第02篇_Java进阶
第01章_数据库编程(JDBC)
第一节 JDBC的基本使用
1. JDBC简介
JDBC(Java DataBase Connectivity)是官方定义的一套操作关系数据库的接口,各数据库厂商实现了这套接口,提供相应的驱动包。
x1<!-- Mysql 8.x 驱动-->2<dependency>3 <groupId>mysql</groupId>4 <artifactId>mysql-connector-java</artifactId>5 <version>8.0.32</version>6</dependency>7
8<!-- Mysql 5.x 驱动-->9<dependency>10 <groupId>mysql</groupId>11 <artifactId>mysql-connector-java</artifactId>12 <version>5.1.49</version>13</dependency>14
注意:
Oracle和SqlServer等数据库由于版权原因,无法从Maven中央仓库下载驱动包,需手动安装。
常见的Oracle驱动包版本有:ojdbc14-10.2.0.5.0.jar、ojdbc6-11.2.0.4.jar、ojdbc8-12.2.0.1.jar、ojdbc8-21.1.0.0.jar。
常见的SqlServer驱动包版本有:sqljdbc4-4.0.jar、mssql-jdbc-9.2.1.jre8.jar。
2. 基本增删改查
1) 直接执行SQL
741public class JdbcTest {2
3 private static final String MYSQL_URL = "jdbc:mysql://106.53.120.230:3306/test01";4 private static final String MYSQL_USER = "root";5 private static final String MYSQL_PASSWORD = "Hyx147741";6
7 private static final String ORACLE_URL = "jdbc:oracle:thin:@127.0.0.1:1521:ORCL01";8 private static final String ORACLE_USER = "kbssfms";9 private static final String ORACLE_PASSWORD = "kbssfms";10
11 private static final String MSSQL_URL = "jdbc:sqlserver://localhost:1433; DatabaseName=test";12
13 private Connection mysql_connection;14 private Connection oracle_connection;15 private Statement statement;16 private PreparedStatement preparedStatement;17 private CallableStatement callableStatement;18 private ResultSet resultSet;19
20 21 public void init() throws SQLException {22 // 1. 注册驱动23 try {24 Class.forName("com.mysql.jdbc.Driver");25 Class.forName("oracle.jdbc.driver.OracleDriver");26 Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");27 } catch (ClassNotFoundException e) {28 e.printStackTrace();29 }30
31 // 2. 获取连接32 mysql_connection = DriverManager.getConnection(MYSQL_URL, MYSQL_USER, MYSQL_PASSWORD);33 oracle_connection = DriverManager.getConnection(ORACLE_URL, ORACLE_USER, ORACLE_PASSWORD);34 }35
36 37 public void testStatement() throws SQLException {38 // 3.1 创建Statement39 statement = mysql_connection.createStatement();40
41 // 3.2 执行查询语句42 resultSet = statement.executeQuery("select * from user");43
44 // 3.3 处理结果45 int columnCount = resultSet.getMetaData().getColumnCount();46 while (resultSet.next()) {47 for (int i = 1; i <= columnCount; i++) {48 System.out.print(resultSet.getMetaData().getColumnLabel(i) + "=" + resultSet.getObject(i) + "\t");49 }50 System.out.println();51 }52 }53
54 55 public void destroy() {56 // 4. 释放资源57 doClose(resultSet);58 doClose(statement);59 doClose(preparedStatement);60 doClose(callableStatement);61 doClose(mysql_connection);62 }63 64 private void doClose(AutoCloseable autoCloseable) {65 if (autoCloseable != null) {66 try {67 autoCloseable.close();68 } catch (Exception exception) {69 exception.printStackTrace();70 }71 }72 }73}74
SQL脚本如下:
131-- MYSQL:user2CREATE TABLE `user` (3 `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '用户编号',4 `username` varchar(32) NOT NULL COMMENT '用户名称',5 `birthday` datetime NOT NULL COMMENT '用户生日',6 `sex` char(2) NOT NULL COMMENT '性别,0男1女',7 `address` varchar(255) DEFAULT NULL COMMENT '用户地址',8 PRIMARY KEY (`id`)9) ENGINE=InnoDB AUTO_INCREMENT=44 DEFAULT CHARSET=utf8 COMMENT='用户表'10INSERT INTO user (id, username, birthday, sex, address) VALUES (1, 'hyx01', '1999-09-13 00:00:00', '0', 'shenzheng');11INSERT INTO user (id, username, birthday, sex, address) VALUES (2, 'hyx2', '1998-09-13 00:00:00', '1', 'shenzheng');12commit;13
2) 预编译执行SQL
151public void testPrepareStatement() throws SQLException {3 // 3.1 创建prepareStatement4 preparedStatement = mysql_connection.prepareStatement("update user set username = ? where id = ?");5
6 // 3.2 设置参数并执行7 preparedStatement.setString(1, "hyx01");8 preparedStatement.setInt(2, 1);9 int update = preparedStatement.executeUpdate();10
11 // 3.3 处理结果12 if (update > 0) {13 System.out.println("更新成功...");14 }15}
3) 调用存储过程
131public void javaCallProcedure() throws Exception {3 // 3.1 创建CallableStatement4 CallableStatement callableStatement = oracle_connection.prepareCall("{call p_yearsal(?, ?)}");5
6 // 3.2 设置参数并执行7 callableStatement.setObject(1, 7788);8 callableStatement.registerOutParameter(2, OracleTypes.NUMBER);9 callableStatement.execute();10
11 // 3.3 输出结果(第二个参数)12 System.out.println(callableStatement.getObject(2)); // 3600013}SQL脚本如下:
331-- Oracle:EMP2create table EMP3(4 empno NUMBER(4),5 ename VARCHAR2(10),6 job VARCHAR2(9),7 mgr NUMBER(4),8 hiredate DATE,9 sal NUMBER(7, 2),10 comm NUMBER(7, 2),11 deptno NUMBER(2)12);13insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)14values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20);15commit;16
17-- 创建存储过程18create or replace procedure p_yearsal(eno emp.empno%type, yearsal out number)19 is20 s number(10);21 c emp.comm%type;22begin23 select sal * 12, nvl(comm, 0) into s, c from emp where empno = eno;24 yearsal := s + c;25end;26
27-- 调用存储过程28declare29 yearsal number(10);30begin31 p_yearsal(7788, yearsal);32 dbms_output.put_line(yearsal);33end;
4) 调用存储函数
131public void javaCallFunction() throws Exception {3 // 3.1 创建CallableStatement4 CallableStatement pstm = oracle_connection.prepareCall("{?= call f_yearsal(?)}");5
6 // 3.2 设置参数并执行7 pstm.setObject(2, 7788);8 pstm.registerOutParameter(1, OracleTypes.NUMBER);9 pstm.execute();10
11 // 3.3 输出结果(第一个参数)12 System.out.println(pstm.getObject(1)); // 3600013}SQL脚本如下:
161-- 创建存储函数2create or replace function f_yearsal(eno emp.empno%type) return number3 is4 s number(10);5begin6 select sal * 12 + nvl(comm, 0) into s from emp where empno = eno;7 return s;8end;9
10-- 调用存储函数11declare12 s number(10);13begin14 s := f_yearsal(7788);15 dbms_output.put_line(s);16end;
5) JDBC批处理
601public void jdbcBatch() throws SQLException {3 ArrayList<List<Integer>> batchResults = new ArrayList<>();4 int[] results = null;5 boolean isAutoCommit = mysql_connection.getAutoCommit();6
7 int TOTAL_NUM = 100;8 int PER_NUM = 30;9
10 try {11 // 3.1 设置为非自动提交12 mysql_connection.setAutoCommit(false);13
14 // 3.2 创建PrepareStatement15 preparedStatement = mysql_connection.prepareStatement("INSERT INTO user (id, username, birthday, sex, address) VALUES (null, ?, ?, ?, ?)");16
17 // 3.3 设置参数并执行18 for (int i = 1; i <= TOTAL_NUM; i++) {19
20 // 3.3.1 设置参数并添加到缓冲区21 preparedStatement.setString(1, "hyx_" + i);22 preparedStatement.setDate(2, new Date(System.currentTimeMillis()));23 preparedStatement.setString(3, "男");24 preparedStatement.setString(4, "深圳市");25 preparedStatement.addBatch();26
27 // 3.3.2 每N个作为一批次执行28 if (i % PER_NUM == 0) {29 results = preparedStatement.executeBatch();30 mysql_connection.commit();31 batchResults.add(Arrays.stream(results).boxed().collect(Collectors.toList()));32 preparedStatement.clearBatch();33 }34 }35
36 // 3.3.3 最后一个批次执行37 if (TOTAL_NUM % PER_NUM != 0) {38 results = preparedStatement.executeBatch();39 mysql_connection.commit();40 batchResults.add(Arrays.stream(results).boxed().collect(Collectors.toList()));41 preparedStatement.clearBatch();42 }43
44 } finally {45 // 3.4 回退自动提交标记46 mysql_connection.setAutoCommit(isAutoCommit);47 }48
49 // 3.5 处理结果50 for (int i = 0; i < batchResults.size(); i++) {51 System.out.println("第" + (i + 1) + "批次结果: " + batchResults.get(i));52 }53}54
55/*56第1批次结果: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]57第2批次结果: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]58第3批次结果: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]59第4批次结果: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]60*/
3. JDBCUtils
601public class JDBCUtils {2 private static String driver;3 private static String url;4 private static String user;5 private static String password;6
7 static {8 try {9 // 1. 加载JDBC配置10 Properties properties = new Properties();11 properties.load(JDBCUtils.class.getClassLoader().getResourceAsStream("jdbc.properties"));12
13 // 2. 设置属性值14 url = properties.getProperty("url");15 user = properties.getProperty("user");16 password = properties.getProperty("password");17 driver = properties.getProperty("driver");18
19 // 3. 注册驱动20 Class.forName(driver);21
22 } catch (Exception e) {23 e.printStackTrace();24 }25 }26
27 /**28 * 获取连接29 *30 * @return31 * @throws SQLException32 */33 public static Connection getConnection() throws SQLException {34 return DriverManager.getConnection(url, user, password);35 }36
37 /**38 * 释放资源39 *40 * @param resultSet41 * @param statement42 * @param connection43 */44 public static void close(ResultSet resultSet, Statement statement, Connection connection) {45 doClose(resultSet);46 doClose(statement);47 doClose(connection);48 }49
50 private static void doClose(AutoCloseable autoCloseable) {51 if (autoCloseable != null) {52 try {53 autoCloseable.close();54 } catch (Exception exception) {55 exception.printStackTrace();56 }57 }58 }59}60
第二节 相关接口详解
1. DriverManager
DriverManager为JDBC客户端管理一组可用的驱动(Driver)实现,主要功能有两个:
101// 1. 注册驱动2public static synchronized void registerDriver(java.sql.Driver driver) throws SQLException3public static synchronized void registerDriver(java.sql.Driver driver, DriverAction da) throws SQLException4public static Driver getDriver(String url) throws SQLException5public static java.util.Enumeration<Driver> getDrivers()6
7// 2. 获取连接8public static Connection getConnection(String url) throws SQLException // 无需用户名时使用9public static Connection getConnection(String url, java.util.Properties info) // 需提供其它连接参数时使用10public static Connection getConnection(String url, String user, String password) throws SQLException
2. DataSource
DataSource是另一种获取连接的方式,主要如下三类:
普通数据源(DataSource ):
41Connection getConnection() throws SQLException2Connection getConnection(String username, String password)3boolean isWrapperFor(java.lang.Class<?> iface) throws java.sql.SQLException; // 是否为某类的包装类4<T> T unwrap(java.lang.Class<T> iface) throws java.sql.SQLException; // 拆包连接池数据源(ConnectionPoolDataSource):
21PooledConnection getPooledConnection() throws SQLException;2PooledConnection getPooledConnection(String user, String password) throws SQLException;分布式数据源(XADataSource):
21XAConnection getXAConnection() throws SQLException;2XAConnection getXAConnection(String user, String password) throws SQLException;注意:
DataSource相关接口并未定义close()方法,但具体连接池一般会扩展类似接口。
3. Connection
Connection表示通过JDBC驱动与数据源建立的连接,数据源可以是关系型数据库、文件系统或者其他通过JDBC驱动访问的数据。
401// 1. 创建Statement2Statement createStatement() throws SQLException3Statement createStatement(int resultSetType, int resultSetConcurrency) throws SQLException;4Statement createStatement(int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException;5
6PreparedStatement prepareStatement(String sql) throws SQLException;7PreparedStatement prepareStatement(String sql, int autoGeneratedKeys) throws SQLException; // autoGeneratedKeys-是否回写自动生成的列值,Statement.RETURN_GENERATED_KEYS表示回写8PreparedStatement prepareStatement(String sql, int columnIndexes[]) throws SQLException; // 回写哪些自动生成的列值9PreparedStatement prepareStatement(String sql, String columnNames[]) throws SQLException; // 回写哪些自动生成的列值10PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency) throws SQLException;11PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException;12
13CallableStatement prepareCall(String sql) throws SQLException;14CallableStatement prepareCall(String sql, int resultSetType, int resultSetConcurrency) throws SQLException;15CallableStatement prepareCall(String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException;16
17
18// 2. 管理事务19void commit() throws SQLException;20void rollback() throws SQLException;21void rollback(Savepoint savepoint) throws SQLException; // 回滚到指定保存点22
23boolean getAutoCommit() throws SQLException;24void setAutoCommit(boolean autoCommit) throws SQLException; // 设置是否自动提交,默认为true25
26Savepoint setSavepoint() throws SQLException;27Savepoint setSavepoint(String name) throws SQLException;28void releaseSavepoint(Savepoint savepoint) throws SQLException;29
30
31// 3. 管理连接状态32void setReadOnly(boolean readOnly) throws SQLException; // 设置连接只读33boolean isReadOnly() throws SQLException; // 判断连接是否只读34boolean isClosed() throws SQLException; // 判断连接是否被关闭35boolean isValid(int timeout) throws SQLException; // 判断连接是否有效36
37
38// 4. 获取其它信息39DatabaseMetaData getMetaData() throws SQLException; // 获取数据库元信息40
4. Statement
Statement接口中定义了直接执行SQL语句的方法,其子类PreparedStatement扩展了设置SQL参数的方法,其孙类CallableStatement 又扩展了调用存储过程/函数的相关方法。
531// 1. 执行DQL语句2ResultSet executeQuery(String sql) throws SQLException; // 如果是预编译形式,则无sql参数,下同3
4// 2. 执行DML/DDL语句5// 默认返回匹配的行数,在mysql中,可通过useAffectedRows=true连接参数修改为受影响的行数6int executeUpdate(String sql) throws SQLException; 7int executeUpdate(String sql, int autoGeneratedKeys) throws SQLException;8int executeUpdate(String sql, int columnIndexes[]) throws SQLException;9int executeUpdate(String sql, String columnNames[]) throws SQLException;10
11// 3. 执行未知SQL语句12// 返回值为true表示为ResultSet结果集,可以通过getResultSet()获取,否则可以尝试通过getUpdateCount()获取更新计数13boolean execute(String sql) throws SQLException; 14boolean execute(String sql, int autoGeneratedKeys) throws SQLException; 15boolean execute(String sql, int columnIndexes[]) throws SQLException;16boolean execute(String sql, String columnNames[]) throws SQLException; 17
18// 4. 批量执行SQL19void addBatch( String sql ) throws SQLException; // 添加SQL到缓冲区20void clearBatch() throws SQLException; // 清空缓冲区21int[] executeBatch() throws SQLException; // 批量执行22
23// 5. 结果处理24ResultSet getResultSet() throws SQLException; // 获取查询语句的结果集25int getUpdateCount() throws SQLException; // 获取更新语句的更新计数(注意:DDL语句该值始终为0)26ResultSet getGeneratedKeys() throws SQLException; // 获取数据库自动生成的值27SQLWarning getWarnings() throws SQLException; // 获取SQL警告28boolean getMoreResults() throws SQLException; // 多结果集支持29
30// 6. 相关参数设置31void setFetchSize(int rows) throws SQLException; // 每次提取的行数,可用于进行流式查询32int getFetchSize() throws SQLException;33void setQueryTimeout(int seconds) throws SQLException; // Statement级别的查询超时时间34int getQueryTimeout() throws SQLException;35
36// 7. 关闭Statement37boolean isClosed() throws SQLException;38void close() throws SQLException;39
40// 8. PreparedStatement设置参数41void setInt(int parameterIndex, int x) throws SQLException;42void setString(int parameterIndex, String x) throws SQLException;43void setObject(int parameterIndex, Object x) throws SQLException;44void setObject(int parameterIndex, Object x, int targetSqlType, int scaleOrLength) throws SQLException;45void setDate(int parameterIndex, java.sql.Date x) throws SQLException;46void setTimestamp(int parameterIndex, java.sql.Timestamp x) throws SQLException;47void setNull(int parameterIndex, int sqlType) throws SQLException; // 将占位符参数设置为 JDBC 的NULL48void setNull (int parameterIndex, int sqlType, String typeName) throws SQLException;49
50// 9. CallableStatement注册输出参数51void registerOutParameter(int parameterIndex, int sqlType) throws SQLException;52default void registerOutParameter(int parameterIndex, SQLType sqlType) throws SQLException53
5. ResultSet
ResultSet提供了检索和操作SQL执行结果相关的方法,有3种不同的类型:
TYPE FORWARD_ONLY:默认类型,仅支持向前滚动。TYPE_SCROLL_INSENSITIVE:可任意滚动,即可相对于当前位置向前或向后移动,也可以移动到绝对位置。TYPE SCROLL SENSITIVE:可任意滚动,并且当ResultSet 没有关闭时,对ResultSet对象的修改会直接影响数据库中的记录。
181// 1. 游标滚动2boolean next() throws SQLException; // 游标向前移动一行,如果游标定位到下一行,则返回true;如果游标位于最后一行之后,则返回false3boolean absolute( int row ) throws SQLException; // 游标定位到ResultSet对象中的第row行,允许负数表示倒数。4
5// 2. 根据索引获取当前行列值,索引从1开始6int getInt(int columnIndex) throws SQLException;7String getString(int columnIndex) throws SQLException;8java.sql.Date getDate(int columnIndex) throws SQLException;9java.sql.Timestamp getTimestamp(int columnIndex) throws SQLException;10Object getObject(int columnIndex) throws SQLException;11
12// 3. 根据查询列名获取当前列值13int getInt(String columnLabel) throws SQLException;14String getString(String columnLabel) throws SQLException;15java.sql.Date getDate(String columnLabel) throws SQLException;16java.sql.Timestamp getTimestamp(String columnLabel) throws SQLException; 17Object getObject(String columnLabel) throws SQLException;18
6. DatabaseMetaData
DatabaseMetaData接口用于获取数据源的相关元信息。
311// 1. 获取数据源基本信息2String getURL() throws SQLException; // 获取连接URL3String getUserName() throws SQLException; // 获取数据库已知的用户4String getDatabaseProductName() throws SQLException;// 获取数据库厂商名5String getDatabaseProductVersion() throws SQLException; // 获取数据库产品的版本6int getDriverMajorVersion(); // 获取驱动主版本7int getDriverMinorVersion(); // 获取驱动副版本8String getSQLKeywords() throws SQLException; // 获取数据库SQL关键字9
10// 2. 获取数据源支持项和限制项11int getMaxConnections() throws SQLException; // 获取此数据库支持的最大连接数12int getMaxStatementLength() throws SQLException; // 获取此数据库在SQL语句中允许的最大字符数13int getMaxTablesInSelect() throws SQLException; // 获取此数据库在SELECT语句中允许的最大表数14
15// 3. 获取事务支持16boolean supportsTransactions() throws SQLException; // 是否支持事务17boolean supportsMultipleTransactions() throws SQLException; // 是否支持同时开启多个事务18boolean supportsTransactionIsolationLevel(int level) throws SQLException; // 是否支持某一事务隔离级别19int getDefaultTransactionIsolation() throws SQLException; // 获取默认的事务隔离级别20
21
