第01篇_Oracle
第01章_Oracle概述
第一节 Oracle简介
1. 什么是Oracle?
Oracle是美国甲骨文公司开发的一款关系型数据库管理系统(RDBMS),是市场上最流行的商业数据库之一。
第二节 安装部署
1. Windows版本安装
详情见“部署文档”目录下相关文档说明!
2. Linux版本安装
详情见“部署文档”目录下相关文档说明!
3. 配置文件
- listener.ora:监听器配置文件。监听器用于侦听客户端的连接请求以及建立客户端和服务器端连接通道,默认端口为1521。
- tnsnames.ora:网络服务名配置文件。配置客户端到服务器端的连接服务,包括客户端要连接到的服务器和数据库的配置信息。
- sqlnet.ora:连接属性配置文件。控制和管理Oracle连接的属性,根据参数作用的不同决定在 Client 端配置还是在 Server 端配置。
4. 监听程序
Oracle监听程序用于监听远程连接,在远程访问数据库时必不可少。
xxxxxxxxxx91# 查看监听状态2lsnrctl status 3
4# 启动监听程序5lsnrctl start 6
7# 停止监听程序8lsnrctl stop 9
第三节 客户端
1. 命令行客户端
xxxxxxxxxx461# 用户登录2sqlplus 用户名/密码[ @服务名 | @IP:端口/实例名 ] [ as sysdba | as sysoper ] 3sqlplus / as sysdba # 操作系统用户登录默认数据库4sqlplus /nolog # 不暴露密码的登陆方式SQL5sqlplus sys/123@ORCL01 as sysdba # 系统用户通过服务名连接6sqlplus sys/123@127.0.0.1:1521/ORCL01 as sysdba # 系统用户通过连接字符串连接7sqlplus kfms/123@ORCL01 # 普通用户通过服务名连接8sqlplus /nolog # 仅登录SqlPlus,不连接数据库9
10# 用户登出11[ exit | quit ]12
13# 连接到其它用户14connect 用户名/密码[ @服务名 | @IP:端口/实例名 ] [ as sysdba | as sysoper ]15
16# 显示登录用户17show user18
19# 显示表结构20desc 表名21
22# 执行Shell命令23host [shell命令]24host mkdir /tmp/test01 # 在SqlPlus中新建目录25
26# 编辑上一条命令27ed # 语句末尾不加分号,编辑完成后用”/”运行28
29# 导出SQL执行日志到文件30spool C:\sql.txt31>>执行一批SQL语句<<32spool off33
34# SqlPlus配置35set timing [ on | off ] # 打开与关闭命令记时36set feedback [ on | off | num ] # 打开与关闭结果显示(num表示超过n行才显示)37set linesize xx # 设置行尺寸38set pagesize xx # 设置页尺寸39col 字段名 for 99999 # 修改数字的列宽40col 字段名 for a20 # 修改字符的列宽41
42# 执行脚本43start xxx.sql # 执行SQL脚本,与@效果一致44@xxx.sql # 执行SQL脚本45sqlplus -S ${DB_USER}/${DB_PASSWORD}@${DB_SERVER} <create_tables.sql >./log/create_tables.log46
2. 其它客户端
- 官方Web客户端:Enterprise Manager(主要在Oracle11g版本使用,相关使用说明参考“部署文档”目录下相关文档)。
- 官方GUI客户端:SqlDeveloper、PLSQL Developer 13等。
- 通用GUI客户端:DataGrip、Navicat、Dbeaver等。
第四节 体系结构
1. 磁盘文件
Oracle数据库在运行过程中使用的一些文件如下:
- 参数文件:用于定义实例启动时的选项,以及配置实例和数据库的特征,如:OracleBase\admin\ORCL01\pfile\init.ora.8720212396、OracleHome\database\SPFILEORCL01.ORA等,在实例启动后也可通过
show parameter / alter system进行查看和修改。 - 控制文件:在数据库启动时,要根据控制文件的信息查找数据文件。控制文件记录了以下关键信息:数据文件的位置和大小、重做日志文件的位置及大小、数据库名称及创建时间、日志序列号等。
- 数据文件:包含用户数据、程序数据、元数据和数据字典的文件,每个数据文件都有自己所属的表空间。
- 重做日志文件:记录了对数据的所有更改信息,并提供一种数据恢复机制,如果数据库服务器发生崩溃,但未丢失任何数据文件,那么实例便可使用这些文件中的信息恢复数据库。
- 归档日志文件:使用这些文件和数据库备份,可以恢复丢失的数据文件。也就是说,归档日志能够恢复还原的数据文件。
- 口令文件:允许sysdba、sysoper 和sysasm 远程连接到实例并执行管理任务。
- 跟踪日志文件:每一个服务器和后台进程都可以对关联的跟踪文件进行写操作。如果在进程中检测到内部错误,进程就会将关于错误的信息转储到进程的跟踪文件。
- 预警日志文件:这些是特殊的跟踪文件,又称为预警日志。数据库预警日志是按时间顺序列出的消息日志和错误日志。
2. 逻辑结构
Oracle逻辑结构从大到小依次分为:集群 -> 实例 -> 数据库 -> 用户/表空间/模式 -> 段 -> 区 -> 数据块等。
集群:Oracle实现高可用的手段之一,主要有
RAC集群(多实例共享存储模型)和DataGrip集群(多实例多存储模型)。实例:可以理解为一系列后台进程的组合,对各类数据进行管理。在多租户模式下,一个实例由一个CDB和多个PDB组成。
数据库:可以理解为一系列磁盘文件的集合。一个数据库可以被多个用户访问,创建多个模式、表空间等。
用户:数据库访问对象,一个数据库下可创建多个用户。
表空间:可以理解为虚拟文件夹,包含1个或多个数据文件,在创建表、索引等时可指定所在的表空间。其分类如下:
- SYSTEM表空间:包含数据字典、存储过程、触发器和系统回滚段等系统信息,是数据库运行的必要条件,其名称是不可更改的。
- SYSAUX表空间:系统表空间的辅助表空间,主要存储除数据字典以外的其他对象。
- UNDO表空间:保存用户回滚段信息,如:UNDOTBS1。
- 用户表空间:存放用户的数据和私有信息,如:USERS、TEST_TS01。
- TEMP表空间:存储Oracle数据库运行期间所产生的临时数据。当数据库关闭后,临时表空间中所有数据将全部被清除。
模式:可以理解为多个表、索引、视图等数据库对象的集合。
段/区/块:表空间可由多个段(数据段/索引段/回滚段/临时段)组成,段可跨文件,当段空间不足时,以区为单位分配空间。每个区又由多个数据块构成,块是读写的最小单位。
3. 内存分区
Oracle占用的内存大致可分为系统全局区(SGA)、进程全局区(PGA)、用户全局区(UGA):
SGA:在实例启动时分配的内存,可以被多个用户共享,包含数据信息或控制信息等内容,相关可通过
v$sga视图查看。- 数据块缓存区:用于缓存数据块,由参数文件 init.ora 中的 DB_LOCK_BUFFERS 参数配置。
- 重做日志缓冲区:REDO文件的缓冲,保存对数据库进行的修改,以便在数据库恢复过程中用于向前滚动操作,由 LOG_BUFFER 参数配置。
- 共享池:由 SHARED_POOL_SIZE 参数配置,包括字典缓存区和库缓存区。前者用于缓存用户、表名、权限等系统信息;后者用于缓存执行计划及SQL语句的语法分析树等。
- 大型池:是一个可选内存区,作为SQL共享池的备用池,防止大量的不常用SQL(如备份/恢复时)导致SQL共享池命中率变低,由LARGE_POOL_SIZE 或 LARGE_POOL_MIN_ALLOC 设置。
- Java池:为Java命令提供语法分析,由 JAVA_POOL_SIZE 参数设置。
- 多缓冲池:可以在SGA中创建多个缓冲池,能够用多个缓冲池把大数据集与其他的应用程序分开,以减少它们争夺数据块缓存区内相同资源的可能性。
- 流池:由 Oracle Streams 使用。
PGA:在用户进程连接到数据库并创建一个会话时自动分配,当会话结束,PAG就会释放,相关信息可通过
v$process视图查看。UGA:用于存储用户进程会话状态。当通过共享服务器连接Oracle时,UGA包含在SGA中,当通过专有服务器连接时,包含在PGA中。
4. 主要服务/进程
在Windows机器上,Oracle实例主要的服务如下(实例名为ORCL01):
- OracleServiceORCL01:数据块实例的核心进程。
- OracleOraDB19Home1TNSListener:监听器进程(用于远程访问数据库)。
- OracleVssWriterORCL01:卷映射拷贝写入进程。
在Linux下,Oracle实例主要的进程如下(实例名为pdborcl):
- oraclepdborcl:服务端进程(SPID),由Oracle实例自动创建,用于处理客户端进程的请求和响应。
- tnslsnr:监听器进程,用于远程访问数据库。
- ora_smon_pdborcl:系统监控进程,用于执行实例恢复,清空未使用的临时段,合并数据字典管理的表空间里的连续的空闲区块等。
- ora_pmon_pdborcl:进程监控进程,负责监控和唤醒调度进程和服务器进程,清理buffer cache以及释放客户端进程使用的资源等。
- ora_dbw0_pdborcl:数据写进程,在合适时机(缓冲数量或时间超限/无可用缓冲区/检查点发生/表删除或截断/联机备份等)将缓冲区数据写入数据文件。
- ora_lgwr_pdborcl:日志写进程,在合适时机(缓冲尺寸或时间超限/commit/日志切换等)将日志缓冲区写入日志文件。
- ora_ckpt_pdborcl:检查点进程,负责更新控制文件和数据文件的头文件的检查点信息,保证数据库日志文件和数据文件的同步。
- ora_reco_pdborcl:在具有分布式选项时所使用的一个进程,自动地解决在分布式事务中的故障。
- ARCn:归档进程,发生日志切换时将重做日志文件复制到归档存储器。当日志是为ARCHIVELOG使用方式、并可自动地归档时ARCH进程才存在。
- Dnnn:调度进程,允许用户进程共享有限的服务器进程。
- LCKn:在具有并行服务器选件环境下使用,可多至10个进程(LCK0,LCK1……,LCK9),用于实例间的封锁。
其它进程可通过ps -ef | grep oracle或ps -ef | grep ora_等查看。
注意:
- 在专用服务器模式,客户端进程和服务端进程一一对应;在共享服务器模式,一个服务端进程可同时服务多个客户端进程。
- 进程监控(PMON)进程、系统监控(SMON)进程、数据写入(DBWR)进程、日志写入(LGWR)进程、检查点(CKPT)进程是必须启动的,否则实例无法启动成功。
第五节 启动和关闭流程
启动或关闭数据库需要以SYSDBA/SYSOPER权限登录:
xxxxxxxxxx41#su - oracle # 切换至Oracle用户及其shell环境2$lsnrctl [start|stop] # 启动监听/停止监听(可以用 lsnrctl status 查看监听状态)3$sqlplus / as sysdba # 以dba身份进入sqlplus4
1. 三阶段启动
Oracle数据库启动流程分为三个阶段:
- nomount:加载参数文件,启动实例,创建后台进程,分配SGA区,但没有加载控制文件、数据文件、重做日志文件等。
- mount:在 nomount 的基础上,加载控制文件。
- open:在 mount 的基础上,加载数据文件等其它数据,并打开数据库,此时非DBA用户才可访问数据库。
xxxxxxxxxx71# 数据库启动2# nomount/mount/open:启动到哪一阶段,默认为open。3# force:强制关闭并重新启动数据库。4# restrict:以受限会话方式启动数据库,只允许具有restricted session或者create session权限的用户访问数据库。5# pfile:用于指定启动实例时所使用的文本参数文件。6startup[nomount|mount|open|force] [restrict][pfile=filename]7
2. 转换启动阶段
在进行某些特定的管理和维护操作时,需要处于特定的阶段:
| 启动阶段 | 可执行的操作 |
|---|---|
| nomount | 创建新的数据库、重建控制文件等 |
| mount | 重命名数据文件、添加删除或重命名重做日志文件、执行数据库的完全恢复操作、改变数据库的归档模式等 |
| open | 业务数据的增删改查等 |
转换启动阶段命令如下:
xxxxxxxxxx71# 数据库启动2startup nomount -- 启动到 nomount 阶段3
4# 数据库启动状态转换5alter database mount; -- 转换到 mount 阶段6alter database open; -- 转换到 open 阶段 7
3. 四种关闭模式
关闭Oracle数据库使用shutdown命令,它有四种模式:
- 正常关闭模式:阻止新建连接,在等待已有连接主动断开后才关闭数据库,在对关闭数据库的时间没有限制时使用。
- 立即关闭模式:阻止新建连接和新建事务,将未提交的事务进行回滚,然后直接关闭数据库。
- 事务关闭模式:正常关闭和立即关闭的一个折中,在等待所有未提交的事务完成后,再关闭数据库。
- 终止关闭模式:当其它三种方式无法关闭数据库时,才使用这种方式,说明数据库发生了严重错误,使用该方式可能丢失数据。
xxxxxxxxxx31# 关闭数据库2shutdown [normal | transactional | immediate | abort]3
4. 会话受限状态
在启动数据库时,如果加上restrict参数,将会进入受限状态,只允许具有restricted session或者create session权限的用户访问数据库。
通过如下命令可进行受限状态的切换:
若是启动数据库的时候设置为受限状态,在完成管理工作后,需要将数据库恢复为非受限状态:
xxxxxxxxxx21# 切换受限状态2alter system [ enable | disable ] restricted session;
5. 读写/只读状态
正常启动模式下,数据库默认处于读写状态,但有时候也需要将数据库设置为只读状态,保证用户只能查询数据,但不能以任何方式对数据库对象进行修改。
xxxxxxxxxx121-- 查看数据库读写状态2select DBID, NAME, OPEN_MODE from v$database;3
4-- 切换只读状态5shutdown immediate6startup mount7alter database open read only;8
9-- 切换读写状态10shutdown immediate11startup open read write;12
6. 静默/挂起状态
静默状态和挂起状态是两种特殊的数据库状态,利用这两种数据库状态,数据库管理员可以完成一些特殊的管理和维护操作。
- 静默状态:在静默状态下,只有SYS和SYSTEM用户才能够在数据库中执行查询、更新操作,运行PL/SQL程序,任何非管理员用户都不能在数据库中执行任何操作。在数据库运行过程中,执行如下的语句将进入和退出静默状态:
xxxxxxxxxx51-- 进入静默状态2alter system quiesce restricted;3
4-- 退出静默状态5alter system unquiesce;- 挂起状态:当数据库处于挂起状态时,数据库所有的物理文件(控制文件、数据文件和重做日志文件)的I/O操作都被暂停,这样能够保证数据库在没有任何I/O操作的情况下进行物理备份。
xxxxxxxxxx51-- 修改为挂起状态2alter system suspend;3
4-- 修改为静默状态5alter system resume;挂起状态与静默状态的区别是:挂起状态并不禁止非管理员用户进行数据库操作,只是暂时停止所有用户的I/O操作。
第02章_实例管理
第一节 数据库
1. 查看数据库信息
xxxxxxxxxx161# 查看当前数据库容器(CDB)2select sys_context('USERENV','CON_NAME') from dual; -- show con_name;3
4# 查看当前PDB数据库(注:如当前会话位于CDB$ROOT容器下,则可查看所有PDB信息,若位于某一PDB下,则只可查看当前PDB信息)5select con_id,dbid,name,open_mode from v$pdbs; -- show pdbs6CON_ID CON_NAME OPEN MODE RESTRICTED7------ ------------------------------ ---------- ----------8 2 PDB$SEED READ ONLY NO9 3 PDB1 READ WRITE NO10 4 PDB2 READ WRITE NO11 5 PTESTUAT READ WRITE NO12 7 PDB3 MOUNTED13 14# 查看数据库内部的编码方式15select userenv('language') from dual;16
2. 新建/销毁数据库
xxxxxxxxxx11
3. 打开/切换数据库
在Oracle12c及之后,一个实例可以创建多个PDB数据库,打开和切换方式如下:
xxxxxxxxxx91# 打开PDB数据库2alter pluggable database pdb1 open;3
4# 切换到CDB5alter session set container=CDB$ROOT;6
7# 切换到某PDB8alter session set container = pdborcl;9
注意:
- 在Oracle中,无法使用
use xxx语法来切换数据库,必须执行 alter session 命令。
4. 数据库配置参数
xxxxxxxxxx81-- 查看数据库参数2SELECT NAME, VALUE, ISDEFAULT, DESCRIPTION FROM V$PARAMETER WHERE NAME = 'sga_max_size';3
4-- 修改数据库参数5ALTER SYSTEM SET sga_max_size=8192M SCOPE=SPFILE;6
7-- 创建SPFILE文件来修改参数(需重启生效)8CREATE PFILE='<pfile路径>' FROM SPFILE;常用数据库参数如下:
| 参数名称 | 参数描述 |
|---|---|
| sga_max_size | 指定 SGA 的最大大小 |
| sga_target | 指定 SGA 的目标大小 |
| pga_aggregate_target | 指定 PGA 的目标大小 |
| db_cache_size | 指定数据库缓存大小 |
| shared_pool_size | 指定共享池大小 |
| processes | 指定可以同时运行的用户进程数 |
| sessions | 指定可以同时连接到数据库的用户数 |
| undo_retention | 指定事务回滚数据保留时间 |
第二节 用户
1. 查询用户信息
xxxxxxxxxx91-- 查询数据库所有用户2select * from dba_users; 3
4-- 查询可访问的用户5select * from all_users; 6
7-- 查询当前用户8select * from user_users; 9
注:在创建实例时,会创建若干个内置用户,它们分别有不同的用途。
- sys:权限最大的超级用户,相当于SQL server中的sa帐户,只能以系统管理员(sysdba)或系统操作员(sysoper)的权限登录。
- system:通常用来创建一些用于查看管理信息的表或视图,权限比sys小,登陆时以normal权限登陆。
- scott:Oracle提供的示例用户之一,为普通用户,默认密码为tiger。
2. 创建新用户
xxxxxxxxxx81-- 创建新用户,设置密码,指定默认表空间,指定临时表空间2create user hyx identified by hyx123 default tablespace ts_hyx temporary tablespace ts_tmp_hyx;3
4-- 给用户授权5grant connect to hyx;6grant resource to hyx;7grant dba to hyx;8
3. 删除或锁定用户
xxxxxxxxxx61-- 删除用户,并级联删除用户下的数据对象2drop user hyx cascade; 3
4-- 锁定用户5alter user hyx account lock;6
4. 修改用户信息
xxxxxxxxxx31-- 修改用户密码2alter user hyx identified by hyx1477413
第三节 表空间
1. 查询表空间信息
xxxxxxxxxx101-- 查询数据库所有表空间2select * from dba_tablespaces;3
4-- 查询可访问的表空间5select * from user_tablespaces;6
7-- 查询表空间对应的的文件信息8select * from dba_data_files where tablespace_name = upper('TS_HYX'); -- 注意表空间名称大写9select * from dba_temp_files;10
2. 创建或删除表空间
xxxxxxxxxx81-- 创建普通表空间(注意:需要拥有对应目录的读写权限,下同)2create tablespace ts_hyx datafile 'c:\app\hyx\oradata\orcl\ts_hyx.dbf' size 10M;3
4-- 创建临时表空间5create temporary tablespace ts_tmp_hyx tempfile 'c:\app\hyx\oradata\orcl\ts_tmp_hyx.dbf' size 20M;6
7-- 删除表空间,连同表空间文件也一起删除8drop tablespace TS_TEST including content;
3. 修改表空间
xxxxxxxxxx111-- 修改用户的默认表空间或临时表空间2ALTER USER username DEFAULT | TEMPORARY TABLESPACE tablespace_name;3
4-- 修改表空间数据文件5alter tablespace ts_hyx add datafile 'ts_hyx_02.dbf' size 10M; -- 增加数据文件6alter tablespace ts_hyx drop datafile 'ts_hyx_02.dbf'; -- 删除数据文件(注:不能删除表空间中的第一个创建的数据文件,如果需要删除的话,我们需要把整个的表空间删掉)7
8-- 修改表空间状态9ALTER TABLESPACE tablespace_name ONLINE | OFFLINE; -- 联机或脱机10ALTER TABLESPACE tablespace_name READ ONLY | READ WRITE; -- 只读或可读写11
第四节 角色
角色就是一组权限或者说是权限的集合。用户可以给角色赋予指定的权限,然后将角色赋给相应的用户,如:
SYSDBA:系统管理员,可以执行任何SYS操作,包括重建数据库和更改数据库配置文件等操作。- SYSOPER:系统操作员,是一种用于管理数据库的特殊权限,如打开/关闭数据库,管理服务器进程等。
DBA:数据库管理员,拥有对数据库的完全访问权限,包括可以创建、删除、备份和还原数据库。- CONNECT:连接角色,允许用户连接到数据库。
- RESOURCE:为用户提供了创建对象的权限,例如表、索引、视图等。
- PUBLIC:提供了所有对象的访问权限,任何用户都可以被授予PUBLIC角色。
注意:
- SYSDBA角色在实例启动后就可以使用,可用其加载和打开数据,而DBA角色只有在数据库完全打开才有意义。
1. 查询角色信息
xxxxxxxxxx81-- 查询所有角色2select * from dba_roles;3
4-- 查询角色所拥有的权限5select * from role_sys_privs; -- 角色的系统权限6select * from role_tab_privs; -- 角色的对象权限7select * from role_role_privs; -- 该角色所拥有的其它角色8
2. 创建或删除角色
xxxxxxxxxx91-- 创建角色2create role role_01;3
4-- 创建需要口令的角色5CREATE ROLE role_02 IDENTIFIED BY password00001;6
7-- 删除角色8drop role role_01;9
3. 使用角色
xxxxxxxxxx91-- 为角色赋权2grant create table,create view to role_01;3
4-- 将角色赋予用户5grant role_01 to hyx;6
7-- 收回角色8revoke role_01 from hyx;9
第五节 权限
权限指的是执行特定命令或访问数据库对象的权利,对数据库的安全性(系统安全性、数据安全性)有着至关重要的作用,可分为:
- 系统权限:允许用户执行特定的数据库动作,如创建表、索引、连接实例等。
- 对象权限:也叫实体权限,允许用户操纵一些特定的对象,如读取视图、更新某些列、执行存储过程等。
1. 查询权限信息
xxxxxxxxxx221-- 查询Oracle支持的系统权限、对象权限2SELECT * FROM SYSTEM_PRIVILEGE_MAP;3SELECT * FROM TABLE_PRIVILEGE_MAP;4
5-- 查询用户所拥有的权限6SELECT * FROM DBA_SYS_PRIVS; -- 所有用户所拥有的系统权限7SELECT * FROM USER_SYS_PRIVS; -- 当前用户拥有的系统权限8SELECT * FROM DBA_TAB_PRIVS; -- 所有用户所拥有的对象权限9SELECT * FROM ALL_TAB_PRIVS; -- 可访问用户拥有的对象权限10SELECT * FROM USER_TAB_PRIVS; -- 当前用户拥有的对象权限11
12-- 查询用户所拥有的角色13SELECT * FROM DBA_ROLE_PRIVS; -- 用户所拥有的角色14SELECT * FROM USER_ROLE_PRIVS;-- 当前用户所拥有的角色15
16-- 查询当前会话的权限17SELECT * FROM SESSION_PRIVS; -- 当前会话拥有的权限18SELECT * FROM SESSION_ROLES; -- 当前会话拥有的角色19
20-- 针对表的访问权限的视图21SELECT * FROM TABLE_PRIVILEGES;22
2. 授权与回收
xxxxxxxxxx81-- 授予/回收系统权限2grant create table,create sequence to hyx;3revoke create table, create sequence from hyx;4
5-- 授予/回收对象权限6grant select,update,insert on scott.emp to role_02;7revoke all on scott.emp from hyx;8
3. 权限的传递
默认情况下,Oracle中的权限是不能传递的,如A授权给B,B不能再将权限授予给C,如需允许传递,需加如下一些选项:
xxxxxxxxxx41-- with admin option / with grant option :授权时一并授予该权限的“赋权”权限,以支持权限的传递2grant connect to tyger1 with admin option; -- 当取消权限时不会级联取消,一般用于系统权限3grant select on scott.emp to tyger1 with grant option; -- 在取消授权时会级联取消所有权限,一般用于对象权限4
第六节 事务
事务是一组独立不可分割的工作单元,事务中的操作要么全部执行,要么都不执行。
1. 事务控制命令
xxxxxxxxxx131-- 设置隔离级别(Oracle仅支持READ COMMITTED和SERIALIZABLE两种)2SET TRANSACTION ISOLATION LEVEL [READ COMMITTED|SERIALIZABLE]3
4-- 设置保存点(可用rollback回退到指定的保存点,当事务提交后该会话的所有保存点都将被删除)5savepoint sp16
7-- 提交事务8-- 事务提交后,会删除保存点,释放锁;在RC隔离级别下,其它会话将可以查看到事务变化后的数据9commit;10
11-- 回滚事务(对未提交的事务进行撤销)12rollback [ to savapoint_name]13
注意:
- 关于事务的四大特性和隔离级别等请参考MySql篇学习笔记。
第七节 锁
1. 锁的分类
锁用于多事务场景下对共享资源的访问,以保证数据库的完整性和一致性。
- 排它锁(X锁):即写锁,持有 X 锁即能对数据进行读取,也能进行修改。如果事务A对数据T加上X锁,则其他事务不能对数据T加任何类型的锁。
- 共享锁(S锁):即读锁,持有 S 锁对数据只能查看,但是无法修改和删除。如果事务A对数据对象T加S锁,则事务A只能读取T,其他事务只能再对T加S锁,不能加X锁,直到S锁释放掉。这样就保证了其他事务可以读数据对象T,但是不能进行任何修改。
- 数据锁(DML锁):用于保护数据的完整性,能够防止同步冲突的DML和DDL操作的破坏性交互。
- 字典锁(DDL锁):用于保护数据库对象的结构,如表、索引等的结构定义。
- 内部锁与闩(internal locks and latches):保护数据库的内部结构,如数据文件,对用户是不可见的。
- 其它锁:如分布式锁(Distributed locks)和并行高速缓存管理锁(PCM locks)等,常用于OPS(并行服务器)中。
注意:
- SELECT语句(无for update等)不需要任何锁,即使记录被锁定,依然可以执行(oracle是用到undo的内容进行一致性读来实现的)。
- Oracle中,每行数据都有标志位来表示该行数据是否被锁定;而在MySql(InnoDB)中,行锁是加在索引上的,如果没有索引,将通过隐藏的聚集索引来对记录加锁。
2. DML锁详解
DML锁(数据锁)主要包括TM锁和TX锁,其中TM锁称为表级锁(意向锁),TX锁称为行级锁(事务锁)。当Oracle执行INSERT/DELETE/ UPDATE/SELECT FOR UPDATE等DML语句时,首先申请表级锁,当表级锁获得后,才会申请行级锁。
1) 表级锁
不同类型的SQL语句需要申请不同类型的表级锁,简述如下:
| 锁模式 | 锁类型 | 锁描述 | 需申请该锁的SQL语句 | lock语法 |
|---|---|---|---|---|
| 0 | NONE | 不存在锁 | ||
| 1 | NULL | 空锁(无冲突) | SELECT | |
| 2 | RS | 行级共享锁 | lock TABLE in row share mode lock TABLE in share update mode | |
| 3 | RX | 行级排他锁 | INSERT、DELETE、UPDATE、SELECT FOR UPDATE | lock TABLE in row exclusive mode |
| 4 | S | 共享锁 | CREATE INDEX、CREATE VIEW | lock TABLE in share mode |
| 5 | SRX | 共享行级排它锁 | lock TABLE share row exclusive mode | |
| 6 | X | 排它锁 | ALTER TABLE、DROP INDEX、TRUNCATE TABLE、 | lock TABLE in exclusive mode |
扩展:
- LOCK TABLE 语句后可接 NO WAIT,如果获取不到锁,将不会等待而是直接返回,放弃执行当前指令并抛出一个错误。
- LOCK TABLE 语句后也可接 WAIT num,表示最多等待多少秒。
当表级锁相互兼容时,才可以加锁成功:
| NULL | RS | RX | S | SRX | X | |
|---|---|---|---|---|---|---|
| NULL | - | - | - | - | - | - |
| RS | - | - | - | - | - | X |
| RX | - | - | - | X | X | X |
| S | - | - | X | - | X | X |
| SRX | - | - | X | X | X | X |
| X | - | X | X | X | X | X |
当出现不兼容时,就直接进入等待,而无需每次都逐行检查锁标志,大大提高了系统的效率。
2) 行级锁
行级锁只有排它锁(X锁)一种,作用是防止两个事务同时修改相同的数据行。
- Oracle 同时支持多版本并发访问控制及行级锁技术,因此用户只有在修改相同数据行时才会出现竞争。
- 读取操作无需等待对相同数据行的写入操作,写入操作也无需等待对相同数据行的读取操作。
- 当事务获得了某些数据行上的行级锁时,此事务同时获得了数据行所属表上的表级锁。
- 表级锁能够防止系统中并发地执行有冲突的 DDL 操作,避免当前事务中的数据操作被并发地 DDL 操作影响。
3. 锁存器机制
1) 锁存器机制简介
锁存器(latch)用来保护对Oracle内存结构的访问,是一种特殊类型的锁,采用低层次的序列化技术,用以保护SGA中的共享数据结构。Oracle通过锁存器机制保证没有任何两个进程可以同时访问同一块数据结构。
- 等待型(willing-to-wait):请求的进程通过数次短时间的等待后再次发出请求,直到获得latch控制权。
- 立即型(immediate):请求的进程如果未能获得latch控制权,则不等待,继续处理其它指令。
DBA无法对 Latch 直接控制,也无相关的初始化参数可以调配。从性能优化的角度看,DBA需要注意锁存器的争用情况,如果 Latch 存在竞争,表明SGA的一部分正在经历不正常的资源使用。
2) 查询锁存器争用
视图v$latch记录了等待型和立即型两类锁存器的活动。以下查询可以检查latch争用情况,锁存器是否存在等待。
xxxxxxxxxx591select name, gets, misses, wait_time from v$latch where misses <> 0 order by wait_time desc;2+-----------------------------------+-------+------+---------+3|NAME |GETS |MISSES|WAIT_TIME(us)|4+-----------------------------------+-------+------+---------+5|space background task latch |17542 |10735 |1271149 |6|qmn task queue latch |2724 |736 |3579 |7|session statistics |303 |14 |852 |8|call allocation |5439 |39 |380 |9|ksv class latch |4645 |121 |269 |10|post/wait queue |44115 |4840 |250 |11|shared pool |315020 |911 |166 |12|messages |139878 |1344 |53 |13|AQ Slave freSlvL_kwsbgsgn latch |516 |70 |51 |14|session state list latch |470 |13 |20 |15|active checkpoint queue latch |11108 |575 |11 |16|JS global state obj latch |42 |5 |6 |17|enqueues |2998 |39 |4 |18|OS process allocation |14259 |4 |0 |19|OS process: request allocation |260 |2 |0 |20|lgwr LWN SCN |4993 |1 |0 |21|Consistent RBA |2840 |1 |0 |22|cache buffers lru chain |26661 |11 |0 |23|checkpoint queue latch |298081 |31 |0 |24|cache buffers chains |1681279|306 |0 |25|cache buffer handles |279 |24 |0 |26|object queue header operation |61884 |2 |0 |27|redo writing |23134 |444 |0 |28|redo allocation |37043 |76 |0 |29|log write worker phase |48 |1 |0 |30|transaction allocation |39199 |2 |0 |31|dummy allocation |304 |14 |0 |32|corrupted undo seg latch |42 |7 |0 |33|ILM Stats main anchor latch |1435 |10 |0 |34|sequence cache |243 |4 |0 |35|remote tool request latch |116 |3 |0 |36|Event Group Locks |366 |1 |0 |37|job_queue_processes free list latch|82 |1 |0 |38|query server freelists |99 |1 |0 |39|error message lists |31 |9 |0 |40|process queue reference |9301 |6 |0 |41|parallel query alloc buffer |134 |16 |0 |42|hash table column usage latch |1833 |2 |0 |43|qmn state object latch |140 |13 |0 |44|active service list |184163 |36 |0 |45|ksv msg queue latch |592 |18 |0 |46|channel operations parent latch |2792 |48 |0 |47|channel handle pool latch |584 |2 |0 |48|resmgr:free threads list |297 |18 |0 |49|enqueue freelist latch |13 |9 |0 |50|enqueue hash chains |1057175|87 |0 |51|parameter table management |604 |4 |0 |52|object stats modification |3875 |13 |0 |53|client/application info |1054 |6 |0 |54|session allocation |826 |8 |0 |55|interrupt manipulation |62 |8 |0 |56|shardgroup list latch |2372 |2 |0 |57|process allocation |435 |3 |0 |58+-----------------------------------+-------+------+---------+59
