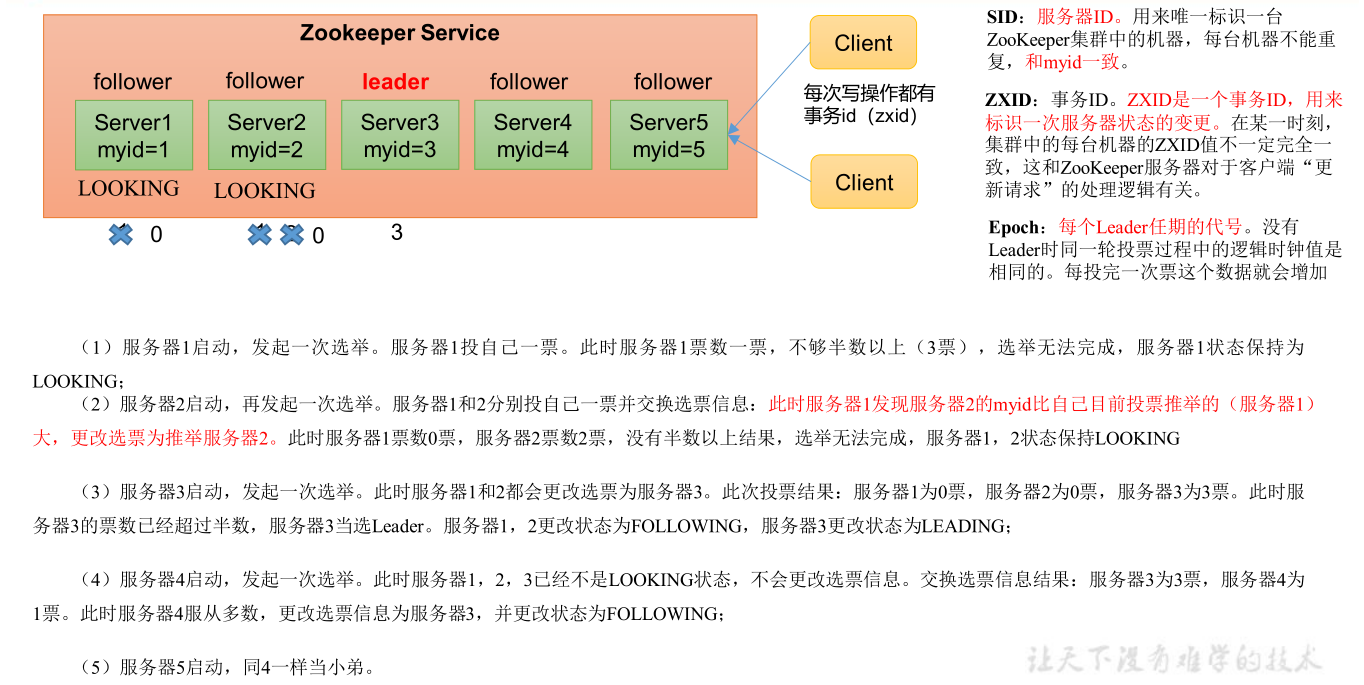
总结:投票过半数时,服务器 id 大的胜出
2) 非第一次启动时
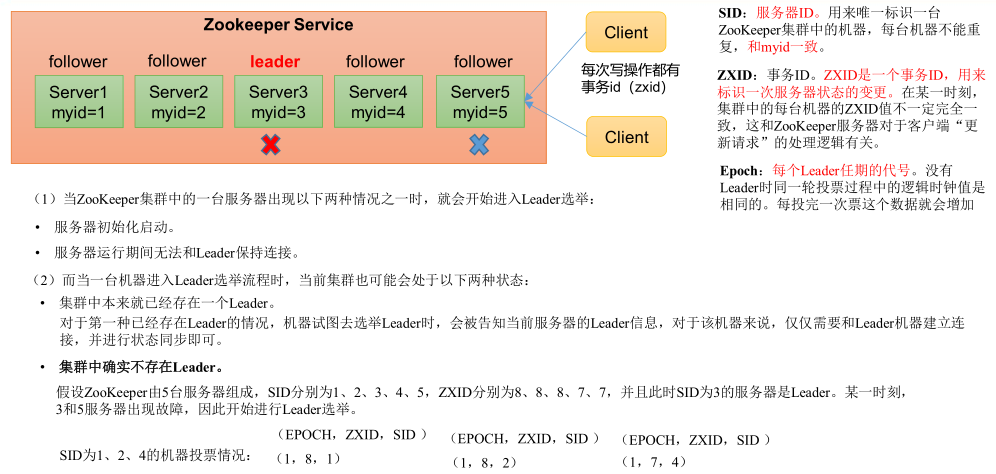
总结: ①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出
4. 应用场景
Zookeeper 提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线(注册中心)、软负载均衡等。
1) 统一命名服务

2) 统一配置管理
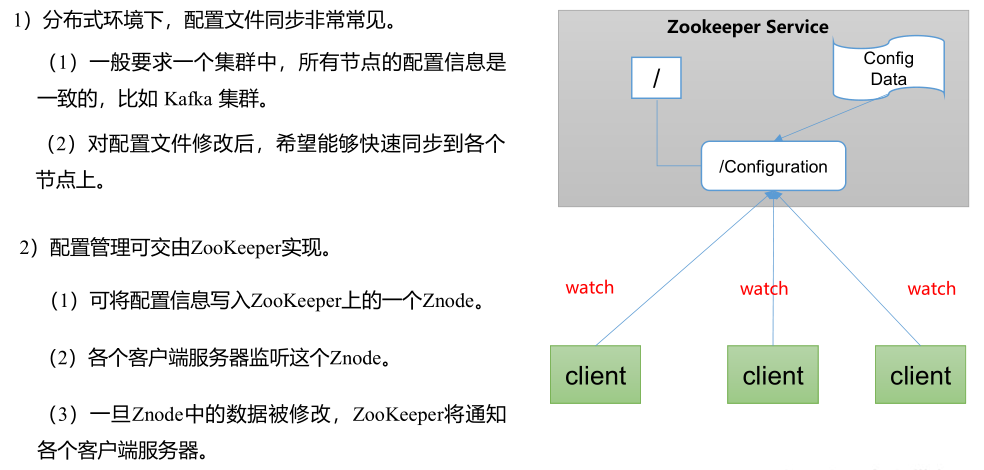
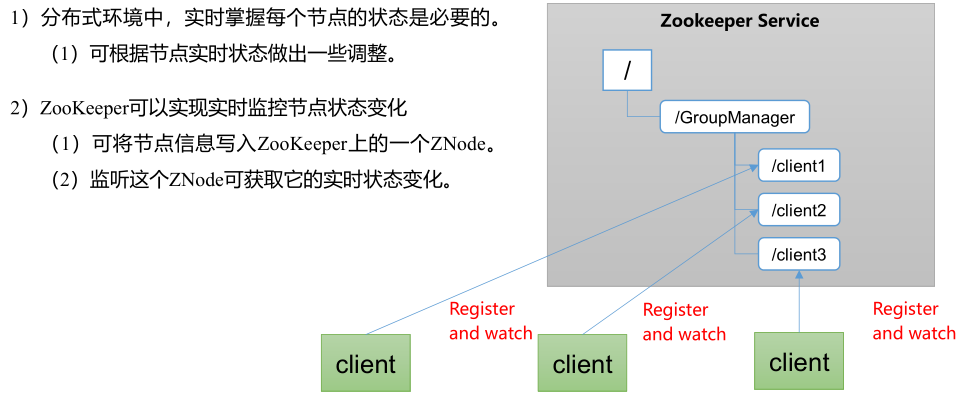
3) 统一集群管理
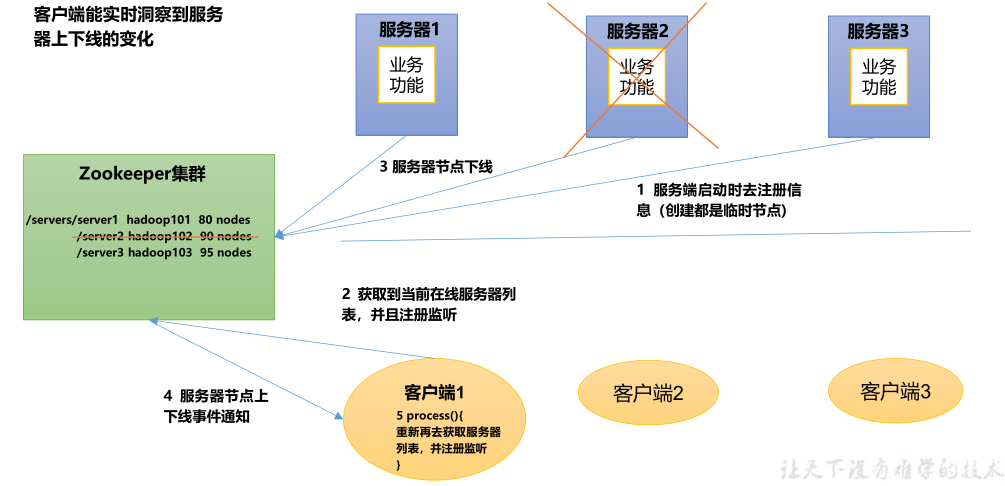
4) 注册中心
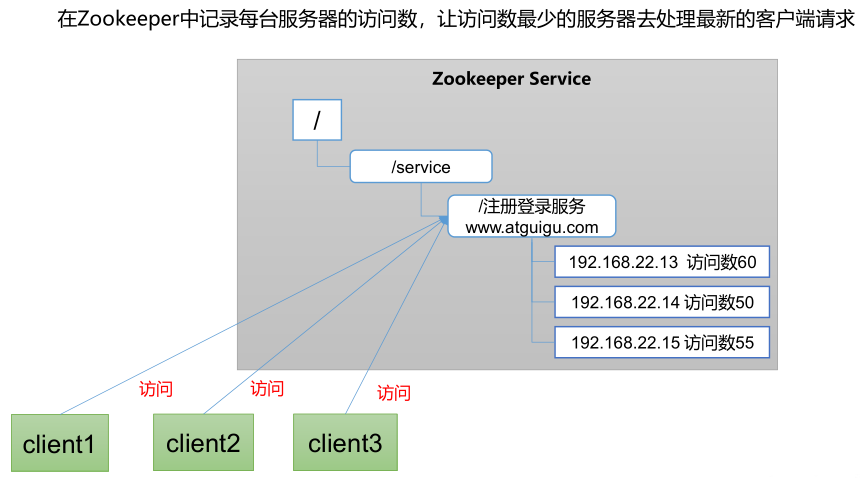
5) 负载均衡
第二节 安装部署
1. 集群部署
ZooKeeper一般部署为集群模式,且节点数为奇数,如3或5台等,当整个集群中有半数以上的节点存活时,那么整个集群环境才可用。
服务器台数多:好处,提高可靠性;坏处:提高通信延时。

为什么ZooKeeper集群一般为奇数个节点呢?
答:因为ZooKeeper集群选举leader时,必须要求半数以上的节点通过(不包含半数),因此3台和2台服务器都是要求至少2台可用,整个集群才可用,以防止“脑裂”现象,同理,5台和4台也是类似情况。
1) 前置准备
181# 1. 安装JDK2https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html3
4# 2. 下载zookpper5https://zookeeper.apache.org/releases.html6http://mirror.bit.edu.cn/apache/zookeeper/7
8# 3. 上传和解压安装包9mkdir /usr/local/zookpper10tar -zxvf zookeeper-3.4.12.tar.gz11
12# 4. 创建data和logs目录13mkdir /usr/local/zookeeper/zookeeper-3.4.12/data14mkdir /usr/local/zookeeper/zookeeper-3.4.12/logs15
16# 5. 拷贝配置模板17cp ./conf/zoo_sample.cfg ./conf/zoo.cfg 18
2) 配置zoo.cfg
221# 通信心跳时间(毫秒)2tickTime=20003# Leader和Follower初始连接时能容忍的最多心跳数4initLimit=105# Leader和Follower数据同步时能容忍的最多心跳数(如果超过,则认为Follwer死掉,将其剔除)6syncLimit=57
8# 数据存储目录及日志保存目录(如果没有指明dataLogDir,则日志也保存到这个文件夹中)9dataDir=/usr/local/zookeeper/zookeeper-3.4.12/data10dataLogDir=/usr/local/zookeeper/zookeeper-3.4.12/logs11
12# 管理服务端端口13admin.serverPort=888814# 客户端连接的端口15clientPort=218116
17# 集群配置18# server.服务器编号=服务器IP:Zookeeper服务器之间的通信端口:Leader选举的端口19server.0=10.0.0.116:2888:388820server.1=10.0.0.117:2888:388821server.2=10.0.0.118:2888:388822
3) 创建myid文件
21cd /usr/local/zookeeper/zookeeper-3.4.12/data # 必须配置在 dataDir 目录2echo 0 > myid # 服务器编号,在集群中唯一,与服务器IP相对应
4) 设置环境变量
修改用户启动配置文件:vim ~/.bash_profile,然后重新加载:source ~/.bash_profile。
21export ZK_HOME=/usr/local/software/zookeeper-3.4.122export PATH=$PATH:$ZK_HOME/bin
5) 设置开机启动
在cd /etc/rc.d/init.d目录创建zookeeper服务:vim zookeeper,并授权:chmod +x /etc/rc.d/init.d/zookeeper。
71#chkconfig: 2345 10 903#description: service zookeeper4export JAVA_HOME=/usr/local/jdk1.8.0_1915export ZOO_LOG_DIR=/opt/zookeeper/log6ZOOKEEPER_HOME=/usr/local/zookeeper-cluster/zookeeper-3.4.12/7su root ${ZOOKEEPER_HOME}/bin/zkServer.sh "$1"然后添加到开机启动项:chkconfig --add zookeeper,可通过chkconfig --list查看是否添加成功。
最后,可以通过reboot命令重启机器,查看zookeeper是否开机启动:service zookeeper status。
注意:若出现“服务 zookeeper 不支持 chkconfig”错误,请检查
/etc/init.d/zookeeper文件的内容。
2. ZooKeeper启停
151# 启动2zkServer.sh start3
4# 停止5zkServer.sh stop6
7# 重启服务8zkServer.sh restart9
10# 查看节点状态11[root@loaclhost ~]# zkServer.sh status12ZooKeeper JMX enabled by default13Using config: /usr/local/zookeeper-cluster/zookeeper-3.4.12/bin/../conf/zoo.cfg14Mode: leader15
注意:如果查看ZK状态时发现ZK不在运行中,先使用
`./zkServer.sh start-foreground查看启动报错信息。
3. 连接ZooKeeper
141# 连接到ZK2zkCli.sh -server 127.0.0.1:21813
4# 测试如下5--------------------------------------------6[zk: 127.0.0.1:2181(CONNECTED) 4] create /test7Created /test8[zk: 127.0.0.1:2181(CONNECTED) 5] ls /9[test, zookeeper]10--------------------------------------------11
12# 退出13quit14
第三节 客户端命令
1. 查询命令
131# 查看节点2ls /3ls /狗狗/边牧 # 查询节点4ls -R / # 递归查询节点5ls -s /猩猩 # 查询节点的详细信息6stat /猩猩 # 查看节点状态7
8# 查看节点值9get /骆驼10get -s /猩猩 # 查询节点的详细信息11get -w /猩猩 # 监听节点的详细信息(注意:注册一次只能监听一次,想再次监听,需要再次注册)12ls -w /猩猩 # 监听节点的详细信息(注意:注册一次只能监听一次,想再次监听,需要再次注册)13
2. 修改命令
161# 创建节点2create /狗狗3create /狗狗/边牧4create -s /bb/bb1 # 序列节点5create -e /cc # 临时节点 在会话结束后,自动被删除(通过这个特性,zk可以实现服务注册与发现的效果)6create -e -s /dd # 临时序列节点7create \[-s\] \[-e\] path data acl # 创建权限节点8
9# 删除节点10delete /aa # 下面没有子节点的,可以直接用 delete11deleteall /手机 # 下面有子节点的,用 deleteall12
13# 设置节点值14set /猩猩 园外区3号15create /骆驼 园区2号 # 创建节点并写入值16
3. 其它命令
71# 查看帮助2help3
4# 添加认证用户5addauth digest maidou # 不带密码6addauth digest beita:123456 # 带密码7
第四节 客户端API
1. 基础案例
431public class ZkApiTest {2 public static void main(String[] args) throws IOException, KeeperException, InterruptedException {3
4 // 建立连接5 // 参数1:连接字符串(支持以逗号分隔配置多个,随机进行连接)6 // 参数2:会话超时时间7 // 参数3:监听器8 // 其它参数:是否只读、密码等9 ZooKeeper zooKeeper = new ZooKeeper("10.210.5.252:2181", 1000 * 60, null);10
11 // 创建节点12 // 参数1:节点路径13 // 参数2:节点数据14 // 参数3:权限控制,一般是无权限控制,即ZooDefs.Ids.OPEN_ACL_UNSAFE15 // 参数4:节点类型,可选 PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL 等16 zooKeeper.create("/test", "test ok!".getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);17
18 // 查询子节点19 List<String> children = zooKeeper.getChildren("/", null);20 System.out.println("子节点:" + children);21
22 // 判断节点是否存在23 Stat existStat = zooKeeper.exists("/test", null);24 System.out.println(existStat != null ? "节点存在" : "节点不存在");25
26 // 查询节点数据27 Stat stat = new Stat();28 byte[] data = zooKeeper.getData("/test", false, stat);29 System.out.println("当前事务ID:" + stat.getCzxid());30 System.out.println("当前节点数据:" + new String(data));31
32 // 修改节点数据33 Stat updatestat = zooKeeper.setData("/test", "new-data".getBytes(), -1);34 System.out.println("当前事务ID:" + updatestat.getCzxid());35
36 // 删除节点37 zooKeeper.delete("/test", -1);38
39 // 关闭连接40 zooKeeper.close();41 }42}43
注意:
ZooKeeper集群中,只有 Leader 有权限发起数据修改操作,如果向 Follower 发起修改请求,则会转给 Leader 处理。
2. 实现注册中心
1) 服务注册
231public class DistributeServer {2 private static ZooKeeper zk = null;3 private static String parentNode = "/test";4 private static String serverNode = "/server01";5
6 public static void main(String[] args) throws Exception {7 // 1. 连接到ZK8 zk = new ZooKeeper("10.210.5.252:2181", 1000 * 60, new9 Watcher() {10 11 public void process(WatchedEvent event) {12 }13 });14
15 // 2. 注册服务(临时节点)16 zk.create(parentNode + serverNode, serverNode.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);17
18 // 3. 执行业务代码19 System.out.println("server01 is working ...");20 Thread.sleep(Long.MAX_VALUE);21 }22}23
2) 服务监听
471public class DistributeClient {2 private static ZooKeeper zk = null;3 private static String parentNode = "/test";4
5 public static void main(String[] args) throws Exception {6 // 1. 连接到ZK7 zk = new ZooKeeper("10.210.5.252:2181", 1000 * 60, new8 Watcher() {9 10 public void process(WatchedEvent event) {11 try {12 // 再次启动监听13 watchServerList();14 } catch (Exception e) {15 e.printStackTrace();16 }17 }18 });19
20 // 2. 监听当前在线服务21 watchServerList();22
23 // 3. 执行业务代码24 System.out.println("client is working ...");25 Thread.sleep(Long.MAX_VALUE);26 }27
28
29 // 监听当前在线服务30 public static void watchServerList() throws KeeperException, InterruptedException {31 List<String> servers = new ArrayList<>();32
33 // 1. 查询 /test 的子节点,并监听 /test 节点34 List<String> children = zk.getChildren(parentNode, true);35
36 // 2. 查询子节点信息37 for (String child : children) {38 String childNode = parentNode + "/" + child;39 byte[] data = zk.getData(childNode, false, null);40 servers.add(childNode + ":" + new String(data));41 }42
43 // 3. 打印44 System.out.println("servers = " + servers);45 }46 47}
3) 测试
101操作步骤:21> 启动客户端进行“服务监听”32> 启动服务端进行“服务注册”43> 关闭服务端模拟”服务关闭“5客户端控制台打印:7servers = []8servers = [/test/server010000000011:/server01]9servers = []10
3. 实现分布式锁
1) 原生方式
1741// 分布式锁实现2public class DistributedLock {3
4 // ZK连接5 private ZooKeeper zk;6
7 // 连接信息8 private String connectString = "10.210.5.252:2181";9 private int sessionTimeout = 1000 * 60;10
11 // 根节点、子节点前缀12 private String rootNode = "locks";13 private String subNode = "seq-";14
15 // 当前节点(等待锁或持有锁)16 private String currentNode;17
18 // 前置节点(当前节点等待的节点)19 private String waitPath;20
21 // 线程协作工具22 private CountDownLatch waitLatch = new CountDownLatch(1);23
24 // 和 zk 服务建立连接,并创建根节点25 public DistributedLock() throws IOException, InterruptedException, KeeperException {26 CountDownLatch connectLatch = new CountDownLatch(1);27
28 // 连接到ZK29 zk = new ZooKeeper(connectString, sessionTimeout, new30 Watcher() {31 32 public void process(WatchedEvent event) {33 // 连接建立时, 打开 latch, 唤醒 wait 在该 latch 上的线程34 if (event.getState() == Event.KeeperState.SyncConnected) {35 connectLatch.countDown();36 }37
38 // 发生了 waitPath 的删除事件39 if (event.getType() == Event.EventType.NodeDeleted && event.getPath().equals(waitPath)) {40 waitLatch.countDown();41 }42 }43 });44
45 // 等待连接建立46 connectLatch.await();47
48 //获取根节点状态49 Stat stat = zk.exists("/" + rootNode, false);50
51 //如果根节点不存在,则创建根节点,根节点类型为永久节点52 if (stat == null) {53 System.out.println("根节点不存在");54 zk.create("/" + rootNode, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);55 }56 }57
58 // 加锁方法59 public void zkLock() {60 try {61 // 在根节点下创建临时顺序节点,返回值为创建的节点路径62 currentNode = zk.create("/" + rootNode + "/" + subNode, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);63
64 // wait 一小会, 让结果更清晰一些65 Thread.sleep(10);66
67 // 查询所有子节点68 // 注意:没有必要监听 /locks 的子节点的变化情况69 List<String> childrenNodes = zk.getChildren("/" + rootNode, false);70
71 // 如果列表中只有一个子节点, 那肯定就是 currentNode , 说明 client 获得锁72 if (childrenNodes.size() == 1) {73 return;74 }75
76 // 对子节点进行排序(从小到大)77 Collections.sort(childrenNodes);78
79 // 获取当前节点的位置80 String thisNode = currentNode.substring(("/" + rootNode + "/").length());81 int index = childrenNodes.indexOf(thisNode);82
83 // 如果未找到当前节点,则为数据异常84 if (index == -1) {85 throw new RuntimeException("数据异常");86 }87
88 // 如果thisNode 在列表中最小, 当前 client 获得锁89 if (index == 0) {90 return;91 }92
93 // 获得前置节点(当前节点的前1节点)94 this.waitPath = "/" + rootNode + "/" + childrenNodes.get(index - 1);95
96 // 在前置节点上注册监听器,97 // 当前置节点被删除时, zookeeper 会回调监听器的 process 方法98 zk.getData(waitPath, true, new Stat());99
100 // 等待前置节点被回调101 waitLatch.await();102
103 } catch (KeeperException | InterruptedException e) {104 e.printStackTrace();105 }106 }107
108 // 解锁方法109 public void zkUnlock() {110 try {111 zk.delete(this.currentNode, -1);112 } catch (InterruptedException | KeeperException e) {113 e.printStackTrace();114 }115 }116
117}118
119// 分布式锁测试120public class DistributedLockTest {121
122 // 测试123 public static void main(String[] args) throws InterruptedException, IOException, KeeperException {124
125 // 创建2个分布式锁126 final DistributedLock lock1 = new DistributedLock();127 final DistributedLock lock2 = new DistributedLock();128
129 // 线程1130 new Thread(new Runnable() {131 132 public void run() {133 try {134 lock1.zkLock();135 System.out.println("线程 1 获取锁");136
137 // 执行业务138 Thread.sleep(5 * 1000);139
140 lock1.zkUnlock();141 System.out.println("线程 1 释放锁");142 } catch (Exception e) {143 e.printStackTrace();144 }145 }146 }).start();147
148 // 线程2149 new Thread(new Runnable() {150 151 public void run() {152 try {153 lock2.zkLock();154 System.out.println("线程 2 获取锁");155
156 // 执行业务157 Thread.sleep(5 * 1000);158
159 lock2.zkUnlock();160 System.out.println("线程 2 释放锁");161 } catch (Exception e) {162 e.printStackTrace();163 }164 }165 }).start();166 }167}168