22// 4. 获取SQL对象及属性23ResultSet getSchemas() throws SQLException; // 获取Schema信息24ResultSet getTables(String catalog, String schemaPattern, String tableNamePattern, String types[]) throws SQLException; // 获取表信息25ResultSet getPrimaryKeys(String catalog, String schema, String table) throws SQLException; // 获取主键信息26ResultSet getProcedures(String catalog, String schemaPattern, String procedureNamePattern) throws SQLException; // 获取存储过程信息27ResultSet getProcedureColumns(String catalog, String schemaPattern, String procedureNamePattern, String columnNamePattern) throws SQLException; // 获取给定类别的存储过程参数和结果列的信息28ResultSet getFunctions(String catalog, String schemaPattern, String functionNamePattern) throws SQLException; // 获取函数信息。29ResultSet getFunctionColumns(String catalog, String schemaPattern, String functionNamePattern, String columnNamePattern) throws SQLException; // 获取给定类别的函数参数和结果列的信息。30ResultSet getUDTs(String catalog, String schemaPattern, String typeNamePattern, int[] types) throws SQLException; // 获取用户自定义数据类型31
7. ResultSetMetaData
ResultSetMetaData用于获取结果集的相关元信息。
61int getColumnCount() throws SQLException; // 结果集列数2String getColumnLabel(int column) throws SQLException; // 查询列名(as后的部分)3String getColumnName(int column) throws SQLException; // 列名所对应的表列名4String getTableName(int column) // 列所定义的表名5int getColumnType(int column) throws SQLException; // 列类型(java.sql.Type)6
第三节 数据库连接池
数据库连接池是一个存储数据库连接的资源池,使用它可以更高效的使用数据库连接。
1. C3P0连接池
C3P0是一个开源的数据库连接池,使用方式如下:
首先需要导入相关依赖:
101<dependency>2<groupId>c3p0</groupId>3<artifactId>c3p0</artifactId>4<version>0.9.1.2</version>5</dependency>6<dependency>7<groupId>com.mchange</groupId>8<artifactId>mchange-commons-java</artifactId>9<version>0.2.15</version>10</dependency>然后在src目录下配置
c3p0.properties或c3p0-config.xml文件:221<c3p0-config>2<!-- 命名的配置 -->3<named-config name="test">4<!-- 连接数据库的4项基本参数 -->5<property name="driverClass">com.mysql.jdbc.Driver</property>6<property name="jdbcUrl">jdbc:mysql://localhost:3306/mytest01</property>7<property name="user">root</property>8<property name="password">123</property>9<!-- 如果池中数据连接不够时一次增长多少个 -->10<property name="acquireIncrement">5</property>11<!-- 初始化连接数 -->12<property name="initialPoolSize">5</property>13<!-- 最小连接数 -->14<property name="minPoolSize">10</property>15<!-- 最大连接数 -->16<property name="maxPoolSize">40</property>17<!-- JDBC的标准参数,用以控制数据源内加载的PrepareStatements数量 -->18<property name="maxStatements">200</property>19<!-- 连接池内单个连接所拥有的最大缓存statements数 -->20<property name="maxStatementsPerConnection">5</property>21</named-config>22</c3p0-config>最后就可以在代码中通过如下一些方法使用连接池了:
91// 1. 创建连接池2DataSource ds = new ComboPooledDataSource(); // 使用默认配置3DataSource ds = new ComboPooledDataSource("otherc3p0"); // 使用指定名称的配置45// 2. 获取连接6Connection conn = ds.getConnection();78// 3. 释放连接9conn.close(); // 归还连接到连接池中
2. Druid连接池
Druid是阿里巴巴开源的一个数据库连接池实现,不仅效率高,而且可以很好的监控DB池连接和SQL的执行情况,使用方式如下:
首先导入相关依赖:
51<dependency>2<groupId>com.alibaba</groupId>3<artifactId>druid</artifactId>4<version>1.2.8</version>5</dependency>然后在类路径下定义配置文件druid.properties如下:
91driverClassName=com.mysql.cj.jdbc.Driver2url=jdbc:mysql://106.53.120.230:3306/test01?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone =Asia/Shanghai3username=root4password=Hyx14774156initialSize=107maxActive=1008maxWait=30009
下面是一个基于Duird连接池的JDBC工具类:
601public class DruidJdbcUtils {2 private static DataSource dataSource;3
4 static {5 try {6 // 1. 加载配置文件7 Properties properties = new Properties();8 properties.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));9
10 // 2. 获取DataSource11 dataSource = DruidDataSourceFactory.createDataSource(properties);12
13 } catch (IOException e) {14 e.printStackTrace();15 } catch (Exception e) {16 e.printStackTrace();17 }18 }19
20 public static void main(String[] args) throws SQLException {21 Connection connection = DruidJdbcUtils.getConnection();22 Statement statement = connection.createStatement();23 ResultSet resultSet = statement.executeQuery("select 1");24 resultSet.next();25 System.out.println(resultSet.getInt(1));26 }27
28 /**29 * 获取连接池30 */31 public static DataSource getDataSource() {32 return dataSource;33 }34
35 /**36 * 获取连接37 */38 public static Connection getConnection() throws SQLException {39 return dataSource.getConnection();40 }41
42 /**43 * 释放连接44 */45 public static void close(ResultSet resultSet, Statement statement, Connection connection) {46 doClose(resultSet);47 doClose(statement);48 doClose(connection);49 }50
51 private static void doClose(AutoCloseable autoCloseable) {52 if (autoCloseable != null) {53 try {54 autoCloseable.close();55 } catch (Exception exception) {56 exception.printStackTrace();57 }58 }59 }60}
第02章_网络编程(TCP&UDP)
第一节 网络基础知识
1. 网络通信三要素
网络程序之间通信必须明确三要素:通信协议、IP地址、端口号。
通信协议:对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交换。
IP地址:表示网络设备的唯一编号,主要有IPv4和IPv6两种协议。
端口号:标识网络设备中的进程,取值范围为0~65535。
上述“通信协议+IP地址+端口号”的组合,唯一标识了网络中的某个进程以及与其的通信方式,基于此就可以实现进程间网络通信了。
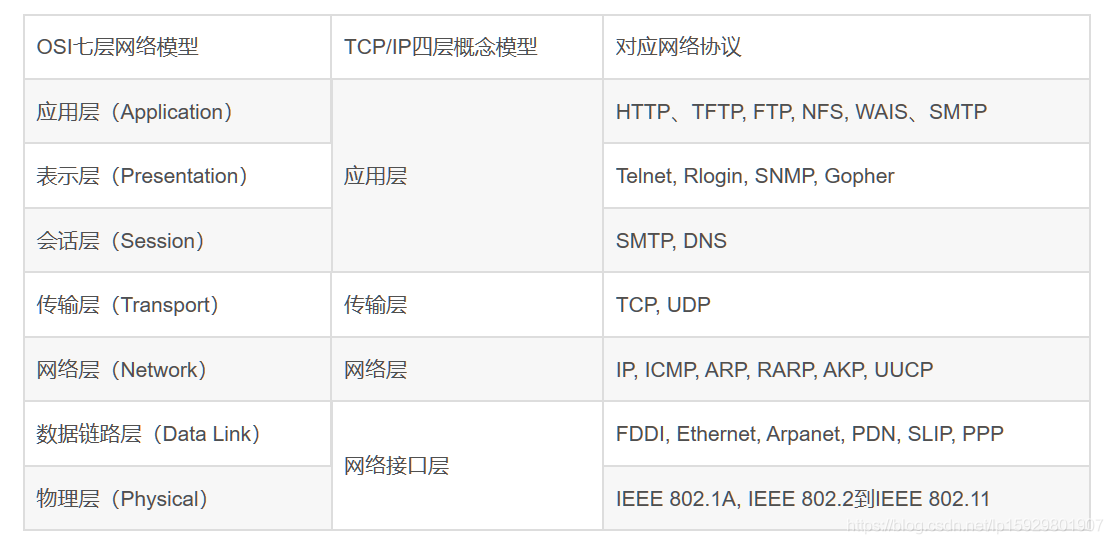
2. 网络分层
网络根据不同的规范可分为OSI七层模型或TCP/IP四层模型:
3. TCP协议
TCP全名为传输控制协议 (Transmission Control Protocol),是一种面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。
TCP连接中必须要明确客户端与服务器端,由客户端向服务端发出连接请求,每次连接的创建都需要经过三次握手,以保证连接的可靠:
第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
第三次握手,客户端再次向服务器端发送确认信息,确认连接。
4. UDP协议
UDP全称为用户数据报协议(User Datagram Protocol)。它是面向无连接的通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输。但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议。
5. HTTP协议
HTTP全名为超文本传输协议(HyperText Transfer Protocol),是一种用于分布式、协作式和超媒体信息系统的应用层协议。
请求头示例
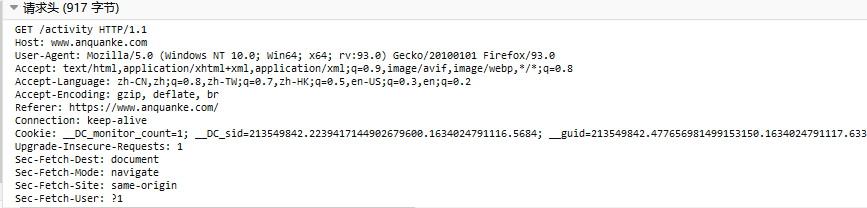
响应头示例

第二节 简单的TCP程序
1. Socket简介
Socket简称套接字,是进程间通信的一种方式,在TCP程序中分为客户端Socket和服务端Socket:
客户端Socket:主要用来创建客户端套接字对象,实现与服务端的通信,用
java.net.Socket类表示。121// 1. 创建客户端Socket,并尝试与指定IP+端口建立TCP连接2public Socket(String host, int port) // host可为null,表示本地回环地址,不进行网络传输34// 2. Socket通信5public InputStream getInputStream() // 返回此套接字的输入流6public OutputStream getOutputStream() // 返回此套接字的输出流78// 3. 关闭客户端Socket9public void close() // Socket被关闭后不可再使用,并且也将关闭相关的InputStream和OutputStream1011// 4. 禁用Socket的输出流(写结束标记)12public void shutdownOutput() // 之后,任何先前写出的数据将被发送,随后终止输出流服务端Socket:相当于一个网络服务,阻塞等待客户端的连接,用
java.net.ServerSocket类表示。51// 1. 创建服务端Socket2public ServerSocket(int port) // port-监听端口34// 2. 阻塞等待客户端Socket发起连接5public Socket accept() // 每次连接成功后返回一个新的Socket对象,用于和客户端实现通信
注意:
客户端Socket返回的输入流、输出流与Socket所关联的通道为同一个,关闭任何一个,其它对象所关联的通道也将关闭。
2. 一个简单的TCP程序示例
581// 服务端2public class ServerTCP {3 public static void main(String[] args) throws IOException {4 // 1.创建服务端Socket,监听指定端口,开始等待连接5 ServerSocket ss = new ServerSocket(6666);6 System.out.println("服务端启动, 等待连接 .... ");7
8 // 2.接收客户端连接, 返回一个用于与客户端通信的Socket对象9 Socket server = ss.accept();10
11 // 3.通过该Socket获取输入流12 InputStream is = server.getInputStream();13
14 // 4.一次性读取数据15 byte[] b = new byte[1024];16 int len = is.read(b);17 String msg = new String(b, 0, len);18 System.out.println("client: " + msg);19
20 // 5. 通过Socket获取输出流21 OutputStream out = server.getOutputStream();22
23 // 6. 回写数据24 out.write("hello, client001".getBytes());25
26 // 7.关闭资源27 out.close();28 is.close();29 server.close();30 }31}32
33// 客户端34public class ClientTCP {35 public static void main(String[] args) throws Exception {36 // 1.创建客户端Socket,连接到指定IP+端口37 Socket client = new Socket("localhost", 6666);38
39 // 2.通过Scoket获取输出流对象40 OutputStream os = client.getOutputStream();41
42 // 3.写数据43 os.write("hello, tcp server".getBytes());44
45 // 4. 通过Scoket获取输入流对象46 InputStream in = client.getInputStream();47
48 // 5. 读取响应数据49 byte[] b = new byte[100];50 int len = in.read(b);51 System.out.println("server: " + new String(b, 0, len));52
53 // 6. 关闭资源54 in.close();55 os.close();56 client.close();57 }58}
3. 文件上传案例(C/S)
921// 图片上传服务端2public class FileUpload_Server implements Closeable {3 public static ExecutorService executorService = Executors.newFixedThreadPool(10);4 public static final String FILE_SUFFIX = ".png";5
6 public static void main(String[] args) throws IOException {7 // 1. 创建服务端Socket8 ServerSocket serverSocket = new ServerSocket(6666);9 System.out.println("文件上传服务器启动..... ");10
11 // 2. 循环接收,建立连接12 while (true) {13 Socket accept = serverSocket.accept();14 String fileName = (System.currentTimeMillis() + FILE_SUFFIX);15
16 // 3. Socket对象交给子线程处理,进行读写操作17 executorService.submit(() -> {18 try {19 // 3.1 获取网络输入流对象20 BufferedInputStream bis = new BufferedInputStream(accept.getInputStream());21
22 // 3.2 创建文件输出流对象, 保存文件到本地23 BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(fileName));24
25 // 3.3 读写数据26 byte[] b = new byte[1024 * 800];27 int len;28 while ((len = bis.read(b)) != -1) {29 bos.write(b, 0, len);30 }31
32 // 4. 获取网络输出流,进行信息回写33 OutputStream out = accept.getOutputStream();34 out.write(("文件[" + fileName + "]上传成功").getBytes());35 out.close();36
37 //5. 关闭资源38 bos.close();39 bis.close();40 accept.close();41 System.out.println("文件[" + fileName + "]上传成功");42 } catch (IOException ioException) {43 ioException.printStackTrace();44 }45 });46 }47 }48
49 50 public void close() throws IOException {51 executorService.shutdown();52 }53}54
55// 图片上传客户端56public class FileUpload_Client {57 public static void main(String[] args) throws IOException {58 String fileName = "C:\\Users\\Administrator\\Desktop\\test.png";59
60 // 1. 创建文件输入流,读取本地文件61 BufferedInputStream bis = new BufferedInputStream(new FileInputStream(fileName));62
63 // 2. 创建客户端Socket,连接到服务端64 Socket socket = new Socket("localhost", 6666);65
66 // 3. 获取网络输出流,写到服务端67 BufferedOutputStream bos = new BufferedOutputStream(socket.getOutputStream());68
69 // 4. 写数据70 byte[] b = new byte[1024 * 800];71 int len;72 while ((len = bis.read(b)) != -1) {73 bos.write(b, 0, len);74 }75 bos.flush(); // 注意:最后必须刷新缓冲区76
77 // 5. 关闭输出流,通知服务端,写出数据完毕78 socket.shutdownOutput();79 System.out.println("文件[" + fileName + "]发送完毕");80
81 // 6. 获取网络输入流,读取响应82 InputStream in = socket.getInputStream();83 byte[] back = new byte[1024];84 int read = in.read(back);85 System.out.println("server: " + new String(back, 0, read));86
87 // 7. 关闭资源88 in.close();89 socket.close();90 bis.close();91 }92}
4. web服务器案例(B/S)
简单的Web服务器程序,在浏览器输入http://127.0.0.1:8888/abc.html就可以访问服务器中WEB_ROOT目录下的abc.html及关联文件了。
661public class MyWebServer {2 public static final String WEB_ROOT = "C:\\Users\\Administrator\\Desktop\\webs\\";3
4 public static void main(String[] args) throws IOException {5 // 1. 创建服务端Socket6 ServerSocket server = new ServerSocket(8888);7 System.out.println("web服务器已启动...");8
9 // 2. 循环处理请求10 while (true) {11 Socket socket = server.accept();12 new Thread(new WebAcceptHandler(socket)).start();13 }14 }15
16 // 处理请求17 static class WebAcceptHandler implements Runnable {18 private Socket socket;19
20 public WebAcceptHandler(Socket socket) {21 this.socket = socket;22 }23
24 25 public void run() {26 try {27 // 1. 获取网络输入流28 BufferedReader readWb = new BufferedReader(new InputStreamReader(socket.getInputStream()));29
30 // 2. 获取HTTP请求行31 String requst = readWb.readLine(); // GET /abc.html HTTP/1.132
33 // 3. 取出请求资源的路径34 String[] strArr = requst.split(" ");35 String path = strArr[1].substring(1); // abc.html36 System.out.println("请求: " + path);37
38 // 4. 打开文件输入流,准备读服务器文件39 FileInputStream fis = new FileInputStream(WEB_ROOT + path);40 byte[] bytes = new byte[1024];41 int len = 0;42
43 // 5. 获取网络输出流44 OutputStream out = socket.getOutputStream();45
46 // 6. 向浏览器回写数据47 out.write("HTTP/1.1 200 OK\r\n".getBytes()); // HTTP响应行48 out.write("Content-Type:text/html\r\n".getBytes()); // HTTP响应头49 out.write("\r\n".getBytes()); // HTTP响应空行50 while ((len = fis.read(bytes)) != -1) { // HTTP响应体51 out.write(bytes, 0, len);52 }53 System.out.println("响应完毕...");54
55 // 7. 释放资源56 fis.close();57 out.close();58 readWb.close();59 socket.close();60 } catch (Exception ex) {61 ex.printStackTrace();62 // todo 这里应该响应失败63 }64 }65 }66}
第三节 简单的UDP程序
1. DatagramSocket简介
在UDP通信中,分为数据发送者和接收者,两者都是通过DatagramSocket来发送和接收数据,使用DatagramPacket进行数据打包。
111// 1. DatagramSocket2public DatagramSocket(int port) // 发送者使用,可指定发送端口;接收者使用,从指定端口接收数据3public void send(DatagramPacket p) throws IOException // 发送数据4public synchronized void receive(DatagramPacket p) throws IOException // 等待接收数据5 6// 2. DatagramPacket7public DatagramPacket(byte buf[], int offset, int length) // 用于待接收数据打包,临时存放接收的数据8public DatagramPacket(byte buf[], int offset, int length, InetAddress address, int port) // 待发送数据包,可指定目标IP+端口9public synchronized byte[] getData() // 返回接收的数据10public synchronized int getLength() // 返回要发送或接收数据的长度11
2. 简单UDP发送/接收程序
401// 发送者2public class UDPSender {3 public static void main(String[] args) throws IOException {4 // 1. 创建DatagramSocket,从9000端口发送5 DatagramSocket server = new DatagramSocket(9000);6
7 // 2. 组建数据包8 String text = "hello, udp";9 DatagramPacket packet = new DatagramPacket(text.getBytes(), 0, text.length(), InetAddress.getByName("localhost"), 9999);10
11 // 3. 发送数据包12 server.send(packet);13 System.out.println("数据发送成功...");14
15 // 4. 关闭DatagramSocket16 server.close();17 }18}19
20// 接收者21public class UDPReceiver {22 public static void main(String[] args) throws Exception {23 // 1. 创建DatagramSocket,监听9999端口24 DatagramSocket client = new DatagramSocket(9999);25 System.out.println("监听[9999]端口中...");26
27 // 2. 组建DatagramPacket,用于临时保存接收到的数据28 byte data[] = new byte[1024];29 DatagramPacket packet = new DatagramPacket(data, data.length);30
31 // 3. 等待接收数据32 System.out.println("开始接收数据...");33 client.receive(packet);34 System.out.println("接收到的消息内容为:" + new String(data, 0, packet.getLength()));35
36 // 4. 关闭DatagramSocket37 client.close();38 }39}40
第03章_Web编程(JavaWeb)
第一节 快速入门
1. JavaWeb简介
Java Web是指使用Java语言进行Web开发的技术体系。
2. 入门案例
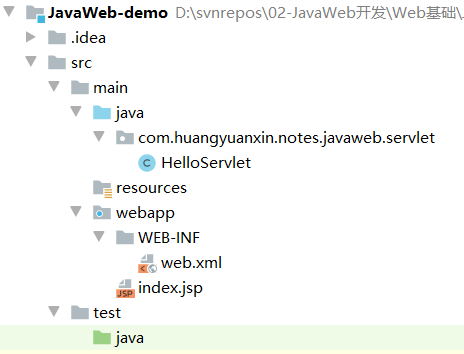
2.1 初始工程建立
新建Maven工程(File->New->Project->Maven->Next->Finish),并补全和标识必要目录。
2.2 引入相关依赖
641 2<project xmlns="http://maven.apache.org/POM/4.0.0"3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">5 <modelVersion>4.0.0</modelVersion>6
7 <groupId>com.huangyuanxin.notes</groupId>8 <artifactId>JavaWeb-demo</artifactId>9 <version>1.0-SNAPSHOT</version>10
11 <properties>12 <maven.compiler.source>1.8</maven.compiler.source>13 <maven.compiler.target>1.8</maven.compiler.target>14 </properties>15
16 <!--打包方式为War包-->17 <packaging>war</packaging>18
19 <dependencies>20 <dependency>21 <groupId>javax.servlet</groupId>22 <artifactId>javax.servlet-api</artifactId>23 <version>3.1.0</version>24 </dependency>25
26 <dependency>27 <groupId>javax.servlet.jsp</groupId>28 <artifactId>jsp-api</artifactId>29 <version>2.1</version>30 </dependency>31
32 <dependency>33 <groupId>javax.servlet</groupId>34 <artifactId>jstl</artifactId>35 <version>1.2</version>36 </dependency>37
38 <dependency>39 <groupId>mysql</groupId>40 <artifactId>mysql-connector-java</artifactId>41 <version>8.0.18</version>42 </dependency>43
44 <dependency>45 <groupId>junit</groupId>46 <artifactId>junit</artifactId>47 <version>4.13.2</version>48 <scope>test</scope>49 </dependency>50
51 <dependency>52 <groupId>com.alibaba</groupId>53 <artifactId>fastjson</artifactId>54 <version>1.2.75</version>55 </dependency>56
57 <dependency>58 <groupId>org.projectlombok</groupId>59 <artifactId>lombok</artifactId>60 <version>1.18.22</version>61 </dependency>62 </dependencies>63
64</project>
2.3 创建src/main/webapp/WEB-INF/web.xml文件
251<web-app2 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"3 xmlns="http://xmlns.jcp.org/xml/ns/javaee"4 xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee5 http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"6 id="WebApp_ID" version="4.0">7
8 <welcome-file-list>9 <welcome-file>index.jsp</welcome-file>10 </welcome-file-list>11
12 <servlet>13 <servlet-name>helloServlet</servlet-name>14 <servlet-class>com.huangyuanxin.notes.javaweb.servlet.HelloServlet</servlet-class>15 16 <!-- Servlet创建时机:>=0表示在服务器启动时 <0表示在第一次访问时-->17 <load-on-startup>0</load-on-startup>18 </servlet>19
20 <servlet-mapping>21 <servlet-name>helloServlet</servlet-name>22 <url-pattern>/hello</url-pattern>23 </servlet-mapping>24
25</web-app>
2.4 创建src\main\webapp\index.jsp文件
91<% page contentType="text/html;charset=UTF-8" language="java" %>2<html>3<head>4 <title>Title</title>5</head>6<body>7 Hello, Jsp!8</body>9</html>
2.5 编写HelloServlet
321package com.huangyuanxin.notes.javaweb.servlet;2
3import javax.servlet.*;4import java.io.IOException;5
6public class HelloServlet implements Servlet {7 8 public void init(ServletConfig config) throws ServletException {9
10 }11
12 13 public ServletConfig getServletConfig() {14 return null;15 }16
17 18 public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {19 System.out.println("请求地址: " + req.getRemoteAddr());20 res.getWriter().write("Hello, Servlet!");21 }22
23 24 public String getServletInfo() {25 return null;26 }27
28 29 public void destroy() {30
31 }32}
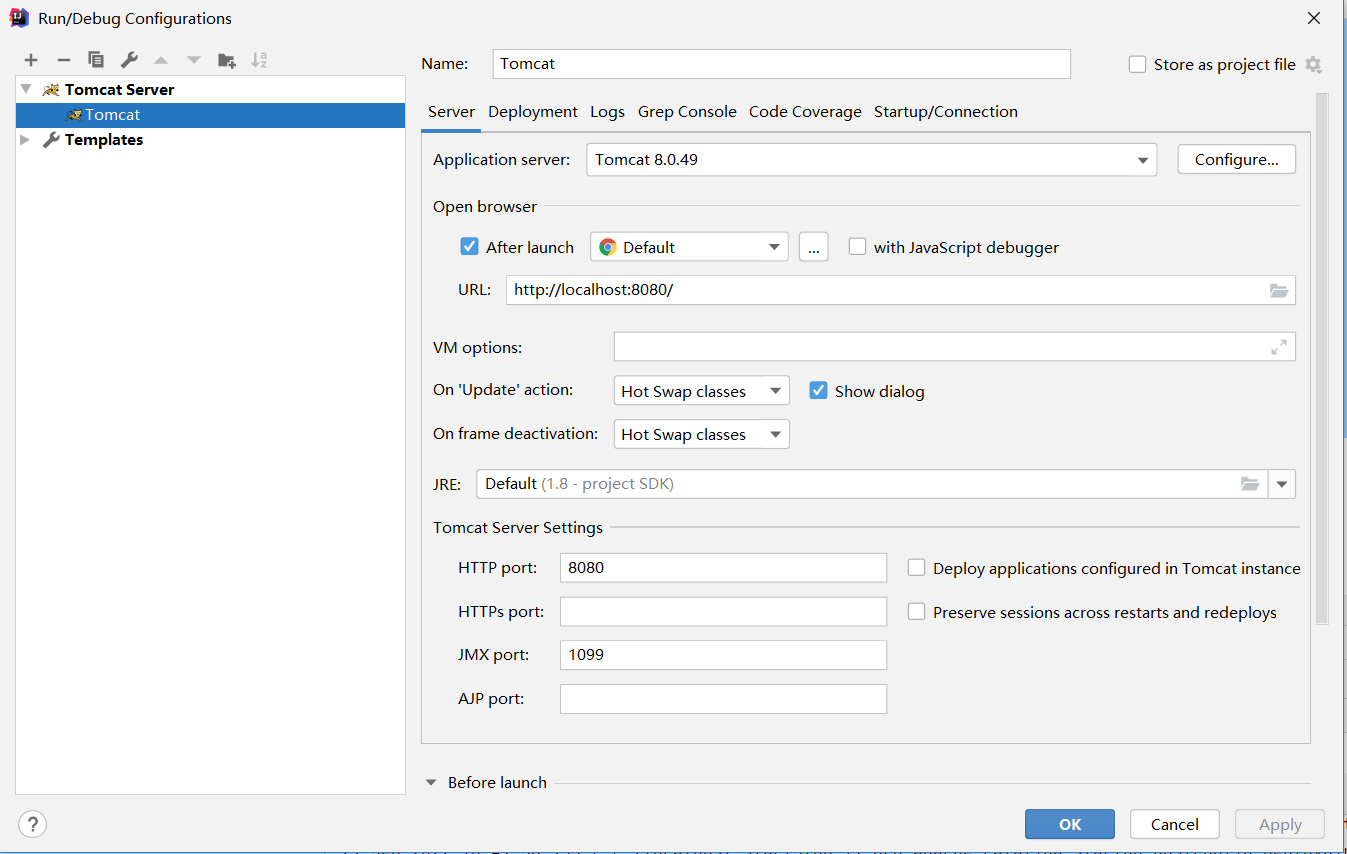
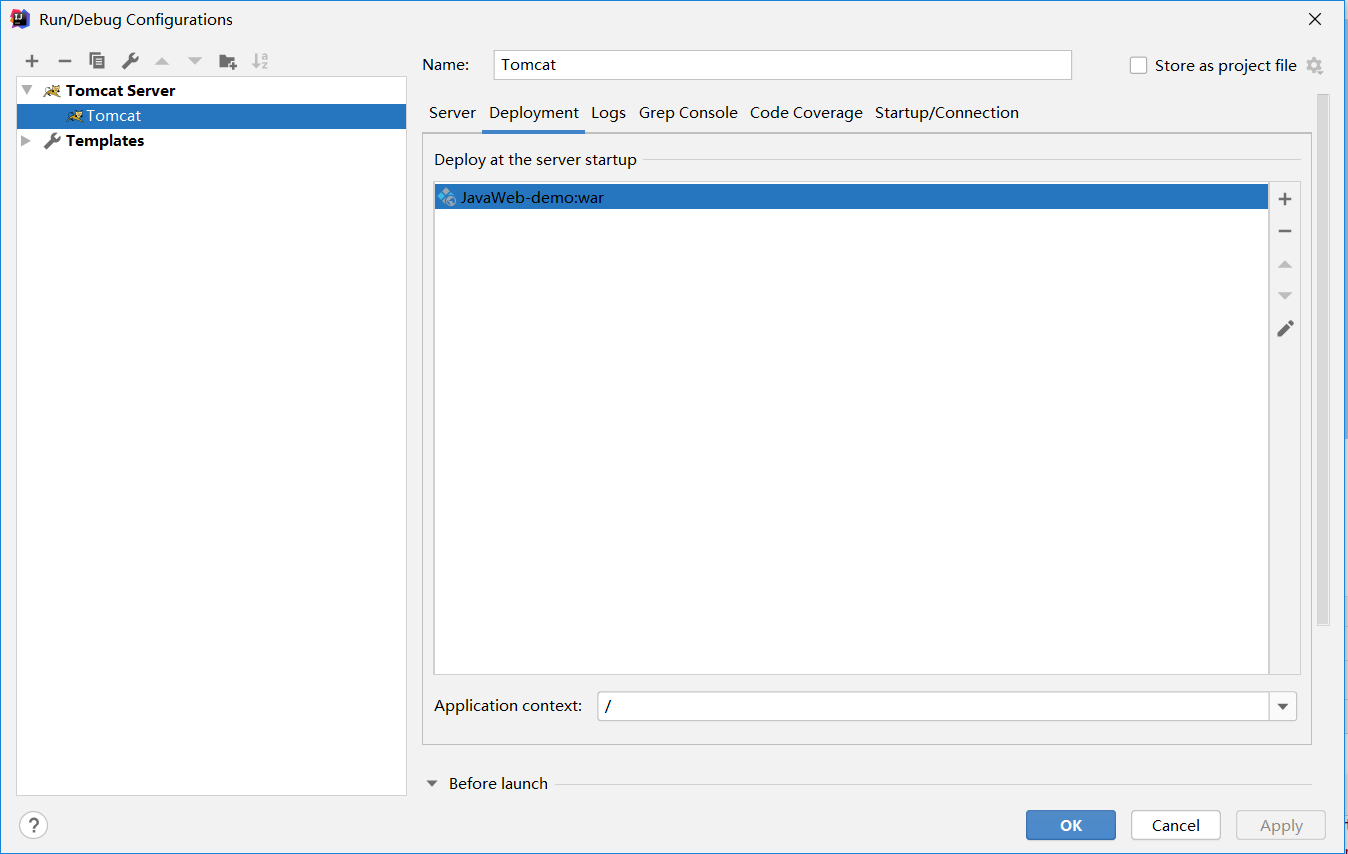
2.6 配置Tomcat Server
新建Tomcat Server(工具栏 -> Add Configurations -> + -> Tomcat Server -> Local),进行如下一些配置,然后启动进行测试。
配置Name
配置Server页面:Application server、On 'update' action、HTTP port等
配置Deployment页面:+ -> Artifact... -> JavaWeb-demo:war、Application Context等
第二节 Servlet
1. 什么是Servlet?