另外通过v$system_event检查系统事件latch free是否出现来判断是否存在锁存器争用。
xxxxxxxxxx81-- 自实例启动以来,经历了与锁存器有关的等待事件次数和消耗的等待时间(毫秒)2select event, total_waits, time_waited from v$system_event where event='latch free';3+----------+-----------+-----------+4|EVENT |TOTAL_WAITS|TIME_WAITED|5+----------+-----------+-----------+6|latch free|9276 |129 |7+----------+-----------+-----------+8
以下统计latch争用导致的各类未命中:
xxxxxxxxxx61select parent_name, sum(longhold_count) from v$latch_misses group by parent_name having sum(longhold_count) > 0 order by sum(longhold_count) desc;2PARENT_NAME SUM(LONGHOLD_COUNT)3---------------------------------------------------------------- -------------------4In memory undo latch 35cache buffers chains 36
4. 锁的查询
1) 锁相关的数据字典
xxxxxxxxxx121SELECT * FROM v$lock; -- 锁信息2SELECT * FROM v$locked_object; -- 当前被锁对象的信息3SELECT * FROM v$session; -- 记录会话及锁的信息4SELECT * FROM v$session_wait; -- 记录会话的等待信息5SELECT * FROM v$latch; -- 锁存器信息6SELECT * FROM v$latch_misses; -- latch争用的丢失统计7SELECT * FROM v$sqltext; -- sga中的sql8SELECT * FROM v$sqlarea; -- shared sql area中的sql9SELECT * FROM dba_objects; -- 数据库中的所有对象10SELECT * FROM dba_locks; -- 对V$lock的格式化视图11SELECT * FROM dba_blockers; -- 正在阻塞资源的会话12SELECT * FROM dba_waiters; -- 正在等待锁资源的会话
2) DML锁查询
日常开发中,最常用的为DML锁的查询:
xxxxxxxxxx251-- 查询DML锁2SELECT L.SESSION_ID "会话ID",3 S.SERIAL# "会话序列号",4 P.SPID "会话进程号",5 S.USERNAME "所属用户",6 S.MACHINE "客户端",7 O.OBJECT_NAME "被锁对象",8 O.OBJECT_TYPE "被锁对象类型",9 CASE L.LOCKED_MODE 10 WHEN 0 THEN 'NONE' 11 WHEN 1 THEN 'NULL' 12 WHEN 2 THEN 'RS' 13 WHEN 3 THEN 'RX' 14 WHEN 4 THEN 'S' 15 WHEN 5 THEN 'SRX' 16 WHEN 6 THEN 'X' 17 ELSE TO_CHAR(L.LOCKED_MODE)18 END "锁模式",19 CEIL((SYSDATE - S.LOGON_TIME) * 24 * 60 * 60) "被锁时间(S)"20 FROM V$LOCKED_OBJECT L, V$SESSION S, DBA_OBJECTS O, V$PROCESS P21 WHERE L.SESSION_ID = S.SID22 AND L.OBJECT_ID = O.OBJECT_ID23 AND S.PADDR = P.ADDR24 AND S.SCHEMA# <> 025AND S.USERNAME = 'KBSSFMS';| 会话ID | 会话序列号 | 会话进程号 | 所属用户 | 客户端 | 被锁对象 | 被锁对象类型 | 锁模式 | 被锁时间(S) |
|---|---|---|---|---|---|---|---|---|
| 1103 | 38434 | 17280 | KRMP | HYX-PC | STK_CALENDAR | TABLE | RX | 52 |
3) 从会话角度查询
xxxxxxxxxx241-- 查询有锁阻塞的会话2select * from v$lock where block=1; 3+------------------+------------------+----+----+------+-----+-----+-------+-----+-----+------+4|ADDR |KADDR |SID |TYPE|ID1 |ID2 |LMODE|REQUEST|CTIME|BLOCK|CON_ID|5+------------------+------------------+----+----+------+-----+-----+-------+-----+-----+------+6|'00007FFBB88992E0'|'00007FFBB8899318'|1103|TX |262151|23576|6 |0 |1296 |1 |0 |7+------------------+------------------+----+----+------+-----+-----+-------+-----+-----+------+8
9-- 正在阻塞资源的会话10SELECT * FROM dba_blockers; 11+---------------+------+12|HOLDING_SESSION|CON_ID|13+---------------+------+14|1103 |0 |15+---------------+------+16
17-- 正在等待锁资源的会话18SELECT * FROM dba_waiters; 19+---------------+--------------+---------------+--------------+-----------+---------+--------------+--------+--------+20|WAITING_SESSION|WAITING_CON_ID|HOLDING_SESSION|HOLDING_CON_ID|LOCK_TYPE |MODE_HELD|MODE_REQUESTED|LOCK_ID1|LOCK_ID2|21+---------------+--------------+---------------+--------------+-----------+---------+--------------+--------+--------+22|1227 |0 |1103 |0 |Transaction|Exclusive|Exclusive |262151 |23576 |23+---------------+--------------+---------------+--------------+-----------+---------+--------------+--------+--------+24
4)从被锁对象角度查询
xxxxxxxxxx631-- 查询被锁住的对象2select object_id, session_id, oracle_username, os_user_name, locked_mode from v$locked_object; 3+---------+----------+---------------+-------------+-----------+4|OBJECT_ID|SESSION_ID|ORACLE_USERNAME|OS_USER_NAME |LOCKED_MODE|5+---------+----------+---------------+-------------+-----------+6|155737 |1103 |KRMP |Administrator|3 |7|155737 |1227 |KRMP |Administrator|3 |8+---------+----------+---------------+-------------+-----------+9
10-- 查看被锁对象的信息11select object_id, object_name, object_type, owner from dba_objects where object_id = 155737; 12+---------+------------+-----------+-----+13|OBJECT_ID|OBJECT_NAME |OBJECT_TYPE|OWNER|14+---------+------------+-----------+-----+15|155737 |STK_CALENDAR|TABLE |KRMP |16+---------+------------+-----------+-----+17
18-- 查看是谁锁住了谁19select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime 20 from v$lock a, v$lock b 21 where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0; 22+-------+-------+----+------+-----+-----+23|HOLDSID|WAITSID|TYPE|ID1 |ID2 |CTIME|24+-------+-------+----+------+-----+-----+25|1103 |1227 |TX |262151|23576|1446 |26+-------+-------+----+------+-----+-----+27
28-- 进一步查看锁阻塞和锁请求的信息29select sid, type, id1, id2,30 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,31 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,32 ctime, block33from v$lock where type in ('TM', 'TX'); 34+----+----+------+-----+-------------+---------+-----+-----+35|SID |TYPE|ID1 |ID2 |LMODE |REQUEST |CTIME|BLOCK|36+----+----+------+-----+-------------+---------+-----+-----+37|1227|TX |262151|23576|none |exclusive|863 |0 |38|1103|TM |155737|0 |row exclusive|none |1462 |0 |39|1227|TM |155737|0 |row exclusive|none |863 |0 |40|1103|TX |262151|23576|exclusive |none |1462 |1 |41+----+----+------+-----+-------------+---------+-----+-----+42
43-- 通过SID查看相关会话的信息44select sid, serial#, audsid, username, status, machine, program, logon_time, lockwait, row_wait_obj# from v$session where sid in (1227,9);45+----+-------+--------+--------+------+-------+--------+-------------------+----------------+-------------+46|SID |SERIAL#|AUDSID |USERNAME|STATUS|MACHINE|PROGRAM |LOGON_TIME |LOCKWAIT |ROW_WAIT_OBJ#|47+----+-------+--------+--------+------+-------+--------+-------------------+----------------+-------------+48|1227|60892 |28170016|KRMP |ACTIVE|HYX-PC |DataGrip|2023-09-14 10:24:23|00007FFBC019EF58|155737 |49+----+-------+--------+--------+------+-------+--------+-------------------+----------------+-------------+50
51-- 也可以将几个视图联合查询,同时找出被锁对象及其会话信息52select t3.row_wait_obj#, t2.object_name, t2.object_type, t2.owner, t1.os_user_name, t1.session_id, 53 t3.serial#, t3.audsid, t3.username, t3.logon_time, t3.machine, t3.program, t3.status54 from v$locked_object t1 55 join dba_objects t2 on t1.object_id = t2.object_id 56 join v$session t3 on t1.session_id = t3.sid;57+-------------+------------+-----------+-----+-------------+----------+-------+--------+--------+-------------------+-------+--------+--------+58|ROW_WAIT_OBJ#|OBJECT_NAME |OBJECT_TYPE|OWNER|OS_USER_NAME |SESSION_ID|SERIAL#|AUDSID |USERNAME|LOGON_TIME |MACHINE|PROGRAM |STATUS |59+-------------+------------+-----------+-----+-------------+----------+-------+--------+--------+-------------------+-------+--------+--------+60|-1 |STK_CALENDAR|TABLE |KRMP |Administrator|1103 |38434 |28170015|KRMP |2023-09-14 10:13:40|HYX-PC |DataGrip|INACTIVE|61|155737 |STK_CALENDAR|TABLE |KRMP |Administrator|1227 |60892 |28170016|KRMP |2023-09-14 10:24:23|HYX-PC |DataGrip|ACTIVE |62+-------------+------------+-----------+-----+-------------+----------+-------+--------+--------+-------------------+-------+--------+--------+63
5. 释放锁
当事务执行COMMIT或ROLLBACK操作,持有的锁都会被释放。此外,也可以强制释放锁:
xxxxxxxxxx71-- 释放锁(SQL层面杀掉会话)2alter system kill session 'SID,SERIAL#';3
4-- 释放锁(操作系统层面杀掉服务端进程)5orakill KFMS 38766kill -9 9876 # 9876为SPID7
6. 锁分析案例
1) 数据库连接与会话信息
xxxxxxxxxx271-- session1:2sqlplus cmes/cmes@mes3select sys_context('userenv','sessionid') from dual;4
5SYS_CONTEXT6-----------73300368
9 10-- session2:11sqlplus rmes/rmes@mes12select sys_context('userenv','sessionid') from dual;13
14SYS_CONTEXT15-----------1633003817
18
19-- session3:查询两个会话的基本信息20sqlplus / as sysdba21select sid, serial#, audsid, username, status, machine, program, logon_time, lockwait, row_wait_obj# from v$session where audsid in (330036, 330038);22
23 SID SERIAL# AUDSID USERNAME STATUS MACHINE PROGRAM LOGON_TIME LOCKWAIT ROW_WAIT_OBJ#24---------- ---------- ---------- ---------- -------- ------------------------------ -------------------- ------------------- -------------------- -------------25 133 8 330036 CMES INACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 14:16:38 1348226 197 28 330038 RMES INACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 14:17:30 -127
2) TM-S锁与TX-X锁
xxxxxxxxxx581-- session1:2lock table rmes.r_wip_tracking_t in share mode;3
4
5-- session2:此更新被卡住,未能执行6update rmes.r_wip_tracking_t set outline_flag=1 where sn='Z51AA5CTF1090063C';7
8-- session3:查询锁阻塞和锁请求的基本信息(谁阻塞了谁)9select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;10
11 HOLDSID WAITSID TY ID1 ID2 CTIME12---------- ---------- -- ---------- ---------- ----------13 133 197 TM 97125 0 6914
15HOLDSID:锁阻塞会话的SID16WAITID:锁请求会话的SID17TYPE:锁类型,TM-DML锁,TX-DDL锁, UL-用户定义的锁类型18ID1:当锁类型为TM锁时,为被锁对象的object_id19ID2:当锁为TX锁时,ID1为usn+slot,而ID2为seq20CTIME:锁持续的时间21
22
23-- 进一步查询锁阻塞和锁请求的详细信息24select sid, type, id1, id2,25 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,26 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,27 ctime, block from v$lock where type in ('TM', 'TX');28 29 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK30---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------31 133 TM 97125 0 share none 351 132 197 TM 97125 0 none row exclusive 335 033
34lmode:锁占用类型35request:锁请求类型36block:阻塞者标志37
38 39-- 此时再看两个会话的基本信息40select sid, serial#, audsid, username, status, machine, program, logon_time, lockwait, row_wait_obj# from v$session where sid in (133,197);41
42 SID SERIAL# AUDSID USERNAME STATUS MACHINE PROGRAM LOGON_TIME LOCKWAIT ROW_WAIT_OBJ#43---------- ---------- ---------- ---------- -------- ------------------------------ -------------------- ------------------- -------------------- -------------44 133 8 330036 CMES INACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 14:16:38 -145 197 28 330038 RMES ACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 14:17:30 000007FF47C507E8 9712546
47status:inactive,表示命令执行已完成正处于就绪状态,active,表示命令正在执行中48lockwait:锁等待的地址49row_wait_object#:出现行等待对象的ID50
51 52-- 可以看到行等待的对象53select object_name from dba_objects where object_id=97125;54
55OBJECT_NAME56--------------------------57R_WIP_TRACKING_T58
3) TM-RS锁与TX-X锁
xxxxxxxxxx211-- session1(SID=68)2lock table rmes.r_wip_tracking_t in row share mode;3
4-- session2(SID=12):已更新 1 行5update rmes.r_wip_tracking_t set outline_flag=1 where sn='Z51AA5CTF1090063C';6
7-- session3:未选定行8select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;9
10-- 第一个会话持有 RS 锁,此时允许第二个会话对同一对象施加行独占锁,与此同时,Oracle自动施加了独占模式的TX锁11select sid, type, id1, id2,12 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,13 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,14 ctime, block from v$lock where type in ('TM', 'TX');15
16 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK17---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------18 12 TM 97125 0 row exclusive none 256 019 68 TM 97125 0 row share none 298 020 12 TX 196619 1498 exclusive none 256 021
4) TM-RX锁和TX-X锁
xxxxxxxxxx211-- session1(SID=68)2lock table rmes.r_wip_tracking_t in row exclusive mode;3
4-- session2(SID=12):已更新 1 行5update rmes.r_wip_tracking_t set outline_flag=1 where sn='Z51AA5CTF1090063C';6
7-- session3:未选定行8select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;9
10-- 行独占模式(RX)下,允许第二个会话对同一对象施加行独占锁,与此同时,Oracle自动施加了独占模式的TX锁11select sid, type, id1, id2,12 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,13 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,14 ctime, block from v$lock where type in ('TM', 'TX');15
16 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK17---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------18 12 TM 97125 0 row exclusive none 2815 019 68 TM 97125 0 row exclusive none 649 020 12 TX 196619 1498 exclusive none 2815 021
5)TM-SRX锁和TX-X锁
xxxxxxxxxx381-- session1(SID=68)2lock table rmes.r_wip_tracking_t in share row exclusive mode;3
4-- session2(SID=133):此更新被卡住,未能执行5update rmes.r_wip_tracking_t set outline_flag=1 where sn='Z51AA5CTF1090063C';6
7-- session3:出现锁等待8select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;9
10 HOLDSID WAITSID TY ID1 ID2 CTIME11---------- ---------- -- ---------- ---------- ----------12 68 133 TM 97125 0 12213
14-- 进一步查看锁等待信息15select sid, type, id1, id2,16 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,17 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,18 ctime, block from v$lock where type in ('TM', 'TX');19
20 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK21---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------22 133 TM 97125 0 none row exclusive 184 023 68 TM 97125 0 share row exclusive none 220 124
25-- 此时再看两个会话的基本信息26select sid, serial#, audsid, username, status, machine, program, logon_time, lockwait, row_wait_obj# from v$session where sid in (68,133);27
28 SID SERIAL# AUDSID USERNAME STATUS MACHINE PROGRAM LOGON_TIME LOCKWAIT ROW_WAIT_OBJ#29---------- ---------- ---------- ---------- -------- ------------------------------ -------------------- ------------------- -------------------- -------------30 68 399 330306 CMES INACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 18:05:30 -131 133 288 330304 RMES ACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 18:05:02 000007FF47C365C8 9712532
33-- 可以看到行等待的对象34select object_name from dba_objects where object_id=97125;35OBJECT_NAME36--------------------------37R_WIP_TRACKING_T38
6) TM-X锁和TX-X锁
xxxxxxxxxx401-- session1(SID=68)2lock table rmes.r_wip_tracking_t in exclusive mode;3
4-- session2(SID=12):此更新被卡住,未能执行5update rmes.r_wip_tracking_t set outline_flag=1 where sn='Z51AA5CTF1090063C';6
7-- session3:8select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;9
10 HOLDSID WAITSID TY ID1 ID2 CTIME11---------- ---------- -- ---------- ---------- ----------12 68 12 TM 97125 0 8113
14-- 进一步查看锁等待信息15select sid, type, id1, id2,16 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,17 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,18 ctime, block from v$lock where type in ('TM', 'TX');19
20 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK21---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------22 12 TM 97125 0 none row exclusive 224 023 68 TM 97125 0 exclusive none 245 124 25
26-- 此时再看两个会话的基本信息27select sid, serial#, audsid, username, status, machine, program, logon_time, lockwait, row_wait_obj# from v$session where sid in (68,12);28
29 SID SERIAL# AUDSID USERNAME STATUS MACHINE PROGRAM LOGON_TIME LOCKWAIT ROW_WAIT_OBJ#30---------- ---------- ---------- ---------- -------- ------------------------------ -------------------- ------------------- -------------------- -------------31 12 241 330322 RMES ACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 18:19:31 000007FF47C24F08 9712532 68 399 330306 CMES INACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 18:05:30 -133
34-- 可以看到行等待的对象35select object_name from dba_objects where object_id=97125;36
37OBJECT_NAME38--------------------------39R_WIP_TRACKING_T40
7) for update和TX-X锁
xxxxxxxxxx411-- session1(SID=133)2select * from rmes.r_wip_tracking_t where sn in ('Z51AA5CTF1090063C','Z51AA5CTF1090064D') for update;3
4-- session2(SID=12):此更新被卡住,未能执行5update rmes.r_wip_tracking_t set outline_flag=1 where sn='Z51AA5CTF1090063C';6
7-- session3:8select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;9
10 HOLDSID WAITSID TY ID1 ID2 CTIME11---------- ---------- -- ---------- ---------- ----------12 133 12 TX 131084 1386 8213
14-- 进一步查看锁等待信息15select sid, type, id1, id2,16 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,17 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,18 ctime, block from v$lock where type in ('TM', 'TX');19 20 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK21---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------22 12 TX 131084 1386 none exclusive 154 023 12 TM 97125 0 row exclusive none 154 024 133 TM 97125 0 row exclusive none 203 025 133 TX 131084 1386 exclusive none 203 126 27-- 此时再看两个会话的基本信息28select sid, serial#, audsid, username, status, machine, program, logon_time, lockwait, row_wait_obj# from v$session where sid in (133,12);29
30 SID SERIAL# AUDSID USERNAME STATUS MACHINE PROGRAM LOGON_TIME LOCKWAIT ROW_WAIT_OBJ#31---------- ---------- ---------- ---------- -------- ------------------------------ -------------------- ------------------- -------------------- -------------32 12 243 330335 RMES ACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 18:28:37 000007FF4AC56980 9712533 133 348 330343 CMES INACTIVE WORKGROUP\ORACLE11G-2 sqlplus.exe 2016-10-30 18:32:02 -134
35-- 可以看到行等待的对象36select object_name from dba_objects where object_id=97125;37
38OBJECT_NAME39--------------------------40R_WIP_TRACKING_T41
8) 死锁模拟
当程序对所做的修改进行提交(Commit)或回滚(Rollback)后,锁住的资源便会得到释放,从而允许其他用户进行操作。如果两个事务,分别锁定一部分数据,而都在等待对方释放锁才能完成事务操作,这种情况下就会发生死锁。
