第03篇_并发编程
第01章_多线程开发
第一节 线程基础
1. 线程简介
1) 什么是线程?
线程是CPU调度和执行的最小单位,线程之间共享进程的堆和方法区(元空间),但是有各自的方法栈和程序计数器等,适合任务协作和高并发性能的场景。
- 优点:多线程可提高IO密集型应用的执行效率,提升GUI程序的响应性等。
- 缺点:提升了编码复杂性,可能带来线程安全问题或死锁等。
注意:
- 进程是操作系统分配资源的最小单位,在启动Java应用时,就是启动了一个JVM进程,它包括主线程(main)和其它线程。
2) 线程的六大状态
在 Java 中,线程状态被定义为枚举类:Thread.State,有如下六种状态(JVM不区分Running和Ready):
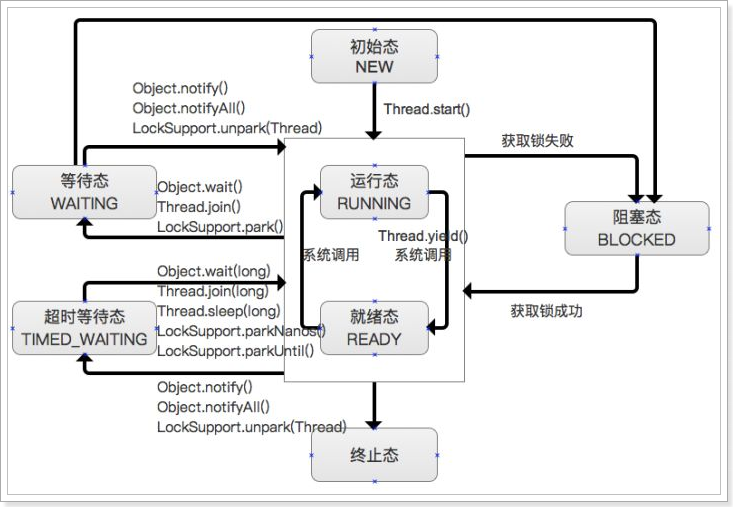
| 线程状态 | 状态说明 |
|---|---|
| NEW | 新建状态,线程创建但未启动。 |
RUNNABLE | 运行状态/就绪状态,线程正在运行,或在等待操作系统调度。 |
BLOCKED | 被动阻塞状态,在等待锁或IO等资源。 |
WAITING | 主动等待状态,线程在等待某个条件,调用wait()/join()方法会进入该状态。 |
| TIMED_WAITING | 主动超时等待状态,线程在等待某个条件或超时,调用wait(timeout)/join(millis)/sleep(millis)会进入该状态。 |
| TERMINATED | 终止状态,线程已结束。 |
注意:
- RUNNABLE不代表CPU一定在执行该线程的代码,也可能在等待操作系统分配时间片,只是它没有在等待其他条件。
- 在操作系统中,其实只有五种状态,其中
Running根据是否在运行拆分出就绪态Ready,但三个阻塞/等待状态不做区分。
2. 创建和启动线程
1) 直接创建Thread
可以通过继承java.lang.Thread类,重写其run方法来直接定义一个线程。
xxxxxxxxxx141// 1. 继承Thread类2public class HelloThread extends Thread {3
4 // 2. 重写run方法:线程入口,无参无返回值,不能抛出受检异常5 6 public void run() {7 System.out.println("hello");8 }9}10
11public static void main(String[] args) {12 Thread thread = new HelloThread(); // 3. 创建线程对象13 thread.start(); // 4. 启动线程,分配程序计数器、栈等线程资源14}注意:
- 此种方式存在单继承问题,不推荐使用。
2) 定义Runable实现类
由于Java只支持单继承,因此一般都是定义java.lang.Runnable接口的实现类,然后创建Runnable的对象传给Thread对象去执行。
xxxxxxxxxx141// 1. 实现Runnable接口2public class HelloRunnable implements Runnable {3
4 // 2. 重写run方法,该方法将优先于Thread的run方法进行调用5 6 public void run() {7 System.out.println("hello");8 }9}10
11public static void main(String[] args) {12 Thread helloThread = new Thread(new HelloRunnable()); // 3. 创建Thread对象,并传递一个Runnable对象13 helloThread.start(); // 4. 启动线程14}注意:
- 一定要通过 start 方法启动线程,如果使用 run 方法启动,将会在当前线程执行。
3) 定义Callable+FutureTask实现类
java.lang.Callable一般用于有返回结果的同步非阻塞的执行方法,需要使用FutureTask包装后执行:
xxxxxxxxxx291public class MiTest {2
3 public static void main(String[] args) throws ExecutionException, InterruptedException {4 //1. 创建MyCallable5 MyCallable myCallable = new MyCallable();6 //2. 创建FutureTask,传入Callable7 FutureTask futureTask = new FutureTask(myCallable);8 //3. 创建Thread线程9 Thread t1 = new Thread(futureTask);10 //4. 启动线程11 t1.start();12 //5. 非阻塞式的做一些操作13 //6. 同步要结果14 Object count = futureTask.get();15 System.out.println("总和为:" + count);16 }17}18
19class MyCallable implements Callable{20
21 22 public Object call() throws Exception {23 int count = 0;24 for (int i = 0; i < 100; i++) {25 count += i;26 }27 return count;28 }29}
3. 线程的相关操作
1) 线程的基本属性
xxxxxxxxxx221// 1. 当前线程2public static native Thread currentThread(); // Thread类静态方法3
4// 2. 线程ID和名称5public long getId(); // 线程ID,一个递增的整数,每创建一个线程就加一6public final String getName(); // 线程名称,默认值是"Thread-"后跟一个编号7public final synchronized void setName(String name) // 设置线程名称(也可以在创建Thread对象时指定)8 9// 3. 线程优先级10public final int getPriority() // 获取线程优先级,从1~10,默认为511public final void setPriority(int newPriority) // 设置线程优先级,映射到不同操作系统优先级上(仅供提示)12 13// 4. 线程状态14public State getState() // 获取线程状态15 16// 5. 线程存活状态17public final native boolean isAlive() // 线程只有在NEW和TERMINATED状态才为false,其它都为true18
19// 6. 是否为守护线程(daemo线程,即其它线程的辅助线程,如垃圾回收线程等,当整个程序只剩下daemo线程时,程序就会退出。)20public final boolean isDaemon() // 是否为守护线程,默认为false21public final void setDaemon(boolean on) // 设置为守护线程22
2) 线程的常用方法
xxxxxxxxxx221// 1. 睡眠指定毫秒2// 时间有一定的偏差,在睡眠期间,会让出CPU,可以被其他线程中断(中断后抛出InterruptedException)3public static native void sleep(long millis) throws InterruptedException; // Thread的静态方法4
5// 2. 让出CPU(Runable->Ready状态,仅供建议,且只作用于当前线程)6public static native void yield(); // Thread的静态方法7
8// 3. 等待该线程结束。转为WAIT/TIMED_WAITING状态,等待期间可以被其他线程中断9public final void join() throws InterruptedException // 内部调用了join(0)10public final synchronized void join(long millis) throws InterruptedException 11
12// 4. 一些过时的方法,不应该去使用。13public final void stop()14public final void suspend()15public final void resume()16 17// 示例1:主线程等待thread线程,先不要退出18public static void main(String[] args) throws InterruptedException {19 Thread thread = new HelloThread();20 thread.start();21 thread.join();22} 注意:
wait()是对象级别的方法,定义在 Object 类,用于线程间的协作,需要在同步代码块中调用,会释放对象锁。join()是线程级别的方法,定义在 Thread 类,用于线程的同步,不会释放锁,用于等待目标线程执行完成。
4. 线程的结束方式
1) 正常/异常返回
正常/异常返回就是让线程的run方法结束,无论是return结束,还是抛出异常结束,都可以。
一般而言,对于以线程提供服务的程序模块,它应该封装取消或关闭的操作,让调用者能正确关闭线程。
xxxxxxxxxx61// Future接口提供了如下方法以取消任务2boolean cancel(boolean mayInterruptIfRunning);3
4// ExecutorService提供了如下两个关闭方法5void shutdown();6List<Runnable> shutdownNow();
2) 调用stop强制停止
强制让线程结束,无论你在干嘛,不推荐使用此种方式,但是,他确实可以把线程干掉。
xxxxxxxxxx131public static void main(String[] args) throws InterruptedException {2 Thread t1 = new Thread(() -> {3 try {4 Thread.sleep(5000);5 } catch (InterruptedException e) {6 e.printStackTrace();7 }8 });9 t1.start();10 Thread.sleep(500);11 t1.stop(); // 停止t1线程12 System.out.println(t1.getState());13}
3) 线程中断
线程中断是一种协作机制,通过给线程传递一个取消信号,由线程来决定如何以及何时退出,并不是强迫终止一个线程。
每个线程都有一个中断标志位,表示该线程是否被中断,可通过如下方式获取和设置:
xxxxxxxxxx71// 1. Thread类的实例方法(操作目标线程)2public boolean isInterrupted() // 获取线程是否被中断,即获取中断标志位3public void interrupt() // 中断该线程,即设置中断标志位为true4
5// 2. Thread类的静态方法(操作当前线程)6// 注意:此操作也会同时清空中断标志位,以方便后续处理!!!7public static boolean interrupted() // 检查当前线程是否被中断(设置了中断标识位)线程处于不同状态时,对中断方法的响应也会有所区别:
- 等待类状态(WAITING/TIMED_WAITING):会唤醒线程并抛
InterruptedException,同时清除中断标志; - RUNNABLE 状态:仅设置中断标志位,需线程主动检测才能响应;
- NEW/TERMINATED 状态:中断无任何效果,信号被忽略;
- BLOCKED 状态(synchronized 锁阻塞):不响应中断,线程继续等待锁;
- 特殊情况(LockSupport.park()):中断会唤醒线程并设置标志位,不抛异常。
5. 面试扩展
1) 并行 vs 并发
- 并行:两个及两个以上的作业在同一 时间段 内执行。
- 并发:两个及两个以上的作业在同一 时刻执行,多核CPU才可能并发,并发是并行的一个特例。
2) 阻塞 vs 非阻塞
主要取决于等待时能做别的吗,阻塞是 “等待时躺平”,资源被占用且无法复用,非阻塞是 “等待时摸鱼”,资源可高效利用:
- 阻塞:等待任务期间,当前线程 / 进程无法做任何事,只能闲置等待。
- 非阻塞:等待任务期间,当前线程 / 进程可继续处理其他任务,不用闲置。
3) 同步 vs 异步
主要取决于任务结果怎么通知,同步是 “主动等结果”,全程不脱离任务流程,异步是 “被动收通知”,发起后即可脱离任务流程:
- 同步:发起任务后,必须等待任务完全完成,才能继续做下一件事,结果实时获取。
- 异步:发起任务后,不用等待,直接去做其他事;任务完成后,会通过回调、通知等方式告知结果。
同步非阻塞与异步非阻塞的区别?
答:非阻塞指调用后立即返回,无需等待,同步还是异步取决于主动检查结果还是通过回调处理结果。
第二节 线程同步
1. 线程并发问题
1) 有序性
有序性指指令的执行顺序和编写顺序是否一致,在JIT编译和CPU执行层面,都可能会对指令进行重排序操作,以优化执行效率。
- 指令重排序操作只保证单线程下的执行逻辑一致(as-if-serial语义+happens-before原则),多线程下可能存在并发问题。
- 在Java中,对共享变量添加
volatile修饰,即可禁止指令重排序,其底层是基于内存屏障(mfence)实现的。
2) 可见性
可见性指一个线程对共享变量做了修改,其它线程是否可以立即看到修改后的值。
- 可见性问题主要是由于JMM的本地内存和CPU一级/二级缓存造成的,修改后的数据未及时写回主内存中。
- 在Java中,对共享变量添加
volatile修饰,也可以解决可见性问题。
注意:
- 在 Intel CPU 缓存层面,有一个MESI协议,标识缓存的修改状态,可以保证CPU缓存一致性问题。
- 但注意写缓冲器和无效化队列会对其进行破坏,部分情形需结合性能稍低的总线锁来保证。
- 伪共享:CPU缓存是按行加载的,如果不同CPU加载了同一个缓存行,分别对该行的X和Y变量进行修改,会导致缓存频繁失效。
3) 原子性
原子性指多次操作要么全都执行,要么全都不执行,不会受任何因素而中断。
- 在Java中,原子性问题可通过
CAS、synchronized、Lock等方式解决。
2. synchronized
1) synchronized简介
synchronized是 Java 内置的 线程同步关键字,用于保证多线程环境下共享资源的安全访问,核心特性如下:
- 原子性:被修饰的代码块 / 方法会被当作一个 “整体” 执行,要么全部完成,要么全部不执行,不会被其他线程打断;
- 可见性:线程释放锁时,会将修改后的共享变量值同步到主内存;其他线程获取锁时,会从主内存读取最新值。
- 有序性:禁止指令重排序,确保代码执行顺序和编写顺序一致,避免多线程下的逻辑混乱;
- 非公平锁:默认不保证等待线程的获取顺序,谁先抢到锁谁执行,优点是效率高。
- 可重入性:内部会记录持有锁的线程和重入数,支持某个线程多次获取和释放锁。
注意:
- 在等待synchronized锁时,进入锁对象的锁等待队列,线程状态为
BLOCK状态,此时无法响应中断。
2) 基本使用
修饰实例方法
修饰实例方法,对 this对象 进行加锁:
xxxxxxxxxx141// 2public class Counter {3 private int count; // 共享变量4
5 // synchronized6 public synchronized void incr() {7 count++;8 }9
10 // synchronized11 public synchronized int getCount() {12 return count;13 }14}注意:
- 特别注意,同一个对象的不同synchronized方法不能同时执行,但不同对象的同一synchronized方法能够同时执行。
- 无法修饰构造方法,因为不可能多个线程同时调用同一个对象的构造方法,如需加锁,需在内部使用静态代码块。
修饰静态方法
修饰静态方法,对 类对象(StaticCounter.class) 进行加锁:
xxxxxxxxxx111public class StaticCounter {2 private static int count = 0; // 共享变量3
4 public static synchronized void incr() {5 count++;6 }7
8 public static synchronized int getCount() {9 return count;10 }11}注意:
- 同一个对象的静态synchronized方法和实例synchronized方法修饰的是不同对象,可以同时执行。
修饰代码块
修饰代码块,对 指定对象 进行加锁:
xxxxxxxxxx161public class Counter {2 private int count; // 共享变量3 private Object lock = new Object(); // 锁对象(lock也可以是this或类对象)4 5 public void incr(){6 synchronized(lock){ 7 count ++; 8 }9 }10 11 public int getCount() {12 synchronized(lock){13 return count;14 }15 }16} 注意:
- 指定的对象不能为null,否则会抛 NullPointerException。
- 尽量不要使用包装类或字符串作为锁对象,因为它们有缓存池或常量池,锁对象粒度会过大。
3) 实现原理
在Java的对象头中,有一个64位的MarkWord字段,用于记录 synchronized锁的四种状态变化:
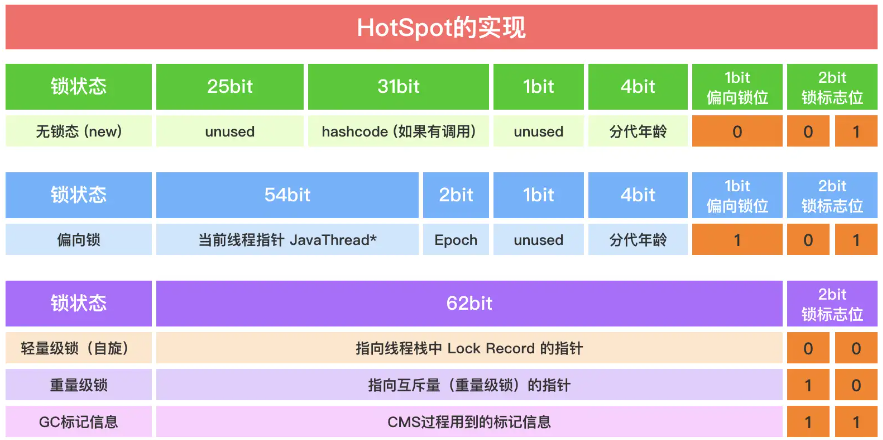
在升级到重量级锁后,调用的是C++编写的ObjectMonitor.hpp代码:https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/69087d08d473/src/share/vm/runtime/objectMonitor.cpp
4) 扩展知识
锁消除:如果不存在操作临界资源的情况,会触发锁消除,你即便写了synchronized,它也不会触发。
xxxxxxxxxx41public synchronized void method(){2// 没有操作临界资源3// 此时这个方法的synchronized你可以认为木有~~4}锁膨胀:在循环中频繁的获取和释放锁资源时,会带来很大的消耗,此时可能会将锁膨胀到循环之外。
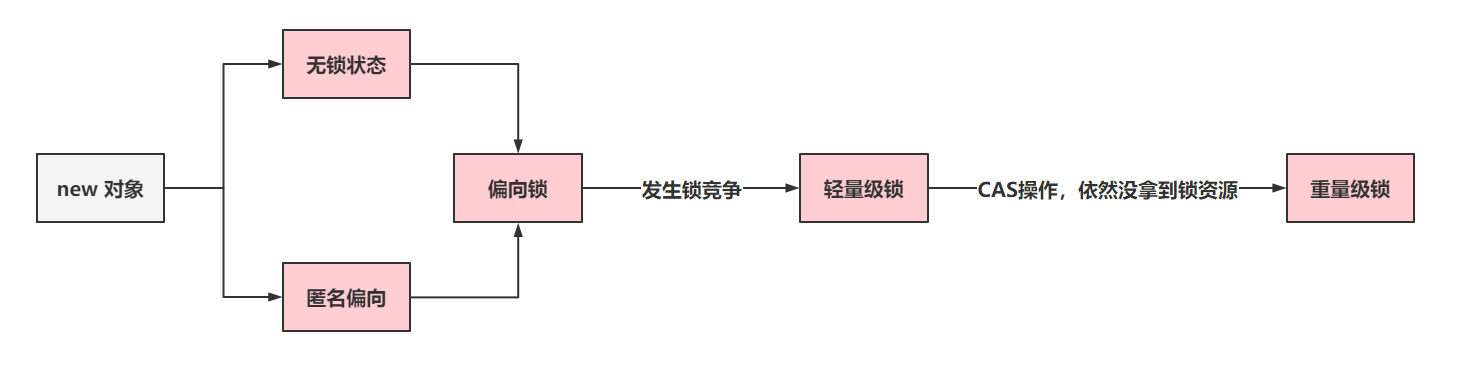
xxxxxxxxxx131public void method(){2for(int i = 0;i < 999999;i++){3synchronized(对象){45}6}7// 这是上面的代码会触发锁膨胀8synchronized(对象){9for(int i = 0;i < 999999;i++){1011}12}13}锁升级:
同步对象初始是无锁状态,当一个线程访问同步块并获取锁时,会升级为偏向锁(该锁在高版本JDK已被禁用)。
当其它线程也试图访问该对象时,偏向锁会升级为轻量级锁,获取到锁的线程执行,其它线程进行自旋。
当锁竞争加剧时,自旋会大量消耗CPU资源,此时会升级为重量级锁,获取到锁的线程执行,其它线程阻塞等待。
3. wait/notify
1) wait/notify简介
在Java中,任意对象都可以参与线程协作,它们都有wait和notify方法,可以在synchronized代码块中调用:
- 在调用wait方法后,当前线程状态变为
WAITING/TIMED_WAITING,进入锁对象的条件等待队列。 - 当被其它线程notify方法唤醒后,需重新竞争锁,如果获取到锁,线程状态变为
RUNNABLE,并从wait调用中返回。 - 如果未获取到锁,将会进入锁对象的锁等待队列,线程状态变为
BLOCKED,直到获得锁后才能从wait调用返回。
xxxxxxxxxx81// 1. wait2public final void wait() throws InterruptedException // 无限期等待,等同wait(0)3public final native void wait(long timeout) throws InterruptedException // 超时等待,timeout表示等待时间,单位为毫秒4
5// 2. notify6public final native void notify(); // 通知,从条件队列中选一个线程,将其从队列中移除并唤醒7public final native void notifyAll(); // 通知所有,移除条件队列中所有的线程并全部唤醒8
特别注意,从wait返回后,不一定表示等待的条件就满足了,仍需进行条件检查,因此,wait方法的一般调用模式为:
xxxxxxxxxx71synchronized (obj) {2 // 循环检查条件是否满足3 while (!条件成立)4 obj.wait(); // 不满足则释放锁,进入等待5 6 // 执行条件满足后的操作7}注意:
- 并非调用notify方法后就立即释放锁,而是等到当前synchronized代码块执行完毕后才会释放,其它线程才可能获取到锁。
- wait/notify 机制只支持一个条件队列,如果有多个等待条件,只能共用,并且在通知时必须通知所有等待的线程。
- 线程对象的join方法是基于wait方法实现的,当子线程运行结束时,由 JVM 调用notifyAll来通知。
2) 生产者/消费者模型
生产者线程和消费者线程通过共享队列进行协作,生产者将数据或任务放到队列上,而消费者从队列上取数据或任务。如果队列长度有限,在队列满的时候,生产者需要等待,而在队列为空的时候,消费者需要等待。
它们协作的共享变量是队列,我们将队列作为单独的类进行设计,代码如下:
xxxxxxxxxx281static class MyBlockingQueue<E> {2 private Queue<E> queue = null; // 1. 共享变量:队列3 private int limit; // 队列上限4
5 public MyBlockingQueue(int limit) {6 this.limit = limit;7 queue = new ArrayDeque<>(limit);8 }9
10 // 2. 生产者调用,放数据,如果满了则等待11 public synchronized void put(E e) throws InterruptedException {12 while (queue.size() == limit) {13 wait(); // 等待(注意,锁对象为this)14 }15 queue.add(e);16 notifyAll(); // 4. 生产数据后可通知消费者“有数据了”!(注意:这里只能通知所有线程)17 }18
19 // 3. 消费者调用,拿数据,空了也等待20 public synchronized E take() throws InterruptedException {21 while (queue.isEmpty()) {22 wait();23 }24 E e = queue.poll();25 notifyAll(); // 5. 拿走数据后可通知生产者“有空位了”(注意:这里只能通知所有线程)26 return e;27 }28}在上面代码中,生产者和消费者都调用了wait方法,但它们等待的条件是不一样的。生产者在队列为满时等待,而消费者在队列为空的时候等待,它们等待条件不同但又使用相同的条件队列,所以要调用notifyAll而不能调用notify,因为notify可能唤醒的恰好是同类线程。
类似的,它们也都调用了notifyAll方法,但是需满足的条件也不一致,生产者在“有数据了”的条件下通知消费者,消费者在“有空位了”的条件下通知生产者。
3) 同时开始模型
在运动员比赛中,听到比赛开始枪响后同时开始,在一些程序,尤其是模拟仿真程序中,要求多个线程能同时开始。
它们协作的共享变量是一个开始信号,我们用一个类FireFlag来表示这个协作对象:
xxxxxxxxxx161static class FireFlag {2 private volatile boolean fired = false; // 1. 共享变量:是否开始3
4 // 2. 子线程在启动后调用,等待开始5 public synchronized void waitForFire() throws InterruptedException {6 while (!fired) {7 wait(); // 等待(注意,锁对象为this)8 }9 }10
11 // 3. 主线程调用,发起开始指令12 public synchronized void fire() {13 this.fired = true; 14 notifyAll(); // 通知所有wait的线程15 }16}子线程应该调用waitForFire()等待枪响,而主线程应该调用fire()发射比赛开始信号,代码如下:
xxxxxxxxxx341// 子线程2static class Racer extends Thread {3 FireFlag fireFlag; // 1. 共享变量4
5 public Racer(FireFlag fireFlag) {6 this.fireFlag = fireFlag;7 }8
9 10 public void run() {11 try {12 // 2. 等待开始13 this.fireFlag.waitForFire();14 System.out.println("start run " + Thread.currentThread().getName());15 } catch (InterruptedException e) {16 }17 }18}19
20// 主线程21public static void main(String[] args) throws InterruptedException {22 // 1. 启动20个子线程23 int num = 10;24 FireFlag fireFlag = new FireFlag();25 Thread[] racers = new Thread[num];26 for (int i = 0; i < num; i++) {27 racers[i] = new Racer(fireFlag);28 racers[i].start();29 }30 Thread.sleep(1000);31 32 // 2. 开始33 fireFlag.fire(); 34}
4) 等待结束模型
主线程将任务分解为若干个子任务,为每个子任务创建一个线程,主线程在继续执行其他任务之前需要等待每个子任务执行完毕。
主线程与各个子线程协作的共享变量是一个数,这个数表示未结束线程个数,代码如下:
xxxxxxxxxx221public class MyLatch {2 private int count; // 1. 共享变量3
4 public MyLatch(int count) {5 this.count = count; // 初始化为子线程个数6 }7
8 // 2. 主线程调用,等待所有子线程结束9 public synchronized void await() throws InterruptedException {10 while (count > 0) {11 wait();12 }13 }14
15 // 3. 子线程在退出前调用,线程计数 - 116 public synchronized void countDown() {17 count--;18 if (count <= 0) {19 notifyAll();20 }21 }22}应用代码示例如下:
xxxxxxxxxx381// 子线程2static class Worker extends Thread {3 MyLatch latch;4
5 public Worker(MyLatch latch) {6 this.latch = latch;7 }8
9 10 public void run() {11 try {12 // 1. 执行业务13 Thread.sleep((int) (Math.random() * 1000));14
15 // 2. 结束前调用countDown,线程计数-116 this.latch.countDown(); 17 } catch (InterruptedException e) {18 }19 }20}21
22// 主线程23public static void main(String[] args) throws InterruptedException {24 // 1. 初始化计数25 int workerNum = 100;26 MyLatch latch = new MyLatch(workerNum); 27 28 // 2. 启动100个线程29 Worker[] workers = new Worker[workerNum];30 for (int i = 0; i < workerNum; i++) {31 workers[i] = new Worker(latch);32 workers[i].start();33 }34 35 // 3. 等待子线程都结束36 latch.await(); 37 System.out.println("collect worker results");38}注意:
- 可将线程计数初始值设置为1,由子线程调用await(),主线程调用countDown(),还可实现上面的“同时开始”模式。
4) 集合点模型
在并行迭代计算中,每个线程负责一部分计算,然后在集合点等待其他线程完成,所有线程到齐后,交换数据和计算结果,再进行下一次迭代。
它们协作的共享变量依然是一个数,这个数表示未到集合点的线程个数。
xxxxxxxxxx281// CyclicBarrier2public class AssemblePoint {3 private int n; // 1. 共享变量4
5 public AssemblePoint(int n) {6 this.n = n;7 }8
9 // 2. 集合,线程达到集合点时调用,等待其它未到的线程。10 public synchronized void await() throws InterruptedException {11 // 2.1 n >0 表示还有线程未到12 if (n > 0) {13 // 2.2 线程计数-114 n--;15 16 // 2.3 n==0 表示当前线程为最后一个到达线程,此时唤醒其它线程17 if (n == 0) {18 notifyAll();19 } else {20 // 2.3 n>0 表示还有线程未到,进行等待21 while (n != 0) {22 wait();23 }24 }25 26 }27 }28}多个游客线程,各自先独立运行,然后使用该协作对象到达集合点进行同步的示例代码如下:
xxxxxxxxxx371// 需集合的线程2public class AssemblePointDemo {3 static class Tourist extends Thread {4 AssemblePoint ap; // 1. 共享变量5
6 public Tourist(AssemblePoint ap) {7 this.ap = ap;8 }9
10 11 public void run() {12 try {13 // 2. 模拟先各自独立运行14 Thread.sleep((int) (Math.random() * 1000));15
16 // 3. 集合17 ap.await();18 System.out.println("arrived");19 20 // 4. 集合后执行其他操作21 } catch (InterruptedException e) {22 }23 }24 }25
26 // 主线程27 public static void main(String[] args) {28 // 1. 启动多个需集合的线程29 int num = 10;30 Tourist[] threads = new Tourist[num];31 AssemblePoint ap = new AssemblePoint(num);32 for (int i = 0; i < num; i++) {33 threads[i] = new Tourist(ap);34 threads[i].start();35 }36 }37}
5) 非阻塞调用模型
在并发编程中,一种常见的模式是将子线程的管理封装为非阻塞调用,非阻塞调用马上返回,但返回的不是最终的结果,而是一个一般称为Promise或Future的对象,通过它可以在随后获得最终的结果。
异步结果模式依赖异步调用框架,主要由调用者、执行器、异步任务、异步结果四个部分组成。
其中异步任务和异步结果代码表示如下:
xxxxxxxxxx91// 异步任务2public interface Callable<V> {3 V call() throws Exception;4}5
6// 异步结果7public interface MyFuture <V> {8 V get() throws Exception ; // 返回真正的结果。如果尚未计算完成,则等待。如果计算过程发生了异常,则抛出保存的异常。9}执行器用于执行子任务并返回异步结果,使用执行器后调用者就无需创建并管理子线程了,其代码如下:
xxxxxxxxxx781// 执行器2public <V> MyFuture<V> execute(final Callable<V> task) {3 // 1. 创建锁对象4 final Object lock = new Object(); 5 6 // 2. 创建和启动执行线程7 final ExecuteThread<V> thread = new ExecuteThread<>(task, lock);8 thread.start();9
10 // 3. 创建异步结果对象,用于获取异步结果11 MyFuture<V> future = new MyFuture<V>() {12 13 public V get() throws Exception {14 synchronized (lock) {15 16 // 3.1 执行线程未结束,则等待17 while (!thread.isDone()) {18 try {19 lock.wait();20 } catch (InterruptedException e) {21 }22 }23 24 // 3.2 执行过程中出现异常,在调用get时直接抛出异常25 if (thread.getException() != null) {26 throw thread.getException(); 27 }28 29 // 3.3 执行线程完结束后,直接返回保存的真实结果30 return thread.getResult(); 31 }32 }33 };34 35 // 4. 返回一个异步结果对象36 return future;37}38
39// 执行器委托给执行线程去执行40static class ExecuteThread<V> extends Thread {41 private V result = null; // 结果42 private Exception exception = null; // 异常43 private boolean done = false; // 是否完成44 private Callable<V> task; // 任务45 private Object lock; // 锁对象46 47 public ExecuteThread(Callable<V> task, Object lock) {48 this.task = task;49 this.lock = lock;50 }51
52 53 public void run() {54 // 1. 执行任务,捕获异常,修改完成标记,通知其它线程55 try {56 result = task.call();57 } catch (Exception e) {58 exception = e;59 } finally {60 synchronized (lock) {61 done = true;62 lock.notifyAll();63 }64 }65 }66
67 public V getResult() {68 return result;69 }70
71 public boolean isDone() {72 return done;73 }74
75 public Exception getException() {76 return exception;77 }78}调用者只需创建执行器,然后执行异步任务,即可得到异步结果对象。
xxxxxxxxxx281public static void main(String[] args) {2 // 1. 创建执行器3 MyExecutor executor = new MyExecutor();4 5 // 2. 创建异步任务6 Callable<Integer> subTask = new Callable<Integer>() {7 8 public Integer call() throws Exception {9 // 执行异步任务10 int millis = (int) (Math.random() * 1000);11 Thread.sleep(millis);12 return millis;13 }14 };15 16 // 3. 执行异步任务,返回异步结果17 MyFuture<Integer> future = executor.execute(subTask); // MyFuture执行的匿名内部类中对象中封装了执行线程对象18 19 // 4. 执行其他操作20 21 try {22 // 5. 获取异步调用的真实结果23 Integer result = future.get(); // 等待执行线程的finally中调用 lock.notifyAll() 24 System.out.println(result); // 6.1 处理真实结果25 } catch (Exception e) {26 e.printStackTrace(); // 6.2 处理异步任务异常27 }28}
4. 面试扩展
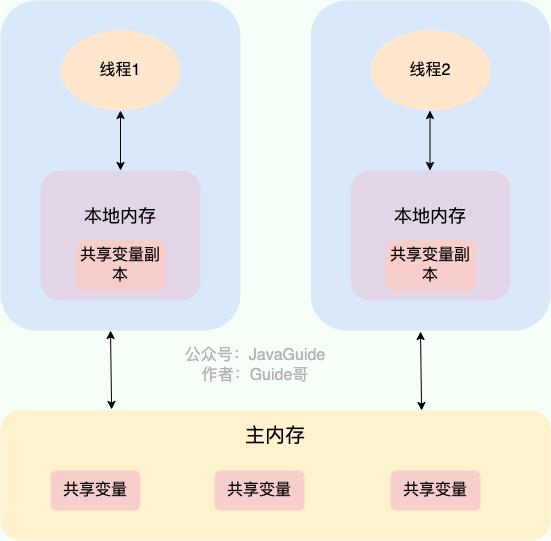
1) JMM简介
JMM是一个语言层面的内存模型抽象,用于描述多线程访问共享变量时的一系列行为规范。主要由两部分组成:
- 主内存:线程共享的内存区域,存储了所有实例对象、类信息、常量、静态变量等。
- 本地内存:线程私有的内存区域,存储了该线程读/写共享变量的副本。
交互原则:变量都存储在主内存中,在操作时,需从主内存复制一份副本到本地内存,修改完毕后,再写回主内存。
交互指令:lock(锁定)、unlock(解锁)、read(读取)、load(载入)、use(使用)、assign(赋值)、store(存储)、write(写入)。
注意:
- JMM是抽象的,定义了线程与主内存、本地内存之间的交互规范,Java运行时内存区域是具体的,定义了运行时内存的划分。
2) sleep/wait/join/park的区别
- Thread::sleep(long ms):Thread类的静态方法,用于暂停当前线程,期间不释放锁资源。
- Object.wait()/wait(long ms):Object类的实例方法,需在synchronized代码中调用, 释放锁并等待,主要用于线程间的协作。
- Thread.join()/join(long ms):Thread类的实例方法,主要用于线程顺序控制(如让子线程执行完后,主线程再继续),也会释放锁。
- LockSupport::park():LockSupport类的静态方法,可无锁调用,阻塞当前线程,但不释放锁或抛中断异常,主要用于实现AQS等。
3) CAS/syncchronized/Lock的对比
| 对比维度 | CAS 的核心特点 | synchronized 的核心特点 | Lock 的核心特点 |
|---|---|---|---|
| 实现原理 | 无锁,依赖 CPU 原子指令(如 cmpxchg),无需阻塞线程 | 基于对象监视器锁(Monitor),JVM 底层实现,可阻塞线程 | 基于 AQS(抽象队列同步器),API 层面实现,可阻塞线程 |
| 锁类型 | 无锁(非阻塞同步),不存在 “锁” 的概念 | 悲观锁,支持可重入,默认非公平锁 | 悲观锁,支持可重入,可选公平 / 非公平锁 |
| 核心特性 | 无线程阻塞,但有 ABA 问题、自旋消耗 | 自动释放锁(异常 / 方法结束),无扩展特性 | 支持超时获取、可中断、条件变量(Condition),特性丰富 |
| 使用场景 | 简单原子操作(如原子类 AtomicInteger),追求极致性能 | 通用并发场景,代码简洁,无需手动处理锁释放 | 复杂并发场景(如需要中断等待、超时获取锁),需灵活控制锁 |
4) 悲观锁 vs 乐观锁
- 悲观锁:假设数据冲突是大概率事件,每次操作前都会加锁,禁止其它线程访问,适用于写操作较多、数据竞争激烈的场景。
- 乐观锁:假设数据冲突是小概率事件,先操作后再检查是否有冲突,如果有再重试,适用于读操作多、写操作少的场景。
注意:
- 乐观锁无需切换上下文及内核态,在并发量低时,性能表现更好,可通过 CAS 来实现。
5) 关于死锁
当以不同顺序对多个资源进行加锁时,就可能造成死锁,即持有锁A的同时去获取锁B,但锁B已被其它线程持有且恰好需要获取锁A。
死锁检测:可通过jstack -pid命令查看。
避免死锁:
- 应该尽量避免在持有一个锁的同时去申请另一个锁,如果确实需要多个锁,所有代码都应该按照相同的顺序去申请锁。
- 在Java中,也有一些显式锁支持tryLock以及加锁超时的设定,也可以一定程度解决死锁问题。
xxxxxxxxxx501public class DeadLockDemo {2 private static Object lockA = new Object(); // 全局锁A3 private static Object lockB = new Object(); // 全局锁B4
5 // A线程6 private static void startThreadA() {7 Thread aThread = new Thread() {8
9 10 public void run() {11 // 1. 线程A:先持有锁A,等待会后去申请锁B12 synchronized (lockA) {13 try {14 Thread.sleep(1000);15 } catch (InterruptedException e) {16 }17 synchronized (lockB) {18 }19 }20 }21 };22 aThread.start();23 }24
25 // B线程26 private static void startThreadB() {27 Thread bThread = new Thread() {28 29 public void run() {30 // 2. 线程B:先持有锁B,等待会后去申请锁A31 synchronized (lockB) {32 try {33 Thread.sleep(1000);34 } catch (InterruptedException e) {35 }36 synchronized (lockA) {37 }38 }39 }40 };41 bThread.start();42 }43
44 public static void main(String[] args) {45 // 3. 启动两个线程,可能造成死锁(线程A等线程B释放B锁,线程B等待线程A释放A锁)46 startThreadA();47 startThreadB();48 }49}50
6) 线程安全问题有哪些解决措施
线程表示一条单独的执行流,有各自的计数器和栈等,但是内存是共享的,并发操作就会存在竞争和内存可见性问题,解决思路如下:
- volatile:可解决内存可见性和指令重排序问题,在无需保证原子性时可以单独使用。
- CAS:基于硬件指令进行原子更新,配合死循环可实现原子变量,配合 LockSupport 等可实现 AQS 等。
- synchronized:Java内置同步机制,但它只有一个条件队列,且不响应中断,不能尝试加锁或超时加锁等。
- ReentrantLock:更灵活的悲观锁,可以响应中断、可以限时、可以指定公平性、可以避免死锁问题等。
- CopyOnWrite:写时复制,在修改时拷贝一份副本,修改好后通过 CAS 修改对象地址,支持读写兼容。
- ThreadLocal:每个线程都持有变量的独立副本,不同线程之间相互隔离,互不影响。
7) 线程之间的协作机制有哪些?