Servlet(server applet)指运行在服务器端的小程序,用来处理服务器收到的请求。
2. 基本使用
入门案例已介绍了如何使用XML配置Servlet,下面案例通过注解配置Servlet。
521package com.huangyuanxin.notes.javaweb.servlet;2
3import javax.servlet.*;4import javax.servlet.annotation.WebServlet;5import java.io.IOException;6
7("/hello2")8public class HelloAnnotationServlet implements Servlet {9 /**10 * 在Servlet对象被创建时执行一次。(Servlet是单例的!)11 *12 * @param config13 * @throws ServletException14 */15 16 public void init(ServletConfig config) throws ServletException {17 System.out.println("初始化...");18 }19
20 21 public ServletConfig getServletConfig() {22 return null;23 }24
25 /**26 * 在每次被访问时都会执行一次27 *28 * @param req29 * @param res30 * @throws ServletException31 * @throws IOException32 */33 34 public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {35 System.out.println("请求地址: " + req.getRemoteAddr());36 res.getWriter().write("Hello, Servlet!");37 }38
39 40 public String getServletInfo() {41 return null;42 }43
44 /**45 * 在Servlet对象被销毁前(服务器被正常关闭时)执行一次46 */47 48 public void destroy() {49 System.out.println("释放资源...");50 }51}52
3. HttpServlet
HttpServlet继承自Servlet,并根据HTTP请求方式将service()方法进行了分发。
231package com.huangyuanxin.notes.javaweb.servlet;2
3import javax.servlet.ServletException;4import javax.servlet.annotation.WebServlet;5import javax.servlet.http.HttpServlet;6import javax.servlet.http.HttpServletRequest;7import javax.servlet.http.HttpServletResponse;8import java.io.IOException;9
10("/hello3")11public class HelloHttpServlet extends HttpServlet {12 13 protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {14 System.out.println("请求地址: " + req.getRemoteAddr());15 resp.getWriter().write("Hello, Servlet!");16 }17
18 19 protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {20 super.doPost(req, resp);21 }22}23
第二节 ServletRequest
1. 什么是ServletRequest?
ServletRequest/HttpServletRequest是一个描述Servlet请求的接口,由应用服务器(Tomcat)创建,封装了请求相关信息。
2. 获取请求信息
241// 获取请求行数据2String request.getMethod() //获取请求方式 ==>GET3String request.getContextPath() //获取虚拟目录==>/day14 4String request.getServletPath() //获取Servlet资源路径==>/demo15String request.getQueryString() //获取get方式请求参数==>name=zhangsan6String request.getRequestURI() //获取请求URI(统一资源标识符)==>/day14/demo1 7StringBuffer request.getRequestURL() //获取请求URL(统一资源定位符) ==> http://localhost/day14/demo18String request.getProtocol() //获取协议及版本==>HTTP/1.19String request.getRemoteAddr() //获取客户机的IP地址10
11// 获取请求头参数12Enumeration<String> request.getHeaderNames() //获取所有的请求头名称13String request.getHeader(String name) //通过请求头的名称获取请求头的值14
15// 获取POST请求体16BufferedReader request.getReader() //获取字符输入流,只能操作字符数据17ServletInputStream request.getInputStream() //获取字节输入流,可以操作所有类型数据18
19// 获取请求参数20String request.getParameter(String name) //根据参数名称获取参数值,适用于如下类型参数:username=zs&password=12321String[] request.getParameterValues(String name) //根据参数名称获取参数值的数组,适用于如下类型参数:hobby=xx&hobby=game22Enumeration<String> request.getParameterNames() //获取所有请求的参数名称23Map<String,String[]> request.getParameterMap() //获取所有参数的map集合24
请求信息乱码问题:
get方式:如果使用tomcat 8+版本,则不会出现乱码。
post方式:在获取参数前,设置request的编码:
request.request.setCharacterEncoding("utf-8");
3. 请求转发
请求转发是一种在服务器内部的资源跳转方式,主要特点如下:
转发地址栏路径不变。
转发只能访问当前服务器下的资源。
转发是一次请求,可以使用request对象来共享数据。
21// 获取请求转发器并进行转发2request.getRequestDispatcher("/target").forward(request, response);
4. 请求域数据共享
在请求转发过程中,可以使用request对象来进行数据共享。Requst域,代表一次请求的范围,一般用于请求转发的多个资源中共享数据。
31request.setAttribute("name", "zhangsan");2request.getAttribute("name");3request.removeAttribute("name");
5. 使用案例
561("/loginServlet")2public class LoginServlet extends HttpServlet {3 4 protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {5 //1.设置编码6 req.setCharacterEncoding("utf-8");7 8 //2.获取请求参数9 String username = req.getParameter("username");10 String password = req.getParameter("password");11 12 //3.封装user对象13 User loginUser = new User();14 loginUser.setUsername(username);15 loginUser.setPassword(password);16
17 //4.调用UserDao的login方法18 UserDao dao = new UserDao();19 User user = dao.login(loginUser);20
21 //5.判断user22 if(user == null){23 //登录失败24 req.getRequestDispatcher("/failServlet").forward(req,resp);25 }else{26 //登录成功, 存储数据27 req.setAttribute("user",user);28 29 //转发30 req.getRequestDispatcher("/successServlet").forward(req,resp);31 }32
33 }34
35 36 protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {37 this.doGet(req,resp);38 }39}40
41("/successServlet")42public class SuccessServlet extends HttpServlet {43 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {44 // 获取request域中共享的user对象45 User user = (User) request.getAttribute("user");46
47 if(user != null){48 //设置编码49 response.setContentType("text/html;charset=utf-8");50 51 //输出52 response.getWriter().write("登录成功!"+user.getUsername()+",欢迎您");53 }54 } 55
56
第三节 ServletResponse
1. 什么是ServletResponse?
ServletResponse/HttpServletResponse是一个描述Servlet响应的接口,由应用服务器(Tomcat)创建,封装了响应相关信息。
2. 设置响应信息
101// 设置响应行2response.setStatus(int sc) //设置状态码3
4// 设置响应头5response.setHeader(String name, String value) //设置响应头,以键值对形式。6
7// 设置响应体8PrintWriter response.getWriter() //字符输出流:9ServletOutputStream response.getOutputStream() //字节输出流10
响应信息乱码问题:
响应时默认流编码为ISO-8859-1,我们需要在获取流之前设置该流的默认编码,即建议浏览器解析响应体使用的编码。
61// 设置编码,在获取流之前设置2response.setContentType("text/html;charset=utf-8");3// 获取流和写响应数据5ServletOutputStream sos = response.getOutputStream();6sos.write("你好".getBytes("utf-8"));
3. 响应重定向
重定向[redirect]是一种跨服务器的资源跳转方式,主要特点如下:
地址栏发生变化。
重定向可以访问其他站点(服务器)的资源。
重定向是两次请求,不能使用request对象来共享数据。
71// 方式一2response.setStatus(302); // 设置状态码为 3023response.setHeader("location","/day15/responseDemo2"); // 设置响应头 location4
5// 方式二6response.sendRedirect("/day15/responseDemo2");7
4. 使用案例
531("/checkCodeServlet")2public class CheckCodeServlet extends HttpServlet {3 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {4 int width = 100;5 int height = 50;6
7 //1.创建一对象,在内存中图片(验证码图片对象)8 BufferedImage image = new BufferedImage(width,height,BufferedImage.TYPE_INT_RGB);9
10 //2.美化图片11 //2.1 填充背景色12 Graphics g = image.getGraphics();//画笔对象13 g.setColor(Color.PINK);//设置画笔颜色14 g.fillRect(0,0,width,height);15
16 //2.2画边框17 g.setColor(Color.BLUE);18 g.drawRect(0,0,width - 1,height - 1);19
20 String str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghigklmnopqrstuvwxyz0123456789";21 //生成随机角标22 Random ran = new Random();23
24 for (int i = 1; i <= 4; i++) {25 int index = ran.nextInt(str.length());26 //获取字符27 char ch = str.charAt(index);//随机字符28 //2.3写验证码29 g.drawString(ch+"",width/5*i,height/2);30 }31
32 //2.4画干扰线33 g.setColor(Color.GREEN);34
35 //随机生成坐标点36 for (int i = 0; i < 10; i++) {37 int x1 = ran.nextInt(width);38 int x2 = ran.nextInt(width);39
40 int y1 = ran.nextInt(height);41 int y2 = ran.nextInt(height);42 g.drawLine(x1,y1,x2,y2);43 }44
45 //3.将图片输出到页面展示46 ImageIO.write(image,"jpg",response.getOutputStream());47 }48
49 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {50 this.doPost(request,response);51 }52}53
第四节 ServletContext
1. 什么是ServletContext?
ServletContext是一个描述Servlet应用上下文的接口,由应用服务器(Tomcat)创建,封装了应用上下文相关信息。
61// 获取方式一:通过request对象获取(在Servlet中)2request.getServletContext();3
4// 获取方式二:通过HttpServlet获取(在Servlet中)5this.getServletContext();6
2. 常用方法简介
161// 获取MIME类型2// MIME类型是在互联网通信过程中定义的一种文件数据类型,格式为大类型/小类型,如text/html、image/jpeg、application/json等3String servletContext.getMimeType(String file)4
5// 做域对象共享数据,作用域为当前Servlet容器6servletContext.setAttribute(String name,Object value)7servletContext.getAttribute(String name)8servletContext.removeAttribute(String name)9
10// 获取文件的真实路径(服务器路径)11String servletContext.getRealPath(String path) // path以web目录的根目录作为/12 13String b = servletContext.getRealPath("/b.txt"); //web目录下资源访问14String c = servletContext.getRealPath("/WEB-INF/c.txt"); //WEB-INF目录下的资源访问15String a = servletContext.getRealPath("/WEB-INF/classes/a.txt"); //src目录下的资源访问16
3. 使用案例
621("/downloadServlet")2public class DownloadServlet extends HttpServlet {3 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {4 //1.获取请求参数,文件名称5 String filename = request.getParameter("filename");6 7 //2.使用字节输入流加载文件进内存8 //2.1找到文件服务器路径9 ServletContext servletContext = this.getServletContext();10 String realPath = servletContext.getRealPath("/img/" + filename);11 //2.2用字节流关联12 FileInputStream fis = new FileInputStream(realPath);13
14 //3.设置response的响应头15 //3.1设置响应头类型:content-type16 String mimeType = servletContext.getMimeType(filename);//获取文件的mime类型17 response.setHeader("content-type",mimeType);18 //3.2设置响应头打开方式:content-disposition19
20 //解决中文文件名问题21 //1.获取user-agent请求头、22 String agent = request.getHeader("user-agent");23 //2.使用工具类方法编码文件名即可24 filename = DownLoadUtils.getFileName(agent, filename);25
26 response.setHeader("content-disposition","attachment;filename="+filename);27 28 //4.将输入流的数据写出到输出流中29 ServletOutputStream sos = response.getOutputStream();30 byte[] buff = new byte[1024 * 8];31 int len = 0;32 while((len = fis.read(buff)) != -1){33 sos.write(buff,0,len);34 }35
36 fis.close();37
38 }39
40 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {41 this.doPost(request,response);42 }43}44
45public class DownLoadUtils {46 public static String getFileName(String agent, String filename) throws UnsupportedEncodingException {47 if (agent.contains("MSIE")) {48 // IE浏览器49 filename = URLEncoder.encode(filename, "utf-8");50 filename = filename.replace("+", " ");51 } else if (agent.contains("Firefox")) {52 // 火狐浏览器53 BASE64Encoder base64Encoder = new BASE64Encoder();54 filename = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";55 } else {56 // 其它浏览器57 filename = URLEncoder.encode(filename, "utf-8");58 }59 return filename;60 }61}62
第五节 Cookie
1. 什么是Cookie?
Cookie是一种客户端会话技术,用来将少量、不太敏感的数据保存到客户端,得以完成一些特殊功能。如在不登录的情况下,完成服务器对客户端的身份识别。
2. 基本使用
191// 创建Cookie对象,绑定数据2new Cookie(String name, String value)3
4// 发送Cookie对象(注意:同一域名下的Cookie数量最多20个,每个Cookie最大4kb)5response.addCookie(Cookie cookie)6
7// 获取Cookie,拿到数据8Cookie[] request.getCookies()9
10// Cookie的持久化11cookie1.setMaxAge(int seconds) // 正数-持久化秒数,0-立即删除Cookie,负数-默认值,浏览器关闭后删除12
13// Cookie路径(用于同一个Tomcat服务器部署的多个web项目之间共享Cookie)14cookie1.setPath(String path) // 默认为当前web项目的虚拟目录。推荐设置为"/"。15
16// Cookie域(相同一级域名下的Cookie共享)17cookie1.setDomain(String path)18cookie1.setDomain(".baidu.com") // tieba.baidu.com、news.baidu19
3. 实现原理
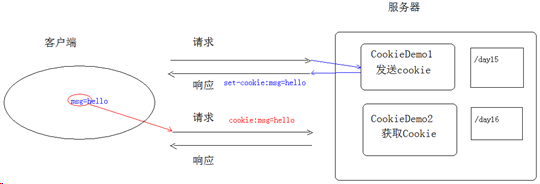
Cookie是基于响应头和请求头实现的。服务器通过响应头set-cookie设置客户端Cookie后,浏览器在后续发送请求时,都会在请求头cookie中携带所有的Cookie键值对。
4. 使用案例
471// 提示上一次访问时间2("/cookieTest")3public class CookieTest extends HttpServlet {4 5 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {6 // 设置响应的消息体的数据格式以及编码7 response.setContentType("text/html;charset=utf-8");8
9 // 1.获取所有Cookie10 Cookie[] cookies = request.getCookies();11
12 // 2. 获取最后一次访问时间13 String lastTime = null;14 for (Cookie cookie : cookies) {15 if (Objects.equals(cookie.getName(), "lastTime")) {16 String cookieValue = cookie.getValue();17 if (cookieValue != null && cookieValue.length() > 0) {18 lastTime = URLDecoder.decode(cookieValue, "utf-8");19 }20 break;21 }22 }23
24 // 3. 获取当前时间25 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");26 String dateStr = sdf.format(new Date());27 String encodeDateStr = URLEncoder.encode(dateStr, "utf-8");28
29 // 4. 刷新 lastTime Cookie30 Cookie lastTimeCookie = new Cookie("lastTime", encodeDateStr);31 lastTimeCookie.setMaxAge(60 * 60 * 24 * 30); // 存活一个月32 response.addCookie(lastTimeCookie);33
34 // 5. 回写数据35 if (lastTime == null) {36 response.getWriter().write("<h1>您好,欢迎您首次访问</h1>");37 } else {38 response.getWriter().write("<h1>欢迎回来,您上次访问时间为:" + lastTime + "</h1>");39 }40 }41
42 43 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {44 this.doPost(request, response);45 }46}47
第六节 Session
1. 什么是Session?
Session/HttpSession是一种服务器端会话技术,可以将关键数据保存在服务器中,实现一次会话的多次请求间共享数据。
会话的概念:会话指一个终端用户与交互系统进行通讯的过程。当客户端第一次给服务器发送资源请求时,就新建立了一个会话,直到有一方断开,则会话结束。
2. Session和Cookie的区别
Session存储数据在服务器端,Cookie在客户端。
Session没有数据大小限制,Cookie有。
Session数据安全,Cookie相对于不安全。
3. 基本使用
101// 获取HttpSession对象2HttpSession session = request.getSession();3
4// Session域共享数据5Object session.getAttribute(String name) 6void session.setAttribute(String name, Object value)7void session.removeAttribute(String name) 8
9// 使Session失效10session.invalidate()
4. 实现原理
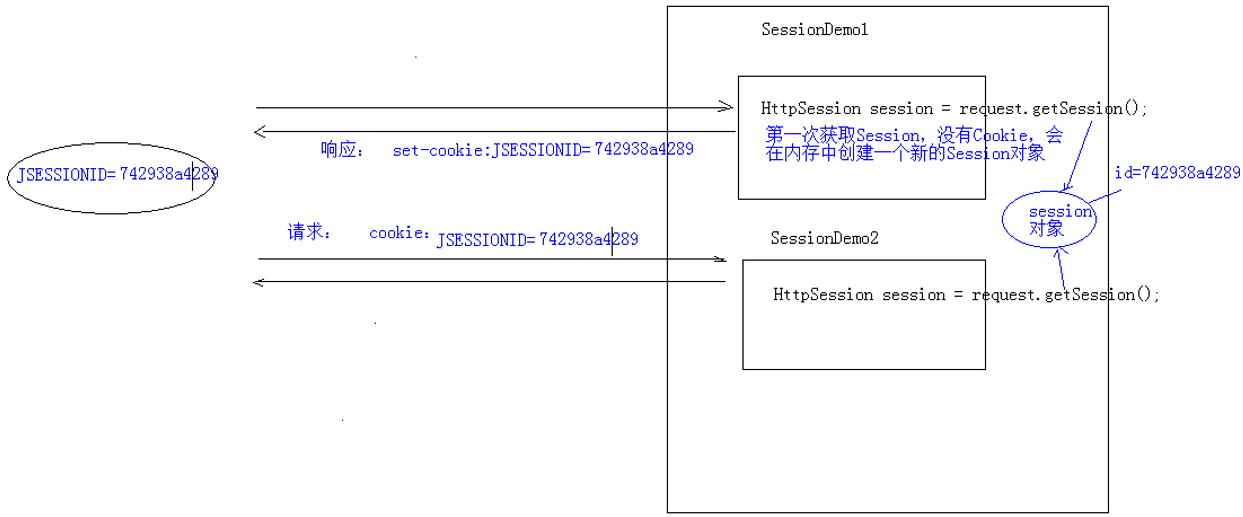
Session是基于Cookie实现的,在第一次请求时,服务器会设置一个名为JSESSIONID的Cookie,在后续请求过程中,如果客户端携带了该Cookie,则表示处于会话中。
Session会在下面几种情况下失效:
客户端关闭或Cookie过期。当名为JSESSIONID的Cookie被销毁后,会话也就关闭了。可以通过设置JSESSIONID的持久化时间来避免。
31Cookie c = new Cookie("JSESSIONID",session.getId());2c.setMaxAge(60*60); // 默认30分钟3response.addCookie(c);服务端关闭。服务器关闭后,SESSION对象自动销毁。但Tomcat会进行钝化和活化处理,确保SESSION数据不丢失。
程序手动关闭。调用request.getSession().invalidate()方法。
5. 使用案例
491// 使用Session实现验证码功能2("/loginServlet")3public class LoginServlet extends HttpServlet {4 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {5 // 1.设置request编码6 request.setCharacterEncoding("utf-8");7 8 // 2.获取参数9 String username = request.getParameter("username");10 String password = request.getParameter("password");11 String checkCode = request.getParameter("checkCode");12 13 // 3.获取生成的验证码14 HttpSession session = request.getSession();15 String checkCode_session = (String) session.getAttribute("checkCode_session");16 17 // 4. 删除session中存储的验证码18 session.removeAttribute("checkCode_session");19 20 // 5.判断验证码是否正确21 if(checkCode_session!= null && checkCode_session.equalsIgnoreCase(checkCode)){22 //验证码正确, 继续判断用户名和密码是否一致23 if("zhangsan".equals(username) && "123".equals(password)){//需要调用UserDao查询数据库24 //登录成功25 session.setAttribute("user",username); //存储信息,用户信息26 27 //重定向到success.jsp28 response.sendRedirect(request.getContextPath()+"/success.jsp");29 }else{30 //登录失败,存储提示信息到request31 request.setAttribute("login_error","用户名或密码错误");32 33 //转发到登录页面34 request.getRequestDispatcher("/login.jsp").forward(request,response);35 }36 }else{37 //验证码不一致,存储提示信息到request38 request.setAttribute("cc_error","验证码错误");39 40 //转发到登录页面41 request.getRequestDispatcher("/login.jsp").forward(request,response);42 }43 }44
45 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {46 this.doPost(request, response);47 }48}49
第七节 Filter
1. 什么是Filter?
Filter表示过滤器,当访问服务器的资源时,将请求拦截下来,完成一些特殊的功能,如登录验证、统一编码处理、敏感字符过滤等。
2. 基本使用
551
2/**3 * value:请求路径匹配4 * /* 拦截所有资源5 * /user/* 拦截/user/下的所有资源6 * *.jsp 拦截所有以.jsp结尾的资源7 * /index.jsp 拦截/index.jsp8 * 9 * dispatcherTypes:请求方式匹配,XML方式可配置<dispatcher></dispatcher>标签配置10 * REQUEST 默认值。浏览器直接请求资源11 * FORWARD 转发访问资源12 * INCLUDE 包含访问资源13 * ERROR 错误跳转资源14 * 和ASYNC 异步访问资源15 */16(value="/*",dispatcherTypes ={ DispatcherType.FORWARD,DispatcherType.REQUEST})17public class MyFilter01 implements Filter {18 /**19 * 在Filter对象被创建时执行一次。(Servlet是单例的!)20 *21 * @param filterConfig22 * @throws ServletException23 */24 25 public void init(FilterConfig filterConfig) throws ServletException {26
27 }28
29 /**30 * 拦截符合匹配路径的请求31 *32 * @param servletRequest33 * @param servletResponse34 * @param filterChain35 * @throws IOException36 * @throws ServletException37 */38 39 public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {40 System.out.println("MyFilter01-before....");41
42 // 放行43 filterChain.doFilter(servletRequest, servletResponse);44
45 System.out.println("MyFilter01-after....");46 }47
48 /**49 * 在Filter对象被销毁前(服务器被正常关闭时)执行一次50 */51 52 public void destroy() {53
54 }55}
如果不使用注解配置,也可以在web.xml中配置如下:
101<filter>2 <filter-name>myFilter01</filter-name>3 <filter-class>com.huangyuanxin.notes.javaweb.filter.MyFilter01</filter-class>4</filter>5<filter-mapping>6 <filter-name>myFilter01</filter-name>7 <!-- 拦截路径 -->8 <url-pattern>/*</url-pattern>9</filter-mapping>10
3. 过滤器链
某个请求可以被多个过滤器进行拦截,执行顺序为:过滤器1->过滤器2->资源执行->过滤器2->过滤器1。
如果使用注解方式配置,则按照类名的字符串比较规则比较,值小的先执行,如AFilter 和 BFilter,则AFilter先执行。
如果使用web.xml配置,则看
<filter-mapping>谁定义在上边,谁就先执行。
4. 使用案例
371("/*")2public class LoginFilter implements Filter {3
4 public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {5 HttpServletRequest request = (HttpServletRequest) req;6
7 //1.获取资源请求路径8 String uri = request.getRequestURI();9 10 //2.判断是否包含登录相关资源路径,要注意排除掉 css/js/图片/验证码等资源11 if(uri.contains("/login.jsp") || uri.contains("/loginServlet") || uri.contains("/css/") || uri.contains("/js/") || uri.contains("/fonts/") || uri.contains("/checkCodeServlet") ){12 //包含,用户就是想登录。放行13 chain.doFilter(req, resp);14 }else{15 //不包含,需要验证用户是否登录16 //3.从获取session中获取user17 Object user = request.getSession().getAttribute("user");18 if(user != null){19 //登录了。放行20 chain.doFilter(req, resp);21 }else{22 //没有登录。跳转登录页面23 request.setAttribute("login_msg","您尚未登录,请登录");24 request.getRequestDispatcher("/login.jsp").forward(request,resp);25 }26 }27 }28
29 public void init(FilterConfig config) throws ServletException {30
31 }32
33 public void destroy() {34 }35
36}37
第八节 Listener
1. 什么是Listener?