当Oracle检测到死锁时,中断并回滚执行死锁的相关语句,报[ORA-00060: 等待资源时检测到死锁]的死锁错误并记录在警告日志文件alert_<sid>.log中,同时会在user_dump_dest下产生一个跟踪文件,详细描述死锁的相关信息。
死锁模拟如下:
xxxxxxxxxx141-- session1:2update emp set sal=1000 where empno=7369;3
4-- session2:5update emp set sal=1500 where empno=7499;6
7-- session1:8update emp set sal=1700 where empno=7499;9
10-- session2:11update emp set sal=900 where empno=7369;12
13-- session1提示:14ORA-00060: 等待资源时检测到死锁发生改错误后,可通过下面步骤来解决:
xxxxxxxxxx361-- 查询锁阻塞和锁请求信息:2select a.sid holdsid, b.sid waitsid, a.type, a.id1, a.id2, a.ctime from v$lock a, v$lock b where a.id1 = b.id1 and a.id2 = b.id2 and a.block = 1 and b.block = 0;3 HOLDSID WAITSID TY ID1 ID2 CTIME4---------- ---------- -- ---------- ---------- ----------5 200 9 TX 458773 1222 7886
7-- 显示session2(SID=9)对表施加的TX exclusive模式的锁请求被session1(SID=200)的TX exclusive锁阻塞8select sid, type, id1, id2,9 decode(lmode, 0, 'none',1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') lmode,10 decode(request, 0, 'none', 1, 'null', 2, 'row share', 3, 'row exclusive', 4, 'share', 5, 'share row exclusive', 6, 'exclusive') request,11 ctime, block 12 from v$lock where type in ('TM', 'TX');13 SID TY ID1 ID2 LMODE REQUEST CTIME BLOCK14---------- -- ---------- ---------- ------------------- ------------------- ---------- ----------15 9 TX 458773 1222 none exclusive 793 016 9 TM 73196 0 row exclusive none 842 017 200 TM 73196 0 row exclusive none 856 018 9 TX 655380 1237 exclusive none 842 019 200 TX 458773 1222 exclusive none 856 120
21
22-- 查看警告日志文件alert_mes.log,提示在跟踪文件中记录了有关死锁的详细信息:23ORA-00060: Deadlock detected. More info in file c:\oracle\diag\rdbms\mes\mes\trace\mes_ora_2252.trc.24
25-- 后续操作26session1提交会话:27SQL> commit;28此时查empno=7499的值保持原样,没有被更新,即第二个更改被回滚,而empno=7369的值被更新。29
30-- 解除死锁的方法有四种:311)收到死锁信息的session1提交事务322)收到死锁信息的session2回滚事务333)DBA通过alter system kill session命令强制中断引发死锁的session2344)DBA通过alter system kill session命令强制中断阻塞session2操作的session135比较上面的四种处理方法,最好的还是方法一,因为它导致的数据丢失量最小,最大限度的保护了数据。36
第八节 数据字典
数据字典用于存储和查看数据库的元数据信息,主要包含内部表(X$)、元数据表(xxx$)、元数据视图(DBA_xxx/ALL_xxx/USER_xxx)、动态性能视图(V$/GV$)等。
xxxxxxxxxx61-- 查询数据字典名称和描述2SELECT * FROM DICT ORDER BY TABLE_NAME; -- 注:DICT为sys.dictionary的别名3
4-- 查询某数据字典各字段的含义5select column_name,comments from dict_columns where table_name='USER_INDEXES';6
1. 内部表
内部表用于跟踪数据库的内部信息,是数据库的运行基础,在数据库启动时动态创建,且加密命名,用户无需过多关注。
2. 元数据表
元数据表用于存储普通表、索引、约束等数据库对象的结构信息,用户无法直接访问,执行DDL操作会对其进行修改,相应的,通过Oracle提供的工具包也可反向生成DDL语句。
xxxxxxxxxx31-- 通过数据库结构信息反向生成SQL语句2select dbms_metadata.get_ddl('TABLE','RISK_INFO') from dual; -- 对象类型,对象名称3
3. 元数据视图
由于元数据表无法直接访问(防止用户恶意修改),因此提供了一系列的元数据视图,主要分为三类:
- USER_XXX:用户所拥有的相关对象信息。
- ALL_XXX:用于有权限访问的所有对象的信息。
- DBA_XXX:数据库所有相关对象的信息,用于需要有 select any table 的权限才能访问。
以DBA_XXX为例,常用的元数据视图如下:
| 数据字典名称 | 说明 |
|---|---|
| dba_objects | 数据库中所有的对象 |
| dba_tablespaces | 表空间信息 |
| dba_segments | 段信息 |
| dba_extents | 区信息 |
| dba_users | 用户信息 |
| dba_tables | 数据表信息 |
| dba_views | 视图信息 |
| dba_tab_columns | 数据表和视图的列信息 |
| dba_indexs | 索引信息 |
| dba_ind_columns | 索引列信息 |
| dba_constraints | 约束信息 |
| dba_sequences | 序列信息 |
| dba_triggers | 触发器信息 |
| dba_source | 存储过程信息 |
| dba_data_files | 数据库文件的信息 |
| dba_synonyms | 同义词的信息 |
| dba_tab_grants/privs | 对象授权的信息 |
4. 动态性能视图
动态性能视图可以查询数据库运行时信息和统计数据,大部分是实时更新的,主要分为如下四类:
- GV_$XXX:全局动态性能视图,直接基于内部表(X$XXX)创建,包含适配OPS/RAC环境的实例ID(INST_ID)列,用户无法直接访问。
- V_$XXX:当前实例的动态性能视图,基于GV_$XXX创建,用户也无法直接访问。
- GV$XXX:GV_$XXX的同义词,用户可进行查询。
- V$XXX:V_$XXX的同义词,用户可进行查询,一般使用该类型视图。
动态性能视图的定义语句可通过如下SQL查询,如:
xxxxxxxxxx31-- 查询V$SESSION视图的创建语句2select * from v$fixed_view_definition WHERE VIEW_NAME = 'V$SESSION';3
常用的动态性能视图如下:
| 数据字典名称 | 说 明 |
|---|---|
| v$database | 描述关于数据库的相关信息 |
| v$datafile | 数据库使用的数据文件信息 |
| v$log | 从控制文件中提取有关重做日志组的信息 |
| v$logfile | 有关实例重置日志组文件名及其位置的信息 |
| v$archived_log | 记录归档日志文件的基本信息 |
| v$archived_dest | 记录归档日志文件的路径信息 |
| v$controlfile | 描述控制文件的相关信息 |
| v$instance | 记录实例的基本信息 |
| v$system_parameter | 显示实例当前有效的参数信息 |
| v$sga | 显示实例的 SGA 区的大小 |
| v$sgastat | 统计 SGA 使用情况的信息 |
| v$parameter | 记录初始化参数文件中所有项的值 |
| v$lock | 通过访问数据库会话,设置对象锁的所有信息 |
| v$session | 有关会话的信息 |
| v$sqltext | 记录 SQL 语句的详细信息 |
| v$bgprocess | 显示后台进程信息 |
| v$process | 当前进程的信息 |
第九节 回收站
回收站是一个数据字典表,保存着最近被删除的对象信息,在原数据没有被覆盖的前提下,能够通过闪回机制恢复被删除的对象。
1. 开启和关闭回收站
xxxxxxxxxx131-- 查看回收站开启状态(ON表示开启 OFF表示关闭)2SHOW PARAMETER RECYCLEBIN;3SELECT NAME, VALUE FROM V$PARAMETER WHERE NAME='recyclebin';4
5-- 开启回收站6ALTER SYSTEM SET RECYCLEBIN=ON;7ALTER SESSION SET RECYCLEBIN =ON;8
9-- 关闭回收站10ALTER SYSTEM SET RECYCLEBIN=OFF;11ALTER SESSION SET RECYCLEBIN=OFF;12
13
2. 查看回收站对象
xxxxxxxxxx151-- 查看当前用户的回收站2show recyclebin3SELECT * FROM RECYCLEBIN; -- RECYCLEBIN是USER_RECYCLEBIN 的同义词4SELECT * FROM USER_RECYCLEBIN; 5
6ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME7---------------- ------------------------------ ------------ -------------------8TEST BIN$BLmi9vltN3TgUKjAgYxoiA==$0 TABLE 2014-10-06:11:25:389
10注:ORIGINAL_NAME为原对象名,在多次DROP同名对象时可能重复;RECYCLEBIN_NAME为已DROP对象在回收站中的唯一标识。11
12
13-- 查看所有用户的回收站14SELECT * FROM DBA_RECYCLEBIN;15
3. 还原回收站对象
xxxxxxxxxx91-- 还原回收站中的表(如果回收站中存在多个重名的表,则恢复最近DROP的那个)2FLASHBACK TABLE TEST TO BEFORE DROP; 3
4-- 还原回收站中的表,并进行重命名(在与现有对象名冲突时非常有用)5FLASHBACK TABLE TEST TO BEFORE DROP RENAME TO TEST_2;6
7-- 指定RECYCLEBIN NAME进行闪回8FLASHBACK TABLE "BIN$BLmi9vlwN3TgUKjAgYxoiA==$0" TO BEFORE DROP;9
注意:
- “回收站-闪回”机制只适用于非系统表空间和本地管理的表空间,而系统表空间的对象会直接删除,而不是放入回收站。
- 该机制不适用于对象的外键约束以及基于该表的物化视图等特殊场景,这需要DBA手工重建。
- 对象能否恢复成功,取决于对象空间是否被覆盖重用,因此,回收站不是一个百分百保险的机制。
4. 清空回收站
xxxxxxxxxx181-- 1) 在Drop时立即删除(即使开启回收站,也不会被放入)2DROP TABLE TABLE_NAME01 PURGE;3
4-- 2) 按 RECYCLEBIN NAME 进行清理5PURGE TABLE SCOTT."BIN$04LhcpndanfgMAAAAAANPw==$0"; 6
7-- 3) 按表/索引清理8PURGE TABLE TABLE_NAME01; -- 清理表及相关的索引、约束等9PURGE INDEX INDEX_NAME01; -- 仅清理索引10
11-- 4) 按表空间清理12PURGE TABLESPACE TS01; -- 清理TS01表空间13PURGE TABLESPACE TS01 USER SCOTT; -- 清理SCOTT用户在TS01表空间中的所有对象14
15-- 5) 按用户清理16PURGE RECYCLEBIN; -- 清理当前用户的对象17PURGE DBA_RECYCLEBIN; -- 清理所有用户的对象18
第十节 备份恢复
1. 逻辑备份-EXP/IMP
EXP和IMP是客户端工具程序,可在客户端或服务端执行,一般用于Oracle10g之前的数据库备份/恢复。
1) 备份数据库
xxxxxxxxxx91-- 导出整个数据库2exp system/system123@ORCL01 file=D:\DB_ORCL01_20230830.dmp full=y3
4-- 导出指定的用户5exp krmp/krmp@ORCL01 file=D:\USER_KRMP_20230830.DMP owner=krmp log=D:\USER_KRMP_20230830.EXP.LOG6
7-- 导出指定的表8exp krmp/krmp@ORCL01 file=D:\TABLE_BIZ01_20230830.DMP tables=CUST_LABEL_CLS,LABELED_CUST_LIST9
注意:
- Oracle新建的空表不占存储空间,不会分配extent/segment,逻辑备份可能无法导出。如下SQL可查询未分配extent的表:
xxxxxxxxxx11select table_name from all_tables where owner= 'KRMP' AND segment_created = 'NO';
- 对于未分配extent的表,需要手动执行如下SQL分配后才可导出。
xxxxxxxxxx11alter table KRMP.CUSTOMER allocate extent;
2) 恢复数据库
xxxxxxxxxx61-- 导入到默认用户2imp krmp/krmp@ORCL01 file=D:\USER_KRMP_20230830.DMP ignore=y3
4-- 导入到指定用户5imp krmp/krmp@ORCL01 FROMUSER=krmp TOUSER=krmp IGNORE=Y ROWS=Y INDEXES=Y COMMIT=Y BUFFER=65536 FEEDBACK=5000 FILE=D:\USER_KRMP_20230830.DMP6
3) 增量备份方案
增量备份是一种常用的数据库备份方案,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。增量导出包括三种类型:
完全增量导出:即备份整个数据库。
xxxxxxxxxx11exp system/manager inctype=complete file=040731.dmp增量型增量导出:备份上一次备份后改变的数据。
xxxxxxxxxx11exp system/manager inctype=incremental file=040731.dmp累积型增量导出:导出自上次“完全”导出之后数据库中变化了的信息。
xxxxxxxxxx11exp system/manager inctype=cumulative file=040731.dmp
数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效的完成。
例如数据库的增量备份任务可以做如下安排: 星期一:完全备份(A) 星期二:增量导出(B) 星期三:增量导出(C) 星期四:增量导出(D) 星期五:累计导出(E) 星期六:增量导出(F) 星期日:增量导出(G) 如果在星期日,数据库遭到意外破坏,数据库管理员可按一下步骤来回复数据库: 第一步:用命令CREATE DATABASE重新生成数据库结构; 第二步:创建一个足够大的附加回滚。 第三步:完全增量导入A:imp system/manager inctype=RESTOREFULL=y FILE=A 第四步:累计增量导入E:imp system/manager inctype=RESTOREFULL=Y FILE=E 第五步:最近增量导入F:imp system/manager inctype=RESTOREFULL=Y FILE=F
2. EXPDP/IMPDP逻辑备份
EXPDP和IMPDP是服务端的工具程序,他们只能在ORACLE服务端使用,不能在客户端使用(但可在客户端发起,服务端执行)。
1) 创建逻辑目录
使用EXPDP/IMPDP前必须先创建逻辑目录和系统目录,并进行授权:
xxxxxxxxxx101-- 创建逻辑目录 2-- 创建后可通过 select * from dba_directories where DIRECTORY_NAME = upper('dpdata1'); 查看3create directory dpdata1 as 'd:\dump'; 4
5-- 创建系统目录6host mkdir d:\dump7
8-- 逻辑目录授权9grant read,write on directory dpdata1 to krmp;10
2) 备份数据库
xxxxxxxxxx381-- 导出整个数据库2expdp system/system123@ORCL01 DIRECTORY=dpdata1 DUMPFILE=DB_ORCL01_20230830.dmp FULL=y # 需要dba/exp_full_database/imp_full_database权限3
4-- 导出指定用户(模式)5expdp krmp/krmp@ORCL01 schemas=krmp DIRECTORY=dpdata1 dumpfile=USER_KRMP_20230830.dmp 6
7-- 并行导出指定用户(模式)8expdp krmp/krmp@ORCL01 schemas=krmp DIRECTORY=dpdata1 dumpfile=USER_KRMP_20230830.dmp parallel=4 # parallel为线程数9expdp krmp/krmp@ORCL01 schemas=krmp DIRECTORY=dpdata1 dumpfile=USER_KRMP_20230830_%U.dmp filesize=500M parallel=4 # 可能生成多个文件10
11-- 导出指定表空间12expdp krmp/krmp@ORCL01 DIRECTORY=dpdata1 DUMPFILE=TS_KRMPSPACE_DWSPACE.dmp TABLESPACES=KRMPSPACE,DWSPACE13
14-- 导出指定表15expdp krmp/krmp@ORCL01 TABLES=CUST_LABEL_CLS,LABELED_CUST_LIST DIRECTORY=dpdata1 dumpfile=TABLE_BIZ01_20230830.dmp16
17-- 导出指定表查询18expdp krmp/krmp@ORCL01 DIRECTORY=dpdata1 DUMPFILE=expdp.dmp Tables=TABLE_CUST_LABEL_CLS_101.DMP query='WHERE LABEL_CLS=101'19
20-- 扩展选项21job_name=KRMP_DUMP_JOB # 导出工作名称22cluster=n # 非集群模式23CONTENT=ALL|DATA_ONLY|METADATA_ONLY # 对象定义+数据 | 仅数据 | 仅对象定义24TABLE_EXISTS_ACTION=SKIP|APPEND|TRUNCATE|REPLACE # 跳过 | 追加 | 截断 | 重建 (同时指定了CONTENT参数为Data_only的话,那么SKIP变为apped,REPLACE参数无效)25Query = [Schema.][Table_name:] Query_clause # EG:Query=TABLE_A:”Where id<5″,TABLE_B:”Where name=’a’”26INCLUDE=[object_type]:[name_clause],[object_type]:[name_clause] 27 INCLUDE=PROCEDURE:"LIKE 'PROC_U%'" # 包含以PROC_U开头的所有存储过程(_ 符号代表任意单个字符)28 INCLUDE=TABLE:"> 'E' " # 包含大于字符E的所有表对象29EXCLUDE=[object_type]:[name_clause],[object_type]:[name_clause]30 EXCLUDE=SEQUENCE,VIEW # 过滤所有的SEQUENCE,VIEW31 EXCLUDE=TABLE:"IN ('EMP','DEPT')" # 过滤表对象EMP,DEPT32 EXCLUDE=SEQUENCE,VIEW,TABLE:"IN ('EMP','DEPT')" # 过滤所有的SEQUENCE,VIEW以及表对象EMP,DEPT33 EXCLUDE=INDEX:"= 'INDX_NAME'" # 过滤指定的索引对象INDX_NAME34# 注意事项:35 INCLUDE和EXCLUDE不可以连用,并且为了避免符号转义,一般使用参数文件形式。36 Windows平台需要对双引号进行转义,如 INCLUDE=TABLE:\"IN ('EMP', 'DEPT')\"。37 Unix平台所有的符号都需要进行转义,包括括号,双引号,单引号等,如INCLUDE=TABLE:\"IN \(\'EMP\', \'DEP\'\)\"。38
注意:
- EXPDP支持加载参数文件,防止命令行过长,如:expdp user/pwd parfile=xxx.par logfile=a.log。
- EXPDP支持NETWORK_LINK导出远程数据库,如:expdp network_link=dl_monitor dumpfile=network_monitor.dmp。
- EXPDP支持交互式窗口命令,具体详情参考官方文档。
3) 恢复数据库
xxxxxxxxxx181-- 导入整个数据库2impdb system/system123@ORCL01 DIRECTORY=dpdata1 DUMPFILE=DB_ORCL01_20230830.dmp FULL=y3
4-- 导入到默认用户(模式)5impdp krmp/krmp@ORCL01 DIRECTORY=dpdata1 DUMPFILE=USER_KRMP_20230830.DMP SCHEMAS=krmp6
7-- 导入到指定用户(模式)8impdp krmp2/krmp2@ORCL01 DIRECTORY=dpdata1 DUMPFILE=USER_KRMP_20230830.DMP SCHEMAS=krmp REMAP_SCHEMA=krmp:krmp2 # REMAP_SCHEMA格式为:a:b,c:d9
10-- 并行导入到默认用户11impdp krmp/krmp@ORCL01 DIRECTORY=dpdata1 DUMPFILE=USER_KRMP_20230830.DMP SCHEMAS=krmp parallel=10 # 同时导入10张表12
13-- 导入到默认表空间14impdp krmp/krmp@ORCL01 DIRECTORY=dpdata1 DUMPFILE=TS_KRMPSPACE.dmp TABLESPACES=KRMPSPACE # 也支持REMAP_TABLESPACE选项15
16-- 导入到默认表17impdp krmp/krmp@ORCL01 DIRECTORY=dpdata1 DUMPFILE=expdp.dmp TABLES=scott.dept18
3. 物理备份-热备份
1) 热备份简介
热备份也叫联机备份,它是指数据库处于open状态下,对数据库的数据文件、控制文件、参数文件、密码文件等进行一系列备份操作,它要求数据库处在归档模式下。
由于数据文件处于备份状态时重做日志后台进程要将这些文件的所有的变化数据块写到重做日志文件中,这对重做日志缓冲区和重做日志文件的压力都增大了,所以需要注意几下几点:
- 重做日志缓冲区和重做日志文件适当增大。
- 在联机备份时,每次只备份一个表空间。
- 在DML最少的时候做备份。
热备份的优点:
- 可在表空间或数据库文件级备份,备份的时间短。
- 备份时数据库仍可使用。
- 可达到秒级恢复(恢复到某一时间点上)。
- 可对几乎所有数据库实体做恢复
- 恢复是快速的,在大多数情况下数据库仍工作时恢复。
热备份的不足:
- 不能出错,否则后果严重
- 若热备份不成功,所得结果不可用于时间点的恢复
- 因难于维护,所以要特别仔细小心,不允许“以失败告终”。
2) 热备份流程
- 备份数据文件
xxxxxxxxxx131--------- 备份某个表空间 ---------------2-- 设置表空间为备份状态,表空间的名字和状态可用 select file_id,tablespace_name,status from dba_data_files 查看3alter tablespace PDMS_DATA begin backup;4-- 备份表空间的数据文件5host cp /opt/oracle/app/oradata/pdms/PDMS_DATA.dbf /u03/backup/hotbak6-- 恢复表空间为正常状态7alter tablespace PDMS_DATA end backup;8
9---------- 备份全数据库 ---------------10alter database begin backup;11host cp /opt/oracle/app/oradata/pdms/*.dbf /u03/backup/hotbak # 拷贝所有数据文件,备份完成后可用 select * from v$backup 查看数据文件的备份状态12alter database end backup;13
- 备份控制文件
xxxxxxxxxx61-- 控制文件的完整备份2alter database backup controlfile to '/u03/backup/hotbak/control_01.ctl'; 3
4-- 用于创建控制文件的语句,丢失了部分信息,可以直接查看5alter database backup controlfile to trace as '/u03/backup/hotbak/control_02.ctl'; 6
- 备份参数文件
xxxxxxxxxx11create pfile = '/u03/backup/hotbak/initdbsrv1.ora' from spfile;注:
- 临时表空间的数据文件、日志文件不需要备份。
4. 物理备份-冷备份
1) 冷备份简介
冷备份也叫脱机备份,其在关闭数据库后,将关键性文件拷贝到另外的位置,是最快和最安全的方法。注意其必须拷贝全部文件的备份,包括参数文件、所有控制文件、所有数据文件、所有联机重做日志文件。
冷备份的优点:
- 是非常快速的备份方法(只需拷贝文件)
- 容易归档(简单拷贝即可)
- 容易恢复到某个时间点上(只需将文件再拷贝回去)
- 能与归档方法相结合,作数据库“最新状态”的恢复。
- 低度维护,高度安全。
冷备份的不足:
- 单独使用时,只能提供到“某一时间点上”的恢复。
- 在实施备份的全过程中,数据库必须要作备份而不能作其它工作。也就是说,在脱机备份过程中,数据库必须是关闭状态。
- 若磁盘空间有限,只能拷贝到其它外部存储设备上,速度会很慢。
- 不能按表或按用户恢复。
2) 冷备份流程
- 以sys用户或者system身份登录数据库,以immediate方式关闭数据库。
- 把需要备份的文件拷贝到指定的位置。
- 拷贝完成后,如果继续让用户使用数据库,需要以open方式启动数据库。
3) 脱机恢复
数据库恢复就是把数据库中备份出来的数据重新还原给原来的数据库。数据库恢复技术分为完全恢复和不完全恢复。完全恢复是指把数据库恢复到数据库失败时的数据库状态,不完全恢复是指将数据库恢复到数据库失败前的某一时刻的数据库状态。
脱机恢复的步骤分为三步:
- 以sys用户或者system身份登录数据库,以immediate方式关闭数据库。
- 把所有备份文件全部拷贝到原来的位置。
- 恢复完成后,如果继续让用户使用数据库,需要以open方式启动数据库。
第03章_数据对象
第一节 数据类型
1. 字符型
| 数据类型 | 说明 |
|---|---|
| CHAR(size) | 定长字符串,不足补空格,可存储1~2000个字节或字符 |
| VARCHAR2(size) | 变长字符串,可存储1~4000个字节或字符 |
| NCHAR/NVARCHAR2(size) | 以 Unicode 国际字符集存储的字符串 |
注意:
- 定长字符串在实际存储数据时,会在右边补足空格,虽然浪费空间,但是存储效率更高,且能减少行迁移现象发生。
- 字符串类型可指定按字节或字符计数,如CHAR(2 BYTE)、VARCHAR2(8 CHAR),默认值由
NLS_LENGTH_SEMANTICS参数确定。- 不要使用VARCHAR类型,虽然目前是VARCHAR2的同义词,但是后续版本可能修改为不同的语义。
2. 数值型
| 数据类型 | 说明 |
|---|---|
| NUMBER(p,s) | 精确数值类型。Precison表示有效数字位数,最大为38位;Scale表示从小数点到最低有效数字的位数(正数时)或从最大有效数字到小数点的位数(负数时),取值范围为-84~127。 |
| INTEGER | NUMBER的子类型,等同于NUMBER(38,0),用来存储整数。若插入、更新的数值有小数,则会被四舍五入。 |
| FLOAT(n) | NUMBER的子类型,存储的精度是按二进制计算的,精度范围为二进制的1~126,在转化为十进制时需要乘以0.30103 |
| INT | 等同于NUMBER(22),用于兼容其它数据库,与之类似的还有decimal、numeric等。 |
注意:
- 当整数部分位数大于 p-s 时,就会报错;当小数部分位数小于 s 时,就会舍入;
- 当 s 为负数时,将对小数点左 s 个数字进行舍入;
- 当 s > p 时, p表示小数点后第s位向左最多可以有多少位数字,如果大于p则报错,小数点后s位向右的数字被舍入。
3. 日期/时间
| 数据类型 | 说明 |
|---|---|
| DATE | 包含年月日时分秒,固定按7个字节存储,默认格式由 NLS_DATE_FORMAT 或 NLS_TERRITORY 确定。 |
| TIMESTAMP(p) | 包含年月日时分秒和小数秒,默认格式由 NLS_TIMESTAMP_FORMAT 或 NLS_TERRITORY 确定。 其中 p 表示小数秒的精度,默认为 6 位,大小为7或11个字节。 |
| TIMESTAMP(p) WITH TIME ZONE | 含时区的TIMESTAMP,大小固定为13个字节,默认格式由 NLS_TIMESTAMP_TZ_FORMAT 参数确定。 |
| TIMESTAMP(p) WITH LOCAL TIME ZONE | 以数据库时区存储的TIMESTAMP,但在查询时转换为会话时区。默认格式由 NLS_DATE_FORMAT 或 NLS_TERRITORY 确定,大小为7或11个字节。 |
4. 其它数据类型
| 数据类型 | 说明 |
|---|---|
| LONG | 变长字符序列,最大长度2GB,不能建立索引和检索等,限制较多,推荐使用CBLOB。 |
| CBLOB | 存储字符串数据,最大4GB。 |
| BLOB | 存储二进制数据,最大4GB。 |
| BFILE | 用来把非结构化的二进制数据存储在数据库以外的操作系统文件中,大小与操作系统有关。 |
| RAW / LONG RAW | 长度大小为字节的原始二进制数据,最多可以存储2000/2GB字节的信息。 |
第二节 数据表
1. 定义表结构
xxxxxxxxxx401-- 创建普通表2CREATE TABLE student (3 sid NUMBER(8, 0),4 name VARCHAR2(20),5 sex CHAR(2),6 birthday DATE,7 address VARCHAR2(50)8) [tablespace 表空间名]; 9
10-- 创建全局临时表(会话级别)11CREATE GLOBAL TEMPORARY TABLE student_temp_sgt (12 sid NUMBER(8, 0),13 name VARCHAR2(20),14 sex CHAR(2),15 birthday DATE,16 address VARCHAR2(50)17) on commit preserve rows;18
19-- 创建全局临时表(事务级别)20CREATE GLOBAL TEMPORARY TABLE student_temp_tgt (21 sid NUMBER(8, 0),22 name VARCHAR2(20),23 sex CHAR(2),24 birthday DATE,25 address VARCHAR2(50)26) on commit delete rows;27
28
29-- 复制表及其数据30create table student2 as select * from student; 31
32-- 创建索引组织表33-- ORACLE中没有“聚集索引”的概念,但有与之类似的“索引组织表”34create table OIT0135(36 id int not null,37 nane varchar2(10),38 constraint PK_OIT01 primary key (id) -- 必须提供一个 PK39) organization index;40
2. 查询和删除表结构
xxxxxxxxxx91-- 查询系统中的表2SELECT * FROM DBA_TABLES WHERE TABLE_NAME = UPPER('STUDENT');3
4-- 查询表中的列5SELECT * FROM DBA_TAB_COLUMNS WHERE TABLE_NAME = UPPER('STUDENT');6
7-- 删除表及其约束8drop table student CASCADE CONSTRAINTS; -- 删除表,并级联删除表关联的约束9
3. 修改表结构
xxxxxxxxxx121-- 修改表名2rename student to student_info;3
4-- 增加列5alter table student add tel varchar2(11);6
7-- 删除列8alter table student drop column tel;9
10-- 修改列11alter table student modify tel number(11,0);12
第三节 约束
约束是ORACLE提供的自动保持数据库完整性的一种方法,它通过限制字段中数据、记录中数据和表之间的数据来保证数据的完整性。
xxxxxxxxxx61-- 查看表的约束2select * from user_constraints where table_name = 'INT_RATE'3
4-- 查看约束列5select * from User_Cons_Columns where table_name = 'INT_RATE';6
1. 主键约束(Primary Key)
主键约束用于定义数据表的主键,主键是表记录的唯一标识符,其值不能为NULL,也不能重复,以此来保证实体的完整性。
xxxxxxxxxx111-- 在创建表的同时添加主键约束2create table student(3 sid number(8,0), 4 name varchar2(20),5 sex char(2),6 birthday date, 7 constraint pk_sid primary key(sid)8);9
10-- 通过修改表结构来添加主键约束11alter table student add constraint pk_sid primary key(sid);注意:
- 约束名称子句 constraint pk_sid 可以省略,将会自动生成名称,其它约束也类似。
- 表中主键只能有一个,但可以由多个列构成。如:primary key(学号,科目编号)。
- 在创建主键时,如果主键字段不存在索引,则会生成一条唯一索引,在删除主键时,也会一并删除。
- 在创建主键时,如果主键字段存在索引(不管是否唯一),则不会再生成新的索引,在删除主键时,该索引依然保留。
2. 唯一约束(Unique)
唯一性约束用于指定一个或者多个列的组合值具有唯一性,以防止在列中输入重复的值。注意:使用唯一性约束的列允许空值。
xxxxxxxxxx111-- 在创建表的时候添加唯一性约束2create table student(3 sid number(8,0), 4 email varchar2(50) constraint uk_email unique, 5 cardid varchar2(18), 6 constraint uk_cardid unique(cardid)7);8
9-- 通过修改表结构来添加唯一性约束10alter table student add constraint uk_cardid unique(cardid);11
3. 非空约束(Not Null)
非空约束用于确保列不能为NULL。如果在列上定义了NOT NULL约束,那么当插入数据时,必须为该列提供数据;当更新列数据时,不能将其值设置为NULL。
xxxxxxxxxx131-- 在创建表时添加列级非空约束2-- 注意:NOT NULL 约束必须定义为列级约束3create table student(4 sid number(8,0) 5 name varchar2(20) not null, -- 匿名非空约束6 sex char(2) constraint nn_sex not null, -- 非空约束7 birthday date, 8);9
10-- 通过修改表结构来添加非空约束11-- 注意:添加非空约束采用的是 modify ,而非 add ,且非空约束的类型为 check12alter table student modify(name varchar2(20) constraint nn_name not null);13
4. 默认值约束(Default)
默认值约束用于指定列的默认值,在插入数据且没有输入该列的值时生效。可防止意外的空值输入。