线程之间需要相互协作,来解决业务问题:
wait/notify:在 synchronized 代码块中调用,通过一个锁等待队列和一个条件等待队列进行协作。
signal/signalAll:在获取锁后,通过条件对象进行调用,可明确等待的条件和通知的线程,更为灵活可靠。
park/unpark:无锁获取锁即可调用,park方法可让当前线程释放CPU进入等待,unpark方法则可唤醒指定的线程。
线程中断:给线程传递一个取消信号,但是由线程来决定如何以及何时退出,线程在不同状态和IO操作时对中断有不同的反应。
- 线程的提供者,应该提供相应的取消/关闭方式,而不是让调用者贸然的调用线程中断。
协作工具类:如信号量(Semaphore)用于限制对资源的并发访问数,倒计时门栓(CountDownLatch)用于不同角色线程间的同步,循环栅栏(CyclicBarrier)用于同一角色线程间的协调一致。
阻塞队列:如基于数组的 ArrayBlockingQueue 和基于链表的 LinkedBlockingQueue 等,可用于实现生产者/消费者协作模式等。
Future/FutureTask:主线程让子线程异步执行一项任务,随后获取其结果,常用于主从协作模式中。
第三节 线程本地变量
1. 基本使用
1) ThreadLocal简介
线程本地变量(ThreadLocal)指与线程绑定的变量,即每个线程都有同一个变量的独有拷贝,在Java中,用ThreadLocal表示。
xxxxxxxxxx151// 1. 构造方法2public ThreadLocal() // 有一个泛型,表示变量的实际类型3public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) // 静态方法,指定初始值构造4
5// 2. 获取和设置当前线程变量6public T get()7public void set(T value)8
9// 3. 提供初始值10// 默认无参构造无法提供初始值,通过重写如下方法,可提供初始值11protected T initialValue() // 当调用get方法时,如果之前没有set过,会调用该方法获取初始值,默认实现是返回null12
13// 4. 删掉当前线程对应的值14public void remove() // 如果删掉后,再次调用get,会再调用initialValue获取初始值15
注意:
- Thread内部存在一个 inheritableThreadLocals 变量,可用于跨线程传递 ThreadLocal 的值,但不支持线程池场景。
- 阿里开源工具类可以解决上述问题:
TransmittableThreadLocal,它自定义了线程类并对线程池进行了装饰。
2) 应用示例
xxxxxxxxxx441// 示例1:主线程和子线程操作同一个变量互不干扰2public class ThreadLocalBasic {3 // 定义线程本地变量,存储一个Integer4 static ThreadLocal<Integer> local = new ThreadLocal<>();5
6 public static void main(String[] args) throws InterruptedException {7 // 子线程8 Thread child = new Thread() {9 10 public void run() {11 System.out.println("child thread initial: " + local.get()); // null12 local.set(200);13 System.out.println("child thread final: " + local.get()); // 20014 }15 };16 17 // 主线程18 local.set(100);19 child.start();20 child.join();21 System.out.println("main thread final: " + local.get()); // 10022 }23}24
25// 示例2:封装线程安全的SimpleDateFormat26public class ThreadLocalDateFormat {27 // 线程本地的DateFormat28 static ThreadLocal<DateFormat> sdf = new ThreadLocal<DateFormat>() {29
30 // 初始值为SimpleDateFormat("yyyy-MM-dd HH:mm:ss")31 32 protected DateFormat initialValue() {33 return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");34 }35 };36
37 public static String date2String(Date date) {38 return sdf.get().format(date);39 }40
41 public static Date string2Date(String str) throws ParseException {42 return sdf.get().parse(str);43 }44}注意:
- 一般来说,ThreadLocal对象都定义为static,以便于引用。
2. 源码分析
1) 实现思路
在 Thread 类内部,有一个名为 threadLocals 的 ThreadLocalMap 对象,其 Key 为 ThreadLocal 对象的弱引用,Value 为该变量在该线程的值,在调用 ThreadLocal 的 get/set 方法时,就是获取当前线程的该变量进行 get/set,而 ThreadLocal 的作用更像是一个工具类。
2) set方法实现
每个线程都有一个ThreadLocalMap,调用set实际上是在线程自己的Map里设置了一个条目,键为当前的ThreadLocal对象,值为value。
xxxxxxxxxx231// ThreadLocal.set2public void set(T value) {3 // 1. 获取当前线程的ThreadLocalMap4 Thread t = Thread.currentThread();5 ThreadLocalMap map = getMap(t); 6
7 // 2. 创建和存储value8 if (map != null)9 map.set(this, value);10 else11 createMap(t, value);12}13
14// ThreadLocal.set -> getMap15ThreadLocalMap getMap(Thread t) {16 return t.threadLocals; // 返回线程的实例变量threadLocals,初始值为null17}18
19// ThreadLocal.set -> createMap20void createMap(Thread t, T firstValue) {21 t.threadLocals = new ThreadLocalMap(this, firstValue); 22}23
注意:
- 当前线程对象不能持有ThreadLocal对象的强引用,否则必须等到当前线程结束,ThreadLocal对象才能被GC回收,所以ThreadLocalMap 的 Key 采用弱引用。
3) get方法实现
xxxxxxxxxx311public T get() {2 // 1. 获取当前线程的ThreadLocalMap3 Thread t = Thread.currentThread();4 ThreadLocalMap map = getMap(t);5
6 // 2. key为当前ThreadLocal变量,value为在当前线程存储的值7 if (map != null) {8 ThreadLocalMap.Entry e = map.getEntry(this);9 if (e != null)10 return (T)e.value;11 }12 13 // 3. 如果未set值(而非值为null),则返回初始值14 return setInitialValue();15}16
17// ThreadLocal.get -> setInitialValue18private T setInitialValue() {19 // 1. 获取初始值20 T value = initialValue();21
22 // 2. 进行set23 Thread t = Thread.currentThread();24 ThreadLocalMap map = getMap(t);25 if (map != null)26 map.set(this, value);27 else28 createMap(t, value);29
30 return value;31}
4) remove方法实现
xxxxxxxxxx81public void remove() {2 // 1. 获取当前线程ThreadLocalMap3 ThreadLocalMap m = getMap(Thread.currentThread());4
5 // 2. 移出当前TL变量对应的条目6 if (m != null)7 m.remove(this);8}注意:
- 在使用完 ThreadLocal 变量后,必须调用 remove() 方法清空 ThreadLocalMap 中的相关条目,否则业务数据(value)一直被当前线程持有,无法被GC回收,可能导致内存泄漏。
3. 面试扩展
1) 在线程池中使用TL时如何清理?
如果在线程池任务中使用了ThreadLocal,并且未进行清理操作,那么会将修改后的值带到下一个任务,清理方式如下:
- 方式一:在任务的run方法中添加finally语句清理当前线程。
xxxxxxxxxx141static class Task implements Runnable {2
3 4 public void run() {5 try{6 AtomicInteger s = sequencer.get();7 int initial = s.getAndIncrement();8 // 期望初始为09 System.out.println(initial); 10 }finally{11 sequencer.remove();12 }13 }14}- 方式二:重写线程池的beforeExecute/afterExecute方法,在任务执行之前/之后,反射清空所有ThreadLocal变量,推荐使用。
xxxxxxxxxx201static class MyThreadPool extends ThreadPoolExecutor {2 public MyThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,3 BlockingQueue<Runnable> workQueue) {4 super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);5 }6
7 8 protected void beforeExecute(Thread t, Runnable r) {9 try {10 // 使用反射清空所有ThreadLocal11 Field f = t.getClass().getDeclaredField("threadLocals");12 f.setAccessible(true);13 f.set(t, null);14 } catch (Exception e) {15 e.printStackTrace();16 }17 18 super.beforeExecute(t, r);19 }20}
第02章_并发工具
第一节 CAS工具
1. volatile
1) volatile简介
volatile关键字可修饰变量,表示该变量是共享且不稳定的,禁用 CPU 缓存,每次都从主内存读取,防止出现内存可见性问题。
另外,还会通过插入特定的 内存屏障 的方式来防止 JVM 的指令重排序,但它不能保证对变量的操作是原子性的。
1// 使用双检锁方式创建单例对象2public class Singleton {3 private volatile static Singleton uniqueInstance; // 必须要加 volatile 防止指令重排4 private Singleton() {5 }6 public static Singleton getUniqueInstance() {7 if (uniqueInstance == null) {8 synchronized (Singleton.class) {9 if (uniqueInstance == null) {10 // 1) 为 uniqueInstance 分配内存空间11 // 2) 初始化 uniqueInstance12 // 3) 将 uniqueInstance 指向分配的内存地址13 uniqueInstance = new Singleton(); // 如果不使用volatile,可能会先执行1和3,被其它线程获取到尚未初始化的实例14 }15 }16 }17 return uniqueInstance;18 }19}
2. CAS
1) CAS简介
CAS 是 Compare and Swap(比较并交换) 的缩写,是一种无锁的原子操作,在Java中,是通过Unsafe 类调用 CPU 指令实现的。
xxxxxxxxxx51// CAS:如果当前值等于expect,则更新为update,否则不更新。如果更新成功,返回true,否则返回false。2public final boolean compareAndSet(int expect, int update) {3 // Unsafe类的CAS方法:依赖底层计算机系统在硬件层次上直接支持的CAS指令4 return unsafe.compareAndSwapInt(this, valueOffset, expect, update);5}
2) CAS优缺点
优点:
- 无锁开销小:不需要加锁 / 解锁(避免了线程上下文切换的开销),并发量不高时效率比
synchronized高; - 原子性保证:CPU 级别的原子操作,天然线程安全;
- 支持乐观锁:假设线程冲突少,失败了再重试,适合读多写少的场景。
缺点:
ABA 问题(核心缺陷):即无法感知两次读取之间值的变化,如果业务有严格要求,可通过附加时间戳或版本号支持检测。
xxxxxxxxxx181// AtomicStampedReference中的CAS:同时修改两个值,一个是值,另一个是时间戳,将两个组合为一个对象进行CAS操作2// 此外,还可以使用AtomicMarkableReference,它多关联了一个boolean类型的标志位,只有值和标志位都相同的情况下才进行修改。3public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp) {4Pair<V> current = pair;5return expectedReference == current.reference && // 期望值与当前值相等6expectedStamp == current.stamp && // 期望时间戳与当前时间戳相等7(8(newReference == current.reference && newStamp == current.stamp) // 无需更新9|| casPair(current, Pair.of(newReference, newStamp)) // 使用组合对象进行CAS更新10);11}1213// 示例1:14Pair pair = new Pair(100, 200);15int stamp = 1;16AtomicStampedReference<Pair> pairRef = new AtomicStampedReference<Pair>(pair, stamp); // 初始值,初始时间戳17int newStamp = 2;18pairRef.compareAndSet(pair, new Pair(200, 200), stamp, newStamp); // 比较旧值和旧时间戳都一致才更新自旋开销:并发冲突严重时,线程会一直循环重试(自旋),占用 CPU 资源(相当于 “忙等”)。
- 解决:可设置自旋次数上限(比如 JVM 的锁优化中的 “自适应自旋”),或改用阻塞锁。
只能保证单个变量原子操作:CAS 只能对单个变量进行原子修改,无法直接实现多个变量的原子操作(比如同时修改两个变量);
- 解决:用
AtomicReference包装多个变量(把它们变成一个对象),或用锁。
- 解决:用
3. 原子变量
1) 原子变量简介
在Java中,基于CAS在应用层提供了一系列的原子变量,可以保证更新操作的原子性,且无需加锁以及上下文切换,效率更高。
| 基本类型 | 原子变量 | 原子数组 | 原子字段更新器 |
|---|---|---|---|
| Boolean | AtomicBoolean | ||
| Integer | AtomicInteger | AtomicIntegerArray | AtomicIntegerFieldUpdater |
| Long | AtomicLong | AtomicLongArray | AtomicLongFieldUpdater |
| Reference | AtomicReference | AtomicReferenceArray | AtomicReferenceFieldUpdater |
注意:
- 在不同CPU架构中,CAS的指令也不相同,在 x86 架构中,CAS指令为:
cmpxchg。
2) AtomicInteger
AtomicInteger可以用作计数器等场景,常用方法如下:
xxxxxxxxxx441// 1. 构造方法2public AtomicInteger(int initialValue) // initialValue-初始值3public AtomicInteger() // initialValue为04 5// 2. 获取和设置6public final int get() 7public final void set(int newValue) 8
9// 3. 组合操作方法10public final int getAndSet(int newValue) // 以原子方式 获取旧值 并 设置新值11public final int getAndIncrement() // 以原子方式获取旧值并给当前值加1,类似于count++12public final int getAndDecrement() // 以原子方式获取旧值并给当前值减1,类似于count--13public final int incrementAndGet() // 以原子方式给当前值加1并获取新值,类似于++count14public final int decrementAndGet() // 以原子方式给当前值减1并获取新值,类似于--count15public final int addAndGet(int delta) // 以原子方式给当前值加delta并获取新值,类似于count = count + delta16public final int getAndAdd(int delta) // 以原子方式获取旧值并给当前值加delta17 18// 示例1:计数器19public class AtomicIntegerDemo {20 private static AtomicInteger counter = new AtomicInteger(0); // 原子变量计数器21
22 static class Visitor extends Thread {23 24 public void run() {25 for (int i = 0; i < 100; i++) {26 counter.incrementAndGet(); // 原子自增27 Thread.yield();28 }29 }30 }31
32 public static void main(String[] args) throws InterruptedException {33 int num = 100;34 Thread[] threads = new Thread[num];35 for (int i = 0; i < num; i++) {36 threads[i] = new Visitor();37 threads[i].start();38 }39 for (int i = 0; i < num; i++) {40 threads[i].join();41 }42 System.out.println(counter.get()); // 计数结果总是1000043 }44}AtomicBoolean可以用来在程序中表示一个标志位,它的原子操作方法有:
xxxxxxxxxx21public final boolean getAndSet(boolean newValue) 2public final boolean compareAndSet(boolean expect, boolean update)AtomicLong可以用来在程序中生成唯一序列号,它的方法与AtomicInteger类似。
注意:
- 在实际应用中,更多的是使用
LongAddr作为并发计数器,性能更高。
3) AtomicReference
AtomicReference用来以原子方式更新引用类型,它有一个类型参数,使用时需要指定引用的类型。以下代码演示了其基本用法:
xxxxxxxxxx321public class AtomicReferenceDemo {2 // 引用类型3 static class Pair {4 final private int first;5 final private int second;6
7 public Pair(int first, int second) {8 this.first = first;9 this.second = second;10 }11
12 public int getFirst() {13 return first;14 }15
16 public int getSecond() {17 return second;18 }19 }20
21 public static void main(String[] args) {22 // 1. 创建引用类型23 Pair p = new Pair(100, 200);24 25 // 2. 创建原子引用类型26 AtomicReference<Pair> pairRef = new AtomicReference<>(p);27 28 // 3. CAS更新29 pairRef.compareAndSet(p, new Pair(200, 200));30 System.out.println(pairRef.get().getFirst());31 }32}
4) AtomicArray
原子数组方便以原子的方式更新数组中的每个元素,我们以AtomicIntegerArray为例来简要介绍下。
xxxxxxxxxx181// 1. 构造方法2public AtomicIntegerArray(int length) // 创建一个长度为length的空数组3public AtomicIntegerArray(int[] array) // 创建一个长度为array.length的空数组,并从array拷贝元素4
5// 2. 原子更新方法(大多带有数组索引参数)6public final boolean compareAndSet(int i, int expect, int update)7public final int getAndIncrement(int i)8public final int getAndAdd(int i, int delta)9 10// 示例111public class AtomicArrayDemo {12 public static void main(String[] args) {13 int[] arr = { 1, 2, 3, 4 };14 AtomicIntegerArray atomicArr = new AtomicIntegerArray(arr);15 atomicArr.compareAndSet(1, 2, 100); // 如果索引位置为1的元素值为2,则更新为10016 System.out.println(atomicArr.get(1)); // 10017 }18}
5) FieldUpdater
FieldUpdater方便以原子方式更新对象中的字段,字段不需要声明为原子变量,FieldUpdater是基于反射机制实现的,看代码:
xxxxxxxxxx401public class FieldUpdaterDemo {2 static class DemoObject {3 private volatile int num; // volatile4 private volatile Object ref; // volatile5
6 // DemoObject类num字段的原子更新器7 private static final AtomicIntegerFieldUpdater<DemoObject> numUpdater8 = AtomicIntegerFieldUpdater.newUpdater(DemoObject.class, "num");9 10 // DemoObject类ref字段的原子更新器11 private static final AtomicReferenceFieldUpdater<DemoObject, Object> refUpdater 12 = AtomicReferenceFieldUpdater.newUpdater(DemoObject.class, Object.class, "ref");13
14 // CAS更新num字段15 public boolean compareAndSetNum(int expect, int update) {16 return numUpdater.compareAndSet(this, expect, update);17 }18
19 public int getNum() {20 return num;21 }22
23 // CAS更新ref字段24 public Object compareAndSetRef(Object expect, Object update) {25 return refUpdater.compareAndSet(this, expect, update);26 }27
28 public Object getRef() {29 return ref;30 }31 }32
33 public static void main(String[] args) {34 DemoObject obj = new DemoObject();35 obj.compareAndSetNum(0, 100);36 obj.compareAndSetRef(null, new String("hello"));37 System.out.println(obj.getNum());38 System.out.println(obj.getRef());39 }40}
第二节 AQS工具
1. AQS
1) AQS简介
AbstractQueuedSynchronizer是Java提供的一个抽象类,它封装了CAS和LockSupport,简化了并发工具的实现。原理简述如下:
封装了一个锁状态(state),在 ReentrantLock 中表示重入次数,在 Semaphore 中,表示当前可用的许可数量等。
xxxxxxxxxx71// 锁状态2private volatile int state;34// 获取或设置状态5protected final int getState()6protected final void setState(int newState)7protected final boolean compareAndSetState(int expect, int update) // CAS设置保存了一个锁持有线程。
xxxxxxxxxx61// 锁的持有线程(独有模式)2private transient Thread exclusiveOwnerThread;34// 获取和设置持有线程5protected final void setExclusiveOwnerThread(Thread t)6protected final Thread getExclusiveOwnerThread()维护了一个锁等待队列(基于自旋锁的双向CHL队列),记录等待该资源的线程:
xxxxxxxxxx31// CHL队列头/尾节点2private transient volatile Node head;3private transient volatile Node tail;
维护了一个条件等待队列(单向队列),记录等待某个条件的线程,一般是通过await()方法进入,signal()方法退出。
xxxxxxxxxx11Node nextWaiter; // 条件节点(每个条件节点都有自己的单向链表维护等待的线程)定义了一套加锁/解锁的模板方法,不同锁类型对在加锁/解锁时,对锁状态、锁持有线程、锁等待队列的操作不同。
xxxxxxxxxx41tryAcquire(int arg) // 尝试以独占模式获取锁2tryRelease(int arg) // 尝试以独占模式释放锁3tryAcquireShared(int arg) // 尝试以共享模式获取锁4tryReleaseShared(int arg) // 尝试以共享模式释放锁
2) LockSupport
java.util.concurrent.locks.LockSupport是线程阻塞与唤醒的底层工具类,无需持有锁、唤醒精准、支持预存许可,解决了 Object.wait ()/notify () 的诸多限制,是 AQS、ReentrantLock 等同步工具的 “基石”。
xxxxxxxxxx291// 1. 搁置,可响应中断,中断时直接返回,并设置线程中断标志(和其它等待方法类似,需循环判断条件是否满足)2public static void park() // 放弃CPU,进入等待状态3public static void parkNanos(long nanos) // 搁置指定纳秒4public static void parkUntil(long deadline) // 搁置到指定时间(毫秒值)5 6// 2. 搁置,同时指定blocker对象,表示是因为该对象进行等待的,一般为this,可用于调试等7public static void park(Object blocker)8public static void parkNanos(Object blocker, long nanos)9public static void parkUntil(Object blocker, long deadline)10public static Object getBlocker(Thread t) // 返回一个线程的blocker对象11 12// 3. 解除搁置13public static void unpark(Thread thread) // 使指定线程恢复可运行状态14 15// 示例1:16public static void main(String[] args) throws InterruptedException {17 // 子线程18 Thread t = new Thread (){19 public void run(){20 LockSupport.park(); // 搁置21 System.out.println("exit");22 }23 };24 t.start(); 25 26 // 主线程27 Thread.sleep(1000);28 LockSupport.unpark(t); // 解除搁置29}注意:
- 与CAS方法类似,park/unpark也是通过
Unsafe类间接调用操作系统API来实现的。
2. 可重入锁(ReentrantLock)
1) Lock接口
java.util.concurrent.locks.Lock是显式锁的顶层接口,定义了锁的获取、释放、中断等核心操作。
xxxxxxxxxx151public interface Lock {2 // 加锁3 void lock(); // 阻塞直到加锁成功4 void lockInterruptibly() throws InterruptedException; // 可响应中断的加锁5 6 // 尝试获取锁7 boolean tryLock(); // 不阻塞,立即返回,如果获取成功,则返回true,否则返回false8 boolean tryLock(long time, TimeUnit unit) throws InterruptedException; // 限时尝试获取锁,可响应中断9 10 // 解锁11 void unlock();12 13 // 新建条件,一个Lock可以关联多个条件14 Condition newCondition(); // 关于条件,我们留待下节介绍15}注意:
- 相比于synchronized关键字,显式锁支持中断响应、超时唤醒、尝试获取、公平锁等,使用时更加灵活。
2) 基本使用
ReentrantLock是显示锁接口的主要实现类,常用方法如下:
xxxxxxxxxx171// 构造方法2public ReentrantLock()3public ReentrantLock(boolean fair) // fair-是否公平(时间优先),默认为false。4
5// 锁持有情况6public boolean isLocked() // 是否被某个线程持有7public boolean isHeldByCurrentThread() // 是否被当前线程持有8public int getHoldCount() // 锁被当前线程持有的数量,0表示不被当前线程持有9
10// 锁等待情况11public final boolean hasQueuedThreads() // 是否有线程在等待该锁12public final boolean hasQueuedThread(Thread thread) // 指定的线程thread是否在等待该锁13public final int getQueueLength() // 在等待该锁的线程个数14 15// 锁等待策略16public final boolean isFair() // 是否公平17
使用示例如下:
xxxxxxxxxx181// 示例1:2public class Counter {3 private final Lock lock = new ReentrantLock(); // 可重入锁4 private volatile int count; // 计数器,加volatile保证共享内存的可见性5
6 public void incr() {7 lock.lock(); // 加锁8 try {9 count++;10 } finally {11 lock.unlock(); // finally中释放锁12 }13 }14
15 public int getCount() {16 return count;17 }18}注意:
- 在获取多个锁时,如果无法确定以相同的顺序获取,则可通过tryLock尝试,如果获取不到则释放已持有的锁,避免死锁。
3) lock方法实现
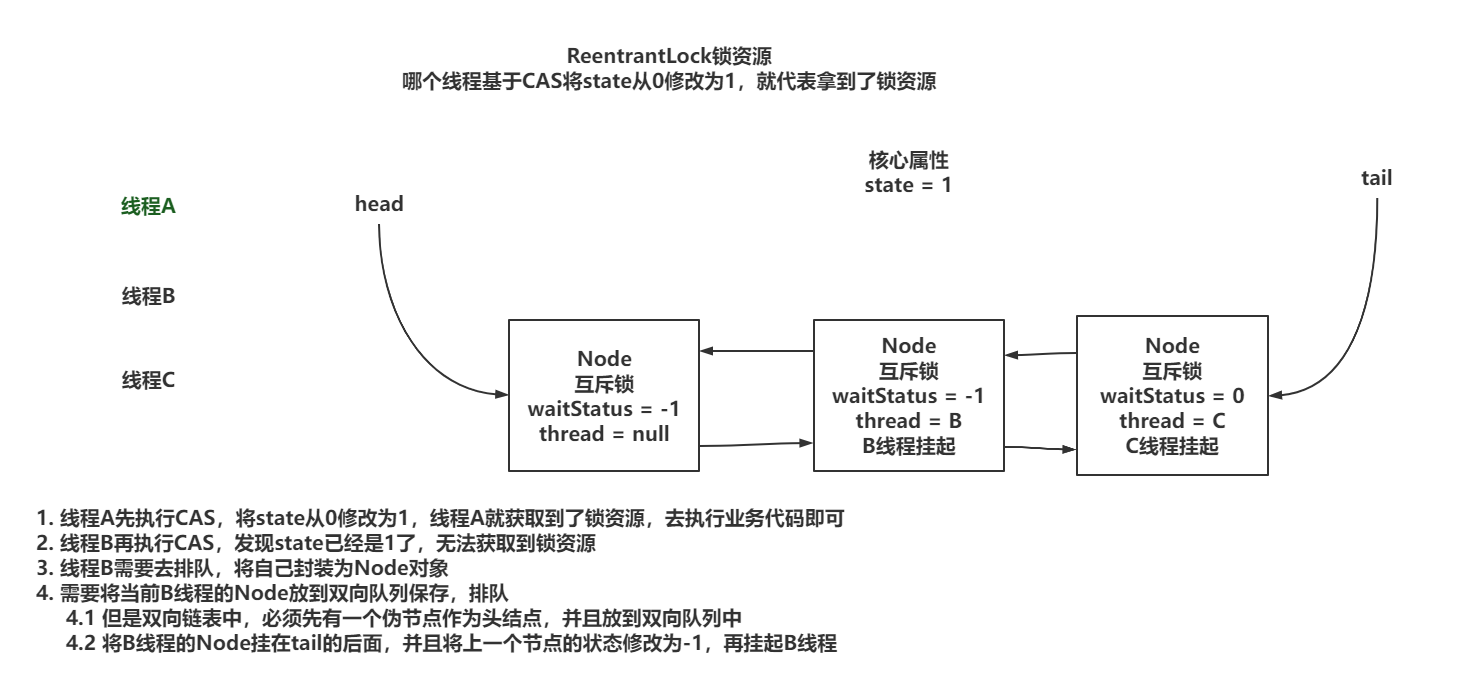
我们先来看下ReentrantLock的lock方法,整体流程图如下:
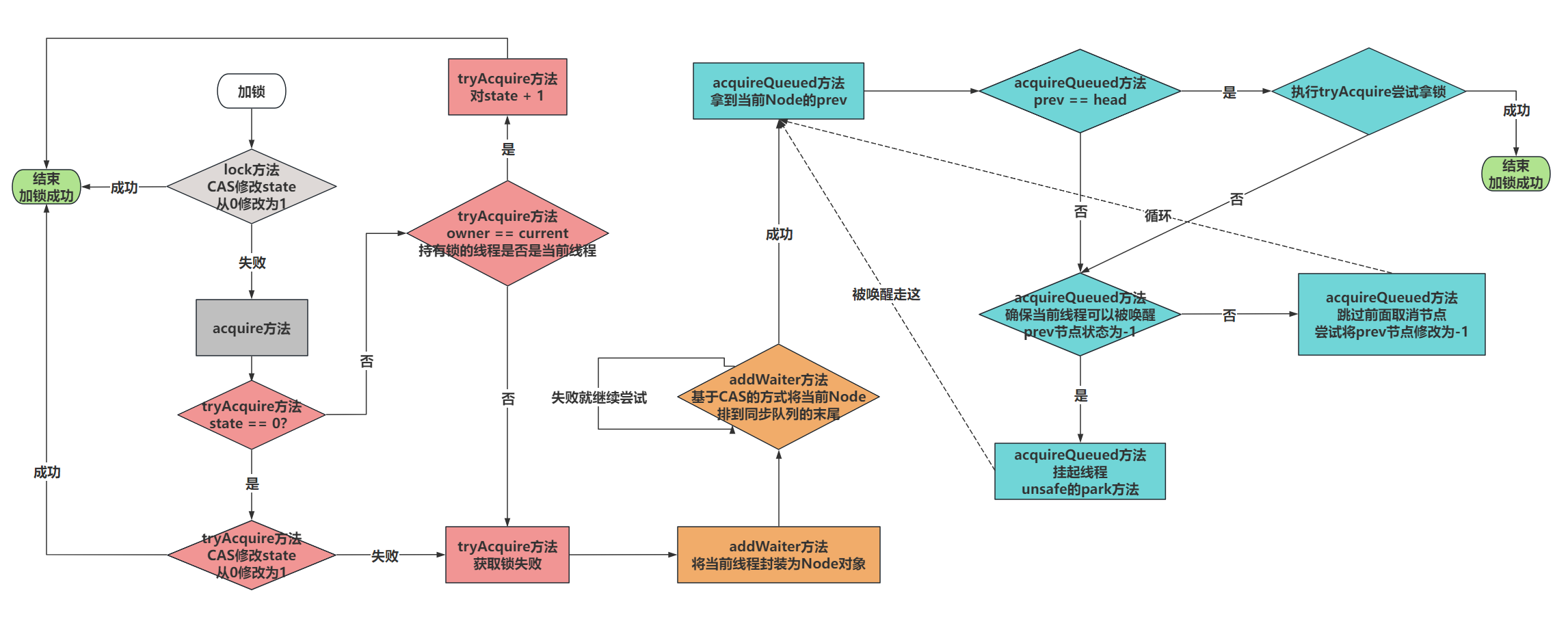
xxxxxxxxxx231// =>ReentrantLock.lock2public void lock() {3 // 直接调用了Sync的lock4 // Sync是内部定义的继承自AQS的抽象类,它有两个实现类NonfairSync(默认)和FairSync。5 sync.lock(); 6}7
8// =>NonfairSync.lock9final void lock() {10 // 判断是否被加过锁(使用state表示锁持有数量),如果未被锁定,则直接加锁11 if (compareAndSetState(0, 1))12 setExclusiveOwnerThread(Thread.currentThread()); // 设置锁持有线程为当前线程13 else14 acquire(1); // 询问锁15}16
17// =>AQS.acquire18public final void acquire(int arg) {19 // 尝试获取锁,获取不到则加入等待队列20 if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))21 selfInterrupt(); // 如果acquireQueued发生过中断,则设置当前线程的中断标志22}23
其中尝试获取锁的方法 tryAcquire 必须被子类重写,NonfairSync的实现如下:
xxxxxxxxxx291// =>NonfairSync.tryAcquire2protected final boolean tryAcquire(int acquires) {3 return nonfairTryAcquire(acquires);4}5
6// =>nonfairTryAcquire是Sync中实现的7final boolean nonfairTryAcquire(int acquires) {8 final Thread current = Thread.currentThread();9 int c = getState();10 if (c == 0) {11 // a) 如果未被锁定,则使用CAS进行锁定12 // 注意:如果是FairSync,这里会多一个!hasQueuedPredecessors()检查13 // 表示不存在其他等待时间更长的线程,它才会尝试获取锁14 if (compareAndSetState(0, acquires)) {15 setExclusiveOwnerThread(current);16 return true;17 }18 }19 else if (current == getExclusiveOwnerThread()) {20 // b) 如果已被当前线程锁定,则增加锁定次数21 int nextc = c + acquires;22 if (nextc < 0) // overflow23 throw new Error("Maximum lock count exceeded");24 setState(nextc);25 return true;26 }27 return false;28}29
如果 tryAcquire 返回false,即被其它线程锁定,则AQS会调用acquireQueued(addWaiter(Node.EXCLUSIVE), arg),其中addWaiter会新建一个节点Node,代表当前线程,然后加入到内部的锁等待队列中。
xxxxxxxxxx181private Node addWaiter(Node mode) {2 // 封装Node3 Node node = new Node(Thread.currentThread(), mode);4 5 // CAS放到锁等待队列的末尾6 Node pred = tail;7 if (pred != null) {8 node.prev = pred;9 if (compareAndSetTail(pred, node)) {10 pred.next = node;11 return node;12 }13 }14 15 // 多次循环CAS保证设置到锁等待队列的末尾16 enq(node);17 return node;18}放入锁等待队列中后,再调用acquireQueued尝试获得锁,代码为:
xxxxxxxxxx541// => AQS.acquireQueued2final boolean acquireQueued(final Node node, int arg) {3 boolean failed = true;4 try {5 boolean interrupted = false;6 7 // 1. 主体是一个死循环8 for (;;) {9 // 2. 检查当前节点是不是第一个等待的节点10 final Node p = node.predecessor(); // 获取前1个节点11 if (p == head && tryAcquire(arg)) {12 // 2.1 如果是,且能获取到锁,则将当前节点从等待队列中移除并返回13 setHead(node);14 p.next = null; // help GC15 failed = false;16 return interrupted;17 }18 19 // 2.2 否则最终调用LockSupport.park放弃CPU,进入等待20 if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())21 // 3. 被唤醒后,检查是否发生了中断,记录中断标志,后重新开始循环22 interrupted = true;23 }24 } finally {25 if (failed)26 cancelAcquire(node);27 }28}29
30// 设置唤醒信号31private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {32 // 获取前1个节点等待状态33 int ws = pred.waitStatus;34 if (ws == Node.SIGNAL)35 // 为 -1 直接返回36 return true;37 if (ws > 0) {38 // 大于0时,表示前1个节点已取消等待,则获取前前1个节点,直到不大于0为止39 do {40 node.prev = pred = pred.prev;41 } while (pred.waitStatus > 0);42 pred.next = node;43 } else {44 // CAS设置前1个节点等待状态为-145 compareAndSetWaitStatus(pred, ws, Node.SIGNAL);46 }47 return false;48}49
50// 等待51private final boolean parkAndCheckInterrupt() {52 LockSupport.park(this); // 放弃CPU,进入等待53 return Thread.interrupted(); // 获取线程中断标志54}以上就是lock方法的基本过程,能获得锁就立即获得,否则加入等待队列,被唤醒后检查自己是否是第一个等待的线程,如果是且能获得锁,则返回,否则继续等待,这个过程中如果发生了中断,lock会记录中断标志位,但不会提前返回或抛出异常。
4) tryLock方法实现
xxxxxxxxxx261// tryLock方法,无论公平锁还有非公平锁。都会走非公平锁抢占锁资源的操作2// 就是拿到state的值, 如果是0,直接CAS浅尝一下3// state 不是0,那就看下是不是锁重入操作4// 如果没抢到,或者不是锁重入操作,告辞,返回false5public boolean tryLock() {6 // 非公平锁的竞争锁操作7 return sync.nonfairTryAcquire(1);8}9final boolean nonfairTryAcquire(int acquires) {10 final Thread current = Thread.currentThread();11 int c = getState();12 if (c == 0) {13 if (compareAndSetState(0, acquires)) {14 setExclusiveOwnerThread(current);15 return true;16 }17 }18 else if (current == getExclusiveOwnerThread()) {19 int nextc = c + acquires;20 if (nextc < 0) // overflow21 throw new Error("Maximum lock count exceeded");22 setState(nextc);23 return true;24 }25 return false;26}
5) tryLock(time,unit)方法实现
xxxxxxxxxx531// tryLock(time,unit)执行的方法2public final boolean tryAcquireNanos(int arg, long nanosTimeout)throws InterruptedException {3 // 线程的中断标记位,是不是从false,别改为了true,如果是,直接抛异常4 if (Thread.interrupted())5 throw new InterruptedException();6 // tryAcquire分为公平和非公平锁两种执行方式,如果拿锁成功, 直接告辞,7 return tryAcquire(arg) ||8 // 如果拿锁失败,在这要等待指定时间9 doAcquireNanos(arg, nanosTimeout);10}11