Listener是JavaWeb三大组件之一。常用的Listener有ServletContextListener等,其用来监听ServletContext对象的创建和销毁!
2. 基本使用
421public class ContextLoaderListener implements ServletContextListener {3
4 /**5 * 监听ServletContext对象创建的。ServletContext对象服务器启动后自动创建。6 * <p>7 * 在服务器启动后自动调用8 *9 * @param servletContextEvent10 */11 12 public void contextInitialized(ServletContextEvent servletContextEvent) {13 //加载资源文件14 //1.获取ServletContext对象15 ServletContext servletContext = servletContextEvent.getServletContext();16
17 //2.加载资源文件18 String contextConfigLocation = servletContext.getInitParameter("contextConfigLocation");19
20 //3.获取真实路径21 String realPath = servletContext.getRealPath(contextConfigLocation);22
23 //4.加载进内存24 try {25 FileInputStream fis = new FileInputStream(realPath);26 System.out.println(fis);27 } catch (Exception e) {28 e.printStackTrace();29 }30 System.out.println("ServletContext对象被创建了。。。");31 }32
33 /**34 * 在服务器关闭后,ServletContext对象被销毁。当服务器正常关闭后该方法被调用35 *36 * @param servletContextEvent37 */38 39 public void contextDestroyed(ServletContextEvent servletContextEvent) {40 System.out.println("ServletContext对象被销毁了。。。");41 }42}
第九节 JSP
1. 什么是JSP?
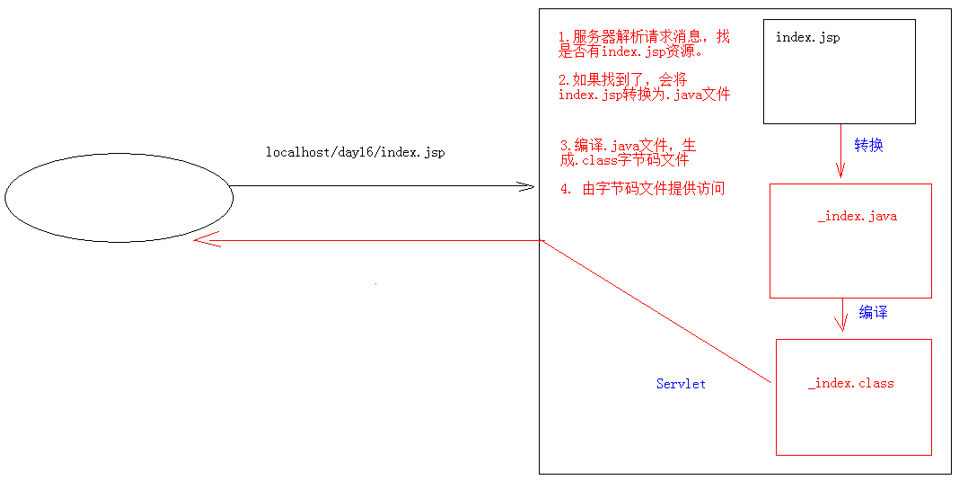
JSP(Java Server Pages,Java服务器端页面)可以理解为一个既可以写HTML标签,又可以写Java代码的特殊页面,其本质是一个Servlet。
2. 指令标签
JSP指令标签用于配置JSP页面,导入资源文件等。
111// page 指令:用于导入Java类以及配置JSP页面(contentType、错误页面、页面字符集、I/O流缓冲区大小)等。2<% page import="java.util.Date" %>3<% page contentType="text/html;charset=gbk" errorPage="500.jsp" 4 pageEncoding="GBK" language="java" buffer="16kb" %>5
6// include 指令: 用于导入页面的资源文件7<% include file="top.jsp"%>8 9// taglib 指令: 用于导入资源10<% taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> 11
上文中的500.jsp如下,isErrorPage为true表示该页面是一个错误页面,并且可以在错误页面使用exception对象
131<% page contentType="text/html;charset=UTF-8" isErrorPage="true" language="java" %>2<html>3<head>4 <title>Title</title>5</head>6<body>7 <h1>服务器正忙...</h1>8 <%9 String message = exception.getMessage();10 out.print(message);11 %>12</body>13</html>
3. 脚本标签
脚本标签用于定义Java代码,在jsp转换为Servlet后,分别放在不同的位置。
121// service方法的方法体。service方法中怎么写,该标签就怎么写2<% service %>3
4// Servlet的成员变量。由于线程安全问题,一般不经常使用。5<%! 成员 %>6 7// 输出到html页面。输出语句可以写什么,该标签就写什么。8<%= 输出 %> 9 10// JSP独有注释,技能注释HTML标签,也能注释JSP标签11<%-- 注释内容 --%>12
4. 内置对象
在jsp页面中不需要获取和创建,可以直接使用的对象,jsp一共有9个内置对象:
| 变量名 | 真实类型 | 作用 |
|---|---|---|
| pageContext | PageContext | 当前页面共享数据,还可以获取其他八个内置对象 |
| request | HttpServletRequest | 一次请求访问的多个资源间共享数据(转发) |
| session | HttpSession | 一次会话的多个请求间共享数据 |
| application | ServletContext | 所有用户间共享数据 |
| response | HttpServletResponse | 响应对象 |
| page | Object | 当前页面(Servlet)的对象 this |
| out | JspWriter | 字符输出流对象,将数据输出到页面上 |
| config | ServletConfig | Servlet的配置对象 |
| exception | Throwable | 异常对象 |
5. 使用案例
561<% page import="java.net.URLDecoder" %>2<% page import="java.net.URLEncoder" %>3<% page import="java.text.SimpleDateFormat" %>4<% page import="java.util.Date" %>5<% page import="java.util.Objects" %>6<% page contentType="text/html;charset=UTF-8" language="java" %>7<html>8<head>9 <title>itcast</title>10</head>11<body>12
13<%14 // 设置响应的消息体的数据格式以及编码15 response.setContentType("text/html;charset=utf-8");16
17 // 1.获取所有Cookie18 Cookie[] cookies = request.getCookies();19
20 // 2. 获取最后一次访问时间21 String lastTime = null;22 for (Cookie cookie : cookies) {23 if (Objects.equals(cookie.getName(), "lastTime")) {24 String cookieValue = cookie.getValue();25 if (cookieValue != null && cookieValue.length() > 0) {26 lastTime = URLDecoder.decode(cookieValue, "utf-8");27 }28 break;29 }30 }31
32 // 3. 获取当前时间33 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");34 String dateStr = sdf.format(new Date());35 String encodeDateStr = URLEncoder.encode(dateStr, "utf-8");36
37 // 4. 刷新 lastTime Cookie38 Cookie lastTimeCookie = new Cookie("lastTime", encodeDateStr);39 lastTimeCookie.setMaxAge(60 * 60 * 24 * 30); // 存活一个月40 response.addCookie(lastTimeCookie);41
42 // 5. 回写数据43 if (lastTime == null) {44%>45 <h1>您好,欢迎您首次访问</h1>46<%47} else {48%>49 <h1>欢迎回来,您上次访问时间为:<%=lastTime%>50 </h1>51<%52 }53%>54</body>55</html>56
第十节 EL表达式
1. 什么是EL表达式?
EL(Expression Language)指表达式语言,用于替换和简化JSP页面中Java代码的编写,格式为:${表达式}。
2. 内置对象
| pageContext | 对应于JSP页面中的pageContext对象,用于获取jsp其他八个内置对象 |
|---|---|
| pageScope | 代表page域中用于保存属性的Map对象 |
| requestScope | 代表request域中用于保存属性的Map对象 |
| sessionScope | 代表session域中用于保存属性的Map对象 |
| applicationScope | 代表application域中用于保存属性的Map对象 |
| param | 表示一个保存了所有请求参数的Map对象 |
| paramValues | 表示一个保存了所有请求参数的Map对象,它对于某些请求参数,返回的是一个string[] |
| header | 表示一个保存了所有http请求头字段的Map对象 |
| headerValues | 同上,返回string[]数组。注意:如果头里面有"-" ,例Accept-Encoding,则要headerValues["Accept-Encoding"] |
| cookie | 表示一个保存了所有cookie的Map对象 |
| initParam | 表示一个保存了所有web应用初始化参数的map对象 |
3. 域对象取值
151// 取域对象中的基础类型,格式为:${[域名称.]属性名}2${name} // 依次从pageScope、requestScope、sessionScope、applicationScope中查找3${requestScope.name} // 指定在requestScope查找4
5// 取域对象中的对象属性,格式为:${域名称.对象名.属性名}6${user01.name}7
8// 取域对象中的List集合,格式为:${域名称.list名[索引]}9${list[0]}10
11// 取域对象中的Map集合,格式为:${域名称.map名.key名称} 或 ${域名称. map名["key名称"]}12${map.gender}13${map["gender"]}14
15//
4.运算符
| 算数运算符 | +、 -、 *、 /(div)、 %(mod) |
|---|---|
| 比较运算符 | >、<、>=、<=、==、!= |
| 逻辑运算符 | &&(and)、||(or)、!(not) |
| 空运算符 | empty,用于判断字符串、集合、数组对象是否为null或者长度是否为0 |
61// 判断字符串、集合、数组对象是否为null或者长度为02${empty list} 3
4// 表示判断字符串、集合、数组对象是否不为null 并且 长度>05${not empty str} 6
5. 忽略EL表达式
JSP是默认支持EL表达式的,如果要忽略EL表达式,有两种方案:
忽略某个EL表达式:只需要在EL表达式前加\即可。格式为
\${表达式}。忽略整个JSP页面中的EL表达式:可以添加page指令,设置属性isELIgnored为true即可。
第十一节 JSTL
1. 什么是JSTL?
JSTL(JavaServer Pages Tag Library,JSP标准标签库)是由Apache组织提供的开源的免费的jsp标签,用于简化和替换jsp页面上的java代码。
2. 基本使用
JSTL的使用步骤如下:
导入jstl相关jar包,注意一定要导入到web/WEB-INF/lib目录下。
引入标签库:使用taglib指令,
<%@taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>。使用标签。
3. 常用标签
501<!-- if标签(注意:没有else的情形) -->2<c:if test="${not empty list}">3 遍历集合...4</c:if>5<br>6
7<!-- choose标签 -->8<c:choose>9 <c:when test="${number == 1}">星期一</c:when>10 <c:when test="${number == 2}">星期二</c:when>11 <c:when test="${number == 3}">星期三</c:when>12 <c:when test="${number == 4}">星期四</c:when>13 <c:when test="${number == 5}">星期五</c:when>14 <c:when test="${number == 6}">星期六</c:when>15 <c:when test="${number == 7}">星期天</c:when>16
17 <c:otherwise>数字输入有误</c:otherwise>18</c:choose>19
20<!-- forEach标签(定值遍历) 21 begin:开始值22 end:结束值23 var:临时变量24 step:步长25 varStatus:循环状态对象,该对象有两个常用属性:26 index:表示容器中元素的索引,从0开始。27 count:循环次数,从1开始。28-->29<c:forEach begin="1" end="10" var="i" step="2" varStatus="s">30 ${i} <h3>${s.index}<h3> <h4> ${s.count} </h4><br>31</c:forEach>32
33<!-- forEach标签(列表遍历) 34 items:遍历的列表35 var:临时变量36 varStatus:循环状态对象,该对象有两个常用属性:37 index:表示容器中元素的索引,从0开始。38 count:循环次数,从1开始。39-->40<%41 List list = new ArrayList();42 list.add("aaa");43 list.add("bbb");44 list.add("ccc");45 request.setAttribute("list",list);46%>47<c:forEach items="${list}" var="str" varStatus="s">48 ${s.index} ${s.count} ${str}<br>49</c:forEach>50
4. 使用案例
551<% page import="cn.itcast.domain.User" %>2<% page import="java.util.List" %>3<% page import="java.util.ArrayList" %>4<% page import="java.util.Date" %>5<% page contentType="text/html;charset=UTF-8" language="java" %>6<% prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>7
8<html>9<head>10 <title>test</title>11</head>12<body>13
14<%15 List list = new ArrayList();16 list.add(new User("张三",23,new Date()));17 list.add(new User("李四",24,new Date()));18 list.add(new User("王五",25,new Date()));19
20 request.setAttribute("list",list);21%>22
23<table border="1" width="500" align="center">24 <tr>25 <th>编号</th>26 <th>姓名</th>27 <th>年龄</th>28 <th>生日</th>29 </tr>30 31 <%--数据行--%>32 <c:forEach items="${list}" var="user" varStatus="s">33 <c:if test="${s.count % 2 != 0}">34 <tr bgcolor="red">35 <td>${s.count}</td>36 <td>${user.name}</td>37 <td>${user.age}</td>38 <td>${user.birStr}</td>39 </tr>40 </c:if>41
42 <c:if test="${s.count % 2 == 0}">43
44 <tr bgcolor="green">45 <td>${s.count}</td>46 <td>${user.name}</td>47 <td>${user.age}</td>48 <td>${user.birStr}</td>49 </tr>50 </c:if>51 </c:forEach>52</table>53</body>54</html>55
第十二节 补充: HTTP协议
1. 什么是HTTP协议?
HTTP(Hyper Text Transfer Protocol)指超文本传输协议,定义了客户端和服务器端通信时,发送数据的格式,它是对TCP/IP协议的一层封装,默认端口为80。
2. HTTP协议的特点
HTTP是无状态的。每次请求之间相互独立,不能交互数据。
HTTP是基于请求/响应模型的。在早期1.0版本,每一次请求响应都会建立新的连接,但1.1版本之后会对进行连接复用。
3. 请求消息格式
HTTP请求消息是客户端发送给服务端的数据,先来看一个简单的HTTP请求示例:
121POST /login.html HTTP/1.12
3Host: localhost4User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.05Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.86Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.27Accept-Encoding: gzip, deflate8Referer: http://localhost/login.html9Connection: keep-alive10Upgrade-Insecure-Requests: 111
12username=zhangsan可以观察到,HTTP请求消息可分为下面四部分:
请求行:格式为请求方式 请求url 请求协议/版本。其中请求方式有七种,最常用的两种如下:
GET:把参数直接放在URL之后,因此不太安全,并且请求的URL有长度限制。
POST:把参数封装为请求体,相对来说安全些,并且请求体中参数没有长度限制。
请求头:客户端浏览器告诉服务器一些信息,格式为[请求头名称: 请求头值],常见的请求头有下:
User-Agent:携带客户端的浏览器版本信息,用于解决浏览器的兼容性问题。
Referer:告诉服务器,我(当前请求)从哪里来,可以防止盗链和进行数据统计。
请求空行:用于分割POST请求的请求头和请求体的,无实际意义。
请求体(正文):封装POST请求消息的请求参数的。
4. 响应消息格式
HTTP响应消息指服务器端发送给客户端的数据,先来看一个简单的示例:
141HTTP/1.1 200 OK2
3Content-Type: text/html;charset=UTF-84Content-Length: 1015Date: Wed, 06 Jun 2018 07:08:42 GMT6
7<html>8 <head>9 <title>Title</title>10 </head>11 <body>12 hello , response13 </body>14</html>可以观察到,HTTP应答消息也分为四部分:
响应行:格式为协议/版本 响应状态码 状态码。其中常用响应状态码如下:
1xx:超时。服务器接收客户端消息,但没有接受完成,等待一段时间后,发送1xx多状态码。
2xx:成功。如200。
3xx:重定向。如302(重定向)、304(访问缓存)。
4xx:客户端错误。如404(请求路径没有对应的资源)、405(请求方式没有对应的doXxx方法)。
5xx:服务器端错误。如500(服务器内部出现异常)。
响应头:格式为[响应头名称: 响应头值]。常见的响应头如下:
Content-Type:服务器告诉客户端本次响应体数据格式以及编码格式。如
text/html;charset=utf-8。Content-disposition:服务器告诉客户端以什么格式打开响应体数据,取值有
in-line和attachment;filename=xxx等。
响应空行:用于分割响应头和响应体的,无实际意义。
响应体 :服务器回写给客户端的业务数据。
第04章_Java虚拟机
第一节 Java运行参数
1. 标准参数
121# 查看标准参数列表2java -help3
4# 查看扩展参数列表5java -X6
7# 查看JVM版本8java -version9
10# 设置系统属性11java -Dusername=hyx # 在代码中可通过 System.getProperty("username") 获取12
注意:
标准参数在未来的JVM版本基本不会改变,而以
-X或-XX开头的扩展参数则可能修改。
2. 堆内存相关参数
171# 堆内存大小2java -Xms512M -Xmx2G # 堆内存初始512M,最大2G(推荐方式)3java -XX:InitialHeapSize=512M -XX:MaxHeapSize=2G # 堆内存初始512M,最大2G4
5# 新生代大小6# 合理设置新生代大小,避免频繁 Full GC 7java -Xmn256m # 新生代固定为256M(推荐方式) 8java -XX:NewSize=256m -XX:MaxNewSize=1024m # 新生代初始为256M,最大为1024M9java -XX:NewRatio=2 # 新生代是老年代的2倍,即:新生代/老年代=210java -XX:SurvivorRatio=6 # Eden区是Survivor区的6倍,即:Eden/Survivor=6 11
12# 永久代/元空间大小 13java -XX:PermSize=N # JDK7:永久代初始大小14java -XX:MaxPermSize=N # JDK7:永久代最大大小,超过这个值将会抛出java.lang.OutOfMemoryError: PermGen15java -XX:MetaspaceSize=N # JDK8:元空间初始大小固定为20MB左右,该参数是设置元空间触发FullGC的阈值16java -XX:MaxMetaspaceSize=N # JDK8:元空间最大大小,如未设置将会无限制占用系统内存17
3. GC相关参数
231# 切换垃圾收集器2java -XX:+UseSerialGC 3java -XX:+UseParallelGC4java -XX:+UseConcMarkSweepGC5java -XX:+UseG1GC6
7# 打印GC日志8java -XX:+PrintGCDetails -XX:+PrintGCDateStamps # 打印基本 GC 信息9 -XX:+PrintTenuringDistribution # 打印对象分布10 -XX:+PrintHeapAtGC # 打印堆数据11 -XX:+PrintReferenceGC # 打印Reference处理信息(强引用/弱引用/软引用/虚引用/finalize 相关的方法)12 -XX:+PrintGCApplicationStoppedTime # 打印STW时间13 -Xloggc:/path/to/gc-%t.log # GC日志输出的文件路径14 -XX:+UseGCLogFileRotation # 开启日志文件分割15 -XX:NumberOfGCLogFiles=14 # 最多分割几个文件,超过之后从头文件开始写16 -XX:GCLogFileSize=50M # 每个文件上限大小,超过就触发分割17
18# 处理OOM19java -XX:+HeapDumpOnOutOfMemoryError # 遇到 OutOfMemoryError 错误时将 heap 转储到物理文件中20 -XX:HeapDumpPath=./java_pid<pid>.hprof # 物理文件路径(如果引用了<pid>,则将使用.hprof格式)21 -XX:OnOutOfMemoryError="< cmd args >" # 内存不足时的紧急指令,如重启:java -XX:OnOutOfMemoryError="shutdown -r"22 -XX:+UseGCOverheadLimit # 限制在抛出 OutOfMemory 错误之前在 GC 中花费的 VM 时间的比例23
4. 其它参数
41
2# 禁用手动GC3java -XX:+DisableExplicitGC # 使代码中的System.gc()语句失效4
第二节 JDK常用工具
1. 查看进程信息(jps -l)
131# 用法参考2jps -q # 只输出进程号3jps -l # 输出全类名4jps -v # 输出启动时 JVM 参数5jps -m # 输出传递给 Java 进程 main() 函数的参数6
7# 示例1:查询java进程8C:\Users\Administrator>jps -l920064 org.jetbrains.idea.maven.server.RemoteMavenServer361017108 sun.tools.jps.Jps11225641223924 org.jetbrains.jps.cmdline.Launcher13
2. 查看运行参数(jinfo <pid>)
71# 查看运行参数2jinfo <pid> # 查看全部参数和系统属性3jinfo -flag <name> <pid> # 查看指定参数,如:jinfo -flag MaxHeapSize 173404jinfo -flags <pid> # 显示 JVM 的非默认参数设置5
6# 调整JVM参数7jinfo -flag [+|-]<name> <pid> # 开启或者关闭对应名称的参数,如:jinfo -flag +PrintGC 17340
3. 查看运行状态( jstat)
jstat命令可以查看堆内存的各种统计信息,使用格式如下:
1) 查看类加载统计
使用jstat -class <进程ID>可以查看类加载统计。
41C:\Users\Administrator>jstat -class 178842Loaded Bytes Unloaded Bytes Time3 18454 32302.9 4 3.6 17.094
如上,表示加载了18454个类,共占用32302.9字节空间,共耗时17.09秒,剩余4个类未进行加载,总大小为3.6字节。
2) 查看编译统计
使用jstat -compiler <进程ID>可以查看编译统计。
31C:\Users\Administrator>jstat -compiler 178842Compiled Failed Invalid Time FailedType FailedMethod3 13399 0 0 4.45 0如上,表示编译了13399个类,失败0个,无效类0个,共耗时4.45秒。
3) 查看垃圾回收统计
使用jstat ‐gc <进程ID>可以查看垃圾回收统计,也可以使用jstat ‐gc <进程ID> <间隔n毫秒> <查询次数>连续多次查询。
221C:\Users\Administrator>jstat -gc 178842S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT362464.0 512.0 0.0 352.0 179200.0 108934.2 307200.0 238046.3 93232.0 87781.6 12848.0 11852.0 91 0.996 11 2.656 3.6524
5S0C :第一个Survivor区的大小(KB)6S1C :第二个Survivor区的大小(KB)7S0U :第一个Survivor区的使用大小(KB)8S1U :第二个Survivor区的使用大小(KB)9EC :Eden区的大小(KB)10EU :Eden区的使用大小(KB)11OC :Old区大小(KB)12OU:Old使用大小(KB)13MC :方法区大小(KB)14MU :方法区使用大小(KB)15CCSC:压缩类空间大小(KB)16CCSU :压缩类空间使用大小(KB)17YGC :年轻代垃圾回收次数18YGCT :年轻代垃圾回收消耗时间19FGC :老年代垃圾回收次数20FGCT :老年代垃圾回收消耗时间21GCT :垃圾回收消耗总时间22
4. 查看内存使用情况(jmap)
1) 查看内存使用情况
使用jmap -heap <进程ID>可以查看堆内存的使用情况。
521C:\Users\Administrator>jmap -heap 178842Attaching to process ID 17884, please wait...3Debugger attached successfully.4Server compiler detected.5JVM version is 25.5-b026
7using thread-local object allocation.8Parallel GC with 13 thread(s)9
10// 堆内存配置11Heap Configuration:12 MinHeapFreeRatio = 4013 MaxHeapFreeRatio = 7014 MaxHeapSize = 8434745344 (8044.0MB)15 NewSize = 1572864 (1.5MB)16 MaxNewSize = 2811232256 (2681.0MB)17 OldSize = 526909440 (502.5MB)18 NewRatio = 219 SurvivorRatio = 820 MetaspaceSize = 21807104 (20.796875MB)21 CompressedClassSpaceSize = 1073741824 (1024.0MB)22 MaxMetaspaceSize = 17592186044415 MB23 G1HeapRegionSize = 0 (0.0MB)24
25Heap Usage:26
27// 年轻代28PS Young Generation29Eden Space:30 capacity = 175636480 (167.5MB)31 used = 125258904 (119.4561996459961MB)32 free = 50377576 (48.043800354003906MB)33 71.3171341170126% used34From Space:35 capacity = 49807360 (47.5MB)36 used = 393216 (0.375MB)37 free = 49414144 (47.125MB)38 0.7894736842105263% used39To Space:40 capacity = 60817408 (58.0MB)41 used = 0 (0.0MB)42 free = 60817408 (58.0MB)43 0.0% used44 45// 老年代46PS Old Generation47 capacity = 314572800 (300.0MB)48 used = 243784016 (232.4905548095703MB)49 free = 70788784 (67.50944519042969MB)50 77.49685160319011% used51
5251692 interned Strings occupying 5304608 bytes.