169// 结果打印170线程 2 获取锁171线程 2 释放锁172线程 1 获取锁173线程 1 释放锁174
2) Curator 方式
首先需导入 Curator 相关依赖:
161<!-- curator -->2<dependency>3 <groupId>org.apache.curator</groupId>4 <artifactId>curator-framework</artifactId>5 <version>4.3.0</version>6</dependency>7<dependency>8 <groupId>org.apache.curator</groupId>9 <artifactId>curator-recipes</artifactId>10 <version>4.3.0</version>11</dependency>12<dependency>13 <groupId>org.apache.curator</groupId>14 <artifactId>curator-client</artifactId>15 <version>4.3.0</version>16</dependency>然后创建一个可重入锁并测试:
951public class CuratorLockTest {2 private String connectString = "10.210.5.252:2181";3 private String rootNode = "/locks";4 private int connectionTimeout = 1000 * 60;5 private int sessionTimeout = 1000 * 60;6
7 // 测试8 public static void main(String[] args) {9 new CuratorLockTest().test();10 }11
12 // 测试13 private void test() {14 // 创建两个分布式锁15 final InterProcessLock lock1 = new InterProcessMutex(getCuratorFramework(), rootNode);16 final InterProcessLock lock2 = new InterProcessMutex(getCuratorFramework(), rootNode);17
18 // 线程119 new Thread(new Runnable() {20 21 public void run() {22 try {23 lock1.acquire();24 System.out.println("线程 1 获取锁");25
26 lock1.acquire();27 System.out.println("线程 1 再次获取锁");28
29 // 执行业务30 Thread.sleep(3 * 1000);31
32 lock1.release();33 System.out.println("线程 1 释放锁");34
35 lock1.release();36 System.out.println("线程 1 再次释放锁");37 } catch (Exception e) {38 e.printStackTrace();39 }40 }41 }).start();42
43 // 线程244 new Thread(new Runnable() {45 46 public void run() {47 try {48 lock2.acquire();49 System.out.println("线程 2 获取锁");50
51 lock2.acquire();52 System.out.println("线程 2 再次获取锁");53
54 // 执行业务55 Thread.sleep(5 * 1000);56
57 lock2.release();58 System.out.println("线程 2 释放锁");59
60 lock2.release();61 System.out.println("线程 2 再次释放锁");62 } catch (Exception e) {63 e.printStackTrace();64 }65 }66 }).start();67 }68
69 // 分布式锁初始化70 public CuratorFramework getCuratorFramework() {71 // 重试策略,初试时间 3 秒,重试 3 次72 RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);73
74 //通过工厂创建 Curator75 CuratorFramework client = CuratorFrameworkFactory.builder()76 .connectString(connectString)77 .connectionTimeoutMs(connectionTimeout)78 .sessionTimeoutMs(sessionTimeout)79 .retryPolicy(policy).build();80
81 //开启连接82 client.start();83 return client;84 }85}86
87// 结果打印88线程 1 获取锁89线程 1 再次获取锁90线程 1 释放锁91线程 1 再次释放锁92线程 2 获取锁93线程 2 再次获取锁94线程 2 释放锁95线程 2 再次释放锁提示:
更多 Curator 框架的用法请参考:https://curator.apache.org/index.html
第03章_Kafka
第一节 Kafka简介
1. 什么是Kafka?
Kafka是一个基于 Scala 语言开发的分布式消息队列(Message Queue),也称作分布式事件流平台(Event Streaming Platform)。
它支持如下两种模式:
点对点模式:一对一,消费者主动拉取数据,消息收到后消息清除。
发布/订阅模式:一对多,数据生产后,分类推送给所有订阅者。
主要的功能如下:
数据存储:持久化队列中的数据,直到被消费完成。
业务解耦:解耦生产者和消费者,两者只需通过消息队列进行通信和协作。
削峰填谷:缓和突发流量,不会因为突发的超负荷的请求而全线崩溃。
异步处理:消息先放在消息队列,在需要的时候或通过其它线程进行处理。
速率控制:控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
顺序保证:同一 Partition 内,消息可以保证有序被消费。
可扩展性:方便的增加或减少生产者或消费者的数量。
可恢复性:未处理的消息会暂存在消息队列,组件崩溃恢复后仍可继续处理,不会影响整个系统。
2. 基础架构
Kafka的基础架构图如下:
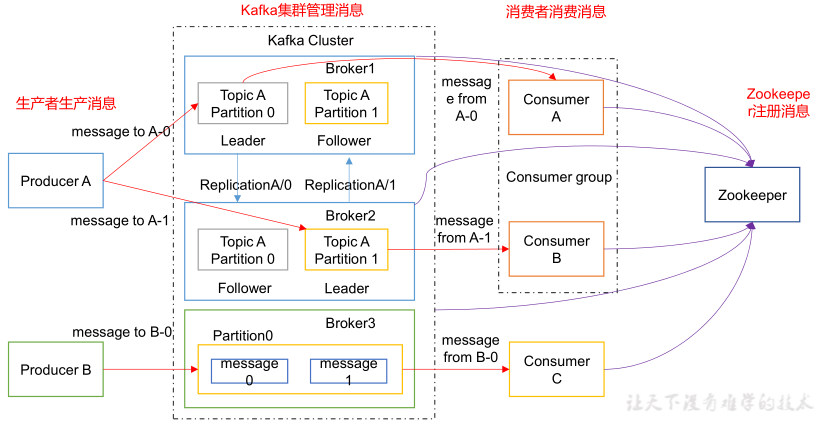
服务器(Broker):一台 kafka 服务器就是一个 broker,一个集群由多个 broker 组成。
主题(Topic) :一个 broker 可以容纳多个 topic(主题可以理解为消息队列)。
分区(Partition):一个 topic 可以细分为多个 partition,不同 partition 可以分布在不同 broker 上( num.partitions)。
副本(Replication):一个 partition 可能有多个 replication,以保证分区数据的高可用(default.replication.factor)。
偏移量(Offset):每个 partition 是一个有序的队列,其中的每条消息都会被分配一个 offset。
生产者(Producer):向 broker 发送消息的客户端,可以指定 topic 和 partition 进行发送。
消费者(Consumer):接收 broker 消息的客户端,在同一 partition 的消息可以按序接收。
消费者组(Consumer Group):用于实现广播(消息发送给关注该topic的所有消费者)和单播(只发给某一消费者)的一种手段。
第二节 安装部署
1. 集群部署
221# 1. 安装JDK2https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html3
4# 2. 下载Kafka5http://kafka.apache.org/downloads.html6
7# 3. 上传和解压安装包8mkdir /usr/local/kafka9tar -zxvf kafka_2.12-3.9.0.tgz10
11# 4. 创建logs目录12mkdir /usr/local/kafka/kafka_2.12-3.9.0/logs13
14# 5. 修改Broker配置文件15vi config/server.properties16
17# 6. 配置环境变量18vim /etc/profile19export KAFKA_HOME=/usr/local/kafka/kafka_2.12-3.9.020export PATH=$PATH:$KAFKA_HOME/bin21source /etc/profile22
2. 配置 server.properties
331# 【重要】broker编号(不同服务器编号必须不同)2broker.id=03
4# 【重要】监听端口5listeners=PLAINTEXT://主机名:90926
7# 支持删除主题8delete.topic.enable=true9
10# 处理网络请求的线程数量11num.network.threads=312# 用来处理磁盘 IO 的线程数量13num.io.threads=814# 发送套接字的缓冲区大小15socket.send.buffer.bytes=10240016# 接收套接字的缓冲区大小17socket.receive.buffer.bytes=10240018# 请求套接字的缓冲区大小19socket.request.max.bytes=10485760020
21# 【重要】运行日志存放的路径 22log.dirs=/usr/local/kafka/kafka_2.12-3.9.0/logs23
24# 主题在当前机器上的分区个数25num.partitions=126# 用来恢复和清理 data 下数据的线程数量27num.recovery.threads.per.data.dir=128# segment 文件保留的最长时间,超时将被删除29log.retention.hours=16830
31# 【重要】ZK地址(以逗号分隔)32zookeeper.connect=127.0.0.1:2181,127.0.0.2:2181,127.0.0.3:218133
3. 启停命令
131# 授权2cd /usr/local/kafka/kafka_2.12-3.9.0/bin3chmod +x *.sh4
5# ZK启动(可能需要)6./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties7
8# Kafka启动9./bin/kafka-server-start.sh -daemon ./config/server.properties10
11# 关闭12./bin/kafka-server-stop.sh stop13
4. 配置开机自启
新建vim /etc/systemd/system/kafka.service文件,内容如下:
151[Unit]2Description=Apache Kafka Server3After=network.target4
5[Service]6Type=simple7User=kafka8Group=kafka9ExecStart=/usr/local/kafka/kafka_2.12-3.9.0/bin/kafka-server-start.sh /usr/local/kafka/kafka_2.12-3.9.0/server.properties10ExecStop=/usr/local/kafka/kafka_2.12-3.9.0/bin/kafka-server-stop.sh /usr/local/kafka/kafka_2.12-3.9.0/server.properties11Restart=on-failure12
13[Install]14WantedBy=multi-user.target15
设置开机自启:
91# 开启服务2sudo systemctl start kafka3
4# 开机自启5sudo systemctl enable kafka6
7# 查看服务状态8sudo systemctl status kafka9
5. 常用命令行操作
1) 主题相关操作
251# 查看主题操作文档2# --bootstrap-server ip/host:port 连接到哪个Broker3# --list 查看所有主题 4# --describe/create/delete/alter/ 查看/创建/删除/修改主题5# --topic topic_name 操作的主题6# --partitions partition_num 设置分区数7# --replication-factor replication_num 设置分区副本数8# --config name=value 修改系统默认的配置9bin/kafka-topics.sh10
11# 查看所有主题12bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list13
14# 查看主题详情15bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first16
17# 创建主题18bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first19
20# 删除主题21bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first22
23# 增加主题分区数(注意:分区数只能增加,不能减少)24bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 325
注意:
在低版本中,查看所有主题需使用
./kafka-topics.sh --zookeeper <ZOOKEEPER_ADDRESS> --list命令,其它同理。
2) 生产者相关操作
91# 查看生产者操作文档2# --bootstrap-server ip/host:port 连接到哪个Broker3# --topic topic_name 操作的主题4bin/kafka-console-producer.sh5
6# 向指定主题发送消息7bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first8>hello world9
3) 消费者相关操作
131# 查看消费者操作文档2# --bootstrap-server ip/host:port 连接到哪个Broker3# --topic topic_name 操作的主题4# --from-beginning 从头开始消费5# --group consumer_group_id 指定消费者组名称6bin/kafka-console-consumer.sh7
8# 消费指定主题中的数据9bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first10
11# 从头消费指定主题中的数据(包括之前已消费过的历史数据)12bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first13
4) 副本相关操作
251# 增加副本因子2vim increase-replication-factor.json3输入:4{5 "version":1,6 "partitions":[7 {"topic":"four","partition":0,"replicas":[0,1,2]},8 {"topic":"four","partition":1,"replicas":[0,1,2]},9 {"topic":"four","partition":2,"replicas":[0,1,2]}]10}11bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute12
13# 调整分区副本存储14vim increase-replication-factor.json15输入:16{17 "version":1,18 "partitions":[{"topic":"three","partition":0,"replicas":[0,1]},19 {"topic":"three","partition":1,"replicas":[0,1]},20 {"topic":"three","partition":2,"replicas":[1,0]},21 {"topic":"three","partition":3,"replicas":[1,0]}]22}23bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute24bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify25
5) Kafka压测操作
171# 生产者压测2bin/kafka-producer-perf-test.sh 3 --topic test 4 --record-size 1024 # 一条信息有多大,单位是字节,本次测试设置为 1k5 --num-records 1000000 # 总共发送多少条信息,本次测试设置为 100 万条6 --throughput 10000 # 每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据7 --producer-props # 生产者参数设置8 bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:90929 batch.size=16384 linger.ms=010
11# 消费者压测12bin/kafka-consumer-perf-test.sh 13 --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 14 --topic test 15 --messages 1000000 # 要消费的消息个数16 --consumer.config config/consumer.properties17
第三节 生产者
1. 消息发送流程
生产者采用推(push)模式将消息发送到 broker ,具体存储于哪个分区可由生产者指定(指定分区或指定Hash Key)或轮询选出。
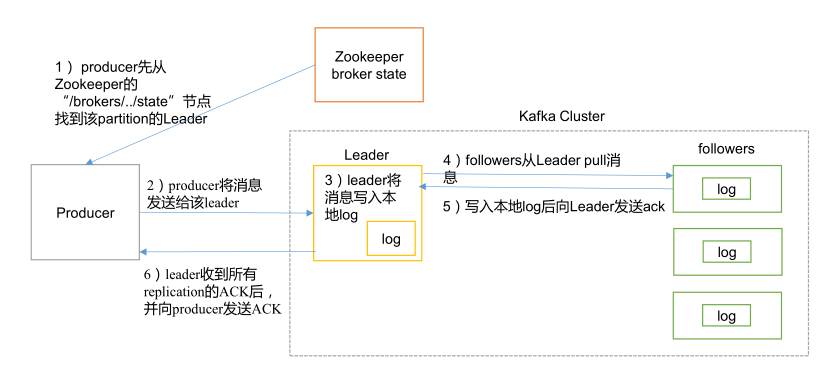
注意:
分区数据始终先由 Leader 写入磁盘,然后复制给其它 follower 副本。
2. 生产者参数配置
| 参数名称 | 参数说明 |
|---|---|
bootstrap.servers | 建立连接用到的Broker列表,以逗号分隔,如:10.201.65.21:9092,10.201.65.22:9092,10.201.65.23:9092; |
| key.serializer | 发送消息时 Key 的序列化器(全类名形式) |
| value.serializer | 发送消息时 Value 的序列化器(全类名形式) |
buffer.memory | 生产者消息队列(RecordAccumulator)总大小,默认32m |
batch.size | 消息发送缓冲区大小,默认 16k,提高该值可增加吞吐量,但会增加传输时延 |
linger.ms | 消息发送最多缓冲时间,默认 0ms,即立即发送,生产建议 5-100ms 之间 |
| acks | 0:发送后无需等待数据落盘应答,一般不使用; 1:发送后需等待Leader应答,传输日志数据等; -1/all:等待 isr 队列中的所有节点(可同步副本)应答,默认值,传输核心业务数据; |
| max.in.flight. requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5次,开启幂等性时要保证该值是 1-5 。 |
| retries | 发送失败后的重试次数,默认为2147483647; |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是 100ms |
| enable.idempotence | 是否开启幂等性,默认 true,开启幂等性 |
compression.type | 消息压缩格式,默认是 none,也就是不压缩。支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
3. Java API
1) 导入依赖
71<dependencies>2 <dependency>3 <groupId>org.apache.kafka</groupId>4 <artifactId>kafka-clients</artifactId>5 <version>3.0.0</version>6 </dependency>7</dependencies>
2) 同步发送
331public class DemoProducerBySync {2 public static void main(String[] args) throws ExecutionException, InterruptedException {3 // 1. 连接配置4 Properties properties = new Properties();5 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.202.82.87:9092");6 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());7 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());8
9 // 2. 创建生产者10 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);11
12 // 3. 发送数据13 for (int i = 0; i < 5; i++) {14 // 发送15 Future<RecordMetadata> future = kafkaProducer.send(new ProducerRecord<>("topic_name", "data" + i));16
17 try {18 // 同步阻塞获取发送结果19 RecordMetadata metadata = future.get();20
21 // 消息发送成功22 System.out.println(" 主 题 : " + metadata.topic() + "->" + "分区:" + metadata.partition());23 } catch (ExecutionException exception) {24 // 消息发送异常25 exception.printStackTrace();26 }27
28 }29
30 // 4. 关闭生产者31 kafkaProducer.close();32 }33}
3) 异步发送