12private boolean doAcquireNanos(int arg, long nanosTimeout)13 throws InterruptedException {14 // 如果等待时间是0秒,直接告辞,拿锁失败 15 if (nanosTimeout <= 0L)16 return false;17 // 设置结束时间。18 final long deadline = System.nanoTime() + nanosTimeout;19 // 先扔到AQS队列20 final Node node = addWaiter(Node.EXCLUSIVE);21 // 拿锁失败,默认true22 boolean failed = true;23 try {24 for (;;) {25 // 如果在AQS中,当前node是head的next,直接抢锁26 final Node p = node.predecessor();27 if (p == head && tryAcquire(arg)) {28 setHead(node);29 p.next = null; // help GC30 failed = false;31 return true;32 }33 // 结算剩余的可用时间34 nanosTimeout = deadline - System.nanoTime();35 // 判断是否是否用尽的位置36 if (nanosTimeout <= 0L)37 return false;38 // shouldParkAfterFailedAcquire:根据上一个节点来确定现在是否可以挂起线程39 if (shouldParkAfterFailedAcquire(p, node) &&40 // 避免剩余时间太少,如果剩余时间少就不用挂起线程41 nanosTimeout > spinForTimeoutThreshold)42 // 如果剩余时间足够,将线程挂起剩余时间43 LockSupport.parkNanos(this, nanosTimeout);44 // 如果线程醒了,查看是中断唤醒的,还是时间到了唤醒的。45 if (Thread.interrupted())46 // 是中断唤醒的!47 throw new InterruptedException();48 }49 } finally {50 if (failed)51 cancelAcquire(node);52 }53}
6) cancelAcquire方法实现
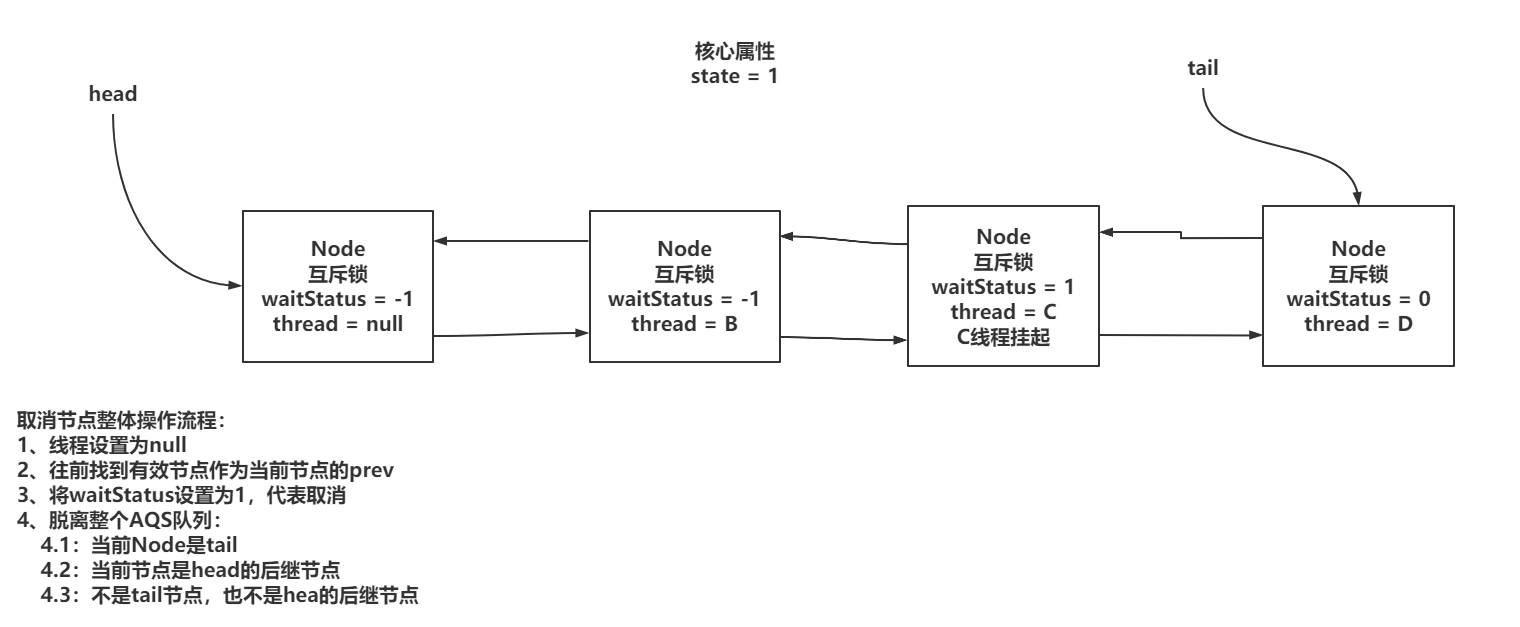
xxxxxxxxxx441// 取消在AQS中排队的Node2private void cancelAcquire(Node node) {3 // 如果当前节点为null,直接忽略。4 if (node == null)5 return;6 //1. 线程设置为null7 node.thread = null;8
9 //2. 往前跳过被取消的节点,找到一个有效节点10 Node pred = node.prev;11 while (pred.waitStatus > 0)12 node.prev = pred = pred.prev;13
14 //3. 拿到了上一个节点之前的next15 Node predNext = pred.next;16
17 //4. 当前节点状态设置为1,代表节点取消18 node.waitStatus = Node.CANCELLED;19
20 // 脱离AQS队列的操作21 // 当前Node是尾结点,将tail从当前节点替换为上一个节点22 if (node == tail && compareAndSetTail(node, pred)) {23 compareAndSetNext(pred, predNext, null);24 } else {25 // 到这,上面的操作CAS操作失败26 int ws = pred.waitStatus;27 // 不是head的后继节点28 if (pred != head &&29 // 拿到上一个节点的状态,只要上一个节点的状态不是取消状态,就改为-130 (ws == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) 31 && pred.thread != null) {32 // 上面的判断都是为了避免后面节点无法被唤醒。33 // 前继节点是有效节点,可以唤醒后面的节点34 Node next = node.next;35 if (next != null && next.waitStatus <= 0)36 compareAndSetNext(pred, predNext, next);37 } else {38 // 当前节点是head的后继节点39 unparkSuccessor(node);40 }41
42 node.next = node; // help GC43 }44}
7) lockInterruptibly方法实现
xxxxxxxxxx301// 这个是lockInterruptibly和tryLock(time,unit)唯一的区别2// lockInterruptibly,拿不到锁资源,就死等,等到锁资源释放后,被唤醒,或者是被中断唤醒3private void doAcquireInterruptibly(int arg) throws InterruptedException {4 final Node node = addWaiter(Node.EXCLUSIVE);5 boolean failed = true;6 try {7 for (;;) {8 final Node p = node.predecessor();9 if (p == head && tryAcquire(arg)) {10 setHead(node);11 p.next = null; // help GC12 failed = false;13 return;14 }15 if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())16 // 中断唤醒抛异常!17 throw new InterruptedException();18 }19 } finally {20 if (failed)21 cancelAcquire(node);22 }23}24
25private final boolean parkAndCheckInterrupt() {26 LockSupport.park(this);27 // 这个方法可以确认,当前挂起的线程,是被中断唤醒的,还是被正常唤醒的。28 // 中断唤醒,返回true,如果是正常唤醒,返回false29 return Thread.interrupted();30}
8) unlock方法实现
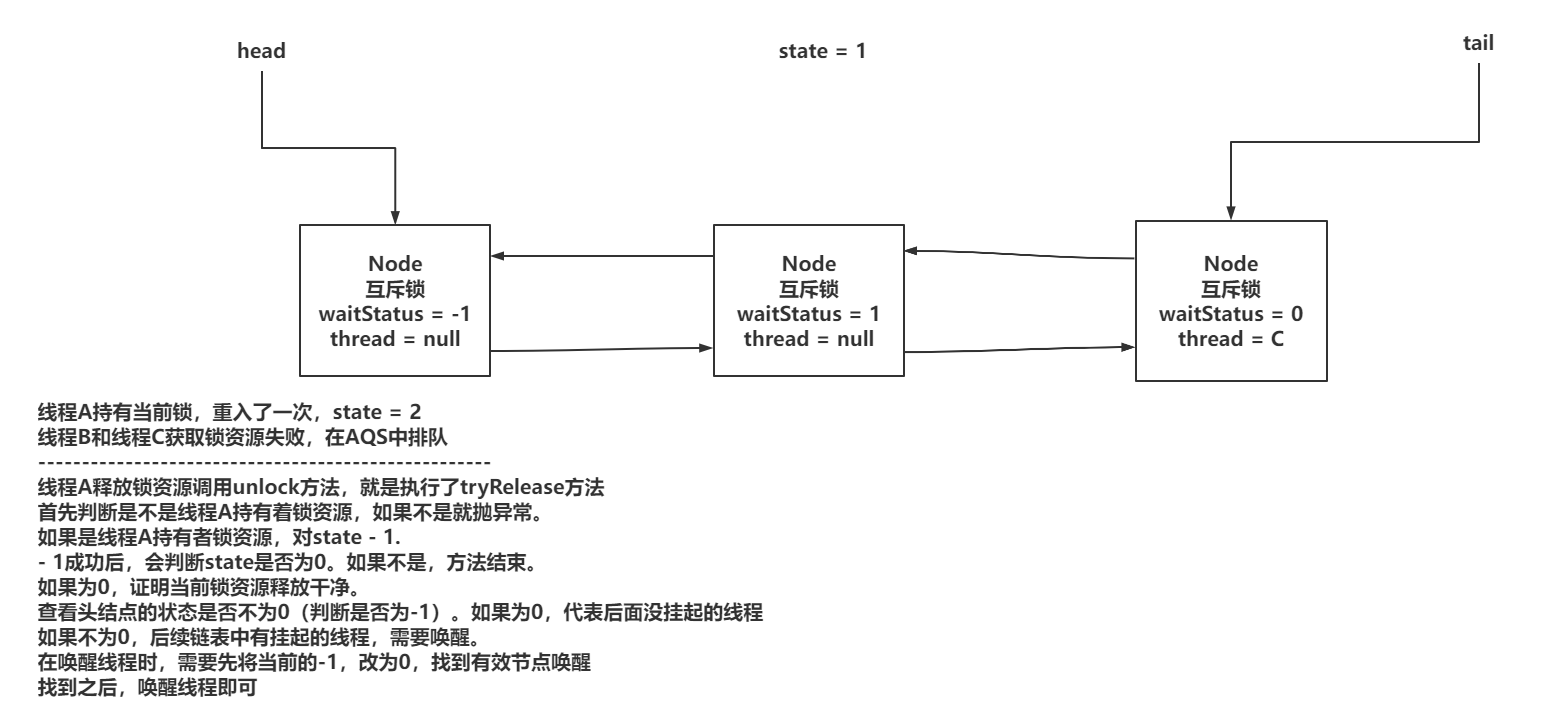
下面是ReentrantLock的unlock方法的实现代码,整理流程图如下:
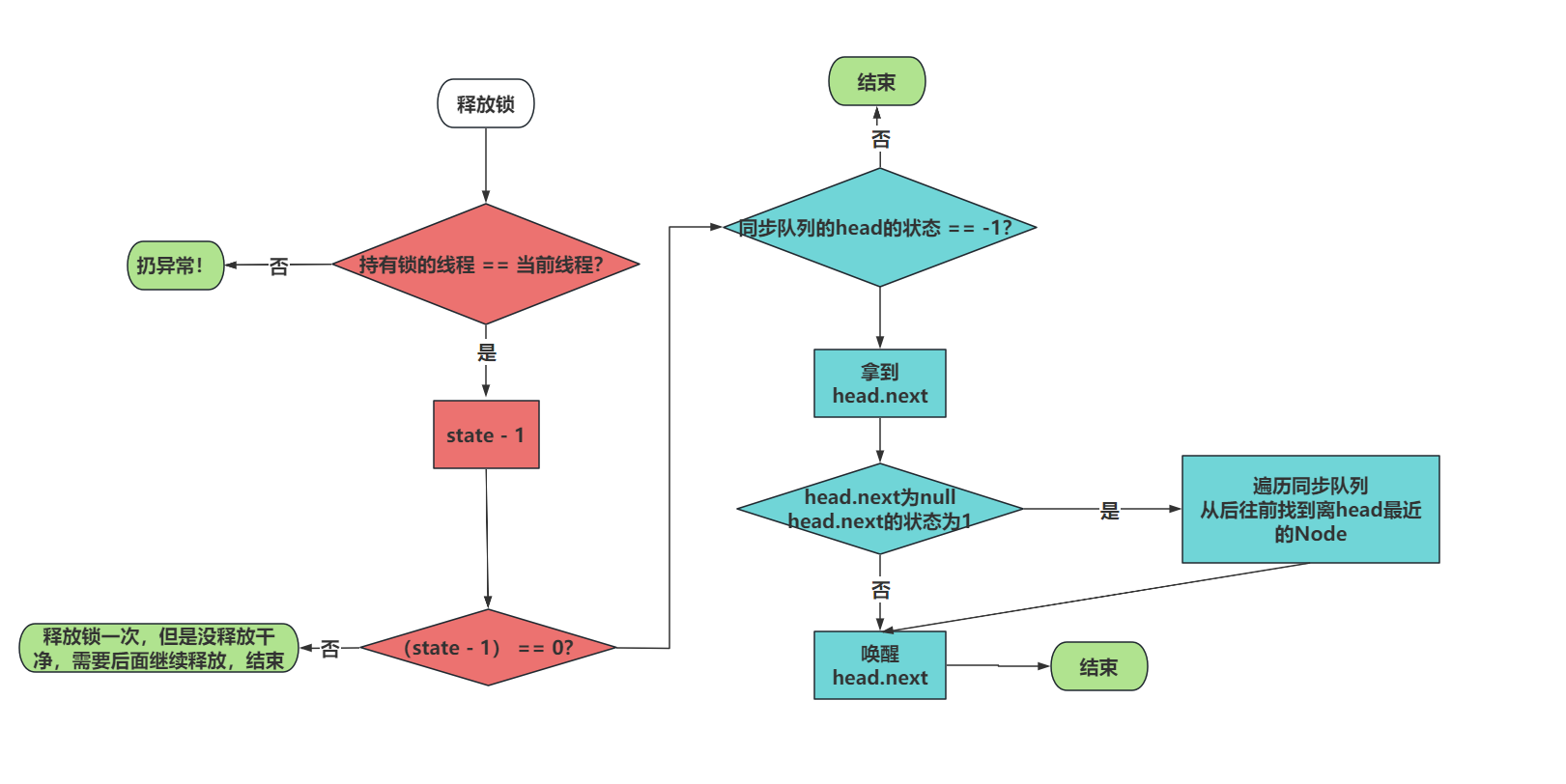
xxxxxxxxxx621// =>ReentrantLock.unlock2public void unlock() {3 sync.release(1);4}5
6// =>AQS.release7public final boolean release(int arg) {8 // 1. 修改状态释放锁9 if (tryRelease(arg)) {10 Node h = head;11 if (h != null && h.waitStatus != 0)12 unparkSuccessor(h); // 2. 调用LockSupport.unpark将第一个等待的线程唤醒13 return true;14 }15 return false;16}17
18// ReentrantLock 尝试释放锁19protected final boolean tryRelease(int releases) {20 // state -121 int c = getState() - releases;22 23 // 检查是否为当前持有线程24 if (Thread.currentThread() != getExclusiveOwnerThread())25 throw new IllegalMonitorStateException();26 27 // 重入次数是否归028 boolean free = false;29 if (c == 0) {30 // 是,则释放锁,设置持有线程为null31 free = true;32 setExclusiveOwnerThread(null);33 }34 35 // 更新state36 setState(c);37 return free;38}39
40// 唤醒下1个等待的节点41private void unparkSuccessor(Node node) {42 // 当前节点等待状态43 int ws = node.waitStatus;44 45 // 重置等待状态为046 if (ws < 0)47 compareAndSetWaitStatus(node, ws, 0);48
49 // 从后往前找到离head最近的正常节点50 // 为什么从后往前找?因为节点取消后会把next指向自己,会造成死循环51 Node s = node.next;52 if (s == null || s.waitStatus > 0) {53 s = null;54 for (Node t = tail; t != null && t != node; t = t.prev)55 if (t.waitStatus <= 0) // 判断节点等待状态是否正常56 s = t;57 }58 59 // 唤醒该节点60 if (s != null)61 LockSupport.unpark(s.thread);62}
3. 条件变量(ConditionObject)
1) ConditionObject简介
显式条件是基于显式锁的 await/signal 线程协作机制,它们之间的关系类似于 synchronized 与 wait/notify 协作机制的关系。
创建显式条件需要通过显式锁,Lock接口定义了创建方法:
xxxxxxxxxx11Condition newCondition();其中Condition为显式条件的接口,它的定义为:
xxxxxxxxxx141public interface Condition {2 // 1. 可中断等待(如果发生了中断,会抛出InterruptedException,但中断标志位会被清空)3 void await() throws InterruptedException; // 无限期等待,对应wait()4 long awaitNanos(long nanosTimeout) throws InterruptedException; // 超时等待,单位为纳秒,返回值为 nanosTimeout - 实际等待的时间5 boolean await(long time, TimeUnit unit) throws InterruptedException; // 超时等待,可指定单位,如果由于等待超时返回,返回值为false,否则为true6 boolean awaitUntil(Date deadline) throws InterruptedException; // 超时等待,参数为截至时间戳,如果由于等待超时返回,返回值为false,否则为true7 8 // 2. 不可中断等待(不会由于中断结束,但当它返回时,如果等待过程中发生了中断,中断标志位会被设置)9 void awaitUninterruptibly();10 11 // 3. 通知12 void signal(); // 对应notify13 void signalAll(); // 对应notifyAll()14}与wait/notify协作机制类似,await()/signal()也具有如下一些特性:
- 调用await()/signal()等方法前必须先获取显式锁,否则会抛出异常IllegalMonitorStateException。
- await在进入等待队列后,会释放锁,释放CPU,当其他线程将它唤醒后,或等待超时后,或发生中断异常后,它都需要重新获取锁,获取锁后,才会从await方法中退出。
- await返回后,不代表其等待的条件就一定满足了,通常要将await的调用放到一个循环内,只有条件满足后才退出。
2) 使用示例(生产者/消费者模型)
生产者/消费者模式存在一个与队列满有关的条件,还存在一个与队列空有关的条件,而在前面通过wait/notify机制实现时,不得不共用同一个条件队列,而使用显式锁,则可以分别创建对应的条件队列。
xxxxxxxxxx401static class MyBlockingQueue<E> {2 private Queue<E> queue = null; // 队列3 private int limit; // 队列上限4 private Lock lock = new ReentrantLock(); // 可重入锁5 private Condition notFull = lock.newCondition(); // lock条件01:队列非满6 private Condition notEmpty = lock.newCondition(); // lock条件02:队列非空7
8
9 public MyBlockingQueue(int limit) {10 this.limit = limit;11 queue = new ArrayDeque<>(limit);12 }13
14 public void put(E e) throws InterruptedException {15 lock.lockInterruptibly(); // 加锁16 try{17 while (queue.size() == limit) {18 notFull.await(); // 队列已满,在notFull条件等待19 }20 queue.add(e);21 notEmpty.signal(); // 队列非空,通知notEmpty条件22 }finally{23 lock.unlock(); // 解锁24 }25 }26
27 public E take() throws InterruptedException {28 lock.lockInterruptibly(); // 加锁29 try{30 while (queue.isEmpty()) {31 notEmpty.await(); // 队列是空的,在notEmpty条件等待32 }33 E e = queue.poll();34 notFull.signal(); // 队列非满,通知notFull条件35 return e; 36 }finally{37 lock.unlock // 解锁38 }39 }40}这样,代码更为清晰易读,同时避免了不必要的唤醒和检查,提高了效率。
3) await方法实现
ConditionObject是AQS中定义的一个成员内部类,它可以直接访问AQS中的数据,比如AQS中定义的锁等待队列。它通过显式锁创建:
xxxxxxxxxx91// => ReentrantLock.newCondition2public Condition newCondition() {3 return sync.newCondition();4}5
6// => Sync.newCondition7final ConditionObject newCondition() {8 return new ConditionObject();9}它内部也有一个条件等待队列,其成员声明为:
xxxxxxxxxx21private transient Node firstWaiter; // 条件队列的头节点2private transient Node lastWaiter; // 条件队列的尾节点await方法实现分析如下:
xxxxxxxxxx801public final void await() throws InterruptedException {2 // 如果等待前中断标志位已被设置,直接抛异常3 if (Thread.interrupted()) throw new InterruptedException();4 5 // 1.为当前线程创建节点,加入条件等待队列6 Node node = addConditionWaiter();7 8 // 2.释放持有的锁9 int savedState = fullyRelease(node);10 int interruptMode = 0;11 12 // 3.放弃CPU,进行等待,直到被中断或isOnSyncQueue变为true13 // isOnSyncQueue为true表示节点被其他线程从条件等待队列移到了外部的锁等待队列,等待的条件已满足14 while (!isOnSyncQueue(node)) {15 LockSupport.park(this);16 17 // 检查是否被唤醒:18 // ①被signl唤醒 19 // ②被Interrupt唤醒(-1),一定在AQS队列20 // ③先被signl唤醒再被中断(1),一定在AQS队列21 if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)22 break;23 }24 25 // 4.重新获取锁26 if (acquireQueued(node, savedState) && interruptMode != THROW_IE)27 // 如果线程在AQS队列排队时,被中断了,并且不是THROW_IE状态,确保线程的interruptMode是REINTERRUPT28 interruptMode = REINTERRUPT;29 if (node.nextWaiter != null) // clean up if cancelled30 unlinkCancelledWaiters(); // 脱离条件等待队列31 32 // 5.处理中断,抛出异常(中断唤醒)或设置中断标志位(先signl唤醒后被中断)33 if (interruptMode != 0)34 reportInterruptAfterWait(interruptMode);35}36
37// 确认Node是否在AQS队列上38final boolean isOnSyncQueue(Node node) {39 // 如果线程状态为-2,肯定没在AQS队列40 // 如果prev节点的值为null,肯定没在AQS队列41 if (node.waitStatus == Node.CONDITION || node.prev == null)42 // 返回false43 return false;44 // 如果节点的next不为null。说明已经在AQS队列上。、45 if (node.next != null) 46 // 确定AQS队列上有!47 return true;48 // 如果上述判断都没有确认节点在AQS队列上,在AQS队列中寻找一波49 return findNodeFromTail(node);50}51
52// 判断线程到底是中断唤醒的,还是signal唤醒的!53final boolean transferAfterCancelledWait(Node node) {54 // 基于CAS将Node的状态从-2改为055 if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {56 // 说明是中断唤醒的线程。因为CAS成功了。57 // 将Node添加到AQS队列中~(如果是中断唤醒的,当前线程同时存在Condition的单向链表以及AQS的队列中)58 enq(node);59 // 返回true60 return true;61 }62 // 判断当前的Node是否在AQS队列(signal唤醒的,但是可能线程还没放到AQS队列)63 // 等到signal方法将线程的Node扔到AQS队列后,再做后续操作64 while (!isOnSyncQueue(node))65 // 如果没在AQS队列上,那就线程让步,稍等一会,Node放到AQS队列再处理(看CPU)66 Thread.yield();67 // signal唤醒的,返回false68 return false;69}70
71private void reportInterruptAfterWait(int interruptMode) throws InterruptedException {72 // 如果是中断唤醒的await,直接抛出异常!73 if (interruptMode == THROW_IE)74 throw new InterruptedException();75 // 如果是REINTERRUPT,signal后被中断过76 else if (interruptMode == REINTERRUPT)77 // 确认线程的中断标记位是true78 // Thread.currentThread().interrupt();79 selfInterrupt();80}
4) awaitNanos实现分析
awaitNanos与await的实现是基本类似的,区别主要是会限定等待的时间,如下所示:
xxxxxxxxxx381public final long awaitNanos(long nanosTimeout) throws InterruptedException {2 if (Thread.interrupted()) throw new InterruptedException();3 4 Node node = addConditionWaiter();5 6 int savedState = fullyRelease(node);7 long lastTime = System.nanoTime();8 int interruptMode = 0;9 10 while (!isOnSyncQueue(node)) {11 if (nanosTimeout <= 0L) {12 // 等待超时,将节点从条件等待队列移到外部的锁等待队列13 transferAfterCancelledWait(node);14 break;15 }16 17 // 限定等待的最长时间18 LockSupport.parkNanos(this, nanosTimeout);19 if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)20 break;21
22 23 // 计算下次等待的最长时间24 long now = System.nanoTime();25 nanosTimeout -= now - lastTime;26 lastTime = now;27 }28 29 if (acquireQueued(node, savedState) && interruptMode != THROW_IE)30 interruptMode = REINTERRUPT;31 if (node.nextWaiter != null)32 unlinkCancelledWaiters();33 34 if (interruptMode != 0)35 reportInterruptAfterWait(interruptMode);36 37 return nanosTimeout - (System.nanoTime() - lastTime);38}
5) signal实现分析
xxxxxxxxxx601public final void signal() {2 // 验证当前线程持有锁3 if (!isHeldExclusively()) throw new IllegalMonitorStateException();4 5 // 调用doSignal唤醒条件等待队列中第1个线程6 Node first = firstWaiter;7 if (first != null)8 doSignal(first); // 将节点从条件等待队列移到锁等待队列,调用LockSupport.unpark将线程唤醒9}10
11// 唤醒条件等待队列中的第1个线程12private void doSignal(Node first) {13 do {14 // 将第2个节点设置为首节点15 if ( (firstWaiter = first.nextWaiter) == null)16 lastWaiter = null; // 表示没有第2个节点17 first.nextWaiter = null;18 19 // 唤醒,如果transferForSignal返回true,一切正常,退出while循环20 } while (!transferForSignal(first) &&21 // 否则,找下一个节点尝试唤醒22 (first = firstWaiter) != null);23}24
25// 唤醒指定线程26final boolean transferForSignal(Node node) {27 // 等待状态变更 -2(等待条件) -> 0(默认)28 if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))29 return false;30
31 // 将当前节点移到AQS锁等待队列32 Node p = enq(node);33
34 // 如果ws > 0 ,说明这个Node已经被取消了;如果ws状态不是取消,将prev节点的状态改为-135 int ws = p.waitStatus;36 if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))37 // 如果prev节点已经取消了,可能会导致当前节点永远无法被唤醒。立即唤醒当前节点,基于acquireQueued方法,38 // 让当前节点找到一个正常的prev节点,并挂起线程39 // 如果prev节点正常,但是CAS修改prev节点失败了。证明prev节点因为并发原因导致状态改变。还是为了避免当前40 // 节点无法被正常唤醒,提前唤醒当前线程,基于acquireQueued方法,让当前节点找到一个正常的prev节点,并挂起线程41 LockSupport.unpark(node.thread);42 return true;43}44
45// 入AQS队列46private Node enq(final Node node) {47 for (;;) {48 Node t = tail;49 if (t == null) { // Must initialize50 if (compareAndSetHead(new Node()))51 tail = head;52 } else {53 node.prev = t;54 if (compareAndSetTail(t, node)) {55 t.next = node;56 return t;57 }58 }59 }60}
4. 读写锁(ReentrantReadWriteLock)
1) ReentrantReadWriteLock简介
在Java并发包中,接口ReadWriteLock表示读写锁,主要实现类是可重入读写锁ReentrantReadWriteLock。
- 读写锁的特性为读写互斥,读读并发,在读多写少的场景下,可以明显提高性能。
- 同一个线程,在获取写锁后可以再获取读锁,但在获取读锁后,不能升级为写锁。
xxxxxxxxxx91// 读写锁接口2public interface ReadWriteLock {3 Lock readLock(); // 读操作使用读锁,多个读线程可以并行4 Lock writeLock(); // 写操作使用写锁,写锁是独占的5}6
7// 可重入读写锁8public ReentrantLock()9public ReentrantLock(boolean fair) // fair-是否公平,默认为falseReentrantReadWriteLock也是基于AQS实现的,也是对state进行操作,拿到锁资源就去干活,如果没有拿到,就去AQS队列中排队。
- 等待线程与锁状态:读写锁内部有一个等待队列存放等待的线程,有一个整数变量表示锁的状态,读锁和写锁各用16位表示。
- 获取写锁:必须确保当前没有其他线程持有任何锁,否则就等待。
- 释放写锁:会将等待队列中的第一个线程唤醒,唤醒的可能是等待读锁的,也可能是等待写锁的。
- 获取读锁:只要写锁没有被其它线程持有,就可以获取成功。此外,在获取到读锁后,它会检查等待队列,逐个唤醒最前面的等待读锁的线程,直到第一个等待写锁的线程为止(之后的读锁不能释放,否则会造成写锁饥饿问题)。
- 释放读锁:检查读锁和写锁数是否都变为了0,如果是,则会唤醒等待队列中的下一个线程。
2) 应用示例
xxxxxxxxxx341// 使用ReentrantReadWriteLock实现一个缓存类MyCache2public class MyCache {3 private Map<String, Object> map = new HashMap<>();4 private ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock(); // 读写锁5 private Lock readLock = readWriteLock.readLock(); // 读锁6 private Lock writeLock = readWriteLock.writeLock(); // 写锁7
8 public Object get(String key) {9 readLock.lock(); // 读前加读锁10 try {11 return map.get(key);12 } finally {13 readLock.unlock(); // 读完释放读锁14 }15 }16
17 public Object put(String key, Object value) {18 writeLock.lock(); // 写前加写锁19 try {20 return map.put(key, value);21 } finally {22 writeLock.unlock(); // 写后释放写锁23 }24 }25
26 public void clear() {27 writeLock.lock(); // 写前加写锁28 try {29 map.clear();30 } finally {31 writeLock.unlock(); // 写后释放写锁32 }33 }34}
3) 写锁加锁源码
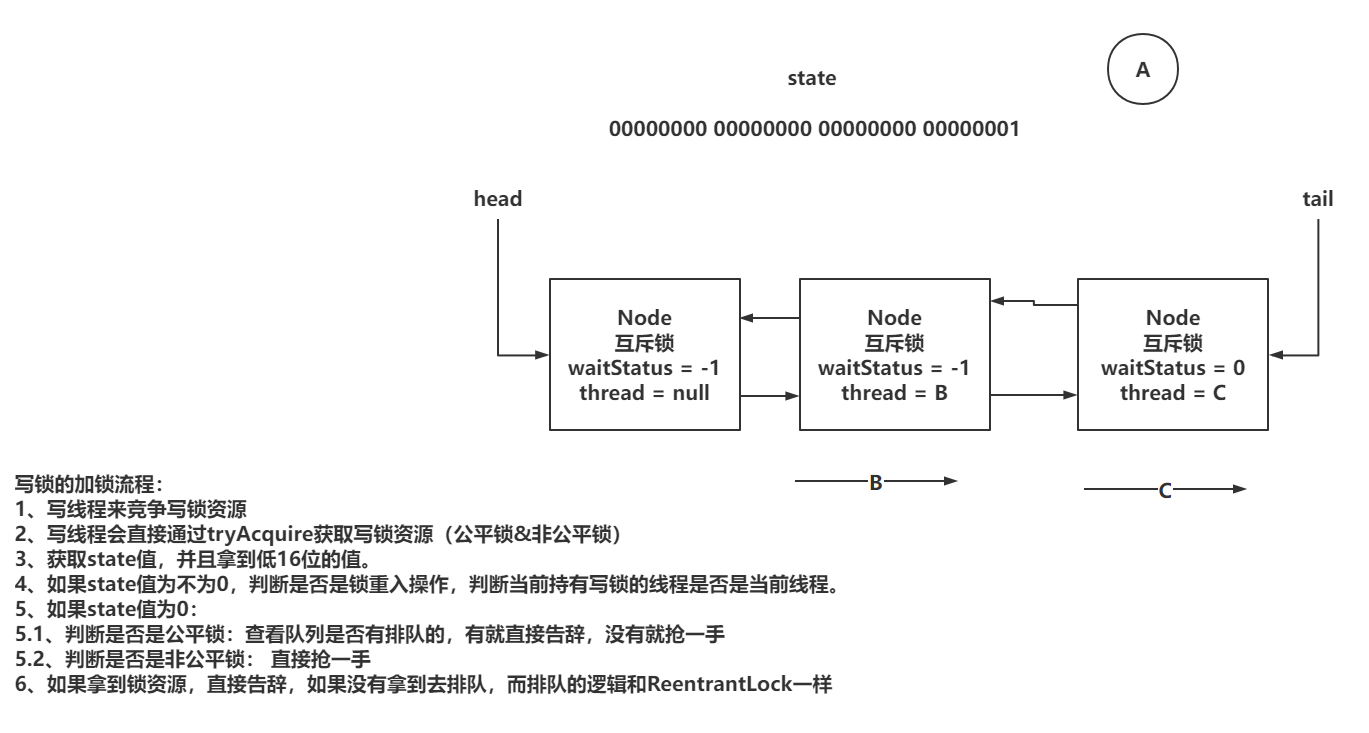
xxxxxxxxxx561// 写锁加锁的入口2public void lock() {3 sync.acquire(1);4}5
6// 阿巴阿巴!!7public final void acquire(int arg) {8 if (!tryAcquire(arg) &&9 acquireQueued(addWaiter(Node.EXCLUSIVE), arg))10 selfInterrupt();11}12
13// 读写锁的写锁实现tryAcquire14protected final boolean tryAcquire(int acquires) {15 // 拿到当前线程16 Thread current = Thread.currentThread();17 // 拿到state的值18 int c = getState();19 // 得到state低16位的值20 int w = exclusiveCount(c);21 // 判断是否有线程持有着锁资源22 if (c != 0) {23 // 当前没有线程持有写锁,读写互斥,告辞。24 // 有线程持有写锁,持有写锁的线程不是当前线程,不是锁重入,告辞。25 if (w == 0 || current != getExclusiveOwnerThread())26 return false;27 // 当前线程持有写锁。 锁重入。28 if (w + exclusiveCount(acquires) > MAX_COUNT)29 throw new Error("Maximum lock count exceeded");30 // 没有超过锁重入的次数,正常 + 131 setState(c + acquires);32 return true;33 }34 // 尝试获取锁资源35 if (writerShouldBlock() ||36 // CAS拿锁37 !compareAndSetState(c, c + acquires))38 return false;39 // 拿锁成功,设置占有互斥锁的线程40 setExclusiveOwnerThread(current);41 // 返回true42 return true;43}44
45// ================================================================46// 这个方法是将state的低16位的值拿到47int w = exclusiveCount(c);48state & ((1 << 16) - 1)4900000000 00000000 00000000 00000001 == 15000000000 00000001 00000000 00000000 == 1 << 165100000000 00000000 11111111 11111111 == (1 << 16) - 152&运算,一个为0,必然为0,都为1,才为153// ================================================================54// writerShouldBlock方法查看公平锁和非公平锁的效果55// 非公平锁直接返回false执行CAS尝试获取锁资源56// 公平锁需要查看是否有排队的,如果有排队的,我是否是head的next
4) 写锁释放源码
释放的流程和ReentrantLock一致,只是在判断释放是否干净时,判断低16位的值。
xxxxxxxxxx171// 写锁释放锁的tryRelease方法2protected final boolean tryRelease(int releases) {3 // 判断当前持有写锁的线程是否是当前线程4 if (!isHeldExclusively())5 throw new IllegalMonitorStateException();6 // 获取state - 17 int nextc = getState() - releases;8 // 判断低16位结果是否为0,如果为0,free设置为true9 boolean free = exclusiveCount(nextc) == 0;10 if (free)11 // 将持有锁的线程设置为null12 setExclusiveOwnerThread(null);13 // 设置给state14 setState(nextc);15 // 释放干净,返回true。 写锁有冲入,这里需要返回false,不去释放排队的Node16 return free;17}
5)读锁加锁源码
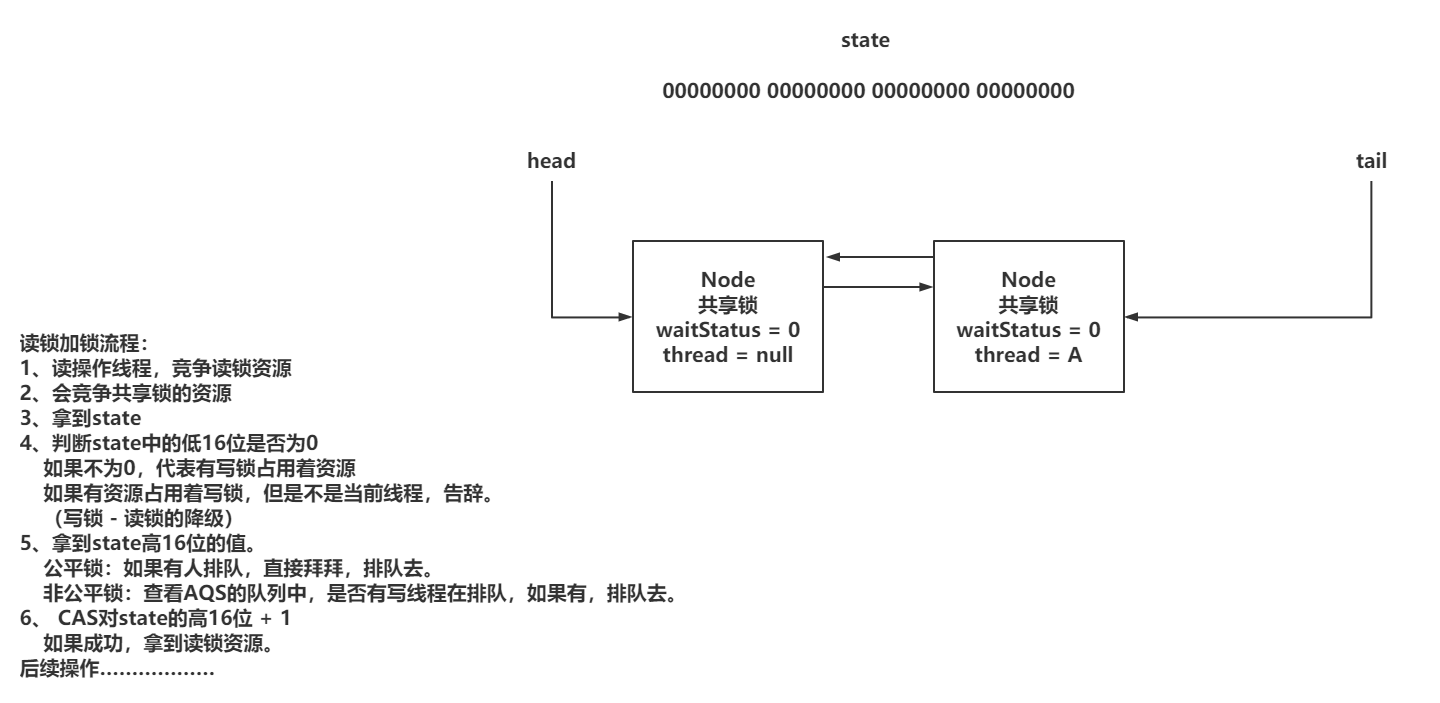
xxxxxxxxxx1081// 读锁加锁的方法入口2public final void acquireShared(int arg) {3 // 竞争锁资源滴干活4 if (tryAcquireShared(arg) < 0)5 // 没拿到锁资源,去排队6 doAcquireShared(arg);7}8
9// 读锁竞争锁资源的操作10protected final int tryAcquireShared(int unused) {11 // 拿到当前线程12 Thread current = Thread.currentThread();13 // 拿到state14 int c = getState();15 // 拿到state的低16位,判断 != 0,有写锁占用着锁资源16 // 并且,当前占用锁资源的线程不是当前线程17 if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current)18 // 写锁被其他线程占用,无法获取读锁,直接返回 -1,去排队19 return -1;20 // 没有线程持有写锁、当前线程持有写锁21 // 获取读锁的信息,state的高16位。22 int r = sharedCount(c);23 // 公平锁:就查看队列是由有排队的,有排队的,直接告辞,进不去if,后面也不用判断(没人排队继续走)24 // 非公平锁:没有排队的,直接抢。 有排队的,但是读锁其实不需要排队,如果出现这个情况,大部分是写锁资源刚刚释放,25 // 后续Node还没有来记得拿到读锁资源,当前竞争的读线程,可以直接获取26 if (!readerShouldBlock() &&27 // 判断持有读锁的临界值是否达到28 r < MAX_COUNT &&29 // CAS修改state,对高16位进行 + 130 compareAndSetState(c, c + SHARED_UNIT)) {31 // 省略部分代码!!!!32 return 1;33 }34 return fullTryAcquireShared(current);35}36// 非公平锁的判断37final boolean apparentlyFirstQueuedIsExclusive() {38 Node h, s;39 return (h = head) != null && // head为null,可以直接抢占锁资源40 (s = h.next) != null && // head的next为null,可以直接抢占锁资源41 !s.isShared() && // 如果排在head后面的Node,是共享锁,可以直接抢占锁资源。42 s.thread != null; // 后面排队的thread为null,可以直接抢占锁资源43}44
45// tryAcquireShard方法中,如果没有拿到锁资源,走这个方法,尝试再次获取,逻辑跟上面基本一致。46final int fullTryAcquireShared(Thread current) {47 // 声明当前线程的锁重入次数48 HoldCounter rh = null;49 // 死循环50 for (;;) {51 // 再次拿到state52 int c = getState();53 // 当前如果有写锁在占用锁资源,并且不是当前线程,返回-1,走排队策略54 if (exclusiveCount(c) != 0) {55 if (getExclusiveOwnerThread() != current)56 return -1;57
58 } 59 // 查看当前是否可以尝试竞争锁资源(公平锁和非公平锁的逻辑)60 else if (readerShouldBlock()) {61 // 无论公平还是非公平,只要进来,就代表要放到AQS队列中了,先做一波准备62 // 在处理ThreadLocal的内存泄漏问题63 if (firstReader == current) {64 // 如果当前当前线程是之前的firstReader,什么都不用做65 } else {66 // 第一次进来是null。67 if (rh == null) {68 // 拿到最后一个获取读锁的线程69 rh = cachedHoldCounter;70 // 当前线程并不是cachedHoldCounter,没到拿到71 if (rh == null || rh.tid != getThreadId(current)) {72 // 从自己的ThreadLocal中拿到重入计数器73 rh = readHolds.get();74 // 如果计数器为0,说明之前没拿到过读锁资源75 if (rh.count == 0)76 // remove,避免内存泄漏77 readHolds.remove();78 }79 }80 // 前面处理完之后,直接返回-181 if (rh.count == 0)82 return -1;83 }84 }85 // 判断重入次数,是否超出阈值86 if (sharedCount(c) == MAX_COUNT)87 throw new Error("Maximum lock count exceeded");88 // CAS尝试获取锁资源89 if (compareAndSetState(c, c + SHARED_UNIT)) {90 if (sharedCount(c) == 0) {91 firstReader = current;92 firstReaderHoldCount = 1;93 } else if (firstReader == current) {94 firstReaderHoldCount++;95 } else {96 if (rh == null)97 rh = cachedHoldCounter;98 if (rh == null || rh.tid != getThreadId(current))99 rh = readHolds.get();100 else if (rh.count == 0)101 readHolds.set(rh);102 rh.count++;103 cachedHoldCounter = rh; // cache for release104 }105 return 1;106 }107 }108}
6) 读锁重入源码
xxxxxxxxxx431protected final int tryAcquireShared(int unused) {2 Thread current = Thread.currentThread();3 int c = getState();4 if (exclusiveCount(c) != 0 &&5 getExclusiveOwnerThread() != current)6 return -1;7 int r = sharedCount(c);8 if (!readerShouldBlock() &&9 r < MAX_COUNT &&10 compareAndSetState(c, c + SHARED_UNIT)) {11 // ===============================================================12 // 判断r == 0,当前是第一个拿到读锁资源的线程13 if (r == 0) {14 // 将firstReader设置为当前线程15 firstReader = current;16 // 将count设置为117 firstReaderHoldCount = 1;18 } 19 // 判断当前线程是否是第一个获取读锁资源的线程20 else if (firstReader == current) {21 // 直接++。22 firstReaderHoldCount++;23 } 24 // 到这,就说明不是第一个获取读锁资源的线程25 else {26 // 那获取最后一个拿到读锁资源的线程27 HoldCounter rh = cachedHoldCounter;28 // 判断当前线程是否是最后一个拿到读锁资源的线程29 if (rh == null || rh.tid != getThreadId(current))30 // 如果不是,设置当前线程为cachedHoldCounter31 cachedHoldCounter = rh = readHolds.get();32 // 当前线程是之前的cacheHoldCounter33 else if (rh.count == 0)34 // 将当前的重入信息设置到ThreadLocal中35 readHolds.set(rh);36 // 重入的++37 rh.count++;38 }39 // ===============================================================40 return 1;41 }42 return fullTryAcquireShared(current);43}
7) 读锁释放源码
xxxxxxxxxx771// 读锁释放锁流程2public final boolean releaseShared(int arg) {3 // tryReleaseShared:处理state的值,以及可重入的内容4 if (tryReleaseShared(arg)) {5 // AQS队列的事!6 doReleaseShared();7 return true;8 }9 return false;10}11
12// 1、 处理重入问题 2、 处理state13protected final boolean tryReleaseShared(int unused) {14 // 拿到当前线程15 Thread current = Thread.currentThread();16 // 如果是firstReader,直接干活,不需要ThreadLocal17 if (firstReader == current) {18 // assert firstReaderHoldCount > 0;19 if (firstReaderHoldCount == 1)20 firstReader = null;21 else22 firstReaderHoldCount--;23 } 24 // 不是firstReader,从cachedHoldCounter以及ThreadLocal处理25 else {26 // 如果是cachedHoldCounter,正常--27 HoldCounter rh = cachedHoldCounter;28 // 如果不是cachedHoldCounter,从自己的ThreadLocal中拿29 if (rh == null || rh.tid != getThreadId(current))30 rh = readHolds.get();31 int count = rh.count;32 // 如果为1或者更小,当前线程就释放干净了,直接remove,避免value内存泄漏33 if (count <= 1) {34 readHolds.remove();35 // 如果已经是0,没必要再unlock,扔个异常36 if (count <= 0)37 throw unmatchedUnlockException();38 }39 // -- 走你。40 --rh.count;41 }42 for (;;) {43 // 拿到state,高16位,-1,成功后,返回state是否为044 int c = getState();45 int nextc = c - SHARED_UNIT;46 if (compareAndSetState(c, nextc))47 return nextc == 0;48 }49}50
51// 唤醒AQS中排队的线程52private void doReleaseShared() {53 // 死循环54 for (;;) {55 // 拿到头56 Node h = head;57 // 说明有排队的58 if (h != null && h != tail) {59 // 拿到head的状态60 int ws = h.waitStatus;61 // 判断是否为 -1 62 if (ws == Node.SIGNAL) {63 // 到这,说明后面有挂起的线程,先基于CAS将head的状态从-1,改为064 if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))65 continue; 66 // 唤醒后续节点67 unparkSuccessor(h);68 }69 // 这里不是给读写锁准备的,在信号量里说。。。70 else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))71 continue;72 }73 // 这里是出口74 if (h == head) 75 break;76 }77}