2) 查看内存中对象数量及大小
使用jmap -histo <进程ID> | more查看内存中的所有对象数量和大小。
限定查看活跃对象
jmap -histo:live <进程ID> | more。
421C:\Users\Administrator>jmap -histo 17884 | more2
3 num #instances #bytes class name4----------------------------------------------5 1: 1226102 80650328 [C6 2: 1123195 26956680 java.lang.String7 3: 705647 22580704 java.util.concurrent.ConcurrentHashMap$Node8 4: 409630 21400376 [Ljava.lang.Object;9 5: 149851 13186888 java.lang.reflect.Method10 6: 35877 12462872 [I11 7: 506407 12153768 java.lang.Long12 8: 170211 10901192 [B13 9: 631 10080088 [Ljava.util.concurrent.ConcurrentHashMap$Node;14 10: 291708 9334656 java.util.HashMap$Node15 11: 80501 8038952 [Ljava.util.HashMap$Node;16 12: 333112 7994688 org.apache.kafka.common.internals.PartitionStates$PartitionState17 13: 262144 6291456 org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor$Log4jEventWrapper18 14: 124146 5959008 java.util.HashMap19 15: 123515 4940600 java.util.LinkedHashMap$Entry20 16: 150479 4815328 java.util.ArrayList$Itr21 17: 93319 4479312 org.aspectj.weaver.reflect.ShadowMatchImpl22 18: 185900 4461600 java.util.ArrayList23 19: 93319 2986208 org.aspectj.weaver.patterns.ExposedState24 20: 68876 2755040 java.util.HashMap$EntryIterator25 21: 49043 2746408 java.util.LinkedHashMap26 22: 113752 2585168 [Ljava.lang.Class;27 23: 41573 2328088 sun.nio.cs.UTF_8$Encoder28 24: 19458 2025464 java.lang.Class29 25: 83466 2003184 org.apache.kafka.common.protocol.types.Struct30 26: 32548 1822688 java.util.concurrent.ConcurrentHashMap$KeyIterator31-- More --32
33// 对象符号说明:34B byte35C char36D double37F float38I int39J long40Z boolean41[ 数组,如[I表示int[]42[L+类名 其他对象
3) 将内存使用情况dump到文件中
使用jmap -dump:format=b,file=<文件名> <进程ID>将内存的使用情况 dump 到文件中,然后使用其它工具进行分析。
31C:\Users\Administrator>jmap -dump:format=b,file=D:\dump_17884.bat 178842Dumping heap to D:\dump_17884.bat ...3Heap dump file created
4) 使用jhat命令分析内存dump文件
内存dump文件是二进制文件,可以借助jhat命令启动内置web服务器进行浏览,命令格式如下:jhat -port <端口> <dump文件名>。
111C:\Users\Administrator>jhat -port 1234 D:\dump_17884.bat2Reading from D:\dump_17884.bat...3Dump file created Tue Dec 28 20:06:20 CST 20214Snapshot read, resolving...5Resolving 8249547 objects...6Chasing references, expect 1649 dots.................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................7Eliminating duplicate references.................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................8Snapshot resolved.9Started HTTP server on port 123410Server is ready.11
web服务启动后,就可以通过浏览器进行查看了( http://127.0.0.1:1234/ )。
在最下方有OQL查询窗口,可以查询需要的信息。如查询长度>1000的字符串。
11select s from java.lang.String s where s.value.length > 10000;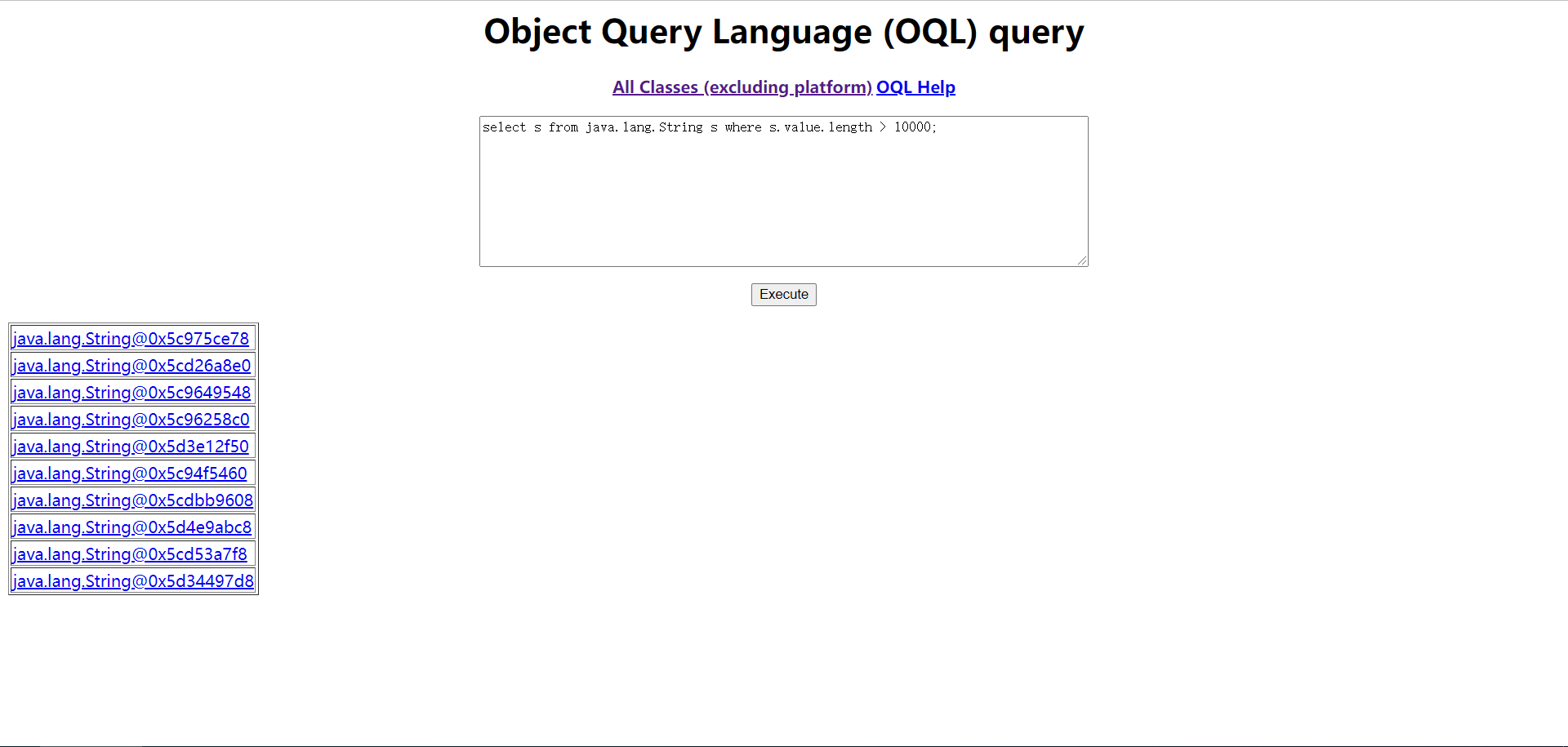
5) 使用mat工具分析内存dump文件
MAT(Memory Analyzer Tool)是一个基于Eclipse的JAVA堆内存分析工具,下载地址:https://www.eclipse.org/mat/downloads.php 。打开后通过点击File->Open Heap Dump...导入内存dump文件,一般选择Leak Suspects Report选项进行打开,得到分析结果如下。

可以点击相关链接查看关注的信息。
5. 查看线程状态
1) 线程的状态图
在 Java中线程的状态一共被分成6种,下面是线程状态之间的流转图。
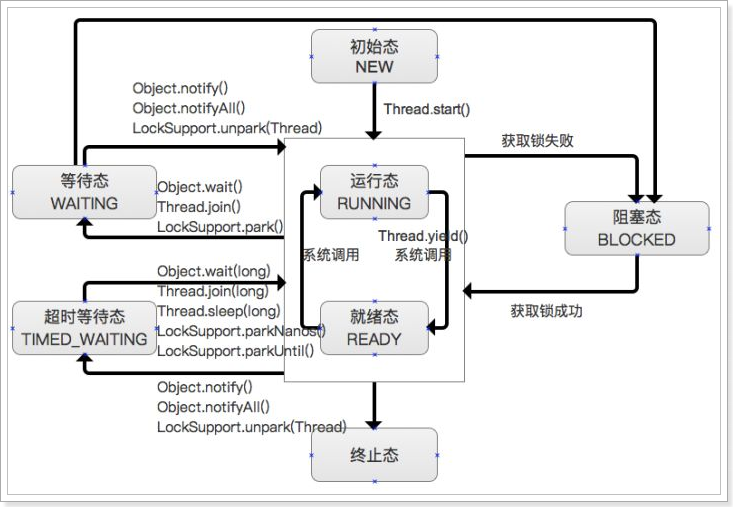
初始态(NEW)
创建一个 Thread对象,但还未调用start()启动线程时,线程处于初始态。
就绪态(READY)
该状态下的线程已经获得执行所需的所有资源,只要 CPU分配执行权就能运行。所有就绪态的线程存放在就绪队列中。
运行态(RUNNABLE)
获得 CPU执行权,正在执行的线程。由于一个 CPU同一时刻只能执行一条线程,因此每个CPU每个时刻只有一条运行态的线程。
阻塞态(BLOCKED)
当一条正在执行的线程请求某一资源失败时,就会进入阻塞态。而在 Java中,阻塞态专指请求锁失败时进入的状态。由一个阻塞队列存放所有阻塞态的线程。处于阻塞态的线程会不断请求资源,一旦请求成功,就会进入就绪队列,等待执行。
等待态(WAITING)
当前线程中调用 wait、join、park函数时,当前线程就会进入等待态。也有一个等待队列存放所有等待态的线程。线程处于等待态表示它需要等待其他线程的指示才能继续运行。进入等待态的线程会释放 CPU执行权,并释放资源(如:锁)。
超时等待态(TIMED_WAITING)
当运行中的线程调用 sleep(time)、wait、join、parkNanos、parkUntil时,就会进入该状态;它和等待态一样,并不是因为请求不到资源,而是主动进入,并且进入后需要其他线程唤醒;进入该状态后释放 CPU执行权 和 占有的资源。与等待态的区别是到了超时时间后自动进入阻塞队列,开始竞争锁。
终止态(TERMINATED)
线程执行结束后的状态。
2) 线程运行信息(jstack)
jstack可以将正在运行的jvm的线程情况进行快照,并且打印出来,格式为:jstack <进程ID>。
191C:\Users\Administrator>jstack 1788422021-12-28 20:40:153Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.5-b02 mixed mode):4
5"Kcxp_Pool_Checking_Task_2" #184 daemon prio=5 os_prio=0 tid=0x0000000030b22800 nid=0x4518 waiting on condition [0x0000000036d6e000]6 java.lang.Thread.State: WAITING (parking)7 at sun.misc.Unsafe.park(Native Method)8 - parking to wait for <0x00000005d68fcf28> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)9 at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)10 at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)11 at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1088)12 at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)13 at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)14 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)15 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)16 at java.lang.Thread.run(Thread.java:745)17
18...................19
如下为一个两个互相死锁的线程信息:
121"Thread‐1":2 at TestDeadLock$Thread2.run(TestDeadLock.java:47) 3 ‐ waiting to lock <0x00000000f655dc40> (a java.lang.Object) 4 ‐ locked <0x00000000f655dc50> (a java.lang.Object) 5 at java.lang.Thread.run(Thread.java:748) 6
7"Thread‐0":8 at TestDeadLock$Thread1.run(TestDeadLock.java:27) 9 ‐ waiting to lock <0x00000000f655dc50> (a java.lang.Object) 10 ‐ locked <0x00000000f655dc40> (a java.lang.Object) 11 at java.lang.Thread.run(Thread.java:748) 12 Thread‐1持有0x00000000f655dc50锁,等待0x00000000f655dc40锁,而Thread‐0持有0x00000000f655dc40锁,等待0x00000000f655dc50锁。
6. JDK可视化分析工具
1) JConsole
JConsole 是基于 JMX 的可视化监视和管理工具,适合快速查看 JVM 的基本运行状态,例如内存使用、线程状态等。
51# 开启JMX远程连接2java -Djava.rmi.server.hostname=外网访问 ip 地址3-Dcom.sun.management.jmxremote.port=60001 //监控的端口号4-Dcom.sun.management.jmxremote.authenticate=false //关闭认证5-Dcom.sun.management.jmxremote.ssl=false
2) VisualVM
VisualVM 基于 NetBeans 平台开发,适合需要进行深入性能分析、内存泄漏排查、线程问题诊断等复杂场景(远程配置方式同上)。
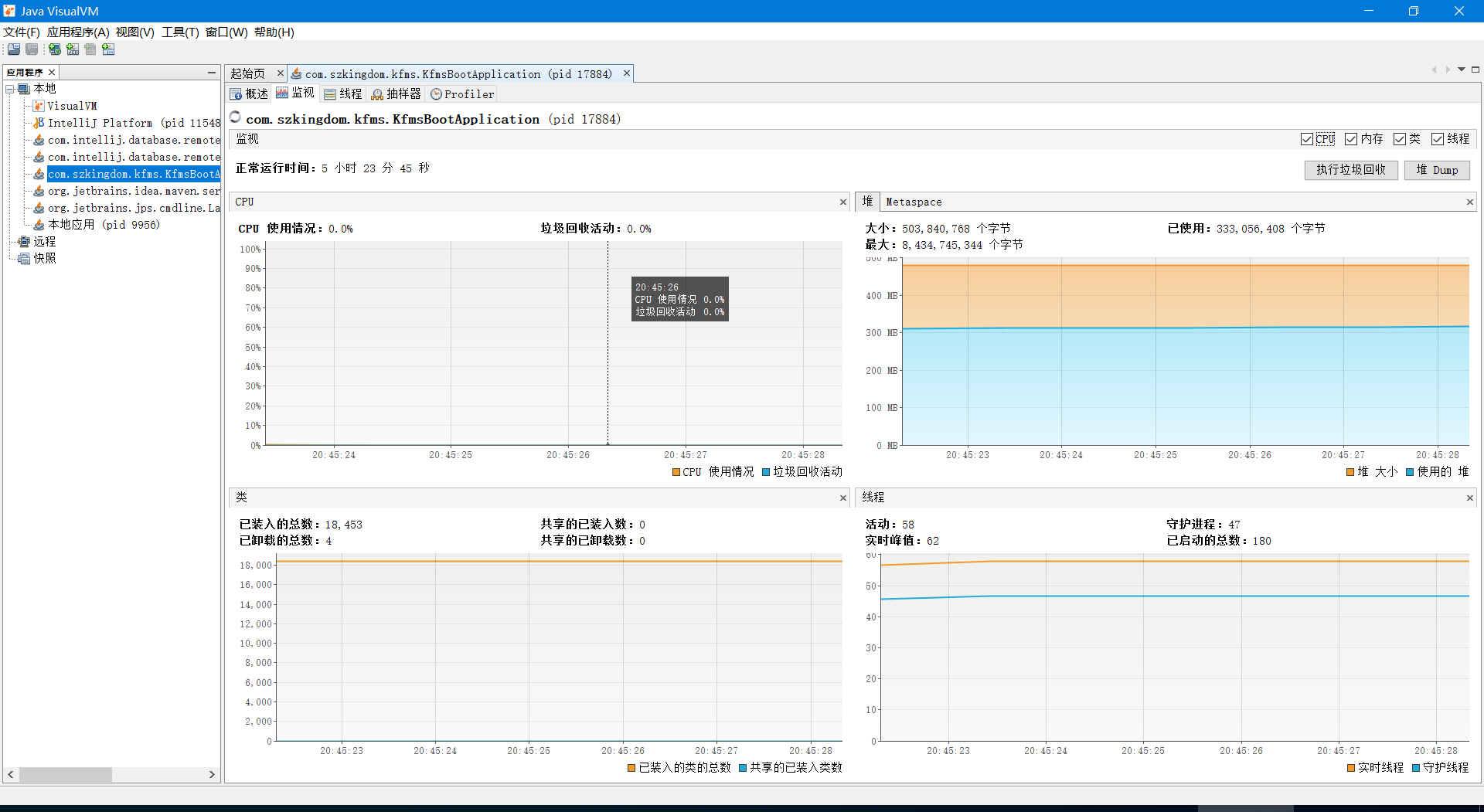
扩展:
如需更进一步的分析,可选择 MAT 和 JProfiler 等专业工具。
7. 常见JVM故障
启动参数设置不合理:
-Xms和-Xmx参数设置过大或过小,-Xmn参数与-Xmx参数相等。内存加载数据量过大: 未限制查询行数的SQL语句,未限制读写字节数的文件IO等。
内存泄漏(资源未关闭/无法回收):如错误使用静态集合类对象,使用数据库、文件等资源未正常调用 close() 方法。
参考:
第三节 垃圾回收机制
1. 运行时内存区域
在执行 Java 程序的过程中,Java 虚拟机会把它管理的内存划分成若干个不同的数据区域。
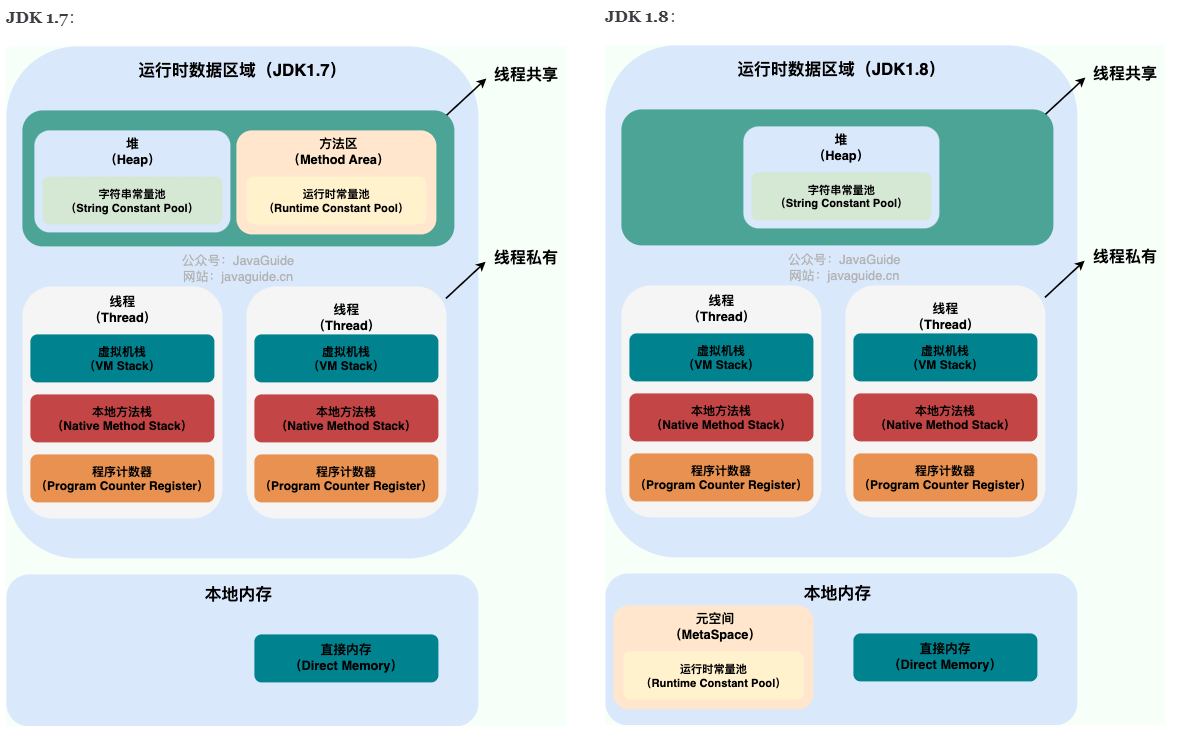
1) 堆内存
堆内存是虚拟机管理的最大的一块内存,被所有线程共享,在虚拟机启动时创建,用于存放对象实例。
从垃圾回收的角度,又可细分为新生代(Eden、S0、S1)和老年代(Tenured),目的是更好地回收内存,或者更快地分配内存。
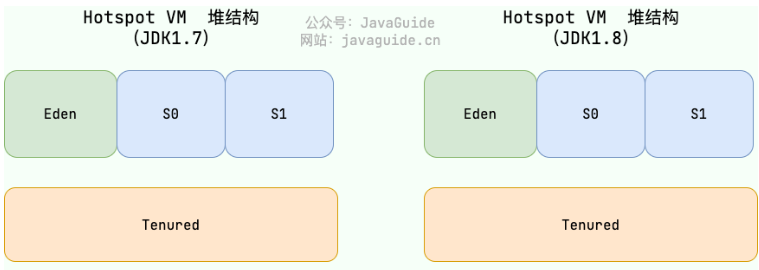
大部分情况,对象的内存都会在 Eden 区进行分配,但需要大量连续内存空间的对象(比如:字符串、数组)的大对象除外。
在一次新生代垃圾回收后,如果对象还存活,则会进入 Survivor 区( S0 或者 S1),并且对象的年龄还会加 1。
当它的年龄增加到一定程度(默认为 15 岁,参数:-XX:MaxTenuringThreshold),就会被晋升到老年代中。
扩展:
堆内存最常见的错误是
OutOfMemoryError错误,如:
在执行垃圾回收很难回收到堆内存空间时:java.lang.OutOfMemoryError: GC Overhead Limit Exceeded。
在创建新对象但堆内存空间不足时:java.lang.OutOfMemoryError: Java heap space。
为什么要分为新生代和老年代?
主要从GC层面考虑的,新生代适合复制算法,只需复制较少的存活对象。
老年代的对象存活几率是比较高的,适合标记清除法或标记压缩算法。
2) 方法区
方法区存储已加载的类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
在JDK1.7中,由JVM管理的PermGen(永久代) 作为方法区,在JDK1.8及之后,被迁移至本地内存中的 Metaspace(元空间) 。
81// JDK1.7参数2-XX:PermSize=N //方法区 (永久代) 初始大小3-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen4
5// JDK1.8参数6-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)7-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小8
注意:
当元空间溢出时会得到如下错误:
java.lang.OutOfMemoryError: MetaSpace
3) 常量池
运行时常量池:位于方法区中,用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)。
字符串常量池:位于堆内存中,是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域。
注意:
在JDK1.6中,字符串常量池存在永久代中,但是由于GC麻烦,在JDK1.7时,就迁移到了堆内存中。
4) 程序计数器
程序计数器是一块较小的内存空间,记录当前线程所执行的字节码指令的地址(执行native方法时为空),从而实现代码的流程控制。
扩展:
程序计数器随线程的创建而创建,随线程的结束而销毁,唯一一个不会出现
OutOfMemoryError的内存区域。
5) 虚拟机栈
虚拟机栈用于执行Java方法,方法的调用和结束(return或抛异常)分别对应入栈和出栈。
栈由一个个栈帧组成,遵循先进后出原则,每个栈帧包括:局部变量表、操作数栈、动态链接、方法返回地址等。
扩展:
虚拟机栈也随线程的创建而创建,随线程的结束而销毁,可能出现
StackOverFlowError或OutOfMemoryError错误。
6) 本地方法栈
虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务,两者基本相似。
7) 直接内存
直接内存是一种特殊的内存缓冲区,通过ByteBuffer.allocateDirect()在本地内存分配,主要用于高性能的I/O操作。
注意:
堆外内存是一个更广泛的概念,包括直接内存以及其它非堆内存,可通过
sun.misc.Unsafe类或其它第三方类库分配,长常用于存储大型缓存数据、日志数据等,以减轻堆内存GC压力。
2. 垃圾回收算法
1) 引用计数法
引用计数法是最早期的垃圾回收算法,当对象被引用时计数器+1,释放引用时计数器-1,当计数器为0时,则进行回收。
优点:
实时性较高,在垃圾回收过程中,应用无需挂起。
更新对象的计数器时,只是影响到该对象,不会扫描全部对象。
缺点:
在内存充足时,也需更新引用计数,浪费CPU资源;
多线程环境下,引用计数变更也要进行昂贵的同步操作,性能较低。
无法解决循环引用问题?(如A对象的成员引用了B对象,B对象的成员又引用了A对象,则引用计数器始终无法归0)。
注意:
引用计数法的循环引用的问题可通过 Recycler 算法解决!