751// 异步发送消息2public class DemoProducer {3 public static void main(String[] args) throws InterruptedException {4 // 1. 连接配置5 Properties properties = new Properties();6 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.202.82.87:9092");7 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());8 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());9 10 // 自定义分区器11 properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.xxx.xxx.DemoPartitioner"); 12 13 // 平衡吞吐量和传输延时14 properties.put(ProducerConfig.ACKS_CONFIG, "1"); // 只等待Leader应答15 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432); // 缓冲区大小16 properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 批次大小17 properties.put(ProducerConfig.LINGER_MS_CONFIG, 1); // 最大缓冲时间(ms)18 properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy"); // 压缩格式19
20 // 2. 创建生产者21 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);22
23 // 3. 发送数据24 for (int i = 0; i < 5; i++) {25 kafkaProducer.send(new ProducerRecord<>("topic_name", "data" + i),26 // 回调函数(可选):在收到 ack 时触发27 new Callback() {28 29 public void onCompletion(RecordMetadata metadata, Exception exception) {30
31 // 消息发送异常32 if (exception != null) {33 exception.printStackTrace();34 return;35 }36
37 // 消息发送成功38 System.out.println(" 主 题 : " + metadata.topic() + "->" + "分区:" + metadata.partition());39 }40 });41
42 // 模拟业务延时43 Thread.sleep(2);44 }45
46 // 4. 关闭生产者47 kafkaProducer.close();48 }49}50
51// 自定义分区器52public class DemoPartitioner implements Partitioner {53 54 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {55
56 // 获取消息值57 String msgValues = value.toString();58
59 // 将vip开头的消息发送到 1 分区60 if (msgValues != null && msgValues.startsWith("vip:")) {61 return 1;62 }63
64 return 0;65 }66
67 68 public void close() {69 }70
71 72 public void configure(Map<String, ?> configs) {73 }74}75
注意:
除了自定义分区器外,
ProducerRecord类可以直接指定消息发送的分区或消息key。默认的
DefaultPartitioner会优先使用 消息Key 的 hash 值对主题分区数进行取余发送。如果既未设置自定义分区器,又未设置消息 Key,则会使用随机粘性分区器(随机分区,但会优先填满目前分区的当前批次)。
4) 事务控制
381public class DemoProducerByTranaction {2 public static void main(String[] args) {3 // 1. 连接配置4 Properties properties = new Properties();5 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");6 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());7 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());8 properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tranactional_id_01"); // 【重要】指定事务id9
10 // 2. 创建生产者11 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);12
13 // 3. 开启事务14 kafkaProducer.initTransactions();15 kafkaProducer.beginTransaction();16
17 try {18 // 4. 发送数据19 for (int i = 0; i < 5; i++) {20 kafkaProducer.send(new ProducerRecord<>("first", "atguigu" + i));21 }22
23 // 模拟业务异常24 int i = 1 / 0;25
26 // 5. 提交事务27 kafkaProducer.commitTransaction();28 } catch (Exception e) {29
30 // 5. 回滚事务31 kafkaProducer.abortTransaction();32 } finally {33
34 // 6. 关闭生产者35 kafkaProducer.close();36 }37 }38}注意:
进行事务控制时, 必须开启幂等性,即
enable.idempotence设置为true。必须定义一个唯一的
transactional.id,这样即使生产者客户端挂掉了,重启后也能继续处理未完成的事务。
4. Spring Boot API
1) 导入依赖
41<dependency>2 <groupId>org.springframework.kafka</groupId>3 <artifactId>spring-kafka</artifactId>4</dependency>
2) 生产者配置
91# application.propeties2
3# 指定 kafka 的地址4spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:90925
6# 【生产者】指定 key 和 value 的序列化器7spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer8spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer9
3) 发送消息
131public class ProducerController {3 // Kafka 模板用来向 kafka 发送数据4 5 KafkaTemplate<String, String> kafka;6 7 ("/atguigu")8 public String data(String msg) {9 kafka.send("first", msg);10 return "ok";11 }12}13
第四节 Broker
1. ZK节点信息
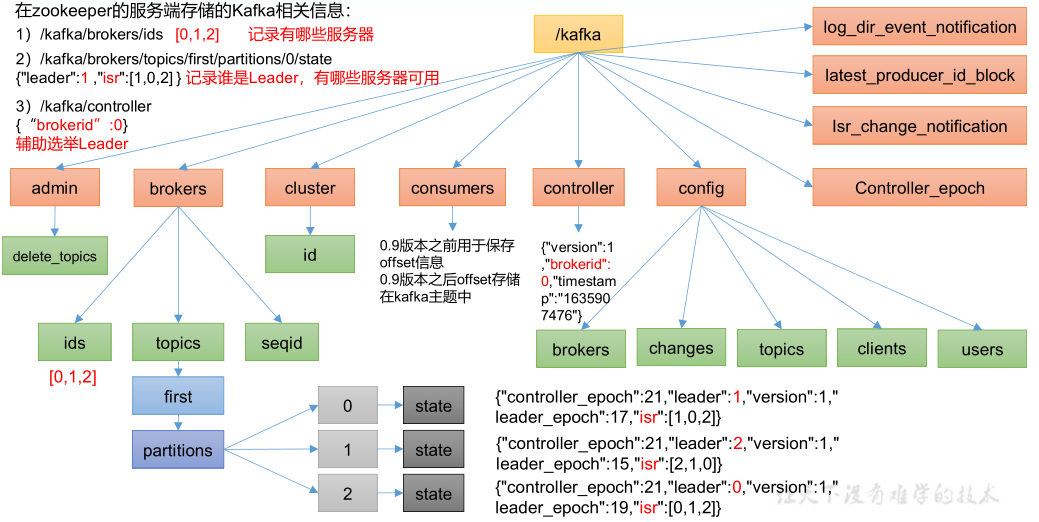
注意:
消费者在 zk 中注册,但生产者不在 zk 中注册。
2. Broker参数配置
| 参数名称 | 参数说明 |
|---|---|
| replica.lag.time.max.ms | Follower 向 Leader 发送通信请求/数据的最大间隔,默认30s,超时则会被踢出 ISR 队列 |
| auto.leader.rebalance.enable | 自动 Leader Partition 平衡,默认为true |
| leader.imbalance.per.broker.percentage | 每个 broker 允许的不平衡 leader 的比率,默认为10%,超过后将会触发 leader 的平衡 |
| leader.imbalance.check.interval.seconds | 检查 leader 负载是否平衡的间隔时间,默认300s |
| log.segment.bytes | 日志块大小,默认1G |
| log.index.interval.bytes | 日志索引间隔,默认4kb,即每写4kb日志文件,则在* index 文件*记录一个索引 |
| log.retention.hours | 日志保存的时间,小时级别,默认 7 天 |
| log.retention.minutes | 日志保存的时间,分钟级别,默认关闭 |
| log.retention.ms | 日志保存的时间,毫秒级别,默认关闭 |
| log.retention.check.interval.ms | 检查日志是否过期的间隔,默认是 5 分钟 |
| log.retention.bytes | 日志保存的大小,默认-1,表示无穷大 |
| log.cleanup.policy | 日志清理策略,默认是 delete,还可设置为 compact,使用压缩策略。 |
| num.io.threads | 写磁盘的线程数,默认为8。这个参数值要占总核数的 50%。 |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50% 的 1/3 |
| num.network.threads | 数据传输线程数,默认为3,这个参数占总核数的50%的 2/3 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。 |
| log.flush.interval.ms | 每隔多久刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
3. 核心机制
1) Leader 选举机制
Controller Leader 负责管理集群 broker的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
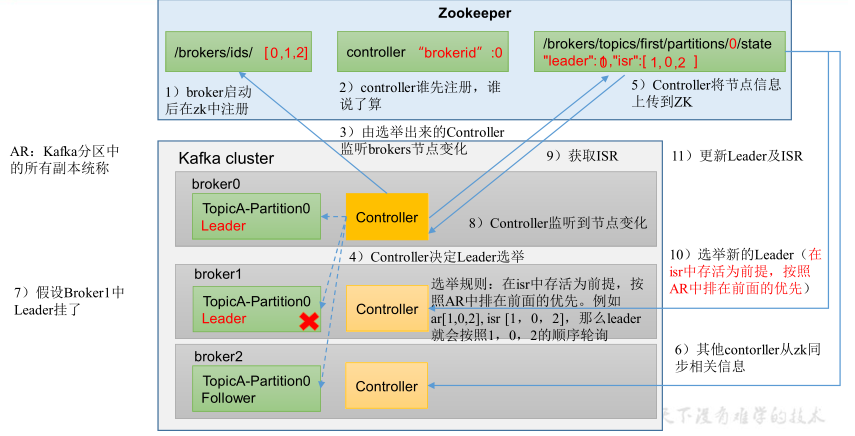
2) Follower故障处理

3) Leader故障处理
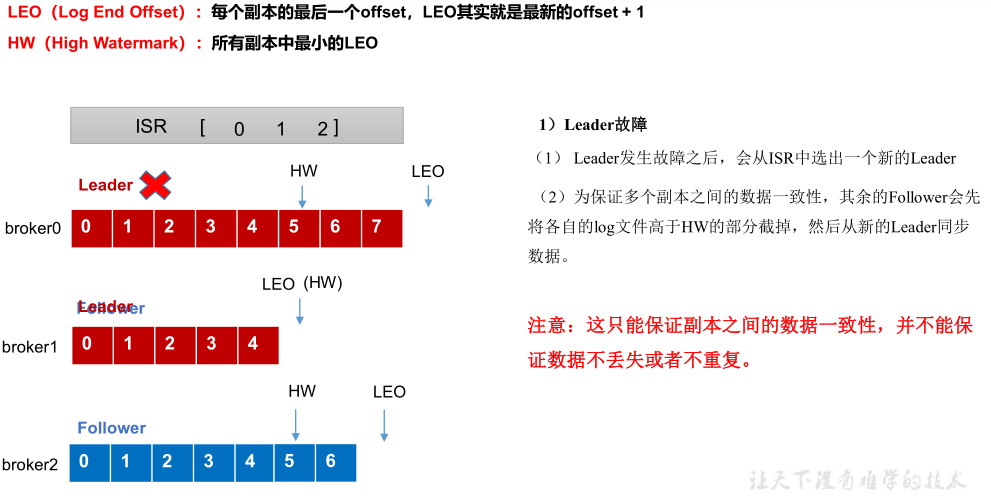
4) 文件存储机制

提示:
使用 kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index 可以查看日志和索引文件。
Broker相关参数可设置文件清理策略,按时间清理或按日志大小清理等。
第五节 消费者
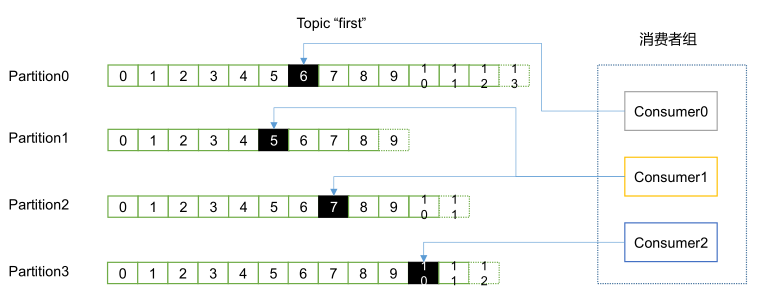
1. 消费流程
消费者以消费者组为单位采用 拉(pull)模式从 broker 中读取数据,每个分区在同一时间只能由组中的一个消费者进行读取,但是不同组可以同时消费这个分区。
注意:
拉模式可以由消费者控制消息消费的速率,但是消费者可能会在等待消息的“长轮询”中被阻塞。
2. 消费者参数配置
| 参数名称 | 参数说明 |
|---|---|
| bootstrap.servers | 建立连接用到的Broker列表,以逗号分隔,如:10.201.65.21:9092,10.201.65.22:9092,10.201.65.23:9092; |
| key.deserializer | 接收消息时 Key 的序列化器(全类名形式) |
| value.deserializer | 接收消息时 Value 的序列化器(全类名形式) |
| group.id | 标记消费者所属的消费者组 |
| enable.auto.commit | 消费者是否向服务器提交偏移量,默认值为 true |
| auto.commit.interval.ms | 消费者向服务器提交偏移量的频率,默认 5s |
| auto.offset.reset | 当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在的处理方式: earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是 50 个分区 |
| heartbeat.interval.ms | 消费者和 coordinator 之间的心跳时间,默认 3s,建议小于 session.timeout.ms 的 1/3 |
| session.timeout.ms | 消费者和 coordinator 之间连接超时时间,默认45s,超过则移除该消费者,消费者组执行再平衡 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟,超过则移除该消费者,消费者组执行再平衡 |
| fetch.min.bytes | 消费者提取消息最小字节数,默认 1 个字节 |
| fetch.max.bytes | 消费者提取消息最大字节数,默认52428800(50 m) |
| fetch.max.wait.ms | 消费者提取消息最长等待时间,默认500ms |
| max.poll.records | 一次 poll拉取数据返回消息的最大条数,默认是 500 条。 |
| partition.assignment.strategy | 消 费 者 分 区 分 配 策 略 , 默 认 策 略 是 Range + CooperativeSticky。 Kafka 可以同时使用多个分区分配策略,可选:Range、RoundRobin、Sticky、CooperativeSticky。 |
3. Java API
1) 导入依赖
71<dependencies>2 <dependency>3 <groupId>org.apache.kafka</groupId>4 <artifactId>kafka-clients</artifactId>5 <version>3.0.0</version>6 </dependency>7</dependencies>
2) 从指定主题消费消息
421public class DemoConsumer {2 public static void main(String[] args) {3
4 // 1. 连接配置5 Properties properties = new Properties();6 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");7 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());8 properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());9
10 // 消费者组ID(必须配置)11 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test5");12
13 // 设置分区分配策略14 properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.StickyAssignor");15
16 // 手动提交offset17 properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);18
19 // 2. 创建消费者20 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);21
22 // 3. 订阅主题23 kafkaConsumer.subscribe(new ArrayList<String>() {{24 add("first");25 }});26
27 // 4. 消费数据28 while (true) {29 ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));30
31 // 执行业务32 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {33 System.out.println(consumerRecord);34 }35
36 // 异步提交offset37 kafkaConsumer.commitAsync(); // 可能会失败38 // kafkaConsumer.commitSync(); // 同步提交,失败重试39 }40 }41}42
3) 从指定分区消费消息
331public class DemoConsumerPartition {2 public static void main(String[] args) {3 // 1. 连接配置4 Properties properties = new Properties();5 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");6 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());7 properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());8
9 // 消费者组ID(必须配置)10 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");11
12 // 自动提交offset,默认为true13 properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);14 properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000); // 自动提交 offset 时间间隔,默认5s15
16 // 2. 创建消费者17 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);18
19 // 3. 订阅主题指定分区20 kafkaConsumer.assign(new ArrayList<TopicPartition>() {{21 add(new TopicPartition("first", 0)); // first主题的 0 分区22 }});23
24 // 4. 消费数据25 while (true) {26 ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));27 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {28 System.out.println(consumerRecord);29 }30 }31 }32}33
4) 从指定offset消费消息
431
2public class DemoConsumerSeek {3 public static void main(String[] args) {4
5 // 1. 连接配置6 Properties properties = new Properties();7 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");8 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());9 properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());10
11 // 消费者组ID(必须配置)12 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test3");13
14 // 2. 创建消费者15 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);16
17 // 3. 订阅主题18 kafkaConsumer.subscribe(new ArrayList<String>() {{19 add("first");20 }});21
22 // 4. 查询消费者分区分配信息(有了分区分配信息才能开始消费)23 Set<TopicPartition> assignment = kafkaConsumer.assignment();24 while (assignment.size() == 0) {25 kafkaConsumer.poll(Duration.ofSeconds(1));26 assignment = kafkaConsumer.assignment();27 }28
29 // 5. 设置消从指定 offset 开始消费(对所有分区设置)30 for (TopicPartition topicPartition : assignment) {31 kafkaConsumer.seek(topicPartition, 600);32 }33
34 // 6. 消费数据35 while (true) {36 ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));37 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {38 System.out.println(consumerRecord);39 }40 }41 }42}43
5) 从指定时间消费消息
521public class DemoConsumerSeekTime {2 public static void main(String[] args) {3 // 1. 连接配置4 Properties properties = new Properties();5 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");6 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());7 properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());8
9 // 消费者组ID(必须配置)10 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test3");11
12 // 2. 创建消费者13 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);14
15 // 3. 订阅主题16 kafkaConsumer.subscribe(new ArrayList<String>() {{17 add("first");18 }});19
20 // 4. 查询消费者分区分配信息(有了分区分配信息才能开始消费)21 Set<TopicPartition> assignment = kafkaConsumer.assignment();22 while (assignment.size() == 0) {23 kafkaConsumer.poll(Duration.ofSeconds(1));24 assignment = kafkaConsumer.assignment();25 }26