8) 扩展知识
StampedLock :邮戳锁,是对 ReentrantReadWriteLock 的改进,额外支持乐观读,且性能更好,写线程更容易获得锁,但它不支持重入和条件变量,代码也相对复杂。
5. 信号量(Semaphore)
1) Semaphore简介
Semaphore可以通过控制许可数量来限制同时访问特定资源的线程数,支持许可的获取与释放,可实现并发限流。
xxxxxxxxxx161// 构造方法2public Semaphore(int permits) // permits-最大许可数量3public Semaphore(int permits, boolean fair)4 5// 直接获取许可(可能阻塞)6public void acquire() throws InterruptedException // 阻塞获取许可7public void acquireUninterruptibly() // 阻塞获取许可,不响应中断8public void acquire(int permits) throws InterruptedException // 批量获取多个许可9public void acquireUninterruptibly(int permits) // 批量获取多个许可,不响应中断10 11// 尝试获取许可12public boolean tryAcquire() 13public boolean tryAcquire(int permits, long timeout, TimeUnit unit) throws InterruptedException // 限定等待时间14 15//释放许可16public void release()
2) 基本使用
xxxxxxxxxx231// 限制并发访问的用户不超过1002public class AccessControlService {3 public static class ConcurrentLimitException extends RuntimeException {4 private static final long serialVersionUID = 1L;5 }6
7 private static final int MAX_PERMITS = 100; // 最大并发数8 private Semaphore permits = new Semaphore(MAX_PERMITS, true); // 信号量9
10 public boolean login(String name, String password) {11 // 尝试获取许可,超过则报错12 if (!permits.tryAcquire()) {13 throw new ConcurrentLimitException(); // 同时登录用户数超过限制14 }15 16 // ..其他验证17 return true;18 }19
20 public void logout(String name) {21 permits.release(); // 释放许可22 }23}注意:
- Semaphore是不可重入的,即使在同一个线程,每一次的acquire调用都会消耗一个许可。
- 一般锁只能由持有锁的线程释放,而Semaphore表示的只是一个许可数,任意线程都可以调用其release方法。
- 因此,即使将permits设置为1,它和一般的锁还是有本质的不同。
3) 核心属性&构造
Semaphore的内部类Sync继承了AQS,是一个基于AQS实现的计数器,计数器值存储在AQS的state变量,当申请许可时计数减少,当释放许可时,计数增加,构造方法如下:
xxxxxxxxxx421public class Semaphore implements java.io.Serializable {2 // 1. 核心同步器:封装许可的获取/释放逻辑(AQS 核心)3 private final Sync sync;4
5 // 2. 内部同步器抽象类(继承 AQS)6 abstract static class Sync extends AbstractQueuedSynchronizer {7 private static final long serialVersionUID = 1192457210091910933L;8
9 // 构造器:初始化 AQS 的 state 为许可总数10 Sync(int permits) {11 setState(permits);12 }13
14 // 获取剩余许可数(直接返回 AQS 的 state)15 final int getPermits() {16 return getState();17 }18
19 // 非公平模式下获取许可(核心方法)20 final int nonfairTryAcquireShared(int acquires) {21 // 省略 CAS 自旋获取许可的逻辑22 }23
24 // 释放许可(核心方法)25 protected final boolean tryReleaseShared(int releases) {26 // 省略 CAS 自旋释放许可的逻辑27 }28
29 // 其他许可操作方法(如 reducePermits、drainPermits)30 }31
32 // 3. 非公平同步器实现(默认)33 static final class NonfairSync extends Sync {34 // 省略非公平模式的获取逻辑35 }36
37 // 4. 公平同步器实现38 static final class FairSync extends Sync {39 // 省略公平模式的获取逻辑40 }41}42
6. 倒计时门栓(CountDownLatch)
1) CountDownLatch简介
CountDownLatch可以让一组线程等待另一组线程完成后再继续执行,本质上是一个计数器,在构造时指定初始值,只能计减,在减为0后,唤醒所有等待的线程。应用场景如下:
- 同时开始:计数值为1,子线程等待,主线程去扣减计数器。
- 等待结束:计数值为N,主线程等待,子线程去扣减计数器。
xxxxxxxxxx91// 构造方法2public CountDownLatch(int count) // count-计数,即参与的线程个数3 4// 等待计数变为05public void await() throws InterruptedException // 检查计数是否为0,如果大于0,就等待6public boolean await(long timeout, TimeUnit unit) throws InterruptedException // 可以设置最长等待时间7
8// 减少计数9public void countDown() // 检查计数,如果已经为0,直接返回,否则减少计数,如果新的计数变为0,则唤醒所有等待的线程
2) 基本使用
前面介绍过门栓的两种应用场景,一种是同时开始,另一种是等待结束,它们都有两类线程,互相需要同步,实现代码如下:
xxxxxxxxxx741// 同时开始2public class RacerWithCountDownLatch {3 // 子线程:等待开始4 static class Racer extends Thread {5 CountDownLatch latch; // 倒计时门栓6
7 public Racer(CountDownLatch latch) {8 this.latch = latch; 9 }10
11 12 public void run() {13 try {14 this.latch.await(); // 先等待15 System.out.println(getName() + " start run "+System.currentTimeMillis());16 } catch (InterruptedException e) {17 }18 }19 }20
21 // 主线程:发起开始指令22 public static void main(String[] args) throws InterruptedException {23 int num = 10;24 CountDownLatch latch = new CountDownLatch(1); // 倒计时门栓,计数为125 Thread[] racers = new Thread[num];26 for (int i = 0; i < num; i++) {27 racers[i] = new Racer(latch);28 racers[i].start();29 }30 Thread.sleep(1000);31 latch.countDown(); // 计数减1后变为0,唤醒所有线程,同时开始32 }33}34
35// 等待结束36public class MasterWorkerDemo {37 // 子线程38 static class Worker extends Thread {39 CountDownLatch latch; // 倒计时门栓40
41 public Worker(CountDownLatch latch) {42 this.latch = latch;43 }44
45 46 public void run() {47 try {48 // 业务代码49 Thread.sleep((int) (Math.random() * 1000));50
51 // 模拟异常52 if (Math.random() < 0.02) {53 throw new RuntimeException("bad luck");54 }55 } catch (InterruptedException e) {56 } finally {57 this.latch.countDown(); // 执行完后计数-158 }59 }60 }61
62 // 主线程63 public static void main(String[] args) throws InterruptedException {64 int workerNum = 100;65 CountDownLatch latch = new CountDownLatch(workerNum); // 倒计时门栓,计数为100,即线程数66 Worker[] workers = new Worker[workerNum];67 for (int i = 0; i < workerNum; i++) {68 workers[i] = new Worker(latch);69 workers[i].start();70 }71 latch.await(); // 等待所有线程结束72 System.out.println("collect worker results");73 }74}注意:
- countDown的调用应该放到finally语句中,确保在工作线程发生异常的情况下也会被调用,使主线程能够从await调用中返回。
3) 核心属性&构造
CountDownLatch的内部类Sync继承了AQS,也是一个基于AQS实现的计数器,计数器值存储在AQS的state变量,构造方法如下:
xxxxxxxxxx141// CountDownLatch的有参构造2public CountDownLatch(int count) {3 // 健壮性校验4 if (count < 0) throw new IllegalArgumentException("count < 0");5 6 // 构建内部类,Sync传入count7 this.sync = new Sync(count);8}9
10// AQS子类,Sync的有参构造11Sync(int count) {12 // 就是给AQS中的state赋值13 setState(count);14}
4) await方法实现
await方法就是判断当前CountDownLatch中的state是否为0,如果为0,直接正常执行后续任务;
如果不为0,以共享锁的方式,插入到AQS的双向链表,并且挂起线程。
xxxxxxxxxx481// 一般主线程await的方法,阻塞主线程,等待state为02public void await() throws InterruptedException {3 sync.acquireSharedInterruptibly(1);4}5
6// 执行了AQS的acquireSharedInterruptibly方法7public final void acquireSharedInterruptibly(int arg) throws InterruptedException {8 // 判断线程是否中断,如果中断标记位是true,直接抛出异常9 if (Thread.interrupted())10 throw new InterruptedException();11 if (tryAcquireShared(arg) < 0)12 // 共享锁挂起的操作13 doAcquireSharedInterruptibly(arg);14}15
16// tryAcquireShared在CountDownLatch中的实现17protected int tryAcquireShared(int acquires) {18 // 查看state是否为0,如果为0,返回1,不为0,返回-119 return (getState() == 0) ? 1 : -1;20}21
22private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {23 // 封装当前先成为Node,属性为共享锁24 final Node node = addWaiter(Node.SHARED);25 boolean failed = true;26 try {27 for (;;) {28 final Node p = node.predecessor();29 if (p == head) {30 int r = tryAcquireShared(arg);31 if (r >= 0) {32 setHeadAndPropagate(node, r);33 p.next = null; // help GC34 failed = false;35 return;36 }37 }38 // 在这,就需要挂起当前线程。39 if (shouldParkAfterFailedAcquire(p, node) &&40 parkAndCheckInterrupt())41 throw new InterruptedException();42 }43 } finally {44 if (failed)45 cancelAcquire(node);46 }47}48
5) countDown方法实现
countDown方法本质就是对state - 1,如果state - 1后变为0,需要去AQS的链表中唤醒挂起的节点。
xxxxxxxxxx631// countDown对计数器-12public void countDown() {3 // 是-1。4 sync.releaseShared(1);5}6
7// AQS提供的功能8public final boolean releaseShared(int arg) {9 // 对state - 110 if (tryReleaseShared(arg)) {11 // state - 1后,变为0,执行doReleaseShared12 doReleaseShared();13 return true;14 }15 return false;16}17// CountDownLatch的tryReleaseShared实现18protected boolean tryReleaseShared(int releases) {19 // 死循环是为了避免CAS并发问题20 for (;;) {21 // 获取state22 int c = getState();23 // state已经为0,直接返回false24 if (c == 0)25 return false;26 // 对获取到的state - 127 int nextc = c-1;28 // 基于CAS的方式,将值赋值给state29 if (compareAndSetState(c, nextc))30 // 赋值完,发现state为0了。此时可能会有线程在await方法处挂起,那边挂起,需要这边唤醒31 return nextc == 0;32 }33}34
35// 如何唤醒在await方法处挂起的线程36private void doReleaseShared() {37 // 死循环38 for (;;) {39 // 拿到head40 Node h = head;41 // head不为null,有值,并且head != tail,代表至少2个节点42 // 一个虚拟的head,加上一个实质性的Node43 if (h != null && h != tail) {44 // 说明AQS队列中有节点45 int ws = h.waitStatus;46 // 如果head节点的状态为 -1.47 if (ws == Node.SIGNAL) {48 // 先对head节点将状态从-1,修改为0,避免重复唤醒的情况49 if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))50 continue; 51 // 正常唤醒节点即可,先看head.next,能唤醒就唤醒,如果head.next有问题,从后往前找有效节点52 unparkSuccessor(h);53 }54 // 会在Semaphore中谈到这个位置55 else if (ws == 0 &&56 !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))57 continue; 58 }59 // 会在Semaphore中谈到这个位置60 if (h == head) 61 break;62 }63}
7. 循环栅栏(CyclicBarrier)
1)CyclicBarrier简介
CyclicBarrier可以让一组线程相互等待至全部到达屏障点后再共同执行,屏障可自动重置并重复使用,还可配置触发回调任务。应用场景如下:
- 集合点:先到的线程进行等待,最后一个到达的线程执行回调任务、重置栅栏,并唤醒其他等待线程。
xxxxxxxxxx141// 1. 构造方法2// parties-参与的线程个数3// barrierAction-集合点动作:当所有线程到达集合点后,在所有线程执行下一步动作前,运行参数中的动作4// 这个动作由最后一个到达集合点的线程执行5public CyclicBarrier(int parties) 6public CyclicBarrier(int parties, Runnable barrierAction) 7
8// 2. 等待其它线程9// 表示自己已经到达,等待其它线程,如果自己是最后一个到达的,就执行集合点动作10// 集合点动作执行后,唤醒所有等待的线程,然后重置内部的同步计数,以循环使用11// await可以被中断或限定最长等待时间,中断或超时后会抛出栅栏破坏异常BrokenBarrierException12public int await() throws InterruptedException, BrokenBarrierException 13public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException14
注意:
- 只要有一个线程抛出BrokenBarrierException,就会导致所有在调用await的线程都抛出BrokenBarrierException。
- 此外,如果栅栏动作(集合点动作)抛出了异常,也会破坏栅栏。
2) 基本使用
xxxxxxxxxx611// 多个游客线程分别在集合点A和B同步2public class CyclicBarrierDemo {3 static class Tourist extends Thread {4 CyclicBarrier barrier;5
6 public Tourist(CyclicBarrier barrier) {7 this.barrier = barrier;8 }9
10 11 public void run() {12 try {13 // 模拟先各自独立运行14 Thread.sleep((int) (Math.random() * 1000));15
16 // 集合点A17 barrier.await();18
19 System.out.println(this.getName() + " arrived A "20 + System.currentTimeMillis());21
22 // 集合后模拟再各自独立运行23 Thread.sleep((int) (Math.random() * 1000));24
25 // 集合点B26 barrier.await();27 System.out.println(this.getName() + " arrived B "28 + System.currentTimeMillis());29 } catch (InterruptedException e) {30 } catch (BrokenBarrierException e) {31 }32 }33 }34
35 public static void main(String[] args) {36 int num = 3;37 Tourist[] threads = new Tourist[num];38 CyclicBarrier barrier = new CyclicBarrier(num, new Runnable() {39
40 41 public void run() {42 System.out.println("all arrived " + System.currentTimeMillis()43 + " executed by " + Thread.currentThread().getName());44 }45 });46 for (int i = 0; i < num; i++) {47 threads[i] = new Tourist(barrier);48 threads[i].start();49 }50 }51}52
53// 输出如下,多个线程到达A和B的时间是一样的,使用CyclicBarrier,达到了重复同步的目的54all arrived 1490053578552 executed by Thread-155Thread-1 arrived A 149005357855556Thread-2 arrived A 149005357855557Thread-0 arrived A 149005357855558all arrived 1490053578889 executed by Thread-059Thread-0 arrived B 149005357889060Thread-2 arrived B 149005357889061Thread-1 arrived B 1490053578890
3) 核心属性&构造
CyclicBarrier并没有直接基于AQS,而是基于ReentrantLock实现对屏障点的计减以及线程挂起操作。
xxxxxxxxxx331public class CyclicBarrier {2 // 1. 内部锁:保护所有状态的同步锁3 private final ReentrantLock lock = new ReentrantLock();4 // 2. 条件变量:用于线程等待/唤醒(核心等待队列)5 private final Condition trip = lock.newCondition();6 // 3. 屏障总数:需要等待的线程总数(固定值,构造时传入)7 private final int parties;8 // 4. 屏障动作:所有线程到达后执行的自定义任务(可选)9 private final Runnable barrierCommand;10 // 5. 当前代:记录屏障的“代次”,支撑循环复用11 private Generation generation = new Generation();12 // 6. 剩余计数:当前代还未到达屏障的线程数(动态变化)13 private int count;14
15 // 内部类:表示屏障的“一代”,用于循环复用16 private static class Generation {17 boolean broken = false; // 标记当前代是否被打破(如超时、中断)18 }19 20 // 有参构造21 public CyclicBarrier(int parties, Runnable barrierAction) {22 // 健壮性判23 if (parties <= 0) throw new IllegalArgumentException();24 25 // 当前类中的属性parties是保存屏障点数值的26 this.parties = parties;27 // 将parties赋值给属性count,每来一个线程,继续count做-1操作。28 this.count = parties;29 // 优先执行的任务30 this.barrierCommand = barrierAction;31 }32}33
4) await方法
在CyclicBarrier中,提供了2个await方法:
- 第一个是无参的方式,线程要死等,直屏障点数值为0,或者有线程中断。
- 第二个是有参方式,传入等待的时间,要么时间到位了,要不就是直屏障点数值为0,或者有线程中断。
无论是哪种await方法,核心都在于内部调用的dowait方法,该方法主要包含了线程互相等待的逻辑,以及屏障点数值到达0之后的操作
xxxxxxxxxx911// 包含了线程互相等待的逻辑,以及屏障点数值到达0后的操作2private int dowait(boolean timed, long nanos)throws 3 // 当前新编程中断,抛出这个异常4 InterruptedException, 5 // 其他线程中断,当前线程抛出这个异常6 BrokenBarrierException,7 // await时间到位,抛出这个异常8 TimeoutException {9 // 加锁10 final ReentrantLock lock = this.lock;11 lock.lock();12 try {13 // 拿到Generation对象的引用14 final Generation g = generation;15
16 // 判断下线程中断了么?如果中断了,直接抛出异常17 if (g.broken)18 throw new BrokenBarrierException();19
20 // 当前线程中断了么?21 if (Thread.interrupted()) {22 // 做了三个实现,23 // 设置broken为true,将count重置,唤醒其他等待的线程24 breakBarrier();25 // 抛出异常26 throw new InterruptedException();27 }28
29 // 屏障点做--30 int index = --count;31 // 如果屏障点为0,打开屏障啦!!32 if (index == 0) { 33 // 标记34 boolean ranAction = false;35 try {36 // 拿到有参构造中传递的任务37 final Runnable command = barrierCommand;38 // 任务不为null,优先执行当前任务39 if (command != null)40 command.run();41 // 上述任务执行没问题,标记位设置为true42 ranAction = true;43 // 执行nextGeneration44 // 唤醒所有线程,重置count,重置generation45 nextGeneration();46 return 0;47 } finally {48 // 如果优先执行的任务出了问题i,就直接抛出异常49 if (!ranAction)50 breakBarrier();51 }52 }53
54 // 死循环55 for (;;) {56 try {57 // 如果调用await方法,死等58 if (!timed)59 trip.await();60 // 如果调用await(time,unit),基于设置的nans时长决定await的时长61 else if (nanos > 0L)62 nanos = trip.awaitNanos(nanos);63 } catch (InterruptedException ie) {64 // 到这,说明线程被中断了65 // 查看generation有没有被重置。66 // 并且当前broken为false,需要做线程中断后的操作。67 if (g == generation && ! g.broken) {68 breakBarrier();69 throw ie;70 } else {71 Thread.currentThread().interrupt();72 }73 }74 // 是否是中断唤醒,是就抛异常。75 if (g.broken)76 throw new BrokenBarrierException();77 // 说明被reset了,返回index的数值。或者任务完毕也会被重置78 if (g != generation)79 return index;80 // 指定了等待的时间内,没有等到所有线程都到位81 if (timed && nanos <= 0L) {82 // 中断任务83 breakBarrier();84 // 抛出异常85 throw new TimeoutException();86 }87 }88 } finally {89 lock.unlock();90 }91}
8. 面试扩展
1) CAS和AQS的区别?
- CAS(Compare-And-Swap)是一种无锁编程技术,它通过硬件指令来保证操作的原子性。
- AQS(AbstractQueuedSynchronizer)是 Java
java.util.concurrent包中的一个抽象类,用于构建锁和其他同步器的基础框架。
2) 公平锁 vs 非公平锁?
- 公平锁会按照线程到达的顺序获取锁,而非公平锁则允许插队,即在排队之前可以尝试抢一次锁。
- 保证公平会让活跃线程得不到锁,进入等待状态,引起上下文切换,降低整体效率,因此一般都是不保证公平的。
- 通常情况下,谁先运行关系不大,而且长时间运行,从统计角度而言,虽然不保证公平,也基本是公平的。
- 而且,即使fair参数为true,不带参数的tryLock方法也是不保证公平的,它不会检查是否有其他等待时间更长的线程。
3) Lock vs synchronized
Lock:一种命令式编程,需程序员实现加锁/解锁细节,但是更为灵活。
synchronized:一种声明式编程,使用更为简单,不易出错,而且Java编译器和虚拟机可以不断优化synchronized的实现。
- 局限:只有一个条件队列,且不能响应中断,不能尝试加锁或超时加锁,不能设置公平锁等。
4) ReentrantLock vs synchronized
- ReentrantLock是一个类,底层是基于AQS实现的;synchronized是一个关键字,底层是基于ObjectMonitor实现的。
- ReentrantLock不存在锁升级,在高并发情况下表现更好,且支持多个条件队列、设置锁超时时间等更多功能。
5) AQS为啥需要一个head节点?
在AQS的双向锁等待队列中,head节点不是必须的,但是可以对唤醒后续节点的操作进行优化。即通过判断head节点的等待状态是否为-1,得出是否有节点需要被唤醒,如果有,采取遍历双向链表。
6) AQS中为什么使用双向链表?
主要是为了更方便的操作Node节点,如取消节点时,如果有前指针,则可以很方便的将前节点的next节点执行当前节点的next节点。
7) ReentrantLock 的 lock 和 lockInterruptibly 有什么区别?
两者均会阻塞获取锁,核心区别是中断响应:
- lock:不可中断,即使线程被中断仍会等待锁;
- lockInterruptibly: 可响应中断,等待时被中断会抛出 InterruptedException 并停止等待。
实际使用中,需要线程取消或超时控制时用 lockInterruptibly,无需中断响应时用 lock。
8) CyclicBarrier vs CountDownLatch
CyclicBarrier与CountDownLatch可能容易混淆,它们主要有两点区别:
倒计时门栓涉及两个角色,而循环栅栏只涉及一个角色。
- 倒计时门栓的参与线程分为两类,一类负责倒计时,一类则在等待倒计时变为0,每类线程都可以是多个。
- 循环栅栏的参与线程都是一类,动作都是在集合点等待最后一个到达的线程,只不过最后一个线程会执行一个额外的动作。
倒计时门栓是一次性的,而循环栅栏是可以重复利用的。
第三节 阻塞队列
1. 阻塞队列简介
1) BlockingQueue
java.util.concurrentBlockingQueue 是阻塞队列的顶层接口,主要方法如下:
xxxxxxxxxx121// 1. 入队2add(E) // 添加数据到队列,如果队列满了,无法存储,抛出异常3offer(E) // 添加数据到队列,如果队列满了,返回false4offer(E,timeout,unit) // 添加数据到队列,如果队列满了,阻塞timeout时间,如果阻塞一段时间,依然没添加进入,返回false5put(E) // 添加数据到队列,如果队列满了,挂起线程,等到队列中有位置,再扔数据进去,死等!6
7// 2. 出队8remove() // 从队列中移除数据,如果队列为空,抛出异常9poll() // 从队列中移除数据,如果队列为空,返回null10poll(timeout,unit) // 从队列中移除数据,如果队列为空,挂起线程timeout时间,等生产者扔数据,再获取,超时返回null11take() // 从队列中移除数据,如果队列为空,线程挂起,一直等到生产者扔数据,再获取12
2) 常用实现类
BlockingQueue的常见实现类如下,这些队列大都是基于ReentrantLock+Condition实现的,是并发安全的、弱一致性的。
| 队列类型 | 队列类名 |
|---|---|
| 普通阻塞队列 | ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque |
| 优先级阻塞队列 | PriorityBlockingQueue |
| 延时阻塞队列 | DelayQueue |
| 其他阻塞队列 | SynchronousQueue:实时队列,容量为0,必须实时传递 LinkedTransferQueue:传递队列,容量无界,支持实时传递,也可以存储数据 |
2. ArrayBlockingQueue
1) 基本使用
ArrayBlockingQueue 是基于数组实现的有界阻塞队列,需在初始化时指定容量,不可扩容,适用于固定大小的缓冲池等场景。
xxxxxxxxxx221import java.util.concurrent.ArrayBlockingQueue;2import java.util.concurrent.BlockingQueue;3
4public class ArrayBlockingQueueDemo {5 public static void main(String[] args) throws InterruptedException {6 // 初始化容量为3的有界阻塞队列7 BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);8 9 // 入队(满时阻塞)10 queue.put("任务1");11 queue.put("任务2");12 queue.put("任务3");13 14 // 尝试非阻塞入队(队列满时返回false)15 boolean offerResult = queue.offer("任务4");16 System.out.println("非阻塞入队结果:" + offerResult); // 输出false17 18 // 出队(空时阻塞)19 String task = queue.take();20 System.out.println("取出任务:" + task); // 输出任务121 }22}
2) 核心属性
ArrayBlockingQueue的底层用ReentrantLock保证线程安全,入队 / 出队共用一把锁,高并发下性能一般。
xxxxxxxxxx171/** 存储队列元素的底层数组(定长,初始化后不可扩容) */2final Object[] items;3
4/** 下次取元素(take/poll/remove)的索引位置 */5int takeIndex;6/** 下次放元素(put/offer/add)的索引位置 */7int putIndex;8/** 队列中当前元素的数量 */9int count;10
11/** 保证队列操作线程安全的重入锁 */12final ReentrantLock lock;13/** 队列非空的条件变量(供消费者等待) */14private final Condition notEmpty;15/** 队列非满的条件变量(供生产者等待) */16private final Condition notFull;17
3) 生产者方法实现
add
add方法本身就是调用了offer方法,如果offer方法返回false,直接抛出异常
xxxxxxxxxx71public boolean add(E e) {2 if (offer(e))3 return true;4 else5 // 抛出的异常6 throw new IllegalStateException("Queue full");7}
offer
xxxxxxxxxx391public boolean offer(E e) {2 // 要求存储的数据不允许为null,为null就抛出空指针3 checkNotNull(e);4 // 当前阻塞队列的lock锁5 final ReentrantLock lock = this.lock;6 // 为了保证线程安全,加锁7 lock.lock();8 try {9 // 如果队列中的元素已经存满了,10 if (count == items.length)11 // 返回false12 return false;13 else {14 // 队列没满,执行enqueue将元素添加到队列中15 enqueue(e);16 // 返回true17 return true;18 }19 } finally {20 // 操作完释放锁21 lock.unlock();22 }23}24
25//==========================================================26private void enqueue(E x) {27 // 拿到数组的引用28 final Object[] items = this.items;29 // 将元素放到指定位置30 items[putIndex] = x;31 // 对inputIndex进行++操作,并且判断是否已经等于数组长度,需要归位32 if (++putIndex == items.length)33 // 将索引设置为034 putIndex = 0;35 // 元素添加成功,进行++操作。36 count++;37 // 将一个Condition中阻塞的线程唤醒。38 notEmpty.signal();39}
offer(time,unit)
生产者在添加数据时,如果队列已经满了,会阻塞一会。
- 阻塞到消费者消费了消息,然后唤醒当前阻塞线程
- 阻塞到了time时间,再次判断是否可以添加,不能,直接告辞。
xxxxxxxxxx311// 如果线程在挂起的时候,如果对当前阻塞线程的中断标记位进行设置,此时会抛出异常直接结束2public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {3 // 非空检验4 checkNotNull(e);5 // 将时间单位转换为纳秒6 long nanos = unit.toNanos(timeout);7 // 加锁8 final ReentrantLock lock = this.lock;9 // 允许线程中断并排除异常的加锁方式10 lock.lockInterruptibly();11 try {12 // 为什么是while(虚假唤醒)13 // 如果元素个数和数组长度一致,队列慢了14 while (count == items.length) {15 // 判断等待的时间是否还充裕16 if (nanos <= 0)17 // 不充裕,直接添加失败18 return false;19 // 挂起等待,会同时释放锁资源(对标sync的wait方法)20 // awaitNanos会挂起线程,并且返回剩余的阻塞时间21 // 恢复执行时,需要重新获取锁资源22 nanos = notFull.awaitNanos(nanos);23 }24 // 说明队列有空间了,enqueue将数据扔到阻塞队列中25 enqueue(e);26 return true;27 } finally {28 // 释放锁资源29 lock.unlock();30 }31}
put
如果队列是满的, 就一直挂起,直到被唤醒,或者被中断:
xxxxxxxxxx131public void put(E e) throws InterruptedException {2 checkNotNull(e);3 final ReentrantLock lock = this.lock;4 lock.lockInterruptibly();5 try {6 while (count == items.length)7 // await方法一直阻塞,直到被唤醒或者中断标记位8 notFull.await();9 enqueue(e);10 } finally {11 lock.unlock();12 }13}
4) 消费者方法实现
remove
xxxxxxxxxx101// remove方法就是调用了poll2public E remove() {3 E x = poll();4 // 如果有数据,直接返回5 if (x != null)6 return x;7 // 没数据抛出异常8 else9 throw new NoSuchElementException();10}
poll
xxxxxxxxxx361// 拉取数据2public E poll() {3 // 加锁操作4 final ReentrantLock lock = this.lock;5 lock.lock();6 try {7 // 如果没有数据,直接返回null,如果有数据,执行dequeue,取出数据并返回8 return (count == 0) ? null : dequeue();9 } finally {10 lock.unlock();11 }12}13
14//==========================================================15// 取出数据16private E dequeue() {17 // 将成员变量引用到局部变量18 final Object[] items = this.items;19 // 直接获取指定索引位置的数据20 E x = (E) items[takeIndex];21 // 将数组上指定索引位置设置为null22 items[takeIndex] = null;23 // 设置下次取数据时的索引位置24 if (++takeIndex == items.length)25 takeIndex = 0;26 // 对count进行--操作27 count--;28 // 迭代器内容,先跳过29 if (itrs != null)30 itrs.elementDequeued();31 // signal方法,会唤醒当前Condition中排队的一个Node。32 // signalAll方法,会将Condition中所有的Node,全都唤醒33 notFull.signal();34 // 返回数据。35 return x;36}
poll(time,unit)
xxxxxxxxxx211public E poll(long timeout, TimeUnit unit) throws InterruptedException {2 // 转换时间单位3 long nanos = unit.toNanos(timeout);4 // 竞争锁5 final ReentrantLock lock = this.lock;6 lock.lockInterruptibly();7 try {8 // 如果没有数据9 while (count == 0) {10 if (nanos <= 0)11 // 没数据,也无法阻塞了,返回null12 return null;13 // 没数据,挂起消费者线程14 nanos = notEmpty.awaitNanos(nanos);15 }16 // 取数据17 return dequeue();18 } finally {19 lock.unlock();20 }21}
take
xxxxxxxxxx121public E take() throws InterruptedException {2 final ReentrantLock lock = this.lock;3 lock.lockInterruptibly();4 try {5 // 虚假唤醒6 while (count == 0)7 notEmpty.await();8 return dequeue();9 } finally {10 lock.unlock();11 }12}
3. LinkedBlockingQueue
1) 基本使用
LinkedBlockingQueue是基于链表实现的无界阻塞队列,适用于任务数量不确定,追求高并发性能的场景,如线程池的任务队列。
xxxxxxxxxx11// ...