xxxxxxxxxx131-- 在创建表的时候添加默认值约束2create table student(3 sid number(8,0), 4 sex varchar2(2) default '男', 5);6
7-- 通过修改表结构来添加默认值约束8-- 注意:与非空约束类似,添加默认值约束用modify,而非add9alter table student modify (sex varchar(2) default ‘男’);10 11-- 设置默认值后,插入数据时也可以显示使用默认值12insert into student values(20150001,’王五’,default,21);13
5. 检查约束(Check)
检查约束对输入列或者整个表中的值设置检查条件,以限制输入值,保证数据库数据的完整性。
xxxxxxxxxx111-- 在创建表的时候添加检查约束2create table student(3 sid number(8,0),4 name varchar2(20),5 sex char(2) constraint ck_sex check(sex in('男', '女')), -- 列级6 constraint ck_sid check(sid > 1000 and sid < 10000) -- 表级7);8
9-- 通过修改表结构来添加检查约束10alter table student add constraint ck_sex check(sex in('男', '女'));11
6. 外键约束(Foreign Key)
外键用于建立和加强两个表数据之间链接的一列或多列。外键约束是唯一涉及两个表关系的约束。
xxxxxxxxxx171-- 在创建表时添加外键约束2-- 注意:student是从表,department、Course是主表,应先创建主表再创建从表,插入数据也类似。3create table student(4 sid number(8,0),5 name varchar2(20), 6 depid varchar2(10) references department(depid),7 course varchar2(12),8 address VARCHAR2(50),9 constraint fk_course foreign key(course) references Course(course) 10);11 12
13-- 通过修改表结构添加外键约束14-- 注:on delete cascade 表示在删除主表记录时级联删除从表记录,类似的还有级联置空15alter table student add constraint fk_depid foreign key(depid) 16 references department(depid) on delete cascade;17
注意:
- 设置外键约束时主表的字段必须是主键列或唯一列。
- 主从表中相应字段必须是同一数据类型。
- 从表中外键字段的值必须来自主表中的相应字段的值,或者为NULL值。
7. 删除或禁用约束
xxxxxxxxxx91-- 删除约束:2alter table student drop constraint constraint_name;3 4-- 删除主键约束:5alter table student drop constraint key;6
7-- 禁用/激活约束:8alter table student disable | enable constraint constraint_name;9
第三节 索引
索引可以提升特定场景下查询的速度,Oracle支持B树索引、位图索引、反向索引和基于函数的索引等多种索引。
索引建立时应注意如下一些事项:
- 索引应该建立在 where 子句频繁引用、排序以及分组的列上,如果选择的列不合适将无法提升查询速度。
- 限制索引的个数。索引可以提升查询速度,但会降低 DML 操作的速度。
1. 创建索引
xxxxxxxxxx351-- 创建索引(B树)2-- pctfree:指定为将来 insert 操作所预留的空闲空间;tablespace:指定索引段所在的表空间3create index ID_EMP_DEPTNO on emp(deptno) Pctfree 25 Tablespace users; 4
5
6-- 创建唯一索引7-- 限制索引关联字段在表中的记录是唯一的,但是注意不能保证其不为空。8create unique index UID_EMP_DEPTNO on emp(deptno);9
10
11-- 基于函数的索引12-- 存放的数据是由表中数据应用函数后得到的,而不是直接存放表中的数据本身13create index index_test on emp( lower(job) );14
15
16-- 创建位图索引17-- 针对于索引值取值较少的场景,如对性别建立索引。18create bitmap index index_test on emp(salary) tablespace users;19
20
21-- 创建反向键索引22-- 在索引值单调递增的场景,可以将添加的数据更加随机的分散到索引中23create index index_test on emp(deptno) reverse;24
25-- 修改B树索引为反向键索引26Alter index index_test rebulid reverse;27
28
29-- 创建过滤索引(条件索引)30create index INDEX01 on STUDENT (31 case when NAME IN ('小明','小红','小刚') then NAME else to_char(SID) end ASC,32 SEX ASC,33 BIRTHDAY ASC34)35
2. 查看和删除索引
xxxxxxxxxx141-- 查询数据库中的普通索引和索引列2SELECT * FROM DBA_INDEXES WHERE INDEX_NAME = 'INDEX01';3SELECT * FROM DBA_IND_COLUMNS WHERE INDEX_NAME = 'INDEX01';4
5-- 查询函数索引和过滤索引6SELECT * FROM user_ind_expressions where index_name = 'INDEX01';7
8-- 查询索引所在段及大小9SELECT * FROM user_segments where segment_name = 'INDEX01'10
11-- 删除索引12-- 注:删除表也会自动删除其相应的索引。13drop index index_test14
3. 索引合并与重建
xxxxxxxxxx71-- 合并索引2-- 将 B 树中叶子节点的存储碎片合并在一起,并不会改变索引的物理组织结构3alter index INDEX01 Coalesce deallocate unused;4
5-- 重建索引6alter index INDEX00001 rebuild tablespace KFMSSPACE;7
第四节 视图
视图是一个逻辑数据结构,不存储实际数据,只存在它的定义语句。它可以简化查询语句的书写,进行权限的隔离,屏蔽基表的差异等。
1. 定义视图
xxxxxxxxxx231-- 创建视图2create view view01 as select * from student;3
4-- 创建只读视图5-- 视图只能用于查询,不能被修改6create view view02 as select * from student with read only;7
8-- 创建检查约束视图9-- 对通过视图进行的增删改操作进行"检查",要求增删改操作的数据, 必须是select查询所能查询到的数据,否则不允许操作并返回错误提示10create view view03 as select * from student where id = 10 with check option;11
12-- 强制创建视图13-- 不考虑基表是否存在,也不考虑是否具有使用基表的权限14create force view view04 as select * from student;15
16-- 修改视图17create or replace view view05 as select * from student;18
19-- 视图重编译20-- 在修改基表结构后,相关的视图会失效(INVALID),修改视图定义后,依赖它的视图或存储过程等也会失效,需要重新编译。21-- 但一般来说,除非修改了基表或视图的名称,否则在访问失效的对象时,会自动进行编译。22alter view view05 compile;23
2. 查看和删除视图
xxxxxxxxxx201-- 查询视图和视图列2SELECT * FROM DBA_VIEWS WHERE VIEW_NAME = UPPER('view01');3SELECT * FROM DBA_TAB_COLUMNS WHERE TABLE_NAME = UPPER('view01'); -- 注意:和表的列是同一个视图4
5-- 查询视图列的可更新/插入/删除状态6SELECT * FROM DBA_UPDATABLE_COLUMNS WHERE TABLE_NAME = UPPER('view01');7+-----+----------+-----------+---------+----------+---------+8|OWNER|TABLE_NAME|COLUMN_NAME|UPDATABLE|INSERTABLE|DELETABLE|9+-----+----------+-----------+---------+----------+---------+10|KRMP |VIEW01 |SID |YES |YES |YES |11|KRMP |VIEW01 |NAME |YES |YES |YES |12|KRMP |VIEW01 |SEX |YES |YES |YES |13|KRMP |VIEW01 |BIRTHDAY |YES |YES |YES |14|KRMP |VIEW01 |ADDRESS |YES |YES |YES |15+-----+----------+-----------+---------+----------+---------+16
17-- 删除视图18-- 注:视图被删除后,其他引用该视图的视图及存储过程等都会失效19drop view view01;20
3. 通过视图修改数据
- 如果是简单视图(基于单表,无复杂操作),可直接进行增删改查操作,会同步到对应的基表。
- 如果是只读视图,则无法进行任何数据的修改。
- 如果是检查约束视图,则必须保证修改后的数据能被视图查询,否则将会返回错误。
xxxxxxxxxx121-- 检查约束视图,检查 deptno=102create view vw_emp_check as select empno,ename,job,hiredate,deptno from emp where deptno=10 with check option;34-- 插入成功5insert into vw_emp_check values('2','c','cc','02-JAN-55',10);67-- 插入失败,因为 deptno=20 不在查询范围内,违反检查约束,所以无法插入8insert into vw_emp_check values('3','d','dd','02-JAN-65',20); -- ORA-01402: view WITH CHECK OPTION where-clause violation910-- 删除成功,所删除的数据在查询范围内,不违反检查约束11delete vw_emp_check where empno=2;12- 如果是连接视图或存在集合运算符、DISTINCT关键字、子查询、分组函数、GROUP BY/ORDER BY/CONNECT BY/START WITH子句等情形,则不建议进行更新操作。
第五节 物化视图
1. 物化视图简介
物化视图是一种真实存在的,占实际空间的数据库对象,一般用来生成基于数据表的汇总表,可以提高数据查询的效率,并且对数据有一定的保护作用。
注意:
- 物化视图可以查询表、视图以及其它的物化视图。当基表中的数据发生变化时,需要对物化视图进行刷新。
- 一般来说,物化视图是只读的,如果想对其进行修改,必须使用高级复制功能。
- 物化视图是真实存在的,故可以为其创建索引,以及分区等操作。
2. 创建物化视图
创建物化视图的语法格式如下,后续对各部分进行详细说明。
xxxxxxxxxx41create materialized view 视图名称2 创建时机 刷新方式 刷新时机 识别键 其它选项3 AS 查询语句4
- BUILD IMMEDIATE:是在创建物化视图的时候就生成数据,默认值。
- BUILD DEFERRED:则在创建时不生成数据,以后根据需要在生成数据。
COMPLETE:完全刷新。先删除所有记录,然后再根据视图定义刷新。注:单表刷新可能会使用TRUNCATE的方式。
FAST:快速刷新。采用增量刷新的机制,只将自上次刷新以后对基表进行的所有操作刷新到物化视图中去。
- 对于增量刷新选项,如果在子查询中存在分析函数,则物化视图不起作用。
- FAST的快速刷新机制是通过物化视图日志完成的,必须创建基于主表的物化视图日志。
FORCE:Oracle会自动判断是否满足快速刷新的条件,如果满足则进行快速刷新,否则进行完全刷新。
NEVER:指物化视图不进行任何刷新。
ON DEMAND:在用户需要的时候进行刷新,默认值。如通过手工执行
DBMS_MVIEW.REFRESH或设置定时任务刷新;ON COMMIT:一旦基表有事务提交,则立刻刷新。注意:使用该选项对性能影响较大,且无法访问远程对象。
START WITH... NEXT...:定时刷新。可指定第一次刷新时间,以及后续刷新间隔。
- WITH PRIMARY KEY:基于主表主键的物化视图,默认值。
- WITH ROWID:基于ROWID的物化视图,只有一个主表,不能有DISTINCT、聚合函数、GROUP BY、子查询、连接、集合运算等操作。
查询重写指当对物化视图的基表进行查询时,Oracle会自动判断能否通过查询物化视图来得到结果,如果可以,则避免了聚集或连接操作,而直接从已经计算好的物化视图中读取数据。
- ENABLE QUERY REWRITE:支持查询重写。
- DISABLE QUERY REWRITE:不支持查询重写,默认值。
在创建物化视图时指明 ON PREBUILD TABLE 语句,可以将物化视图建立在一个已经存在的表上。
这种情况下,物化视图和表必须同名。当删除物化视图时,不会删除同名的表。
这种物化视图的查询重写要求参数 QUERY_REWRITE_INTEGERITY 必须设置为 trusted 或者 stale_tolerated 。
在建立物化视图的时候可以指定ORDER BY语句,使生成的数据按照一定的顺序进行保存。不过这个语句不会写入物化视图的定义中,而且对以后的刷新也无效。
xxxxxxxxxx481-- 1. 基于单表查询的物化视图2CREATE MATERIALIZED VIEW mv01 AS SELECT * FROM RISK_INFO;3
4-- 2. 基于多表关联的物化视图5CREATE MATERIALIZED VIEW mv026 AS SELECT * FROM RISK_SCENE_DEGREES A7 WHERE EXISTS (SELECT * FROM RISK_SCENES B WHERE A.SCENE_ID = B.SCENE_ID);8
9-- 3. 基于主键的物化视图,采用快速刷新模式,从当前时间开始,每隔半小时刷新一次10CREATE MATERIALIZED VIEW mv0311 REFRESH FAST12 START WITH SYSDATE NEXT SYSDATE + 1/4813 WITH PRIMARY KEY14 AS SELECT * FROM RISK_INDICATORS; -- 注:RISK_INDICATORS必须包含主键约束15
16-- 注:采用快速刷新模式时,必须先创建基于主表的物化视图日志17CREATE MATERIALIZED VIEW LOG ON RISK_INDICATORS;18
19-- 扩展:主键类型的物化视图日志20CREATE MATERIALIZED VIEW LOG ON FLUC_STK_INFO TABLESPACE KRMP WITH PRIMARY KEY;21
22
23-- 4. 基于ROWID的物化视图24CREATE MATERIALIZED VIEW mv0425 REFRESH WITH ROWID26 AS SELECT * FROM RISK_FACTORS;27
28-- 5. 综合案例129CREATE MATERIALIZED VIEW mv0530 TABLESPACE KTRC_SPACE -- 保存的表空间31 BUILD DEFERRED -- 创建时不立即生成数据32 REFRESH FORCE -- 如果可以快速刷新则进行快速刷新,否则完全刷新33 ON DEMAND -- 按照指定方式手动刷新34 START WITH TO_DATE('2023-11-24 18:00:10', 'yyyy-mm-dd hh24:mi:ss') -- 第一次刷新时间35 NEXT TRUNC(SYSDATE+1) + 18/2436 AS SELECT * FROM USER_LOG;37
38
39-- 6. 综合案例240CREATE MATERIALIZED VIEW mv0841 REFRESH FAST42 ON DEMAND43 START WITH SYSDATE -- 第一次刷新时间44 NEXT SYSDATE+1/24/2045 WITH PRIMARY KEY -- 基于主键的物化视图46 DISABLE QUERY REWRITE -- 关闭查询重写47 AS SELECT INDICATOR_ID, INDICATOR_NAME FROM RISK_INDICATORS;48
扩展:物化视图日志
- Oracle通过一个物化视图日志还可以支持多个物化视图的快速刷新。
- 物化视图日志根据不同物化视图的快速刷新的需要,可以建立为ROWID或PRIMARY KEY类型的。
- 还可以选择是否包括SEQUENCE、INCLUDING NEW VALUES以及指定列的列表。
3. 查询物化视图
xxxxxxxxxx91-- 查询物化视图2SELECT * FROM USER_MVIEWS; -- 视图名称、上次刷新时间、刷新状态(STALENESS)3
4-- 查询物化视图刷新信息5SELECT * FROM USER_MVIEW_REFRESH_TIMES;6
7-- 查询物化视图日志8SELECT * FROM MLOG$_FLUC_STK_INFO; -- MLOG$_表名9
4. 刷新物化视图
xxxxxxxxxx91-- 手工刷新物化视图2EXEC DBMS_MVIEW.REFRESH('MV01');3EXEC DBMS_MVIEW.REFRESH('MV01','F'); -- 执行快速刷新4EXEC DBMS_MVIEW.REFRESH('MV01','C'); -- 执行完全刷新5
6-- 批量刷新物化视图7EXEC DBMS_REFRESH.MAKE('REFRESH_GROUP01', 'MV01,MV02,MV03', SYSDATE, 'SYSDATE+ 1'); -- 创建刷新组8EXEC DBMS_REFRESH.REFRESH('REFRESH_GROUP01'); -- 刷新整个刷新组9
5. 修改与删除物化视图
xxxxxxxxxx131-- 修改物化视图2ALTER MATERIALIZED VIEW MV013 REFRESH FORCE4 ON DEMAND5 START WITH SYSDATE6 NEXT TO_DATE(CONCAT(TO_CHAR(SYSDATE+1,'DD-MM-YYYY'),' 22:00:00'),'DD-MM-YYYY HH24:MI:SS'); -- 每天晚上10点刷新一次7
8-- 删除物化视图日志9DROP MATERIALIZED VIEW LOG ON RISK_INDICATORS;10
11-- 删除物化视图12DROP MATERIALIZED VIEW mv03;13
7. 物化视图分区
物化视图可以进行分区。而且基于分区的物化视图可以支持分区变化跟踪(PCT)。具有这种特性的物化视图,当基表进行了分区维护操作后,仍然可以进行快速刷新操作。对于聚集物化视图,可以在GROUP BY列表中使用CUBE或ROLLUP,来建立不同等级的聚集物化视图。
第六节 序列
序列用于产生一系列唯一数字。由于oracle中没有设置自增列的方法,所以我们在oracle数据库中主要用序列来实现主键自增的功能。
1. 创建和修改序列
xxxxxxxxxx241-- 创建序列的语法格式2CREATE SEQUENCE sequence -- 创建序列名称3[INCREMENT BY n] -- 递增的序列值是 n 如果 n 是正数就递增,如果是负数就递减 默认是 14[START WITH n] -- 开始的值,递增默认是 minvalue 递减是 maxvalue5[{MAXVALUE n | NOMAXVALUE}] -- 最大值 6[{MINVALUE n | NOMINVALUE}] -- 最小值7[{CYCLE | NOCYCLE}] -- 循环/不循环8[{CACHE n | NOCACHE}]; -- 分配并存入到内存中9
10
11-- 创建一个最小值为9,最大值为500,从10开始,步长为10的循环序列,每次加载50个值放入内存待使用12create sequence SEQ_CACHE113 increment by 1014 start with 1015 maxvalue 50016 minvalue 917 cycle18 cache 50;19
20
21-- 可以修改序列的增量, 最大值, 最小值, 循环选项, 或是否装入内存22alter sequence seqEmp maxvalue 5;23ALTER SEQUENCE emp_sequence INCREMENT BY 10 MAXVALUE 10000 CYCLE;24
注意:
- 创建或修改序列时需保证“最大值-最小值 >= (缓存值-1)*每次循环的值”。
- 在修改序列时,只有将来的序列值会被改变。
- 改变序列的初始值只能通过删除序列之后重建序列的方法实现。
2. 查询和删除序列
xxxxxxxxxx61-- 查询数据库中的序列2SELECT * FROM DBA_SEQUENCES WHERE SEQUENCE_NAME = 'SEQ01';3
4-- 删除序列5drop sequence SEQ01; 6
3. 使用序列
xxxxxxxxxx61-- 序列调用 产生一个新的序列2select seq_test.nextval from dual3
4-- 查看当前序列的值5select seq_test.currval from dual6
注意:
- 序列在使用缓存、事务回滚、多表使用同一序列、系统异常等情形时,可能出现序列裂缝(不连续)。
- 使用alter system flush shared_pool 可以清空 cache 中缓存的序列值。
第七节 数据库链接
1. DB_LINK简介
Database Link用于访问远程数据库对象,按可使用的对象分为:
- 私有DB_LINK(private):仅创建该DB_LINK的用户可使用,不能授权给其它用户使用。
- 公有DB_LINK(public):Owner为public,数据库中的所有用户经授权后方可使用。
- 全局DB_LINK(global):Owner为public,可以在多个数据库之间共用,一般用于分布式环境。
2. 创建DB_LINK
xxxxxxxxxx281-- 创建语法2CREATE [SHARED][PUBLIC] database link link_name3 [CONNECT TO [user][current_user] IDENTIFIED BY password]4 [AUTHENTICATED BY user IDENTIFIED BY password]5 [USING 'connect_string']6
7-- 使用网络服务名配置信息创建(推荐)8CREATE DATABASE LINK DB_LINK01 CONNECT TO KRMP IDENTIFIED BY "1" using '(DESCRIPTION =(ADDRESS_LIST =(ADDRESS =(PROTOCOL = TCP)(HOST = 10.203.2.84)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = pdborcl))) ';9
10-- 使用网络服务名创建11CREATE DATABASE LINK DB_LINK02 CONNECT TO KRMP IDENTIFIED BY "1" using 'SERVICE_NAME_PDBORCL';12
13-- 使用连接字符串创建14CREATE DATABASE LINK DB_LINK03 CONNECT TO KRMP IDENTIFIED BY "1" using '10.203.2.84:1521/pdborcl';15
16-- 可重复执行创建脚本17DECLARE18 NUM NUMBER;19BEGIN20 SELECT COUNT(1) INTO NUM FROM user_db_links WHERE db_link = 'DBLINK_KBSSDSVC';21 IF NUM > 0 THEN22 EXECUTE IMMEDIATE 'drop database link DBLINK_KBSSDSVC';23 END IF;24
25 EXECUTE IMMEDIATE 'create database link DBLINK_KBSSDSVC connect to &1 identified by &2 using ''(DESCRIPTION =(ADDRESS_LIST =(ADDRESS =(PROTOCOL = TCP)(HOST = &3)(PORT = &4)))(CONNECT_DATA =(SERVICE_NAME = &5))) '' ';26END;27/28
注意:
- 创建 DB_LINK 需要当前数据库的 CREATE DATABASE LINK 或 CREATE PUBLIC DATABASE LINK 权限,以及远程数据库的 CREATE SESSION 权限。
3. 查询和使用DB_LINK
xxxxxxxxxx311-- 1. 查询已创建的DB_LINK2SELECT * FROM DBA_DB_LINKS WHERE DB_LINK = 'DB_LINK01';3SELECT * FROM DBA_OBJECTS WHERE OBJECT_TYPE = 'DATABASE LINK';4
5
6-- 2. 查询远程对象7SELECT * FROM table_name@database link; 8select A.SERIAL_NO, A.BIZ_CONTENT, B.FLD_NAME, B.NEW_VAL FROM USER_LOG@DB_LINK01 A LEFT JOIN USER_LOG_DETAIL B ON A.SERIAL_NO = B.SERIAL_NO;9
10-- 扩展:不想让使用的人知道 database link 的名字的时候,建一个别名或视图来包装一下 11CREATE SYNONYM table_name2 FOR table_name@database link;12CREATE VIEW table_name2 AS SELECT * FROM table_name@database link; 13SELECT * FROM table_name2; 14
15
16-- 3. 无法通过DB_LINK直接执行DDL语句17drop table db_test@DBLINK_CONNECTED_HR; -- ORA-02021: DDL operations are not allowed on a remote database18
19
20-- 4. 可通过DB_LINK执行远程库的存储过程(在存储过程中执行DDL语句)21-- 远程库创建存储过程如下22create or replace procedure p_execute_ddl(p_ddl in varchar2)23as24begin25execute immediate p_ddl;26end;27/28-- 在本地库通过DB_LINK调用,间接执行DDL语句29exec p_execute_ddl@DBLINK_CONNECTED_HR('drop table db_test');30
31
注意:
- 使用DB_LINK时应注意事务问题,是否需要加上 set transaction read only 。
4. 删除DB_LINK
xxxxxxxxxx71-- 删除public类型的database link2DROP PUBLIC database link link_name; 3
4-- 删除非public类型的database link5-- 注意:只有owner自己能删除自己的非public类型database link6DROP database link link_name; 7
第八节 同义词
同义词是数据库对象的一个别名,在使用同义词时,Oracle数据库将它翻译成对应Scheme对象的名字。大部分数据库对象,如表、视图、物化视图、序列、函数、存储过程、包、同义词等,都可以根据实际情况为它们定义同义词。
- 私有同义词:一般由普通用户创建,跟公用同义词所对应,由创建他的用户所有,同义词的创建者,可以通过授权控制其他用户是否有权使用属于自己的私有同义词。
- 公用同义词:一般由DBA创建,由一个特殊的用户组Public所拥有,数据库中所有的用户都可以使用公用同义词,往往用来标示一些比较普通的数据库对象,这些对象往往大家都需要引用。
同义词可以简化对象访问和提高对象访问的安全性,如操作其他用户的表时,不再需要通过user名.object名的形式。
同义词还可以为分布式数据库的远程对象提供位置透明性,如访问数据库链接时不再需要通过object名@数据库链名的形式。
1. 创建同义词
xxxxxxxxxx181-- 创建专有(私有)同义词2CREATE SYNONYM SYSN_TEST FOR TEST; -- 需要 CREATE SYNONYM 权限3CREATE SYNONYM SCOTT.EM FOR SOCTT.EMP; -- 创建其它模式的同义词,需要 CREATE ANY SYNONYM 权限4
5
6-- 创建公用同义词7-- 公用同义词是和用户的schema无关的,但是公共的意思并不是所有的用户都可以访问它,必须被授权后才能进行 8CREATE PUBLIC SYNONYM PUBLIC_TEST FOR TEST; -- CREATE PUBLIC SYNONYM 系统权限9
10
11-- 为DB_LINK创建同义词12-- Create database link 数据库链接名 connect to 用户名 identified by 口令 using 'Oracle连接串'; 13create synonym table_name for table_name@DB_Link;14
15
16-- 重编译同义词17ALTER SYNONYM S1 COMPILE; 18
2. 查询和删除同义词
xxxxxxxxxx131-- 查询数据库的同义词2SELECT * FROM DBA_SYNONYMS WHERE SYNONYM_NAME = 'S1';3
4-- 查询同义词有效状态5SELECT OBJECT_NAME, STATUS FROM ALL_OBJECTS WHERE OBJECT_NAME='DUAL';6
7-- 删除同义词8-- 注意:当同义词的原对象被删除时,同义词并不会被级联删除9DROP SYNONYM SYSN_TEST;10
11-- 删除公有同义词12DROP PUBLIC SYNONYM PUBLIC_TEST; 13
3. 使用同义词
xxxxxxxxxx31-- 使用同义词查询2SELECT * FROM SYSN_TEST;3
注意:
- 不能创建和数据库对象同名的私有同义词。
- 数据库对象(或私有同义词)和公有同义词同名时,优先访问数据库对象(或私有同义词)。
第九节 分区表
1. 分区表简介
分区表即把某个大表按某种规则水平拆分成几个部分分开存储,各分区之间可独立查询,并建立各自的索引,不仅改善了查询性能,对数据的管理、备份和恢复也方便。
2. 哈希分区
对于那些无法有效的划分范围的表,可以使用 hash 分区。hash分区会将数据平均的分配到指定的几个分区表中,由于数据被平均分配到不同的分区,减少查询时对数据块的竞争,这样对于提高性能还是会有一些帮助,列所在的分区是依据分区列的hash值自动分配,因此不能控制,也不知道哪条记录被放到哪个分区中。
xxxxxxxxxx141-- 创建哈希分区表2CREATE TABLE drawlist(3 draw_id NUMBER,4 draw_name VARCHAR2(20)5)6-- 创建散列分区7PARTITION BY HASH(draw_name)8(9 PARTITION p1 TABLESPACE USERS,10 PARTITION p2 TABLESPACE USERS,11 PARTITION p3 TABLESPACE USERS,12 PARTITION p4 TABLESPACE USERS13);14
注意:
- hash分区也可以支持多个依赖列。
- 建立散列分区最好使用2的冥次个分区表。
3. 范围分区
范围分区是使用最广泛的分区方式。它是以列值所属的范围来作为分区的划分条件,将记录存放到列值所在的 range 分区中。
xxxxxxxxxx291
2-- 建立一个按时间分区的分区表如下:3CREATE TABLE drawlist(4 drawname VARCHAR2(20),5 drawtime DATE NOT NULL6)7PARTITION BY range(drawtime)( --创建表分区,以drawtime为分区范围8 PARTITION part_1 VALUES LESS THAN (to_date('2010-1-1','yyyy-mm-dd')), -- 定义2010-1-1以前的数据保存的分区,不包括2010-1-19 PARTITION part_2 VALUES LESS THAN (to_date('2011-1-1','yyyy-mm-dd')), -- 定义2011-1-1以前的数据分区10 PARTITION part_3 VALUES LESS THAN (to_date('2012-1-1','yyyy-mm-dd')),11 PARTITION part_4 VALUES LESS THAN (maxvalue) -- 其他的值保存的分区12)13
14-- 插入数据,系统会自动将数据保存到对应的分区表中。15INSERT INTO drawlist16SELECT 'aaa',to_date('2009-10-20','yyyy-mm-dd') FROM dual UNION 17SELECT 'bbb',to_date('2009-11-20','yyyy-mm-dd') FROM dual UNION 18SELECT 'ccc',to_date('2009-12-20','yyyy-mm-dd') FROM dual UNION 19SELECT 'ddd',to_date('2010-10-20','yyyy-mm-dd') FROM dual UNION 20SELECT 'eee',to_date('2010-10-20','yyyy-mm-dd') FROM dual UNION 21SELECT 'fff',to_date('2011-10-20','yyyy-mm-dd') FROM dual UNION 22SELECT 'ggg',to_date('2012-10-20','yyyy-mm-dd') FROM dual 23
24-- 查询分区表25SELECT * FROM drawlist PARTITION (part_1);26SELECT * FROM drawlist PARTITION (part_2);27SELECT * FROM drawlist PARTITION (part_3);28SELECT * FROM drawlist PARTITION (part_4);29
4. 列表分区
列表分区也需要指定列的值,其分区必须明确指定,该分区列只能有一个,不能像range或hash分区那样同时指定多个列作为分区依赖列,但它的单个分区对应值可以是多个。使用列表分区,必须确定分区列可能存在的值,一旦插入的列值不在分区范围内,则插入/更新就会失败,因此通常建议使用list分区时,要创建一个default分区存储哪些不在指定范围内的记录,类似range分区中的maxvalue分区。
xxxxxxxxxx131CREATE TABLE area2(3 CODE NUMBER,4 NAME VARCHAR2(20)5)6-- 创建列表分区7PARTITION BY LIST(CODE)8(9 PARTITION p1 VALUES(10,20,30), -- 指定当code值为10,20,30为第一分区10 PARTITION p2 VALUES(40,50,60), -- 指定当code值为40,50,60为第二分区11 PARTITION p_other VALUES(DEFAULT) -- 其他值为第三分区12)13
5. 间隔分区
在Oracle10g中,没有定义间隔分区,只能通过范围分区实现间隔分区功能,如果要实现自动创建分区,只能通过创建JOB或者scheduler来实现;而在11g中,Oracle直接提供了间隔分区功能,大大简化了间隔分区的实现。
xxxxxxxxxx181CREATE TABLE interval_sales2 ( prod_id NUMBER(6)3 , cust_id NUMBER4 , time_id DATE5 , channel_id CHAR(1)6 , promo_id NUMBER(6)7 , quantity_sold NUMBER(3)8 , amount_sold NUMBER(10,2)9 )10 PARTITION BY RANGE (time_id)11 INTERVAL(NUMTOYMINTERVAL(1, \'MONTH\'))12 ( PARTITION p0 VALUES LESS THAN (TO_DATE(\'1-1-2008\', \'DD-MM-YYYY\')),13 PARTITION p1 VALUES LESS THAN (TO_DATE(\'1-1-2009\', \'DD-MM-YYYY\')),14 PARTITION p2 VALUES LESS THAN (TO_DATE(\'1-7-2009\', \'DD-MM-YYYY\')),15 PARTITION p3 VALUES LESS THAN (TO_DATE(\'1-1-2010\', \'DD-MM-YYYY\')) )16 17