27 // 5. 查询各分区 1 天前的 offset28 HashMap<TopicPartition, Long> timeMap = new HashMap<>();29 for (TopicPartition topicPartition : assignment) {30 timeMap.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000); // 每个分区都从前 1 天开始消费31 }32 Map<TopicPartition, OffsetAndTimestamp> offsetMap = kafkaConsumer.offsetsForTimes(timeMap); // 获取每个分区前 1 天时的 offset33
34 // 6. 设置消从指定 offset 开始消费(对所有分区设置)35 for (TopicPartition topicPartition : assignment) {36 // 获取 1 天前的分区 offset 并设置37 OffsetAndTimestamp offsetAndTimestamp = offsetMap.get(topicPartition);38 if (offsetAndTimestamp != null) {39 kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset());40 }41 }42
43 // 7. 消费数据44 while (true) {45 ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));46 for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {47 System.out.println(consumerRecord);48 }49 }50 }51}52
6) 事务控制
131// 自动提交offset,默认为true2properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);3properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000); // 自动提交 offset 时间间隔,默认5s4
5// 手动提交offset6properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);7
8// 异步提交offset9// 没有失败重试机制,故有可能提交失败10kafkaConsumer.commitAsync();11// 同步提交offset12// 同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败)13kafkaConsumer.commitSync();提示:
消费 offset 保存在内置主题__consumer_offsets中,key 是 group.id+topic+分区号,value 就是当前 offset 的值。
4. Spring Boot API
1) 导入依赖
41<dependency>2 <groupId>org.springframework.kafka</groupId>3 <artifactId>spring-kafka</artifactId>4</dependency>
2) 消费者配置
111# application.propeties2
3# 指定 kafka 的地址4spring.kafka.bootstrap-servers=hadoop102:9092,hadoop103:9092,hadoop104:90925
6# 【消费者】指定 key 和 value 的反序列化器7spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer8spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer9
10# 【消费者】指定消费者组的 group_id11spring.kafka.consumer.group-id=atguigu
3) 消费消息
81public class KafkaConsumer {3 // 指定要监听的 topic4 (topics = "first")5 public void consumeTopic(String msg) {6 System.out.println(" 收到的信息: " + msg);7 }8}
第六节 扩展知识
1. 生产经验
1) 生产者精确发送一次
保证数据至少发送一次 :ACK 级别设置为-1 + 分区副本大于等于2 + ISR队列里应答的最小副本数量大于等于2。
保证数据至多发送一次 : ACK 级别设置为0。
保证数据精确发送一次 : 满足数据至少发送一次的条件,并且开启幂等性支持,使用事务控制发送。
2) 保证分区内数据有序
不同分区无法保证有序:不同分区可能在不同机器,无法保证有序,只能保证分区内数据有序。
保证分区内数据有序 : 需设置 max.in.flight.requests.per.connection 为 1,如果未设置重试次数且开启幂等性时,允许 <= 5。
3) 消费者精确消费一次
重复消费:如果已经消费了数据,但是 offset 没提交,此时消费者挂掉了再起来,就会造成重复消费;
漏消费:相应的,如果先提交了 offset ,但是还没消费完就挂掉了,会造成漏消费。
精确消费一次:如果需要实现精确消费一次,那么必须将消费过程和手动提交offset 过程做原子绑定。
4) 如何提高Kafka吞吐量
生产者:合理设置缓冲区大小(buffer.memory)、批次大小( batch.size)、等待时间(linger.ms)、压缩类型(compression.type)等。
消费者:增加主题分区数,并使组下消费者数量等于分区数量;提升每批次拉取数量(max.poll.records)和大小(fetch.max.bytes)。
2. Kafka-Eagle 监控
Kafka-Eagle 框架(https://www.kafka-eagle.org/)可以监控 Kafka 集群的整体运行情况,在生产环境中经常使用。
3. Kafka-Kraft 模式
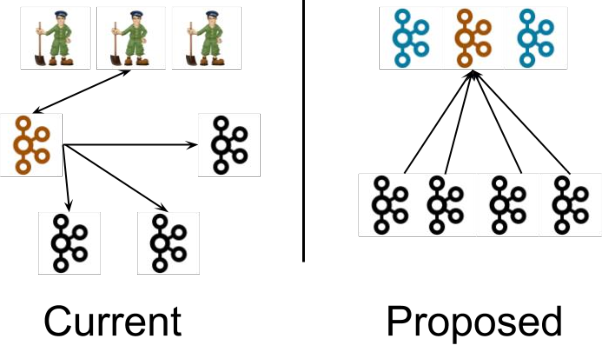
在 Kafka 现有架构中(左图),元数据在 zookeeper 中,运行时动态选举 controller,由 controller 进行 Kafka 集群管理。
而在 kraft 模式架构中(右图,实验性),不再依赖 zookeeper 集群,而是用三台 controller 节点 代替 zookeeper,元数据保存在controller 中,由 controller 直接进行 Kafka集群管理。 这样做的好处有以下几个:
Kafka 不再依赖外部框架,而是能够独立运行;
controller管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
controller 不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强 controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策。
第04章_Redis
第一节 Redis简介
1.什么是Redis?
Redis(https://redis.io/)是一款C语言开发的高性能键值存储数据库,遵守BSD开源协议。
扩展
官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s。
2. Redis安装
1) Windows服务端
51- 下载地址:https://github.com/dmajkic/redis/downloads2- 启动服务端:redis-server.exe [配置文件]3- 启动客户端:redis-cli.exe [-h 127.0.0.1] [-p 6379] [-a "mypass"]4- 配置文件:redis.windows.conf5
2) Linux服务端
141- 下载地址:https://redis.io/download/2---# 源码安装 -------4$ wget http://download.redis.io/releases/redis-7.2.4.tar.gz5$ tar xzf redis-7.2.4.tar.gz6$ cd redis-7.2.47$ make8$ ./redis-server9$ ./redis-cli10---# apt-get/yum安装 -----13xxx install redis-server14
3) 图形客户端
31- 客户端源码:https://github.com/uglide/RedisDesktopManager2- 客户端安装包:https://github.com/lework/RedisDesktopManager-Windows/releases3
3. Redis配置
1) 配置命令
101# 获取所有配置项2CONFIG GET *3
4# 获取指定配置项5CONFIG GET xxx6
7# 修改配置项8CONFIG SET name value9CONFIG SET loglevel "notice"10
2) 基础配置项
171# 基础配置2daemonize no # 是否以守护进程的方式运行3pidfile /var/run/redis.pid # 守护进程PID文件4bind 127.0.0.1 # 绑定的主机地址5port 6379 # Redis监听端口6requirepass foobared # 设置Redis连接密码,如果配置了连接密码,默认关闭7timeout 300 # 当客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能8loglevel verbose # 指定日志记录级别:debug、verbose、notice、warning9logfile stdout # 日志文件,stdout表示标准输出(当为守护进程时,stdout将发送到/dev/null)10include /path/to/local.conf # 指定包含其它的配置文件11
12# 设置密码13# 设置密码后,客户端连接 redis 服务就需要密码验证,否则无法执行命令14CONFIG set requirepass "123" # 设置密码15CONFIG get requirepass # 查看密码(为空字符串表示没有密码)16AUTH 123 # 验证密码17
3) 数据存储配置
181
2# 数据库配置3databases 16 # 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id4dbfilename dump.rdb # 指定本地数据库文件名5dir ./ # 指定本地数据库存放目录6rdbcompression yes # 存储时是否进行压缩(LZF压缩)7
8# 同步配置9save <seconds> <changes> # 同步时机设置10appendonly no # 是否在每次更新操作后立即进行日志记录11appendfilename appendonly.aof # 更新日志文件名12appendfsync everysec # 更新日志缓冲区刷新行为13
14# 主从配置15slaveof <masterip> <masterport> # 当本机为slav服务时,设置master服务的IP地址及端口16 # 在Redis启动时,它会自动从master进行数据同步17masterauth <master-password> # 当master服务设置了密码保护时,slav服务连接master的密码18
4) 性能调优配置
111
2# 调优配置3maxclients 128 # 设置同一时间最大客户端连接数,默认无限制,为Redis进程可以打开的最大文件描述符数4maxmemory <bytes> # 指定Redis最大内存限制5glueoutputbuf yes # 在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启6vm-page-size 32 # 页大小7
8# 虚拟内存配置9vm-enabled no # 允许将访问量较少的页即冷数据存入虚拟内存10vm-swap-file /tmp/redis.swap # 虚拟内存文件路径11
第二节 常用命令
1. 基础命令
1) 连接Redis
161# 客户端连接2redis-cli.exe [-h 127.0.0.1] [-p 6379] [-a "mypass"]3
4# 验证密码5AUTH password6
7# 切换数据库8SELECT index9
10# 验证连接是否成功11PING # 查看服务是否运行12ECHO message # 打印字符串13
14# 关闭连接15QUIT # 关闭当前连接16
2) 运行信息
131# 服务器信息2# https://www.redis.net.cn/tutorial/3518.html3INFO # 打印服务器信息4TIME # 返回当前服务器时间5LASTSAVE # 最近持久化时间(时间戳格式)6MONITOR # 实时打印出 Redis 服务器接收到的命令,调试用7
8# 客户端信息9CLIENT LIST # 已连接的客户端列表10CLIENT SETNAME # 设置当前连接的名称11CLIENT GETNAME # 获取当前连接的名称12CLIENT PAUSE # 挂起客户端13CLIENT KILL # 关闭客户端
3) Key 操作
201# key的增删改查2keys pattern # 如 keys * 表示查询Redis中所有的key3type key # 获取key对应value的类型4exists key # 判断key是否存在5del key # 删除指定的key和value6rename key newkey # 修改 key 的名称7renamenx key newkey # 修改 key 的名称(仅当newkey不存在时)8randomkey # 从当前数据库中随机返回一个 key 9move key db # 将当前数据库的 key 移动到给定的数据库 db 当中10object encoding key01 # 获取key对应的存储类型11
12# key超时设置13EXPIRE key seconds14PEXPIRE key milliseconds15EXPIREAT key timestamp16PEXPIREAT key milliseconds-timestamp17PERSIST key # 移除key的过期时间18PTTL key # 以毫秒为单位返回 key 的剩余的过期时间19TTL key # 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)20
4) 全库操作
31# 全库操作2FLUSHALL # 删除所有数据库的所有key3FLUSHDB # 删除当前数据库的所有key
2. 五种基本类型
1) String(字符串)
基于 SDS 字符串实现的Map<String,String>类型结构,可以用来存储任何类型的数据,如:字符串、整数、浮点数、对象等。
| 命令 | 介绍 |
|---|---|
| SET key value | 设置指定 key 的值 |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| GET key | 获取指定 key 的值 |
| MSET key1 value1 key2 value2 …… | 设置一个或多个指定 key 的值 |
| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
| STRLEN key | 返回 key 所储存的字符串值的长度 |
| INCR key | 将 key 中储存的数字值增一 |
| DECR key | 将 key 中储存的数字值减一 |
| EXISTS key | 判断指定 key 是否存在 |
| DEL key(通用) | 删除指定的 key |
| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
注意:
String类型的value最大支持512M,单个set和list最大存储 2^32-1 个键值对(40多亿)。
2) List(列表)
基于双向链表实现的Map<String,List<String>>类型结构,可用作队列或栈。
| 命令 | 介绍 |
|---|---|
| RPUSH key value1 value2 ... | 在指定列表的尾部(右边)添加一个或多个元素 |
| LPUSH key value1 value2 ... | 在指定列表的头部(左边)添加一个或多个元素 |
| LSET key index value | 将指定列表索引 index 位置的值设置为 value |
| LPOP key | 移除并获取指定列表的第一个元素(最左边) |
| RPOP key | 移除并获取指定列表的最后一个元素(最右边) |
| LLEN key | 获取列表元素数量 |
| LRANGE key start end | 获取列表 start 和 end 之间 的元素 |
3) Hash(哈希)
基于数组+链表实现的Map<String,Map<String,String>>类型结构,常用于存储对象字段等。
| 命令 | 介绍 |
|---|---|
| HSET key field value | 设置指定哈希表中指定字段的值 |
| HSETNX key field value | 只有指定字段不存在时设置指定字段的值 |
| HMSET key field1 value1 field2 value2 ... | 同时将一个或多个 field-value (域-值)对设置到指定哈希表中 |
| HGET key field | 获取指定哈希表中指定字段的值 |
| HMGET key field1 field2 ... | 获取指定哈希表中一个或者多个指定字段的值 |
| HGETALL key | 获取指定哈希表中所有的键值对 |
| HEXISTS key field | 查看指定哈希表中指定的字段是否存在 |
| HDEL key field1 field2 ... | 删除一个或多个哈希表字段 |
| HLEN key | 获取指定哈希表中字段的数量 |
| HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
4) Set(集合)
基于哈希表实现的Map<String,Set<String>>类型结构,是不存在重复元素的无序集合,常用于去重、取交集/并集/差集等。
| 命令 | 介绍 |
|---|---|
| SADD key member1 member2 ... | 向指定集合添加一个或多个元素 |
| SREM key member1 member2 ... | 从指定集合移除一个或多个元素 |
| SMEMBERS key | 获取指定集合中的所有元素 |
| SCARD key | 获取指定集合的元素数量 |
| SISMEMBER key member | 判断指定元素是否在指定集合中 |
| SINTER key1 key2 ... | 获取给定所有集合的交集 |
| SINTERSTORE destination key1 key2 ... | 将给定所有集合的交集存储在 destination 中 |
| SUNION key1 key2 ... | 获取给定所有集合的并集 |
| SUNIONSTORE destination key1 key2 ... | 将给定所有集合的并集存储在 destination 中 |
| SDIFF key1 key2 ... | 获取给定所有集合的差集 |
| SDIFFSTORE destination key1 key2 ... | 将给定所有集合的差集存储在 destination 中 |
| SPOP key count | 随机移除并获取指定集合中一个或多个元素 |
| SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
5) Sorted Set(有序集合)
基于哈希表+跳表实现的Map<String,SortedSet<String>>类型结构,是不存在重复元素的有序集合,常用于制作排行榜等。
| 命令 | 介绍 |
|---|---|
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
| ZREM key score1 member1 score2 member2 ... | 从指定有序集合删除一个或多个元素 |
| ZCARD KEY | 获取指定有序集合的元素数量 |
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
| ZINTERSTORE destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
注意:
如果集合元素较短(<64字节)且元素个数较少(<128个),则会使用
ziplist存储,以节省内存空间。使用跳表不仅能维持比较好的读写平衡,且相对红黑树来说对范围查询更加友好,对B+树来说更节省内存。
3. 其它数据类型
1) Bitmap(位图)
用于存储二进制位,可以理解为bool[512M]类型结构,非常节省内存,常用于活跃用户统计、用户行为分析(登录、点击...)等。
| 命令 | 介绍 |
|---|---|
| SETBIT key offset value | 设置指定 offset 位置的值 |
| GETBIT key offset | 获取指定 offset 位置的值 |
| BITCOUNT key start end | 获取 start 和 end 之间值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
2) HyperLogLog(基数统计)
基于矩阵+基数统计的近似算法,能够以极低的内存来估算一个集合中不重复元素的数量,常用于统计页面UV(独立访客量)等。
| 命令 | 介绍 |
|---|---|
| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
3) Geospatial(地理位置)
用于存储地理位置信息,可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能,常用于实现“附近的人”功能。
| 命令 | 介绍 |
|---|---|
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
第三节 高级特性
1. 发布订阅
141# 订阅2subscribe channel01 # 订阅3psubscribe channel* # 订阅(支持通配符)4
5# 发布6publish channel01 "msg01" # 发布 7
8# 退订9unsubscribe channel01 # 退订10punsubscribe channel* # 退订(支持通配符)11
12# 查看订阅与发布系统状态13PUBSUB subcommand [argument [argument ...]]14
注意
必须先订阅后发布,订阅某个通道,并不能收到该通道之前已发布的消息。
2. 事务
1) 事务控制命令
Redis的事务可以一次执行多个命令,它可以保证:
事务中的命令将会按顺序执行,并且期间不会执行其它命令。
事务中的命令要么全部被执行,要么全部都不执行。
171# 开启事务2MULTI3
4# 输入多个命令5SET key01 value016SET key02 value027
8# 执行命令9EXEC10
11# 回滚命令12DISCARD13