2) 核心属性
LinkedBlockingQueue 在入队和出队时使用两把独立的锁(入队锁、出队锁),高并发下性能比 ArrayBlockingQueue 好。
xxxxxxxxxx351/** 链表节点类(静态内部类),存储元素和下一个节点引用 */2static class Node<E> {3 E item;4 Node<E> next;5 Node(E x) { item = x; }6}7/** 队列的头节点(head.item 永远为null,是哨兵节点) */8transient Node<E> head;9/** 队列的尾节点(last.next 永远为null) */10private transient Node<E> last;11
12/** 队列的容量上限(可选,默认Integer.MAX_VALUE,即无界) */13private final int capacity;14/** 队列中当前元素的数量(用AtomicInteger保证原子性) */15private final AtomicInteger count = new AtomicInteger();16
17/** 入队锁:所有添加元素的操作(put/offer)都需要获取这把锁 */18private final ReentrantLock takeLock = new ReentrantLock();19/** 出队锁:所有取出元素的操作(take/poll)都需要获取这把锁 */20private final ReentrantLock putLock = new ReentrantLock();21/** 队列非空的条件变量(绑定到takeLock,供消费者等待) */22private final Condition notEmpty = takeLock.newCondition();23/** 队列非满的条件变量(绑定到putLock,供生产者等待) */24private final Condition notFull = putLock.newCondition();25
26// 构造方法27public LinkedBlockingQueue(int capacity) {28 if (capacity <= 0) throw new IllegalArgumentException();29 this.capacity = capacity;30 // 在初始化时,构建一个item为null的节点,作为head和last31 // 这种node可以成为哨兵Node,32 // 如果没有哨兵节点,那么在获取数据时,需要判断head是否为null,才能找next33 // 如果没有哨兵节点,那么在添加数据时,需要判断last是否为null,才能找next34 last = head = new Node<E>(null);35}
3) 生产者方法实现
add
xxxxxxxxxx71public boolean add(E e) {2 if (offer(e))3 return true;4 else5 // 抛异常6 throw new IllegalStateException("Queue full");7}
offer
xxxxxxxxxx621public boolean offer(E e) {2 // 非空校验3 if (e == null) throw new NullPointerException();4 // 拿到存储数据条数的count5 final AtomicInteger count = this.count;6 // 查看当前数据条数,是否等于队列限制长度,达到了这个长度,直接返回false7 if (count.get() == capacity)8 return false;9 // 声明c,作为标记存在10 int c = -1;11 // 将存储的数据封装为Node对象12 Node<E> node = new Node<E>(e);13 // 获取生产者的锁。14 final ReentrantLock putLock = this.putLock;15 // 竞争锁资源16 putLock.lock();17 try {18 // 再次做一个判断,查看是否还有空间19 if (count.get() < capacity) {20 // enqueue,扔数据21 enqueue(node);22 // 将数据个数 + 123 c = count.getAndIncrement();24 // 拿到count的值 小于 长度限制25 // 有生产者在基于await挂起,这里添加完数据后,发现还有空间可以存储数据,26 // 唤醒前面可能已经挂起的生产者27 // 因为这里生产者和消费者不是互斥的,写操作进行的同时,可能也有消费者在消费数据。28 if (c + 1 < capacity)29 // 唤醒生产者30 notFull.signal();31 }32 } finally {33 // 释放锁资源34 putLock.unlock();35 }36 // 如果c == 0,代表添加数据之前,队列元素个数是0个。37 // 如果有消费者在队列没有数据的时候,来消费,此时消费者一定会挂起线程38 if (c == 0)39 // 唤醒消费者40 signalNotEmpty();41 // 添加成功返回true,失败返回-142 return c >= 0;43}44
45//================================================46private void enqueue(Node<E> node) {47 // 将当前Node设置为last的next,并且再将当前Node作为last48 last = last.next = node;49}50//================================================51private void signalNotEmpty() {52 // 获取读锁53 final ReentrantLock takeLock = this.takeLock;54 takeLock.lock();55 try {56 // 唤醒。57 notEmpty.signal();58 } finally {59 takeLock.unlock();60 }61}62sync -> wait / notify
offer(time,unit)
xxxxxxxxxx381public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {2 // 非空检验3 if (e == null) throw new NullPointerException();4 // 将时间转换为纳秒5 long nanos = unit.toNanos(timeout);6 // 标记7 int c = -1;8 // 写锁,数据条数9 final ReentrantLock putLock = this.putLock;10 final AtomicInteger count = this.count;11 // 允许中断的加锁方式12 putLock.lockInterruptibly();13 try {14 // 如果元素个数和限制个数一致,直接准备挂起15 while (count.get() == capacity) {16 // 挂起的时间是不是已经没了17 if (nanos <= 0)18 // 添加失败,返回false19 return false;20 // 挂起线程21 nanos = notFull.awaitNanos(nanos);22 }23 // 有空余位置,enqueue添加数据24 enqueue(new Node<E>(e));25 // 元素个数 + 126 c = count.getAndIncrement();27 // 当前添加完数据,还有位置可以添加数据,唤醒可能阻塞的生产者28 if (c + 1 < capacity)29 notFull.signal();30 } finally {31 // 释放锁32 putLock.unlock();33 }34 // 如果之前元素个数是0,唤醒可能等待的消费者35 if (c == 0)36 signalNotEmpty();37 return true;38}
put
xxxxxxxxxx221public void put(E e) throws InterruptedException {2 if (e == null) throw new NullPointerException();3 int c = -1;4 Node<E> node = new Node<E>(e);5 final ReentrantLock putLock = this.putLock;6 final AtomicInteger count = this.count;7 putLock.lockInterruptibly();8 try {9 while (count.get() == capacity) {10 // 一直挂起线程,等待被唤醒11 notFull.await();12 }13 enqueue(node);14 c = count.getAndIncrement();15 if (c + 1 < capacity)16 notFull.signal();17 } finally {18 putLock.unlock();19 }20 if (c == 0)21 signalNotEmpty();22}
4) 消费者方法实现
put
xxxxxxxxxx81public E remove() {2 E x = poll();3 if (x != null)4 return x;5 else6 // 抛异常7 throw new NoSuchElementException();8}
poll
xxxxxxxxxx691public E poll() {2 // 拿到队列数据个数的计数器3 final AtomicInteger count = this.count;4 // 当前队列中数据是否05 if (count.get() == 0)6 // 说明队列没数据,直接返回null即可7 return null;8 // 声明返回结果9 E x = null;10 // 标记11 int c = -1;12 // 获取消费者的takeLock13 final ReentrantLock takeLock = this.takeLock;14 // 加锁15 takeLock.lock();16 try {17 // 基于DCL,确保当前队列中依然有元素18 if (count.get() > 0) {19 // 从队列中移除数据20 x = dequeue();21 // 将之前的元素个数获取,并--22 c = count.getAndDecrement();23 if (c > 1)24 // 如果依然有数据,继续唤醒await的消费者。25 notEmpty.signal();26 }27 } finally {28 // 释放锁资源29 takeLock.unlock();30 }31 // 如果之前的元素个数为当前队列的限制长度,32 // 现在消费者消费了一个数据,多了一个空位可以添加33 if (c == capacity)34 // 唤醒阻塞的生产者35 signalNotFull();36 return x;37}38
39//================================================40
41private E dequeue() {42 // 拿到队列的head位置数据43 Node<E> h = head;44 // 拿到了head的next,因为这个是哨兵Node,需要拿到的head.next的数据45 Node<E> first = h.next;46 // 将之前的哨兵Node.next置位null。help GC。47 h.next = h; 48 // 将first置位新的head49 head = first;50 // 拿到返回结果first节点的item数据,也就是之前head.next.item51 E x = first.item;52 // 将first数据置位null,作为新的head53 first.item = null;54 // 返回数据55 return x;56}57
58//================================================59
60private void signalNotFull() {61 final ReentrantLock putLock = this.putLock;62 putLock.lock();63 try {64 // 唤醒生产者。65 notFull.signal();66 } finally {67 putLock.unlock();68 }69}
poll(time,unit)
xxxxxxxxxx321public E poll(long timeout, TimeUnit unit) throws InterruptedException {2 // 返回结果3 E x = null;4 // 标识5 int c = -1;6 // 将挂起实现设置为纳秒级别7 long nanos = unit.toNanos(timeout);8 // 拿到计数器9 final AtomicInteger count = this.count;10 // take锁加锁11 final ReentrantLock takeLock = this.takeLock;12 takeLock.lockInterruptibly();13 try {14 // 如果没数据,进到while15 while (count.get() == 0) {16 if (nanos <= 0)17 return null;18 // 挂起当前线程19 nanos = notEmpty.awaitNanos(nanos);20 }21 // 剩下内容,和之前一样。22 x = dequeue();23 c = count.getAndDecrement();24 if (c > 1)25 notEmpty.signal();26 } finally {27 takeLock.unlock();28 }29 if (c == capacity)30 signalNotFull();31 return x;32}
take
xxxxxxxxxx221public E take() throws InterruptedException {2 E x;3 int c = -1;4 final AtomicInteger count = this.count;5 final ReentrantLock takeLock = this.takeLock;6 takeLock.lockInterruptibly();7 try {8 // 相比poll(time,unit)方法,这里的出口只有一个,就是中断标记位,抛出异常,否则一直等待9 while (count.get() == 0) {10 notEmpty.await();11 }12 x = dequeue();13 c = count.getAndDecrement();14 if (c > 1)15 notEmpty.signal();16 } finally {17 takeLock.unlock();18 }19 if (c == capacity)20 signalNotFull();21 return x;22}
4. PriorityBlockingQueue
1) 基本使用
PriorityBlockingQueue是基于小顶堆实现的无界阻塞队列,适用于按优先级处理任务的场景,如任务调度系统等。
xxxxxxxxxx11// ...注意:
- PriorityBlockingQueue队列要求元素需实现
Comparable接口或在构造时指定Comparator。
2) 核心属性
xxxxxxxxxx161/** 存储元素的底层数组(基于二叉堆实现优先级排序) */2private transient Object[] queue;3/** 队列中当前元素的数量 */4private transient int size;5/** 优先级比较器(null则使用元素自身的Comparable接口) */6private transient Comparator<? super E> comparator;7
8/** 保证所有操作线程安全的重入锁 */9private final ReentrantLock lock;10/** 队列非空的条件变量(仅用于take()阻塞,无notFull!) */11private final Condition notEmpty;12/** 扩容时的自旋锁(CAS实现,避免扩容和入队操作冲突) */13private transient volatile int allocationSpinLock;14
15/** 数组最大容量(防止扩容时数组过大导致OOM,值为Integer.MAX_VALUE - 8) */16private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
3) 生产者方法实现
offer
xxxxxxxxxx341public boolean offer(E e) {2 // 非空判断。3 if (e == null)4 throw new NullPointerException();5 // 拿到锁,直接上锁6 final ReentrantLock lock = this.lock;7 lock.lock();8 // n:size,元素的个数9 // cap:当前数组的长度10 // array:就是存储数据的数组11 int n, cap;12 Object[] array;13 while ((n = size) >= (cap = (array = queue).length))14 // 如果元素个数大于等于数组的长度,需要尝试扩容。15 tryGrow(array, cap);16 try {17 // 拿到了比较器18 Comparator<? super E> cmp = comparator;19 // 比较数据大小,存储数据,是否需要做上移操作,保证平衡的20 if (cmp == null)21 siftUpComparable(n, e, array);22 else23 siftUpUsingComparator(n, e, array, cmp);24 // 元素个数 + 125 size = n + 1;26 // 如果有挂起的线程,需要去唤醒挂起的消费者。27 notEmpty.signal();28 } finally {29 // 释放锁30 lock.unlock();31 }32 // 返回true33 return true;34}
tryGrow(扩容)
xxxxxxxxxx511private void tryGrow(Object[] array, int oldCap) {2 // 释放锁资源。3 lock.unlock(); 4 // 声明新数组。5 Object[] newArray = null;6 // 如果allocationSpinLock属性值为0,说明当前没有线程正在扩容的。7 if (allocationSpinLock == 0 &&8 // 基于CAS的方式,将allocationSpinLock从0修改为1,代表当前线程可以开始扩容9 UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,0, 1)) {10 try {11 // 计算新数组长度12 int newCap = oldCap + ((oldCap < 64) ?13 // 如果数组长度比较小,这里加快扩容长度速度。14 (oldCap + 2) : 15 // 如果长度大于等于64了,每次扩容到1.5倍即可。16 (oldCap >> 1));17 // 如果新数组长度大于MAX_ARRAY_SIZE,需要做点事了。18 if (newCap - MAX_ARRAY_SIZE > 0) { 19 // 声明minCap,长度为老数组 + 120 int minCap = oldCap + 1;21 // 老数组+1变为负数,或者老数组长度已经大于MAX_ARRAY_SIZE了,无法扩容了。22 if (minCap < 0 || minCap > MAX_ARRAY_SIZE)23 // 告辞,凉凉~~~~24 throw new OutOfMemoryError();25 // 如果没有超过限制,直接设置为最大长度即可26 newCap = MAX_ARRAY_SIZE;27 }28 // 新数组长度,得大于老数组长度,29 // 第二个判断确保没有并发扩容的出现。30 if (newCap > oldCap && queue == array)31 // 构建出新数组32 newArray = new Object[newCap];33 } finally {34 // 新数组有了,标记位归0~~35 allocationSpinLock = 0;36 }37 }38 // 如果到了这,newArray依然为null,说明这个线程没有进到if方法中,去构建新数组39 if (newArray == null) 40 // 稍微等一手。41 Thread.yield();42 // 拿锁资源,43 lock.lock();44 // 拿到锁资源后,确认是构建了新数组的线程,这里就需要将新数组复制给queue,并且导入数据45 if (newArray != null && queue == array) {46 // 将新数组赋值给queue47 queue = newArray;48 // 将老数组的数据全部导入到新数组中。49 System.arraycopy(array, 0, newArray, 0, oldCap);50 }51}
siftUpComparable(上浮)
xxxxxxxxxx251// k:当前元素的个数(其实就是要放的索引位置)2// x:需要添加的数据3// array:数组。。4private static <T> void siftUpComparable(int k, T x, Object[] array) {5 // 将插入的元素直接强转为Comparable(com.mashibing.User cannot be cast to java.lang.Comparable)6 // 这行强转,会导致添加没有实现Comparable的元素,直接报错。7 Comparable<? super T> key = (Comparable<? super T>) x;8 // k大于0,走while逻辑。(原来有数据)9 while (k > 0) {10 // 获取父节点的索引位置。11 int parent = (k - 1) >>> 1;12 // 拿到父节点的元素。13 Object e = array[parent];14 // 用子节点compareTo父节点,如果 >= 0,说明当前son节点比parent要大。15 if (key.compareTo((T) e) >= 0)16 // 直接break,完事,17 break;18 // 将son节点的位置设置上之前的parent节点19 array[k] = e;20 // 重新设置x节点需要放置的位置。21 k = parent;22 }23 // k == 0,当前元素是第一个元素,直接插入进去。24 array[k] = key;25}
4) 消费者方法实现
poll
xxxxxxxxxx111public E poll() {2 final ReentrantLock lock = this.lock;3 // 加锁4 lock.lock();5 try {6 // 拿到返回数据,没拿到,返回null7 return dequeue();8 } finally {9 lock.unlock();10 }11}
poll(time,unit)
xxxxxxxxxx181public E poll(long timeout, TimeUnit unit) throws InterruptedException {2 // 将挂起的时间转换为纳秒3 long nanos = unit.toNanos(timeout);4 final ReentrantLock lock = this.lock;5 // 允许线程中断抛异常的加锁6 lock.lockInterruptibly();7 // 声明结果8 E result;9 try {10 // dequeue是去拿数据的,可能会出现拿到的数据为null,如果为null,同时挂起时间还有剩余,这边就直接通过notEmpty挂起线程11 while ( (result = dequeue()) == null && nanos > 0)12 nanos = notEmpty.awaitNanos(nanos);13 } finally {14 lock.unlock();15 }16 // 有数据正常返回,没数据,告辞~17 return result;18}
take
xxxxxxxxxx411public E take() throws InterruptedException {2 final ReentrantLock lock = this.lock;3 lock.lockInterruptibly();4 E result;5 try {6 while ( (result = dequeue()) == null)7 // 无线等,要么有数据,要么中断线程8 notEmpty.await();9 } finally {10 lock.unlock();11 }12 return result;13}14
15private E dequeue() {16 // 将元素个数-1,拿到了索引位置。17 int n = size - 1;18 // 判断是不是木有数据了,没数据直接返回null即可19 if (n < 0)20 return null;21 // 说明有数据22 else {23 // 拿到数组,array24 Object[] array = queue;25 // 拿到0索引位置的数据26 E result = (E) array[0];27 // 拿到最后一个数据28 E x = (E) array[n];29 // 将最后一个位置置位null30 array[n] = null;31 Comparator<? super E> cmp = comparator;32 if (cmp == null)33 siftDownComparable(0, x, array, n);34 else35 siftDownUsingComparator(0, x, array, n, cmp);36 // 元素个数-1,赋值size37 size = n;38 // 返回result39 return result;40 }41}
siftDownComparable(下移平衡二叉堆)
xxxxxxxxxx371// k:默认进来是02// x:代表二叉堆的最后一个数据3// array:数组4// n:最后一个索引5private static <T> void siftDownComparable(int k, T x, Object[] array,int n) {6 // 健壮性校验,取完第一个数据,已经没数据了,那就不需要做平衡操作7 if (n > 0) {8 // 拿到最后一个数据的比较器9 Comparable<? super T> key = (Comparable<? super T>)x;10 // 因为二叉堆是一个二叉满树,所以在保证二叉堆结构时,只需要做一半就可以11 int half = n >>> 1; 12 // 做了超过一半,就不需要再往下找了。13 while (k < half) {14 // 找左子节点索引,一个公式,可以找到当前节点的左子节点15 int child = (k << 1) + 1; 16 // 拿到左子节点的数据17 Object c = array[child];18 // 拿到右子节点索引19 int right = child + 1;20 // 确认有右子节点21 // 判断左节点是否大于右节点22 if (right < n && c.compareTo(array[right]) > 0)23 // 如果左大于右,那么c就执行右24 c = array[child = right];25 // 比较最后一个节点是否小于当前的较小的子节点26 if (key.compareTo((T) c) <= 0)27 break;28 // 将左右子节点较小的放到之前的父节点位置29 array[k] = c;30 // k重置到之前的子节点位置31 k = child;32 }33 // 上面while循环搞定后,可以确认整个二叉堆中,数据已经移动ok了,只差当前k的位置数据是null34 // 将最后一个索引的数据放到k的位置35 array[k] = key;36 }37}
5. DelayQueue
1) 基本使用
DelayQueue是基于优先级队列实现的无界阻塞队列,存入的元素必须在延时到期后才能被取出,适用于 定时任务等场景。
xxxxxxxxxx701// Delayed接口(可比较且可延迟的)2public interface Delayed extends Comparable<Delayed> {3 long getDelay(TimeUnit unit); // 剩余延迟时间,0表示不再延迟4}5
6// 使用DelayQueue实现定时任务7public class DelayedQueueDemo {8 private static final AtomicLong taskSequencer = new AtomicLong(0); 9
10 // 1. 定时任务(Delayed接口实现类)11 static class DelayedTask implements Delayed {12 private long runTime; // 开始运行的时间(第一次序)13 private long sequence; // 运行顺序(第二次序)14 private Runnable task; // 实际执行的任务15
16 public DelayedTask(int delayedSeconds, Runnable task) {17 this.runTime = System.currentTimeMillis() + delayedSeconds * 1000; // 当前时间+延时时间18 this.sequence = taskSequencer.getAndIncrement(); // 自增ID19 this.task = task;20 }21
22 // 1.1 实现compareTo方法23 24 public int compareTo(Delayed o) {25 if (o == this) {26 return 0;27 }28 if (o instanceof DelayedTask) {29 DelayedTask other = (DelayedTask) o;30 if (runTime < other.runTime) {31 return -1;32 } else if (runTime > other.runTime) {33 return 1;34 } else if (sequence < other.sequence) {35 return -1;36 } else {37 return 1;38 }39 }40 throw new IllegalArgumentException();41 }42
43 // 1.2 实现getDelay方法44 45 public long getDelay(TimeUnit unit) {46 return unit.convert(runTime - System.currentTimeMillis(), TimeUnit.MICROSECONDS);47 }48
49 public Runnable getTask() {50 return task;51 }52 }53
54 // 2. 启动定时任务55 public static void main(String[] args) throws InterruptedException {56 // 2.1 构建延时队列57 DelayQueue<DelayedTask> tasks = new DelayQueue<>();58 tasks.put(new DelayedTask(2, new Runnable() {59 60 public void run() {61 System.out.println("execute delayed task");62 }63 }));64
65 // 2.2 从延时队列中取任务执行,如果未到时间则阻塞66 DelayedTask task = tasks.take();67 task.getTask().run();68 }69}70
注意:
- DelayQueue要求元素必须实现
Delayed接口,指定延迟时间。
2) 核心属性
xxxxxxxxxx91/** 底层存储容器,复用PriorityBlockingQueue实现按延迟时间排序 */2private final PriorityQueue<E> q = new PriorityQueue<E>();3/** 保证所有操作线程安全的重入锁(统一管控队列操作) */4private final ReentrantLock lock = new ReentrantLock();5/** 用于等待队列中最早到期元素的条件变量 */6private final Condition available = lock.newCondition();7
8/** 优化性属性:记录当前正在等待堆顶元素到期的线程(避免多线程无效等待) */9private Thread leader = null;
3) 生产者方法实现(略)
4) 消费者方法实现(略)
6. SynchronousQueue
1) 基本使用
SynchronousQueue(实时队列)是容量为0的特殊阻塞队列,入队操作(put)必须等待对应的出队操作(take),适用于线程间直接传递数据的场景,是CachedThreadPool的默认队列。
xxxxxxxxxx311import java.util.concurrent.SynchronousQueue;2import java.util.concurrent.BlockingQueue;3
4public class SynchronousQueueDemo {5 public static void main(String[] args) {6 BlockingQueue<String> queue = new SynchronousQueue<>();7 8 // 生产者线程9 new Thread(() -> {10 try {11 System.out.println("生产者准备放入数据");12 queue.put("直接传递的数据"); // 阻塞,直到消费者取出13 System.out.println("生产者数据放入成功");14 } catch (InterruptedException e) {15 Thread.currentThread().interrupt();16 }17 }).start();18 19 // 消费者线程20 new Thread(() -> {21 try {22 Thread.sleep(1000); // 模拟延迟23 System.out.println("消费者准备取出数据");24 String data = queue.take(); // 取出数据,唤醒生产者25 System.out.println("消费者取出数据:" + data);26 } catch (InterruptedException e) {27 Thread.currentThread().interrupt();28 }29 }).start();30 }31}
2) 核心属性
xxxxxxxxxx71/** 抽象核心类:封装线程间数据交换的逻辑(所有操作都基于这个类的实现) */2private transient volatile Transferer<E> transferer;3
4/** 公平模式标识(true=公平/TransferQueue,false=非公平/TransferStack) */5private final boolean fair;6/** 仅公平模式下使用的自旋锁(CAS实现,保护TransferQueue的尾节点) */7private transient volatile int qlock;
3) 生产者方法实现(略)
4) 消费者方法实现(略)
7. Disruptor
第四节 并发容器
1. CopyOnWriteList
1) 基本使用
CopyOnWriteArrayList 是一个线程安全的 ArrayList ,是基于写时复制机制(Copy On Write,简称 COW)实现的。
- 写操作(添加、删除、修改)会先复制一份新数组,在新数组上完成操作后,再将原数组的引用指向新数组;
- 读操作直接访问原数组,无需加锁,读写兼容,同样也是弱一致性的。
xxxxxxxxxx31// 额外支持的复合操作2public boolean addIfAbsent(E e) // 不存在才添加,如果添加了,返回true,否则返回false3public int addAllAbsent(Collection<? extends E> c) // 批量添加c中的非重复元素,不存在才添加,返回实际添加的个数注意:
- JUC还提供了一个
CopyOnWriteArraySet,基于在CopyOnWriteArrayList的复合操作addIfAbsent实现的。
2) 核心属性&构造
xxxxxxxxxx141// 存储数组(被 volatile 修饰,保证多线程下的可见性)2private transient volatile Object[] array;3
4// 可重入锁,保证写操作的原子性,避免多个线程同时执行 “复制数组 + 修改 + 替换引用” 的操作5final transient ReentrantLock lock = new ReentrantLock();6
7/**8 * 默认new的CopyOnWriteArrayList数组长度为0。9 * 不像ArrayList,初始长度是10,每次扩容1/2, CopyOnWriteArrayList不存在这个概念10 * 每次写的时候都会构建一个新的数组11 */12public CopyOnWriteArrayList() {13 setArray(new Object[0]);14}
2) 读操作(get)
读操作就是基于数组索引位置获取数据,始终读取的是原数组,不需要加锁。
xxxxxxxxxx111// 查询数据时,只能通过get方法查询CopyOnWriteArrayList中的数据2public E get(int index) {3 // getArray拿到array数组,调用get方法的重载4 return get(getArray(), index);5}6
7// 执行get(int)时,内部调用的方法8private E get(Object[] a, int index) {9 // 直接拿到数组上指定索引位置的值10 return (E) a[index];11}
3) 写操作(add)
CopyOnWriteArrayList是基于lock锁和副本数组的形式保证线程安全。
xxxxxxxxxx651// 写入元素,不指定索引位置,直接放到最后的位置2public boolean add(E e) {3 // 获取全局锁,并执行lock4 final ReentrantLock lock = this.lock;5 lock.lock();6 try {7 // 获取原数组,还获取了原数组的长度8 Object[] elements = getArray();9 int len = elements.length;10 // 基于原数组复制一份副本数组,并且长度比原来多了一个11 Object[] newElements = Arrays.copyOf(elements, len + 1);12 // 将添加的数据放到副本数组最后一个位置13 newElements[len] = e;14 // 将副本数组,赋值给CopyOnWriteArrayList的原数组15 setArray(newElements);16 // 添加成功,返回true17 return true;18 } finally {19 // 释放锁~20 lock.unlock();21 }22}23
24// 写入元素,指定索引位置。(不会覆盖数据)25public void add(int index, E element) {26 // 拿锁,加锁~27 final ReentrantLock lock = this.lock;28 lock.lock();29 try {30 // 获取原数组,还获取了原数组的长度31 Object[] elements = getArray();32 int len = elements.length;33 // 如果索引位置大于原数组的长度,或者索引位置是小于0的。34 if (index > len || index < 0)35 throw new IndexOutOfBoundsException("Index: "+index+36 ", Size: "+len);37 // 声明了副本数组38 Object[] newElements;39 // 原数组长度 - 索引位置等到numMoved40 int numMoved = len - index;41 // 如果numMoved为0,说明数据要放到最后面的位置42 if (numMoved == 0)43 // 直接走了原生态的方式,正常复制一份副本数组44 newElements = Arrays.copyOf(elements, len + 1);45 else {46 // 数组要插入的位置不是最后一个位置47 // 副本数组长度依然是原长度 + 148 newElements = new Object[len + 1];49 // 将原数组从0索引位置开始复制,复制到副本数组中的前置位置50 System.arraycopy(elements, 0, newElements, 0, index);51 // 将原数组从index位置开始复制,复制到副本数组的index + 1往后放。52 // 这时,index就空缺出来了。53 System.arraycopy(elements, index, newElements, index + 1,54 numMoved);55 }56 // 数据正常放到指定的索引位置57 newElements[index] = element;58 // 将副本数组,赋值给CopyOnWriteArrayList的原数组59 setArray(newElements);60 } finally {61 // 释放锁62 lock.unlock();63 }64}65
4) 删除操作(remove)
删除操作分为两种,一种是基于数组索引进行删除,另一种是基于元素值删除查找到的第一个元素。
xxxxxxxxxx1031// 删除指定索引位置的数据2public E remove(int index) {3 // 拿锁,加锁4 final ReentrantLock lock = this.lock;5 lock.lock();6 try {7 // 获取原数组和原数组长度8 Object[] elements = getArray();9 int len = elements.length;10 // 通过get方法拿到index位置的数据11 E oldValue = get(elements, index);12 // 声明numMoved13 int numMoved = len - index - 1;14 // 如果numMoved为0,说明删除的元素是最后的位置15 if (numMoved == 0)16 // Arrays.copyOf复制一份新的副本数组,并且将最后一个数据不要了17 // 基于setArray将副本数组赋值给array原数组18 setArray(Arrays.copyOf(elements, len - 1));19 else {20 // 删除的元素不在最后面的位置21 // 声明副本数组,长度是原数组长度 - 122 Object[] newElements = new Object[len - 1];23 // 从0开始复制的index前面24 System.arraycopy(elements, 0, newElements, 0, index);25 // 从index后面复制到最后26 System.arraycopy(elements, index + 1, newElements, index,27 numMoved);28 setArray(newElements);29 }30 // 返回被干掉的数据31 return oldValue;32 } finally {33 // 释放锁34 lock.unlock();35 }36}37
38// 删除元素(最前面的)39public boolean remove(Object o) {40 // 没加锁!!!!41 // 获取原数组42 Object[] snapshot = getArray();43 // 用indexOf获取元素在数组的哪个索引位置44 // 没找到的话,返回-145 int index = indexOf(o, snapshot, 0, snapshot.length);46 // 如果index < 0,说明元素没找到,直接返回false,告辞47 // 如果找到了元素的位置,直接执行remove方法的重载48 return (index < 0) ? false : remove(o, snapshot, index);49}50// 执行remove(Object o),找到元素位置时,执行当前方法51private boolean remove(Object o, Object[] snapshot, int index) {52 // 拿锁,加锁53 final ReentrantLock lock = this.lock;54 lock.lock();55 try {56 // 拿到原数组和长度57 Object[] current = getArray();58 int len = current.length;59 // findIndex: 是给if起标识,break 标识的时候,直接跳出if的代码块~~60 if (snapshot != current) findIndex: {61 // 如果没进到if,说明数组没变化,按照原来的index位置删除即可62 // 进到这,说明数组有变化,之前的索引位置不一定对63 // 拿到index位置和原数组长度的值64 int prefix = Math.min(index, len);65 // 循环判断,数组变更后,是否影响到了要删除元素的位置66 for (int i = 0; i < prefix; i++) {67 // 如果不相等,说明元素变化了。68 // 同时判断变化的元素是否是我要删除的元素o69 if (current[i] != snapshot[i] && eq(o, current[i])) {70 // 如果满足条件,说明当前位置就是我要删除的元素71 index = i;72 break findIndex;73 }74 }75 // 如果for循环结束,没有退出if,说明元素可能变化了,总之没找到要删除的元素76 // 如果删除元素的位置,已经大于等于数组长度了。77 if (index >= len)78 // 超过索引范围了,没法删除了。79 return false;80 // 索引还在范围内,判断是否是还是原位置,如果是,直接跳出if代码块81 if (current[index] == o)82 break findIndex;83 // 重新找元素在数组中的位置84 index = indexOf(o, current, index, len);85 // 找到直接跳出if代码块86 // 没找到。执行下面的return false87 if (index < 0)88 return false;89 }90 // 删除套路,构建新数组,复制index前的,复制index后的91 Object[] newElements = new Object[len - 1];92 System.arraycopy(current, 0, newElements, 0, index);93 System.arraycopy(current, index + 1,94 newElements, index,95 len - index - 1);96 // 复制到array97 setArray(newElements);98 // 返回true,删除成功99 return true;100 } finally {101 lock.unlock();102 }103}
5) 修改操作(set)
xxxxxxxxxx321// 修改数据2public E set(int index, E element) {3 // 拿锁,加锁4 final ReentrantLock lock = this.lock;5 lock.lock();6 try {7 // 获取原数组8 Object[] elements = getArray();9 // 获取原数组的原位置数据10 E oldValue = get(elements, index);11
12 // 原数据和新数据不一样13 if (oldValue != element) {14 // 拿到原数据的长度,复制一份副本。15 int len = elements.length;16 Object[] newElements = Arrays.copyOf(elements, len);17 // 将element替换掉副本数组中的数据18 newElements[index] = element;19 // 写回原数组20 setArray(newElements);21 } else {22 // 原数据和新数据一样,啥不干,把拿出来的数组再写回去23 setArray(elements);24 }25 // 返回原值26 return oldValue;27 } finally {28 // 释放锁29 lock.unlock();30 }31}32
6) 清空操作(clear)
xxxxxxxxxx111public void clear() {2 // 加锁3 final ReentrantLock lock = this.lock;4 lock.lock();5 try {6 // 扔一个长度为0的数组7 setArray(new Object[0]);8 } finally {9 lock.unlock();10 }11}
7) 迭代操作
用ArrayList时,如果想在遍历的过程中去移除或者修改元素,必须使用迭代器才可以。
但是CopyOnWriteArrayList中即便用了迭代器也不让做写操作,因为不希望迭代时,还需要加锁。
xxxxxxxxxx801// 获取遍历CopyOnWriteArrayList的iterator。2public Iterator<E> iterator() {3 // 其实就是new了一个COWIterator对象,并且获取了array,指定从0开始遍历4 return new COWIterator<E>(getArray(), 0);5}6
7static final class COWIterator<E> implements ListIterator<E> {8 /** 遍历的快照 */9 private final Object[] snapshot;10 /** 游标,索引~~~ */11 private int cursor;12
13 // 有参构造14 private COWIterator(Object[] elements, int initialCursor) {15 cursor = initialCursor;16 snapshot = elements;17 }18
19 // 有没有下一个元素,基于遍历的索引位置和数组长度查看20 public boolean hasNext() {21 return cursor < snapshot.length;22 }23 // 有没有上一个元素24 public boolean hasPrevious() {25 return cursor > 0;26 }27
28 // 获取下一个值,游标动一下29 public E next() {30 // 确保下个位置有数据31 if (! hasNext())32 throw new NoSuchElementException();33 return (E) snapshot[cursor++];34 }35
36 // 获取上一个值,游标往上移动37 public E previous() {38 if (! hasPrevious())39 throw new NoSuchElementException();40 return (E) snapshot[--cursor];41 }42
43 // 拿到下一个值的索引,返回游标44 public int nextIndex() {45 return cursor;46 }47
48 // 拿到上一个值的索引,返回游标49 public int previousIndex() {50 return cursor-1;51 }52
53 // 写操作全面禁止!!54 public void remove() {55 throw new UnsupportedOperationException();56 }57
58 59 public void set(E e) {60 throw new UnsupportedOperationException();61 }62
63 64 public void add(E e) {65 throw new UnsupportedOperationException();66 }67
68 // 兼容函数式编程69 70 public void forEachRemaining(Consumer<? super E> action) {71 Objects.requireNonNull(action);72 Object[] elements = snapshot;73 final int size = elements.length;74 for (int i = cursor; i < size; i++) {75 ("unchecked") E e = (E) elements[i];76 action.accept(e);77 }78 cursor = size;79 }80}
2. ConcurrentHashMap
1) 基本使用
ConcurrentHashMap是一个线程安全且高效的HashMap,读操作完全并行,写操作支持一定程度的并行。
xxxxxxxxxx111// 构造方法,可设置分段数,其中concurrencyLevel表示并行更新的线程个数,将会转为2的整数次幂2public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) 3 4// 条件更新,如果Map中没有key,设置key为value,返回原来key对应的值,如果没有,返回null5V putIfAbsent(K key, V value);6// 条件删除,如果Map中有key,且对应的值为value,则删除,如果删除了,返回true,否则false7boolean remove(Object key, Object value);8// 条件替换,如果Map中有key,且对应的值为oldValue,则替换为newValue,如果替换了,返回ture,否则false9boolean replace(K key, V oldValue, V newValue);10// 条件替换,如果Map中有key,则替换值为value,返回原来key对应的值,如果原来没有,返回null11V replace(K key, V value);注意:
- 可以使用Collections.newSetFromMap方法基于ConcurrentHashMap构建一个线程安全的HashSet。
- HashMap在在多个线程同时扩容哈希表的时候,链表结构可能形成环,出现死循环,占满CPU。
2) 存储结构
在JDK1.8中,ConcurrentHashMap的存储结构为数组+链表+红黑树:
3) 核心属性
xxxxxxxxxx201// 存储数组,元素类型为 Node<K,V>(哈希桶的基本节点)2transient volatile Node<K,V>[] table;3
4// 扩容中转数组5private transient volatile Node<K,V>[] nextTable;6
7// 控制扩容 / 初始化的核心标识8// 一个多功能的整型变量,不同取值代表不同状态:9// sizeCtl = 0 默认值,表示数组未初始化10// sizeCtl > 0 数组初始化时:表示数组的初始容量;初始化后:表示扩容的阈值(负载因子 × 容量)11// sizeCtl = -1 表示有线程正在初始化数组(CAS 抢占初始化权限)12// sizeCtl = -(1 + n) 表示有 n 个线程正在协助扩容(负数的绝对值 - 1 是扩容线程数)13private transient volatile int sizeCtl;14
15// 链表转红黑树的阈值(链表长度≥8 时触发)16static final int TREEIFY_THRESHOLD = 8;17// 红黑树转链表的阈值(扩容时链表长度≤6 时触发)18static final int UNTREEIFY_THRESHOLD = 6;19// 触发树化的最小数组容量(数组长度≥64 才会树化,否则先扩容)20static final int MIN_TREEIFY_CAPACITY = 64;注意:
- 在JDK1.7中,ConcurrentHashMap基于分段锁实现,核心属性有所不同。
4) 写入操作流程(put)
将key进行散列运算,计算出具体的hash值。后面要基于这个hash值确定数据存放的索引位置。
循环开始-------------------------------------------------------------------
查看ConcurrentHashMap的 数组是否已经初始化 。(数组全局唯一,懒加载)
- 初始化就继续尝试存放数据。
- 没初始化,那就先尝试将数组new出来。
基于hash值,确认数据要存放的索引位置 。
如果数组索引位置没数据,将当前数据扔进去。优先将key-value封装为一个Node对象。这里为了保证线程安全, 直接采用CAS的方式,将当前索引位置的null替换为指定的Node数据 。
- 如果CAS成功,循环结束
- 如果CAS失败,重新走循环
如果数组索引有数据,往后走其他流程
如果有数据,查看当前数据的状态 是否是扩容的情况 。MOVED(hash = -1)
- 如果正在扩容,当前线程去 协助扩容 ,加快扩容速度。协助扩容结束后,重新走循环。
如果有数据,没有扩容操作影响到当前线程。
加锁,基于数组索引位置的Node对象作为 synchronized的锁 。
将数据 挂到链表的末端 。
- 添加数据到链表后,会查看链表长度,是否达到了8个,就需要尝试链表转红黑树 。CHM要求必须数组长度 ≥ 64 && 链表长度达到8才会转换。
将数据 添加到红黑树 结构中。TREEBIN(hash = -2)
循环结束---------------------------------------------------------------------
需要记录元素个数,为了保证线程安全,这里采用了 LongAdder做计数器 。
添加数据结束。
5) 扩容流程
ConcurrentHashMap扩容操作只有两个事情:
- 构建新数组,长度是老数组长度的二倍。(new)
- 将老数组中的数据,迁移到新数组中。
区分第一个来扩容和协助扩容的方式:
为了区分谁是第一个来扩容的线程,谁是来协助扩容的线程,需要掌握一个属性,这个属性就是sizeCtl
xxxxxxxxxx11private transient volatile int sizeCtl;第一个来扩容的线程会优先修改sizeCtl的值,将其修改为一个<-1的值。
其他所有来协助扩容的线程,发现sizeCtl<-1,直接对sizeCtl做 + 1操作,代表我来扩容了。
修改sizeCtl的操作,是基于CAS完成的。
第一个来扩容的线程,由他去初始化新数组,并且做迁移数据的操作。协助扩容的线程,就是来帮忙将老数组的数据迁移到新数组的。
整体扩容的流程(以第一个来扩容的线程)
计算每次迁移多长索引位置的数据到新数组( 步长 ),会根据CPU内核数和数组长度来计算,最小是16。
会由 第一个来扩容的线程 , 初始化新数组 ,长度为原来的二倍。
迁移数据循环开始-------------------------------------------------------------------------
扩容的线程开始 领取迁移数据的任务 。
- 领取到任务的,准备干活。
- 没领取到任务,可以退出扩容
没领取到的查看一下, 扩容结束了么?
- 结束了,说明当前线程是最后一个退出扩容的线程, 整体检查一遍 ,退出滴干活。
- 没结束呢,sizeCtl - 1 ,退出的滴干活。
领取到迁移数据操作,在迁移任务中某一个索引位置时,会有不同的情况
当前 索引位置没数据 ,直接仍一个MOVED(hash = -1)
当前 索引位置是MOVED ,啥事不做。(扩容操作最后会有一个大检查)
当前位置有数据,锁住当前位置:
- 链表迁移新数组
- 红黑树迁移到新数组 (红黑树会保留一个双向链表,利用双向链表迁移的)
迁移数据循环结束-------------------------------------------------------------------------
6) 查询操作流程(get)
ConcurrentHashMap本来就是作为JVM缓存使用的,对查询速度要求极高。所以在ConcurrentHashMap中 查询操作永远不会阻塞 。无论什么情况,都能去查数据。
查询数据的操作无非就是几种情况:
数据在数组上呢,查的嗷嗷快。
数据在链表上呢,next,next的找,找到返回。
如果数组上的Node是MOVED状态, 代表数据已经迁移到新数组上了,直接去新数组上查询数据 。
如果数组上的Node是RESERVED状态, 代表当前位置被占了,但是value还在计算中,返回null 。
数据在红黑树上呢:
- 如果此时 有写线程正在平衡红黑树或者是等待平衡红黑树,那么读线程会去查询保留的双向链表 。
- 如果此时 没有写线程正在平衡或等待平衡操作,直接去红黑树中找数据 。(如果此时有写线程想操作红黑树,那么需要等到读线程完毕后,才可以操作)
lockState == 1:有写线程正在平衡红黑树。
lockState == 2:代表写线程在等着平衡红黑树。
lockState >= 4:代表有读线程在读取红黑树中的数据。(读线程来读数据,就对lockState + 4)
红黑树是一个平衡的二叉树,怎么保持平衡的?
为了保证平衡,写操作可能会旋转某个节点,导致节点的指针发生变化。如果此时读线程在红黑树中遍历找数据,结果写线程改变了红黑树的指针,导致无法找到对应的数据。
系统讲解~~~
3. ConcurrentSkipListMap
1) SkipList
SkipList称为跳表或跳跃表,是一种基于有序链表的多级索引数据结构,使其更易于实现高效并发算法。
下面是一个包含3, 6, 7, 9, 12, 17, 19, 21, 25, 26元素的跳表结构,两条线展示了查找值19和8的过程:
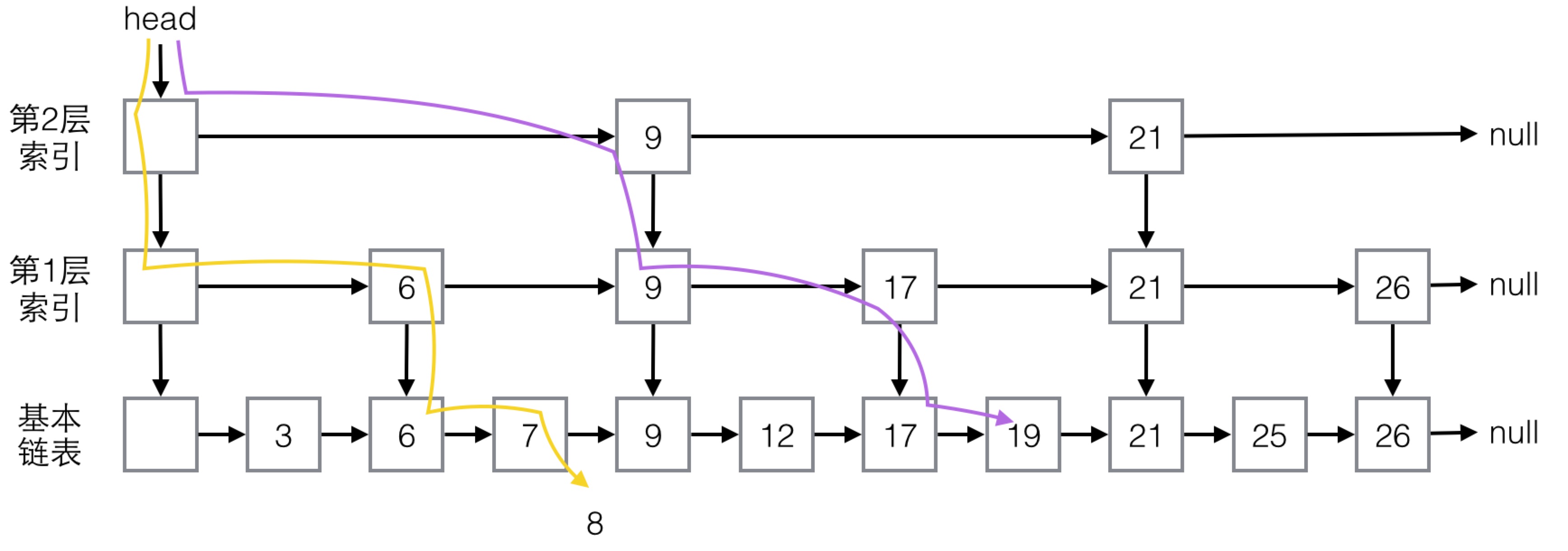
2) ConcurrentSkipListMap
ConcurrentSkipListMap实现了ConcurrentMap和SortedMap等接口,是线程安全的TreeMap,要求Key可比较或传入比较器。
xxxxxxxxxx71public static void main(String[] args) {2 Map<String, String> map = new ConcurrentSkipListMap<>(Collections.reverseOrder());3 map.put("a", "abstract");4 map.put("c", "call");5 map.put("b", "basic");6 System.out.println(map.toString()); // {c=call, b=basic, a=abstract}7}注意:
- ConcurrentSkipListMap的size方法不是常量操作,需要遍历所有元素,且遍历结束后size可能已改变,因此一般用处不大。
- TreeSet是基于TreeMap实现的,与此类似,也提供了基于ConcurrentSkipListMap的ConcurrentSkipListSet。
4. ConcurrentLinkedQueue
1) 基本使用
ConcurrentLinkedQueue是一个线程安全且无锁的单向链表实现,是LinkedList的线程安全版本。
xxxxxxxxxx401import java.util.Iterator;2import java.util.concurrent.ConcurrentLinkedQueue;3
4public class ConcurrentLinkedQueueDemo {5 public static void main(String[] args) {6 // 1. 创建 ConcurrentLinkedQueue 实例7 ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();8
9 // 2. 入队操作(offer(),无阻塞,始终返回true)10 queue.offer("任务1");11 queue.offer("任务2");12 queue.offer("任务3");13
14 // 3. 出队操作(poll(),队列为空时返回null)15 String task1 = queue.poll();16 System.out.println("取出的任务:" + task1); // 输出:取出的任务:任务117
18 // 4. 查看队首元素(peek(),不删除,队列为空返回null)19 String peekTask = queue.peek();20 System.out.println("队首任务:" + peekTask); // 输出:队首任务:任务221
22 // 5. 遍历队列(弱一致性,遍历中修改不抛异常)23 Iterator<String> iterator = queue.iterator();24 while (iterator.hasNext()) {25 String task = iterator.next();26 System.out.println("遍历任务:" + task);27 // 遍历中入队28 if (task.equals("任务2")) {29 queue.offer("任务4");30 }31 }32
33 // 6. 最终队列内容34 System.out.println("最终队列:" + queue); // 输出:最终队列:[任务2, 任务3, 任务4]35
36 // 7. 清空队列(可选)37 queue.clear();38 System.out.println("清空后队列是否为空:" + queue.isEmpty()); // 输出:true39 }40}
2) 实现原理
直接基于CAS原子操作+自旋来保证并发安全,核心结构是带有 head(头节点)和 tail(尾节点)的单向链表:
5. synchronizedCollection
1) 基本使用
Collections类可对部分普通容器进行修饰,对每个容器方法都加上synchronized,使其具备线程安全性:
xxxxxxxxxx31public static <T> Collection<T> synchronizedCollection(Collection<T> c)2public static <T> List<T> synchronizedList(List<T> list)3public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)注意:
- 在并发访问量比较大时,同步容器的性能较差,推荐使用Concurrent系列的并发容器,性能更高且支持复合操作。
2) 复合操作
在基于同步容器的方法进行复合操作时,不能保证原子性:
xxxxxxxxxx221// 自定义Map2public class EnhancedMap <K, V> {3 Map<K, V> map;4 5 public EnhancedMap(Map<K,V> map){6 // 1. 修饰为同步的Map7 this.map = Collections.synchronizedMap(map); 8 }9 10 // 2. 期望实现putIfAbsent的原子操作,但这是不符合预期的11 // - 虽然map.get(key)和map.put(key, value)是原子操作,但putIfAbsent并不是12 // - 即使给putIfAbsent加上synchronized,由于锁对象不同,也并非原子操作13 public V putIfAbsent(K key, V value){14 V old = map.get(key);15 if(old!=null){16 return old;17 }18 map.put(key, value);19 return null;20 }21}22
如需解决上述问题,可在putIfAbsent方法中使用synchronized代码块,并且使用map进行加锁,这样锁对象就是同一个了。
xxxxxxxxxx111public V putIfAbsent(K key, V value){2 // synchronized,使用map进行加锁3 synchronized(map){4 V old = map.get(key);5 if(old!=null){6 return old;7 }8 map.put(key, value);9 return null; 10 }11}
3) 并发修改异常
在增删元素的同时进行迭代操作,可能会被检测到结构变更,抛出ConcurrentModificationException。
xxxxxxxxxx381private static void startModifyThread(final List<String> list) {2 Thread modifyThread = new Thread(new Runnable() {3 4 public void run() {5 // 1. 线程1:增删list的元素6 for (int i = 0; i < 100; i++) {7 list.add("item " + i);8 try {9 Thread.sleep((int) (Math.random() * 10));10 } catch (InterruptedException e) {11 }12 }13 }14 });15 modifyThread.start();16}17
18private static void startIteratorThread(final List<String> list) {19 Thread iteratorThread = new Thread(new Runnable() {20 21 public void run() {22 // 2. 线程2:重复进行遍历操作23 while (true) {24 for (String str : list) {25 }26 }27 }28 });29 iteratorThread.start();30}31
32public static void main(String[] args) {33 // 3. 创建同步容器list进行测试,发现会抛出ConcurrentModificationException34 final List<String> list = Collections.synchronizedList(new ArrayList<String>());35 startIteratorThread(list);36 startModifyThread(list);37}38
如需解决上述问题,需要在遍历的时候给整个容器对象加锁,如startIteratorThread可以改为:
xxxxxxxxxx161private static void startIteratorThread(final List<String> list) {2 Thread iteratorThread = new Thread(new Runnable() {3 4 public void run() {5 // 2. 线程2:重复进行遍历操作6 while (true) {7 // 但是在遍历前对list进行加锁8 synchronized(list){9 for (String str : list) {10 } 11 }12 }13 }14 });15 iteratorThread.start();16}
6. 面试扩展
1) JUC中的容器都是无锁的吗?