2) 标记清除法
标记清除法使用可达性分析算法,从根节点标记那些不再被任何引用链所指向的对象,然后对未标记的对象进行清除。
优点:
解决了引用计数算法中的循环引用的问题,没有从根节点引用的对象都会被回收。
缺点:
在GC时,需要停止应用程序,对于交互性要求比较高的应用而言这个体验是非常差的。
效率较低,标记和清除两个动作都需要遍历所有的对象。
通过标记清除算法清理出来的内存,碎片化较为严重,因为被回收的对象可能存在于内存的各个角落。
扩展:
根节点对象包括:栈中引用的对象、方法区中静态属性和常量引用的对象、被同步锁持有的对象、JNI 引用的对象等。
3) 标记复制算法
标记复制算法将内存分为两个区域,通常是大小相等的两个半区(From区和To区)。每次只使用其中一个区域来分配对象,当这个区域用完时,将其中还存活的对象复制到另一个区域,然后清空当前区域,再将To区和From区的角色互换。
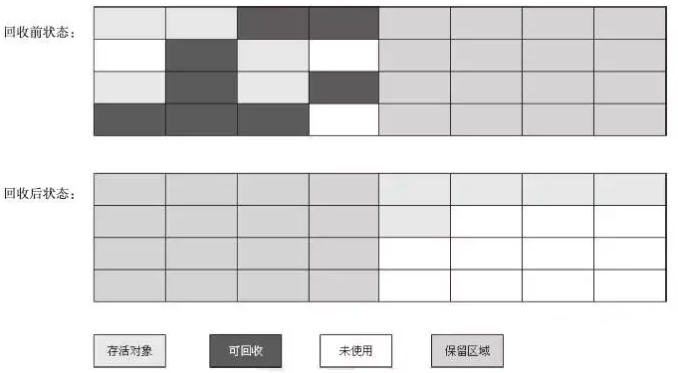
优点:
在存活对象较少的情况下,效率较高,适用于年轻代。
清理后无内存碎片。
缺点:
在存活对象较多的情况下,效率较低,不适用于老年代。
内存使用率较低,分配的2块内存空间,在同一个时刻,只能使用一半。
注意:
触发GC后,Eden区中所有存活的对象都会被复制到"To"区,而"From"区中存活的对象会根据年龄复制到"To"区或“老年代”。
4) 标记压缩算法
标记压缩法是标记清除法的改进,在清除阶段,将存活的对象压缩到内存的一端,然后直接清理掉端边界以外的内存空间。
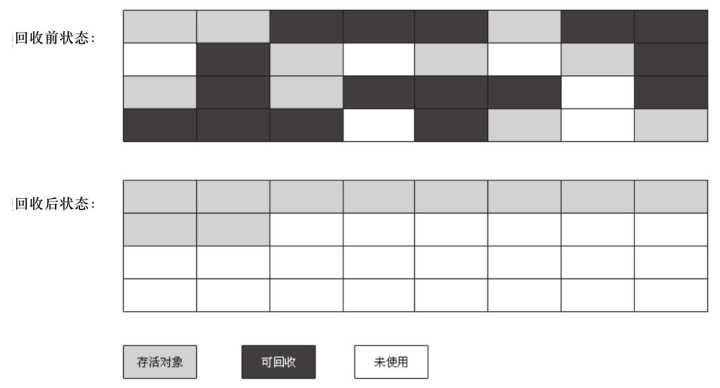
优点:
解决了标记清除算法的碎片化的问题。
避免了复制算法中内存利用率低的缺点。
缺点:
整理过程需要移动对象,可能会导致性能开销。
5) 分代垃圾回收
分代垃圾回收指根据内存区域的特点,选用不同的垃圾回收算法,如新生代存活对象少,适合复制算法,老年代垃圾回收频率较低,则适用于标记清除算法或标记压缩算法。
3. 垃圾收集器
1) 垃圾收集日志
为了方便查看GC的执行过程,可以通过下面一些参数打开GC日志。
161# 查看默认垃圾收集器2# JDK 8: Parallel Scavenge(新生代)+ Parallel Old(老年代)3# JDK 9 ~ JDK22: G14java -XX:+PrintCommandLineFlags -version5
6# GC日志相关参数7-XX:+PrintGC # 输出GC日志。8-XX:+PrintGCDetails # 输出GC日志明细。9-XX:+PrintGCTimeStamps # 输出GC的时间戳(以基准时间的形式)。10-XX:+PrintGCDateStamps # 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)。11-XX:+PrintHeapAtGC # 在进行GC的前后打印出堆的信息。12-Xloggc:../logs/gc.log # 日志文件的输出路径。13
14# 示例15java -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -Xmx256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:D:\gc.log TestGC16
如果选择文件形式输出,则还可以上传到GC Easy网站,生成GC报告。
2) 串行垃圾收集器
串行收集器(Serial GC)使用单线程进行垃圾回收,适用于单核处理器的机器和小内存应用。在垃圾回收过程中,会暂停用户线程(STW,Stop-The-World),直到垃圾回收完成。
Serial GC:新生代采用标记-复制算法,老年代采用标记-整理算法。
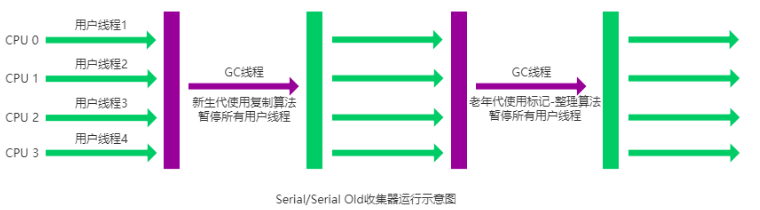
141# 使用串行垃圾收集器:Serial(年轻代+老年代)2java -XX:+UseSerialGC -XX:+PrintGCDetails -Xms16m -Xmx16m TestGC3
4# GC日志5[GC (Allocation Failure) [DefNew: 4416K->512K(4928K), 0.0046102 secs]4416K->1973K(15872K), 0.0046533 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]6[Full GC (Allocation Failure) [Tenured: 10944K->3107K(10944K), 0.0085637secs] 15871K->3107K(15872K), [Metaspace: 3496K->3496K(1056768K)],0.0085974 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]7
8# 日志说明9DefNew:表示使用的是串行垃圾收集器。104416K->512K(4928K):表示年轻代GC前占有4416K内存,GC后占有512K内存,总大小4928K。110.0046102 secs:表示GC所用的时间,单位为毫秒。124416K->1973K(15872K):表示GC前堆内存占有4416K,GC后占有1973K,总大小为15872K。13Full GC:表示内存空间全部进行GC。14
注意:
对于交互性较强的应用而言,这种垃圾收集器是不能够接受的,一般在JavaWeb应用中是不会采用该收集器的。
3) 并行垃圾收集器
并行收集器(Parallel GC) 也称为吞吐量优先收集器,虽然同样会暂停用户线程,但使用多个线程进行垃圾回收,可以缩短垃圾回收时间,提高吞吐量,适合对吞吐量要求较高的场景,例如服务器端应用。
ParNew GC:除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。
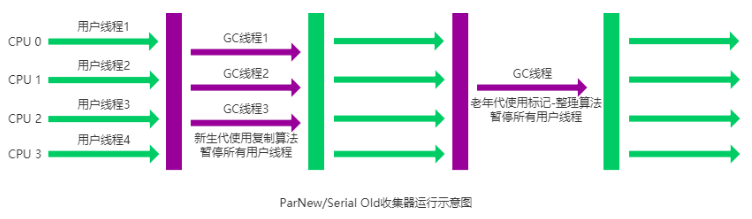
91# 使用并行垃圾收集器:ParNew(仅年轻代))2java -XX:+UseParNewGC -XX:+PrintGCDetails -Xms16m -Xmx16m TestGC3
4# GC日志5[GC (Allocation Failure) [ParNew: 4416K->512K(4928K), 0.0032106 secs]4416K->1988K(15872K), 0.0032697 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]6
7# 日志说明8ParNew:表示年轻代使用并行垃圾收集器9
Parallel GC:在ParNew的基础上新增了两个和系统吞吐量相关的参数,使得其使用起来更加的灵活和高效。
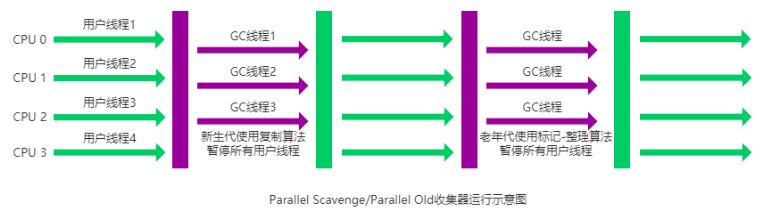
181# 使用并行垃圾收集器:Parallel(年轻代)、ParallelOldGC(老年代)2java -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails -Xms16m -Xmx16m -Xms16m -Xmx16m TestGC3
4# GC日志5[GC (Allocation Failure) [PSYoungGen: 4096K->480K(4608K)] 4096K->1840K(15872K), 0.0034307 secs] [Times: user=0.00 sys=0.00, real=0.00secs]6[Full GC (Ergonomics) [PSYoungGen: 505K->0K(4608K)] [ParOldGen: 10332K->10751K(11264K)] 10837K->10751K(15872K), [Metaspace: 3491K->3491K(1056768K)], 0.0793622 secs] [Times: user=0.13 sys=0.00, real=0.08secs]7
8# 常用参数9# 垃圾收集时的最大停顿时间,单位为毫秒10# 需要注意的是,ParallelGC为了达到设置的停顿时间,可能会调整堆大小或其他的参数,如果堆的大小设置的较小,就会导致GC工作变得很频繁,反而可能会影响到性能,该参数使用需谨慎。11-XX:MaxGCPauseMillis12# 设置垃圾回收时间占程序运行时间的百分比,公式为 1/(1+n)13# 它的值为 0~100之间的数字,默认值为99,也就是垃圾回收时间不能超过1%14-XX:GCTimeRatio15# 自适应GC模式,垃圾回收器将自动调整年轻代、老年代等参数,达到吞吐量、堆大小、停顿时间之间的平衡16# 一般用于,手动调整参数比较困难的场景,让收集器自动进行调整17-XX:UseAdaptiveSizePolicy18
注意:
JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old。
如果指定了-XX:+UseParallelGC 参数,则默认指定了-XX:+UseParallelOldGC,可以使用-XX:-UseParallelOldGC 来禁用该功能。
4) 并发垃圾收集器
并发收集器(Concurrent GC)的垃圾回收线程可以与用户线程并发执行,减少了垃圾回收过程中的停顿时间,适合响应速度要求较高的场景,例如交互式应用。
CMS收集器:在标记和清除阶段可以与用户线程并发执行,但仍然存在一些阶段需要暂停用户线程。
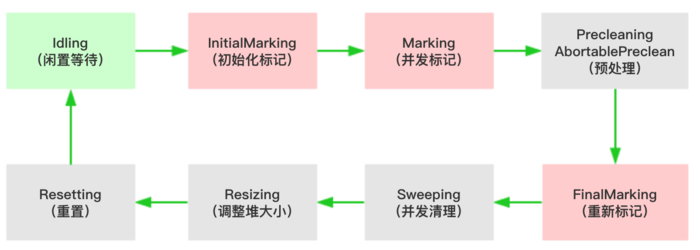
初始化标记 (CMS-initial-mark) ,标记根对象,会导致
STW;并发标记 (CMS-concurrent-mark),与用户线程同时运行,标记可达对象;
预清理( CMS-concurrent-preclean),与用户线程同时运行;
重新标记 (CMS-remark) ,修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,会导致
STW;并发清除 (CMS-concurrent-sweep),与用户线程同时运行,对未标记的区域做清扫;
调整堆大小,设置 CMS在清理之后进行内存压缩,目的是清理内存中的碎片;
并发重置状态等待下次 CMS的触发(CMS-concurrent-reset),与用户线程同时运行;
221# 设置 CMS 垃圾收集器 (仅老年代)2java -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -Xms16m -Xmx16m TestGC3
4# GC日志5[GC (Allocation Failure) [ParNew: 4926K->512K(4928K), 0.0041843 secs]9424K->6736K(15872K), 0.0042168 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]6# 第一步,初始标记7[GC (CMS Initial Mark) [1 CMS-initial-mark: 6224K(10944K)] 6824K(15872K),0.0004209 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]8# 第二步,并发标记9[CMS-concurrent-mark-start]10[CMS-concurrent-mark: 0.002/0.002 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]11# 第三步,预处理12[CMS-concurrent-preclean-start]13[CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]14# 第四步,重新标记15[GC (CMS Final Remark) [YG occupancy: 1657 K (4928 K)][Rescan (parallel), 0.0005811 secs][weak refs processing, 0.0000136 secs][class unloading,0.0003671 secs][scrub symbol table, 0.0006813 secs][scrub string table,0.0001216 secs][1 CMS-remark: 6224K(10944K)] 7881K(15872K), 0.0018324secs] [Times: user=0.00 sys=0.00, real=0.00 secs]16# 第五步,并发清理17[CMS-concurrent-sweep-start]18[CMS-concurrent-sweep: 0.004/0.004 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]19# 第六步,重置20[CMS-concurrent-reset-start]21[CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]22
5) G1收集器
G1 (Garbage-First) 是一款面向服务器的分区垃圾收集器,主要针对配备多颗处理器及大容量内存的机器,以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征。
541# 使用 G1 垃圾收集器2java -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails -Xmx256m TestGC3
4# 设置期望达到的最大GC停顿时间指标(JVM会尽力实现,但不保证达到),默认值是 200 毫秒。5-XX:MaxGCPauseMillis6
7# 设置的 G1 区域的大小(值是 2 的幂,范围是 1 MB 到 32 MB 之间)8# 目标是根据最小的 Java 堆大小划分出约 2048 个区域,默认是堆内存的 1/2000。9-XX:G1HeapRegionSize=n10
11# 设置 STW 工作线程数的值12# 将 n 的值设置为逻辑处理器的数量,最多为 8。13-XX:ParallelGCThreads=n14
15# 设置并行标记的线程数16# 将 n 设置为并行垃圾回收线程数 (ParallelGCThreads)的 1/4 左右17-XX:ConcGCThreads=n:18
19# 设置触发标记周期的 Java 堆占用率阈值20# 默认占用率是整个 Java 堆的 45%21-XX:InitiatingHeapOccupancyPercent=n:22
23# GC日志24[GC pause (G1 Evacuation Pause) (young), 0.0044882 secs]25 [Parallel Time: 3.7 ms, GC Workers: 3]26 [GC Worker Start (ms): Min: 14763.7, Avg: 14763.8, Max: 14763.8,Diff: 0.1]27 #扫描根节点28 [Ext Root Scanning (ms): Min: 0.2, Avg: 0.3, Max: 0.3, Diff: 0.1,Sum: 0.8]29 #更新RS区域所消耗的时间30 [Update RS (ms): Min: 1.8, Avg: 1.9, Max: 1.9, Diff: 0.2, Sum: 5.6]31 [Processed Buffers: Min: 1, Avg: 1.7, Max: 3, Diff: 2, Sum: 5]32 [Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]33 [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0,Sum: 0.0]34 #对象拷贝35 [Object Copy (ms): Min: 1.1, Avg: 1.2, Max: 1.3, Diff: 0.2, Sum:3.6]36 [Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum:0.2]37 [Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum:3]38 [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0,Sum: 0.0]39 [GC Worker Total (ms): Min: 3.4, Avg: 3.4, Max: 3.5, Diff: 0.1,Sum: 10.3]40 [GC Worker End (ms): Min: 14767.2, Avg: 14767.2, Max: 14767.3,Diff: 0.1]41 [Code Root Fixup: 0.0 ms]42 [Code Root Purge: 0.0 ms]43 [Clear CT: 0.0 ms] #清空CardTable44 [Other: 0.7 ms]45 [Choose CSet: 0.0 ms] #选取CSet46 [Ref Proc: 0.5 ms] #弱引用、软引用的处理耗时47 [Ref Enq: 0.0 ms] #弱引用、软引用的入队耗时48 [Redirty Cards: 0.0 ms]49 [Humongous Register: 0.0 ms] #大对象区域注册耗时50 [Humongous Reclaim: 0.0 ms] #大对象区域回收耗时51 [Free CSet: 0.0 ms]52 [Eden: 7168.0K(7168.0K)->0.0B(13.0M) Survivors: 2048.0K->2048.0K Heap:55.5M(192.0M)->48.5M(192.0M)] #年轻代的大小统计53 [Times: user=0.00 sys=0.00, real=0.00 secs]54
扩展:
G1收集器在 JDK1.7 中正式使用,在 JDK9 中修改为默认垃圾收集器,以替代 CMS 收集器。
G1 收集器根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)。
避免使用 -Xmn 选项或 -XX:NewRatio 等其他相关选项显式设置年轻代大小,固定年轻代的大小会覆盖暂停时间目标。
G1垃圾收集器相对比其他收集器而言,最大的区别在于它取消了年轻代、老年代的物理划分,取而代之的是将堆划分为若干个区域(Region),这些区域中包含了有逻辑上的年轻代、老年代区域。
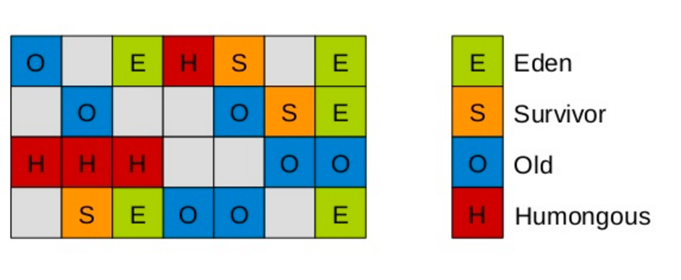
开发人员只需要简单的三步即可完成G1垃圾收集器的调优:
第一步,开启G1垃圾收集器
第二步,设置堆的最大内存
第三步,设置最大的停顿时间
6) ZGC 垃圾收集器
Z Garbage Collector是一种低延迟的垃圾收集器,支持更大的堆内存(可达数TB)。它通过使用染色指针等技术,在垃圾回收过程中几乎不会暂停用户线程,从而实现极低的停顿时间,适合对延迟要求极高的场景,例如金融交易系统等。
51# 使用ZGC2java -XX:+UseZGC className3
4# 使用分代ZGC5java -XX:+UseZGC -XX:+ZGenerational className
4. 面试扩展
1) GC类型有哪些?
HotSpot VM 的GC分类主要有如下两种:
部分收集 (Partial GC):新生代收集(Minor GC / Young GC)、老年代收集(Major GC / Old GC)、混合收集(Mixed GC)。
整堆收集 (Full GC):收集整个 Java 堆和方法区。
2) 对象可回收时一定会被回收吗?
不一定。垃圾回收器会根据内存压力、垃圾回收策略和对象的引用类型等因素来决定是否回收对象。
3) 对象的引用类型有哪些?