14# 监视命令15WATCH key01 [key02 ...] # 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断16UNWATCH # 取消 WATCH 命令对所有 key 的监视。17
注意:
Redis的事务是通过队列实现的,当开启事务时,通过队列收集命令,当提交或回滚时,依次执行或删除队列中的命令。
当事务中的命令较多时,会阻塞其它客户端请求,并且错误处理不够灵活,报错了还继续执行后续命令。
2) 事务的ACID特性
原子性(Atomicity):在发生错误时,不支持回滚,会继续执行后续命令,因此不满足原子性。
一致性(Consistency):在出现数据丢失的情况下,可能破坏一致性,如:A转账给B,A扣钱了,但B加钱的命令丢失了。
隔离性(Isolation):在事务执行期间,其它线程可以读取刚执行的结果,可能会造成不可重复读或幻读。
持久性(Durability):通过RDB模式或AOF模式支持持久化,但在写入延迟或服务器崩溃仍可能导致数据丢失。
3. 持久化
1) RDB方式
基于某个时间点的数据创建快照,是Redis版本使用的默认方式。
91# RDB持久化配置2save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。3save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。4save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。5
6# RDB持久化命令7save # 同步保存操作,会阻塞 Redis 主线程;8bgsave # fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。9
2) AOF方式
基于每条更新命令写AOF缓存区(server.aof_buf)和AOF文件(appendonly.aof),再异步根据刷盘策略进行刷盘,当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
111# 开启AOF方式2appendonly yes3
4# 配置AOF日志文件名5appendfilename appendonly.aof6
7# AOF日志缓冲区刷盘策略8appendfsync no # 表示等操作系统进行数据缓存同步到磁盘(快)9appendfsync always # 表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)10appendfsync everysec # 表示每秒同步一次(折中,默认值)11
注意:
AOF日志是更新命令执行完毕后再写入的,这样不会阻塞当前命令的执行,但在Redis崩溃或宕机时,可能会丢失该笔日志。
当AOF文件达到一定大小时(64M),就会触发AOF重写,从Redis读取当前数据并加上期间的增量数据生成新的AOF文件,以节省磁盘空间。
3) 混合持久化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化,即在 AOF 重写的时候直接把 RDB 的内容写到 AOF 文件开头,这样可以快速加载同时避免丢失过多的数据,但破坏了AOF文件的可读性。
31# 开启混合持久化2aof-use-rdb-preamble3
4. 备份恢复
71# 备份2save # 将在 redis 安装目录中生成 dump.rdb 文件3bgsave # 后台执行4
5# 恢复6CONFIG GET dir # 查询安装目录,并将 dump.rdb 文件移动到该目录并重启7
5. 脚本
Redis 使用 Lua 解释器来执行脚本,可参考:https://www.redis.net.cn/tutorial/3516.html
6. 管道
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
服务端处理命令,并将结果返回给客户端。
Redis 管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。
91$(echo -en "PING\r\n SET w3ckey redis\r\nGET w3ckey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n"; sleep 10) | nc localhost 63792 3+PONG4+OK5redis6:17:28:39
这可以显著的改善往返时延,提提高Redis的性能。
7. 模块
Redis 从 4.0 版本开始,支持通过 Module (动态链接库形式)来扩展其功能以满足特殊的需求,推荐的模块如下:
RediSearch:用于实现搜索引擎的模块。
RedisJSON:用于处理 JSON 数据的模块。
RedisGraph:用于实现图形数据库的模块。
RedisTimeSeries:用于处理时间序列数据的模块。
RedisBloom:用于实现布隆过滤器的模块。
RedisAI:用于执行深度学习/机器学习模型并管理其数据的模块。
RedisCell:用于实现分布式限流的模块。
8. 性能测试
101# 命令格式2# https://www.redis.net.cn/tutorial/3521.html3redis-benchmark [option] [option value]4
5# 同时执行 10000 个请求6redis-benchmark -n 100000 7
8# 显示每秒执行的请求数,执行的命令为 set,lpush9redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 100000 -q10
第四节 Java客户端
1. Jedis
1) 引入依赖
51<dependency>2 <groupId>redis.clients</groupId>3 <artifactId>jedis</artifactId>4 <version>2.9.0</version>5</dependency>
2) 连接Redis
141import redis.clients.jedis.Jedis;2public class RedisJava {3 public static void main(String[] args) {4 //连接本地的 Redis 服务5 Jedis jedis = new Jedis("localhost", 6379 );6 System.out.println("Connection to server sucessfully");7 8 //查看服务是否运行9 System.out.println("Server is running: "+jedis.ping());10 11 // 关闭连接12 jedis.close();13 }14}
3) 数据存取
281// 字符串2jedis.set("username","zhangsan");3String username = jedis.get("username");4
5// 哈希6jedis.hset("user","name","lisi");7jedis.hset("user","age","23");8jedis.hset("user","gender","female");9String name = jedis.hget("user", "name");10Map<String, String> user = jedis.hgetAll("user");11
12// 列表/队列13jedis.lpush("mylist","a","b","c");14jedis.rpush("mylist","a","b","c");15List<String> mylist = jedis.lrange("mylist", 0, -1);16String element1 = jedis.lpop("mylist");17String element2 = jedis.rpop("mylist");18
19// 集合20jedis.sadd("myset","java","php","c++");21Set<String> myset = jedis.smembers("myset");22
23// 有序集合24jedis.zadd("mysortedset",3,"亚瑟");25jedis.zadd("mysortedset",30,"后裔");26jedis.zadd("mysortedset",55,"孙悟空");27Set<String> mysortedset = jedis.zrange("mysortedset", 0, -1);28
4) 其它命令
61// 设置过期时间2jedis.setex("key01",20,"value01"); // 20秒后自动删除该键值对 key01:value013
4// keys5List<String> list = jedis.keys("*");6
5) Jedis连接池
331// Jedis连接池工具类2public class JedisPoolUtils {3
4 // 连接池引用5 private static JedisPool jedisPool;6
7 // 连接池初始化8 static{9 10 // 1. 读取配置文件11 InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties");12 Properties pro = new Properties();13 try {14 pro.load(is);15 } catch (IOException e) {16 e.printStackTrace();17 }18 19 // 2. 创建配置类20 JedisPoolConfig config = new JedisPoolConfig();21 config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal")));22 config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle")));23
24 // 3. 创建JedisPool25 jedisPool = new JedisPool(config, pro.getProperty("host"), Integer.parseInt(pro.getProperty("port")));26 }27 28 // 获取Jedis连接29 public static Jedis getJedis(){30 return jedisPool.getResource();31 }32 33}注意:
Jedis连接使用完毕后,必须调用
jedis.close();归还连接。
2. RedisTemplate
1) 引入依赖
81<dependency>2 <groupId>org.springframework.boot</groupId>3 <artifactId>spring-boot-starter-data-redis</artifactId>4</dependency>5<dependency>6 <groupId>org.apache.commons</groupId>7 <artifactId>commons-pool2</artifactId>8</dependency>
2) 注入StringRedisTemplate使用
1031public class RedisTestController {3 4 private StringRedisTemplate redisTemplate;5
6 ("redisTest")7 public String redisTest() {8
9 // 1. 关于key的操作10 // 获取所有的key11 Set<String> keys = redisTemplate.keys("*");12 System.out.println("keys:" + keys);13 // 判断是否存在指定的key14 Boolean hasKey = redisTemplate.hasKey("k1");15 System.out.println("判断是否存在指定的key:" + hasKey);16 // 删除指定的key17 Boolean k1 = redisTemplate.delete("k1");18 System.out.println("是否删除指定key成功:" + k1);19
20
21 // 2. 操作Stirng22 ValueOperations<String, String> forValue = redisTemplate.opsForValue();23 // 设置和获取24 forValue.set("k2", "张明喆");25 String k2 = forValue.get("k2");26 System.out.println("k2:" + k2);27 //只有在 key 不存在时设置 key 的值28 Boolean aBoolean = forValue.setIfAbsent("k2", "zmz2");29 System.out.println("是否存入成功:" + aBoolean);30 //incr decr31 Long k4 = forValue.increment("k4", 20);32 System.out.println("k4:" + k4);33 forValue.decrement("k4");34 //批量添加35 Map<String, String> map = new HashMap<>();36 map.put("m1", "m1");37 map.put("m2", "m2");38 forValue.multiSet(map);39
40 // 3. 操作hash41 HashOperations<String, Object, Object> forHash = redisTemplate.opsForHash();42 // 逐个put43 forHash.put("k5", "name", "zmz");44 forHash.put("k5", "age", "16");45 forHash.put("k5", "sex", "男");46 // 批量put47 Map<String, String> map1 = new HashMap<>();48 map.put("name", "jsl");49 map.put("age", "29");50 map.put("sex", "男");51 forHash.putAll("k6", map1);52 // 获取53 Map<Object, Object> k5 = forHash.entries("k5");54 System.out.println(k5);55 Set<Object> k6 = forHash.keys("k6");56 System.out.println(k6);57 System.out.println(forHash.values("k6"));58
59 // 4. 操作list60 ListOperations<String, String> list = redisTemplate.opsForList();61 // 放入单个 key value62 list.leftPush("l1", "111");63 // 放入 批量value64 list.leftPushAll("l2", "zmz", "jsl", "hql", "fxd");65 // 获取列表指定范围内的元素66 List<String> l2 = list.range("l2", 0, -1);67 System.out.println(l2);68 // 移出并获取列表的第一个元素69 list.leftPop("l2");70
71 // 5. 操作set72 SetOperations<String, String> forSet = redisTemplate.opsForSet();73 // 向集合添加一个或多个成员74 forSet.add("s1", "张明喆", "贾善领", "黄启龙", "张明喆", "贾善领");75 forSet.add("s2", "张明喆1", "贾善领2", "黄启龙3", "张明喆", "贾善领");76 // 返回集合中的所有成员77 Set<String> s1 = forSet.members("s1");78 System.out.println(s1);79 // 随机获取一个或多个元素80 String s11 = forSet.randomMember("s1");81 System.out.println(s11);82 // 返回给定所有集合的交集83 Set<String> intersect = forSet.intersect("s1", "s2");84 System.out.println(intersect);85
86 // 6. 操作sort set87 ZSetOperations<String, String> forZSet = redisTemplate.opsForZSet();88 // 向有序集合添加一个或多个成员,或者更新已存在成员的分数89 forZSet.add("z1", "math", 80);90 forZSet.add("z1", "chinese", 99);91 forZSet.add("z1", "english", 78);92 forZSet.add("z1", "physics", 76);93 forZSet.add("z1", "biology", 60);94 // 通过索引区间返回有序集合成指定区间内的成员95 Set<String> z1 = forZSet.range("z1", 0, -1);96 System.out.println(z1);97 // 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序98 Set<String> z11 = forZSet.reverseRange("z1", 0, -1);99 System.out.println(z11);100
101 return "OK";102 }103}
3) 注入RedisTemplate使用
RedisTemplate允许你以Java对象的形式存取数据。
181public class Test2 {2 3 private RedisTemplate redisTemplate;4 5 6 void test(){7 ValueOperations valueOperations = redisTemplate.opsForValue();8 valueOperations.set("user",new User("张明喆",29,"上海"));9 Object o = valueOperations.get("user");10 System.out.println(o);11
12 HashOperations hashOperations = redisTemplate.opsForHash();13 hashOperations.put("k3","name","zmz");14 Map<String, Object> map = new HashMap<>();15 map.put("1", new User("zz",22,"ll"));16 hashOperations.putAll("k5", map);17 }18}但其默认采用JDK序列化机制,阅读能力差,而且占用空间大,一般需要人为指定序列化方式:
361package com.sws;2 3import com.fasterxml.jackson.annotation.JsonAutoDetect;4import com.fasterxml.jackson.annotation.PropertyAccessor;5import com.fasterxml.jackson.databind.ObjectMapper;6import org.springframework.context.annotation.Bean;7import org.springframework.context.annotation.Configuration;8import org.springframework.data.redis.connection.RedisConnectionFactory;9import org.springframework.data.redis.core.RedisTemplate;10import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;11import org.springframework.data.redis.serializer.RedisSerializer;12import org.springframework.data.redis.serializer.StringRedisSerializer;13
14public class RedisConfig {16 17 18 public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {19 RedisTemplate<String, Object> template = new RedisTemplate<>();20 RedisSerializer<String> redisSerializer = new StringRedisSerializer();21 Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);22 ObjectMapper om = new ObjectMapper();23 om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);24 om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);25 jackson2JsonRedisSerializer.setObjectMapper(om);26 template.setConnectionFactory(factory);27 //key序列化方式28 template.setKeySerializer(redisSerializer);29 //value序列化30 template.setValueSerializer(jackson2JsonRedisSerializer);31 //value hashmap序列化32 template.setHashValueSerializer(jackson2JsonRedisSerializer);33 template.setHashKeySerializer(redisSerializer);34 return template;35 }36}
第五节 面试扩展
1. Redis基础
Redis为什么快?
基于内存存储,无磁盘I/O操作,读写速度可达到几十纳秒级别。
使用单线程模式,避免线程切换带来的额外开销。
优化数据结构,使用哈希表、跳表、压缩列表等优化插入和查询速度。
优化内存管理,使用内存分配器来减少内存碎片问题。
优化命令行:使用极为精简的命令格式,传输和解析更加高效。
Redis vs Memcached?
Redis的数据结构更加丰富,而 Memcached 只支持简单的键值对结构,只能存储字符串类型的数据。
Redis支持数据持久化、主从复制、哨兵机制等高级功能,且用户群体较大。
为什么不使用Redis作为主数据库?
数据持久化支持不足:定时写磁盘模式(RDB)可能丢失数据,追加文件方式(AOF)占用磁盘较大且恢复数据较慢。
数据容量有限:Redis数据存储在内存中,容量收到限制,且成本较高。
数据模型限制:主要支持键值对、列表、集合、有序集合、哈希表等几种基本数据结构,无法高效处理关系数据和支持复杂查询。
事务支持有限:事务机制是通过命令打包实现的,不支持自动回滚,不支持事务隔离级别,无法保证ACID等。
2. Redis应用
Redis 除了做缓存,还能做什么?