- 无锁容器:如
ConcurrentHashMap、ConcurrentLinkedQueue和Atomic类,通过CAS操作和分段锁等机制实现线程安全,适用于高并发场景,性能较高。 - 使用锁的容器:如
ReentrantLock、ReentrantReadWriteLock和BlockingQueue的实现类,通过锁机制实现线程安全,适用于需要复杂锁操作或阻塞操作的场景。
第03章_异步执行
第一节 线程池
线程池是实现资源共享的一种方式,主要由工作线程和任务队列两个概念组成,它可以重用线程,减少线程创建的开销。
1. 基本使用
1) 创建和使用线程池
在Java中,默认的线程池实现类为ThreadPoolExecutor,常用方法如下:
x1// 构造函数2public ThreadPoolExecutor(int corePoolSize, // 核心线程个数(当前线程数小于该值时,有新任务则直接创建线程)3 int maximumPoolSize, // 最大线程个数4 long keepAliveTime, // 空闲线程存活时间(0表示无限长),释放“空闲的非核心线程”占用的资源5 TimeUnit unit, // 时间单位6 BlockingQueue<Runnable> workQueue){} // 任务队列7public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,8 BlockingQueue<Runnable> workQueue,9 ThreadFactory threadFactory, // 线程工厂(自定义线程属性)10 RejectedExecutionHandler handler){} // 任务拒绝策略11
12// 执行异步任务13void execute(Runnable command);14Future<T> submit(Callable<T> task); // 提交Callable,返回实际结果,异常可通过线程池的 afterExecute() 方法处理15Future<T> submit(Runnable task, T result); // 提交Runnable,结果为result(如“执行成功”)16Future<?> submit(Runnable task); // 提交Runnable,结果为null17
18// 获取线程池状态19boolean isTerminated(); // 是否所有任务都已结束(isDone为true)20boolean isShutdown(); // 执行服务是否被关闭(注意:即使执行服务被关闭,但可能还有任务在继续执行)21 22// 等待所有任务结束(即等待isTerminated为true)23// 限定等待的时间,如果在限期内都结束了则返回true,否则返回false24boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; 25 26// 关闭线程池(被调用后isShutdown会返回true)27// 关闭方法不会阻塞等待,而是直接返回,但返回后可能还有任务再继续执行,只是不继续接收新任务了28void shutdown(); // 已提交但尚未开始的任务仍会继续执行29List<Runnable> shutdownNow(); // 已提交但尚未开始的任务会被终止,已执行的任务会尝试中断,返回已提交但尚未开始的任务列表30
使用示例如下:
xxxxxxxxxx231// 1. 创建线程池2ThreadPoolExecutor threadPool 3 = new ThreadPoolExecutor(10, 20, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());4
5// 2. 让线程池执行任务,没返回结果6threadPool.execute(() -> {7 System.out.println("没有返回结果的任务");8});9
10// 3. 让线程池执行有返回结果的任务11Future<Object> future = threadPool.submit(new Callable<Object>() {12 13 public Object call() throws Exception {14 System.out.println("我有返回结果!");15 return "返回结果";16 }17});18// 获取返回结果19Object result = future.get();20System.out.println(result);21
22// 4. 如果是局部变量的线程池,记得用完要shutdown23threadPool.shutdown();注意:
- ThreadPoolExecutor继承自AbstractExecutorService,顶层接口为Executor,了解即可。
2) 获取线程池信息
xxxxxxxxxx71// 1. 获取线程个数信息2public int getPoolSize() // 返回当前线程个数3public int getLargestPoolSize() // 返回线程池曾经达到过的最大线程个数4
5// 2. 获取任务个数信息6public long getCompletedTaskCount() // 返回线程池自创建以来所有已完成的任务数7public long getTaskCount() // 返回所有任务数,包括所有已完成的加上所有排队待执行的
3) 配置线程池大小
除了在创建时配置线程池大小外,还可以通过getter/setter方法获取和设置线程池大小。
xxxxxxxxxx91// 1. 获取核心线程数、最大线程数、空闲线程存活时间2public int getCorePoolSize()3public int getMaximumPoolSize()4public long getKeepAliveTime(TimeUnit unit)5
6// 2. 设置核心线程数、最大线程数、空闲线程存活时间7public void setCorePoolSize(int corePoolSize) 8public void setMaximumPoolSize(int maximumPoolSize) 9public void setKeepAliveTime(long time, TimeUnit unit)注意:
- 线程池的核心参数可通过
hippo4j等框架进行监控和修改。
4) 选择任务队列
ThreadPoolExecutor要求的队列类型必须是阻塞队列BlockingQueue,可以是:
- LinkedBlockingQueue:基于链表的阻塞队列,可以指定最大长度,但默认是无界的。
- ArrayBlockingQueue:基于数组的有界阻塞队列。
- PriorityBlockingQueue:基于堆的无界阻塞优先级队列。
- SynchronousQueue:没有实际存储空间的同步阻塞队列(如果没有空闲线程,则总会创建新线程,直到达到maximumPoolSize)。
注意:
- 如果使用无界队列,则线程个数最大只能达到corePoolSize,设置maximumPoolSize参数将无意义。
5) 配置任务拒绝策略
线程池一般使用有界队列且maximumPoolSize是有限的,当两者都达到上限时,就会拒绝任务的提交(execute/submit/invokeAll),可以通过构造方法或setter方法设置拒绝策略。
xxxxxxxxxx71// 拒绝策略接口2public interface RejectedExecutionHandler {3 void rejectedExecution(Runnable r, ThreadPoolExecutor executor);4}5
6// 设置拒绝策略7public void setRejectedExecutionHandler(RejectedExecutionHandler handler)ThreadPoolExecutor内部实现了四种拒绝策略可供选择:
AbortPolicy:默认方式,抛出RejectedExecutionException异常。DiscardPolicy:静默处理,忽略新任务,不抛异常,也不执行(丢弃)。DiscardOldestPolicy:将等待时间最长的任务扔掉,然后自己排队(抢占)。CallerRunsPolicy:在任务提交者线程中执行任务,而不是交给线程池中的线程执行(降级)。
注意:
- 拒绝策略只有在队列有界,且最大线程数有限的情况下才会触发,让拒绝策略有机会执行对保证系统稳定非常重要。
- 在任务量非常大的场景中,如果队列无界,可能会导致请求处理队列积压过多任务,消费非常大的内存;如果队列有界但不限制最大线程数,可能会创建过多的线程,占满CPU和内存。
- 如需保证任务不被丢弃,则必须使用
CallerRunsPolicy或进行任务持久化存储(自定义拒绝策略/实现混合阻塞队列)。
6) 自定义线程工厂
线程工厂可以对创建的线程进行一些配置,如设置线程名称等:
xxxxxxxxxx181public final class NamingThreadFactory implements ThreadFactory {2 private final AtomicInteger threadNum = new AtomicInteger();3 private final String name;4
5 /**6 * 创建一个带名字的线程池生产工厂7 */8 public NamingThreadFactory(String name) {9 this.name = name;10 }11
12 13 public Thread newThread(Runnable r) {14 Thread t = new Thread(r);15 t.setName(name + " [#" + threadNum.incrementAndGet() + "]");16 return t;17 }18}默认实现类为Executors类中的静态内部类DefaultThreadFactory,它主要就是创建一个线程,给线程设置一个名称( pool-<线程池编号>-thread-<线程编号>),设置daemon属性为false,设置线程优先级为标准默认优先级等。
7) 线程池的其他配置
xxxxxxxxxx51// 1. 关于核心线程的配置2public int prestartAllCoreThreads() // 预先创建所有的核心线程3public boolean prestartCoreThread() // 创建一个核心线程,如果所有核心线程都已创建,返回false4public void allowCoreThreadTimeOut(boolean value) // 如果参数为true,则keepAliveTime参数也适用于核心线程5
8) 线程池工厂类
线程池工厂类Executors提供了一些静态工厂方法,可以方便的创建一些预配置的线程池,主要方法有:
xxxxxxxxxx191// 1. 单线程线程池2// 核心线程数=最大线程数=1(任务串行执行),队列为无界的链式阻塞队列:LinkedBlockingQueue3public static ExecutorService newSingleThreadExecutor()4 5// 2. 固定数目线程池6// 核心线程数=最大线程数=nThreads,队列为无界的链式阻塞队列:LinkedBlockingQueue7public static ExecutorService newFixedThreadPool(int nThreads)8
9// 3. 缓存线程池10// 核心线程数=0,最大线程数无限制(空闲线程会缓存60s),队列为无存储的同步队列:SynchronousQueue11public static ExecutorService newCachedThreadPool()12 13// 4. 调度线程池14// 核心线程数=corePoolSize,队列是基于堆的延时队列:DelayedWorkQueue(按执行时间出队)15public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)16 17// 5. 转换任务类型18public static Callable<Object> callable(Runnable task)19public static <T> Callable<T> callable(Runnable task, T result) // result为无异常时固定返回结果,如“执行成功”注意:
- 在系统负载可能极高的情况下,FixedThreadPool 的问题是队列过长,而 CachedThreadPool 的问题是线程过多。
- 一般情况下,建议自定义 ThreadPoolExecutor,使用有界队列,控制线程创建数量。
2. 源码分析
1) 核心属性
xxxxxxxxxx431/**2 * 【核心属性】一个复合变量:高3位存储线程池状态,低29位存储当前工作线程数3 * 用一个变量存储两个值,通过位运算快速拆分 / 组合,避免多变量的并发同步问题4 */5private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));6/** 线程数的位数(32-3=29,最多支持2^29-1个线程) */7private static final int COUNT_BITS = Integer.SIZE - 3;8/** 线程数的最大值(2^29-1) */9private static final int CAPACITY = (1 << COUNT_BITS) - 1;10// 线程池状态常量(高3位)11private static final int RUNNING = -1 << COUNT_BITS; // 接受新任务+处理队列任务12private static final int SHUTDOWN = 0 << COUNT_BITS; // 不接受新任务,但处理队列任务13private static final int STOP = 1 << COUNT_BITS; // 不接受新任务,不处理队列任务,中断正在执行的任务14private static final int TIDYING = 2 << COUNT_BITS; // 所有任务完成,线程数为0,准备执行terminated()15private static final int TERMINATED = 3 << COUNT_BITS; // terminated()执行完成16// 辅助方法:拆分/组合状态和线程数17private static int runStateOf(int c) { return c & ~CAPACITY; } // 获取状态18private static int workerCountOf(int c) { return c & CAPACITY; } // 获取线程数19private static int ctlOf(int rs, int wc) { return rs | wc; } // 组合状态和线程数20
21/** 核心线程数(核心线程默认不会超时销毁) */22private final int corePoolSize;23/** 最大线程数(线程池允许的最大线程数) */24private final int maximumPoolSize;25/** 非核心线程的空闲存活时间 */26private final long keepAliveTime;27/** 存活时间的时间单位 */28private final TimeUnit unit;29/** 是否允许核心线程超时销毁(默认false) */30private volatile boolean allowCoreThreadTimeOut;31/** 存储工作线程的集合(Worker是线程池的内部线程封装类) */32private final HashSet<Worker> workers = new HashSet<>();33/** 保护workers集合的重入锁 */34private final ReentrantLock mainLock = new ReentrantLock();35/** 线程池终止的条件变量(awaitTermination()依赖) */36private final Condition termination = mainLock.newCondition();37
38/** 存储待执行任务的阻塞队列 */39private final BlockingQueue<Runnable> workQueue;40/** 创建新线程的工厂(自定义线程名称/优先级/是否守护线程) */41private volatile ThreadFactory threadFactory;42/** 任务拒绝处理器(当线程池饱和时触发) */43private volatile RejectedExecutionHandler handler;
2) 状态流转
线程池状态只能单向流转,即:RUNNING -> SHUTDOWN/STOP -> TIDYING -> TERMINATED。
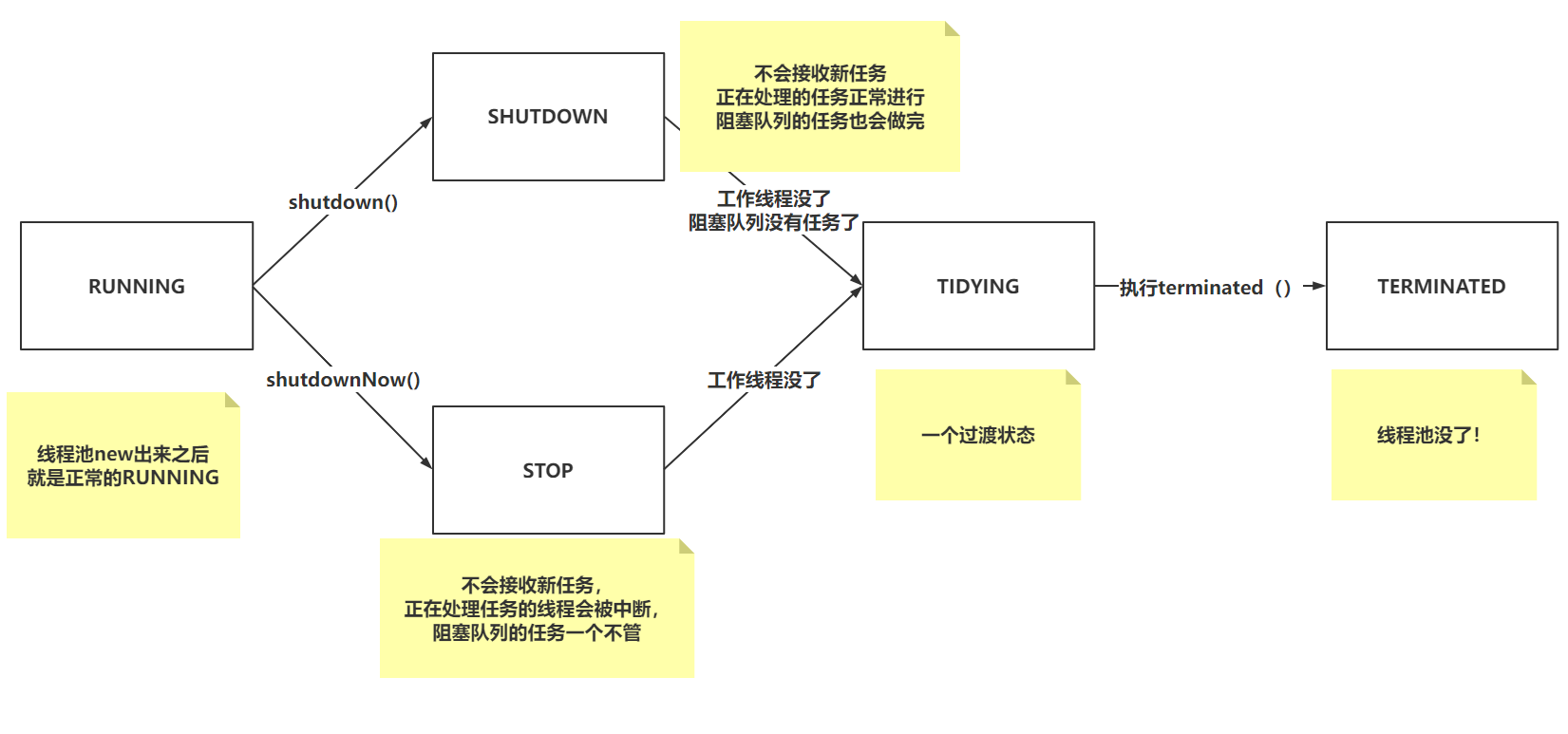
3) 执行流程
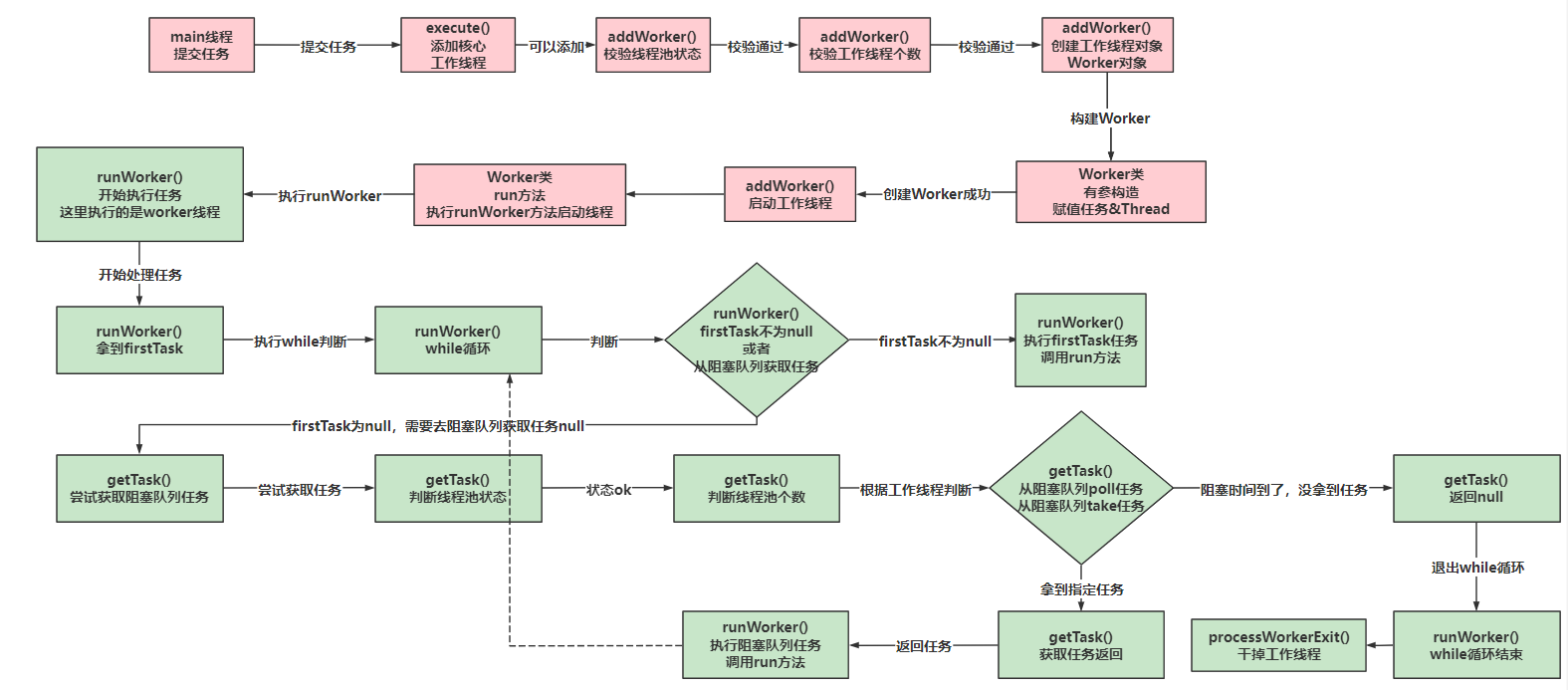
4) 构造方法
有参构造主要是对核心线程数、最大线程数,以及线程工厂、拒绝策略进行一些设置和校验,注意下核心线程数允许为0就OK。
xxxxxxxxxx331// 有参构造。无论调用哪个有参构造,最终都会执行当前的有参构造2public ThreadPoolExecutor(int corePoolSize,3 int maximumPoolSize,4 long keepAliveTime,5 TimeUnit unit,6 BlockingQueue<Runnable> workQueue,7 ThreadFactory threadFactory,8 RejectedExecutionHandler handler) {9 // 健壮性校验10 // 核心线程个数是允许为0个的。11 // 最大线程数必须大于0,最大线程数要大于等于核心线程数12 // 非核心线程的最大空闲时间,可以等于013 if (corePoolSize < 0 ||14 maximumPoolSize <= 0 ||15 maximumPoolSize < corePoolSize ||16 keepAliveTime < 0)17 // 不满足要求就抛出参数异常18 throw new IllegalArgumentException();19 // 阻塞队列,线程工厂,拒绝策略都不允许为null,为null就扔空指针异常20 if (workQueue == null || threadFactory == null || handler == null)21 throw new NullPointerException();22 // 不要关注当前内容,系统资源访问决策,和线程池核心业务关系不大。23 this.acc = System.getSecurityManager() == null ? null : AccessController.getContext();24 // 各种赋值,JUC包下,几乎所有涉及到线程挂起的操作,单位都用纳秒。25 // 有参构造的值,都赋值给成员变量。26 // Doug Lea的习惯就是将成员变量作为局部变量单独操作。27 this.corePoolSize = corePoolSize;28 this.maximumPoolSize = maximumPoolSize;29 this.workQueue = workQueue;30 this.keepAliveTime = unit.toNanos(keepAliveTime);31 this.threadFactory = threadFactory;32 this.handler = handler;33}
5) 执行任务(execute)
execute方法是提交任务到线程池的核心方法,线程池的执行流程就是在指execute方法内部做了哪些判断:
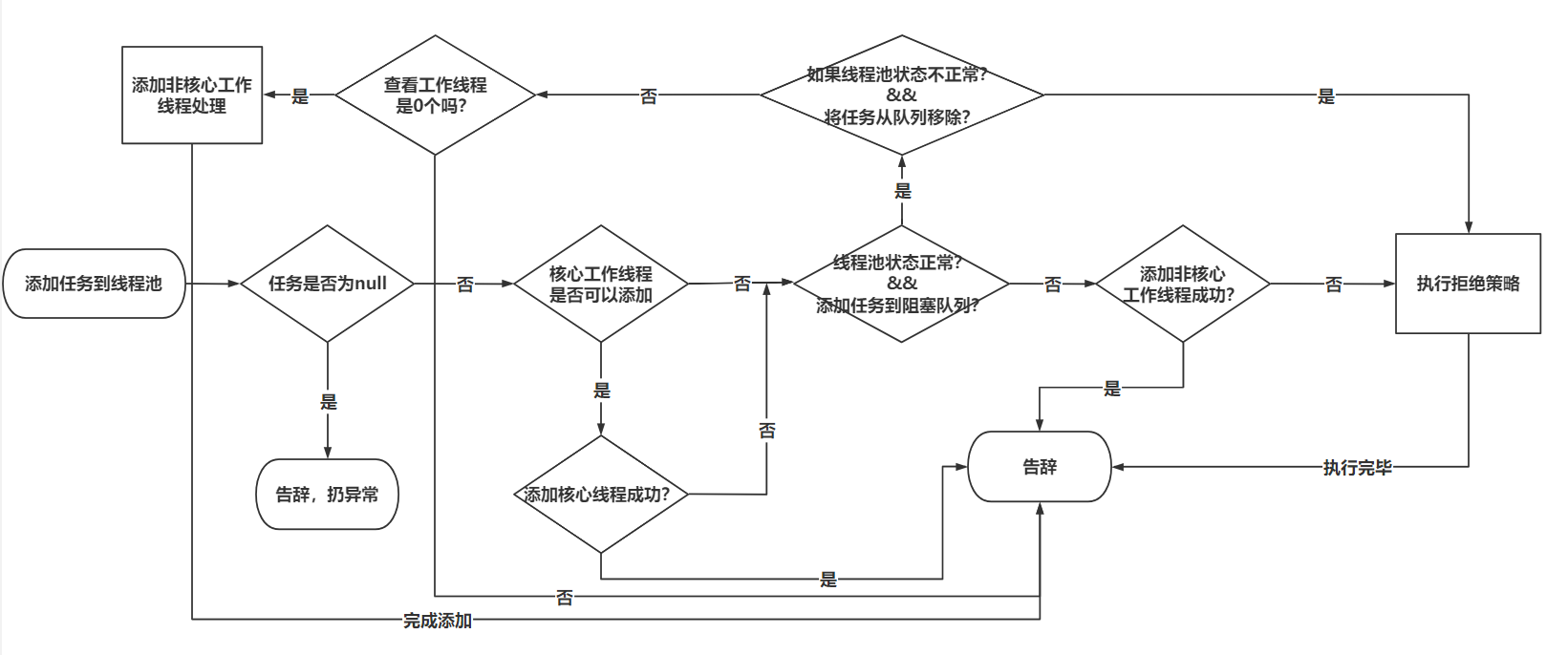
xxxxxxxxxx1891// 提交任务到线程池的核心方法2// command就是提交过来的任务3public void execute(Runnable command) {4 // 提交的任务不能为null5 if (command == null)6 throw new NullPointerException();7 // 获取核心属性ctl,用于后面的判断8 int c = ctl.get();9 // 如果工作线程个数,小于核心线程数。10 // 满足要求,添加核心工作线程11 if (workerCountOf(c) < corePoolSize) {12 // addWorker(任务,是核心线程吗)13 // addWorker返回true:代表添加工作线程成功14 // addWorker返回false:代表添加工作线程失败15 // addWorker中会基于线程池状态,以及工作线程个数做判断,查看能否添加工作线程16 if (addWorker(command, true))17 // 工作线程构建出来了,任务也交给command去处理了。18 return;19 // 说明线程池状态或者是工作线程个数发生了变化,导致添加失败,重新获取一次ctl20 c = ctl.get();21 }22 // 添加核心工作线程失败,往这走23 // 判断线程池状态是否是RUNNING,如果是,正常基于阻塞队列的offer方法,将任务添加到阻塞队列24 if (isRunning(c) && workQueue.offer(command)) {25 // 如果任务添加到阻塞队列成功,走if内部26 // 如果任务在扔到阻塞队列之前,线程池状态突然改变了。27 // 重新获取ctl28 int recheck = ctl.get();29 // 如果线程池的状态不是RUNNING,将任务从阻塞队列移除,30 if (!isRunning(recheck) && remove(command))31 // 并且直接拒绝策略32 reject(command);33 // 在这,说明阻塞队列有我刚刚放进去的任务34 // 查看一下工作线程数是不是0个35 // 如果工作线程为0个,需要添加一个非核心工作线程去处理阻塞队列中的任务36 // 发生这种情况有两种:37 // 1. 构建线程池时,核心线程数是0个。38 // 2. 即便有核心线程,可以设置核心线程也允许超时,设置allowCoreThreadTimeOut为true,代表核心线程也可以超时39 else if (workerCountOf(recheck) == 0)40 // 为了避免阻塞队列中的任务饥饿,添加一个非核心工作线程去处理41 addWorker(null, false);42 }43 // 任务添加到阻塞队列失败44 // 构建一个非核心工作线程45 // 如果添加非核心工作线程成功,直接完事,告辞46 else if (!addWorker(command, false))47 // 添加失败,执行决绝策略48 reject(command);49}50
51
52// addWorker方法用于新建工作线程,代码分为上下两部分:53private boolean addWorker(Runnable firstTask, boolean core) {54 // 一、第一部分是校验线程池的状态以及工作线程个数55 56 // 外层for循环在校验线程池的状态57 // 内层for循环是在校验工作线程的个数58 // retry是给外层for循环添加一个标记,是为了方便在内层for循坏跳出外层for循环59 retry:60 for (;;) {61 // 获取ctl62 int c = ctl.get();63 // 拿到ctl的高3位的值64 int rs = runStateOf(c);65//==========================线程池状态判断==================================================66 // 如果线程池状态是SHUTDOWN,并且此时阻塞队列有任务,工作线程个数为0,添加一个工作线程去处理阻塞队列的任务67
68 // 判断线程池的状态是否大于等于SHUTDOWN,如果满足,说明线程池不是RUNNING69 if (rs >= SHUTDOWN &&70 // 如果这三个条件都满足,就代表是要添加非核心工作线程去处理阻塞队列任务71 // 如果三个条件有一个没满足,返回false,配合!,就代表不需要添加72 !(rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))73 // 不需要添加工作线程74 return false;75
76 for (;;) {77//==========================工作线程个数判断================================================== 78 // 基于ctl拿到低29位的值,代表当前工作线程个数 79 int wc = workerCountOf(c);80 // 如果工作线程个数大于最大值了,不可以添加了,返回false81 if (wc >= CAPACITY ||82 // 基于core来判断添加的是否是核心工作线程83 // 如果是核心:基于corePoolSize去判断84 // 如果是非核心:基于maximumPoolSize去判断85 wc >= (core ? corePoolSize : maximumPoolSize))86 // 代表不能添加,工作线程个数不满足要求87 return false;88 // 针对ctl进行 + 1,采用CAS的方式89 if (compareAndIncrementWorkerCount(c))90 // CAS成功后,直接退出外层循环,代表可以执行添加工作线程操作了。91 break retry;92 // 重新获取一次ctl的值93 c = ctl.get(); 94 // 判断重新获取到的ctl中,表示的线程池状态跟之前的是否有区别95 // 如果状态不一样,说明有变化,重新的去判断线程池状态96 if (runStateOf(c) != rs)97 // 跳出一次外层for循环98 continue retry;99 }100 }101
102
103 // 二、第二部分是添加并且启动工作线程104 // 添加工作线程以及启动工作线程~~~105 // 声明了三个变量106 // 工作线程启动了没,默认false107 boolean workerStarted = false;108 // 工作线程添加了没,默认false109 boolean workerAdded = false;110 // 工作线程,默认为null111 Worker w = null;112
113 try {114 // 构建工作线程,并且将任务传递进去115 w = new Worker(firstTask);116 // 获取了Worker中的Thread对象117 final Thread t = w.thread;118 // 判断Thread是否不为null,在new Worker时,内部会通过给予的ThreadFactory去构建Thread交给Worker119 // 一般如果为null,代表ThreadFactory有问题。120 if (t != null) {121 // 加锁,保证使用workers成员变量以及对largestPoolSize赋值时,保证线程安全122 final ReentrantLock mainLock = this.mainLock;123 mainLock.lock();124 try {125 // 再次获取线程池状态。126 int rs = runStateOf(ctl.get());127 // 再次判断128 // 如果满足 rs < SHUTDOWN 说明线程池是RUNNING,状态正常,执行if代码块129 // 如果线程池状态为SHUTDOWN,并且firstTask为null,添加非核心工作处理阻塞队列任务130 if (rs < SHUTDOWN ||131 (rs == SHUTDOWN && firstTask == null)) {132 // 到这,可以添加工作线程。133 // 校验ThreadFactory构建线程后,不能自己启动线程,如果启动了,抛出异常134 if (t.isAlive()) 135 throw new IllegalThreadStateException();136 // private final HashSet<Worker> workers = new HashSet<Worker>();137 // 将new好的Worker添加到HashSet中。138 workers.add(w);139 // 获取了HashSet的size,拿到工作线程个数140 int s = workers.size();141 // largestPoolSize在记录最大线程个数的记录142 // 如果当前工作线程个数,大于最大线程个数的记录,就赋值143 if (s > largestPoolSize)144 largestPoolSize = s;145 // 添加工作线程成功146 workerAdded = true;147 }148 } finally {149 mainLock.unlock();150 }151 // 如果工作线程添加成功,152 if (workerAdded) {153 // 直接启动Worker中的线程154 t.start();155 // 启动工作线程成功156 workerStarted = true;157 }158 }159 } finally {160 // 做补偿的操作,如果工作线程启动失败,将这个添加失败的工作线程处理掉161 if (!workerStarted)162 addWorkerFailed(w);163 }164 // 返回工作线程是否启动成功165 return workerStarted;166}167
168
169// 工作线程启动失败,需要不的步长操作170private void addWorkerFailed(Worker w) {171 // 因为操作了workers,需要加锁172 final ReentrantLock mainLock = this.mainLock;173 mainLock.lock();174 try {175 // 如果w不为null,之前Worker已经new出来了。176 if (w != null)177 // 从HashSet中移除178 workers.remove(w);179 // 同时对ctl进行 - 1,代表去掉了一个工作线程个数180 decrementWorkerCount();181 // 因为工作线程启动失败,判断一下状态的问题,是不是可以走TIDYING状态最终到TERMINATED状态了。182 tryTerminate();183 } finally {184 // 释放锁185 mainLock.unlock();186 }187}188
189
submit方法是在execute方法的基础上做的一层封装,执行的是可异步获取结果的FutureTask对象:
xxxxxxxxxx61public <T> Future<T> submit(Callable<T> task) {2 if (task == null) throw new NullPointerException();3 RunnableFuture<T> ftask = newTaskFor(task); // 1. 生成了一个RunnableFuture(FutureTask)4 execute(ftask); // 2. 传递给execute方法进行执行5 return ftask;6}
6) 工作线程(Worker#run)
工作线程Worker循环获取任务并执行,执行时支持中断。
xxxxxxxxxx2481// Worker继承了AQS,目的就是为了控制工作线程的中断。2// Worker实现了Runnable,内部的Thread对象,在执行start时,必然要执行Worker中断额一些操作3private final class Worker extends AbstractQueuedSynchronizer implements Runnable{4 5// =======================Worker管理任务================================ 6 // 线程工厂构建的线程7 final Thread thread;8
9 // 当前Worker要执行的任务10 Runnable firstTask;11
12 // 记录当前工作线程处理了多少个任务。13 volatile long completedTasks;14
15 // 有参构造16 Worker(Runnable firstTask) {17 // 将State设置为-1,代表当前不允许中断线程18 setState(-1); 19 // 任务赋值20 this.firstTask = firstTask;21 // 基于线程工作构建Thread,并且传入的Runnable是Worker22 this.thread = getThreadFactory().newThread(this);23 }24
25 // 当thread执行start方法时,调用的是Worker的run方法,26 public void run() {27 // 任务执行时,执行的是runWorker方法28 runWorker(this);29 }30
31
32// =======================Worker管理中断================================ 33 // 当前方法是中断工作线程时,执行的方法34 void interruptIfStarted() {35 Thread t;36 // 只有Worker中的state >= 0的时候,可以中断工作线程37 if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {38 try {39 // 如果状态正常,并且线程未中断,这边就中断线程40 t.interrupt();41 } catch (SecurityException ignore) {42 }43 }44 }45 46 protected boolean isHeldExclusively() {47 return getState() != 0;48 }49 protected boolean tryAcquire(int unused) {50 if (compareAndSetState(0, 1)) {51 setExclusiveOwnerThread(Thread.currentThread());52 return true;53 }54 return false;55 }56 protected boolean tryRelease(int unused) {57 setExclusiveOwnerThread(null);58 setState(0);59 return true;60 }61 public void lock() { acquire(1); }62 public boolean tryLock() { return tryAcquire(1); }63 public void unlock() { release(1); }64 public boolean isLocked() { return isHeldExclusively(); }65
66}67
68// 工作线程启动后执行的任务。69final void runWorker(Worker w) {70 // 拿到当前线程71 Thread wt = Thread.currentThread();72 // 从worker对象中拿到任务73 Runnable task = w.firstTask;74 // 将Worker中的firstTask置位空75 w.firstTask = null;76 // 将Worker中的state置位0,代表当前线程可以中断的77 w.unlock(); // allow interrupts78 // 判断工作线程是否是异常结束,默认就是异常结束79 boolean completedAbruptly = true;80 try {81 // 获取任务82 // 直接拿到第一个任务去执行83 // 如果第一个任务为null,去阻塞队列中获取任务84 while (task != null || (task = getTask()) != null) {85 // 执行了Worker的lock方法,当前在lock时,shutdown操作不能中断当前线程,因为当前线程正在处理任务86 w.lock();87 // 比较ctl >= STOP,如果满足找个状态,说明线程池已经到了STOP状态甚至已经要凉凉了88 // 线程池到STOP状态,并且当前线程还没有中断,确保线程是中断的,进到if内部执行中断方法89 // if(runStateAtLeast(ctl.get(), STOP) && !wt.isInterrupted()) {中断线程}90 // 如果线程池状态不是STOP,确保线程不是中断的。91 // 如果发现线程中断标记位是true了,再次查看线程池状态是大于STOP了,再次中断线程92 // 这里其实就是做了一个事情,如果线程池状态 >= STOP,确保线程中断了。93 if (94 (95 runStateAtLeast(ctl.get(), STOP) || 96 ( Thread.interrupted() && runStateAtLeast(ctl.get(), STOP) )97 )98 && !wt.isInterrupted())99 wt.interrupt();100 try {101 // 勾子函数在线程池中没有做任何的实现,如果需要在线程池执行任务前后做一些额外的处理,可以重写勾子函数102 // 前置勾子函数103 beforeExecute(wt, task);104 Throwable thrown = null;105 try {106 // 执行任务。107 task.run();108 } catch (RuntimeException x) {109 thrown = x; throw x;110 } catch (Error x) {111 thrown = x; throw x;112 } catch (Throwable x) {113 thrown = x; throw new Error(x);114 } finally {115 // 前后置勾子函数116 afterExecute(task, thrown);117 }118 } finally {119 // 任务执行完,丢掉任务120 task = null;121 // 当前工作线程处理的任务数+1122 w.completedTasks++;123 // 执行unlock方法,此时shutdown方法才可以中断当前线程124 w.unlock();125 }126 }127 // 如果while循环结束,正常走到这,说明是正常结束128 // 正常结束的话,在getTask中就会做一个额外的处理,将ctl - 1,代表工作线程没一个。129 completedAbruptly = false;130 } finally {131 // 考虑干掉工作线程132 processWorkerExit(w, completedAbruptly);133 }134}135
136
137// 工作线程结束前,要执行当前方法138private void processWorkerExit(Worker w, boolean completedAbruptly) {139 // 如果是异常结束140 if (completedAbruptly) 141 // 将ctl - 1,扣掉一个工作线程142 decrementWorkerCount();143
144 // 操作Worker,为了线程安全,加锁145 final ReentrantLock mainLock = this.mainLock;146 mainLock.lock();147 try {148 // 当前工作线程处理的任务个数累加到线程池处理任务的个数属性中149 completedTaskCount += w.completedTasks;150 // 将工作线程从hashSet中移除151 workers.remove(w);152 } finally {153 // 释放锁154 mainLock.unlock();155 }156
157 // 只要工作线程凉了,查看是不是线程池状态改变了。158 tryTerminate();159
160 // 获取ctl161 int c = ctl.get();162 // 判断线程池状态,当前线程池要么是RUNNING,要么是SHUTDOWN163 if (runStateLessThan(c, STOP)) {164 // 如果正常结束工作线程165 if (!completedAbruptly) {166 // 如果核心线程允许超时,min = 0,否则就是核心线程个数167 int min = allowCoreThreadTimeOut ? 0 : corePoolSize;168 // 如果min == 0,可能会出现没有工作线程,并且阻塞队列有任务没有线程处理169 if (min == 0 && ! workQueue.isEmpty())170 // 至少要有一个工作线程处理阻塞队列任务171 min = 1;172 // 如果工作线程个数 大于等于1,不怕没线程处理,正常return173 if (workerCountOf(c) >= min)174 return; 175 }176 // 异常结束,为了避免出现问题,添加一个空任务的非核心线程来填补上刚刚异常结束的工作线程177 addWorker(null, false);178 }179}180
181
182// 当前方法就在阻塞队列中获取任务183// 前面半部分是判断当前工作线程是否可以返回null,结束。184// 后半部分就是从阻塞队列中拿任务185private Runnable getTask() {186 // timeOut默认值是false。187 boolean timedOut = false; 188
189 // 死循环190 for (;;) {191 // 拿到ctl192 int c = ctl.get();193 // 拿到线程池的状态194 int rs = runStateOf(c);195
196 // 如果线程池状态是STOP,没有必要处理阻塞队列任务,直接返回null197 // 如果线程池状态是SHUTDOWN,并且阻塞队列是空的,直接返回null198 if (rs >= SHUTDOWN && 199 (rs >= STOP || workQueue.isEmpty())) {200 // 如果可以返回null,先扣减工作线程个数201 decrementWorkerCount();202 // 返回null,结束runWorker的while循环203 return null;204 }205
206 // 基于ctl拿到工作线程个数207 int wc = workerCountOf(c);208
209 // 核心线程允许超时,timed为true210 // 工作线程个数大于核心线程数,timed为true211 boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;212
213 if (214 // 如果工作线程个数,大于最大线程数。(一般情况不会满足),把他看成false215 // 第二个判断代表,只要工作线程数小于等于核心线程数,必然为false216 // 即便工作线程个数大于核心线程数了,此时第一次循环也不会为true,因为timedOut默认值是false217 // 考虑第二次循环了,因为循环内部必然有修改timeOut的位置218 (wc > maximumPoolSize || (timed && timedOut))219 && 220 // 要么工作线程还有,要么阻塞队列为空,并且满足上述条件后,工作线程才会走到if内部,结束工作线程221 (wc > 1 || workQueue.isEmpty())222 ) {223 // 第二次循环才有可能到这。224 // 正常结束,工作线程 - 1,因为是CAS操作,如果失败了,重新走for循环225 if (compareAndDecrementWorkerCount(c))226 return null;227 continue;228 }229
230 // 工作线程从阻塞队列拿任务231 try {232 // 如果是核心线程,timed是false,如果是非核心线程,timed就是true233 Runnable r = timed ?234 // 如果是非核心,走poll方法,拿任务,等待一会235 workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :236 // 如果是核心,走take方法,死等。237 workQueue.take();238 // 从阻塞队列拿到的任务不为null,这边就正常返回任务,去执行239 if (r != null)240 return r;241 // 说明当前线程没拿到任务,将timeOut设置为true,在上面就可以返回null退出了。242 timedOut = true;243 } catch (InterruptedException retry) {244 timedOut = false;245 }246 }247}248
7) 立即关闭(shutdownNow)
执行shutdownNow方法,直接将线程池从RUNNING状态转变为STOP状态。
xxxxxxxxxx1131// shutDownNow方法,shutdownNow不会处理阻塞队列的任务,将任务全部给你返回了。2public List<Runnable> shutdownNow() {3 // 声明返回结果4 List<Runnable> tasks;5 // 加锁6 final ReentrantLock mainLock = this.mainLock;7 mainLock.lock();8 try {9 // 不关注这个方法……10 checkShutdownAccess();11 // 将线程池状态修改为STOP12 advanceRunState(STOP);13 // 无论怎么,直接中断工作线程。14 interruptWorkers();15 // 将阻塞队列的任务全部扔到List集合中。16 tasks = drainQueue();17 } finally {18 // 释放锁19 mainLock.unlock();20 }21 tryTerminate();22 return tasks;23}24
25// 将线程池状态修改为STOP26private void advanceRunState(int STOP) {27 // 死循环。28 for (;;) {29 // 获取ctl属性的值30 int c = ctl.get();31 // 第一个判断:如果当前线程池状态已经大于等于STOP了,不管了,告辞。32 if (runStateAtLeast(c, STOP) ||33 // 基于CAS,将ctl从c修改为STOP状态,不修改工作线程个数,但是状态变为了STOP34 // 如果修改成功结束35 ctl.compareAndSet(c, ctlOf(STOP, workerCountOf(c))))36 break;37 }38}39// 无论怎么,直接中断工作线程。40private void interruptWorkers() {41 final ReentrantLock mainLock = this.mainLock;42 mainLock.lock();43 try {44 // 遍历HashSet,拿到所有的工作线程,直接中断。45 for (Worker w : workers)46 w.interruptIfStarted();47 } finally {48 mainLock.unlock();49 }50}51// 移除阻塞队列,内容全部扔到List集合中52private List<Runnable> drainQueue() {53 BlockingQueue<Runnable> q = workQueue;54 ArrayList<Runnable> taskList = new ArrayList<Runnable>();55 // 阻塞队列自带的,直接清空阻塞队列,内容扔到List集合56 q.drainTo(taskList);57 // 为了避免任务丢失,重新判断,是否需要编辑阻塞队列,重新扔到List58 if (!q.isEmpty()) {59 for (Runnable r : q.toArray(new Runnable[0])) {60 if (q.remove(r))61 taskList.add(r);62 }63 }64 return taskList;65}66
67// 查看当前线程池是否可以变为TERMINATED状态68final void tryTerminate() {69 // 死循环。70 for (;;) {71 // 拿到ctl72 int c = ctl.get();73 // 如果是RUNNING,直接告辞。74 // 如果状态已经大于等于TIDYING,马上就要凉凉,直接告辞。75 // 如果状态是SHUTDOWN,但是阻塞队列还有任务,直接告辞。76 if (isRunning(c) ||77 runStateAtLeast(c, TIDYING) ||78 (runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))79 return;80 // 如果还有工作线程81 if (workerCountOf(c) != 0) { 82 // 再次中断工作线程83 interruptIdleWorkers(ONLY_ONE);84 // 告辞,等你工作线程全完事,我这再尝试进入到TERMINATED状态85 return;86 }87
88 // 加锁,为了可以执行Condition的释放操作89 final ReentrantLock mainLock = this.mainLock;90 mainLock.lock();91 try {92 // 将线程池状态修改为TIDYING状态,如果成功,继续往下走93 if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {94 try {95 // 这个方法是空的,如果你需要在线程池关闭后做一些额外操作,这里你可以自行实现96 terminated();97 } finally {98 // 最终修改为TERMINATED状态99 ctl.set(ctlOf(TERMINATED, 0));100 // 线程池提供了一个方法,主线程在提交任务到线程池后,是可以继续做其他操作的。101 // 咱们也可以让主线程提交任务后,等待线程池处理完毕,再做后续操作102 // 这里线程池凉凉后,要唤醒哪些调用了awaitTermination方法的线程103 termination.signalAll();104 }105 return;106 }107 } finally {108 mainLock.unlock();109 }110 // else retry on failed CAS111 }112}113
8) 正常关闭(shutdown)
执行shutdown方法,可以将线程池从RUNNING状态先转变为SHUTDOWN状态,该状态不会中断正在干活的线程,而且会处理阻塞队列中的任务。
xxxxxxxxxx461public void shutdown() {2 // 加锁。。3 final ReentrantLock mainLock = this.mainLock;4 mainLock.lock();5 try {6 // 不看。7 checkShutdownAccess();8 // 里面是一个死循环,将线程池状态修改为SHUTDOWN9 advanceRunState(SHUTDOWN);10 // 中断空闲线程11 interruptIdleWorkers();12 // 说了,这个是为了ScheduleThreadPoolExecutor准备的,不管13 onShutdown(); 14 } finally {15 mainLock.unlock();16 }17 // 尝试结束线程18 tryTerminate();19}20
21// 中断空闲线程22private void interruptIdleWorkers(boolean onlyOne) {23 // 加锁24 final ReentrantLock mainLock = this.mainLock;25 mainLock.lock();26 try {27 for (Worker w : workers) {28 Thread t = w.thread;29 // 如果线程没有中断,那么就去获取Worker的锁,基于tryLock可知,不会中断正在干活的线程30 if (!t.isInterrupted() && w.tryLock()) {31 try {32 // 会中断空闲线程33 t.interrupt();34 } catch (SecurityException ignore) {35 } finally {36 w.unlock();37 }38 }39 if (onlyOne)40 break;41 }42 } finally {43 mainLock.unlock();44 }45}46
3. 面试扩展
1) 线程池有哪些核心参数?