18
上述sql语句创建了4个不等区间的分区,分别是2008年1月1日之前的所有数据、08年到09年的所有数据、09年上半年的所有数据、09年下半年的所有数据;同时,它也制定了在2010年1月1日之后,每个月单独创建一个分区。需要注意一点,间隔分区的键值只能是一个列,并且该列只能是Date类型或者number类型。
6. 多级分区
如果某表按照某列分区之后仍然较大,或者有一些其他的需求,还可以通过分区内再建子分区的方式将分区再分区,即组合分区的方式。
xxxxxxxxxx141-- 范围-哈希(range-hash)2PARTITION BY RANGE (列1) SUBPARTITION BY HASH(列2)(3 PARTITION 分区名 VALUES LESS THAN (值)4 TABLESPACE 表空间5)6
7-- 范围-列表(range-list)8PARTITION BY RANGE (列1) SUBPARTITION BY LIST(列2)(9 PARTITION 分区名 VALUES LESS THAN (值) 10 TABLESPACE 表空间(11 SUBPARTITION 子分区名 VALUES(列表指定值...) TABLESPACE 表空间12 )13 )14
7.分区索引
分区之后虽然可以提高查询效率,但也仅是缩小了数据的范围,所以我们在有必要的情况下,需要在分区内建立索引,进一步提高效率。
分区索引分为两类。一类叫做local。一类叫做global。
- local:每个分区上都建立索引(本地索引)。
- global:一种是在全局上建立索引,这种方式分布分区都一样,一般不使用。
xxxxxxxxxx191
2-- 本地索引 3create index grade_index on tablename(grade) local4 5-- 在p1和p2和p3三个分区上分别建立索引6create index grade_index on studentgrade(grade)7 local --根据表分区创建本地索引分区8 (9 partition p1,10 partition p2,11 partition p312 );13
14-- 查看分区索引15select * from user_ind_partitions;16
17-- 全局索引18create index idxname on tablename (field) global;19
还有一种就是自定义数据区间的前缀索引,这个是非常有意义的,自定义区间值必须使用MAXVALUE。另外一点是在分区上建立的索引必须是分区字段列。
xxxxxxxxxx51create index idxname on tablename(field) global partition by range(field){2 partition p1 values less than(value),3 partition p2 values less than(maxvalue)4};5
8. 分区维护
xxxxxxxxxx431
2-- 查看分区数据3select * from area PARTITION (p1);4select * from area PARTITION (p2);5
6-- 查看表分区信息7select * from user_tab_partitions where table_name ='tableName';8
9-- 增加分区10ALTER TBALE 表名 ADD PARTITION 分区表名 VALUES LESS THAN(值)11
12-- 增加区间分区13ALTER TABLE drawlist ADD PARTITION p3 VALUES LESS THEN to_date('2013-1-1','yyyy-mm-dd') TABLESPACE USERS;14-- 注意:插入的区间数据值不能小于原有的分区表的值。如果包含了maxvalues,必须删除原有分区表15 16-- 删除分区17ALTER TABLE 表名 DROP PARTITION 分区表名18
19-- 删除区间分区(注:删除分区表后,分区表中的数据也会一同删除)20ALTER TABLE drawlist DROP PARTITION p3 21 22-- 截断分区:删除当前分区中的数据,但是它并不会影响其他分区。23ALTER TABLE 表名 TRUNCATE PARTITION 分区表名24ALTER TABLE drawlist TRUNCATE PARTITION p3 25 26-- 合并分区:将两个分区表中的数据合并到一个分区,被合并的分区将不复存在。注意:高界线的分区不能合并到低界线的分区中。比如将小于2009年的数据合并到小于2010年的分区中,反过来则不行。27ALTER TABLE 表名 MERGE PARTITIONS 分区表1,分区表2 INTO PARTITION 分区表228ALTER TABLE drawlist MERGE PARTITIONS p1,p2 INTO PARTITION p229
30-- 拆分分区:拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。31ALTER TABLE TABLENAME SBLIT PARTITION P2 AT(TO_DATE('2003-02-01','YYYY-MM-DD')) INTO (PARTITION P21,PARTITION P22);32
33-- 可移动分区34-- 更新数据是操作时不可以跨分区操作,会出现错误,需要设置可移动的分区才能进行跨分区查询。35alter table tablename enable row movement;36
37-- 接合分区(coalesca) 38-- 结合分区是将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,值得注意的是,接合分区只能用于散列分区中。通过以下代码进行接合分区:39ALTER TABLE SALES COALESCA PARTITION;40
41-- 重命名表分区 42ALTER TABLE SALES RENAME PARTITION P21 TO P2; -- 将P21更改为P243
第04章_增删改查
第一节 数据修改
1. 插入数据
xxxxxxxxxx221-- 1. 插入单行所有列2insert into DEPT(DEPTNO,DNAME,LOC) values(50, 'Public', 'changsha'); -- 此时 (DEPTNO,DNAME,LOC) 部分可以省略 3
4-- 2. 插入单行部分列5insert into DEPT(DEPTNO,DNAME) values(60, null); -- DNAME为显式插入空值,LOC为隐式插入空值6
7-- 3. 插入多行数据8INSERT ALL9 INTO T1 (C1, C2, C3) VALUES (1, 'C2', 'C3')10 INTO T1 (C1, C2, C3) VALUES (2, 'C2', 'C3')11SELECT 1 FROM dual; -- 注:Oracle不支持Values后拼接多个值列表12
13-- 4. SQLPlus交互式插入数据/脚本传入SQL参数14insert into DEPT(DEPTNO,DNAME,LOC) values(&deptno,&dname, '默认');15insert into DEPT(DEPTNO,DNAME,LOC) values(&1,&2, '默认'); -- &1、&2用于执行脚本时传参16
17-- 5. 拷贝表插入18insert into DEPT2 select * from DEPT where DEPTNO = 20;19
20-- 6. 插入重复行21INSERT /*+IGNORE_ROW_ON_DUPKEY_INDEX(t3,idx_t3_col3) */ INTO t3 (col3_a,col3_b) VALUES (1,3);22
2. 删除数据
xxxxxxxxxx111-- 删除数据2delete [from] DEPT where DEPTNO > 30; 3
4-- 清空数据5truncate table T1;6
7-- 删除表中重复记录8delete from T19where C1 in (select C1 from T1 group by C1 having count(C1) > 1)10 and rowid not in (select min(rowid) from T1 group by C1 having count(C1)>1);11
注意:
- delete:是DML语言,逐条删除,不释放空间,会产生碎片,可以回滚和闪回。
- trunc:是DDL语言,先摧毁再重建,会释放空间,不产生碎片,不可以回滚和闪回。
3. 修改数据
xxxxxxxxxx621-- 修改数据2update DEPT set DEPTNO = 70 , DNAME = 'HH', LOC = 'BeiJing' where DEPTNO = 80;3
4-- UPDATE SET FROM 5-- 一个SqlServer的USF语法如下;6UPDATE t 7 SET t.EXT_SUBSYS_SN = tt.SUBSYS_SN 8 FROM CUACCT_LOG t,CUACCT tt9 WHERE t.CUACCT_CODE = tt.CUACCT_CODE10 AND t.SETT_DATE = 2023092011 AND t.BIZ_NO = 20230920000000112 AND tt.SUBSYS_SN > 0;13
14-- Oracle本身不支持 USF 语法,主要通过子查询实现15-- 案例1:一次子查询更新一个列16UPDATE EMP1 SET SAL = (SELECT SAL+1 FROM EMP WHERE EMPNO = 7568) WHERE EMPNO = 7568;17
18-- 案例2:一次子查询更新多个列19UPDATE EMP1 SET (SAL,COMM) = (SELECT SAL+1,nvl(COMM,0)+1 FROM EMP WHERE EMPNO = 7568) WHERE EMPNO = 7568;20
21-- 案例3:上述SqlServer语句在Oracle中应该这样写22UPDATE CUACCT_LOG t23 SET t.EXT_SUBSYS_SN = (select tt.SUBSYS_SN from CUACCT tt WHERE t.CUACCT_CODE = tt.CUACCT_CODE and tt.SUBSYS_SN > 0)24 WHERE t.SETT_DATE = @SETT_DATE 25 AND t.BIZ_NO = @BIZ_NO26 -- 必须包含一个exists子句,否则CUACCT表数据不存在时,CUACCT_LOG.EXT_SUBSYS_SN将会被更新为NULL27 AND exists (select 1 from CUACCT tt WHERE t.CUACCT_CODE = tt.CUACCT_CODE and tt.SUBSYS_SN > 0); 28
29-- 案例4:复杂案例30UPDATE CUACCT_FUND CF31 SET (FUND_BLN,CASH_ACCU,INT_BLN_ACCU,FUND_ALLOCATED_FRZ) 32 = (SELECT CF.FUND_BLN - A.FUND_BLN,33 CF.CASH_ACCU - A.CASH_ACCU,34 CF.INT_BLN_ACCU - A.INT_BLN_ACCU,35 CF.FUND_ALLOCATED_FRZ - A.FUND_BLN36 FROM (SELECT CUACCT_CODE, CURRENCY,SUM(FUND_BLN) AS FUND_BLN, 37 SUM(CASH_ACCU) AS CASH_ACCU,SUM(INT_BLN_ACCU) AS INT_BLN_ACCU38 FROM FUND_CHANGE_DETAIL39 WHERE SETT_DATE = 20200324 AND BAT_NO = 20200324999001 40 GROUP BY CUACCT_CODE, CURRENCY41 ) A42 WHERE A.CUACCT_CODE = CF.CUACCT_CODE AND A.CURRENCY = CF.CURRENCY43 )44 WHERE EXISTS( SELECT 1 45 FROM (SELECT CUACCT_CODE, CURRENCY,SUM(FUND_BLN) AS FUND_BLN, 46 SUM(CASH_ACCU) AS CASH_ACCU,SUM(INT_BLN_ACCU) AS INT_BLN_ACCU47 FROM FUND_CHANGE_DETAIL48 WHERE SETT_DATE = 20200324 AND BAT_NO = 20200324999001 49 GROUP BY CUACCT_CODE, CURRENCY50 ) A51 WHERE A.CUACCT_CODE = CF.CUACCT_CODE AND A.CURRENCY = CF.CURRENCY52 );53
54-- 扩展:USF语法也可通过行列子集视图实现,但不推荐55-- 注意:update只涉及一个表且视图列中包含了被更新的表的整个主键,否则不能更新视图的基表56UPDATE (57 SELECT E1.EMPNO,E1.SAL SAL1, E.EMPNO, E.SAL SAL2 FROM EMP E,EMP1 E1 58 WHERE E.EMPNO = E1.EMPNO AND E.EMPNO = 756859)60SET SAL1 = SAL2 61
62
4. 归并数据
xxxxxxxxxx91-- 数据存在就更新,不存在则插入2MERGE INTO A_MERGE A 3USING (SELECT B.AID,B.NAME,B.YEAR,B.CITY FROM B_MERGE B) C 4 ON (A.ID=C.AID) 5 WHEN MATCHED THEN -- 当ON中的条件匹配时6 UPDATE SET A.NAME=C.NAME WHERE C.CITY != '江西' -- 执行操作 更新或删除等7 WHEN NOT MATCHED THEN -- 当ON中的条件不匹配时8 INSERT(A.ID,A.NAME,A.YEAR) VALUES(C.AID,C.NAME,C.YEAR) WHERE C.CITY='江西'; -- 执行操作 新增等9
第二节 数据查询
1. 简单查询
xxxxxxxxxx151-- 1. 查询所有列2select * from DEPT;3
4-- 2. 查询部分列5select EMPNO,ENAME from EMP;6
7-- 3. 去除重复列8select DISTINCT EMPNO,ENAME from EMP;9
10-- 4. 给列起别名11select EMPNO 员工编号,ENAME 员工姓名 from EMP; -- 如果别名中带有空格或是纯数字,则需要用双引号括起来12 13-- 5. 列参与运算14select EMPNO 员工编号,ENAME 姓名,SAL 薪水,COMM 奖金,(SAL+COMM)*12 年收入 from EMP; 15
2. 列表达式
xxxxxxxxxx201-- 1. SQL99表达式(类似IF语句)2SELECT 3 CASE WHEN SCORE < 60 THEN '不及格' 4 WHEN SCORE >= 60 AND SCORE < 90 THEN '及格' 5 ELSE '优秀' 6 END 7 FROM (SELECT 70 SCORE FROM DUAL);8 9-- 2. SQL99表达式特殊情形(类似SWITCH语句)10SELECT 11 CASE SCORE WHEN 60 THEN '及格线' 12 WHEN 90 THEN '优秀线' 13 ELSE '其它' 14 END 15 FROM (SELECT 90 SCORE FROM DUAL);16 17-- 3. 特殊情形可以使用DECODE函数简化18SELECT DECODE(SCORE, '60', '及格线', 90, '优秀线', '其它') 19 FROM (SELECT 90 SCORE FROM DUAL);20
3. 结果排序
xxxxxxxxxx221-- 1. 依据单列排序2-- 查询员工的编号、姓名和薪水,并根据薪水升序3select EMPNO 员工编号,ENAME 姓名,SAL 薪水4 from EMP5 order by SAL asc; -- asc可以省略6 #order by 薪水 asc; -- 用别名来代替列名排序7 #order by 3 asc; -- 用序号代替列名排序8 #order by SAL*12 asc; -- 列名也可以进行运算9
10-- 查询员工的编号、姓名和奖金,并根据奖金降序11select EMPNO 员工编号,ENAME 姓名,COMM 奖金12 from EMP13 order by COMM desc14 nulls last; -- 排序列为空的行置后15
16
17-- 2. 依据多列排序18-- 查询员工的编号、姓名、部门编号和薪水,先根据部门编号升序,在根据薪水降序19select EMPNO 员工编号,ENAME 姓名,DEPTNO 部门编号,SAL 薪水20 from EMP21 order by DEPTNO asc,SAL desc;22
4. 结果分组
1) 依据单列分组
xxxxxxxxxx41-- eg:求出EMP表中各部门的平均工资2select DEPTNO 部门编号, avg(SAL)3 from EMP4 group by DEPTNO;
2) 依据多列分组
xxxxxxxxxx51-- eg:按部门 不同的职位 统计平均工资2select DEPTNO 部门编号,JOB 职位,avg(SAL)3 from EMP4 group by DEPTNO,JOB5 order by 1;
3) 分组过滤(having)
xxxxxxxxxx51-- eg:查询平均工资大于2000的部门2select DEPTNO, avg(SAL)3 from EMP4 group by DEPTNO 5 having avg(SAL) > 2000;注意:
- where语句在分组前对查询记录进行过滤,条件中不能包括聚合函数。
- having子句在分组后对组进行过滤,用于筛选满足条件的组,条件中常包含聚合函数。
4) 分组聚合
xxxxxxxxxx101-- 1)MAX MIN AVG SUM 函数2-- EG:求员工表中 最高工资,最低工资 平均工资 所有工资3select max(SAL) 最高工资,min(SAL) 最低工资, avg(SAL) 平均工资,sum(SAL)总工资4 from EMP;5
6-- 2)count函数7-- EG: 返查询员工表中的经理总人数(去除重复)8select count(distinct MGR) 经理总人数9 from EMP;10
注意:
- 组函数默认忽略空值,可手动调用滤空函数来特殊处理。
5) 高级分组
group by(A,B,C):正常按(A,B,C)分组。
xxxxxxxxxx31select earnmonth, area, sum(personincome)2from earnings3group by earnmonth,area;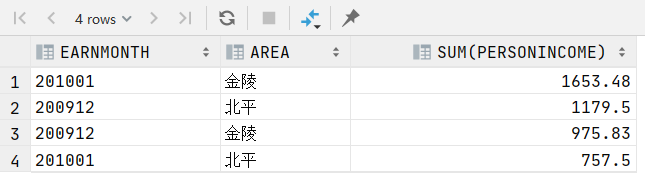
group by rollup(A,B,C):按(A,B,C)、(A,B)、(A)执行三次分组查询,再将全表作为一个组执行一次查询。
xxxxxxxxxx41select earnmonth, area, sum(personincome)2from earnings3group by rollup(earnmonth,area);4
group by cube(A,B,C):按(A,B,C)、(A,B)、(A,C)、(A)、(B,C)、(B)、(C)执行七次分组查询,再将全表作为一个组执行一次查询。
xxxxxxxxxx51select earnmonth, area, sum(personincome)2from earnings3group by cube(earnmonth,area)4order by earnmonth,area nulls last; -- 其中nulls last表示null值放在末尾5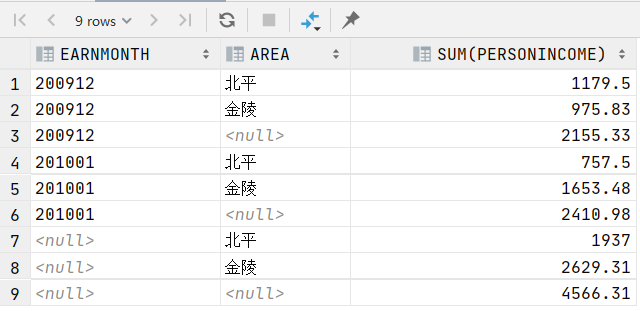
在以上例子中,用 rollup 和 cube 函数都会对结果集产生null,这时候可用grouping函数来确认该记录是由哪个字段得出来的。
xxxxxxxxxx81-- grouping:参数为字段名,如果当前行是由 rollup/cube 汇总得来的,结果就返回1,反之返回0。2select decode(grouping(earnmonth),1,'所有月份',earnmonth) 月份,3 decode(grouping(area),1,'全部地区',area) 地区, 4 sum(personincome) 总金额5 from earnings6 group by cube(earnmonth,area)7 order by earnmonth,area nulls last;8
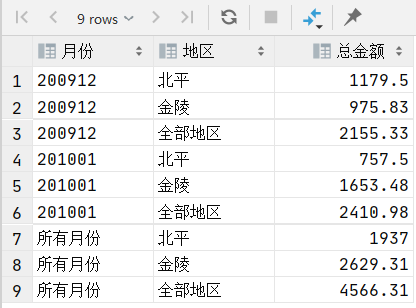
5. 查询过滤
1) 空值过滤
xxxxxxxxxx51-- 查询奖金为空/不为空的员工编号和姓名2select EMPNO 员工编号, ENAME 员工姓名, COMM 奖金 from EMP3 where COMM is NULL; 4 -- where COMM is not NULL;5
2) 离散过滤
xxxxxxxxxx101-- 1) 查询部门编号是/不是20的员工编号和姓名2select EMPNO 员工编号, ENAME 员工姓名, DEPTNO 部门编号 from EMP3 where DEPTNO = 20; 4 -- where DEPTNO != 20;5
6-- 2) 查询部门编号是/不是20或30的员工编号和姓名7select EMPNO 员工编号, ENAME 员工姓名, DEPTNO 部门编号 from EMP8 where DEPTNO in (20,30); 9 -- where DEPTNO not in (20,30);10
注意:
- in后带有 null 将会被忽略,而 not in 后带有null,会导致表达式始终不成立。
3) 连续过滤
xxxxxxxxxx51-- 查询薪水在/不在1000到2000之间的员工编号和姓名2select EMPNO 员工编号, ENAME 员工姓名, SAL 薪水 from EMP3 where SAL between 1000 and 2000; 4 -- where SAL not between 1000 and 2000; 5
注意:
- between… and… 是双闭区间,等效:where SAL >=1000 and SAL <=2000;
- not between… and… 是双开区间,等效:where SAL < 1000 OR SAL > 2000;
4) 模糊过滤
xxxxxxxxxx121-- 查询名字以S开头的员工编号和姓名2select EMPNO 员工编号,ENAME 姓名 from EMP3 where ENAME like ‘S%’;4
5-- 查询名字是四个字母的员工编号和姓名6select EMPNO 员工编号,ENAME 姓名 from EMP7 where ENAME like ‘____’;8
9-- 查询名字含有下划线的员工编号和姓名 (查询的内容含有转义字符)10select EMPNO 员工编号,ENAME 姓名 from EMP11 where ENAME like ‘%\_%’ escape ‘\’; 12
扩展:
escape ‘\’用来定义转义开始字符,也可以用其它字符,如 ! 号。
6. 子查询
1) 单行子查询与多行子查询
xxxxxxxxxx241-- 查询薪水大于SCOTT的员工编号和姓名2select EMPNO 员工编号, ENAME 员工姓名3 from EMP4 where SAL > (select SAL from EMP where ENAME = 'SCOTT');5
6-- 查询部门编号不是SALES或ACCOUNTING的员工编号和姓名7select EMPNO 员工编号, ENAME 员工姓名8 from EMP9 where DEPTNO not in (select DEPTNO from DEPT where DNAME = 'SALES' or dname='ACCOUNTING');10
11-- 查询薪水 比30号部门 所有员工薪高的员工信息 12select EMPNO 员工编号, ENAME 员工姓名13 from EMP14 where SAL > all(select SAL from EMP where DEPTNO = 30);15-- 一切all都可以用>max替代,如上例只要大于30部门薪水的最大值即可 16 where SAL > (select max(SAL) from EMP where DEPTNO = 30 );17
18-- 查询薪水 比30号部门 任意一个员工薪高的员工信息 19select EMPNO 员工编号, ENAME 员工姓名20 from EMP21 where SAL > any( select SAL from EMP where DEPTNO = 30 );22-- 一切any都可以用> min 替代,如上例只要大于30部门薪水的最小值即可 23 where SAL > ( select min(SAL) from EMP where DEPTNO = 30 );24
注意:
- 单行子查询只能用单行比较操作符 (= < >),多行子查询只能用多行比较操作符 (in any all)。
- 单行/多行子查询只能通过主键(或唯一索引)保证。但一般在业务层面确定,与预期不一致时,将会因为操作符不匹配而报错。
2) 相关子查询与非相关子查询
上述例子都是非相关子查询,即子查询返回值给主查询使用,另一种子查询叫相关子查询,即主查询 通过别名 把主查询的值 传递给 子查询,每一行处理的过程分为三步解析:
- 主查询传字段值值给子查询
- 子查询使用主表字段
- 主查询使用子查询的返回结果
xxxxxxxxxx101-- 查找 员工表中 薪水 大于 本部门平均薪水 的员工2select E.EMPNO 员工编号,E.ENAME 员工姓名,E.SAL 薪水, ( select avg(sal) from EMP where DEPTNO = E.DEPTNO ) 平均薪水3 from EMP E -- 1 主查询中:给EMP表起个别名,方便传值4 where SAL > ( select avg(SAL) from EMP where DEPTNO = E.DEPTNO ); -- 2 子查询中:引用主查询中的EMP表5 -- 3 子查询返回结果后主查询继续执行6
7-- 相关子查询难以理解,可以改写为 一般子查询 + 多表查询8select E.EMPNO 员工编号,E.ENAME 员工姓名,E.SAL 薪水,D.AVGSAL9 from EMP E, (select DEPTNO, avg(SAL) from EMP group by DEPTNO ) D 10 where E.DEPTNO = D.DEPTNO and E.SAL > D.AVGSAL
3) 使用子查询的一些注意事项
- 不能在order by和group by后放子查询,也不能在select语句后放多行子查询,但from、where、having后都可接子查询。
- 子查询有时可以用多表查询替代,并且效率更高,如下:
xxxxxxxxxx131-- EG:查询部门是SALES的员工信息2select EMPNO 员工编号, ENAME 员工姓名3 from EMP 4 where DEPTNO = (5 select DEPTNO6 from DEPT7 where DNAME = 'SALES');8 9-- 可以替换为:10select EMPNO 员工编号, ENAME 员工姓名11 from EMP,DEPT12 where EMP.DEPTNO = DEPT.DEPTNO and DEPT.DNAME = 'SALES';13 注意:
- Mysql中子查询必须起别名,否则会报“ERROR 1248 (42000): Every derived table must have its own alias”错误。
4) 子查询应用:TOP-N问题
xxxxxxxxxx51-- EG:查询薪水排行前三的员工信息2select rownum, EMPNO, ENAME, SAL 3from ( select EMPNO, ENAME, SAL from EMP order by SAL desc)4where rownum<=3; -- rownum是oracle的伪列5
注意:
TOP-N问题如果需要排序,应采用两层结构,因为rownum是属于服务器返回的结果集的固有属性,排序会打乱rownum的顺序
只能使用rownum<=3,而不能使用rownum>=3,因为没有产生第1行、第2行,就不可能出现满足条件的第3行、第4行。
与rownum相关的还有结果集的行地址rowid,唯一标识数据库中的一条表记录,用法如下:
xxxxxxxxxx11select rowid, empno, ename from emp;
5) 子查询应用:分页问题
xxxxxxxxxx71-- EG:查询薪水排行为 5-8 的员工信息2select r, EMPNO, ENAME, SAL3 from (select rownum r, EMPNO, ENAME, SAL 4 from (select EMPNO, ENAME, SAL from EMP order by SAL desc)5 where rownum<=8)6 where r >= 5;7 扩展:分页问题解决思路
- 内层:排序。
- 中层:使用rownum选择前n条;并给rownum指定一个别名,以供最外层过滤使用。
- 外层:去掉前m条结果。
7. 关联查询

1) 内连接
内连接(INNER JOIN)分显式的和隐式的,返回连接表中符合连接条件和查询条件的数据行。
xxxxxxxxxx221-- 隐式的内连接没有INNER JOIN,形成的中间表为两个表的笛卡尔积。2select E.EMPNO 员工编号,E.ENAME 姓名,D.DNAME 部门名称3 from EMP E,DEPT D4 where E.DEPTNO = D.DEPTNO;5 6-- 显式的内连接有INNER JOIN,形成的中间表为两个表经过ON条件过滤后的笛卡尔积。7select E.EMPNO 员工编号,E.ENAME 姓名,D.DNAME 部门名称8 from EMP E9 inner join DEPT D on E.DEPTNO = D.DEPTNO;10
11-- 如果内连接的连接条件是=,则称为等值连接,否则称为非等值连接,如 12-- eg: 查询员工表中的员工编号、姓名、薪水和薪水表中的薪水级别13select E.EMPNO 员工编号,E.ENAME 姓名,E.SAL 薪水, S.GRADE 薪水级别14 from EMP E,SALGRADE S15 where E.SAL between S.LOSAL and S.HISAL;16
17-- 也可以写成18select E.EMPNO 员工编号,E.ENAME 姓名,E.SAL 薪水, S.GRADE 薪水级别19 from EMP E20 inner join SALGRADE S 21 on E.SAL between S.LOSAL and S.HISAL;22
2) 外连接
外连接分为左外连接、右外连接以及全连接,其中左外连接表示除了返回自连接的结果外,还额外返回左表中不满足连接条件的行,此时结果集中这些行右表的数据为null。
xxxxxxxxxx131-- eg: 查询部门表中的部门编号、部门名称和统计各部门人数(员工表)2select D.DEPTNO 部门编号, D.DNAME 部门名称, count(E.EMPNO) 部门人数3 from DEPT D,EMP E4 where D.DEPTNO = E.DEPTNO(+) -- 要想显示DEPT表中所有的部门编号,则要在=对面加上(+),表示左外连接5 group by D.DEPTNO,D.DNAME;6 7
8-- 上述语句也可写为9select D.DEPTNO 部门编号, D.DNAME 部门名称, count(E.EMPNO) 部门人数10 from DEPT D11 left join EMP E on D.DEPTNO = E.DEPTNO12 group by D.DEPTNO,D.DNAME;13
右外连接与左外连接类似,不同的是额外返回右表中不满足连接条件的行,全连接表示既返回左表又返回右表中不满足条件的行,关键字分别为right join和full join。
3) 自连接
一种特殊的连接,即对同一个表进行连接操作, 这个连接叫做自连接。
xxxxxxxxxx71-- eg: 查询员工的老板信息2select E1.ENAME 员工姓名 || '的老板是' || nvl(E2.ENAME, '他自己')3 from EMP E1,EMP E2;4 where E1.MGR = E2.EMPNO(+);5-- E1表中KING的MGR为空,不可能满足条件,因此要用外连接显示E1表中所有的行6-- 即使E1表中的所有行显示出来了,但KING的老板为空,应进行滤空修正7
4) 其它
SQL99标准提供了一些新的连接方式,如:
自然连接(NATURAL JOIN):自动查询两张连接表中所有相同的字段 ,然后进行等值连接。
xxxxxxxxxx11SELECT employee_id,last_name,department_name FROM employees e NATURAL JOIN departments d;USING连接:指定数据表里的同名字段进行等值连接。
xxxxxxxxxx21SELECT employee_id,last_name,department_name FROM employees e2JOIN departments d USING (department_id);
8. 递归查询
递归查询也称结构化查询/分层查询,下面是一个示例:
xxxxxxxxxx41SELECT * FROM EMP WHERE EMPNO != 7839 -- 递归查询的数据范围2 START WITH EMPNO = 7369 OR EMPNO = 7934 -- 根结点,可以是多个,即同时查询多颗树3 CONNECT BY PRIOR MGR=EMPNO -- 连接条件,用PRIOR表示上一条记录 4 ORDER BY SAL DESC; -- 查询结果可以进行排序查询结果如下:
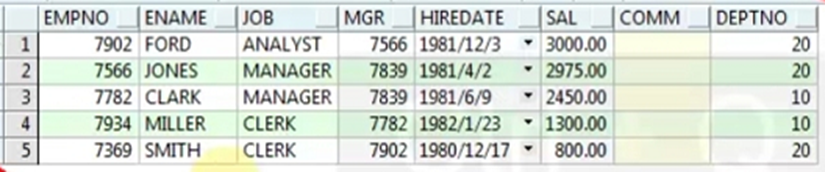
9. 集合运算
1) union/union all
union用于返回两个集合去掉重复元素后的所有记录,union all直接返回两个集合所有元素,不进行去重。
xxxxxxxxxx71-- eg:查询E1和E2表中的所有员工信息,去掉重复项2select EMPNO, JOB3 from EMP14union 5select EMP, JOB6 from EMP2;7
2) intersect
intersect运算符返回同时属于两个集合的记录。
xxxxxxxxxx91-- EG: 显示薪水同时位于级别1(700~1300)和级别2(1201~1400)的员工信息2select ENAME,SAL 3 from EMP4 where SAL between 700 and 13005intersect 6select ENAME,SAL 7 from EMP8 where SAL between 1201 and 1400;9
3) minus
minus返回属于第一个集合,但不属于第二个集合的记录。
xxxxxxxxxx91-- EG: 显示薪水同时位于级别1(700~1300),但不属于级别2(1201~1400)的员工信息2select ENAME,SAL 3 from EMP4 where SAL between 700 and 13005minus 6select ENAME,SAL 7 from emp8 where SAL between 1201 and 1400;9
4) 集合运算的注意事项
- select语句中参数类型和个数要一致。
- 可以使用括号改变集合执行的顺序。
- 如果有order by子句,必须放到每一句查询语句后。
- 集合运算采用第一个语句的表头作为表头。
10. 公用表达式(CTE)
xxxxxxxxxx101WITH department_avg_salary AS (2 SELECT department, AVG(salary) AS avg_salary3 FROM employees4 GROUP BY department5)6SELECT e.name, e.salary7 FROM employees e8 JOIN department_avg_salary d ON e.department = d.department9 WHERE e.salary > d.avg_salary;10
第三节 内置函数
1. 单行函数
单行函数为查询的表或视图的每一行返回一个结果行。这些函数可以出现在SELECT列表、WHERE子句、START WITH和CONNECT BY子句以及HAVING子句中。
1) 数值函数
数值函数接受 numeric 值输入并返回 numeric 值,返回值精确到小数点后30~38位。
xxxxxxxxxx121-- 绝对值、取余2SELECT ABS(-1), mod(10,3) FROM DUAL; -- 1 13
4-- 四舍五入(参数2表示舍入位数)5select round(45.923,2) as "2", round(45.923,0) as "0", round(45.925,-1) as "-1" from dual; -- 45.92 46 506
7-- 数值截断(参数2表示截断位数)8select trunc(45.923,2) "2",trunc(45.923,0) "0",trunc(45.925,-1) "-1" from dual; -- 45.92 45 409
10-- 向上取整,向下取整11SELECT CEIL(1.2), CEIL(-1.2), FLOOR(1.2), FLOOR(-1.2) FROM DUAL; -- 2 -1 1 -212
注意:
- Mysql不支持trunc函数。
2) 字符函数