分布式锁:基于原子操作命令(如:SETNX等),可以用来实现分布式锁。
配置中心:用来存储系统的配置信息,如数据库连接信息、服务地址等。
消息队列:基于列表(List)、发布/订阅(Pub/Sub)、Stream等实现消息队列。
会话存储:在Web应用中,存储用于保存用户的会话信息,如登录状态、用户权限等。
限流器(Rate Limiter):一般是通过 Redis + Lua 脚本的方式来实现限流。
复杂业务场景:如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV 等。
为什么不建议使用Redis作消息队列?
基于List方式:功能简单,无法支持ACK机制,且消息不能广播,只能被消费一次。
发布订阅功能:引入 channel 来支持消息广播,但无法解决消息丢失和消息堆积问题。
基于Stram方式:支持ACK、消费组、持久化,但在 Redis 发生故障恢复后不能保证消息至少被消费一次。
Redis 可以做搜索引擎么?
Redis可以借助
RedisSearch模块实现全文搜索引擎功能,支持中文分词、聚合统计、分页搜索等功能。其性能比 ElastcSearch 更加优秀,但对大规模、分布式数据支持不太友好。
如何基于 Redis 实现延时任务?
监控key的过期事件:当1个key过期被删除时,Redis会在
__keyevent@0__:expired通道发布过期事件,可监听进行相应处理。劣势:时效性差(在定期删除或惰性删除时)、当消费者不存在时,存在丢消息问题、当消费者存在多个时,存在重复消费问题。
使用 Redisson 内置的延时队列:基于 SortedSet 实现,使用过期时间作为分数,定期扫描是否过期,并将其移至就绪队列。
优势:减小消息丢失的可能、确保消息不会被消费多次。
3. Redis线程模型
Redis是单线程还是多线程?
主要操作是单线程的,包括:接收客户端清求->解析请求->进行数据读写等操作->发送数据给客户端等。
其使用 I/O 多路复用机制来处理多个客户端连接,然后通过事件分发器分发给不同的事件处理器。
会有一些辅助线程来处理文件关闭、AOF 刷盘、内存释放等耗时的操作,防止主线程阻塞。
在 Redis 6.0 版本之后,也采用多个IO线程来处理网络请求,防止网络I/O处理性能限制网络硬件的提升。
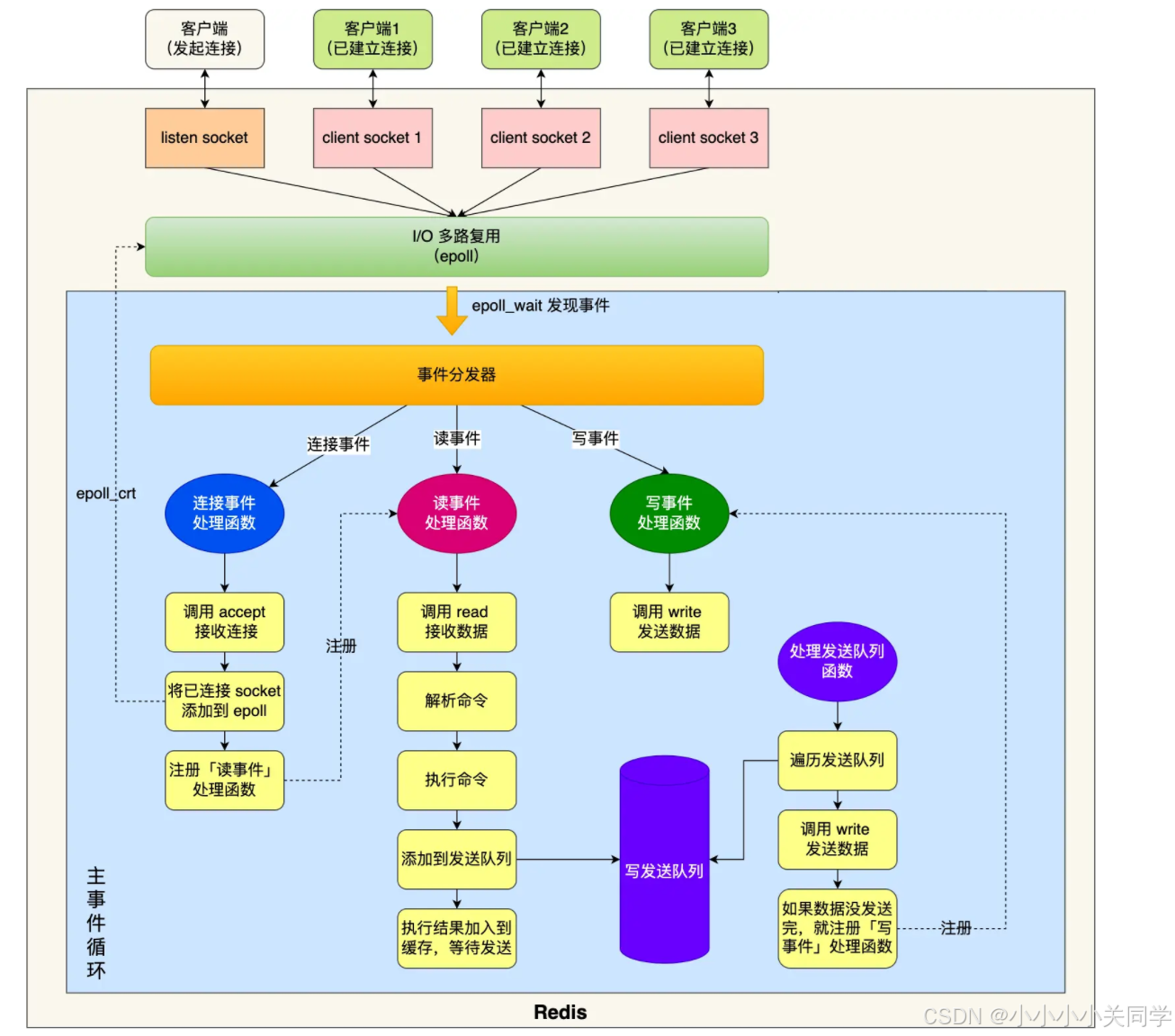
Redis使用单线程模式的优劣势?
优势: Redis 的性能瓶颈不在 CPU,主要在内存和网络,因此单线程避免了数据同步和上下文切换,性能更加优秀。
劣势:CPU利用率低,处理大规模数据时容易阻塞,并且对分布式扩展支持不好。
Redis6.0之后为什么引入多线程?
主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性 能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
Redis 6.0 新增的异步命令有哪些?
UNLINK :用于大规模数据集的异步删除,防止阻塞主线程,可以看作是 DEL 命令的异步版本。
FLUSHALL ASYNC :用于清空所有数据库的所有键,不限于当前 SELECT 的数据库。
FLUSHDB ASYNC :用于清空当前 SELECT 数据库中的所有键。
Redis后台线程有哪些?
bio_close_file:释放 AOF / RDB 等过程中产生的临时文件资源。
bio_aof_fsync:调用 fsync 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘(AOF 文件)。
bio_lazy_free:释放大对象(已删除)占用的内存空间。
4. Redis内存模型
为什么要设置数据过期时间?
设置过期时间可以防止内存数据不断增长。
部分业务场景,如“短信验证码1分钟有效”、“用户登录的 Token1天内有效”可以通过设置过期时间实现。
41expire key 60 # 数据在 60s 后过期(通用)2setex key 60 value # 数据在 60s 后过期(字符串专属命令,setex:[set] + [ex]pire)3ttl key # 查看数据还有多久过期4persist key # 移除键的过期时间扩展:
Redis是通过过期字典(可以看作是 hash 表)来实现数据过期的,查询数据前会先查询过期字典进行检查。
过期 key 删除策略有哪些?
惰性删除:只会在取出/查询 key 的时候才对数据进行过期检查。对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
定期删除:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
延迟队列:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
定时删除:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
Redis默认的过期key清理策略是什么?
Redis 采用的是 惰性删除+定期删除 结合的策略,同时兼顾CPU和内存,这也是大部分缓存框架的选择。
定期删除主要和“执行频率”、“执行时间”、“过期 key 的比例”有关。
一般是:每隔1/10秒,发起过期 key 清理操作,每次随机抽取20个设置了过期时间的 key ,然后逐个检查是否过期。
如果过期则执行删除,如果发现过期 key 的比例超过 10%,则继续抽取20个检查,但该过程不能超过执行时间限制。
大量 key 集中过期怎么办?
大量 key 集中过期,会使 Redis 清理过期 key 的时长增加,从而造成请求延迟增加,并且未清理的数据会继续占用内存。
我们应该避免大量 key 集中过期,并且手动设置 lazyfree-lazy-expire 参数开启
lazy free机制,在后台异步删除过期 key 。
Redis 内存淘汰策略了解么?
noeviction(默认策略): 不删除任何键,达到内存上限后,只能读不能写。
allkeys-lru(Least Recently Used):删除长时间没有被访问的键。
allkeys-lfu(Least Frequently Used):删除访问频率最低的键。
allkeys-random: 随机删除一些键,而不考虑键的访问频率或是否设置了过期时间。
volatile-lru:会删除设置了过期时间的键中最近最少使用的键。
volatile-random:会随机删除设置了过期时间的键。
volatile-ttl:优先删除那些剩余生存时间(TTL)最短的键,也就是即将过期的键。
注意:
Redis 的内存淘汰策略只有在运行内存达到了配置的最大内存阈值(
maxmemory参数)时才会触发,默认为 0 ,表示不限制。
Redis内存碎片
61# 查看内存碎片率(mem_fragmentation_ratio) = used_memory_rss(系统分配内存)/used_memory(实际申请内存)2redis-cli -p 6379 info | grep mem_fragmentation_ratio3# 开启自动内存整理(Redis4.0-RC3版本新增)5config set activedefrag yes6
5. Redis生产实践
常见性能调优
批量执行命令:通过MGET、MSET、SADD等批量命令执行或使用流水线(PipeLine)进行封装,但对 Redis cluster 支持不好。
避免集中过期:大量 key 集中过期,会影响 Redis 处理客户端请求,应通过设置随机过期时间避免且开启 lazy free 机制。
避免 bigkey:避免产生 bigkey(一个 key 对应的 value 超过 1M,或元素个数超过 5000 个),在操作时会阻塞主线程。
优化 hotkey:高频访问的 key 可通过 -
-hotkeys参数或 monitor 命令查找,并通过读写分离或二级缓存降低查询压力。减少慢查询:在执行
KEYS *、zrange等复杂度高的命令时,会导致慢查询,可通过慢查询日志SLOWLOG GET查看。
常见缓存问题
缓存穿透: 大量无效 key查询,查询既不在缓存中,也不在数据库中的数据,通常是恶意攻击导致的。
解决方案:做好参数校验、缓存无效key、使用布隆过滤器提前检查(不存在的key直接退出)、进行接口限流等
缓存击穿: 热点 key 突然失效,对数据库造成巨大的压力,通常是由于热点 key 突然过期导致的。
解决方案:设置热点key永不过期、针对热点key提前预热并设置合理的过期时间、针对数据库查询加锁,只需要1个线程去查询
缓存雪崩: 大量或所有 key突然失效,对数据库造成巨大的压力,通常是由于缓存服务器宕机导致的。
解决方案:采用Redis集群保证高可用、采用多级缓存。
如何保证缓存和数据库的一致性?
指定过期时间:根据缓存数据的敏感性,指定数据的过期时间,尽量保证数据一致性。
主动更新缓存:当数据库数据发生变化时,主动修改或删除缓存,适用于对数据一致性较高的场景。
常见缓存读写策略?
旁路缓存:在更新时先修改数据库再删除缓存,在查询时优先查询缓存,否则查询数据库。
读写穿透:将缓存作为主存储,读取和写入都操作缓存,由缓存服务器去同步写入给数据库。
异步缓存:将缓存作为主存储,读取和写入都操作缓存,由缓存服务器去异步写入给数据库。
常见阻塞原因?
执行复杂命令:执行
KEYS *、LRANGE、ZRANGE等超过 O(1) 复杂度的命令。后台进程影响:在创建RDB快照、AOF日志刷盘、AOF文件重写等可能过度消耗系统资源,间接造成主线程卡顿。
操作bigkey:在插入、查找、删除bigkey时,消耗网络和CPU资源较大,可能造成客户端超时。
系统资源竞争:CPU、内存、网络等资源达到瓶颈,发生内存交换(swap)等。
第05章_Quartz
第一节 Quartz简介
1. 什么是Quartz?