- 核心线程数、最大线程数、空闲线程存活时间。
- 任务等待队列、任务拒绝策略、线程创建工厂。
2) 线程池处理任务的流程?
- 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
- 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
- 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
- 如果当前运行的线程数已经达到最大线程数了,则会执行任务拒绝策略。
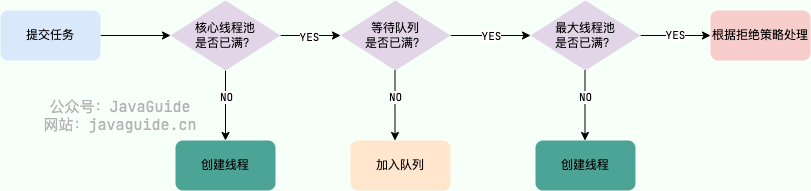
3) 线程空闲时在干嘛?
- 线程在空闲时,会处于
WAITING状态,等待获取任务。 - 当等待时间超过空闲线程存活时间,则会从工作线程集合中移除,变为
TERMINATED状态。
4) 线程池线程抛出异常怎么处理?
- 使用
execute()执行任务时,未捕获异常将会导致线程终止(打印异常信息),线程池创建新线程替代; - 使用
submit()提交任务时,未捕获异常将被封装在Future中(不打印异常信息),线程继续复用。
5) 线程池线程数设置多少合适?
过少的线程数会导致CPU利用不充分,过多的线程数会导致频繁的上下文切换,影响整体执行效率。建议如下:
- CPU密集型任务:推荐
CPU核心数+1,加1是为了防止某个线程任务暂停而导致CPU空闲。 - IO 密集型任务:推荐
2*CPU核心数或更高,视当前CPU负载而定(可通过VisualVM查看WT-线程等待时间和ST-线程计算时间)。
- CPU密集型任务:推荐
6) 线程池最佳实践?
- 通过
new ThreadPoolExecutor(...)的方式正确定义线程池,即使用有界队列,控制线程创建数量,并为线程池命名。 - 通过
ThreadPoolExecutor的相关 API 或 SpringBoot 中的 Actuator 组件实时监控线程池运行状态。 - 建议不同类别的业务用不同的线程池,避免线程池打满时,父子任务死锁。
- 使用线程池后应正确关闭线程池,需要调用
awaitTermination方法进行同步等待。 - 在线程池线程中使用
ThreadLocal变量时,一定要注意使用完及时清理,以免获取到旧值/脏数据。 - 线程池中尽量不要放耗时过长的任务,占用线程池线程,无法及时响应其他任务。
7) 线程池可能出现死锁吗?
如果提交的任务之间存在依赖,在线程池打满时,可能会出现死锁。
xxxxxxxxxx471public class ThreadPoolDeadLockDemo {2 // 1. 创建固定数目线程池,只有5个线程3 private static final int THREAD_NUM = 5; 4 static ExecutorService executor = Executors.newFixedThreadPool(THREAD_NUM); 5
6 // 2. 任务A7 static class TaskA implements Runnable {8 9 public void run() {10 try {11 Thread.sleep(100);12 } catch (InterruptedException e) {13 e.printStackTrace();14 }15 16 // 在任务A中提交任务B17 Future<?> future = executor.submit(new TaskB());18 try {19 future.get();20 } catch (Exception e) {21 e.printStackTrace();22 }23 24 System.out.println("finished task A");25 }26 }27
28 // 3. 任务B29 static class TaskB implements Runnable {30 31 public void run() {32 System.out.println("finished task B");33 }34 }35
36 // 4. 验证线程池死锁37 public static void main(String[] args) throws InterruptedException {38 // 4.1 先提交5个任务A39 for (int i = 0; i < 5; i++) {40 executor.execute(new TaskA());41 }42 43 // 4.2 进行等待发现死锁了,因为任务A在等待任务B的结果,而任务B在等待任务A结束获得执行机会44 Thread.sleep(2000);45 executor.shutdown();46 }47}上述问题可以将线程池类型替换为newCachedThreadPool来解决,让创建的线程不再受限。
另外,创建线程池时使用SynchronousQueue队列也可解决上述问题:
xxxxxxxxxx11executor = new ThreadPoolExecutor(THREAD_NUM, THREAD_NUM, 0, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());对于普通队列,入队只是把任务放到了队列中,而对于SynchronousQueue来说,入队成功就意味着已有线程接受处理,如果入队失败,可以创建更多线程直到maximumPoolSize,如果达到了maximumPoolSize,会触发拒绝机制,不管怎么样,都不会死锁。
第二节 定时任务
在Java中,定时任务可以使用java.util包中的Timer和TimerTask实现,也可以使用并发包中的ScheduledExecutorService实现。
注意:
- 上述两者都不能胜任复杂的定时任务调度,如每周一和周三晚上18:00到22:00,每半小时执行一次。
- 对于类似这种需求,可以使用更为强大的第三方类库,比如Quartz(http://www.quartz-scheduler.org/)。
1. Timer和TimerTask
1) 基本使用
TimerTask表示一个定时任务,它是一个抽象类,实现了Runnable接口,具体的定时任务需要继承该类,实现run方法。
Timer表示一个定时器,负责定时任务的调度和执行,它有如下主要方法:
xxxxxxxxxx171// 1. 指定时间执行2public void schedule(TimerTask task, Date time) // 在time时执行3
4// 2. 延时执行5public void schedule(TimerTask task, long delay) // 延迟delay毫秒后执行6
7// 3. 固定延时重复执行:基于上一个任务的开始时间,延迟period毫秒再次执行8public void schedule(TimerTask task, Date firstTime, long period) // firstTime-第一次执行时间,如果小于当前时间,则会立即执行9public void schedule(TimerTask task, long delay, long period) // 第一次执行时间为当前时间延时delay毫秒10
11// 5. 固定频率重复执行:基于初次计划开始时间,每间隔period毫秒执行一次12public void scheduleAtFixedRate(TimerTask task, Date firstTime, long period) // firstTime-如果小于当前时间,则会立即执行,而且可能连续执行多次(因为firstTime+period后还可能仍是一个过去时间)13public void scheduleAtFixedRate(TimerTask task, long delay, long period) // 第一次执行时间为当前时间延时delay毫秒14
15// 6. 取消所有定时任务16public void cancel()17 注意:
- 对于固定延时的任务,下次执行时间为当前任务执行前的时间加上period,这并不符合一般的期望。
- 对于固定频率的任务,它总是基于最先的任务计划的,所以,很有可能会出现一下子执行很多次任务的情况。
2) 实现原理
Timer内部主要由Timer线程和任务队列两部分组成
- 任务队列是一个基于堆实现的优先级队列,按照下次执行的时间排优先级。
- Timer线程负责循环执行定时任务,需要强调的是,一个Timer对象只有一个Timer线程,任务的执行时间可能会相互影响。
3) 应用示例
xxxxxxxxxx641// 示例1:延时执行2public class BasicTimer {3 static class DelayTask extends TimerTask {4 5 6 public void run() {7 System.out.println("delayed task");8 }9 }10 11 public static void main(String[] args) throws InterruptedException {12 Timer timer = new Timer();13 timer.schedule(new DelayTask(), 1000); // 延时执行14 Thread.sleep(2000);15 timer.cancel(); // 取消所有定时任务16 }17}18
19// 示例2:固定延时重复执行 vs 固定频率重复执行20public class TimerFixedDelay {21
22 // 1. 一个耗时5秒的延时任务23 static class LongRunningTask extends TimerTask {24 25 public void run() {26 try {27 Thread.sleep(5000);28 } catch (InterruptedException e) {29 }30 System.out.println("long running finished");31 }32 }33
34 // 2. 延时任务:打印当前时间35 static class FixedDelayTask extends TimerTask {36 37 public void run() {38 System.out.println(System.currentTimeMillis());39 }40 }41
42 // 3. 固定延时43 public static void main(String[] args) throws InterruptedException {44 Timer timer = new Timer();45
46 // 3.1 延时10ms后执行,耗时5s47 timer.schedule(new LongRunningTask(), 10); 48 49 // 3.2 延时100ms后执行,但是执行线程正忙,一直被延迟到5s后才开始执行,后续任务都将被推迟5s50 timer.schedule(new FixedDelayTask(), 100, 1000); 51 }52 53 // 4. 固定频率54 public static void main(String[] args) throws InterruptedException {55 Timer timer = new Timer();56
57 // 4.1 延时10ms后执行,耗时5s58 timer.schedule(new LongRunningTask(), 10); 59 60 // 4.2 延时100ms后执行,每隔1s执行一次,但是执行线程正忙,一直被延迟到5s后才开始执行61 // 但是会在之后尽量补够延迟期间的执行次数,即可能会在5s后连续打印5次相同的时间!62 timer.scheduleAtFixedRate(new FixedRateTask(), 100, 1000); 63 }64}
4) 注意事项
一个Timer对象只有一个Timer线程,这意味着,定时任务不能耗时太长,更不能是无限循环,看个例子:
xxxxxxxxxx321public class EndlessLoopTimer {2 // 1. 一个循环任务3 static class LoopTask extends TimerTask {4
5 6 public void run() {7 while (true) {8 try {9 // ... 执行任务10 Thread.sleep(1000);11 } catch (InterruptedException e) {12 e.printStackTrace();13 }14 }15 }16 }17
18 // 2. 另一个任务19 static class ExampleTask extends TimerTask {20 21 public void run() {22 System.out.println("hello");23 }24 }25
26 public static void main(String[] args) throws InterruptedException {27 Timer timer = new Timer();28 timer.schedule(new LoopTask(), 10); // 一直在循环29 timer.schedule(new ExampleTask(), 100); // 永远也没有机会执行30 }31}32
Timer线程在执行任何一个任务的run方法时,一旦run抛出异常,Timer线程就会退出,从而所有定时任务都会被取消。
xxxxxxxxxx291public class TimerException {2
3 // 1. 定时任务A4 static class TaskA extends TimerTask {5 6 7 public void run() {8 System.out.println("task A");9 }10 }11 12 // 2. 定时任务B(会抛异常)13 static class TaskB extends TimerTask {14 15 16 public void run() {17 System.out.println("task B");18 throw new RuntimeException();19 }20 }21
22 // 3. 测试23 public static void main(String[] args) throws InterruptedException {24 Timer timer = new Timer();25 timer.schedule(new TaskA(), 1, 1000); // 任务A抛了异常,定时器终止26 timer.schedule(new TaskB(), 2000, 1000); // 任务B不再执行27 }28}29
所以,如果希望各个定时任务不互相干扰,一定要在run方法内捕获所有异常。
2. ScheduledThreadPoolExecutor
1) ScheduledThreadPoolExecutor简介
由于Timer/TimerTask的一些问题,Java并发包引入了ScheduledExecutorService,它是一个接口:
xxxxxxxxxx131public interface ScheduledExecutorService extends ExecutorService {2 // 1. 单次延时执行3 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); // Runnable任务4 public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit); // Callable任务5 6 // 2. 固定延时重复执行7 // 注意:不同于Timer的固定延时方法,它是从上一个任务结束后才开始计算延时的8 public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);9 10 // 3. 固定频率重复执行11 // 第一次执行时间为initialDelay后,第二次为initialDelay+period,第三次initialDelay+2*period,依次类推12 public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);13}返回类型都是ScheduledFuture,它也是一个接口,实现了Future和Delayed,没有定义额外方法。
注意:
- 与Timer不同,ScheduledExecutorService不支持以绝对时间作为首次运行的时间。
主要实现类为ScheduledThreadPoolExecutor,它是线程池ThreadPoolExecutor的子类,是基于线程池实现的,构造方法如下:
xxxxxxxxxx51public ScheduledThreadPoolExecutor(int corePoolSize) 2public ScheduledThreadPoolExecutor(int corePoolSize, RejectedExecutionHandler handler)3public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) 4public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler)5
工厂类Executors也提供了一些方便的方法,以方便创建ScheduledThreadPoolExecutor,如下所示:
xxxxxxxxxx71// 1. 单线程的定时任务执行服务2public static ScheduledExecutorService newSingleThreadScheduledExecutor()3public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory)4
5// 2. 多线程的定时任务执行服务6public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)7public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory)注意:
- 它的任务队列是一个无界的优先级队列,所以最大线程数对它没有作用。
- 此外,即使corePoolSize设为0,它也会至少运行一个线程。
2) 应用示例
由于可以有多个线程执行定时任务,一般任务就不会被某个长时间运行的任务所延迟了,比如,对于前面的TimerFixedDelay,如果改为:
xxxxxxxxxx261public class ScheduledFixedDelay {2 static class LongRunningTask implements Runnable {3 4 public void run() {5 try {6 Thread.sleep(5000);7 } catch (InterruptedException e) {8 }9 System.out.println("long running finished");10 }11 }12
13 static class FixedDelayTask implements Runnable {14 15 public void run() {16 System.out.println(System.currentTimeMillis());17 }18 }19
20 public static void main(String[] args) throws InterruptedException {21 ScheduledExecutorService timer = Executors.newScheduledThreadPool(10);22 timer.schedule(new LongRunningTask(), 10, TimeUnit.MILLISECONDS);23 timer.scheduleWithFixedDelay(new FixedDelayTask(), 100, 1000,24 TimeUnit.MILLISECONDS);25 }26}再次执行,第二个任务就不会被第一个任务延迟了。
另外,与Timer不同,单个定时任务的异常不会再导致整个定时任务被取消了,即使背后只有一个线程执行任务,我们看个例子:
xxxxxxxxxx261public class ScheduledException {2
3 static class TaskA implements Runnable {4
5 6 public void run() {7 System.out.println("task A");8 }9 }10
11 static class TaskB implements Runnable {12
13 14 public void run() {15 System.out.println("task B");16 throw new RuntimeException();17 }18 }19
20 public static void main(String[] args) throws InterruptedException {21 ScheduledExecutorService timer = Executors22 .newSingleThreadScheduledExecutor();23 timer.scheduleWithFixedDelay(new TaskA(), 0, 1, TimeUnit.SECONDS);24 timer.scheduleWithFixedDelay(new TaskB(), 2, 1, TimeUnit.SECONDS);25 }26}TaskA和TaskB都是每秒执行一次,TaskB两秒后执行,但一执行就抛出异常,屏幕的输出类似如下:
xxxxxxxxxx61task A2task A3task B4task A5task A6...
这说明,定时任务TaskB被取消了,但TaskA不受影响,即使它们是由同一个线程执行的。不过,需要强调的是,与Timer不同,没有异常被抛出来,TaskB的异常没有在任何地方体现。所以,与Timer中的任务类似,应该捕获所有异常。
注意:
- 如果某个任务抛出了异常,那么该任务将不会被重新调度,即使它是一个重复任务。
3) 核心属性
xxxxxxxxxx371/** 存储定时/周期性任务的延迟队列(自定义实现的DelayedQueue) */2private final BlockingQueue<Runnable> workQueue = new DelayedWorkQueue();3/** 任务序列号生成器(保证周期性任务的执行顺序) */4private static final AtomicLong sequencer = new AtomicLong();5
6private class ScheduledFutureTask<V> extends FutureTask<V> implements RunnableScheduledFuture<V> {7 /** 任务的唯一序列号(用于同时间任务的排序) */8 private final long sequenceNumber;9 /** 任务下次执行的时间(纳秒级时间戳) */10 private long time;11 /** 周期性任务的执行周期(纳秒):正数=固定延迟,负数=固定频率,0=非周期性 */12 private final long period;13 /** 任务的执行目标(实际要运行的Runnable/Callable) */14 RunnableScheduledFuture<V> outerTask = this;15 /** 任务在延迟队列中的索引(优化删除效率) */16 int heapIndex;17 18 // 核心方法:计算任务的剩余延迟时间(实现Delayed接口)19 public long getDelay(TimeUnit unit) {20 return unit.convert(time - System.nanoTime(), TimeUnit.NANOSECONDS);21 }22 23 // 核心方法:任务排序规则(先按执行时间,再按序列号)24 public int compareTo(Delayed other) {25 if (other == this) return 0;26 if (other instanceof ScheduledFutureTask) {27 ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;28 long diff = time - x.time;29 if (diff < 0) return -1;30 else if (diff > 0) return 1;31 else if (sequenceNumber < x.sequenceNumber) return -1;32 else return 1;33 }34 long diff = getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS);35 return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;36 }37}
4) 任务调度(schedule)
schedule方法就是将任务和延迟时间封装到一起,并且将任务扔到阻塞队列中,再去创建工作线程去take阻塞队列。
xxxxxxxxxx1081// 延迟任务执行的方法。2// command:任务3// delay:延迟时间4// unit:延迟时间的单位5public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {6 // 健壮性校验。7 if (command == null || unit == null)8 throw new NullPointerException();9
10 // 将任务和延迟时间封装到一起,最终组成ScheduledFutureTask11 // 要分成三个方法去看12 // triggerTime:计算延迟时间。最终返回的是当前系统时间 + 延迟时间 13 // triggerTime就是将延迟时间转换为纳秒,并且+当前系统时间,再做一些健壮性校验14
15 // ScheduledFutureTask有参构造:将任务以及延迟时间封装到一起,并且设置任务执行的方式16
17 // decorateTask:当前方式是让用户基于自身情况可以动态修改任务的一个扩展口18 RunnableScheduledFuture<?> t = decorateTask(command, 19 new ScheduledFutureTask<Void>(command, null,20 triggerTime(delay, unit)));21 // 任务封装好,执行delayedExecute方法,去执行任务22 delayedExecute(t);23
24 // 返回FutureTask25 return t;26}27
28// triggerTime做的事情29// 外部方法,对延迟时间做校验,如果小于0,就直接设置为030// 并且转换为纳秒单位31private long triggerTime(long delay, TimeUnit unit) {32 return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));33}34// 将延迟时间+当前系统时间35// 后面的校验是为了避免延迟时间超过Long的取值范围36long triggerTime(long delay) {37 return now() + ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));38}39
40// ScheduledFutureTask有参构造41ScheduledFutureTask(Runnable r, V result, long ns) {42 super(r, result);43 // time就是任务要执行的时间44 this.time = ns;45 // period,为0,代表任务是延迟执行,不是周期执行46 this.period = 0;47 // 基于AtmoicLong生成的序列48 this.sequenceNumber = sequencer.getAndIncrement();49}50
51
52// delayedExecute 执行延迟任务的操作53private void delayedExecute(RunnableScheduledFuture<?> task) {54 // 查看当前线程池是否还是RUNNING状态,如果不是RUNNING,进到if55 if (isShutdown())56 // 不是RUNNING。57 // 执行拒绝策略。58 reject(task);59 else {60 // 线程池状态是RUNNING61 // 直接让任务扔到延迟的阻塞队列中62 super.getQueue().add(task);63 // DCL的操作,再次查看线程池状态64 // 如果线程池在添加任务到阻塞队列后,状态不是RUNNING65 if (isShutdown() &&66 // task.isPeriodic():现在反回的是false,因为任务是延迟执行,不是周期执行67 // 默认情况,延迟队列中的延迟任务,可以执行68 !canRunInCurrentRunState(task.isPeriodic()) &&69 // 从阻塞队列中移除任务。70 remove(task))71 task.cancel(false);72 else73 // 线程池状态正常,任务可以执行74 ensurePrestart();75 }76}77
78// 线程池状态不为RUNNING,查看任务是否可以执行79// 延迟执行:periodic==false80// 周期执行:periodic==true81// continueExistingPeriodicTasksAfterShutdown:周期执行任务,默认为false82// executeExistingDelayedTasksAfterShutdown:延迟执行任务,默认为true83boolean canRunInCurrentRunState(boolean periodic) {84 return isRunningOrShutdown(periodic ?85 continueExistingPeriodicTasksAfterShutdown :86 executeExistingDelayedTasksAfterShutdown);87}88// 当前情况,shutdownOK为true89final boolean isRunningOrShutdown(boolean shutdownOK) {90 int rs = runStateOf(ctl.get());91 // 如果状态是RUNNING,正常可以执行,返回true92 // 如果状态是SHUTDOWN,根据shutdownOK来决定93 return rs == RUNNING || (rs == SHUTDOWN && shutdownOK);94}95
96
97// 任务可以正常执行后,做的操作98void ensurePrestart() {99 // 拿到工作线程个数100 int wc = workerCountOf(ctl.get());101 // 如果工作线程个数小于核心线程数102 if (wc < corePoolSize)103 // 添加核心线程去处理阻塞队列中的任务104 addWorker(null, true);105 else if (wc == 0)106 // 如果工作线程数为0,核心线程数也为0,这是添加一个非核心线程去处理阻塞队列任务107 addWorker(null, false);108}
5) At和With方法&任务的run方法
这两个方法在源码层面上的第一个区别,就是在计算周期时间时,需要将这个值传递给period,基于正负数在区别At和With
所以查看一个方法就ok,查看At方法:
xxxxxxxxxx781// At方法,2// command:任务3// initialDelay:第一次执行的延迟时间4// period:任务的周期执行时间5// unit:上面两个时间的单位6public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,7 long initialDelay,8 long period,9 TimeUnit unit) {10 // 健壮性校验11 if (command == null || unit == null)12 throw new NullPointerException();13 // 周期时间不能小于等于0.14 if (period <= 0)15 throw new IllegalArgumentException();16 // 将任务以及第一次的延迟时间,和后续的周期时间封装好。17 ScheduledFutureTask<Void> sft =18 new ScheduledFutureTask<Void>(command,19 null,20 triggerTime(initialDelay, unit),21 unit.toNanos(period));22 // 扩展口,可以对任务做修改。23 RunnableScheduledFuture<Void> t = decorateTask(command, sft);24
25 // 周期性任务,需要在任务执行完毕后,重新扔会到阻塞队列,为了方便拿任务,将任务设置到outerTask成员变量中26 sft.outerTask = t;27 // 和schedule方法一样的方式28 // 如果任务刚刚扔到阻塞队列,线程池状态变为SHUTDOWN,默认情况,当前任务不执行29 delayedExecute(t);30 return t;31}32
33// 延迟任务以及周期任务在执行时,都会调用当前任务的run方法。34public void run() {35 // periodic == false:一次性延迟任务36 // periodic == true:周期任务37 boolean periodic = isPeriodic();38 // 任务执行前,会再次判断状态,能否执行任务39 if (!canRunInCurrentRunState(periodic))40 cancel(false);41 // 判断是周期执行还是一次性任务42 else if (!periodic)43 // 一次性任务,让工作线程直接执行command的逻辑44 ScheduledFutureTask.super.run();45 // 到这个else if,说明任务是周期执行46 else if (ScheduledFutureTask.super.runAndReset()) {47 // 设置下次任务执行的时间48 setNextRunTime();49 // 将任务重新扔回线程池做处理50 reExecutePeriodic(outerTask);51 }52}53// 设置下次任务执行的时间54private void setNextRunTime() {55 // 拿到period值,正数:At,负数:With56 long p = period;57 if (p > 0)58 // 拿着之前的执行时间,直接追加上周期时间59 time += p;60 else61 // 如果走到else,代表任务是With方式,这种方式要重新计算延迟时间62 // 拿到当前系统时间,追加上延迟时间,63 time = triggerTime(-p);64}65 // 将任务重新扔回线程池做处理66void reExecutePeriodic(RunnableScheduledFuture<?> task) {67 // 如果状态ok,可以执行68 if (canRunInCurrentRunState(true)) {69 // 将任务扔到延迟队列70 super.getQueue().add(task);71 // DCL,判断线程池状态72 if (!canRunInCurrentRunState(true) && remove(task))73 task.cancel(false);74 else75 // 添加工作线程76 ensurePrestart();77 }78}
3. 面试扩展
1) 对比Timer/TimerTask
ScheduledThreadPoolExecutor的实现思路与Timer基本是类似的,都有一个基于堆的优先级队列,保存待执行的定时任务,主要不同有:
- 它的背后是线程池,可以有多个线程执行任务。
- 它在任务执行后再设置下次执行的时间,对于固定延时的任务更为合理。
- 任务执行线程会捕获任务执行过程中的所有异常,一个定时任务的异常不会影响其他定时任务。
第三节 异步编程
1. FutureTask
1) FutureTask简介
FutureTask 实现了 Future 和 Runnable 接口,表示可取消的异步任务,主要作用如下:
- 任务封装:在构造时传入 Callable 或 Runnable 作为待执行的核心任务。
- 状态管理:通过 AQS 的 state 变量维护任务状态,包括新建、运行、完成、取消。
- 异步执行:执行线程调用 run() 方法执行封装的任务,将结果或异常存储到内部变量。
- 结果获取:通过 get() 方法获取结果,若任务未完成则阻塞等待;任务完成后,直接返回结果或抛出执行时的异常。
xxxxxxxxxx231// 构造方法2FutureTask(Callable<V> callable) // 封装有返回值的异步任务(Callable)3FutureTask(Runnable runnable, V result) // 封装无返回值的异步任务(Runnable)4
5// 结果获取方法6V get() // 阻塞式获取任务执行结果,直到任务完成/取消/异常7V get(long timeout, TimeUnit unit) // 带超时的阻塞获取结果,超时未完成抛TimeoutException8
9// 任务控制方法10boolean cancel(boolean mayInterruptIfRunning) // 尝试取消任务,入参控制是否中断执行线程11
12// 状态查询方法13boolean isDone() // 判断任务是否完成(广义完成,含正常/异常/取消/中断)14boolean isCancelled() // 判断任务是否被取消(此时任务可能仍在执行,只是任务状态已变更)15
16// 任务执行方法17void run() // 执行封装的任务,实现Runnable接口,仅执行一次18
19// 受保护方法(可重写/内部调用)20protected void done() // 任务完成后触发的回调方法,默认空实现21protected void set(V v) // 手动设置任务正常完成的结果,仅NEW状态有效22protected void setException(Throwable t) // 手动设置任务执行异常,仅NEW状态有效23protected boolean runAndReset() // 执行任务但不存储结果,执行后重置为NEW状态
2) 基本使用
xxxxxxxxxx441import java.util.concurrent.ExecutionException;2import java.util.concurrent.FutureTask;3import java.util.concurrent.ThreadPoolExecutor;4import java.util.concurrent.Executors;5
6public class FutureTaskBasicDemo {7 public static void main(String[] args) {8 // 1. 封装Callable任务(计算1-100的累加和)9 FutureTask<Integer> futureTask = new FutureTask<>(() -> {10 int sum = 0;11 for (int i = 1; i <= 100; i++) {12 sum += i;13 // 模拟任务耗时14 Thread.sleep(50);15 }16 return sum;17 });18
19 // 2. 提交任务到线程池执行(推荐使用线程池,而非手动创建线程)20 ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newSingleThreadExecutor();21 executor.submit(futureTask);22
23 try {24 // 3. 主线程执行其他业务逻辑25 System.out.println("主线程处理其他任务...");26 Thread.sleep(200);27
28 // 4. 阻塞获取任务结果29 Integer result = futureTask.get();30 System.out.println("1-100累加和:" + result); // 输出 505031 } catch (InterruptedException e) {32 // 线程中断异常处理33 Thread.currentThread().interrupt();34 System.err.println("获取结果时线程被中断");35 } catch (ExecutionException e) {36 // 任务执行异常处理37 System.err.println("任务执行抛出异常:" + e.getCause());38 } finally {39 // 关闭线程池40 executor.shutdown();41 }42 }43}44
3) 核心属性&构造
FutureTask 是基于 AQS 实现的,通过状态机管理任务生命周期,核心属性如下:
xxxxxxxxxx371public class FutureTask<V> implements RunnableFuture<V> {2 // 1. 任务运行状态(核心控制变量,所有操作围绕该状态展开)3 private volatile int state;4 5 // 状态常量(按执行流程排序)6 // NEW -> COMPLETING -> NORMAL 任务正常执行,并且返回结果也正常返回7 // NEW -> COMPLETING -> EXCEPTIONAL 任务正常执行,但是结果是异常8 // NEW -> CANCELLED 任务被取消 9 // NEW -> INTERRUPTING -> INTERRUPTED 任务被中断10 private static final int NEW = 0; // 初始状态:任务未执行11 private static final int COMPLETING = 1; // 中间状态:任务即将完成(正在设置结果/异常)12 private static final int NORMAL = 2; // 最终状态:任务正常完成(有返回结果)13 private static final int EXCEPTIONAL = 3; // 最终状态:任务抛出异常14 private static final int CANCELLED = 4; // 最终状态:任务被取消15 private static final int INTERRUPTING = 5; // 中间状态:任务正在被中断16 private static final int INTERRUPTED = 6; // 最终状态:任务已被中断17
18 // 2. 待执行的核心任务(Callable 或 Runnable 封装)19 private Callable<V> callable;20 21 // 3. 任务执行结果(正常完成时存储,volatile 保证可见性)22 private Object outcome; // 存储 V 或 Throwable23 24 // 4. 执行任务的线程(通过 CAS 设置,用于中断控制)25 private volatile Thread runner;26 27 // 5. 等待结果的线程链表(替代 AQS,轻量级同步等待队列)28 private volatile WaitNode waiters;29
30 // 内部类:等待节点(存储等待结果的线程)31 static final class WaitNode {32 volatile Thread thread;33 volatile WaitNode next;34 WaitNode() { thread = Thread.currentThread(); }35 }36}37
4) run方法实现
xxxxxxxxxx1141// 当线程池执行 FutureTask 任务时,会调用它的 run 方法2public void run() {3 // 如果当前任务状态不是NEW,直接return告辞4 if (state != NEW || 5 // 如果状态正确是NEW,这边需要基于CAS将runner属性设置为当前线程6 // 如果CAS失败,直接return告辞7 !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread()))8 return;9
10 try {11 // 将要执行的任务拿到12 Callable<V> c = callable;13 // 健壮性判断,保证任务不是null14 // 再次判断任务的状态是NEW(DCL)15 if (c != null && state == NEW) {16 // 执行任务17 // result:任务的返回结果18 // ran:如果为true,任务正常结束。 如果为false,任务异常结束。19 V result;20 boolean ran;21 try {22 // 执行任务23 result = c.call();24 // 正常结果,ran设置为true25 ran = true;26 } catch (Throwable ex) {27 // 如果任务执行期间出了异常28 // 返回结果置位null29 result = null;30 // ran设置为false31 ran = false;32 // 封装异常结果33 setException(ex);34 }35 if (ran)36 // 封装正常结果37 set(result);38 }39 } finally {40 // 将执行任务的线程置位null41 runner = null;42 // 拿到任务的状态43 int s = state;44 // 如果状态大于等于INTERRUPTING45 if (s >= INTERRUPTING)46 // 进来代表任务中断,做一些后续处理47 handlePossibleCancellationInterrupt(s);48 }49}50
51// 没有异常的时候,正常返回结果52protected void set(V v) {53 // 因为任务执行完毕,需要将任务的状态从NEW,修改为COMPLETING54 if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {55 // 将返回结果赋值给 outcome 属性56 outcome = v;57 // 将任务状态变为NORMAL,正常结束58 UNSAFE.putOrderedInt(this, stateOffset, NORMAL);59 // 正常结束60 finishCompletion();61 }62}63
64// 任务执行期间出现了异常,这边要封装结果65protected void setException(Throwable t) {66 // 因为任务执行完毕,需要将任务的状态从NEW,修改为COMPLETING67 if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {68 // 将异常信息封装到 outcome 属性69 outcome = t;70 // 将任务状态变为EXCEPTIONAL,异常结束71 UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); 72 // 异常结束73 finishCompletion();74 }75}76
77// 任务结束后触发78// 只要任务结束了,无论是正常返回,异常返回,还是任务被取消都会执行这个方法79// 而这个方法其实就是唤醒那些执行get方法等待任务结果的线程80private void finishCompletion() {81 // 在任务结束后,需要唤醒82 for (WaitNode q; (q = waiters) != null;) {83 // 第一步直接以CAS的方式将WaitNode置为null84 if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {85 for (;;) {86 // 拿到了Node中的线程87 Thread t = q.thread;88 // 如果线程不为null89 if (t != null) {90 // 第一步先置位null91 q.thread = null;92 // 直接唤醒这个线程93 LockSupport.unpark(t);94 }95 // 拿到当前Node的next96 WaitNode next = q.next;97 // next为null,代表已经将全部节点唤醒了吗,跳出循环98 if (next == null)99 break;100 // 将next置位null101 q.next = null; 102 // q的引用指向next103 q = next;104 }105 break;106 }107 }108
109 // 任务结束后,可以基于这个扩展方法,记录一些信息110 done();111
112 // 任务执行完,把callable具体任务置位null113 callable = null; 114}5) cancel方法实现
任务取消根据参数是否允许中断有两种状态变化:
- 在不允许中断时,任务直接从NEW状态转换为CANCEL。
- 在允许中断时,任务从NEW状态变成INTERRUPTING,然后再转换为INTERRUPTED。
xxxxxxxxxx281// 取消任务操作2public boolean cancel(boolean mayInterruptIfRunning) {3 // 查看任务的状态是否是NEW,如果NEW状态,就基于传入的参数mayInterruptIfRunning4 // 决定任务是直接从NEW转换为CANCEL,还是从NEW转换为INTERRUPTING5 if (!(state == NEW && 6 UNSAFE.compareAndSwapInt(this, stateOffset, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))7 return false;8 try { 9 // 如果mayInterruptIfRunning为true10 // 就需要中断线程11 if (mayInterruptIfRunning) {12 try {13 // 拿到任务线程14 Thread t = runner;15 if (t != null)16 // 如果线程不为null,直接interrupt17 t.interrupt();18 } finally { 19 // 将任务状态设置为INTERRUPTED20 UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);21 }22 }23 } finally {24 // 任务结束后的一些处理~~ 一会看~~25 finishCompletion();26 }27 return true;28}6) get方法实现
xxxxxxxxxx781// 拿任务结果2public V get() throws InterruptedException, ExecutionException {3 // 获取任务的状态4 int s = state;5 // 要么是NEW,任务还没执行完6 // 要么COMPLETING,任务执行完了,结果还没封装好。7 if (s <= COMPLETING)8 // 让当前线程阻塞,等待结果9 s = awaitDone(false, 0L);10 // 最终想要获取结果,需要执行report方法11 return report(s);12}13
14// 线程等待FutureTask结果的过程15private int awaitDone(boolean timed, long nanos) throws InterruptedException {16 // 针对get方法传入了等待时长时,需要计算等到什么时间点17 final long deadline = timed ? System.nanoTime() + nanos : 0L;18 // 声明好需要的Node,queued:放到链表中了么?19 WaitNode q = null;20 boolean queued = false;21 for (;;) {22 // 查看线程是否中断,如果中断,从等待链表中移除,甩个异常23 if (Thread.interrupted()) {24 removeWaiter(q);25 throw new InterruptedException();26 }27 // 拿到状态28 int s = state;29 // 到这,说明任务结束了。30 if (s > COMPLETING) {31 if (q != null)32 // 如果之前封装了WaitNode,现在要清空33 q.thread = null;34 return s;35 }36 // 如果任务状态是COMPLETING,这就不需要去阻塞线程,让步一下,等待一小会,结果就有了37 else if (s == COMPLETING) 38 Thread.yield();39 // 如果还没初始化WaitNode,初始化40 else if (q == null)41 q = new WaitNode();42 // 没放队列的话,直接放到waiters的前面43 else if (!queued)44 queued = UNSAFE.compareAndSwapObject(this, waitersOffset,45 q.next = waiters, q);46 // 准备挂起线程,如果timed为true,挂起一段时间47 else if (timed) {48 // 计算出最多可以等待多久49 nanos = deadline - System.nanoTime();50 // 如果等待的时间没了51 if (nanos <= 0L) {52 // 移除当前的Node,返回任务状态53 removeWaiter(q);54 return state;55 }56 // 等一会57 LockSupport.parkNanos(this, nanos);58 }59 else60 // 死等61 LockSupport.park(this);62 }63}64