xxxxxxxxxx371-- 1. 大小写转换2select lower('HeLlo wOrld') 全小写, upper('hello world') 全大写, initcap('hello woRld') 首字母大写 from dual;3
4-- 2. 字符串连接5select concat('aaaa', concat('bbbb', 'cccc')) 字符串连接 from dual;6select 'aaaa' || 'bbbb' || 'cccc' 字符串连接 from dual; -- 也可以用连接符||来实现7
8-- 3. 子串截取9select substr('abcd黄原鑫hijklmn', 3, 10) 子串截取 from dual; -- 从位置3开始,截取10个字符,参数2可以缺省 cd黄原鑫hijkl10select substring('Hello MySQL',1,5); -- 仅Mysql支持11
12-- 4. 子串查找13select instr('aaaabbbbb', 'ab') from dual; -- 返回参数1中ab首次出现的位置,或0 414
15-- 5. 子串替换16select replace('abcd', 'bc', 'cb') from dual; -- 把参数1中的参数2替换为参数3 acdb17
18-- 6. 字符长度(汉字占一个字符)19select length('中国abc') 字符数 from dual; -- Oracle/Gauss集中式-PG兼容返回5,Mysql返回720
21-- 7. 字节长度(汉字占两个字节)22select lengthb('中国abc') 字节数 from dual; -- Oracle返回7,Mysql不支持23
24-- 8. 字符串填充25select lpad('abcd', 10, '*') 左填充 , rpad('abcd', 10, '*') 右填充 from dual -- 参数1:字符串 参数2:总长度 参数3:填充值26
27-- 9. 字符串修剪28select trim(' hello '), ltrim(' hello '), rtrim(' hello '), trim('H' from 'HellowroHldHHHHH') from dual; -- hello hello空格 空格hello ellowroHld29
30-- 10. 返回首字符的ASCII码31SELECT ASCII('A'), ASCII('a'), ASCII('AIX') FROM DUAL; -- 65 97 6532
33-- 11. 正则操作34REGEXP_REPLACE35REGEXP_SUBSTR36REGEXP_COUNT37REGEXP_INSTR注意:
- Mysql字符串拼接只能用
concat函数,不能用||或+号拼接,但是可以输入多个参数,如:select concat('A','B','C')。- Mysql不支持initcap和lengthb函数,并且length函数执行结果和Oracle不一致(Oracle返回字符数,Mysql返回字节数)。
- Mysql的子串截取函数,除了substr外,还可以用substring,功能和参数含义相同。
- 关于instr的区别:Mysql中instr('','')返回1,而Oracle中将''视为null,返回null。
- 关于substr的区别:Mysql中substr('abc',0,1)返回'',而Oracle中与substr('abc',1,1)效果一致,都返回'a'。
3) 日期时间函数
xxxxxxxxxx411-- 1. 当前日期时间2SELECT CURRENT_DATE 当前日期01, SYSDATE 当前日期02,3 CURRENT_TIMESTAMP 当前日期时间01, SYSTIMESTAMP 当前日期时间02,4 LOCALTIMESTAMP 本地化日期时间 FROM DUAL; 5+-------------------+-------------------+--------------------------+---------------------------------+--------------------------+6|当前日期01 |当前日期02 |当前日期时间01 |当前日期时间02 |本地化日期时间 |7+-------------------+-------------------+--------------------------+---------------------------------+--------------------------+8|2023-11-13 10:28:13|2023-11-13 18:28:13|2023-11-13 10:28:13.444503|2023-11-13 18:28:13.444500 +08:00|2023-11-13 10:28:13.444503|9+-------------------+-------------------+--------------------------+---------------------------------+--------------------------+10
11-- 2. 日期运算12-- 在Oracle中,日期和整数可以直接运算,整数的单位为天13SELECT SYSDATE - 1 FROM DUAL; -- 日期减1(昨天)14select (sysdate – HIREDATE) 距今天数 from EMP; -- 日期-日期=>相差天数15
16-- 3. 两个日期相差的月数(精确月)17select months_between(sysdate,HIREDATE) from EMP;18
19-- 4. 向指定日期加上指定月数20select add_months(sysdate,1) 加1月 from dual;21
22-- 5. 指定日期的下一个日期23select next_day(sysdate,'星期五') from dual; -- 下一个星期五24
25-- 6. 本月最后一天26select last_day(sysdate) 本月最后一天 from dual;27
28-- 7. 日期四舍五入29select round(sysdate,'month') from dual; -- 日期按月四舍五入30select round(sysdate,'year') from dual; -- 日期按年四舍五入31
32-- 8. 日期截断33select trunc(sysdate,'month') from dual; -- 日期按月四舍截断34select trunc (sysdate,'year') from dual; -- 日期按年四舍截断35
36-- 9. 日期提取年月日、时间戳提取年月日时分秒37SELECT EXTRACT(YEAR FROM SYSDATE) 年, EXTRACT(MONTH FROM SYSDATE) 月, EXTRACT(DAY FROM SYSDATE) 日 FROM DUAL;38SELECT EXTRACT(YEAR FROM LOCALTIMESTAMP) 年, EXTRACT(MONTH FROM LOCALTIMESTAMP) 月, EXTRACT(DAY FROM LOCALTIMESTAMP) 日, EXTRACT(HOUR FROM LOCALTIMESTAMP) 时, EXTRACT(MINUTE FROM LOCALTIMESTAMP) 分, EXTRACT(SECOND FROM LOCALTIMESTAMP) 秒 FROM DUAL;39 年 月 日 时 分 秒40---------- ---------- ---------- ---------- ---------- ----------41 2023 9 22 15 42 5.185注意:
- Mysql和oracle都支持使用
CURRENT_TIMESTAMP获取当前日期和时间。
4) 类型转换函数
xxxxxxxxxx221-- 1. 数值转字符串2SELECT TO_CHAR(123456.789) NTOC, TO_CHAR(123456.789,'L999,999.000') NTOM FROM DUAL; -- 123456.789 ¥123,456.7893
4-- 2. 字符串转数值5SELECT TO_NUMBER('123456.789') CTON, TO_NUMBER('¥123,456.789','L999,999.000') MTON FROM DUAL; -- 123456.789 6
7-- 3. 日期转字符串8SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') FROM DUAL; -- 2023-09-229SELECT TO_CHAR(SYSDATE, 'YEAR-MONTH-DAY') FROM DUAL; -- TWENTY TWENTY-THREE-9月 -星期五10
11-- 4. 字符串转日期12SELECT TO_DATE('2023-09-22', 'YYYY-MM-DD') FROM DUAL;13
14-- 5. 时间戳转字符串15SELECT TO_CHAR(SYSTIMESTAMP, 'YYYY-MM-DD HH24:MI:SS.FF6') FROM DUAL; -- 2023-09-22 16:30:08.16300016
17-- 6. 字符串转时间戳18SELECT TO_TIMESTAMP('2023-09-22 16:30:08.163000', 'YYYY-MM-DD HH24:MI:SS.FF6') FROM DUAL;19
20-- 7. ASCII码和CHAR转换21SELECT ASCII('a'),CHR(97) FROM DUAL;22
注意:
SYSDATE的默认显示格式为DD-MON-RR,其中RR表年份,与YY表示的年份在跨xx50年时会有所差别。
设置当前会话的默认日期/时间戳展示格式(如下第2/3行SQL经测试无效):
xxxxxxxxxx61-- 指定日期/时间戳格式2alter session SET nls_date_format='YYYY-MM-DD';3alter session SET NLS_TIMESTAMP_FORMAT='YYYY-MM-DD HH24:MI:SS.FF6';4-- 设置语言区域6alter session SET nls_language='SIMPLIFIED CHINESE'; -- 可选'AMERICAN'等Mysql中字符串转数值转换失败时不会报错,如CAST('中' AS SIGNED)和'中'+1分别返回0和1,而Oracle中会报“无效数字”错误。
5) 滤空函数
xxxxxxxxxx111-- 1. NULL值转换函数2-- NVL:若expr1为空值,则转换为expr2(支持日期、数字、字符串)3-- NVL2:若expr1为空值,转换为expr3,否则转换为expr24SELECT NVL(NULL,'Default') 空值, NVL2(NULL,'Replace','Default') 是否为NULL FROM DUAL; -- 0 1 5
6-- 2. 滤空函数7SELECT COALESCE(NULL,NULL,1,2) 滤空 FROM DUAL; -- 返回参数列表中第一个不为空的expr8
9-- 3. 等值判断函数10SELECT NULLIF('A','A') 相等返回NULL, NULLIF('A','B') 不相等返回A FROM DUAL; -- 若expr1与expr2相等,则返回NULL,不等返回expr1(注意:expr1不能为NULL)11
注意:
- Mysql不支持Nvl和Nvl2,但有类似的IFNULL(NULL,'DEFAULT')函数。
- Mysql和Oracle都支持使用COALESCE函数进行滤空。
5) 其它单行函数
xxxxxxxxxx271-- 1. 获取系统上下文2-- 参考:https://docs.oracle.com/en/database/oracle/oracle-database/12.2/sqlrf/SYS_CONTEXT.html#GUID-B9934A5D-D97B-4E51-B01B-80C76A5BD0863SELECT SYS_CONTEXT ('USERENV', 'SESSION_USER') FROM DUAL;4
5-- 2. 返回有关当前会话的信息6-- 参考:https://docs.oracle.com/en/database/oracle/oracle-database/12.2/sqlrf/USERENV.html#GUID-AC3C8AEF-A988-41C4-9242-69B54E5941D27SELECT USERENV('LANGUAGE') "Language" FROM DUAL; -- AMERICAN_CHINA.ZHS16GBK8
9-- 3. 生成GUID10-- 返回由16个字节组成的全局唯一标识符(RAW类型),由主机标识符、调用函数的进程/线程等确定11SELECT SYS_GUID() FROM DUAL; -- 33316E3FF4F844ABB01616F20503440A12
13-- 4. 获取会话用户的唯一标识14SELECT UID FROM DUAL;15
16-- 5. 递归查询的路径17SELECT LPAD(' ', 2*level-1)||SYS_CONNECT_BY_PATH(last_name, '/') "Path"18 FROM employees19 START WITH last_name = 'Kochhar'20 CONNECT BY PRIOR employee_id = manager_id;21Path22------------------------------23 /Kochhar/Greenberg/Urman24 /Kochhar/Higgins/Gietz25 /Kochhar/Mavris26 /Kochhar/Whalen27 /KochharCOLLECT、SET、CAST
2. 窗口函数
1) 窗口函数简介
窗口函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
| 分析函数 | 说明 |
|---|---|
| sum() over(partition by ... order by ...) | |
| max() over(partition by ... order by ...) | |
| min() over(partition by ... order by ...) | |
| avg() over(partition by ... order by ...) | |
| count() over(partition by ... order by ...) | |
| row_number() over(partition by ... order by ...) | |
| rank() over(partition by ... order by ...) | |
| dense_rank() over(partition by ... order by ...) | |
| first_value() over(partition by ... order by ...) | |
| last_value() over(partition by ... order by ...) | |
| lag() over(partition by ... order by ...) | |
| lead() over(partition by ... order by ...) |
下面是一些业务数据,将基于此对上述函数进行验证:
xxxxxxxxxx371create table earnings -- 打工赚钱表2(3 earnmonth varchar2(6), -- 打工月份4 area varchar2(20), -- 打工地区5 sno varchar2(10), -- 打工者编号6 sname varchar2(20), -- 打工者姓名7 times int, -- 本月打工次数8 singleincome number(10,2), -- 每次赚多少钱9 personincome number(10,2) -- 当月总收入10);11
12SELECT * FROM earnings;13
14insert into earnings values('200912','北平','511601','大魁',11,30,11*30);15insert into earnings values('200912','北平','511602','大凯',8,25,8*25);16insert into earnings values('200912','北平','511603','小东',30,6.25,30*6.25);17insert into earnings values('200912','北平','511604','大亮',16,8.25,16*8.25);18insert into earnings values('200912','北平','511605','贱敬',30,11,30*11);19
20insert into earnings values('200912','金陵','511301','小玉',15,12.25,15*12.25);21insert into earnings values('200912','金陵','511302','小凡',27,16.67,27*16.67);22insert into earnings values('200912','金陵','511303','小妮',7,33.33,7*33.33);23insert into earnings values('200912','金陵','511304','小俐',0,18,0);24insert into earnings values('200912','金陵','511305','雪儿',11,9.88,11*9.88);25
26insert into earnings values('201001','北平','511601','大魁',0,30,0);27insert into earnings values('201001','北平','511602','大凯',14,25,14*25);28insert into earnings values('201001','北平','511603','小东',19,6.25,19*6.25);29insert into earnings values('201001','北平','511604','大亮',7,8.25,7*8.25);30insert into earnings values('201001','北平','511605','贱敬',21,11,21*11);31
32insert into earnings values('201001','金陵','511301','小玉',6,12.25,6*12.25);33insert into earnings values('201001','金陵','511302','小凡',17,16.67,17*16.67);34insert into earnings values('201001','金陵','511303','小妮',27,33.33,27*33.33);35insert into earnings values('201001','金陵','511304','小俐',16,18,16*18);36insert into earnings values('201001','金陵','511305','雪儿',11,9.88,11*9.88);37
2) 分区进行求和
xxxxxxxxxx81-- 分区进行求和、最高值、最低值、平均值2select distinct earnmonth 月份, area 地区,3 sum(personincome) over(partition by earnmonth,area) 分区和,4 max(personincome) over(partition by earnmonth,area) 最高值,5 min(personincome) over(partition by earnmonth,area) 最低值,6 avg(personincome) over(partition by earnmonth,area) 平均值7from earnings;8
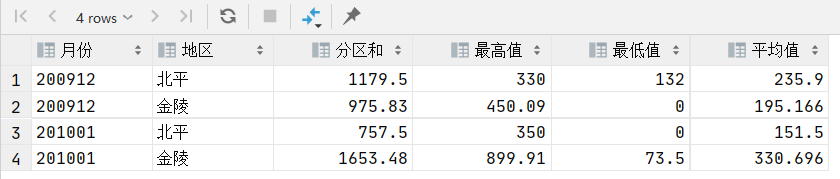
3) 分区进行累计求和
xxxxxxxxxx51-- 按月份和地区分区,算每个分区的累积收入2select earnmonth 月份,area 地区,sname 打工者, personincome 收入,3 sum(personincome) over (partition by earnmonth,area order by personincome) 月份地区累积收入4from earnings;5
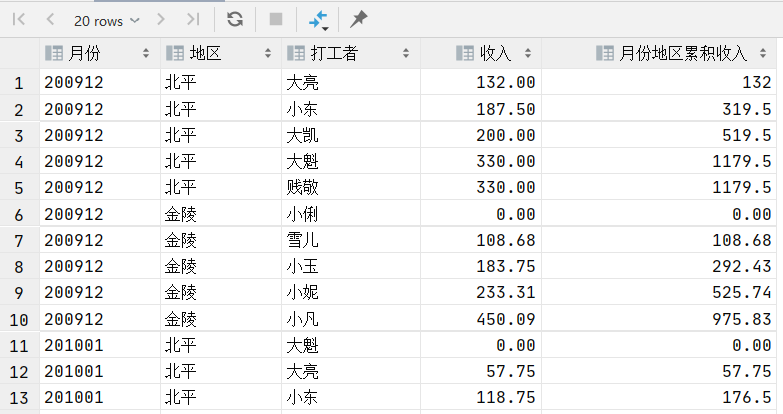
4) 分区进行编号排名
xxxxxxxxxx141-- 分区进行编号、排名、密集排名(不跳号)2select earnmonth 月份,area 地区,sname 打工者, personincome 收入,3 row_number() over (partition by earnmonth,area order by personincome desc) 编号,4 rank() over (partition by earnmonth,area order by personincome desc) 排名,5 dense_rank() over (partition by earnmonth,area order by personincome desc) 密集排名6from earnings;7
8-- 查询各班前三名9select * from10 (11 select name,class,score,rank()over(partition by class order by score desc) RK from student12 )13where RK <=314
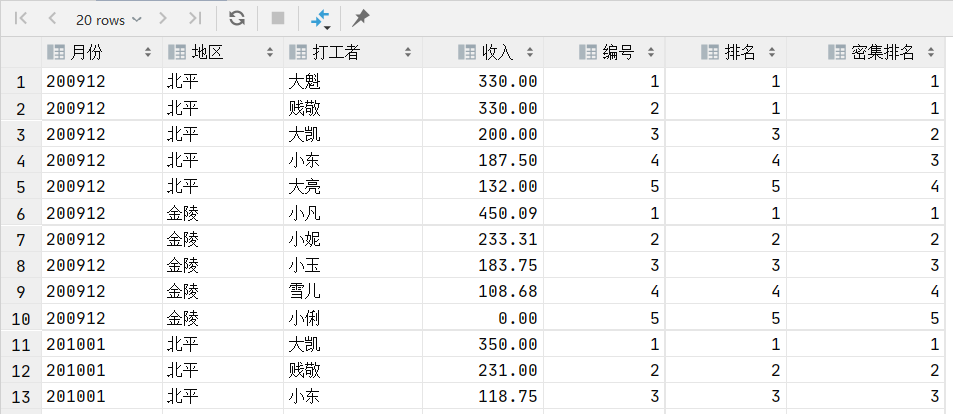
5) 分区取首尾记录
xxxxxxxxxx81select2 dept_id3 ,sale_date4 ,goods_type5 ,sale_cnt6 ,first_value(sale_date) over (partition by dept_id order by sale_date) first_value7 ,last_value(sale_date) over (partition by dept_id order by sale_date desc) last_value8from criss_sales;
6) 分区取前后数据
xxxxxxxxxx61-- 求出每个打工者上个月和下个月有没有赚钱(personincome大于零即为赚钱)2-- Lag和Lead函数可以在一次查询中取出某个字段的前N行和后N行的数据(可以是其他字段的数据)3select earnmonth 本月,sname 打工者,4 lag(decode(nvl(personincome,0),0,'没赚','赚了'),1,0) over(partition by sname order by earnmonth) 上月,5 lead(decode(nvl(personincome,0),0,'没赚','赚了'),1,0) over(partition by sname order by earnmonth) 下月6from earnings;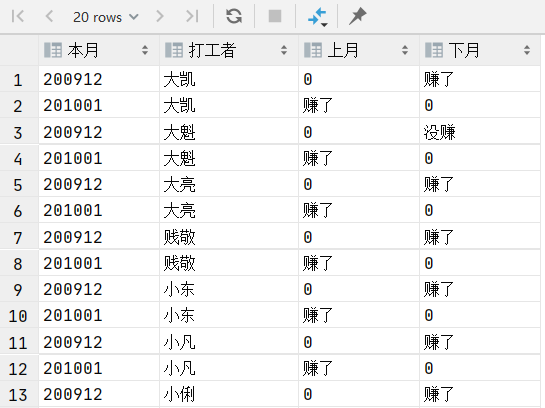
3. 其它函数
1) LISTAGG
xxxxxxxxxx491-- 1 最简单的用法:分组拼接2with temp as(3 select 'China' nation ,'Guangzhou' city from dual union all4 select 'China' nation ,'Shanghai' city from dual union all5 select 'China' nation ,'Beijing' city from dual union all6 select 'USA' nation ,'New York' city from dual union all7 select 'USA' nation ,'Bostom' city from dual union all8 select 'Japan' nation ,'Tokyo' city from dual9)10select nation, listagg(city,',')11from temp12group by nation;13+------+--------------------------+14|NATION|LISTAGG(CITY,',') |15+------+--------------------------+16|Japan |Tokyo |17|USA |New York,Bostom |18|China |Guangzhou,Shanghai,Beijing|19+------+--------------------------+20
21-- 2 分组排序后再拼接(常用)22with temp as Xxx23select nation, listagg(city,',') within GROUP (order by city)24from temp25group by nation;26+------+-----------------------------------------+27|NATION|LISTAGG(CITY,',')WITHINGROUP(ORDERBYCITY)|28+------+-----------------------------------------+29|China |Beijing,Guangzhou,Shanghai |30|Japan |Tokyo |31|USA |Bostom,New York |32+------+-----------------------------------------+33
34-- 3 不分组,配置窗口函数进行分区拼接35with temp as Xxxx36select nation,37 listagg(city,',') within GROUP (order by city) over (partition by nation) city38from temp;39+------+--------------------------+40|NATION|CITY |41+------+--------------------------+42|China |Beijing,Guangzhou,Shanghai|43|China |Beijing,Guangzhou,Shanghai|44|China |Beijing,Guangzhou,Shanghai|45|Japan |Tokyo |46|USA |Bostom,New York |47|USA |Bostom,New York |48+------+--------------------------+49
第05章_性能优化
第一节 SQL执行流程
SQL语句的执行大体上分为解析、优化、执行、输出四步完成。

1. 解析
当我们将SQL语句通过客户端发送到服务端后首先要做的工作便是parser:
- 1) 查询Shared pool:检查该SQL是否存在执行计划,如果有则直接复用(软解析)。
- 2) 硬解析:包括语法检查、语义分析、加锁、权限检查等
2. 优化
优化器是Oracle数据库中内置的一个核心模块,用于获取当前情形下最高效的执行计划。分为如下两种:
- RBO(基于规则的优化器):使用硬编码的判断规则来选择执行路径。
- CBO(基于成本的优化器):基于统计信息计算的成本来选择执行路径。
优化器的模式用于决定在解析SQL时所用的优化器类型,以及决定使用CBO时计算成本值的侧重点,由参数OPTIMIZER_MODE来设置。
- RULE:使用RBO来解析目标SQL,不使用统计信息。
- CHOOSE:默认值,当SQL所涉及的对象存在统计信息时,则会使用CBO,否则使用RBO
- FIRST_ROWS_n(n=1,10,100,1000):使用CBO来解析目标SQL,且侧重点在于以最快的响应速度返回头n条记录。
- FIRST_ROWS:大多情况下会使用CBO,但特殊情况也会使用RBO,侧重点也在于以最快的响应速度返回头几条记录。
- ALL_ROWS:使用CBO来解析目标SQL,且侧重点在于最佳的吞吐量(即最小的系统I/O和CPU资源的消耗量)。
3. 执行与输出
- 1) 加载数据:优先从 database buffer cache 查找缓存的数据,如不存在则读数据文件。
- 2) 修改数据:直接在 database buffer cache 中修改数据,此过程会产生重做日志,写入 Redo log buffer。
- 3) 响应客户端:服务端进程将该SQL的执行结果返回给客户端进程,随后DBWR和LGWR进程负责将缓存中的数据同步到磁盘。
第二节 执行计划
1. 执行计划简介
执行计划是由Oracle数据库生成的,可以提供以下一些信息:
- 执行顺序:缩进最深的,最先执行;缩进深度相同的,先上后下。
- 访问路径:显示查询如何访问表或索引,包括全表扫描、索引扫描、索引范围扫描等,这可以帮助确定数据是如何被检索的。
- 连接顺序:如果查询涉及多个表的连接操作,执行计划将显示连接的顺序。
- 连接类型:执行计划指示了连接操作使用的连接类型,以及内连接、外连接或半连接。
- 过滤条件:执行计划会显示应用在表或索引访问上的过滤条件。这可以帮助确认查询中的过滤逻辑是否被正确地应用。
- 排序操作:如果查询涉及排序操作,执行计划将显示排序的方式和排序所使用的算法。这对于优化排序操作的性能很有帮助。
- 聚合操作:如果查询包含聚合函数(如 SUM、AVG、COUNT 等),执行计划将显示聚合操作的方式和执行方法。
- 统计信息:执行计划可以提供表、索引或列的统计信息,如行数、唯一值数量等。这对于优化查询计划选择和索引设计很重要。
通过分析执行计划,可以确定查询中的性能瓶颈和优化机会,了解查询的执行方式,以及根据需要进行调整和优化的方法。
2. 获取执行计划
执行计划可以通过多种方式获取,如使用EXPLAIN PLAN FOR语句、使用 SQL Trace 功能、使用 SqlDeveloper/PlsqlDeveloper 工具等。
xxxxxxxxxx61-- 生成执行计划2explain plan for SQL语句;3
4-- 查看上次生成的执行计划5SELECT * FROM TABLE(dbms_xplan.display);6
3. 字段说明
- Id:执行计划中每一个操作(行)的标识符。如果数字前面带有星号,意味着将在随后提供这行包含的谓词信息。
- Operation:对应执行的操作,如Full Table Scan、Index Scan等。
- Name:操作所涉及的表或索引的名称。
- Rows(E-Rows):预估操作返回的记录条数。
- Bytes(E-Bytes):预估操作返回的记录字节数。
- TempSpc:预估操作使用临时表空间的大小。
- Cost(%CPU):操作所需的成本,包括I/O成本和CPU成本(是通过执行计划计算出来的,且父操作的开销包含子操作的开销)。
- Time:预估执行操作所需要的时间(HH:MM:SS)。
- Pstart:访问的第一个分区。如果解析时不知道是哪个分区就设为KEY,KEY(I),KEY(MC),KEY(OR),KEY(SQ)。
- Pstop:访问的最后一个分区。如果解析时不知道是哪个分区就设为KEY,KEY(I),KEY(MC),KEY(OR),KEY(SQ)。
4) 并行和分布式处理(仅当使用并行或分布式操作时下列字段可见)
- Inst:在分布式操作中,指操作使用的数据库链接的名字。
- TQ:在并行操作中,用于从属线程间通信的表队列。
- IN-OUT:并行或分布式操作间的关系。
- PQ Distrib:在并行操作中,生产者为发送数据给消费者进行的分配。
5) 运行时统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)
- Starts:指定操作执行的次数。
- A-Rows:操作返回的真实记录数。
- A-Time:操作执行的真实时间(HH:MM:SS.FF)。
6) I/O 统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)
- Buffers:执行期间进行的逻辑读操作数量。
- Reads:执行期间进行的物理读操作数量。
- Writes:执行期间进行的物理写操作数量。
- OMem:最优执行所需内存的预估值。
- 1Mem:一次通过(one-pass)执行所需内存的预估值。
- 0/1/M:最优/一次通过/多次通过(multipass)模式操作执行的次数。
- Used-Mem:最后一次执行时操作使用的内存量。
- Used-Tmp:最后一次执行时操作使用的临时空间大小(与其它常用字段比较时需将其扩大1024倍)。
- Max-Tmp:操作使用的最大临时空间大小(与其它常用字段比较时需将其扩大1024倍)。
xxxxxxxxxx231-- 生成和查看执行计划2EXPLAIN PLAN FOR SELECT * FROM employees WHERE salary > 5000;3SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);4
5--------------------------------------------------------------------------------------6| Id | Operation | Name | Rows | Bytes | Cost | Time |7--------------------------------------------------------------------------------------8| 0 | SELECT STATEMENT | | 101 | 5050 | 8 | 00:00:01 |9| * 1 | VIEW | | 101 | 5050 | 8 | 00:00:01 |10| 2 | COUNT | | | | | |11| 3 | VIEW | | 101 | 3737 | 8 | 00:00:01 |12| 4 | SORT ORDER BY | | 101 | 3939 | 8 | 00:00:01 |13| * 5 | HASH JOIN OUTER | | 101 | 3939 | 7 | 00:00:01 |14| * 6 | TABLE ACCESS FULL | LABELED_STK_LIST | 101 | 2020 | 4 | 00:00:01 |15| 7 | TABLE ACCESS FULL | DW_VAR_STK_INFO | 44 | 836 | 3 | 00:00:01 |16--------------------------------------------------------------------------------------17
18Predicate Information (identified by operation id):19------------------------------------------20* 1 - filter("ROW_ID">0 AND "ROW_ID"<=50)21* 5 - access("L"."STK_CODE"="S"."STK_CODE"(+) AND "L"."STKBD"="S"."STKBD"(+))22* 6 - filter("L"."LABEL_STK_CLS"<>'999')23
4. Operation
TABLE ACCESS FULL(全表扫描):读取表中的所有行。
TABLE ACCESS BY ROWID(通过ROWID的表存取):直接通过ROWID读取行(ROWID是隐藏列,具有唯一性,且不受行迁移影响)。
TABLE ACCESS BY INDEX SCAN(索引扫描):先通过索引定位ROWID,再通过ROWID读取行(叫做“回表”)。
- INDEX UNIQUE SCAN(唯一索引扫描):使用唯一索引上读取一行数据的情形,如唯一索引字段的等值条件。
- INDEX RANGE SCAN(索引范围扫描):使用非唯一索引或在唯一索引上使用范围操作符。
- INDEX FULL SCAN(索引全扫描):查询的字段恰好都是索引字段,无需回表。
- INDEX FAST FULL SCAN(索引快速扫描):与索引全扫描类似,但是不对返回数据进行排序。
- INDEX SKIP SCAN(索引跳跃扫描):如仅使用id字段在(sex,id)索引查询,可能会优化为在('男',id)和('女',id)索引进行两次查询。
- HASH JOIN(哈希连接):先根据驱动表创建哈希位图,再使用匹配表进行哈希匹配,适用的连接条件只有
=。 - SORT MERGE JOIN(归并连接):先按关联列进行排序,再执行合并,适用
<、<=、=、>、>=连接,不适用!=、like。 - NESTED LOOPS(嵌套循环连接):双层循环进行合并,适合驱动表行数较少且匹配表能快速匹配的场景。
- HASH JOIN(哈希连接):先根据驱动表创建哈希位图,再使用匹配表进行哈希匹配,适用的连接条件只有
- 语句类型:SELECT STATEMENT、UPDATE STATEMENT, GOAL = ALL_ROWS、CREATE TABLE STATEMENT等。
- 聚合操作:COUNT等。
5. Predicate
执行计划中的 Predicate Information 表示操作所用到的谓词信息,包括过滤条件、连接条件等。
6 - filter("L"."LABEL_STK_CLS"<>'999'):对LABELED_STK_LIST表通过L.LABEL_STK_CLS<>'999'条件进行过滤。5 - access("L"."STK_CODE"="S"."STK_CODE"(+) AND "L"."STKBD"="S"."STKBD"(+)):通过所示条件对两表进行关联。
第三节 Hint优化
第06章_PLSQL基础
PL/SQL是一种程序语言,叫做过程化SQL语言(PL/SQL是面向过程语言),是Oracle数据库对SQL语句的扩展,在普通SQL语句的使用上增加了编程语言的特点(PL/SQL是对SQL语言的扩展)。
PL/SQL是Oracle系统的核心语言,现在Oracle的许多部件都是由PL/SQL写成的,具有简单、高效、灵活、实用的特点。
第一节 快速入门
1. PL/SQL块