| 引用类型 | 特点 | 使用场景 |
|---|---|---|
| 强引用 | 对象不会被垃圾回收器回收,除非显式设置为null或超出作用域 | 普通对象引用 |
| 软引用 | 对象在内存不足时可能会被回收,但在内存足够时仍然可以保留 | 内存敏感的高速缓存 |
| 弱引用 | 对象在下一次垃圾回收时一定会被回收 | 类似缓存的功能,但比软引用更激进 |
| 虚引用 | 对象和没有引用一样,必须和引用队列(ReferenceQueue)联合使用 | 跟踪对象被垃圾回收的活动 |
121// 强引用2Object obj = new Object();3
4// 软引用5SoftReference<Object> softRef = new SoftReference<>(obj);6
7// 弱引用8WeakReference<Object> weakRef = new WeakReference<>(obj);9
10// 虚引用11ReferenceQueue<Object> queue = new ReferenceQueue<>();12PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue);
第05章_JDK新特性
第一节 JDK11新特性
1. 模块化
引入了模块化系统(Java Platform Module System,JPMS),通过 module 关键字来定义模块,并提供了更好的封装和可重用性。
2. JShell
引入了交互式的 Java 编程工具JShell,可以在命令行上直接编写和执行Java 代码片段,用于快速开发和学习。
91D:\Application\Java\jdk-11.0.6\bin>jshell2| 欢迎使用 JShell -- 版本 11.0.63| 要大致了解该版本, 请键入: /help intro4
5jshell> 1+16$1 ==> 27
8jshell>9
3. 接口私有实例方法
接口中可以定义私有的实例方法,用private关键字修饰,用于在接口内部共享代码。
131public interface TestInterFace {2 // 接口私有实例方法3 private void common() {4 System.out.println("接口私有实例方法");5 }6
7 // 默认方法8 default void defaultBiz() {9 // 调用接口私有实例方法10 common();11 }12}13
4. 改进try-with-resources
try-with-resources 语句可以使用资源的最终变量(final或等效于final的变量),不需要显式声明为final。
301// JDK8 方式一2public static void useResource() throws Exception {3 // 创建资源4 try (AutoCloseable r = new FileInputStream("hello")) {5 // 使用资源6 }7}8 9// JDK8 方式二10public static void useResource() throws Exception {11 final Resource resource1 = new Resource("resource1");12 Resource resource2 = new Resource("resource2");13 14 // 引入方式15 try (Resource r1 = resource1; Resource r2 = resource2) {16 // 使用资源17 }18}19
20// JDK11 21public static void useResource() throws Exception {22 final Resource resource1 = new Resource("resource1");23 Resource resource2 = new Resource("resource2");24
25 // 引入方式26 try (resource1; resource2) {27 // 使用资源28 }29}30
5. 改进<>操作符
支持在匿名内部类的实例化中使用钻石操作符<>,可以省略泛型类型的重复声明。
101// JDK82userMapper.selectByMap(new HashMap<String, Object>() {{3 put("age", 23);4}});5 6// JDK11 7userMapper.selectByMap(new HashMap<>() {{8 put("age", 23);9}});10
6. 增强String类
String类新增了一些方法:
101// 检查是否为空白字符串2boolean blank = " ".isBlank();3
4// 字符串拆分多行5Stream<String> lines = "a\nb\nc".lines();6
7// 移除字符串前后空格8String stripped = " Java ".strip(); // "Java"9String stripped = " Java ".strip(); // "Java"10String strippedLeading = " Java".stripLeading(); // "Java"
7. 增强List/Set/Map接口
List、Set和Map接口中新增了一些静态工厂方法,用于创建不可变集合的实例。
11List<Integer> integerList = List.of(1, 2, 3);
8. 推断局部变量类型
引入了var关键字,支持在局部变量声明时进行类型推断。
41var varDemo = new Application();2System.out.println("varDemo = " + varDemo); // org.example.test.TestQuery@2d2374603System.out.println("varDemoClass = " + varDemo.getClass()); // lass org.example.test.TestQuery4
9. 增强Stream API
Stream API引入了一些新的方法,如takeWhile()和dropWhile(),用于在满足特定条件之前或之后对流进行截断。
11
10. 增强Optional类
Optional类引入了一些新的方法,如stream()和ifPresentOrElse(),提供更多的操作和处理 Optional 对象的方式。
11
11. 增强CompletableFuture类
CompletableFuture类增加了一些新的方法,如orTimeout()和completeOnTimeout(),用于处理异步任务的超时情况。
11
12. 引入HTTP/2客户端
引入了新的HTTP/2标准的客户端API,以提供更高效和性能更好的HTTP通信。
13. 增强启动器
允许直接运行单个源代码文件,而不需要将其编译为类文件。例如:java HelloWorld.java。
14. ZGC垃圾收集器
一个实验性的垃圾收集器,目标是实现低延迟和高吞吐量。
第二节 JDK17新特性
1. 增强switch语句
支持匹配多个值、范围值、不同类型的值,以及用作表达式等。
301// 匹配多个值,并用作表达式2String memo = switch (week) {3 case 1 -> "星期日,休息";4 case 2,3,4,5,6 -> "工作日";5 case 7 -> "星期六,休息";6 default -> throw new RuntimeException("无效的日期");7};8
9// 范围匹配10int number = ...11switch (number) {12 case 1, 2, 3 -> System.out.println("小数值");13 case int i when i > 3 && i < 10 -> System.out.println("介于4到9之间");14 case int i when i >= 10 -> System.out.println("10或更大");15 default -> System.out.println("其他值");16}17
18// 匹配不同类型19Object obj = ...20switch (obj) {21 case String s -> 22 System.out.println("它是字符串: " + s);23 case Integer i -> 24 System.out.println("它是整数: " + i);25 case Double d -> 26 System.out.println("它是双精度浮点数: " + d);27 default -> 28 System.out.println("未知类型");29}30
注意:
特别的,在JDK17中,如果case后面只有一条语句,可以省略break。
2. 增强String类
String类新增一些方法:
61// 将给定的lambda表达式应用于字符串2String transformed = "Java".transform(s -> s + " is cool"); // "Java is cool"3
4// 在字符串的每一行前面添加指定数量的空格5String indented = "Java\nEvolution".indent(4); // " Java\n Evolution"6
3. 文本块
使用三个双引号 """ 括起来的文本块可以更自然的定义多行字符串。
161// 定义多行字符串2String json = """3{4 "name": "John Doe",5 "age": 30,6 "isEmployed": true7}8""";9
10// 格式化多行字符串11String name = "Kimi";12int age = 30;13String greeting = """14Hello, my name is %s and I am %d years old.15""".formatted(name, age);16
4. 密封类
密封类提供了一种新的方式来控制类的继承,通过使用sealed关键字,我们可以定义一个类只能有哪些特定的子类,这有助于我们创建更加清晰和可维护的代码
131// 定义一个密封类Shape,它只能被Circle和Rectangle类继承2sealed class Shape permits Circle, Rectangle {3 String name;4
5 Shape(String name) {6 this.name = name;7 }8
9 void draw() {10 System.out.println("Drawing " + name);11 }12}13
5. 改进instanceof
在检查对象类型的同时进行类型转换,并且可以直接在条件表达式的结果中使用这个转换后的对象。
71// 在检查后进行强转2if (obj instanceof String s) {3 System.out.println(s.length());4} else {5 System.out.println("不是String类型");6}7
6. 记录类
记录类是一种特殊的不可变类,一般用作数据传输对象,也被称作“数据类”。
141// 纪录类2public record TestRecord(String name,int age,long tel) {3}4
5// 使用6public class Main {7 public static void main(String[] args) {8 TestRecord testRecord1=new TestRecord("小明",9,1335061187);9 TestRecord testRecord2=new TestRecord("小明",9,1335061187);10 System.out.println(testRecord1.equals(testRecord2)); // true11 System.out.println(testRecord1.hashCode()+" "+testRecord2.hashCode()); // 2062253049 206225304912 }13}14
第三节 JDK21新特性
1. 虚拟线程
1) 虚拟线程简介
虚拟线程(Virtual Thread)是由 JDK 实现的轻量级线程(Lightweight Process,LWP),和平台线程(操作系统线程)是多对一的关系。
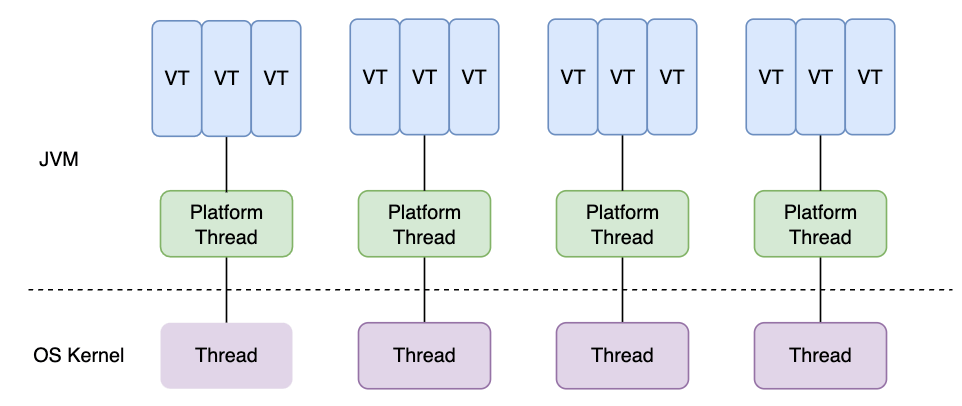
优点:使用较少的资源,大大的提高了并发量,且简化了异步编程。
缺点:不适用计算密集型任务;兼容性稍差(不兼容一些依赖平台线程特性的第三方库。
2) 创建虚拟线程
271// 创建虚拟线程2Thread.ofVirtual().name("virtual thread").start(() -> {3 System.out.println("Hello, virtual thread!");4});5
6// 虚拟线程池7try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {8 IntStream.range(1, 10_000).forEach(i -> {9 executor.submit(() -> {10 Thread.sleep(Duration.ofSeconds(0));11 return i;12 });13 });14}15
16// 虚拟线程工厂17ThreadFactory factory = Thread.ofVirtual().factory();18Thread thread = factory.newThread(() -> {19 System.out.println("Hello, virtual thread!");20});21thread.start();22
23// 使用启动虚拟线程运行任务24Thread.startVirtualThread(() -> {25 System.out.println("Hello, virtual thread!");26});27
2. 分代ZGC
扩展了原有的Z Garbage Collector(ZGC),为年轻对象和老对象维护单独的代,从而提高应用程序的性能。
3. 序列集合
引入了一套新的接口来标识各类集合是否有序。
311// 有序Collection集合接口(被List和Deque继承)2interface SequencedCollection<E> extends Collection<E> {3 SequencedCollection<E> reversed();4 void addFirst(E);5 void addLast(E);6 E getFirst();7 E getLast();8 E removeFirst();9 E removeLast();10}11
12// 有序Set接口(被SortedSet和LinkedHashSet继承)13interface SequencedSet<E> extends Set<E>, SequencedCollection<E> {14 SequencedSet<E> reversed(); 15}16
17// 有序Map接口(被SortedMap和LinkedHashMap继承)18interface SequencedMap<K,V> extends Map<K,V> {19 SequencedMap<K,V> reversed();20 SequencedSet<K> sequencedKeySet();21 SequencedCollection<V> sequencedValues();22 SequencedSet<Entry<K,V>> sequencedEntrySet();23 V putFirst(K, V);24 V putLast(K, V);25 26 Entry<K, V> firstEntry();27 Entry<K, V> lastEntry();28 Entry<K, V> pollFirstEntry();29 Entry<K, V> pollLastEntry();30}31
4. 记录模式
支持在 switch 表达式和 if 语句中使用简化的语法来匹配和解构记录类型。
31if (obj instanceof Point(int x, int y)) {2 System.out.println(x + y);3}
第06章_其它补充
第一节 代码组织机制
1. 包
1) 包的概念
在Java中,使用包来组织多个源文件,以及避免命名冲突等。包类似于文件夹的概念,包名以.号分隔表示层次结构,如常用的String类,位于java.lang包下。
注意:
Java API中所有的类和接口都位于包
java或javax下,java是标准包,javax是扩展包。
2) 声明类所在的包
默认情况下,类位于默认包下,但使用默认包是不建议的,定义类的时候,应该先使用关键字package,声明其包名,如下所示:
81// 声明包名,应该位于源代码的最前面,前面不能有注释外的其他语句2package com.huangyuanxin;3
4public class Hello {5 public static void main(String[] args){6 System.out.println("hello");7 }8}包名和文件目录结构必须匹配,否则会提示编译错误。如源文件的根目录为D:\src,则上面的Hello类对应的全路径就应该是D:\src\com\huangyuanxin\Hello.java。
3) 通过包使用类
同一个包下的类可以直接引用,不同包下的类需要进行导包或通过全限定类名进行引用。
301package com.huangyuanxin;2
3// 1.1 提前导包4// import java.util.Arrays;5
6// 2.1 静态方法支持静态导入7// import static java.util.Arrays.sort;8
9// 3.1 同一个包支持批量导入10// import java.util.*; // 批量导入java.util包下的类(但不包括其子包下的)11
12public class Hello {13 public static void main(String[] args){14 int[] arr = new int[]{1,4,2,3};15 16 // 1.2 直接使用类名引用17 // Arrays.sort(arr); 18 19 // 2.2 直接使用静态导入的静态方法20 // sort(arr); 21 22 // 3.2 直接使用类名引用,自动匹配全限定类名23 // Arrays.sort(arr); 24 25 // 4. 通过全限定类名引用26 java.util.Arrays.sort(arr); 27 28 System.out.println(java.util.Arrays.toString(arr)); // [1, 2, 3, 4]29 }30}注意:
java.lang包下的类可以直接使用,无需导包或使用全限定类名,如String、System等。在一个类中,对其他类的引用必须是唯一确定的,不能有重名的类。
如果确实需要在同一个类中引用多个重名类,则可以通过import导入其中最常用的一个,其它的通过全限定类名使用。
4) 关于包范围可见性
对于类、变量和方法,都支持设置一个可见性修饰符(public/private/protected)。这个修饰符可以省略(default),表示在包可见性,即同一个包内的其他类可以访问,但其他包内的类不可以访问。
注意:
在Java中,无特殊说明时,同一个包一般都不包括其子包。
protected修饰符的可见性包括包可见性,也就是说,不仅子类可以访问,同一个包内的其它类也可以访问,即使不是子类。
5) 生成jar包
为方便使用第三方代码或将自己的代码给其他人使用,需要进行打包操作,即将编译后的多个字节码文件等打包为一个压缩文件。
在Java中,打包命令如下:jar -cvf <包名>.jar <最上层目录名>,打包后的文件后缀为.jar,称之为Jar包。
如上述Hello类的打包,先切换到源码根目录D:\src,再使用 jar -cvf hello.jar com 命令进行打包,将会在根目录下生成一个hello.jar包。
6) 程序的编译与连接
Java类库和第三方类库等都是通过jar包形式提供的,只要将jar包加入到类路径(classpath)中即可进行使用。那类路径又是什么呢?
从Java源代码到运行的程序,有编译和运行两个步骤,编译指将源代码文件变成一种后缀为.class的字节码文件,运行是指根据引用到的类加载相应的字节码并执行。编译和运行时都需要指定一个类路径,在编译时用于确定所引用类的全限定类名(需结合import语句),在运行时,根据已确定的全限定类名寻找并加载类。
类路径可以有多个(以;或:分隔),对于直接的class文件,类路径就是class文件的源码根目录;对于jar包,类路径是jar包的完整名称(包括路径和jar包名),Jar包会在内存中进行解压,然后再寻找和加载对应的类。
2. 模块(JDK9+)
第二节 类加载机制
1. 类文件结构
1) 概览
类文件结构可通过javap -c -v HelloWorld.class命令查看,其组成如下:
2) 分段说明
魔数(Magic Number):类文件的前4个字节,值为
0xCAFEBABE,用于标识这是一个Java类文件。版本信息(Version):用于标识类文件的版本,包括次版本号(Minor Version)和主版本号(Major Version),各占2个字节。
Java 8:主版本号为52,次版本号为0。
Java 11:主版本号为55,次版本号为0。
Java 17:主版本号为61,次版本号为0。
常量池(Constant Pool):存储类文件中用到的各种常量信息,包括字符串常量、类名、字段名、方法名等。
常量池计数器(Constant Pool Count):2个字节,表示常量池的大小(实际常量数量 + 1)。
常量池表(Constant Pool Table):具体的常量信息,每个常量项的结构取决于其类型(如UTF-8字符串、类名、字段引用等)。
访问标志(Access Flags):用于标识类或接口的访问权限和特性。
ACC_PUBLIC:0x0001,表示类是public的。
ACC_FINAL:0x0010,表示类是final的。
ACC_INTERFACE:0x0200,表示这是一个接口。
ACC_ABSTRACT:0x0400,表示类是抽象的。
类索引(This Class):指向常量池中表示当前类的类名的索引。
父类索引(Super Class):指向常量池中表示父类的类名的索引。
接口索引表(Interfaces):存储当前类实现的接口信息。
接口计数器(Interfaces Count):2个字节,表示实现的接口数量。
接口索引表(Interfaces Table):每个接口的索引指向常量池中对应的接口名。
字段表(Fields):存储类的字段信息。
字段计数器(Fields Count):2个字节,表示字段的数量。
字段信息表(Fields Table):每个字段包含字段的访问标志、名称索引、描述符索引和属性表等信息。
方法表(Methods):存储类的方法信息。
方法计数器(Methods Count):2个字节,表示方法的数量。
方法信息表(Methods Table):每个方法包含方法的访问标志、名称索引、描述符索引、属性表等信息。
属性表(Attributes):存储类文件的附加信息,如源文件名、调试信息等。
属性计数器(Attributes Count):2个字节,表示属性的数量。
属性信息表(Attributes Table):每个属性包含属性名索引、属性长度和属性值等信息。
3) 字节码示例
641C:\Users\Administrator\Desktop>javap -c -v HelloWorld.class2Classfile /C:/Users/Administrator/Desktop/HelloWorld.class3 Last modified 2025-3-27; size 427 bytes4 MD5 checksum f9ee02811f7c42671c5e5e3fa49bd13b5 Compiled from "HelloWorld.java"6public class HelloWorld7 minor version: 08 major version: 529 flags: ACC_PUBLIC, ACC_SUPER10Constant pool:11 #1 = Methodref #6.#15 // java/lang/Object."<init>":()V12 #2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;13 #3 = String #18 // Hello, World!14 #4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V15 #5 = Class #21 // HelloWorld16 #6 = Class #22 // java/lang/Object17 #7 = Utf8 <init>18 #8 = Utf8 ()V19 #9 = Utf8 Code20 #10 = Utf8 LineNumberTable21 #11 = Utf8 main22 #12 = Utf8 ([Ljava/lang/String;)V23 #13 = Utf8 SourceFile24 #14 = Utf8 HelloWorld.java25 #15 = NameAndType #7:#8 // "<init>":()V26 #16 = Class #23 // java/lang/System27 #17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;28 #18 = Utf8 Hello, World!29 #19 = Class #26 // java/io/PrintStream30 #20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V31 #21 = Utf8 HelloWorld32 #22 = Utf8 java/lang/Object33 #23 = Utf8 java/lang/System34 #24 = Utf8 out35 #25 = Utf8 Ljava/io/PrintStream;36 #26 = Utf8 java/io/PrintStream37 #27 = Utf8 println38 #28 = Utf8 (Ljava/lang/String;)V39{40 public HelloWorld();41 descriptor: ()V42 flags: ACC_PUBLIC43 Code:44 stack=1, locals=1, args_size=145 0: aload_046 1: invokespecial #1 // Method java/lang/Object."<init>":()V47 4: return48 LineNumberTable:49 line 1: 050
51 public static void main(java.lang.String[]);52 descriptor: ([Ljava/lang/String;)V53 flags: ACC_PUBLIC, ACC_STATIC54 Code:55 stack=2, locals=1, args_size=156 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;57 3: ldc #3 // String Hello, World!58 5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V59 8: return60 LineNumberTable:61 line 3: 062 line 4: 863}64SourceFile: "HelloWorld.java"
2. 类加载过程
类加载过程指将类的字节码文件(.class文件)加载到Java虚拟机(JVM)中,并将其转换为java.lang.Class对象的过程。
加载阶段:通过全类名从文件、网络、数据库等处查找字节码文件,并解析为方法区的
java.lang.Class对象。连接阶段:
验证:确保加载的类信息符合JVM规范,保证类的正确性和安全性。
准备:为类的静态变量分配内存,并设置默认初始值。
解析:将类、接口、字段和方法的符号引用(如全类名、方法描述符等)转换为直接引用(内存地址)。
初始化阶段:执行类的初始化代码,包括静态变量的赋值和静态初始化块中的代码。
扩展:
类卸载指类对象被垃圾回收的过程,除了不可达之外,还需保证该类的所有实例都被回收且其类加载器也被回收。
3. 类加载器
1) 基本概念
类加载器(ClassLoader)用于将字节码文件加载到 JVM 内存,创建Class对象,作用于类加载过程的加载阶段。
JVM 中内置了三个重要的 ClassLoader:
BootstrapClassLoader(启动类加载器):最顶层的加载类,没有父级,由 C++ 实现,通常表示为 null。
加载 JDK 内部的核心类库,包括:
%JAVA_HOME%/lib目录下的rt.jar、resources.jar、charsets.jar 等 。加载被 -Xbootclasspath 参数指定路径下的所有类(可直接获取Unsafe实例)。
ExtClassLoader(扩展类加载器):
加载
%JRE_HOME%/lib/ext目录下的 jar 包。加载被 java.ext.dirs 系统变量指定路径下的所有类。
AppClassLoader(应用程序类加载器):面向用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
131// 获取当前类加载器2ClassLoader classLoader = MyClass.class.getClassLoader();3
4// 获取当前线程的上下文类加载器5ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader(); // 默认为系统类加载器6
7// 获取系统类加载器8ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader(); // 应用类加载器(静态)9ClassLoader extClassLoader = systemClassLoader.getParent(); // 扩展类加载器10ClassLoader classLoader = String.class.getClassLoader(); // 启动类加载器11
12// 使用类加载器加载类13Class<?> cls = classLoader.loadClass("java.util.ArrayList");注意:
在JDK9中,扩展类加载器被修改为平台类加载器,除
java.base.*外的类几乎都是由它加载。每个 Java 类都有一个引用指向加载它的
ClassLoader,但数组除外。两个类是否相同,不仅要保证它们类名相同,还要保证类加载器也相同。
2) 双亲委派机制
双亲委派机制指优先使用父加载器加载类,当父加载器无法加载时,才会使用当前类加载器进行加载,这样可以避免类的重复加载和防止核心 API 被篡改。
361public abstract class ClassLoader {2 // 加载类(外部调用)3 public Class<?> loadClass(String name) throws ClassNotFoundException {4 return loadClass(name, false);5 }6 7 // 加载类(内部实现)8 protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {9 synchronized (getClassLoadingLock(name)) {10 // 1. 检查类是否已经被加载11 Class c = findLoadedClass(name);12 if (c == null) {13 // 2. 没有被加载,则加载类【双亲委派机制】14 try {15 if (parent != null) {16 c = parent.loadClass(name, false); // 优先使用父加载器17 } else {18 c = findBootstrapClassOrNull(name); // 或BootstrapClassLoader加载19 }20 } catch (ClassNotFoundException e) { 21 }22 23 // 3. 如果父类无法加载,才使用当前类加载器加载24 if (c == null) {25 c = findClass(name); // 模板方法,由实现类重写26 }27 }28 29 // 始终为false30 if (resolve) {31 resolveClass(c); // 链接,执行static语句块32 }33 return c;34 }35 }36}注意:
双亲委派机制中,所有的类加载最终都会传递给
BootstrapClassLoader优先进行尝试。
3) 自定义类加载器
自定义类加载器可以实现灵活加载、热部署、应用的模块化和相互隔离等功能。
211// 继承ClassLoader实现自定义类加载器2public class MyClassLoader extends ClassLoader {3 private static final String BASE_DIR = "data/c87/";4
5 public MyClassLoader() {6 super(ClassLoader.getSystemClassLoader().getParent()); // 指定父加载器,默认为系统类加载器7 }8
9 // 从不同来源查找类10 11 protected Class<?> findClass(String name) throws ClassNotFoundException {12 String fileName = name.replaceAll("\\.", "/");13 fileName = BASE_DIR + fileName + ".class";14 try {15 byte[] bytes = BinaryFileUtils.readFileToByteArray(fileName); // 读取类数据16 return defineClass(name, bytes, 0, bytes.length); // 生成class对象17 } catch (IOException ex) {18 throw new ClassNotFoundException("failed to load class " + name, ex);19 }20 }21}注意:
自定义类加载器可以实现 loadClass 来打破双亲委派机制,或实现 findClass 遵循双亲委派机制。
第三节 虚拟机对象
1. 创建对象过程
类加载检查:在执行
new指令时,首先从常量池查询这个类的符号引用,检查类是否被加载及初始化。分配内存:根据 “Java 堆是否规整” 选择指针碰撞(ParNew收集器等)或空闲列表(CMS收集器等)方式分配内存。
内存初始化:将分配到的内存空间都初始化为零值(不包括对象头)。
设置对象头:设置对象的类型指针和标记字段,标记字段包括:哈希码、GC分代年龄、锁信息等。
执行 init 方法:调用构造方法初始化对象,这样一个真正可用的对象才算完全产生出来。
2. 对象的内存布局
对象在内存中的布局可以分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
3. 对象的访问定位
Java 程序通过栈上的 reference 数据来操作堆上的具体对象,主流的访问方式有:句柄、直接指针。
句柄:通过堆上的句柄池来间接找到对象的指针地址。
直接指针:直接在 reference 中存储对象的指针地址,速度快,HotSpot 虚拟机使用该方式。
第三节 动态代理
1. 动态代理简介
动态代理是一种强大的功能,它可以在运行时动态的创建一个类,实现一个或多个接口,可以在不修改原有类的基础上动态为该类的对象添加方法和修改行为,这些特性使得它广泛应用于各种框架和库中,比如Spring、Hibernate、MyBatis、Guice等。
2. 静态代理
学习动态代理前,我们先了解下静态代理。静态代理在编码阶段显示的写出代理类代码,通过其对象来操作被代理对象。
401public class SimpleStaticProxyDemo {2
3 // 共同接口4 static interface IService {5 public void sayHello();6 }7
8 // 业务类9 static class RealService implements IService {10
11 12 public void sayHello() {13 System.out.println("hello");14 }15 }16
17 // 代理类18 static class TraceProxy implements IService {19 private IService realService;20
21 public TraceProxy(IService realService) {22 this.realService = realService;23 }24
25 26 public void sayHello() {27 System.out.println("entering sayHello");28 this.realService.sayHello();29 System.out.println("leaving sayHello");30 }31 }32
33 // 测试34 public static void main(String[] args) {35 IService realService = new RealService();36 IService proxyService = new TraceProxy(realService); // 静态代理37 proxyService.sayHello(); // entering sayHello hello leaving sayHello38 }39}40
注意:区分代理模式和装饰器模式
它们的背后都有一个实际对象,都是通过组合的方式指向该对象。
装饰器的特点在于增强,不修改原有对象的行为而添加额外功能,是继承的替代,如JDK的IO流。
代理模式的特点在于隔离,对原有对象进行控制,不暴露给外部对象,如Spring的事务管理。
3. 动态代理-基于接口
了解了静态代理后,我们再来看动态代理。动态代理主要有两种实现方式,一种是JDK提供的基于接口的代理,另外一种是第三方库cglib提供的基于子类的代理。
1) 基本使用
在静态代理中,代理类是直接定义在代码中的,而在动态代理中,代理类是动态生成的,JDK提供的生成方法如下:
111/**2 * JDK动态代理3 *4 * @param loader 类加载器,一般使用和被代理对象相同的类加载器5 * @param interfaces 代理类要实现的接口列表,是一个数组,元素的类型只能是接口,不能是普通的类6 * @param invocationHandler 它是一个接口,定义了一个方法invoke,对代理接口所有方法的调用都会转发给该方法7 * @return 返回值类型为Object,可以强制转换为interfaces数组中的某个接口类型8 * 注意:JDK动态代理生成的代理对象不能强制转换为某个类类型,比如RealService,即使它实际代理的对象类型就是RealService9 */10public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler invocationHandler)11
下面是一个简单示例:
591import java.lang.reflect.InvocationHandler;2import java.lang.reflect.Method;3import java.lang.reflect.Proxy;4
5public class SimpleJDKDynamicProxyDemo {6
7 // 共同接口8 static interface IService {9 public void sayHello();10 }11
12 // 业务对象13 static class RealService implements IService {14
15 16 public void sayHello() {17 System.out.println("hello");18 }19 }20
21 // InvocationHandler22 static class SimpleInvocationHandler implements InvocationHandler {23 private Object realObj;24