Quartz是一款基于Java实现的开源的任务调度库,体系结构如下:

核心组件包括:
任务(Job&JobDetail):调度任务需实现
org.quartz.Job接口和它的execute()方法。触发器(Trigger):任务触发的时机,如设置凌晨1点执行某任务。
调度器(Scheduler):任务的调度器,将任务(Job)和触发器(Trigger)整合起来,负责基于Trigger设定的时间来执行Job。
扩展:
任务调度指系统中创建了 N 个任务,每个任务都有指定的时间进行执行,而这种多任务的执行策略就是任务调度。
2. Quartz示例
1) 引入Quartz相关依赖
61<dependency>2 <groupId>org.quartz-scheduler</groupId>3 <artifactId>quartz</artifactId>4 <version>2.3.2</version>5</dependency>6
2) 自定义任务
91// @PersistJobDataAfterExecution2public class TestJob implements Job {3 4 public void execute(JobExecutionContext jobExecutionContext) {5 String data = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));6 System.out.println("START DATA BACKUP, current time :" + data);7 }8}9
默认情况下,Job是无状态的,每次都会创建新的实例,上下文中的JobDataMap也是新的。可以在Job类上加上@PersistJobDataAfterExecution注解,则会变成有状态的Job,允许将数据传递给下一个Job,如统计Job执行次数。
3) 创建任务调度
341public class TestScheduler {2 public static void main(String[] args) throws Exception {3 4 // 1. 定义任务明细, 并与TestJob绑定5 JobDetail jobDetail = JobBuilder.newJob(TestJob.class)6 // 任务名称, 任务组名称7 .withIdentity("testJob", "testJobGroup")8 .build();9
10 // 2. 定义触发器, 立即执行一次, 接着5秒执行一次11 Trigger trigger = TriggerBuilder.newTrigger()12 // 触发器名称, 触发器组名称13 .withIdentity("testTrigger", "testTriggerGroup")14 // 立即执行一次15 .startNow()16 // 每隔5秒执行一次17 .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))18 .build();19
20 // 3. 获取调度器,并绑定任务和触发器21 Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();22 scheduler.scheduleJob(jobDetail, trigger);23
24 // 4. 开启调度25 scheduler.start();26 }27}28
29/** OUTPUT:30START DATA BACKUP, current time :2024-04-24 10:49:4831START DATA BACKUP, current time :2024-04-24 10:49:5332START DATA BACKUP, current time :2024-04-24 10:49:5833**/34
3. SpringBoot整合
1) 引入依赖
401 2<project xmlns="http://maven.apache.org/POM/4.0.0"3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">5 <modelVersion>4.0.0</modelVersion>6
7 <groupId>org.example</groupId>8 <artifactId>SpringBoot-Quartz-demo</artifactId>9 <version>1.0-SNAPSHOT</version>10
11 <!-- 引入SpringBoot父工程 -->12 <parent>13 <groupId>org.springframework.boot</groupId>14 <artifactId>spring-boot-starter-parent</artifactId>15 <version>2.1.1.RELEASE</version>16 </parent>17
18 <dependencies>19 <!-- SpringMVC -->20 <dependency>21 <groupId>org.springframework.boot</groupId>22 <artifactId>spring-boot-starter-web</artifactId>23 </dependency>24
25 <!-- Quartz -->26 <dependency>27 <groupId>org.springframework.boot</groupId>28 <artifactId>spring-boot-starter-quartz</artifactId>29 </dependency>30
31 <!-- test -->32 <dependency>33 <groupId>org.springframework.boot</groupId>34 <artifactId>spring-boot-starter-test</artifactId>35 </dependency>36
37 </dependencies>38
39</project>40
2) 定义Job
111// 注意:这里继承SpringBoot提供的 QuartzJobBean 类(也会间接继承Job类),就可以在Job中使用Spring容器了2public class HelloJob extends QuartzJobBean {3
4 5 protected void executeInternal(JobExecutionContext context) throws JobExecutionException {6 JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();7 String name = jobDataMap.getString("name");8 System.out.println("Hello :" + name);9 }10}11
3) 手动执行
331public class HelloController {3
4 5 private Scheduler scheduler;6
7 ("/hello")8 public void helloJob(String name) throws SchedulerException {9 // 使用 HelloJob 定义一个 JobDetail10 JobDetail job = JobBuilder.newJob(HelloJob.class)11 // 任务名、组名12 .withIdentity("job11", "group1")13 // 传递参数数据14 .usingJobData("name", name)15 .build();16
17 // 定义一个简单的触发器: 每隔 1 秒执行 1 次,任务永不停止18 SimpleTrigger trigger = TriggerBuilder.newTrigger()19 .withIdentity("trigger1", "group1")20 .withSchedule(SimpleScheduleBuilder21 .simpleSchedule()22 .withIntervalInSeconds(1)23 .repeatForever()24 ).build();25
26 // 开始调度27 scheduler.scheduleJob(job, trigger);28 }29}30
31// 浏览器输入 http://localhost:8080/hello?name=phoenix 进行测试32// 控制台会间隔1秒打印1次 Hello :phoenix33
4) 自动执行
将 JobDetail 和 Trigger 注册为Bean,任务就会随Spring启动而自动触发执行,这对需要随程序启动而执行的作业非常有用。
331public class QuartzConfig {3
4 // 将JobDetail注册为Bean5 6 public JobDetail jobDetail() {7 JobDetail job = JobBuilder.newJob(HelloJob.class)8 .withIdentity("job22", "group2")9 .usingJobData("name", "springboot")10 .storeDurably()11 .build();12
13 return job;14 }15
16 // 将Trigger注册为Bean17 18 public Trigger trigger() {19 SimpleTrigger trigger = TriggerBuilder.newTrigger()20 .forJob(jobDetail())21 .withIdentity("trigger2", "group2")22 .withSchedule(SimpleScheduleBuilder23 .simpleSchedule()24 .withIntervalInSeconds(1)25 .repeatForever()26 ).build();27
28 return trigger;29 }30}31
32// 上面配置在SpringBoot程序启动后会自动打印 Hello :springboot33
4. 集群模式
集群模式可以防止单点故障,减少对业务的影响,同时可以分散单个节点的压力,提升集群整体处理能力。
Quartz基于数据库实现了集群模式,支持高可用、负载均衡(随机算法)、故障恢复等。
1) 添加数据库相关依赖
111<!-- 数据库相关依赖 -->2<!-- 需要提前建立数据库,参考JDBCStore小节 -->3<dependency>4 <groupId>mysql</groupId>5 <artifactId>mysql-connector-java</artifactId>6 <version>8.0.29</version>7</dependency>8<dependency>9 <groupId>org.springframework.boot</groupId>10 <artifactId>spring-boot-starter-data-jpa</artifactId>11</dependency>
2) 添加集群配置
271spring2 datasource3 driverClassNamecom.mysql.cj.jdbc.Driver4 urljdbcmysql//106.53.120.2303306/quartz5 usernameroot6 passwordHyx1477417 quartz8 job-store-typejdbc9 properties10 org11 quartz12 scheduler13 instanceNameClusteredScheduler # 集群名,若使用集群功能,则每一个实例都要使用相同的名字14 instanceIdAUTO # 若是集群下,每个 instanceId 必须唯一,设置 AUTO 自动生成唯一 Id15 threadPool16 classorg.quartz.simpl.SimpleThreadPool17 threadCount2518 threadPriority519 jobStore20 classorg.springframework.scheduling.quartz.LocalDataSourceJobStore21 driverDelegateClassorg.quartz.impl.jdbcjobstore.StdJDBCDelegate22 tablePrefixQRTZ_23 usePropertiestrue # 使用字符串参数,避免了将非 String 类序列化为 BLOB 的类版本问题24 isClusteredtrue # 打开集群模式25 clusterCheckinInterval5000 # 集群存活检测间隔26 misfireThreshold60000 # 最大错过触发事件时间27
3) 创建SchedulerFactory
221public class SchedulerConfig {3
4 5 private DataSource dataSource;6
7 8 private QuartzProperties quartzProperties;9
10 11 public SchedulerFactoryBean schedulerFactoryBean() {12 Properties properties = new Properties();13 properties.putAll(quartzProperties.getProperties());14
15 SchedulerFactoryBean factory = new SchedulerFactoryBean();16 factory.setOverwriteExistingJobs(true);17 factory.setDataSource(dataSource);18 factory.setQuartzProperties(properties);19 return factory;20 }21}22
4) 注意事项
需要启用 JDBCStore 或 TerracottaJobStore(http://www.terracotta.org/quartz) 运行模式。
需要将
isClustered属性设置为 true,并为每个单独的实例需要设置唯一的instanceId。不要在单机模式下使用集群模式,不然会出现时钟同步问题;
不要在集群示例中,运行单机示例,不然会出现数据混乱和不稳定的情况。
关于任务的运行节点是随机的,哪个节点抢到锁就可以执行。
第二节 常用类详解
1. Job和JobDetail
Job是任务的顶层接口,承载具体的业务逻辑,每次调用时都会创建新的实例对象。
JobDetail是任务的调度信息,可以构建和设置Job实例。
301// Job2public interface Job {3 // 执行任务4 void execute(JobExecutionContext context) throws JobExecutionException;5}6
7// JobDetail8public interface JobDetail extends Serializable, Cloneable {9 10 // 任务ID(任务名称+组名称)11 public JobKey getKey();12 13 // 任务描述14 public String getDescription();15 16 // 获取Job实例17 public Class<? extends Job> getJobClass();18 19 // 任务状态信息20 public JobDataMap getJobDataMap();21 22 // 其它23 public boolean isDurable();24 public boolean isPersistJobDataAfterExecution();25 public boolean isConcurrentExectionDisallowed();26 public boolean requestsRecovery();27 public Object clone();28 public JobBuilder getJobBuilder();29}30
2. JobExecutionContext
Job执行的上下文信息,可以访问到 Quartz 运行时的环境以及 Job 本身的明细数据。
481public interface JobExecutionContext {2
3 // 调度器4 public Scheduler getScheduler();5
6 // 触发器7 public Trigger getTrigger();8
9 // 日历10 public Calendar getCalendar();11
12 // JobDetail13 public JobDetail getJobDetail();14
15 // Job实例16 public Job getJobInstance();17 18 // 是否为被恢复的作业19 public boolean isRecovering();20
21 // 合并后的JobDataMap22 public JobDataMap getMergedJobDataMap();23
24 // 实际触发时间25 public Date getFireTime();26
27 // 计划触发时间28 public Date getScheduledFireTime();29
30 // 业务代码的执行结果31 public Object getResult();32 public void setResult(Object result);33
34 // Job的运行时间(ms),在实际完成或异常结束前为-1。35 public long getJobRunTime();36
37 // 上下文Map,可用于监听器和Job之间的数据传递等场景38 public void put(Object key, Object value);39 public Object get(Object key);40
41 // 其它42 public Date getPreviousFireTime();43 public Date getNextFireTime();44 public String getFireInstanceId();45 public TriggerKey getRecoveringTriggerKey() throws IllegalStateException;46 public int getRefireCount();47 48}
3. JobDataMap
一个键为String,值为Object类型的Map,用于存储和传递数据,存在于JobDetail和Trigger等中。
161// 1. 创建JobDetail时进行设置2JobDetail jobDetail = JobBuilder.newJob(TestJob.class)3 .withIdentity("testJob", "testJobGroup")4 // 任务数据5 .usingJobData("key01", "jobDetail01")6 .build();7 8// 2. 定义触发器时进行设置9Trigger trigger = TriggerBuilder.newTrigger()10 .withIdentity("testTrigger", "testTriggerGroup")11 .startNow()12 .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))13 // 触发器数据14 .usingJobData("key01", "trigger01")15 .build();16
在Job类中,可以通过JobExecutionContext获取设置的数据,或通过Quartz框架进行注入。
221public class TestJob implements Job {2
3 // 1.1 存储数据的变量4 private String key01;5
6 // 1.2 注入方法(检测到对应setter方法存在时,Quartz框架会自动注入)7 public void setKey01(String key01) {8 this.key01 = key01;9 }10
11 12 public void execute(JobExecutionContext context) throws JobExecutionException {13 // 2. 方式二:使用 JobExecutionContext 获取设置的数据14 System.out.println(context.getJobDetail().getJobDataMap().get("key01"));15 System.out.println(context.getTrigger().getJobDataMap().get("key01"));16
17 // 1.3 方式一:通过注入的方式使用设置的数据18 // 注意:当JobDetail和Trigger设置的key冲突时,优先使用Trigger的19 System.out.println(key01);20 }21}22
4. Trigger
Trigger用于指定任务触发的时机,其接口和实现类如下,我们一般使用 SimpleTrigger 和 CronTrigger 两种。
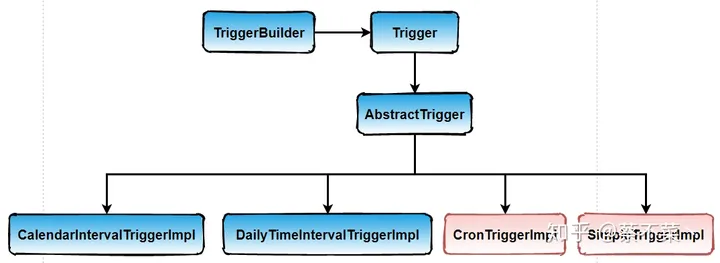
1) SimpleTrigger
SimpleTrigger适用于在特定的日期(或时间)启动,以固定的间隔时间重复执行 n 次的Job任务。
181Trigger trigger = TriggerBuilder.newTrigger()2 // 触发器名称, 触发器组名称3 .withIdentity("testTrigger", "testTriggerGroup")4 // 开始时间5 .startAt(new Date()) // startNow() 表示开始时间为当前时间6 // 结束时间7 .endAt(new Date())8 // Simple策略9 .withSchedule(10 SimpleScheduleBuilder11 // 间隔5s12 .repeatSecondlyForever(5)13 // 最多执行10次14 .withRepeatCount(10)15 )16 .endAt(new Date())17 .build();18
2) CronTrigger
CronTrigger是基于日历的作业调度器,可以做到某个时间点执行,例如“每天的凌晨1点”、“每个工作日的12点”等。
41Trigger trigger = TriggerBuilder.newTrigger()2 .withIdentity("testTrigger", "testTriggerGroup")3 .withSchedule(CronScheduleBuilder.cronSchedule("0/5 * * 6 4 ?"))4 .build();
5. Scheduler
调度器(Scheduler)负责将任务(Job)和触发器(Trigger)整合起来,基于Trigger设定的时间来执行Job。
1) 创建和使用
231// 调度器配置2Properties properties = new Properties();3properties.put(StdSchedulerFactory.PROP_THREAD_POOL_CLASS, "org.quartz.simpl.SimpleThreadPool"); // 线程池定义4properties.put("org.quartz.threadPool.threadCount", "5"); // 默认Scheduler的线程数5
6// 获取调度器7StdSchedulerFactory stdSchedulerFactory = new StdSchedulerFactory();8stdSchedulerFactory.initialize(properties);9Scheduler scheduler = stdSchedulerFactory.getScheduler();10
11// 组合任务和触发器12Date date = scheduler.scheduleJob(jobDetail, trigger); // 返回调度器开始的时间13
14// 启动任务调度15scheduler.start();16
17// 将任务调度挂起(暂停)18scheduler.standby();19
20// 将任务调度关闭21shutdown(true); //表示等待所有正在执行的job执行完毕之后,再关闭Scheduler22shutdown(false); //表示直接关闭Scheduler23
2) 标准调度器
41// 创建一个标准调度器2// 默认加载 quartz.properties 文件中的配置,可由 org.quartz.properties 属性指定文件名3Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();4
quartz.properties 文件配置示例如下,更多配置可参考 StdSchedulerFactory 类代码。
131org.quartz.scheduler.instanceName: DefaultQuartzScheduler2org.quartz.scheduler.rmi.export: false3org.quartz.scheduler.rmi.proxy: false4org.quartz.scheduler.wrapJobExecutionInUserTransaction: false5
6org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool7org.quartz.threadPool.threadCount: 108org.quartz.threadPool.threadPriority: 59org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true10
11org.quartz.jobStore.misfireThreshold: 6000012org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore13
6. Listener
监听器(Listener)用于监听特定事件的发生,以便做出对应的处理,包括任务监听器、触发器监听器、调度器监听器。
1) JobListener
271// JobListener2public class TestJobListener implements JobListener {3 4 public String getName() {5 return "任务监控器01";6 }7
8 9 public void jobToBeExecuted(JobExecutionContext context) {10 String jobName = context.getJobDetail().getKey().getName();11 System.out.println("任务[" + jobName + "]执行前处理");12 }13
14 15 public void jobExecutionVetoed(JobExecutionContext context) {16 String jobName = context.getJobDetail().getKey().getName();17 System.out.println("任务[" + jobName + "]执行前被TriggerListerner否决");18 }19
20 21 public void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException) {22 String jobName = context.getJobDetail().getKey().getName();23 System.out.println("任务[" + jobName + "]执行后处理");24 }25}26
27
2) TriggerListener
381public class TestTriggerListener implements TriggerListener {2 3 public String getName() {4 return "触发器监听器01";5 }6
7 8 public void triggerFired(Trigger trigger, JobExecutionContext context) {9 String triggerName = trigger.getKey().getName();10 System.out.println("触发器[" + triggerName + "]被触发,将执行Job#execute()方法");11 }12
13 14 public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context) {15 if (System.currentTimeMillis() % 2 == 0) {16 String triggerName = trigger.getKey().getName();17 System.out.println("触发器[" + triggerName + "]否决了Job#execute()方法的执行");18 return true;19 } else {20 String triggerName = trigger.getKey().getName();21 System.out.println("触发器[" + triggerName + "]没有否决Job#execute()方法的执行");22 return false;23 }24 }25
26 27 public void triggerMisfired(Trigger trigger) {28 String triggerName = trigger.getKey().getName();29 System.out.println("触发器[" + triggerName + "]错过了触发时机");30 }31
32 33 public void triggerComplete(Trigger trigger, JobExecutionContext context, Trigger.CompletedExecutionInstruction triggerInstructionCode) {34 String triggerName = trigger.getKey().getName();35 System.out.println("触发器[" + triggerName + "]被触发且任务执行完成");36 }37}38
3) SchedulerListener
1031public class TestSchedulerListener implements SchedulerListener {2
3 4 public void jobScheduled(Trigger trigger) {5
6 }7
8 9 public void jobUnscheduled(TriggerKey triggerKey) {10
11 }12
13 14 public void triggerFinalized(Trigger trigger) {15
16 }17
18 19 public void triggerPaused(TriggerKey triggerKey) {20
21 }22
23 24 public void triggersPaused(String triggerGroup) {25
26 }27
28 29 public void triggerResumed(TriggerKey triggerKey) {30
31 }32
33 34 public void triggersResumed(String triggerGroup) {35
36 }37
38 39 public void jobAdded(JobDetail jobDetail) {40
41 }42
43 44 public void jobDeleted(JobKey jobKey) {45
46 }47
48 49 public void jobPaused(JobKey jobKey) {50
51 }52
53 54 public void jobsPaused(String jobGroup) {55
56 }57
58 59 public void jobResumed(JobKey jobKey) {60
61 }62
63 64 public void jobsResumed(String jobGroup) {65
66 }67
68 69 public void schedulerError(String msg, SchedulerException cause) {70
71 }72
73 74 public void schedulerInStandbyMode() {75
76 }77
78 79 public void schedulerStarted() {80
81 }82
83 84 public void schedulerStarting() {85
86 }87
88 89 public void schedulerShutdown() {90
91 }92
93 94 public void schedulerShuttingdown() {95
96 }97
98 99 public void schedulingDataCleared() {100
101 }102}103
4) 注册Listener
421public class TestScheduler4 {2 public static void main(String[] args) throws SchedulerException {3
4 // 1. 定义任务明细, 并与TestJob绑定5 JobDetail jobDetail = JobBuilder.newJob(TestJob.class)6 .withIdentity("testJob", "testJobGroup")7 .build();8
9 // 2. 定义触发器, 立即执行一次, 接着5秒执行一次10 Trigger trigger = TriggerBuilder.newTrigger()11 .withIdentity("testTrigger", "testTriggerGroup")12 .startNow()13 .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))14 .build();15
16 // 3. 获取调度器,并绑定任务和触发器17 Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();18 scheduler.scheduleJob(jobDetail, trigger);19