65// get的线程已经可以阻塞结束了,基于状态查看能否拿到返回结果66private V report(int s) throws ExecutionException {67 // 拿到outcome 返回结果68 Object x = outcome;69 // 如果任务状态是NORMAL,任务正常结束,返回结果70 if (s == NORMAL)71 return (V)x;72 // 如果任务状态大于等于取消73 if (s >= CANCELLED)74 // 直接抛出异常75 throw new CancellationException();76 // 到这就是异常结束77 throw new ExecutionException((Throwable)x);78}
2. CompletableFuture-基本使用
1) CompletableFuture简介
CompletableFuture 是对 Future 接口的增强,用于对异步任务进行编排组合,是 Java 实现非阻塞异步编程的核心类。
xxxxxxxxxx151// 1. 直接获取一个“未完成”状态的CompletableFuture2// 注意:如果CompletableFuture未完成,获取结果时将会阻塞3public CompletableFuture() 4
5// 2. 直接获取一个“已完成”状态的CompletableFuture6public static <U> CompletableFuture<U> completedFuture(U value)7
8// 3. 异步执行Runnable,获取一个无返回值的CompletableFuture9public static CompletableFuture<Void> runAsync(Runnable runnable)10public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor) // 建议传线程池,否则会使用内部线程池11
12// 4. 异步执行Supplier,获取一个有返回值的CompletableFuture13public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)14public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)15
使用示例如下:
xxxxxxxxxx351public static void 创建和执行() {2 // 1. 直接获取一个“未完成”状态的CompletableFuture3 CompletableFuture<String> unCompletedFuture = new CompletableFuture<>();4 unCompletedFuture.complete("666"); // 使其完成,否则后续join将阻塞5 System.out.println("future01 = " + unCompletedFuture.join());6
7 // 2. 直接获取一个“已完成”状态的CompletableFuture8 CompletableFuture<String> completedFuture = CompletableFuture.completedFuture("777");9 System.out.println("completedFuture = " + completedFuture.join());10
11 // 3. 异步执行Runnable,获取一个无返回值的CompletableFuture12 CompletableFuture<Void> voidCompletableFuture = CompletableFuture.runAsync(new Runnable() {13 14 public void run() {15 try {16 Thread.sleep(1000);17 } catch (InterruptedException e) {18 e.printStackTrace();19 }20 System.out.println("CompletableFuture.runAsync....");21 }22 });23 // 阻塞等待Runnable执行完成24 System.out.println("voidCompletableFuture = " + voidCompletableFuture.join()); // voidCompletableFuture = null25
26 // 4. 异步执行Supplier,获取一个有返回值的CompletableFuture27 CompletableFuture<String> stringCompletableFuture = CompletableFuture.supplyAsync(new Supplier<String>() {28
29 30 public String get() {31 return "888";32 }33 });34 System.out.println("stringCompletableFuture = " + stringCompletableFuture.join()); // stringCompletableFuture = 88835}注意:
- 可以通过executor参数指定执行线程池,如果省略,默认使用ForkJoinPool.commonPool()执行。
- 带Async后缀的函数表示该任务可能被提交到单独线程池中,从而相对前置任务来说是异步运行的。
- 同步处理函数(不带Async)被注册后,如果任务线程未结束,将会使用任务线程执行,如果已结束,将会由当前注册线程执行。
2) 完成和取消任务
xxxxxxxxxx101// 1. 主动完成任务2// 如果任务已经完成,则无任何效果,直接返回false3// 如果是由于该方法导致任务提前完成,则方法返回true,且使用value作为任务结果4public boolean complete(T value) // 任务正常完成5public boolean completeExceptionally(Throwable ex) // 任务异常完成6
7// 2. 主动取消任务8// 如果任务已经完成,则取消无任何效果,直接返回false9// 如果是由于该方法导致任务提前取消,则方法返回true,且在获取结果时抛出CancellationException10public boolean cancel(boolean mayInterruptIfRunning)
3) 获取任务状态
xxxxxxxxxx81// 1. 任务是否被取消(调用了cancel方法)2public boolean isCancelled()3
4// 2. 任务是否完成(包括正常完成、主动完成、抛出异常,不包括任务被取消)5public boolean isDone()6 7// 3. 任务是否为异常完成8public boolean isCompletedExceptionally()
4) 获取任务结果
xxxxxxxxxx71// 1. 阻塞获取结果2public T get() throws InterruptedException, ExecutionException 3public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException 4public T join() // 类似get,但是不会抛出受检异常,而是包装为CompletionException或CancellationException等运行时异常5 6// 2. 立即返回结果7public T getNow(T valueIfAbsent) // 实际任务结果尚未计算出来时,不等待,直接返回valueIfAbsent作为结果
5) 任务完成回调
任务完成回调方法可以接收前一个任务正常结束时的结果值,或前面链路中的任务异常结束时的异常(抛出异常后,链路中的后续任务将不会继续执行),无返回值,不会改变原结果或覆盖原异常。
xxxxxxxxxx331// 1. 任务完成后进行回调2public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action)3public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action)4public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)5
6// 示例1:7// 有一个异步任务,可能正常,也可能抛出异常8CompletableFuture<String> future = CompletableFuture.supplyAsync(new Supplier<String>() {9
10 11 public String get() {12 if (System.currentTimeMillis() % 2 == 0) {13 return "hello";14 }15
16 throw new RuntimeException("当前不是2的倍数");17 }18});19// 为该任务注册完成时的回调20CompletableFuture<String> future_whenComplete = future.whenComplete(new BiConsumer<String, Throwable>() {21 22 public void accept(String result, Throwable throwable) {23 if (result != null) {24 System.out.println("result = " + result); // hello25 }26
27 if (throwable != null) {28 System.out.println("exception = " + throwable); // java.util.concurrent.CompletionException: java.lang.RuntimeException: 当前不是2的倍数29 }30 }31});32System.out.println("future_whenComplete = " + future_whenComplete.join()); // hello 或 任务运行错误33
注意:
- 注册的异常处理逻辑对前面链路中的任务都生效,可参考下方“顺序任务流”案例。
6)结果或异常处理
结果或异常处理方法也可以接收正常结束时的结果值,或异常结束时的异常,但可以修改任务结果,且会覆盖原异常。
xxxxxxxxxx351// 1. 处理结果或异常2public <U> CompletableFuture<U> handle(BiFunction<? super T,Throwable,? extends U> fn)3public <U> CompletableFuture<U> handleAsync(BiFunction<? super T,Throwable,? extends U> fn)4public <U> CompletableFuture<U> handleAsync(BiFunction<? super T,Throwable,? extends U> fn, Executor executor)5
6// 2. 仅处理异常,同时可修改任务结果7public CompletableFuture<T> exceptionally(Function<Throwable,? extends T> fn)8 9// 示例1:handle10CompletableFuture<String> future_handle = future.handle((result, exception) -> {11 if (result != null) {12 System.out.println("result = " + result); // hello13 return result;14 }15
16 if (exception != null) {17 System.out.println("exception = " + exception); // java.util.concurrent.CompletionException: java.lang.RuntimeException: 当前不是2的倍数18 return "任务运行错误";19 }20
21 return "Other"; // 一般不会出现该情形22});23System.out.println("future_handle = " + future_handle.join()); // hello 或 任务运行错误24
25// 示例2:exceptionally26CompletableFuture<String> future_handle = future.exceptionally((exception) -> {27 if (exception != null) {28 System.out.println("exception = " + exception); // java.util.concurrent.CompletionException: java.lang.RuntimeException: 当前不是2的倍数29 return "任务运行错误";30 }31
32 return "Other"; // 一般不会出现该情形33});34System.out.println("future_handle = " + future_handle.join()); // hello 或 任务运行错误35
3. CompletableFuture-任务编排
1) 依赖前一阶段正常完成
下面一些方法可以用来构建依赖单一阶段的任务流,当前一个阶段正常完成时,自动触发所有依赖该阶段的下一阶段任务,如果前一个阶段发生了异常,所有后续阶段都不会执行,结果会被设为相同的异常,调用join会抛出运行时异常CompletionException。
xxxxxxxxxx221// 1. 后接一个基于Runnable构建的阶段(无需接收前一阶段的结果,且该阶段无返回值)2public CompletableFuture<Void> thenRun(Runnable action)3public CompletableFuture<Void> thenRunAsync(Runnable action)4public CompletableFuture<Void> thenRunAsync(Runnable action, Executor executor)5 6// 2. 后接一个基于Consumer构建的阶段,支持接收前一个任务的参数 (可接收前一阶段的结果,但该阶段无返回值)7public CompletableFuture<Void> thenAccept(Consumer<? super T> action)8public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action)9public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action, Executor executor)10
11// 3. 后接一个基于Function构建的阶段,支持接收前一个任务的参数,以及返回自定义类型的结果 (可接收前一阶段的结果,且该阶段有返回值)12public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)13public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)14public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)15
16// 4. 后接一个返回的CompletionStage,支持接收前一个任务的参数,以及返回CompletionStage类型的结果 (可接收前一阶段的结果,但该阶段有返回值,并且返回值类型必须是CompletionStage或其子类)17// 注意:该方法自动将返回的CompletionStage作为下一阶段,而不会再构建嵌套的阶段,主要用于组合另一个CompletionStage18// 如果使用thenApply组合另一个CompletionStage话,那么将会返回嵌套的CompletableFuture<CompletableFuture<U>>类型,要使用join().join()才能获取结果19public <U> CompletableFuture<U> thenCompose(Function<? super T, ? extends CompletionStage<U>> fn)20public <U> CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn)21public <U> CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn, Executor executor)22
简单示例如下:
xxxxxxxxxx601// 示例1:thenRun/thenAccept/thenApply2public static void 顺序任务流() {3 CompletableFuture<String> future = CompletableFuture4 .runAsync(() -> System.out.println("Step A1"))5 .thenRun(() -> System.out.println("Step A2"))6 .thenAccept(perResult -> {7 System.out.println("thenAccept.perResult = " + perResult);8 System.out.println("Step A3");9 //throw new RuntimeException("演示错误情形");10 })11 .thenApply(perResult -> {12 System.out.println("thenApply.perResult = " + perResult);13 System.out.println("Step A4");14 return "thenApply...";15 }).handle(new BiFunction<String, Throwable, String>() {16 17 public String apply(String s, Throwable throwable) {18 if (s != null) {19 return "任务完成,结果为[" + s + "]";20 }21
22 if (throwable != null) {23 return "出现了[" + throwable.getMessage() + "]异常,但是被我处理了";24 }25
26 return "未知情形";27 }28 });29 System.out.println("future = " + future.join()); // thenApply...30}31
32// 示例2:thenCompose33public static void 顺序任务流2() {34 CompletableFuture<Void> completableFuture = CompletableFuture35 .supplyAsync(new Supplier<String>() {36 37 public String get() {38 return "hello";39 }40 })41 // 组合另一个CompletionStage<String>42 .thenCompose(new Function<String, CompletionStage<String>>() {43 44 public CompletionStage<String> apply(String s) {45 return CompletableFuture.supplyAsync(new Supplier<String>() {46 47 public String get() {48 return s.toUpperCase();49 }50 });51 }52 })53 .thenAccept(new Consumer<String>() {54 55 public void accept(String s) {56 System.out.println("hello");57 }58 });59 System.out.println("completableFuture = " + completableFuture.join());60}注意:
- 以run、accept、apply开头的方法,参数类型一般为Runnable、Consumer、Function类型。
- 在调用 thenXxx 时,如果前一阶段任务已经结束,那么将会在调用者线程执行子任务,可以使用 thenXxxAsync 避免该情形。
2) 依赖前两阶段都正常完成
当一个阶段正常完成,且指定的另一个阶段也正常完成时,才触发下一阶段。注意,这两个阶段可以并行执行,并且没有依赖关系。
xxxxxxxxxx271// 1. 后接一个基于Runnable构建的阶段,在other也正常完成时执行2public CompletableFuture<Void> runAfterBoth(CompletionStage<?> other, Runnable action)3public CompletableFuture<Void> runAfterBothAsync(CompletionStage<?> other, Runnable action)4public CompletableFuture<Void> runAfterBothAsync(CompletionStage<?> other, Runnable action, Executor executor)5
6// 2. 接受前两个阶段的结果作为参数,但不返回结果7public <U> CompletableFuture<Void> thenAcceptBoth(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action)8public <U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action)9public <U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action, Executor executor)10
11// 3. 接受前两个阶段的结果作为参数,返回一个结果12public <U,V> CompletableFuture<V> thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)13public <U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)14public <U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor)15
16// 示例1:17public static void 两个都正常完成才执行() {18 Supplier<String> taskA = () -> "taskA";19 CompletableFuture<String> taskB = CompletableFuture.supplyAsync(() -> "taskB");20 BiFunction<String, String, String> taskC = (a, b) -> a + "," + b;21
22 CompletableFuture<String> completableFuture = CompletableFuture23 .supplyAsync(taskA)24 .thenCombineAsync(taskB, taskC); // 当前任务A和任务B都正常完成才执行任务C25 System.out.println(completableFuture.join()); // taskA,taskB26}27
3) 依赖前两阶段之一正常完成
当前阶段和指定的另一个阶段,只要其中一个正常完成,就会启动下一阶段任务。
xxxxxxxxxx361// 1. Runnable2public CompletableFuture<Void> runAfterEither(CompletionStage<?> other, Runnable action)3public CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other, Runnable action) 4public CompletableFuture<Void> runAfterEitherAsync(CompletionStage<?> other, Runnable action, Executor executor)5
6// 2. Consumer7public CompletableFuture<Void> acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action)8public CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action)9public CompletableFuture<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action, Executor executor)10
11// 3. Function12public <U> CompletableFuture<U> applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn)13public <U> CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn)14public <U> CompletableFuture<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn, Executor executor)15
16// 示例1:17public static void 两者之一正常完成就执行() {18 CompletableFuture<Void> otherCompletableFuture = CompletableFuture.runAsync(() -> {19 try {20 Thread.sleep(5000);21 } catch (InterruptedException e) {22 e.printStackTrace();23 }24 });25
26 CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {27 try {28 Thread.sleep(500);29 } catch (InterruptedException e) {30 e.printStackTrace();31 }32 }).runAfterEither(otherCompletableFuture, () -> System.out.println("ok")); // 500ms后打印ok33
34 System.out.println(completableFuture.join()); // 500ms后输出null35}36
4) 构建依赖多个阶段的任务流
如果依赖的阶段不止两个,可以使用如下静态方法,基于多个CompletableFuture构建了一个新的CompletableFuture。
xxxxxxxxxx511// 1. 当所有子阶段都完成时,它才完成,如果某个阶段异常,则它的结果也是异常2// 某个子阶段异常时并不会导致其它子阶段提前结束,如果多个阶段出现异常,则只会保留最新的那个3// 注意:它只会持有异常结果,并不会保存正常结束的结果,如果需要,可以从每个阶段中获取4public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs) // 获取所有完成结果;如果最快完成的任务出现了异常,也会先返回异常,如果害怕出错可以加个exceptionally() 去处理一下可能发生的异常并设定默认返回值5
6// 2. 当第一个子阶段完成或异常结束时,它相应地完成或异常结束,结果与第一个结束的子阶段一样7public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)8
9// 示例1:allOf10public static void 依赖所有子阶段完成() {11 CompletableFuture<String> taskA = CompletableFuture.supplyAsync(() -> {12 try {13 Thread.sleep(500);14 } catch (InterruptedException e) {15 e.printStackTrace();16 }17 return "helloA";18 });19
20 CompletableFuture<Void> taskB = CompletableFuture.runAsync(() -> {21 try {22 Thread.sleep(200);23 } catch (InterruptedException e) {24 e.printStackTrace();25 }26 });27
28 CompletableFuture<Void> taskC = CompletableFuture.runAsync(() -> {29 try {30 Thread.sleep(1000);31 } catch (InterruptedException e) {32 e.printStackTrace();33 }34 throw new RuntimeException("task C exception");35 });36
37 // 只有在taskA, taskB, taskC都完成后才完成38 CompletableFuture<Void> completableFuture = CompletableFuture.allOf(taskA, taskB, taskC).whenComplete((result, throwable) -> {39 // 最新的异常40 if (throwable != null) {41 System.out.println(throwable.getMessage()); // java.lang.RuntimeException: task C exception42 }43
44 // 获取子阶段A的结果45 if (!taskA.isCompletedExceptionally()) {46 System.out.println("task A " + taskA.join()); // task A helloA47 }48 });49 System.out.println("completableFuture = " + completableFuture.join()); // CompletionException: java.lang.RuntimeException: task C exception50}51
4. CompletableFuture-源码分析
1) 核心属性
xxxxxxxxxx361// 1. 核心:存储任务结果/异常(状态载体)2// - 正常结果:直接存储业务返回值3// - 异常结果:包装为内部类 AltResult4// - 未完成:null 或特殊标记5volatile Object result;6
7// 2. 核心:回调链表头节点(管理待执行的回调任务)8// - 类型为 Completion(抽象回调接口)9// - 子类:UniApply(thenApply)、UniWhenComplete(whenComplete) 等10volatile Completion stack;11
12// 3. 同步锁:多线程竞争下保证状态修改/回调执行的线程安全13private transient Object sync;14
15// 4. 状态标记(通过 UNSAFE 操作的 volatile int 字段)16// 核心状态:NEW(0) → COMPLETING(1) → NORMAL(2)/EXCEPTIONAL(3)/CANCELLED(4) 等17private volatile int state;18
19// 内部异常容器:包装异常结果(仅内部使用)20private static final class AltResult {21 final Throwable ex;22 AltResult(Throwable x) { ex = x; }23}24
25// 状态常量定义26// 1. 不可回退:只能从 NEW → 中间态 → 终态,终态不可修改27// 2. 原子性:通过 CAS 操作保证状态修改线程安全28// 3. 驱动回调:状态变为终态时,自动触发 stack 链表中的回调29private static final int NEW = 0; // 初始状态:任务未开始/未完成30private static final int COMPLETING = 1; // 中间状态:结果已计算,未通知回调(短暂)31private static final int NORMAL = 2; // 终态:任务正常完成,result 存返回值32private static final int EXCEPTIONAL = 3; // 终态:任务异常,result 存 AltResult(包装异常)33private static final int CANCELLED = 4; // 终态:任务被取消34private static final int INTERRUPTED = 5; // 终态:任务被中断35private static final int TIMED_OUT = 6; // 终态:任务超时(JDK9+)36
2) 执行当前任务
将任务和CompletableFuture封装到一起,再执行封装好的具体对象的run方法即可:
xxxxxxxxxx561// 提交任务到CompletableFuture2public static CompletableFuture<Void> runAsync(Runnable runnable) {3 // asyncPool:执行任务的线程池4 // runnable:具体任务。5 return asyncRunStage(asyncPool, runnable);6}7
8// 内部执行的方法9static CompletableFuture<Void> asyncRunStage(Executor e, Runnable f) {10 // 对任务做非空校验11 if (f == null) throw new NullPointerException();12 // 直接构建了CompletableFuture的对象,作为最后的返回结果13 CompletableFuture<Void> d = new CompletableFuture<Void>();14 // 将任务和CompletableFuture对象封装为了AsyncRun的对象15 // 将封装好的任务交给了线程池去执行16 e.execute(new AsyncRun(d, f));17 // 返回构建好的CompletableFuture18 return d;19}20
21// 封装任务的AsyncRun类信息22static final class AsyncRun extends ForkJoinTask<Void> implements Runnable, AsynchronousCompletionTask {23 // 声明存储CompletableFuture对象以及任务的成员变量24 CompletableFuture<Void> dep; 25 Runnable fn;26
27 // 将传入的属性赋值给成员变量28 AsyncRun(CompletableFuture<Void> dep, Runnable fn) {29 this.dep = dep; 30 this.fn = fn;31 }32 // 当前对象作为任务提交给线程池之后,必然会执行当前方法33 public void run() {34 // 声明局部变量35 CompletableFuture<Void> d; Runnable f;36 // 将成员变量赋值给局部变量,并且做非空判断37 if ((d = dep) != null && (f = fn) != null) {38 // help GC,将成员变量置位null,只要当前任务结束后,成员变量也拿不到引用。39 dep = null; fn = null;40 // 先确认任务没有执行。41 if (d.result == null) {42 try {43 // 直接执行任务44 f.run();45 // 当前方法是针对Runnable任务的,不能将结果置位null46 // 要给没有返回结果的Runnable做一个返回结果47 d.completeNull();48 } catch (Throwable ex) {49 // 异常结束!50 d.completeThrowable(ex);51 }52 }53 d.postComplete();54 }55 }56}
3) 编排后续任务
首先如果要在前继任务处理后,执行后置任务的话。
有两种情况:
- 前继任务如果没有执行完毕,后置任务需要先放在stack栈结构中存储
- 前继任务已经执行完毕了,后置任务就应该直接执行,不需要在往stack中存储了。
如果单独采用thenRun在一个任务后面指定多个后继任务,CompletableFuture无法保证具体的执行顺序,而影响执行顺序的是前继任务的执行时间,以及后置任务编排的时机。
xxxxxxxxxx331// 编排任务,前继任务搞定,后继任务再执行2public CompletableFuture<Void> thenRun(Runnable action) {3 // 执行了内部的uniRunStage方法,4 // null:线程池,现在没给。5 // action:具体要执行的任务6 return uniRunStage(null, action);7}8
9// 内部编排任务方法10private CompletableFuture<Void> uniRunStage(Executor e, Runnable f) {11 // 后继任务不能为null,健壮性判断12 if (f == null) throw new NullPointerException();13 // 创建CompletableFuture对象d,与后继任务f绑定14 CompletableFuture<Void> d = new CompletableFuture<Void>();15 // 如果线程池不为null,代表异步执行,将任务压栈16 // 如果线程池是null,先基于uniRun尝试下,看任务能否执行17 if (e != null || !d.uniRun(this, f, null)) {18 // 如果传了线程池,这边需要走一下具体逻辑19 // e:线程池20 // d:后继任务的CompletableFuture21 // this:前继任务的CompletableFuture22 // f:后继任务23 UniRun<T> c = new UniRun<T>(e, d, this, f);24 // 将封装好的任务,push到stack栈结构25 // 只要前继任务没结束,这边就可以正常的将任务推到栈结构中26 // 放入栈中可能会失败27 push(c);28 // 无论压栈成功与否,都要尝试执行以下。29 c.tryFire(SYNC);30 }31 // 无论任务执行完毕与否,都要返回后继任务的CompletableFuture32 return d;33}
4) 执行后续任务
任务在编排到前继任务时,因为前继任务已经结束了,这边后置任务会主动的执行:
xxxxxxxxxx791// 后置任务无论压栈成功与否,都需要执行tryFire方法2static final class UniRun<T> extends UniCompletion<T,Void> {3
4 Runnable fn;5 // executor:线程池6 // dep:后置任务的CompletableFuture7 // src:前继任务的CompletableFuture8 // fn:具体的任务9 UniRun(Executor executor, CompletableFuture<Void> dep,CompletableFuture<T> src, Runnable fn) {10 super(executor, dep, src); this.fn = fn;11 }12
13 final CompletableFuture<Void> tryFire(int mode) {14 // 声明局部变量15 CompletableFuture<Void> d; CompletableFuture<T> a;16 // 赋值局部变量17 // (d = dep) == null:赋值加健壮性校验18 if ((d = dep) == null ||19 // 调用uniRun。20 // a:前继任务的CompletableFuture21 // fn:后置任务22 // 第三个参数:传入的是this,是UniRun对象23 !d.uniRun(a = src, fn, mode > 0 ? null : this))24 // 进到这,说明前继任务没结束,等!25 return null;26 dep = null; src = null; fn = null;27 return d.postFire(a, mode);28 }29}30
31// 是否要主动执行任务32final boolean uniRun(CompletableFuture<?> a, Runnable f, UniRun<?> c) {33 // 方法要么正常结束,要么异常结束34 Object r; Throwable x;35 // a == null:健壮性校验36 // (r = a.result) == null:判断前继任务结束了么?37 // f == null:健壮性校验38 if (a == null || (r = a.result) == null || f == null)39 // 到这代表任务没结束。40 return false;41 // 后置任务执行了没? == null,代表没执行42 if (result == null) {43 // 如果前继任务的结果是异常结束。如果前继异常结束,直接告辞,封装异常结果44 if (r instanceof AltResult && (x = ((AltResult)r).ex) != null)45 completeThrowable(x, r);46 else47 // 到这,前继任务正常结束,后置任务正常执行48 try {49 // 如果基于tryFire(SYNC)进来,这里的C不为null,执行c.claim50 // 如果是因为没有传递executor,c就是null,不会执行c.claim51 if (c != null && !c.claim())52 // 如果返回false,任务异步执行了,直接return false53 return false;54 // 如果claim没有基于线程池运行任务,那这里就是同步执行55 // 直接f.run了。56 f.run();57 // 封装Null结果58 completeNull();59 } catch (Throwable ex) {60 // 封装异常结果61 completeThrowable(ex);62 }63 }64 return true;65}66
67// 异步的线程池处理任务68final boolean claim() {69 Executor e = executor;70 if (compareAndSetForkJoinTaskTag((short)0, (short)1)) {71 // 只要有线程池对象,不为null72 if (e == null)73 return true;74 executor = null; // disable75 // 基于线程池的execute去执行任务76 e.execute(this);77 }78 return false;79}前继任务执行完毕后,基于嵌套的方式执行后置。
xxxxxxxxxx381// A:嵌套了B+C, B:嵌套了D+E2// 前继任务搞定,遍历stack执行后置任务3// A任务处理完,解决嵌套的B和C4final void postComplete() {5 // f:前继任务的CompletableFuture6 // h:存储后置任务的栈结构7 CompletableFuture<?> f = this; Completion h;8 // (h = f.stack) != null:赋值加健壮性判断,要确保栈中有数据9 while ((h = f.stack) != null ||10 // 循环一次后,对后续节点的赋值以及健壮性判断,要确保栈中有数据11 (f != this && (h = (f = this).stack) != null)) {12 // t:当前栈中任务的后续任务13 CompletableFuture<?> d; Completion t;14 // 拿到之前的栈顶h后,将栈顶换数据15 if (f.casStack(h, t = h.next)) {16 if (t != null) {17 if (f != this) {18 pushStack(h);19 continue;20 }21 h.next = null; // detach22 }23 // 执行tryFire方法,24 f = (d = h.tryFire(NESTED)) == null ? this : d;25 }26 }27}28
29// 回来了 NESTED == -130final CompletableFuture<Void> tryFire(int mode) {31 CompletableFuture<Void> d; CompletableFuture<T> a;32 if ((d = dep) == null ||33 !d.uniRun(a = src, fn, mode > 0 ? null : this))34 return null;35 dep = null; src = null; fn = null;36 // 内部会执行postComplete,运行B内部嵌套的D和E37 return d.postFire(a, mode);38}
5) 流程图总结
5. 面试扩展
1) Runnable vs Future vs FutureTask
- Runnable:是一个接口,它定义了一个可以被线程执行的任务,与之相关的还有能返回结果和抛异常的Callable。
- Future:也是一个接口,它表示一个异步计算的结果,并提供了一些方法来管理异步任务,如:get、cancel、isDone等。
- FutureTask:同时实现了
Runnable和Future,具备两者特征,并供了一些额外的功能,例如执行任务的 run 方法等。
第四节 Fork/Join框架
1. Fork/Join框架简介
Fork/Join框架是一个并行任务执行框架,它把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果,适用于多核环境的可分割计算再合并结果的计算密集型任务。
- Fork:递归地将任务分解为较小的独立子任务,直到它们足够简单以便异步执行。
- Join:将所有子任务的结果递归合并成单个结果,或者在任务无返回值的情况下,等待每个子任务执行完毕。
注意:
- ForkJoinPool不是为了替代ExecutorService,而是它的补充,在某些应用场景下(计算密集型任务)性能比ExecutorService更好。
- ForkJoinPool主要用于实现分而治之的算法,特别是分治之后递归调用的函数,例如QuickSort等;
- ForkJoinPool的宗旨是使用少量的线程来处理大量的任务,多个线程获取到多个处理器的时间分片,并行的执行子任务。
2. Fork/Join框架原理
Fork/Join框架其实就是指由ForkJoinPool作为线程池、ForkJoinTask作为异步任务、ForkJoinWorkerThread作为执行任务的线程这三者构成的任务调度机制。
1) ForkJoinPool
ForkJoinPool是ExecutorService的一个实现,用于管理工作线程,以及提供获取线程池状态和性能信息的相关方法。
xxxxxxxxxx61// 1. 获取公共ForkJoinPool线程池2// 使用预定义的公共池可以减少资源消耗,因为它会避免每个任务创建一个单独的线程池3ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();4
5// 2. 提交任务给线程池6public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)ForkJoinPool中的每个工作线程都有自己的双端队列(WorkQueue)用于存储任务(ForkJoinTask),并且使用了一种名为工作窃取(work-stealing)算法来平衡线程的工作负载。
注意:
- 工作窃取(work-stealing)算法指空闲的线程试图从繁忙线程的队列中(队首)窃取任务。
2) ForkJoinWorkerThread
ForkJoinWorkerThread直接继承了Thread,是被ForkJoinPool管理的工作线程,由它来执行ForkJoinTask。
3) ForkJoinTask<V>
ForkJoinTask抽象类表示一个可分割计算再合并结果的异步任务,常用方法如下:
xxxxxxxxxx111// 1. 推入工作线程的工作队列异步执行2public final ForkJoinTask<V> fork()3
4// 2. 等待任务执行结果5public final V join()6
7// 3. 立即执行任务,并等待返回结果8public final V invoke()9
10// 4. 批量执行任务,并等待它们执行结束11public static void invokeAll(ForkJoinTask<?>... tasks)它有两个子抽象类RecursiveAction和RecursiveTask,分别表示无返回结果和有返回结果的异步任务,我们一般使用它们。
3. Fork/Join的使用
xxxxxxxxxx731// 示例1:使用Fork/Join框架拆分计算1+2+...+100002public class RecursiveTaskDemo extends RecursiveTask<Integer> {3 private int from; // 计算区间开始值4 private int to; // 计算区间结束值5
6 private static final int THRESHOLD = 1000; // 停止拆分阈值7
8 public RecursiveTaskDemo(int from, int to) {9 super();10 this.from = from;11 this.to = to;12 }13
14 15 protected Integer compute() {16 // 是否需要继续拆分17 if ((to - from) < THRESHOLD) {18 // 否,进行计算19 return IntStream.range(from, to + 1).reduce((a, b) -> a + b).getAsInt(); // 汇总from~to+120
21 } else {22 // 是,继续拆分23 int forkNumber = (from + to) / 2;24 System.out.println(String.format("拆分%d - %d ==> %d ~ %d, %d~%d", 25 from, to, from, forkNumber, forkNumber + 1, to));26 RecursiveTaskDemo left = new RecursiveTaskDemo(from, forkNumber);27 RecursiveTaskDemo right = new RecursiveTaskDemo(forkNumber + 1, to);28
29 // 将子任务放入队列,并安排异步执行30 left.fork();31 right.fork();32 // invokeAll(left, right); 也可以使用invokeAll,保证执行顺序33
34 // 分别拿到两个子任务的值,并进行合并35 return left.join() + right.join(); //阻塞当前线程并等待获取结果36 }37 }38
39 public static void main(String[] args) throws ExecutionException, InterruptedException {40 // 获取ForkJoinPool的公共线程池41 ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();42 // 创建一个ForkJoinPool43 // ForkJoinPool forkJoinPool = (ForkJoinPool) Executors.newWorkStealingPool();44
45 // 提交可拆分合并的计算密集型任务:RecursiveTaskDemo46 ForkJoinTask<Integer> result = forkJoinPool.submit(new RecursiveTaskDemo(1, 10000));47
48 // 获取任务结果49 System.out.println("计算结果为" + result.get());50
51 // 关闭线程池52 forkJoinPool.shutdown();53 }54}55
56/*57拆分1 - 10000 ==> 1 ~ 5000, 5001~1000058拆分1 - 5000 ==> 1 ~ 2500, 2501~500059拆分5001 - 10000 ==> 5001 ~ 7500, 7501~1000060拆分1 - 2500 ==> 1 ~ 1250, 1251~250061拆分7501 - 10000 ==> 7501 ~ 8750, 8751~1000062拆分5001 - 7500 ==> 5001 ~ 6250, 6251~750063拆分1 - 1250 ==> 1 ~ 625, 626~125064拆分5001 - 6250 ==> 5001 ~ 5625, 5626~625065拆分1251 - 2500 ==> 1251 ~ 1875, 1876~250066拆分7501 - 8750 ==> 7501 ~ 8125, 8126~875067拆分2501 - 5000 ==> 2501 ~ 3750, 3751~500068拆分6251 - 7500 ==> 6251 ~ 6875, 6876~750069拆分8751 - 10000 ==> 8751 ~ 9375, 9376~1000070拆分2501 - 3750 ==> 2501 ~ 3125, 3126~375071拆分3751 - 5000 ==> 3751 ~ 4375, 4376~500072计算结果为5000500073 */注意:
- 如果拆分逻辑比计算逻辑还要复杂时,ForkJoinPool并不会带来性能的提升,反而可能会起到负面作用。