块(block)是PL/SQL的基本程序处理单元,由三部分组成,分别是声明部分、执行部分以及异常处理部分。
xxxxxxxxxx81DECLARE2 -- 声明部分:声明变量、常量、复杂数据类型、游标等3BEGIN4 -- 执行部分:PL/SQL语句和SQL语句5EXCEPTION6 -- 异常处理部分:处理运行错误7END;8
2. 第一个PL/SQL程序
xxxxxxxxxx81-- 例:打印hello word!2SET SERVEROUTPUT ON3
4BEGIN5 DBMS_OUTPUT.PUT_LINE('HELLO WORD');6END;7/8
3. PL/SQL分类
- 1) 匿名块:动态构造、只能执行一次。
- 2) 子程序:存储在数据库中的存储过程、函数及包等。当在数据库上建立好后可以在其它程序中调用它们。
- 3) 触发器:当数据库发生操作时,会触发一些事件,从而自动执行相应的程序。
第二节 变量
1. PL/SQL标识符
当编写PL/SQL块时,为了临时存储数据,需要定义变量和常量。变量和常量的定义是需要满足标识符的限制要求的:
- 标识符名不能超过30个字符。
- 第一个字符必须为字母。
- 不分大小写。
- 不能用减号
-。
注意:
- 尽量不把变量名声明和表中字段名一样,以防混淆。
2. 变量的类型
- 1) 数值类型:NUMBER(p,s)以及子类型INT、FLOAT 等。
- 2) 字符类型:CHAR(n)、VARCHAR2(n) 等。
- 3) 日期类型:DATE 等
- 4) 布尔类型:BOOLEAN。
3. 变量的命名规范
为了提高代码的可读性,建议遵从以下编码规则:
| 标识符 | 命名规则 | 例子 |
|---|---|---|
| 程序变量 | v_name | v_sal |
| 程序常量 | c_name | c_pi |
| 游标变量 | name_curror | emp_curror |
| 异常标识 | e_name | e_integrity_error |
| 记录类型 | name_record | emp_record |
4. 变量的大小写规范
当编写sql语句和PL/SQL语句时,既可以采用大写格式,也可以采用小写格式。但是为了程序的可读性,应尽量按照以下规则:
- SQL关键字采用大写格式,如:SELECT,UPDATE等。
- PL/SQL关键字采用大写格式,如:DECLARE,BEGIN,END等。
- 数据类型采用大写格式,如:INT、DATE等。
- 标识符和参数采用小写格式,如:v_sal等。
- 数据库对象和列采用小写格式,如:emp,sal等。
5. 代码缩进与注释
xxxxxxxxxx31-- 这是一个单行注释2/*这是一个多行注释*/3
6. 引用型变量与记录型变量
在许多情况下,PL/SQL变量可以用来存储在数据库表中的数据。在这种情况下,变量应该拥有与表列相同的类型,如:
xxxxxxxxxx111DECLARE2 v_name varchar(10);3 v_sal number(7,2);4BEGIN5 SELECT ename, sal INTO v_name, v_sal FROM emp WHERE empno = 7788;6 -- 打印姓名和薪水7 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:' || v_sal);8END;9/10SCOTT的工资是:300011
引用型变量是指其数据类型与已经定义的某个数据变量的类型相同,或者与数据库表的某个列的数据类型相同。例:
xxxxxxxxxx131DECLARE2 v_name emp.ename%TYPE;3 v_sal emp.sal%TYPE;4BEGIN5 SELECT ename, sal6 INTO v_name,v_sal7 FROM emp8 WHERE empno = 7788;9 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:' || v_sal);10END;11/12SCOTT的工资是:300013
记录型变量:PL/SQL提供%ROWTYPE操作符,返回一个记录类型,其数据类型和数据库表的数据结构相一致。举例:
xxxxxxxxxx91DECLARE2 emp_record emp%ROWTYPE;3BEGIN4 SELECT * INTO emp_record FROM emp WHERE empno = 7788;5 DBMS_OUTPUT.PUT_LINE(emp_record.ename||'的工资是:'||emp_record.sal);6END;7/8SCOTT的工资是:30009
第三节 运算符
1. 算数运算符
xxxxxxxxxx181DECLARE2 v_num1 NUMBER(3) := 10;3 v_num2 NUMBER(3) := 2;4BEGIN5 DBMS_OUTPUT.PUT_LINE('加法:' || (v_num1 + v_num2));6 DBMS_OUTPUT.PUT_LINE('减法:' || (v_num1 - v_num2));7 DBMS_OUTPUT.PUT_LINE('乘法:' || (v_num1 * v_num2));8 DBMS_OUTPUT.PUT_LINE('除法:' || (v_num1 / v_num2));9 DBMS_OUTPUT.PUT_LINE('乘方:' || (v_num1 ** v_num2));10END;11/12
13加法:1214减法:815乘法:2016除法:517乘方:10018
2. 关系运算符
xxxxxxxxxx181DECLARE2 v_num1 NUMBER(2) := &n1;3 v_num2 NUMBER(2) := &n2;4BEGIN5 IF(v_num1 != v_num2) THEN6 DBMS_OUTPUT.PUT_LINE('num1 != num2');7 ELSIF (v_num1 > v_num2) THEN8 DBMS_OUTPUT.PUT_LINE('num1 > num2');9 END IF;10END;11/12
13输入 n1 的值: 1014输入 n2 的值: 515num1 != num216
17-- 18
注意:
- 其它的关系运算符还有:
=、<>、~=、^=、>=、<=。
3. 比较运算符
xxxxxxxxxx241DECLARE2 v_num1 NUMBER(2) := &n1;3BEGIN4 IF(v_num1 BETWEEN 5 AND 10) THEN5 DBMS_OUTPUT.PUT_LINE('num1在5到10之间');6 ELSE7 DBMS_OUTPUT.PUT_LINE('num1不在5到10之间');8 END IF;9
10 IF(v_num1 NOT IN(3,8)) THEN11 DBMS_OUTPUT.PUT_LINE('num1不为3或8');12 END IF;13
14 IF(v_num1 IS NOT NULL) THEN15 DBMS_OUTPUT.PUT_LINE('num1不为NULL');16 END IF;17END;18/19
20输入 n1 的值: 421num1不在5到10之间22num1不为3或823num1不为NULL24
4. 逻辑运算符
xxxxxxxxxx221DECLARE2 v_b1 BOOLEAN := &n1;3 v_b2 BOOLEAN := &n2;4BEGIN5 IF(v_b1 AND v_b2) THEN6 DBMS_OUTPUT.PUT_LINE('AND-TURE');7 END IF;8
9 IF(v_b1 OR v_b2) THEN10 DBMS_OUTPUT.PUT_LINE('OR-TURE');11 END IF;12
13 IF( NOT v_b1) THEN14 DBMS_OUTPUT.PUT_LINE('FALSE-TURE');15 END IF;16END;17/18
19输入 n1 的值: TRUE20输入 n2 的值: FALSE21OR-TURE22
注意:
- 逻辑运算符只可以取TURE、FALSE或NULL。
5. NULL的运算规则
1) NULL与算术运算符
如果算术表达式的任一输入为空,则该算术表达式(涉及诸如 +、-、* 或 / 的算术运算)结果为空。
2) NULL与关系运算符
SQL将涉及空值的任何比较运算的结果视为
unknown(既不是谓词is null,也不是is not null)。unknown是在SQL中除true和false之外的第三个逻辑值。特别的,"null = null"会返回unknown,而不是true。3) NULL与逻辑运算符
And:true and unknown = unknown, false and unknown = false, unknown and unknown = unknown or: true or unknown = true, false or unknown = unknown, unknown or unknown = unknown not: not unknown = unknown
4) NULL与比较运算符
in后带有null将会被忽略,而not in后带有null,会导致表达式始终不成立。
5) NULL与集合运算
在集合运算中,{('A', null), ('A', null)}中的两个元素会被认为是相同的元素,因此在使用distinct子句只会保留这样的相同的元组的一份拷贝。
6) NULL与字符串连接
NULL||字符串 -> 字符串
第四节 流程控制
1. IF语句
xxxxxxxxxx561-- 1) 简单IF语句:IF...THEN... END IF2-- 例:新入员工号,判断员工工资,显示工资小于3000的员工姓名及工资3DECLARE4 v_name emp.ename%TYPE;5 v_sal emp.sal%TYPE;6BEGIN7 SELECT ename,sal8 INTO v_name,v_sal9 FROM emp10 WHERE empno=&no;11 12 IF v_sal < 3000 THEN13 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:'|| v_sal);14END IF;15END;16
17
18-- 2) 二重IF语句:IF... THEN... ELSE... END IF19-- 例:输入员工号,判断员工工资将工资小于3000的员工工资涨200,并显示涨工资的员工姓名,其他员工显示员工姓名及工资。20DECLARE21 v_name emp.ename%TYPE;22 v_sal emp.sal%TYPE;23 v_empno emp.empno%TYPE := &no;24BEGIN25 SELECT ename, sal 26 INTO v_name, v_sal 27 FROM emp 28 WHERE empno=v_empno;29 30 IF v_sal < 3000 THEN31 UPDATE emp SET sal = sal + 200 WHERE empno = v_empno;32 COMMIT;33 DBMS_OUTPUT.PUT_LINE(v_name || '涨工资了');34 ELSE35 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:' || v_sal);36 END IF;37END;38
39
40-- 3) 三重IF语句: IF... THEN... ELSIF... THEN... ELSE... END IF41-- 例3:输入员工号,判断员工工资工资小于2000,显示低收入,工资小于6000,显示中等收入,其它显示高收入 42DECLARE43 v_name emp.ename%TYPE;44 v_sal emp.sal%TYPE;45BEGIN46 SELECT ename,sal INTO v_name, v_sal FROM emp WHERE empno = &no;47 48 IF v_sal < 2000 THEN49 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:' || v_sal || '属于低收入');50 ELSIF v_sal < 6000 THEN51 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:' || v_sal || '属于中收入');52 ELSE53 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:' || v_sal || '属于高收入');54 END IF;55END;56
2. CASE语句
xxxxxxxxxx391-- 1) 等值比较2-- 例:输入成级等级,判断属于哪个层次,并打印输出。3-- 注意输入字符要带单引号4DECLARE5 v_grade CHAR(1) := &n;6BEGIN7 CASE v_grade8 WHEN 'A' THEN9 DBMS_OUTPUT.PUT_LINE('优秀');10 WHEN 'B' THEN11 DBMS_OUTPUT.PUT_LINE('中等');12 WHEN 'C' THEN13 DBMS_OUTPUT.PUT_LINE('一般');14 ELSE15 DBMS_OUTPUT.PUT_LINE('输入有误');16 END CASE;17END;18
19
20
21-- 2) 非等值比较22-- 例:输入员工号,获取员工工资,判断工资,如果工资小于1500,补助加100,如果工资小于2500,补助加80,如果工资小于5000,补助加50.23DECLARE24 v_sal emp.sal%TYPE;25 v_empno emp.empno%TYPE := &no;26BEGIN27 SELECT sal INTO v_sal FROM emp WHERE empno = v_empno;28
29 CASE 30 WHEN v_sal < 1500 THEN31 UPDATE emp SET comm = nvl(comm,0) + 100 WHERE empno = v_empno;32 WHEN v_sal < 2500 THEN33 UPDATE emp SET comm = nvl(comm,0) + 80 WHERE empno = v_empno;34 WHEN v_sal < 5000 THEN35 UPDATE emp SET comm = nvl(comm,0) + 50 WHERE empno = v_empno;36 COMMIT;37 END CASE;38END;39
3. 循环语句
xxxxxxxxxx611-- 1) LOOP循环2-- 例:打印1~103DECLARE4 v_cnt INT := 1;5BEGIN6 LOOP7 DBMS_OUTPUT.PUT_LINE(v_cnt);8 EXIT WHEN v_cnt = 10;9 v_cnt := v_cnt + 1;10 END LOOP;11END;12
13
14-- 2) WHILE循环15-- 例:打印1~1016DECLARE17 v_cnt INT := 1;18BEGIN19 WHILE v_cnt <= 10 LOOP20 DBMS_OUTPUT.PUT_LINE(v_cnt);21 v_cnt := v_cnt + 1;22 END LOOP;23END;24
25
26-- 3) FOR... IN...循环27-- 例:打印1~1028BEGIN29 FOR i IN 1..10 LOOP30 DBMS_OUTPUT.PUT_LINE(i);31 END LOOP;32END;33
34
35-- 4) 嵌套循环与标号36-- 嵌套循环是指在一个循环语句中嵌入另一个循环语句,标号用于标记嵌套块或嵌套循环,使用可以<<label_name>>定义标号37DECLARE38 v_result INT;39BEGIN40 <<outter>> FOR i IN 1..5 LOOP41 <<inter>> FOR j IN 1..5 LOOP42 v_result := i;43 EXIT outter WHEN i = 4;44 END LOOP inter;45 DBMS_OUTPUT.PUT_LINE('内:' || v_result);46 END LOOP outter;47 DBMS_OUTPUT.PUT_LINE('外:' || v_result);48END;49-- 写成C语言如下:50for(int i = 1;i <5; i++)51{52 for(int j= 1;j < 5;j++)53 {54 v_result = i;55 if (i == 4) goto END;56 }57 printf("内:%d", v_result);58}59END:60 printf("外:%d", v_result);61 注意:关于循环退出
EXIT语句用于直接退出当前循环,CONTINUE语句用于直接结束当前循环并继续下一次循环。EXIT WHEN语句和CONTINUE WHEN语句分别用于在满足特定条件时退出当前循环或继续下一次循环。
4. 其它流程控制语句
xxxxxxxxxx211-- 1) GOTO语句2-- GOTO语句用于跳转到特定标号处执行语句。语法格式:GOTO label_name;3-- 注意:当使用GOTO跳转到特定标号时,标号后至少要包含一条执行语句。4DECLARE5 v_cnt INT := 1;6BEGIN7 LOOP8 DBMS_OUTPUT.PUT_LINE(v_cnt);9 IF v_cnt = 10 THEN10 --EXIT:11 GOTO end_loop;12 END IF;13 v_cnt := v_cnt + 1;14 END LOOP;15<<end_loop>> 16 NULL;17END;18
19-- 2) NULL语句20 NULL语句不会执行任何操作,并且会直接将控制传递到下一个语句,使用该语句的主要目的是提高PL/SQL块的可读性。示例如上。21
第五节 游标
游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是用于临时存储从数据库中提取的数据块,通俗的来讲游标就是一个结果集。
1. 显式游标
显示游标是用户自定义的,显示创建的游标,主要是用于对查询语句的处理。显示游标的使用一般分为定义游标 -> 打开游标 -> 提取数据 -> 关闭游标四个步骤。语法如下:
xxxxxxxxxx251-- 例:查询所有员工的员工号、姓名和职位的信息。2DECLARE 3 --1 定义游标4 CURSOR emp_cursor IS SELECT empno,ename,job FROM emp;5 v_empno emp.empno%TYPE;6 v_ename emp.ename%TYPE;7 v_job emp.job%TYPE;8 9BEGIN10 --2 打开游标,执行查询11 OPEN emp_cursor;12
13 --3 提取数据14 LOOP15 FETCH emp_cursor INTO v_empno,v_ename,v_job;16 DBMS_OUTPUT.PUT_LINE('员工号:'||v_empno||'姓名:'||v_ename||'职位:'||v_job);17
18 -- 在适时退出数据提取19 EXIT WHEN emp_cursor%NOTFOUND;20 END LOOP;21 22 --4 关闭游标23 CLOSE emp_cursor;24END;25
2. 游标属性
- 1)
%FOUND:该属性用于检测游标结果集是否存在数据,如果存在数据,返回TRUE。 - 2)
%NOTFOUND:该属性用于检测游标结果集是否不存在数据,如果不存在数据,返回TRUE。 - 3)
%ISOPEN:该属性用于检测游标是否已经打开,如果已经打开返回TRUE。 - 4)
%ROWCOUNT:该属性用于返回已提取的实际行数。
xxxxxxxxxx141-- 例1:上例的退出语句还可以写成如下:2EXIT WHEN NOT emp_cursor%FOUND3
4-- 或者提取5行后退出:5EXIT WHEN emp_cursor%ROWCOUNT = 5;6
7
8-- 例2:检测游标是否打开可用下面语句:9IF emp_cursor%ISOPEN THEN10 DBMS_OUTPUT.PUT_LINE('游标已打开!');11ELSE12 DBMS_OUTPUT.PUT_LINE('游标未打开!');13END IF;14
3. 游标FOR循环
当使用游标FOR循环时,Oracle会隐含地打开游标,提取数据并关闭游标。
xxxxxxxxxx161-- 如上例可以改写为以下:2DECLARE3 CURSOR emp_cursor IS SELECT empno, ename, job FROM emp;4BEGIN5 FOR emp_record IN emp_cursor LOOP6 DBMS_OUTPUT.PUT_LINE('员工号:'||emp_record.empno||'姓名:'||emp_record.ename||'职位:'||emp_record.job);7 END LOOP;8END;9
10-- 进一步,还可以在FOR IN中利用子查询11BEGIN12 FOR emp_record IN (SELECT empno,ename, job FROM emp) LOOP13 DBMS_OUTPUT.PUT_LINE('员工号:'||emp_record.empno||'姓名:'||emp_record.ename||'职位:'||emp_record.job);14 END LOOP;15END;16
4. 参数游标
参数游标是指带有参数的游标。通过使用参数游标,使用不同参数值可以生成不同的游标结果集。
xxxxxxxxxx171-- 例:查询指定部门的员工号、姓名和职位2DECLARE 3 CURSOR emp_cursor(dno NUMBER) IS SELECT empno, ename, job FROM emp WHERE deptno = dno;4BEGIN5 FOR emp_record IN emp_cursor(&no) LOOP6 DBMS_OUTPUT.PUT_LINE('员工号:'||emp_record.empno||'姓名:'||emp_record.ename||'职位:'||emp_record.job);7 END LOOP;8END;9
10
11-- 也可以直接写成这样12BEGIN13 FOR emp_record IN (SELECT empno, ename, job FROM emp WHERE deptno = &no) LOOP14 DBMS_OUTPUT.PUT_LINE('员工号:'||emp_record.empno||'姓名:'||emp_record.ename||'职位:'||emp_record.job);15 END LOOP;16END;17
5. 隐式游标
隐式游标是由系统隐含创建的游标。主要用于对非查询语句,如修改,删除等操作,有Oracle系统自动地为这些操作设置游标并创建其工作区,对于隐式游标的操作,如定义、打开、取值及关闭操作,都有Oracle系统自动完成,无需用户进行处理。
隐式游标的名字为SQL,这是由Oracle系统定义的。当系统使用一个隐式游标时,可以通过隐式游标的属性来了解操作的状态和结果,进而控制程序的流程。
xxxxxxxxxx121-- 例:利用SQL%FOUND判断UPDATE执行是否成功,并打印影响行数2BEGIN3 UPDATE emp SET sal = sal+100 WHERE deptno = &no;4 IF SQL%FOUND THEN5 DBMS_OUTPUT.PUT_LINE('成功修改员工工资,影响了'|| SQL%ROWCOUNT||'行');6 COMMIT;7 ELSE8 DBMS_OUTPUT.PUT_LINE('成功修改员工工资');9 ROLLBACK;10 END IF;11END;12
注意:
- 通过SQL游标名总是只能访问前一个DML操作或单行SELECT操作的游标属性。
6. 使用游标修改或删除数据
如果创建的游标需要执行更新或删除的操作必须带有FOR UPDATE子句。FOR UPDATE子句会将游标提取出来的数据进行行级锁定,这样在本会话更新期间,其他用户的会话就不能对当前游标中的数据行进行更新操作。
xxxxxxxxxx431-- 例:如果没有获取到锁,打开游标就会失败,同理,获得锁后,一直到提交前,别的会话都无法获得锁。2DECLARE3 CURSOR emp_cursor IS SELECT empno,job FROM emp FOR UPDATE;4 5BEGIN6 -- 更新数据7 FOR emp_record IN emp_cursor LOOP8 DBMS_OUTPUT.PUT_LINE(emp_record.empno || '---' ||emp_record.job);9 IF emp_record.job = 'PERSIDENT' THEN10 UPDATE emp SET sal = sal+1000 WHERE CURRENT OF emp_cursor;11 ELSIF emp_record.job = 'MANAGER' THEN12 UPDATE emp SET sal = sal+500 WHERE CURRENT OF emp_cursor;13 ELSE14 UPDATE emp SET sal = sal+300 WHERE CURRENT OF emp_cursor;15 END IF;16 END LOOP;17 18 -- 提交19 COMMIT;20END;21
22-- 1) NOWAIT参数23-- 用于指定不等待锁,如果发现所操作的数据行已经锁定,将不会等待,立即返回错误。24-- 用法:CURSOR emp_cursor IS SELECT empno,job FROM emp FOR UPDATE NOWAIT;25
26
27-- 2) OF子句28-- 用于在特定表上加行共享锁。当游标子查询涉及到多张表时,如果在特定表上加行共享锁,那么需要使用OF子句。29-- 例:输入部门号,显示该部门的部门名称及员工的姓名,并删除该部门下的这些员工。30DECLARE31 CURSOR empnew_cursor IS 32 SELECT d.dname dname, e.ename ename FROM empnew e JOIN dept d ON e.deptno = d.deptno WHERE e.deptno = &deptno33 FOR UPDATE OF e.deptno;34BEGIN35 FOR empnew_record IN empnew_cursor LOOP36 DBMS_OUTPUT.PUT_LINE('部门名称:'||empnew_record.dname||'员工名:'||empnew_record.ename);37 DELETE FROM empnew WHERE CURRENT OF empnew_cursor;38 END LOOP;39 40 COMMIT;41END;42
43
第六节 异常处理
异常是程序在正常执行过程中发生的未预料的事件。异常处理是为了提高程序的健壮性,使用异常处理部分可以有效地解决程序正常执行过程中可能出现的各种错误,使程序正常运行。
1. 预定义异常
预定义异常是指由PL/SQL所提供的系统异常,每个预定义异常对应一个特定的Oracle错误,当PL/SQL块出现这些Oracle错误时,会隐含地触发相应的预定义异常。
常见的预定义异常如下:
| 错误号 | 异常错误信息名称 | 说明 |
|---|---|---|
| ORA-00001 | DUP_VAL_ON_INDEX | 试图破坏一个唯一性限制 |
| ORA-00051 | TIMEOUT_ON_RESOURCE | 在等待资源时发生超时 |
| ORA-01001 | INVALID_CURSOR | 试图使用一个无效的游标 |
| ORA-01012 | NOT_LOGGED_ON | 没有连接到ORACLE |
| ORA-01017 | LOGIN_DENIED | 无效的用户名及口令 |
| ORA-01403 | NO_DATA_FOUND | SELECT INTO没有找到数据 |
| ORA-01422 | TWO_MANY_ROWS | SELECT INTO 返回多行 |
| ORA-01410 | SYS_INVALID_ROWID | 从字符串向ROWID转换发生错误 |
| ORA-01476 | ZERO_DIVIDE | 数字值除零时触发的异常 |
| ORA-01722 | INVALID_NUMBER | 转换一个数字失败 |
| ORA-06500 | STORAGE_ERROR | 内存不够引发的内部错误 |
| ORA-06501 | PROGRAM_ERROR | 存在PL/SQL内部问题 |
| ORA-06502 | VALUE_ERROR | 转换或截断错误 |
| ORA-06504 | ROWTYPE_MISMATCH | 宿主游标变量与 PL/SQL 游标变量的返回类型不兼容 |
| ORA-06511 | CURSOR_ALREADY_OPEN | 游标已经打开 |
| ORA-06530 | ACCESS_INTO_NULL | 未定义对象 |
| ORA-06531 | COLLECTION_IS_NULL | 集合元素未初始化 |
| ORA-06532 | SUBSCRIPT_OUTSIDE_LIMIT | 使用嵌套表或 VARRAY 时,将下标指定为负数 |
| ORA-06533 | SUBSCRIPT_BEYOND_COUNT | 元素下标超过嵌套表或 VARRAY 的最大值 |
| ORA-06592 | CASE_NOT_FOUND | CASE 中若未包含相应的 WHEN ,并且没有设置 |
| ORA-30625 | SELF_IS_NULL | 使用对象类型时,在 null 对象上调用对象方法 |
对于预定义异常情况的处理,无需在程序中定义,只需在PL/SQL块的异常处理部分,直接引用相应的异常情况名,并对其完成相应的异常错误处理即可。
xxxxxxxxxx181-- 例:根据输入的工资,查询员工的姓名,并输出员工的姓名及工资。如果没有该工资,则捕获NO_DATA_FOUND异常,如果发现重复记录,则捕获TOO_MANY_ROWS异常2DECLARE3 v_name emp.ename%TYPE;4 v_sal emp.sal%TYPE := &sal;5 6BEGIN7 SELECT ename INTO v_name FROM emp WHERE sal = v_sal;8 DBMS_OUTPUT.PUT_LINE(v_name || '的工资是:'|| v_sal );9
10EXCEPTION 11 WHEN NO_DATA_FOUND THEN 12 DBMS_OUTPUT.PUT_LINE('没有该员工的工资!' );13 WHEN TOO_MANY_ROWS THEN14 DBMS_OUTPUT.PUT_LINE('多个员工具有该工资!' );15 WHEN OTHERS THEN16 DBMS_OUTPUT.PUT_LINE('其它异常!' );17END;18
2. 非预定义异常
用于处理预定义异常所不能处理的ORACLE错误。此种异常需要在程序中定义。
xxxxxxxxxx201-- 例:删除dept表中指定部门的信息。在PL/SQL中定义非预定义异常,并关联oracle错误(-2292异常是违反外键约束的oracle错误码),在末尾捕捉并处理异常2DECLARE3 --1 定义非预定义异常的标氓符4 e_fk EXCEPTION;5
6 --2 把oracle错误与异常建立关联7 PRAGMA EXCEPTION_INIT(e_fk,-2292); -- -2292异常是违反外键约束的oracle错误码8
9BEGIN10 DELETE FROM dept WHERE deptno = &deptno; 11
12EXCEPTION 13 WHEN e_fk THEN14 --3 捕捉并处理异常15 DBMS_OUTPUT.PUT_LINE('此部门下有员工,不能删除!');16 17 WHEN OTHERS THEN18 DBMS_OUTPUT.PUT_LINE(SQLCODE || '###'||SQLERRM); 19END;20
注意:
SQLCODE与SQLERRM是oracle的异常处理函数,分别用来获取oracle错误号和错误信息,通过在异常处理部分引用,可以取得未预计到的oracle错误。
3. 自定义异常
如果你想在某个特定事件发生时向应用程序的用户发出一些警告信息,而事件本身不会抛出Oracle内部异常,这个异常是属于应用程序的特定异常,那么就需要自定义异常。
自定义异常通过使用RAISE语句来抛出。当引发一个异常错误时,控制就转向到EXCEPTION块异常错误部分,执行错误处理代码。
xxxxxxxxxx251-- 例:给输入员工号,给员工工资加100。在声明部分定义自定义异常,适时抛出异常,并捕捉和处理异常2DECLARE3 v_empno emp.empno%TYPE := &empno;4 5 --1 定义自定义异常6 e_no_result EXCEPTION;7 8BEGIN9 UPDATE emp SET sal = sal+100 WHERE empno = v_empno;10 IF SQL%NOTFOUND THEN11 --2 适时抛出异常12 RAISE e_no_result;13 ELSE14 COMMIT;15 END IF;16 17EXCEPTION18 --3 捕获并处理异常19 WHEN e_no_result THEN20 DBMS_OUTPUT.PUT_LINE('数据更新失败!');21 WHEN OTHERS THEN22 DBMS_OUTPUT.PUT_LINE('其他错误!');23END;24
25
4. RAISE_APPLICATION_ERROR
虽然我们通过DBMS_OUTPUT.PUT_LINE来输出异常信息,但是在实际的应用中,需要把异常信息返回给调用的客户端。
而RAISE_APPLICATION_ERROR将应用程序专有的错误从服务器端转达到客户端应用程序(其他机器上的SQLPLUS或者其他前台开发语言)。
xxxxxxxxxx361-- 其函数声明如下:2-- 错误号的范围是-20001到-20999;错误信息是文本字符串,最多为2048字节;true和false表示是添加(true)进错误堆(error stack)还是覆盖(overwrite)错误堆(false),缺省情况下是false。3PROCEDURE RAISE_APPLICATION_ERROR( error_number_in IN NUMBER, error_msg_in IN VARCHAR2[,{true|| false}]);4
5-- 例1:6CREATE OR REPLACE PROCEDURE change_sal(p_empno NUMBER,p_sal NUMBER) IS7BEGIN8 UPDATE EMP SET SAL = p_sal WHERE EMPNO = p_empno;9 IF SQL%NOTFOUND THEN10 RAISE_APPLICATION_ERROR(-20002, '该员工不存在');11 ELSE12 DBMS_OUTPUT.PUT_LINE('更新成功');13 COMMIT;14 END IF;15END;16
17-- 例2:18CREATE OR REPLACE PROCEDURE new_emp(p_empno in EMP.EMPNO%TYPE, p_name in EMP.ENAME%type, p_sal in EMP.SAL%TYPE, p_job in EMP.JOB%TYPE,p_deptno in EMP.DEPTNO%TYPE, p_mgr in EMP.MGR%TYPE, p_hired in EMP.HIREDATE%TYPE := SYSDATE) 19IS20 e_invalid_manager EXCEPTION;21 PRAGMA EXCEPTION_INIT(e_invalid_manager, -2291); -- -2291表示违反完整性约束22
23BEGIN24 IF TRUNC(p_hired) > TRUNC(SYSDATE) THEN25 RAISE_APPLICATION_ERROR(-20000, 'NEW_EMP:hiredate cannot be in the future');26 END IF; 27 28 INSERT INTO EMP(EMPNO,ENAME,SAL,JOB,DEPTNO,MGR,HIREDATE) VALUES(p_empno, p_name, p_sal, p_job, p_deptno,p_mgr,TRUNC(p_hired));29 30EXCEPTION31 WHEN dup_val_on_index THEN32 RAISE_APPLICATION_ERROR(-20001, 'NEW_EMP:employee called'|| p_name||'already exists',TRUE);33 WHEN e_invalid_manager THEN34 RAISE_APPLICATION_ERROR(-20002, 'NEW_EMP:'||p_mgr||'is not a valid manager');35END;36
第07章_PLSQL对象
存储过程和存储函数是存储在数据库中的被命名的PLSQL块,供所有用户程序调用,完成特定功能的子程序。
第一节 存储过程与存储函数
1. 存储过程的创建
xxxxxxxxxx101-- 创建存储过程的语法如下:2CREATE [OR REPLACE] PROCEDURE Procedure_name [(argment1[{IN | OUT | IN OUT}] Type,argment2[{IN|OUT |IN OUT}] Type,…)]3{IS|AS}4 声明部分5BEGIN6 执行部分7EXCEPTION8 异常错误处理部分9END;10
1) 创建无参数的存储过程
xxxxxxxxxx71-- 例:打印'存储过程'四个字2CREATE OR REPLACE PROCEDURE first_proc3IS 4BEGIN5 DBMS_OUTPUT.PUT_LINE('存储过程!');6END;7
2) 创建带输入参数的存储过程
xxxxxxxxxx121-- 例:输入员工号,删除该员工2CREATE OR REPLACE PROCEDURE Proc_IN(v_empno IN EMP.EMPNO%TYPE)3IS 4BEGIN5 DELETE FROM EMP WHERE EMPNO = v_empno;6 IF SQL%NOTFOUND THEN7 RAISE_APPLICATION_ERROR(-20008,'指定删除的员工不存在!');8 ELSE9 DBMS_OUTPUT.PUT_LINE('删除成功!');10 END IF;11END;12