20 // 4. 添加全局监听器21 ListenerManager listenerManager = scheduler.getListenerManager();22 listenerManager.addJobListener(new TestJobListener(), EverythingMatcher.allJobs());23 listenerManager.addTriggerListener(new TestTriggerListener(), EverythingMatcher.allTriggers());24 listenerManager.addSchedulerListener(new TestSchedulerListener());25
26 // 5. 开启调度27 scheduler.start();28 }29}30
31
32触发器[testTrigger]被触发,将执行Job#execute()方法33触发器[testTrigger]否决了Job#execute()方法的执行34任务[testJob]执行前被TriggerListerner否决35
36触发器[testTrigger]被触发,将执行Job#execute()方法37触发器[testTrigger]没有否决Job#execute()方法的执行38任务[testJob]执行前处理39START DATA BACKUP, current time :2024-05-07 17:45:0540任务[testJob]执行后处理41触发器[testTrigger]被触发且任务执行完成42
7. JobStore
作业存储(JobStore)用于定义Quartz运行时任务的存储方式。
1) RAMJobStore
RAMJobStore是基于内存的存储模式,调度信息保存在内存中,性能较高,但应用程序结束或崩溃时数据将丢失。
31# 设置为内存模式(需配合StdSchedulerFactory使用)2org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore3
2) JDBCJobStore
JDBCJobStore是基于数据库的存储模式,调度信息保存在数据库中,可以持久化保存调度信息,但是性能取决于数据库性能。
下面是使用步骤:
建库建表:
11-- 见附录引入数据库依赖:
61<!-- 添加数据库依赖 -->2<dependency>3<groupId>mysql</groupId>4<artifactId>mysql-connector-java</artifactId>5<version>8.0.29</version>6</dependency>修改配置文件:
221org.quartz.scheduler.instanceName: DefaultQuartzScheduler2org.quartz.scheduler.rmi.export: false3org.quartz.scheduler.rmi.proxy: false4org.quartz.scheduler.wrapJobExecutionInUserTransaction: false56org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool7org.quartz.threadPool.threadCount: 108org.quartz.threadPool.threadPriority: 59org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true1011org.quartz.jobStore.misfireThreshold: 6000012org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX13org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate14org.quartz.jobStore.tablePrefix = QRTZ_15org.quartz.jobStore.dataSource = myDS1617org.quartz.dataSource.myDS.driver = com.mysql.cj.jdbc.Driver18org.quartz.dataSource.myDS.URL = jdbc:mysql://127.0.0.1:3306/quartz_demo19org.quartz.dataSource.myDS.user = root20org.quartz.dataSource.myDS.password = test12345621org.quartz.dataSource.myDS.maxConnections = 3022
执行任务调度后,可以在 QRTZ_JOB_DETAILS 表查看任务明细数据。

第三节 扩展补充
1. Cron表达式简介
Cron表达式由7个子表达式组成,分别是:
| 字段 | 是否必填 | 允许值 | 可用特殊字符 |
|---|---|---|---|
| 秒 | 是 | 0-59 | , - * / |
| 分 | 是 | 0-59 | , - * / |
| 时 | 是 | 0-23 | , - * / |
| 日(月中的哪几天) | 是 | 1-31 | , - * / ? L C W |
| 月 | 是 | 1-12 或 JAN-DEC | , - * / |
| 周(周中的哪几天) | 是 | 1-7 或 SUN-SAT | , - * / ? L C # |
| 年 | 否 | 不填写 或 1970-2099 | , - * / |
可用的特殊字符及含义如下:
| 特殊字符含义 | |
|---|---|
* | 可用在所有字段中,表示对应时间域的每一个时刻,如:在分钟字段时,表示“每分钟” |
? | 该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于点位符 |
- | 表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12 |
, | 表达一个列表值,如在星期字段中使用“MON,WED,FRI”,则表示星期一,星期三和星期五 |
/ | x/y表达一个等步长序列,x为起始值,y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒,而5/15在分钟字段中表示5,20,35,50,你也可以使用*/y,它等同于0/y |
L | 该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中意思不同。L在日期字段中,表示这个月份的最后一天,如一月的31号,非闰年二月的28号;如果L用在星期中,则表示星期六,等同于7。但是,如果L出现在星期字段里,而且在前面有一个数值X,则表示“这个月的最后X天”,例如,6L表示该月的最后星期五 |
W | 该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如15W表示离该月15号最近的工作日,如果该月15号是星期六,则匹配14号星期五;如果15日是星期日,则匹配16号星期一;如果15号是星期二,那结果就是15号星期二。但必须注意关联的匹配日期不能够跨月,如你指定1W,如果1号是星期六,结果匹配的是3号星期一,而非上个月最后的那天。W字符串只能指定单一日期,而不能指定日期范围 |
# | 该字符只能在星期字段中使用,表示当月某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三,假设当月没有第五个星期三,忽略不触发 |
Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。
181"0 0 10,14,16 * * ?" 每天上午10点,下午2点,4点2"0 0/30 9-17 * * ?" 朝九晚五工作时间内每半小时,从0分开始每隔30分钟发送一次3"0 0 12 ? * WED" 表示每个星期三中午12点 4"0 0 12 * * ?" 每天中午12点触发 5"0 15 10 ? * *" 每天上午10:15触发 6"0 15 10 * * ?" 每天上午10:15触发 7"0 15 10 * * ? *" 每天上午10:15触发 8"0 15 10 * * ? 2005" 2005年的每天上午10:15触发 9"0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发 10"0 0/55 14 * * ?" 在每天下午2点到下午2:55期间,从0开始到55分钟触发 11"0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发 12"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发 13"0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发 14"0 15 10 15 * ?" 每月15日上午10:15触发 15"0 15 10 L * ?" 每月最后一日的上午10:15触发 16"0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发 17"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发 18"0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
2. Quartz表结构
1861-- Quartz表结构脚本(MySql版)2-- Quartz代码中使用大写表名,建表时注意区分表名大小写3-- 表字段含义参考:https://blog.csdn.net/sqlgao22/article/details/1006972144
5-- 建库6-- drop database if exists quartz;7-- create database `quartz` character set 'utf8' collate 'utf8_general_ci';8use quartz;9
10-- 调度器信息11DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;12CREATE TABLE QRTZ_SCHEDULER_STATE (13 SCHED_NAME VARCHAR(120) NOT NULL,14 INSTANCE_NAME VARCHAR(200) NOT NULL,15 LAST_CHECKIN_TIME BIGINT(13) NOT NULL,16 CHECKIN_INTERVAL BIGINT(13) NOT NULL,17 PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)18) ENGINE=INNODB;19
20-- 任务信息21DROP TABLE IF EXISTS QRTZ_JOB_DETAILS; 22CREATE TABLE QRTZ_JOB_DETAILS(23 SCHED_NAME VARCHAR(120) NOT NULL,24 JOB_NAME VARCHAR(200) NOT NULL,25 JOB_GROUP VARCHAR(200) NOT NULL,26 DESCRIPTION VARCHAR(250) NULL,27 JOB_CLASS_NAME VARCHAR(250) NOT NULL,28 IS_DURABLE VARCHAR(1) NOT NULL,29 IS_NONCONCURRENT VARCHAR(1) NOT NULL,30 IS_UPDATE_DATA VARCHAR(1) NOT NULL,31 REQUESTS_RECOVERY VARCHAR(1) NOT NULL,32 JOB_DATA BLOB NULL,33 PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)34) ENGINE=INNODB;35CREATE INDEX IDX_QRTZ_J_REQ_RECOVERY ON QRTZ_JOB_DETAILS(SCHED_NAME,REQUESTS_RECOVERY);36CREATE INDEX IDX_QRTZ_J_GRP ON QRTZ_JOB_DETAILS(SCHED_NAME,JOB_GROUP);37
38-- 日历信息39DROP TABLE IF EXISTS QRTZ_CALENDARS; 40CREATE TABLE QRTZ_CALENDARS (41 SCHED_NAME VARCHAR(120) NOT NULL,42 CALENDAR_NAME VARCHAR(200) NOT NULL,43 CALENDAR BLOB NOT NULL,44 PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)45) ENGINE=INNODB;46
47-- 程序的悲观锁信息48DROP TABLE IF EXISTS QRTZ_LOCKS; 49CREATE TABLE QRTZ_LOCKS (50 SCHED_NAME VARCHAR(120) NOT NULL,51 LOCK_NAME VARCHAR(40) NOT NULL,52 PRIMARY KEY (SCHED_NAME,LOCK_NAME)53) ENGINE=INNODB;54
55-- 已配置的触发器信息56DROP TABLE IF EXISTS QRTZ_TRIGGERS; 57CREATE TABLE QRTZ_TRIGGERS (58 SCHED_NAME VARCHAR(120) NOT NULL,59 TRIGGER_NAME VARCHAR(200) NOT NULL,60 TRIGGER_GROUP VARCHAR(200) NOT NULL,61 JOB_NAME VARCHAR(200) NOT NULL,62 JOB_GROUP VARCHAR(200) NOT NULL,63 DESCRIPTION VARCHAR(250) NULL,64 NEXT_FIRE_TIME BIGINT(13) NULL,65 PREV_FIRE_TIME BIGINT(13) NULL,66 PRIORITY INTEGER NULL,67 TRIGGER_STATE VARCHAR(16) NOT NULL,68 TRIGGER_TYPE VARCHAR(8) NOT NULL,69 START_TIME BIGINT(13) NOT NULL,70 END_TIME BIGINT(13) NULL,71 CALENDAR_NAME VARCHAR(200) NULL,72 MISFIRE_INSTR SMALLINT(2) NULL,73 JOB_DATA BLOB NULL,74 PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),75 FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)76 REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)77) ENGINE=INNODB;78CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);79CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);80CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);81CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);82CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);83CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);84CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);85CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);86CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);87CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);88CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);89CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);90
91-- 简单触发器信息92DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;93CREATE TABLE QRTZ_SIMPLE_TRIGGERS (94 SCHED_NAME VARCHAR(120) NOT NULL,95 TRIGGER_NAME VARCHAR(200) NOT NULL,96 TRIGGER_GROUP VARCHAR(200) NOT NULL,97 REPEAT_COUNT BIGINT(7) NOT NULL,98 REPEAT_INTERVAL BIGINT(12) NOT NULL,99 TIMES_TRIGGERED BIGINT(10) NOT NULL,100 PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),101 FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)102 REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)103) ENGINE=INNODB;104
105-- Cron触发器信息106DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;107CREATE TABLE QRTZ_CRON_TRIGGERS (108 SCHED_NAME VARCHAR(120) NOT NULL,109 TRIGGER_NAME VARCHAR(200) NOT NULL,110 TRIGGER_GROUP VARCHAR(200) NOT NULL,111 CRON_EXPRESSION VARCHAR(120) NOT NULL,112 TIME_ZONE_ID VARCHAR(80),113 PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),114 FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)115 REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)116) ENGINE=INNODB;117
118-- CalendarIntervalTrigger和DailyTimeIntervalTrigger信息119DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;120CREATE TABLE QRTZ_SIMPROP_TRIGGERS (121 SCHED_NAME VARCHAR(120) NOT NULL,122 TRIGGER_NAME VARCHAR(200) NOT NULL,123 TRIGGER_GROUP VARCHAR(200) NOT NULL,124 STR_PROP_1 VARCHAR(512) NULL,125 STR_PROP_2 VARCHAR(512) NULL,126 STR_PROP_3 VARCHAR(512) NULL,127 INT_PROP_1 INT NULL,128 INT_PROP_2 INT NULL,129 LONG_PROP_1 BIGINT NULL,130 LONG_PROP_2 BIGINT NULL,131 DEC_PROP_1 NUMERIC(13,4) NULL,132 DEC_PROP_2 NUMERIC(13,4) NULL,133 BOOL_PROP_1 VARCHAR(1) NULL,134 BOOL_PROP_2 VARCHAR(1) NULL,135 PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),136 FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)137 REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)138) ENGINE=INNODB;139
140-- 触发器作为BLOB类型存储141DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;142CREATE TABLE QRTZ_BLOB_TRIGGERS (143 SCHED_NAME VARCHAR(120) NOT NULL,144 TRIGGER_NAME VARCHAR(200) NOT NULL,145 TRIGGER_GROUP VARCHAR(200) NOT NULL,146 BLOB_DATA BLOB NULL,147 PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),148 INDEX (SCHED_NAME,TRIGGER_NAME, TRIGGER_GROUP),149 FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)150 REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)151) ENGINE=INNODB;152
153-- 已触发的触发器信息154DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS; 155CREATE TABLE QRTZ_FIRED_TRIGGERS (156 SCHED_NAME VARCHAR(120) NOT NULL,157 ENTRY_ID VARCHAR(95) NOT NULL,158 TRIGGER_NAME VARCHAR(200) NOT NULL,159 TRIGGER_GROUP VARCHAR(200) NOT NULL,160 INSTANCE_NAME VARCHAR(200) NOT NULL,161 FIRED_TIME BIGINT(13) NOT NULL,162 SCHED_TIME BIGINT(13) NOT NULL,163 PRIORITY INTEGER NOT NULL,164 STATE VARCHAR(16) NOT NULL,165 JOB_NAME VARCHAR(200) NULL,166 JOB_GROUP VARCHAR(200) NULL,167 IS_NONCONCURRENT VARCHAR(1) NULL,168 REQUESTS_RECOVERY VARCHAR(1) NULL,169 PRIMARY KEY (SCHED_NAME,ENTRY_ID)170) ENGINE=INNODB;171CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);172CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);173CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);174CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);175CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);176CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);177
178-- 已暂停的触发器信息179DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS; 180CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (181 SCHED_NAME VARCHAR(120) NOT NULL,182 TRIGGER_GROUP VARCHAR(200) NOT NULL,183 PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)184) ENGINE=INNODB;185
186COMMIT;
第06章_Elasticsearch
第一节 索引操作
1. 创建索引
71PUT /goods2{3 "settings": {4 "number_of_shards": 1,5 "number_of_replicas": 06 }7}
2. 删除索引
11DELETE /goods
3. 查看索引信息
11GET /goods
第二节 映射操作
1. 创建映射
161PUT /goods/_mapping/docs2{3 "properties": {4 "title":{5 "type": "text",6 "analyzer": "ik_max_word"7 },8 "images":{9 "type": "keyword",10 "index": false11 },12 "price":{13 "type": "double"14 }15 }16}
2. 查看映射信息
11GET /goods/_mapping
第三节 数据增删改
1. 新增数据
81POST /goods/docs/12{3 "title":"小米手机",4 "images":"http://image.leyou.com/12479122.jpg",5 "price":2899.006}7
8tips:新增数据中存在映射没有的字段,则会自动更新映射信息
2. 修改数据
81PUT /goods/docs/12{3 "title":"小米手机",4 "images":"http://image.leyou.com/12479122.jpg",5 "price":2799.006}7
8tips:只需将新增的POST请求改为PUT就行了
3. 删除数据
11DELETE /goods/docs/1
4. 批量新增
371PUT /cars2{3 "settings": {4 "number_of_shards": 1,5 "number_of_replicas": 06 },7 "mappings": {8 "transactions": {9 "properties": {10 "color": {11 "type": "keyword"12 },13 "make": {14 "type": "keyword"15 }16 }17 }18 }19}20
21POST /cars/transactions/_bulk22{ "index": {}}23{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }24{ "index": {}}25{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }26{ "index": {}}27{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }28{ "index": {}}29{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }30{ "index": {}}31{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }32{ "index": {}}33{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }34{ "index": {}}35{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }36{ "index": {}}37{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
第四节 数据查询
1. 查询所有数据
61GET /goods/_search2{3 "query": {4 "match_all": {}5 }6}
2. 分词匹配查询
1) 分词or匹配
81GET /goods/_search2{3 "query": {4 "match": {5 "title": "小米手机"6 }7 }8}2) 分词and匹配
111GET /goods/_search2{3 "query": {4 "match": {5 "title": {6 "query": "小米手机",7 "operator": "and"8 }9 }10 }11}3) 分词比例匹配
111GET /goods/_search2{3 "query": {4 "match": {5 "title": {6 "query": "小米手机",7 "minimum_should_match": "75%"8 }9 }10 }11}
3. 多字段分词匹配查询
91GET /goods/_search2{3 "query": {4 "multi_match": {5 "query": "小米",6 "fields": ["title","subTitle"]7 }8 }9}
4. 词条匹配查询
171GET goods/_search2{3 "query": {4 "term": {5 "price": 2799.006 }7 }8}9
10GET /goods/_search11{12 "query":{13 "terms":{14 "price":[2799.00,2899.00,3899.00]15 }16 }17}
5. 范围查询
111GET /goods/_search2{3 "query": {4 "range": {5 "price": {6 "gte": 2500,7 "lte": 30008 }9 }10 }11}
6. 模糊查询
111GET goods/_search2{3 "query": {4 "fuzzy": {5 "title": {6 "value": "小木",7 "fuzziness": 28 }9 }10 }11}
7. 布尔查询(高级查询)
311GET goods/_search2{3 "query": {4 "bool": {5 "must": [6 {"match": {7 "title": "手机"8 }}9 ],10 "must_not": [11 {"term": {12 "price": {13 "value": "2799"14 }15 }}16 ],17 "should": [18 {"multi_match": {19 "query": "小米",20 "fields": ["title","subTitle"]21 }22 }23 ]24 }25 }26}27
28上述语句地含义为:291. 必须满足:"title包含手机"302. 不能满足:"price为2799"313. 最好满足:"title或subTitle包含小米"
8. 查询过滤
201GET goods/_search2{3 "query": {4 "bool": {5 "must": [6 {"match": {7 "title": "小米"8 }}9 ],10 "filter": {11 "range": {12 "price": {13 "gte": 2699,14 "lte": 279915 }16 }17 }18 }19 }20}
第五节 结果集操作
1. 结果列过滤
171GET /goods/_search2{3 "_source": ["title","price"], 4 "query": {5 "match_all": {}6 }7}8
9GET /goods/_search10{11 "_source": {12 "excludes": ["price","images"]13 }, 14 "query": {15 "match_all": {}16 }17}
2. 结果排序
1) 单字段排序
131GET goods/_search2{3 "query": {4 "match_all": {}5 },6 "sort": [7 {8 "price": {9 "order": "desc"10 }11 }12 ]13}2) 多字段排序
101GET /goods/_search2{3 "query": {4 "match_all": {}5 },6 "sort": [7 { "price": { "order": "desc" }},8 { "_score": { "order": "desc" }}9 ]10}
3. 结果聚合
1) 聚合为桶
111GET /cars/_search2{3 "size": 0,4 "aggs": {5 "popular_colors": {6 "terms": {7 "field": "color"8 }9 }10 }11}2) 桶内度量
181GET /cars/_search2{3 "size": 0,4 "aggs": {5 "popular_colors": {6 "terms": {7 "field": "color"8 },9 "aggs": {10 "avg_price": {11 "avg": {12 "field": "price"13 }14 }15 }16 }17 }18}3) 桶内嵌套桶
231GET /cars/_search2{3 "size": 0,4 "aggs": {5 "popular_colors": {6 "terms": {7 "field": "color"8 },9 "aggs": {10 "avg_price": {11 "avg": {12 "field": "price"13 }14 },15 "maker":{16 "terms": {17 "field": "make"18 }19 }20 }21 }22 }23}4) 阶梯分桶
131GET cars/_search2{3 "size": 0,4 "aggs": {5 "price_agg": {6 "histogram": {7 "field": "price",8 "interval": 5000,9 "min_doc_count": 110 }11 }12 }13}