3) 创建带输出参数的存储过程
xxxxxxxxxx121-- 例:输入部门编号,输出该部门平均薪水和人数2CREATE OR REPLACE PROCEDURE Proc_OUT(v_deptno IN NUMBER, v_avgsal OUT NUMBER, v_cnt OUT NUMBER)3IS 4BEGIN5 SELECT AVG(sal),COUNT(1) INTO v_avgsal,v_cnt FROM EMP WHERE DEPTNO = v_deptno;6EXCEPTION7 WHEN NO_DATA_FOUND THEN8 DBMS_OUTPUT.PUT_LINE('没有此部门!');9 WHEN OTHERS THEN10 DBMS_OUTPUT.PUT_LINE(SQLERRM);11END;12
4) 创建带输入输出参数的存储过程
xxxxxxxxxx101-- 例:调用存储过程,交换两个变量的值2CREATE OR REPLACE PROCEDURE Proc_IN_OUT(v_num1 IN OUT NUMBER, v_num2 IN OUT NUMBER)3AS4 v_temp NUMBER := 0;5BEGIN6 v_temp := v_num1;7 v_num1 := v_num2;8 v_num2 := v_temp;9END;10
2. 存储过程的调用
xxxxxxxxxx361-- 1) 调用无参数的存储过程2BEGIN3 FIRST_PROC;4END;5
6-- 2) 调用带输入参数的存储过程7BEGIN8 PROC_IN(7598);9END;10
11-- 3) 调用带输出参数的存储过程12DECLARE13 v_avgsal NUMBER;14 v_cnt NUMBER;15BEGIN16 PROC_OUT(10,v_avgsal,v_cnt);17 DBMS_OUTPUT.PUT_LINE('平均工资:'||v_avgsal);18 DBMS_OUTPUT.PUT_LINE('总人数:'||v_cnt);19END;20
21-- 4) 调用带输入输出参数的存储过程22DECLARE23 v_n1 NUMBER := 5;24 v_n2 NUMBER := 10;25BEGIN26 PROC_IN_OUT(v_n1,v_n2);27 DBMS_OUTPUT.PUT_LINE('N1:'||v_n1);28 DBMS_OUTPUT.PUT_LINE('N2:'||v_n2);29END;30
31-- 5) 使用EXEC来调用存储过程32-- EXEC方式调用存储过程本质上是在存储过程外嵌套一层BEGIN...END;如:33-- 测试时注意设置:SET SERVEROUTPUT ON34SQL> EXEC first_proc;35SQL> EXEC PROC_IN(1234);36
3. 存储过程的删除
xxxxxxxxxx31-- 删除存储过程2DROP PROCEDURE FIRST_PROC;3
第二节 存储函数
1. 存储函数的创建
xxxxxxxxxx111-- 创建存储函数的语法如下:2CREATE [OR REPLACE] FUNCTION Function_name [(argment1[{INIOUTIIN OUT}]Type,argment2[{IN I OUTIIN OUT}]Type,…)]3RETURN return_type4{IS|AS}5 声明部分6BEGIN7 执行部分8EXCEPTION9 异常错误处理部分10END;11
1) 创建无参数的存储函数
xxxxxxxxxx71-- 例:返回'存储函数'四个字2CREATE OR REPLACE FUNCTION First_func RETURN VARCHAR23IS4BEGIN5 RETURN'存储函数';6END;7
2) 创建带输入参数的存储函数
xxxxxxxxxx141-- 例:输入部门编号,返回该部门的总工资2CREATE OR REPLACE FUNCTION Func_IN(v_deptno IN NUMBER) RETURN NUMBER3IS 4 v_sumsal NUMBER;5BEGIN6 SELECT SUM(SAL) INTO v_sumsal FROM EMP WHERE DEPTNO = v_deptno;7 RETURN v_sumsal;8EXCEPTION9 WHEN NO_DATA_FOUND THEN10 DBMS_OUTPUT.PUT_LINE('没有此部门!');11 WHEN OTHERS THEN12 DBMS_OUTPUT.PUT_LINE(SQLERRM);13END;14
3) 创建带输出参数的存储函数
xxxxxxxxxx141-- 例:输入员工工号,输出员工的姓名和员工工资,并返回员工年收入2CREATE OR REPLACE FUNCTION Func_OUT(v_empno IN EMP.EMPNO%TYPE, v_name OUT EMP.ENAME%TYPE,v_sal OUT EMP.SAL%TYPE) RETURN NUMBER3IS 4 v_yearsal NUMBER;5BEGIN6 SELECT ENAME,SAL,(SAL+NVL(COMM,0))*12 INTO v_name,v_sal,v_yearsal FROM EMP WHERE EMPNO = v_empno;7 RETURN v_yearsal;8EXCEPTION9 WHEN NO_DATA_FOUND THEN10 DBMS_OUTPUT.PUT_LINE('没有此员工!');11 WHEN OTHERS THEN12 DBMS_OUTPUT.PUT_LINE(SQLERRM);13END;14
4) 创建带输入和输出参数的函数
xxxxxxxxxx91-- 例:输入两个数,输出其平方,并返回其平方和2CREATE OR REPLACE FUNCTION Func_IN_OUT(n1 IN OUT NUMBER, n2 IN OUT NUMBER) RETURN NUMBER3IS 4BEGIN5 n1 := n1*n1;6 n2 := n2*n2;7 RETURN n1+n2;8END;9
2. 存储函数的调用
xxxxxxxxxx341-- 1) 调用无参的存储函数2BEGIN3 DBMS_OUTPUT.PUT_LINE(FIRST_FUNC);4END;5
6-- 2) 调用带输入参数的存储函数7BEGIN8 DBMS_OUTPUT.PUT_LINE('部门工资的总额:'||FUNC_IN(10));9END;10
11-- 3) 调用带输出参数的存储函数12DECLARE13 v_name EMP.ENAME%TYPE;14 v_sal EMP.SAL%TYPE;15 v_yearsal NUMBER;16BEGIN17 v_yearsal := FUNC_OUT(7568,v_name,v_sal);18 DBMS_OUTPUT.PUT_LINE('姓名:'||v_name);19 DBMS_OUTPUT.PUT_LINE('工资:'||v_sal);20 DBMS_OUTPUT.PUT_LINE('年收入:'||v_yearsal);21END;22
23-- 4) 调用带输入输出参数的存储函数24DECLARE25 v_num1 NUMBER := 5;26 v_num2 NUMBER := 10;27 v_sum NUMBER;28BEGIN29 v_sum := FUNC_IN_OUT(v_num1,v_num2);30 DBMS_OUTPUT.PUT_LINE('N1的平方:'||v_num1);31 DBMS_OUTPUT.PUT_LINE('N2的平方:'||v_num2);32 DBMS_OUTPUT.PUT_LINE('N1、N2的平方和:'||v_sum);33END;34
3. 存储函数的删除
xxxxxxxxxx31-- 删除函数2DROP FUNCTION FIRST_FUNC;3
4. 存储过程和存储函数的比较
- 1) 关键字不同。存储过程为PROCEDURE,存储函数为FUNCTION。
- 2) 调用方式不同。存储过程一般为独立的过程调用语句,而存储函数一般以表达式方式调用。
- 3) 有无返回值。存储过程没有返回值。
- 4) 存储过程一般用来完成一系列的数据处理,而存储函数的目的是获得函数返回值。
- 5) 存储过程和存储函数都有参数默认值。
xxxxxxxxxx211-- 如下例:求部门的年收入2CREATE OR REPLACE FUNCTION FUNC_DEFAULT(v_deptno IN NUMBER DEFAULT 10) RETURN NUMBER3IS 4 v_yearsalsum NUMBER;5BEGIN6 SELECT SUM((SAL+NVL(COMM,0))*12) INTO v_yearsalsum FROM EMP WHERE DEPTNO = v_deptno;7 RETURN v_yearsalsum;8EXCEPTION9 WHEN NO_DATA_FOUND THEN10 DBMS_OUTPUT.PUT_LINE('没有此部门!');11 WHEN OTHERS THEN12 DBMS_OUTPUT.PUT_LINE(SQLERRM);13END;14
15DECLARE16 v_totalsal NUMBER;17BEGIN18 v_totalsal := FUNC_DEFAULT;19 DBMS_OUTPUT.PUT_LINE(v_totalsal);20END;21
第三节 包
包是一组相关过程、函数、变量、常量和游标等PL/SQL程序设计元素的组合。它具有面向对象程序设计语言的特点,是对PL/SQL程序设计元素(过程、函数、变量等)的封装。
一个包由两个分开的部分组成:
- 包规范(包定义):用于定义包的公用组件,包括常量、变量、游标、过程和函数等。
- 包体(包主体):用于实现包规范所定义的公用过程和函数。包体不仅可用于实现公用过程和函数,而且还可以定义包的私有组件(变量、游标、过程、函数等)。
下面是一个简单的包应用示例:
xxxxxxxxxx311-- 创建包2CREATE OR REPLACE PACKAGE First_package 3IS 4 v_no EMP.DEPTNO%TYPE := 10;5 PROCEDURE query_emp(v_avgsal OUT NUMBER, v_cnt OUT NUMBER,v_deptno IN NUMBER DEFAULT v_no);6END First_package;7
8-- 创建包体9CREATE OR REPLACE PACKAGE BODY First_package IS 10 PROCEDURE query_emp(v_avgsal OUT NUMBER, v_cnt OUT NUMBER,v_deptno IN NUMBER DEFAULT v_no) IS11 BEGIN12 SELECT AVG(sal),COUNT(*) INTO v_avgsal,v_cnt FROM EMP WHERE DEPTNO = v_deptno;13 EXCEPTION14 WHEN NO_DATA_FOUND THEN15 DBMS_OUTPUT.PUT_LINE('没有此部门');16 WHEN OTHERS THEN17 DBMS_OUTPUT.PUT_LINE(SQLERRM);18 END;19END First_package;20
21-- 调用22DECLARE23 v_avgsal NUMBER(10,2);24 v_cnt NUMBER;25BEGIN26 First_package.v_no := 20;27 First_package.query_emp(v_avgsal,v_cnt);28 DBMS_OUTPUT.PUT_LINE('平均工资:'||v_avgsal);29 DBMS_OUTPUT.PUT_LINE('总人数:'||v_cnt);30END;31
1. 包的创建
一般来说,创建包分为创建包规范和创建包体两步:
1) 创建包规范
xxxxxxxxxx211-- 创建包规范语法格式如下:2CREATE [OR REPLACE] PACKAGE package_name3IS|AS4 --在此处定义公用常量、变量、游标、过程、函数等5END [package_name];6
7-- 例1:创建一个包规范,有两个过程,分别是添加员工信息和删除员工信息8CREATE OR REPLACE PACKAGE emp_package 9IS10 PROCEDURE add_emp_pro(v_empno IN EMP.EMPNO%TYPE,v_ename IN EMP.ENAME%TYPE,v_job IN EMP.JOB%TYPE,MGR IN EMP.MGR%TYPE,11 v_hiredate IN EMP.HIREDATE%TYPE,v_sal IN EMP.SAL%TYPE,v_comm IN EMP.COMM%TYPE,v_deptno IN EMP.DEPTNO%TYPE);12 PROCEDURE del_emp_pro(v_empno IN EMP.EMPNO%TYPE);13END emp_package;14
15-- 例2:根据员工号查询工资,如果工资小于等于3000,工资涨500.16CREATE OR REPLACE PACKAGE emp_sal_pa 17IS18 FUNCTION get_sal(p_empno NUMBER) RETURN NUMBER;19 PROCEDURE upd_sal(p_empno NUMBER);20END;21
2) 创建包体
xxxxxxxxxx671-- 创建包体的语法格式下:2CREATE [OR REPLACE] PACKAGE BODY package_name3IS|AS4 --在此处定义私有常量、变量、游标、过程和函数等5 --实在此处现公用过程和函数6END [package_name];7
8-- 例1:实现上面包规范9CREATE OR REPLACE PACKAGE BODY emp_package10IS 11 PROCEDURE add_emp_pro(v_empno IN EMP.EMPNO%TYPE,v_ename IN EMP.ENAME%TYPE,v_job IN EMP.JOB%TYPE,v_mgr IN EMP.MGR%TYPE,12 v_hiredate IN EMP.HIREDATE%TYPE,v_sal IN EMP.SAL%TYPE,v_comm IN EMP.COMM%TYPE,v_deptno IN EMP.DEPTNO%TYPE)13 IS 14 e_2291 EXCEPTION;15 PRAGMA EXCEPTION_INIT(e_2291,-2291);16 BEGIN17 INSERT INTO EMP VALUES(v_empno,v_ename,v_job,v_mgr,v_hiredate,v_sal,v_comm,v_deptno);18 EXCEPTION19 WHEN DUP_VAL_ON_INDEX THEN20 RAISE_APPLICATION_ERROR(-20001,'员工已存在!');21 WHEN e_2291 THEN22 RAISE_APPLICATION_ERROR(-20001,'部门号不存在');23 WHEN OTHERS THEN24 DBMS_OUTPUT.PUT_LINE(v_empno||' 插入成功!');25 END;26 27 PROCEDURE del_emp_pro(v_empno IN EMP.EMPNO%TYPE)28 IS29 BEGIN30 DELETE FROM EMP WHERE EMPNO = v_empno;31 IF SQL%NOTFOUND THEN32 RAISE_APPLICATION_ERROR(-20008,'员工不存在');33 ELSE34 DBMS_OUTPUT.PUT_LINE(v_empno||' 已删除!');35 END IF;36 END;37END emp_package;38
39
40-- 例子2:实现上面包规范41CREATE OR REPLACE PACKAGE BODY emp_sal_pa42IS43 FUNCTION get_sal(p_empno NUMBER) RETURN NUMBER44 IS45 v_sal EMP.SAL%TYPE := 0;46 BEGIN47 SELECT SAL INTO v_sal FROM EMP WHERE EMPNO = p_empno;48 RETURN v_sal;49 EXCEPTION50 WHEN NO_DATA_FOUND THEN51 RAISE_APPLICATION_ERROR(-20008,'该员工不存在!');52 END; 53 54 PROCEDURE upd_sal(p_empno NUMBER) 55 IS 56 v_sal EMP.SAL%TYPE;57 BEGIN58 SELECT SAL INTO v_sal FROM EMP WHERE EMPNO = p_empno;59 IF v_sal <= 3000 THEN60 UPDATE EMP SET SAL = SAL+500 WHERE EMPNO = p_empno;61 END IF;62 EXCEPTION63 WHEN NO_DATA_FOUND THEN64 RAISE_APPLICATION_ERROR(-20008,'该员工不存在!');65 END;66END emp_sal_pa;67
2. 包的调用
对包内共有元素(公共组件)一般采用包名.元素名称来进行调用。
xxxxxxxxxx611-- 例1:调用emp_package添加员工2DECLARE3 v_empno EMP.EMPNO%TYPE := &empno;4 v_ename EMP.ENAME%TYPE := '&name';5 v_sal EMP.SAL%TYPE := &sal;6 v_deptno EMP.DEPTNO%TYPE := &deptno;7 e_dup_val EXCEPTION;8 e_no_dept EXCEPTION;9 PRAGMA EXCEPTION_INIT(e_dup_val,-20001);10 PRAGMA EXCEPTION_INIT(e_no_dept, -20002);11BEGIN12 emp_package.add_emp_pro(v_empno,v_ename,'SALES',7839,sysdate,v_sal,NULL,v_deptno);13 COMMIT;14EXCEPTION15 WHEN e_dup_val THEN16 DBMS_OUTPUT.PUT_LINE(SQLERRM);17 WHEN e_no_dept THEN18 DBMS_OUTPUT.PUT_LINE(SQLERRM);19 ROLLBACK;20END;21
22-- 例2:调用emp_package中删除指定员工的过程23DECLARE 24 v_empno EMP.EMPNO%TYPE := &EMPNO;25 e_no_emp EXCEPTION;26 PRAGMA EXCEPTION_INIT(e_no_emp, -20008);27BEGIN28 emp_package.del_emp_pro(v_empno);29 COMMIT;30EXCEPTION31 WHEN e_no_emp THEN32 DBMS_OUTPUT. put_line(SQLERRM);33 ROLLBACK;34END;35
36-- 例3:调用emp_sal_pkg更新员工工资37DECLARE38 v_empno EMP.EMPNO%TYPE :=&EMPNO;39 v_sal EMP.SAL%TYPE;40 e_no_emp EXCEPTION;41 PRAGMA EXCEPTION_INIT(e_no_emp,-20008);42BEGIN43 emp_sal_pa.upd_sal(v_empno);44 COMMIT;45 v_sal := emp_sal_pa.get_sal(v_empno);46 DBMS_OUTPUT. put_line('员工工资变为:'||v_sal);47EXCEPTION48 WHEN e_no_emp THEN49 DBMS_OUTPUT. put_line(SQLERRM);50END;51
52-- 例4:使用EXEC调用包53SQL> VAR v_empno NUMBER54SQL> EXEC :v_empno := &no55
56SQL> VAR v_sal NUMBER57SQL> EXEC :v_sal := emp_sal_pa.get_sal(:v_empno);58
59
60
61
3. 包的删除
xxxxxxxxxx91-- 可以使用DROPPACKAGE命令对不需要的包进行删除,语法如下:2DROP PACKAGE [BODY][user.]package_name;3
4-- 删除包和包体5DROP PACKAGE emp_sal_pa6
7--仅删除包体8DROP PACKAGE BODY emp_package9
4. 子程序重载
所谓重载是指两个或多个子程序有相同的名称,但拥有不同的参数变量、参数顺序或参数数据类型。
xxxxxxxxxx811-- 例:获取或删除员工信息,可根据员工号或姓名来操作,使用子程序重载2
3-- 创建包规范4CREATE OR REPLACE PACKAGE overload_pkg5IS6 FUNCTION get_info(p_empno NUMBER) RETURN EMP%ROWTYPE;7 FUNCTION get_info(p_ename VARCHAR2) RETURN EMP%ROWTYPE;8 PROCEDURE del_emp(p_empno NUMBER);9 PROCEDURE del_emp(p_ename VARCHAR2);10END;11
12--创建包体13CREATE OR REPLACE PACKAGE BODY overload_pkg14IS15 FUNCTION get_info(p_empno NUMBER) RETURN EMP%ROWTYPE16 IS17 emp_record EMP%ROWTYPE;18 BEGIN19 SELECT * INTO emp_record FROM EMP WHERE EMPNO = p_empno;20 RETURN emp_record; 21 EXCEPTION22 WHEN NO_DATA_FOUND THEN23 RAISE_APPLICATION_ERROR(-20002,'没有此员工!');24 END;25 FUNCTION get_info(p_ename VARCHAR2) RETURN EMP%ROWTYPE26 IS27 emp_record EMP%ROWTYPE;28 BEGIN29 SELECT * INTO emp_record FROM EMP WHERE ENAME = p_ename;30 RETURN emp_record; 31 EXCEPTION32 WHEN NO_DATA_FOUND THEN33 RAISE_APPLICATION_ERROR(-20002,'没有此员工!');34 END;35 PROCEDURE del_emp(p_empno NUMBER)36 IS37 BEGIN38 DELETE EMP WHERE EMPNO = p_empno;39 IF SQL%NOTFOUND THEN40 RAISE_APPLICATION_ERROR(-20002,'没有此员工!');41 END IF;42 END;43 PROCEDURE del_emp(p_ename VARCHAR2)44 IS45 BEGIN46 DELETE EMP WHERE ENAME = p_ename;47 IF SQL%NOTFOUND THEN48 RAISE_APPLICATION_ERROR(-20002,'没有此员工!');49 END IF;50 END;51END;52
53-- 调用:查询员工信息54DECLARE55 emp_record EMP%ROWTYPE;56 e_no_emp EXCEPTION;57 PRAGMA EXCEPTION_INIT(e_no_emp,-20002);58BEGIN59 -- emp_record := overload_pkg.get_info(&no);60 emp_record := overload_pkg.get_info('&name');61 DBMS_OUTPUT.PUT_LINE('员工号:'||emp_record.empno || '员工姓名:'||emp_record.ename||' 员工工资:'||emp_record.sal);62 EXCEPTION63 WHEN e_no_emp THEN64 DBMS_OUTPUT.PUT_LINE(SQLERRM);65END;66
67-- 调用:删除员工信息68DECLARE69 e_no_emp EXCEPTION;70 PRAGMA EXCEPTION_INIT(e_no_emp,-20002);71BEGIN72 -- overload_pkg.del_emp(&no);73 overload_pkg.del_emp('&name');74 COMMIT;75EXCEPTION76 WHEN e_no_emp THEN77 DBMS_OUTPUT.PUT_LINE(SQLERRM);78 ROLLBACK;79END;80
81
4. DBMS_OUTPUT包
5. UTL_FILE包
使用UTL_FILE包进行文件写入的案例如下:
xxxxxxxxxx121--1 创建一个目录2create or replace DIRECTORY MY_DIR1 AS 'D:/Script';3
4--2 使用UTL_FILE包输出HELLOWORLD到文件5DECLARE 6 FILE_HANDLE UTL_FILE.FILE_TYPE;7BEGIN8 FILE_HANDLE := UTL_FILE.FOPEN('MY_DIR1','hello.txt','A');9 UTL_FILE.PUT_LINE(FILE_HANDLE,'HELLO WORLD');10 UTL_FILE.FCLOSE(FILE_HANDLE);11END;12
第四节 触发器
触发器是指存放在数据库中,并且被隐含执行的存储过程。当发生特定事件时,Oracle会自动执行触发器的相应代码。
触发器的类型有:DML触发器、DDL触发器、替代(instead of)触发器以及系统触发器。
触发器的组成:
- 触发事件:即在何种情况下触发TRIGGER。
- 触发时间:即该TRIGGER是在触发事件发生之前(BEFORE)还是之后(AFTER)触发。
- 触发器本身:即该TRIGGER被触发之后的目的和意图,正是触发器本身要做的事情。
- 触发频率:说明触发器内定义的动作被执行的次数。
一个简单的触发器如下:
xxxxxxxxxx71-- 当我们对empnew执行删除操作之后,它就会出现一个提示信息,提示:这是删除操作!2CREATE TRIGGER First_TRIGGER3AFTER DELETE ON EMP4BEGIN5 DBMS_OUTPUT.PUT_LINE('EMP表发生了删除操作!');6END;7
1. DDL触发器
当创建、修改或者删除数据库对象时,会引起相应的触发器操作事件,此时就可以利用触发器来对这些数据库对象的DDL操作进行监控。
xxxxxxxxxx101-- 创建DDL触发器的语法格式如下:2CREATE[OR REPLACE]TRIGGER触发器的名称3 [BEFORE | AFTER | INTEAD OF] [DDL事件] ON [DATABASE | SCHEMA]4 [WHEN 触发条件]5 [DECLARE]6 [程序的声明部分]7BEGIN8 程序的代码部分;9END;10
常见的DDL事件如下:
| NO. | DDL事件触发时机 | 描述 | |
|---|---|---|---|
| 1 | ALTER | BEFORE/AFTER | 修改对象的结构时触发 |
| 2 | ANALYZE | BEFORE/AFTER | 分析数据库对象时触发 |
| 3 | ASSOCIATE STATISTICS | BEFORE/AFTER | 启动统计数据库对象时触发 |
| 4 | AUDIT | BEFORE/AFTER | 开启审核数据库对象时触发 |
| 5 | COMMENT | BEFORE/AFTER | 对数据库对象做注释时触发 |
| 6 | CREATE | BEFORE/AFTER | 创建数据库对象时触发 |
| 7 | DDL | BEFORE/AFTER | 针对出现的所用DDL事件都会触发 |
| 8 | DISASSOCIATE STATISTICS | BEFORE/AFTER | 关闭统计数据库对象时触发 |
| 9 | DROP | BEFORE/AFTER | 删除数据库对象时触发 |
| 10 | GRANT | BEFORE/AFTER | 通过SQL的GRANT命令赋权时触发 |
| 11 | NOAUDIT | BEFORE/AFTER | 禁用审核数据库对象时触发 |
| 12 | RENAME | BEFORE/AFTER | 通过SQL的RENAME命令对对象重命名时触发 |
| 13 | REVOKE | BEFORE/AFTER | 通过SQL的REVOKE语句撤销授权时触发 |
| 14 | TRUNCATE | BEFORE/AFTER | 通过SQL的TRUNCATE语句截断表时触发 |
xxxxxxxxxx341-- 例1:禁止SCOTT用户的所有DDL操作2CREATE OR REPLACE TRIGGER scot_trigger3BEFORE DDL ON SCHEMA 4BEGIN5 RAISE_APPLICATION_ERROR(-20005,'SCOTT用户不允许任何DDL操作!');6END;7
8-- 例2:实现对数据库对象操作的日志记录9-- 创建数据库对象DDL操作日志记录表10SQL> CONN SYS /AS SYSDBA11
12CREATE TABLE object_log(13 logid NUMBER CONSTRAINT pk_logid PRIMARY KEY,14 operate_date DATE NOT NULL,15 object_type VARCHAR2(50) NOT NULL,16 object_owner VARCHAR2(50) NOT NULL17);18
19
20CREATE SEQUENCE object_1og_seq;21
22CREATE OR REPLACE TRIGGER object_trigger23AFTER CREATE OR DROP OR ALTER ON DATABASE 24BEGIN25 INSERT INTO object_log values(object_1og_seq.nextval,sysdate,ora_dict_obj_type,ora_dict_obj_owner );26END;27
28-- 测试29SQL> CONN SCOTT/SCOTT30CREATE SEQUENCE test_seq2;31
32SQL> CONN SYS /AS SYSDBA33SELECT * FROM object_log;34
2. DML触发器
基于DML操作的DML触发器可用于实现数据安全保护、数据审计、数据完整性、参照完整性、数据复制等功能。按触发频率分为:
- 语句触发器:在指定的操作语句之前或之后执行一次,不管这条语句影响了多少行。
- 行触发器:触发语句作用的每一条记录都被触发,在行级触发器中使用
:old和:new伪记录变量,识别值的状态。
xxxxxxxxxx711-- 创建DML触发器的语法格式如下:2CREATE [OR REPLACE] TRIGGER trigger_name3 {BEFORE | AFTER}4 {DELETE | INSERT | UPDATE [ OF 列名]} ON 表名5 [FOR EACH ROW [WHEN(条件)]6 >>PLSQL块<<7
8-- 例1:实现数据安全保护(数据的安全性检查),如禁止在休息日改变EMP表的数据9CREATE OR REPLACE TRIGGER emp_TRIGGER110BEFORE INSERT OR UPDATE OR DELETE ON EMP11BEGIN12 IF TO_CHAR(SYSDATE,'day') IN ('星期六','星期日') THEN13 RAISE_APPLICATION_ERROR(-20006,'不能在休息日改变员工信息!');14 END IF;15END;16-- 测试17DELETE EMP WHERE EMPNO = 756918
19
20-- 例2:实现数据审计,如 审计员工信息表数据的变化,审计删除时间,以及被删除的雇员名。21--创建审计表22CREATE TABLE delete_emp_audit(23name VARCHAR2(10),24delete_time DATE25);26--创建触发器27CREATE OR REPLACE TRIGGER del_emp_trigger28AFTER DELETE ON EMP FOR EACH ROW29BEGIN30 INSERT INTO delete_emp_audit VALUES(:old.ename,SYSDATE);31END;32--测试33DELETE FROM EMP WHERE empno=7566;34select * from delete_emp_audit;35
36
37-- 例3:实现数据完整性(数据确认),如:要求员工涨后工作不能低于原来的工资,并且所涨的工资不能超过原工资的50%。38-- 数据完整性用于确保数据满足商业逻辑或企业规则,实现数据完整性首选约束,约束无法实现的,可以使用触发器实现数据完整性。39CREATE OR REPLACE TRIGGER TR_CHECK_SAL40BEFORE UPDATE OF SAL ON EMP FOR EACH ROW41WHEN (new.sal < old.sal OR new.sal > old.sal*1.5)42BEGIN43 RAISE_APPLICATION_ERROR(-20028,'工资只升不降,并且升幅不能超过50%!');44END;45-- 测试46UPDATE EMP SET SAL = SAL*1.8 WHERE EMPNO = 7788;47
48
49-- 示例4:实现参照完整性(比如级联更新)50-- 参照完整性是指在两张表之间具有主从关系。当删除主表数据时,需要首先删除从表的相关数据;当更新主表主键列时,需要首先更新从表相关数据。51CREATE OR REPLACE TRIGGER upd_cascade_trigger52AFTER UPDATE OF DEPTNO ON DEPT FOR EACH ROW 53BEGIN54 UPDATE EMP SET DEPTNO = :new.deptno WHERE DEPTNO = :old.deptno;55END;56--测试57UPDATE dept SET deptno=50 WHERE deptno=10;58
59
60-- 例5:利用触发器实现系统的同步备份61--创建员工装的务份表62CREATE TABLE emp_bak63AS64SELECT *FROM emp;65-- 创建触发器来实现数据的同步务份:如同步删除66CREATE OR REPLACE TRIGGER emp_bak_trigger67AFTER DELETE ON EMP FOR EACH ROW 68BEGIN69 DELETE FROM emp_bak WHERE EMPNO = :old.empno;70END;71
3. 替代触发器
在简单视图上往往可以执行INSERT、UPDATE、DELETE操作。但在复杂视图上执行INSERT、UPDATE、DLETE操作是有限制的。为了在这些复杂的视图上执行DML操作,需要建立INSTEAD OF触发器。
INSTEAD OF 触发器的限制:
- 替代触发器只适用于视图
- 替代触发器不能指定BEFORE和AFTER选项
- 不能在具有WITH CHECK OPTION选项的视图上建立替代触发器
- 替代触发器必须包含FOR EACH ROW选项
xxxxxxxxxx261-- 例:给EMP_DEPT视图创建一个替代触发器2-- 创建EMP_DEPT视图3CREATE OR REPLACE VIEW emp_dept4AS 5SELECT d.deptno,d.dname,e.empno, e.ename6 FROM DEPT d, EMP e7 WHERE d.deptno = e.deptno;8-- 在视图上创建替代触发器 9CREATE OR REPLACE TRIGGER instead_of_trigger10INSTEAD OF INSERT ON EMP_DEPT FOR EACH ROW 11DECLARE12 v_temp INT;13BEGIN14 SELECT COUNT(*) INTO v_temp FROM DEPT WHERE DEPTNO = :new.deptno;15 IF v_temp = 0 THEN16 INSERT INTO DEPT(DEPTNO, DNAME) VALUES(:new.deptno, :new.dname);17 END IF;18 SELECT COUNT(*) INTO v_temp FROM EMP WHERE EMPNO = :new.empno;19 IF v_temp = 0 THEN20 INSERT INTO EMP(EMPNO, ENAME, DEPTNO) VALUES(:new.empno, :new.ename, :new.deptno);21 END IF;22END;23
24-- 在连接视图上插入数据25INSERT INTO EMP_DEPT VALUES(50,'DEVELOPMENT',2222,'ALICE');26
4. 系统触发器
系统触发器是由特定系统事件(与例程或方案相关的数据库事件)所触发的触发器。常见的系统事件有:
- STARTUP事件触发器:在启动数据库后触发。
- SHUTDOWN事件触发器:在关闭数据之前触发。
- DB_ROLE_CHANGE事件触发器:在改变角色后第一次打开数据库时触发。
- SERVERERROR事件触发器:在发生Oracle错误时触发
151-- 创建一个事件表2SQL> CONN /as sysdba3
4CREATE TABLE event_table(5 event VARCHAR2(50),6 event_time DATE7)8
9-- 创建一个系统触发器:在开机后写入事件10CREATE OR REPLACE TRIGGER startup_trigger11AFTER STARTUP ON DATABASE 12BEGIN13 INSERT INTO event_table VALUES(ora_sysevent, SYSDATE);14END;15