25 public SimpleInvocationHandler(Object realObj) {26 this.realObj = realObj;27 }28
29 /**30 * 代理逻辑31 *32 * @param proxy 代理对象本身,需要注意,它不是被代理的对象,这个参数一般用处不大33 * @param method 当前被调用的方法34 * @param args 方法的参数35 * @return36 * @throws Throwable37 * 注意:method.invoke时只能传递实际对象realObj作为参数,达到调用实际对象对应方法的目的。38 * 而不能将proxy作为参数传递给method.invoke,否则又将被代理,这样会出现死循环。39 */40 41 public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {42 System.out.println("entering " + method.getName());43 Object result = method.invoke(realObj, args); // 第一个参数必须为realObj,而不能为proxy44 System.out.println("leaving " + method.getName());45 return result;46 }47 }48
49 public static void main(String[] args) {50 IService realService = new RealService();51
52 // JDK动态代理53 IService proxyService = (IService) Proxy.newProxyInstance(realService.getClass().getClassLoader(),54 new Class<?>[]{IService.class}, new SimpleInvocationHandler(realService));55
56 proxyService.sayHello(); // entering sayHello hello leaving sayHello57 }58}59
2) 实现原理
上面例子中创建proxyService的代码可以用如下代码代替:
101// 1. 通过Proxy.getProxyClass创建代理类定义(类定义会被缓存)2Class<?> proxyCls = Proxy.getProxyClass(realService.getClass().getClassLoader(), new Class<?>[] { IService.class });3
4// 2. 获取代理类的构造方法,构造方法有一个InvocationHandler类型的参数5Constructor<?> ctor = proxyCls.getConstructor(new Class<?>[] { InvocationHandler.class });6
7// 3. 创建InvocationHandler对象,创建代理类对象8InvocationHandler handler = new SimpleInvocationHandler(realService);9IService proxyService = (IService) ctor.newInstance(handler);10
其中Proxy.getProxyClass会动态生成一个类,类名以$Proxy开头,后跟一个数字。上面例子生成的代理类如下:
391// $Proxy0继承Proxy,并实现传入的SimpleJDKDynamicProxyDemo.IService接口2// 主要功能:将实现的业务方法sayHello和Object中的hashCode, equals、toString方法转发给InvocationHandler的invoke方法。3final class $Proxy0 extends Proxy implements SimpleJDKDynamicProxyDemo.IService {4 private static Method m0;5 private static Method m1;6 private static Method m2;7 private static Method m3;8
9 // 构造方法,接收一个InvocationHandler类型的参数10 public $Proxy0(InvocationHandler paramInvocationHandler) {11 super(paramInvocationHandler); // 保存在Proxy中定义的h变量中12 }13
14 public final int hashCode() {15 return ((Integer) this.h.invoke(this, m0, null)).intValue(); // 转发16 }17 18 public final boolean equals(Object paramObject) {19 return ((Boolean) this.h.invoke(this, m1,20 new Object[] { paramObject })).booleanValue(); // 转发21 }22
23 public final String toString() {24 return (String) this.h.invoke(this, m2, null); // 转发25 }26
27 // 实现业务方法28 public final void sayHello() {29 this.h.invoke(this, m3, null);30 }31
32 static {33 m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);34 m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[] { Class.forName("java.lang.Object") });35 m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);36 m3 = Class.forName("laoma.demo.proxy.SimpleJDKDynamicProxyDemo$IService").getMethod("sayHello",new Class[0]); 37 }38}39
Proxy$0类的代码与被代理对象毫无关系,与InvocationHandler的具体实现也毫无关系,它只会实现参数传入的所有接口并重写接口方法,重写的方法和Object中的hashcode、equals、toString方法都将直接转发到InvocationHandler的invoke方法,后续在invoke方法中针对不同业务方法进行不同处理,这由传入的InvocationHandler实现类决定。
扩展:我们是怎么知道$Proxy0的定义的呢? 对于Oracle的JVM,可以配置java的一个属性:
11java -Dsun.misc.ProxyGenerator.saveGeneratedFiles=true com.huangyuanxin.notes.javabase.proxy.SimpleJDKDynamicProxyDemo以上命令会把动态生成的代理类$Proxy0保存到文件$Proxy0.class中,通过一些反编译器工具比如JD-GUI就可以得到源码。
3) 动态代理的优点
使用动态代理,可以编写通用的代理逻辑,用于各种类型的被代理对象,而不需要为每个被代理的类型都创建一个静态代理类。
221public class GeneralProxyDemo {2 3 // 创建代理(通用方法)4 private static <T> T getProxy(Class<T> intf, T realObj) {5 return (T) Proxy.newProxyInstance(intf.getClassLoader(), new Class<?>[] { intf },6 new SimpleInvocationHandler(realObj));7 }8
9 // 其它对象都可以使用上述方法创建代理对象10 public static void main(String[] args) throws Exception {11 // 获可以创建ServiceAImpl对象的代理12 IServiceA a = new ServiceAImpl();13 IServiceA aProxy = getProxy(IServiceA.class, a);14 aProxy.sayHello();15
16 // 也可以创建ServiceBImpl对象的代理17 IServiceB b = new ServiceBImpl();18 IServiceB bProxy = getProxy(IServiceB.class, b);19 bProxy.fly();20 }21}22
4. 动态代理-基于子类
JDK动态代理是基于接口的代理,只能代理接口中的方法,代理对象也只能转换到某个接口类型,如果一个类没有接口,或者希望代理非接口中定义的方法,可以使用第三方的类库cglib。
1) 基本使用
使用cglib前需导入依赖:
51<dependency>2 <groupId>cglib</groupId>3 <artifactId>cglib</artifactId>4 <version>3.1</version>5</dependency>一个简单的使用示例如下:
531import net.sf.cglib.proxy.Enhancer;2import net.sf.cglib.proxy.MethodInterceptor;3import net.sf.cglib.proxy.MethodProxy;4
5import java.lang.reflect.Method;6
7public class SimpleCGLibDemo {8 // 被代理的类(无需实现接口)9 static class RealService {10 public void sayHello() {11 System.out.println("hello");12 }13 }14
15 static class SimpleInterceptor implements MethodInterceptor {16
17 /**18 * 代理逻辑19 *20 * @param object 代理对象 SimpleCGLibDemo$RealService$$EnhancerByCGLIB$$b9e1e177@5b275dab21 * @param method22 * @param args23 * @param proxy24 * @return 返回值为Object类型,且可以安全的转换为被代理类的类型25 * @throws Throwable 26 * 注意:不能这样调用被代理方法,会出现死循环:Object result = method.invoke(object, args);27 */28 29 public Object intercept(Object object, Method method, Object[] args, MethodProxy proxy) throws Throwable {30 System.out.println("entering " + method.getName());31 Object result = proxy.invokeSuper(object, args); // 必须使用proxy而非method调用32 System.out.println("leaving " + method.getName());33 return result;34 }35 }36
37 // 创建代理(通用方法)38 ("unchecked")39 private static <T> T getProxy(Class<T> cls) {40 Enhancer enhancer = new Enhancer();41 enhancer.setSuperclass(cls); // 设置被代理的类42 enhancer.setCallback(new SimpleInterceptor()); // 设置被代理类的方法被调用时的处理类(仅适用public且非final方法)43 return (T) enhancer.create();44 }45
46 // 测试47 // 在main方法中,我们没有创建被代理的对象,创建的对象直接就是代理对象48 public static void main(String[] args) throws Exception {49 RealService proxyService = getProxy(RealService.class);50 proxyService.sayHello();51 }52}53
2) 实现原理
cglib动态代理是基于继承实现的,也是动态的创建一个类,但这个类的父类是被代理的类,代理类重写了父类的所有public且非final方法,改为调用Callback中的相关方法,在上例中,调用SimpleInterceptor的intercept方法。
3) 与JDK代理对比
JDK代理面向的是一组接口,它为这些接口动态的创建一个实现类,实现类中接口方法都将转发到InvocationHandler的invoke方法。这里需要注意,JDK动态代理的背后不一定有实际对象,也可能有多个实际对象,根据情况动态选择。
cglib代理面向的是一个具体的类,它也动态的创建一个新类,并继承了该类,重写了其方法进行转发。
从代理的角度看,JDK代理的是对象,需要先有一个实际对象,自定义的InvocationHandler引用该对象,然后创建一个代理类和代理对象,客户端访问的是代理对象,代理对象最后再调用实际对象的方法,cglib代理的是类,创建的对象只有一个。
如果目的都是为一个类的方法增强功能,JDK代理要求该类必须有接口,且只能处理接口中的方法,cglib没有这个限制,只要方法是public且非final即可。
5. 简单AOP框架
动态代理是面向切面编程(AOP - Aspect Oriented Programming)的基础,切面的例子有日志、性能监控、权限检查、数据库事务等,它们在程序的很多地方都会用到,代码都差不多,但与某个具体的业务逻辑关系也不太密切,如果在每个用到的地方都写,代码会很冗余,也难以维护,AOP将这些切面与主体逻辑相分离,代码简单优雅的多,下面我们自己实现一个简单的AOP框架。
详见:https://www.cnblogs.com/swiftma/p/6869790.html。
第四节 单元测试
单元测试(Unit Testing)又称为模块测试 ,是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。
1. Junit简介
JUnit是Java中最常用的单元测试框架之一,使用它需要添加如下依赖:
61<dependency>2 <groupId>junit</groupId>3 <artifactId>junit</artifactId>4 <version>4.13.2</version>5 <scope>compile</scope>6</dependency>下面是一个简单的使用案例:
461// ----- 业务类 ----- 2public class Calculator {3 // 加法4 public int add(int a, int b) {5 //int i = 3/0; // 模拟异常6 return a - b;7 }8}9
10// ----- 测试类 ----- 11public class CalculatorTest {12 // 初始化方法:用于资源申请,所有测试方法在执行之前都会先执行该方法13 14 public void init() {15 System.out.println("init...");16 }17
18 // 释放资源方法:在所有测试方法执行完后,都会自动执行该方法19 20 public void close() {21 System.out.println("close...");22 }23
24 // 测试add方法25 26 public void testAdd() {27 System.out.println("testAdd...");28
29 // 1. 调用业务方法30 Calculator c = new Calculator();31 int result = c.add(1, 2);32
33 // 2. 断言结果34 Assert.assertEquals(3, result); // 期望为3,实际为result,不一致则报错35 }36}37
38/*39init...40testAdd...41close...42
43java.lang.AssertionError: 44Expected :345Actual :-146*/更多关于单元测试的操作请参阅:https://www.w3cschool.cn/junit/fegu1hv3.html。
第五节 日志框架
1. 日志框架简介
Java最早的日志框架是Apache提出的log4j,随后Sun公司为制定Java日志标准,在JDK4中内置了JUL(java.util.logging),同时期,其它优秀的日志框架也相继涌现,如simplelog等。
随着日志框架越来越多,为了统一日志接口,Apache提出了日志门面JCL(commons-logging)。后面log4j的作者觉得不好用,又开发了另一套日志门面SLF4J(simple logging facade for Java),并还开发了一个基于SLF4J的日志框架实现logback,与此同时,又继续维护并升级了log4j,形成了其升级版本log4j2。此时Java日志体系如下:

2. 基本使用
为了方便的切换日志实现,用户应选用某一种日志门面(JCL或SLF4J),而不是具体的日志实现。在使用时,需要关注日志门面依赖、日志实现依赖以及它们的桥接依赖是否引入。
2.1JCL
131import org.apache.commons.logging.Log;2import org.apache.commons.logging.LogFactory;3import org.junit.Test;4
5public class JCLTest {6 private static final Log log = LogFactory.getLog(JCLTest.class);7
8 9 public void test() throws Exception {10 log.info("hello jcl");11 }12}13
2.2 SLF4J
121import org.slf4j.Logger;2import org.slf4j.LoggerFactory;3 4public class SLF4JTest {5 private static final Logger logger = LoggerFactory.getLogger(SLF4JTest.class);6 7 8 public void test() throws Exception {9 String message = "Hello World.";10 logger.info("This is a test message: {}", message);11 }12}
2.3 JCL->Log4j
161<dependencies>2 <!-- JCL日志门面依赖(默认支持LOG4J,无需桥接依赖) -->3 <dependency>4 <groupId>commons-logging</groupId>5 <artifactId>commons-logging</artifactId>6 <version>1.2</version>7 </dependency>8
9 <!-- LOG4J依赖 -->10 <dependency>11 <groupId>log4j</groupId>12 <artifactId>log4j</artifactId>13 <version>1.2.17</version>14 </dependency>15</dependencies>16
2.4 SLF4J->Log4j
231<dependencies>2 <!-- SLF4J日志门面依赖 -->3 <dependency>4 <groupId>org.slf4j</groupId>5 <artifactId>slf4j-api</artifactId>6 <version>1.7.25</version>7 </dependency>8 9 <!-- LOG4J依赖 -->10 <dependency>11 <groupId>log4j</groupId>12 <artifactId>log4j</artifactId>13 <version>1.2.17</version>14 </dependency>15 16 <!-- SLF4J->LOG4J桥接依赖 -->17 <dependency>18 <groupId>org.slf4j</groupId>19 <artifactId>slf4j-log4j12</artifactId>20 <version>1.7.25</version>21 </dependency>22</dependencies>23
2.5 SLF4J->Logback
261<dependencies>2 <!-- SLF4J日志门面依赖(默认支持Logback,无需桥接依赖) -->3 <dependency>4 <groupId>org.slf4j</groupId>5 <artifactId>slf4j-api</artifactId>6 <version>1.7.25</version>7 </dependency>8
9 <!-- logback依赖 -->10 <dependency>11 <groupId>ch.qos.logback</groupId>12 <artifactId>logback-core</artifactId>13 <version>1.2.3</version>14 </dependency>15 <dependency>16 <groupId>ch.qos.logback</groupId>17 <artifactId>logback-classic</artifactId>18 <version>1.2.3</version>19 </dependency>20 <dependency>21 <groupId>ch.qos.logback</groupId>22 <artifactId>logback-access</artifactId>23 <version>1.2.3</version>24 </dependency>25</dependencies>26
2.6 JCL/SLF4J->Log4j2
141<dependencies>2 <!-- log4j2依赖(直接集成了JCL和SLF4J门面) -->3 <dependency>4 <groupId>org.apache.logging.log4j</groupId>5 <artifactId>log4j-api</artifactId>6 <version>2.8.2</version>7 </dependency>8 <dependency>9 <groupId>org.apache.logging.log4j</groupId>10 <artifactId>log4j-core</artifactId>11 <version>2.8.2</version>12 </dependency>13</dependencies>14
3. Log4j配置详解
Log4j有三个主要的组件,分别是Loggers(记录器)、Appenders(输出源)和Layout(布局)。
3.1 Loggers
Loggers(记录器)可以配置日志类别所对应的日志级别。日志类别指日志信息的分类,一般为调用类的全类名。日志级别按照重要程度可分为DEBUG < INFO < WARN < ERROR < FATAL五类。每条日志信息都有其日志级别,只有>=其类别所配置的日志级别时才会被输出。
3.2 Appenders
Appenders(输出源)用于配置日志的输出位置,常使用的类如下:
111# 输出到控制台2org.apache.log4j.ConsoleAppender 3# 输出到普通文件4org.apache.log4j.FileAppender5# 每天产生一个日志文件6org.apache.log4j.DailyRollingFileAppender7# 文件大小到达指定尺寸的时候产生一个新的文件8org.apache.log4j.RollingFileAppender9# 将日志信息以流格式发送到任意指定的地方10org.apache.log4j.WriterAppender11
3.3 Layout
Layout(布局)用来配置日志输出格式,常使用的类如下:
91# 以HTML表格形式布局2org.apache.log4j.HTMLLayout3# 可以灵活地指定布局模式4org.apache.log4j.PatternLayout 5# 包含日志信息的级别和信息字符串6org.apache.log4j.SimpleLayout 7# 包含日志产生的时间、线程、类别等信息8org.apache.log4j.TTCCLayout 9
3.4 配置案例
291# rootLogger配置2log4j.rootLogger=WARN,CONSOLE,logfile # 格式为日志级别,输出位置名称3
4# 输出到控制台5log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender 6log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout # 设置为自定义布局模式7log4j.appender.CONSOLE.layout.ConversionPattern=[frame] %d{yyyy-MM-dd HH:mm:ss,SSS} - %-4r %-5p [%t] %C:%L %x - %m%n # 配置输出格式:[frame] 2019-08-22 22:52:12,000 %r耗费毫秒数 %p日志的优先级 %t线程名 %C所属类名通常为全类名 %L代码中的行号 %x线程相关联的NDC %m日志 %n换行8
9# 输出到日志文件中10log4j.appender.logfile=org.apache.log4j.RollingFileAppender # 配置logfile输出到文件中 文件大小到达指定尺寸的时候产生新的日志文件11log4j.appender.logfile.Threshold = DEBUG # 大于该级别的日志才会被输出(可以根据不同的日志级别配置多个appender,将不同级别的信息输出到不同的文件)12log4j.appender.logfile.Encoding=UTF-8 # 保存编码格式13log4j.appender.logfile.File=logs/root.log # 输出文件位置,此为项目根目录下的logs文件夹中14log4j.appender.logfile.MaxFileSize=10MB # 达到该大小后创建新的日志文件,后缀可以是KB,MB,GB15log4j.appender.logfile.MaxBackupIndex=3 # 设置滚定文件的最大值3,指可以产生root.log.1、root.log.2、root.log.3和root.log四个日志文件16log4j.appender.logfile.layout=org.apache.log4j.PatternLayout # 配置为自定义布局模式17log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %F %p %m%n # 日志格式18
19# 其它Logger配置20log4j.logger.com.huangyuanxin=DEBUG,bagedate # com.huangyuanxin包下的日志单独输出21log4j.additivity.com.huangyuanxin=false # 设置为false该日志信息就不会加入到rootLogger中了22log4j.appender.bagedate=org.apache.log4j.RollingFileAppender23log4j.appender.bagedate.Encoding=UTF-824log4j.appender.bagedate.File=logs/bagedate.log25log4j.appender.bagedate.MaxFileSize=10MB26log4j.appender.bagedate.MaxBackupIndex=327log4j.appender.bagedate.layout=org.apache.log4j.PatternLayout28log4j.appender.bagedate.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %F %p %m%n29
4. Log4j2配置详解
4.1 配置案例
591 2<Configuration status="WARN">3 <!--全局参数-->4 <Properties>5 <Property name="pattern">%d{yyyy-MM-dd HH:mm:ss,SSS} %5p %c{1}:%L - %m%n</Property>6 <Property name="logDir">/data/logs/dust-server</Property>7 </Properties>8
9 <!--输出位置-->10 <Appenders>11 <!-- 定义输出到控制台 -->12 <Console name="console" target="SYSTEM_OUT" follow="true">13 <!--控制台只输出level及以上级别的信息-->14 <ThresholdFilter level="INFO" onMatch="ACCEPT" onMismatch="DENY"/>15 <PatternLayout>16 <Pattern>${pattern}</Pattern>17 </PatternLayout>18 </Console>19 <!-- 同一来源的Appender可以定义多个RollingFile,定义按天存储日志 -->20 <RollingFile name="rolling_file"21 fileName="${logDir}/dust-server.log"22 filePattern="${logDir}/dust-server_%d{yyyy-MM-dd}.log">23 <ThresholdFilter level="INFO" onMatch="ACCEPT" onMismatch="DENY"/>24 <PatternLayout>25 <Pattern>${pattern}</Pattern>26 </PatternLayout>27 <Policies>28 <TimeBasedTriggeringPolicy interval="1"/>29 </Policies>30 <!-- 日志保留策略,配置只保留七天 -->31 <DefaultRolloverStrategy>32 <Delete basePath="${logDir}/" maxDepth="1">33 <IfFileName glob="dust-server_*.log" />34 <IfLastModified age="7d" />35 </Delete>36 </DefaultRolloverStrategy>37 </RollingFile>38 </Appenders>39 40 <!--然后定义logger,只有定义了logger并引入的appender,appender才会生效-->41 <loggers>42 <!-- root/asyncRoot节点用来指定项目的根日志,如果没有单独指定Logger,那么就会默认使用该Root日志输出 -->43 <root level="INFO">44 <appender-ref ref="console"/>45 <appender-ref ref="rolling_file"/>46 </root>47 48 <!--Logger节点用来单独指定日志的形式,name为包路径 -->49 <logger name="org.springframework" level="INFO"></logger>50 <logger name="org.mybatis" level="INFO"></logger>51 52 <!--AsyncLogger:异步日志,LOG4J有三种日志模式,全异步日志,混合模式,同步日志,性能从高到底,线程越多效率越高,也可以避免日志卡死线程情况发生-->53 <!--additivity="false" : additivity设置事件是否在root logger输出,为了避免重复输出,可以在Logger 标签下设置additivity为”false”-->54 <AsyncLogger name="AsyncLogger" level="trace" includeLocation="true" additivity="false">55 <appender-ref ref="RollingFileError"/>56 </AsyncLogger>57 </loggers>58</Configuration>59
5. Logback配置详解
5.1 配置案例
321 2<configuration>3 <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">4 <encoder>5 <pattern><![CDATA[%n[%d{yyyy-MM-dd HH:mm:ss.SSS}] [level: %p] [Thread: %t] [ Class:%c >> Method: %M:%L ]%n%p:%m%n]]></pattern>6 </encoder>7 </appender>8 <appender name="LOG_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">9 <encoder>10 <pattern><![CDATA[%n[%d{yyyy-MM-dd HH:mm:ss.SSS}] [level: %p] [Thread: %t] [ Class:%c >> Method: %M:%L ]%n%p:%m%n]]></pattern>11 </encoder>12 <file>logs/sports-web.log</file>13 <rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">14 <fileNamePattern>logs/sports-web.-%d{yyyyMMdd}.%i.log</fileNamePattern>15 <!-- 每天一个日志文件,当天的日志文件超过10MB时,生成新的日志文件,当天的日志文件数量超过totalSizeCap/maxFileSize,日志文件就会被回滚覆盖。 -->16 <maxFileSize>10MB</maxFileSize>17 <maxHistory>30</maxHistory>18 <totalSizeCap>10GB</totalSizeCap>19 </rollingPolicy> 20 </appender>21 <logger name="com.sports" level="DEBUG" additivity="false">22 <appender-ref ref="STDOUT"/>23 <appender-ref ref="LOG_FILE"/>24 <!--<appender-ref ref="myAppender"/>-->25 </logger>26 <root level="INFO">27 <appender-ref ref="STDOUT"/>28 <appender-ref ref="LOG_FILE"/>29 <!--<appender-ref ref="mqAppender"/>-->30 </root>31</configuration>32
提示:有关Logback的更多信息可参考:https://blog.csdn.net/qq_41946216/article/details/124983469?spm=1001.2014.3001.5502。
第五节 XML解析
1. XML基本概念
XML(Extensible Markup Language)的中文名为可扩展标记语言,主要用来存储数据,如做项目的配置文件或作为网络文件传输数据等。
471<!-- 1. 文档声明2 1) 格式:<?xml 属性列表 ?>3 2) 属性:4 version:版本号,必须的属性5 encoding:编码方式,用于告知解析引擎当前文档使用的字符集,默认值:ISO-8859-16 standalone:是否独立,取值为yes或no7 3) 注意:文档声明必须为第一行,前面不能有注释等内容(注意删除这个注释)!8 -->9 10
11
12<!-- 2. 指令13 1) 格式:<?xml-stylesheet type="text/css" href="a.css" ?>14 2) 注意:虽然可以在xml中引用css,但一般不推荐使用15-->16
17
18<!-- 3. 标签19 1) 标签名称可以自定义,且名称区分大小写20 2) 名称可以包含字母、数字以及其他的字符,但不能包括空格21 3) 名称不能以数字、标点符号、特殊单词(xml/XML/Xml等)开始22 4) 标签必须正确关闭23 5) XML的根标签有且只有一个24-->25<users>26
27<!-- 4. 标签属性28 1) 属性值必须使用引号(单双都可)引起来29 2) id属性值必须唯一(注:此id是约束文档所定义的属性)30-->31 <user id='1'>32 33<!-- 5. 文本块34 1) 即标签体,可以用 <![CDATA[ 数据 ]]> 指定在该区域中的数据原样展示35-->36 <name>zhangsan</name>37 <age>23</age>38 <gender>male</gender>39 <br/>40 </user>41 42 <user id='2'>43 <name>lisi</name>44 <age>24</age>45 <gender>female</gender>46 </user>47</users>
2. XML约束
XML约束规定了xml文档的书写规则,主要有DTD和Schema两种方式。
1) DTD方式
DTD是一种简单的XML约束技术,有三种使用方式:
1)内联方式:将约束规则定义在xml文档中。
2)从本地引入:语法如下,
<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">。3)从网络引入:语法如下,
<!DOCTYPE 根标签名 PUBLIC "dtd文件名字" "dtd文件的位置URL">。
下面是一个引用了DTD约束的XML文件:
301 2
3<!-- 从本地引入 -->4
6<!-- 内联方式 -->7<!--<!DOCTYPE students [8 <!ELEMENT students (student+) >9 <!ELEMENT student (name,age,sex)>10 <!ELEMENT name (#PCDATA)>11 <!ELEMENT age (#PCDATA)>12 <!ELEMENT sex (#PCDATA)>13 <!ATTLIST student number ID #REQUIRED>14 ]>-->15 16<students>17 18 <student number="s001">19 <name>zhangsan</name>20 <age>abc</age>21 <sex>hehe</sex>22 </student>23
24 <student number="s002">25 <name>lisi</name>26 <age>24</age>27 <sex>female</sex>28 </student>29 30</students>在同目录下的student.dtd文件如下:
71<!ELEMENT students (student+) >2<!ELEMENT student (name,age,sex)>3<!ELEMENT name (#PCDATA)>4<!ELEMENT age (#PCDATA)>5<!ELEMENT sex (#PCDATA)>6<!ATTLIST student number ID #REQUIRED>7
2) Schema方式
Schema是一种复杂的XML约束技术,其引入步骤如下:
1)填写xml文档的根元素。
2)引入xsi前缀: xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"。
3)引入xsd文件命名空间: xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"。
4)为每一个xsd约束声明一个前缀,作为标识: xmlns="http://www.itcast.cn/xml" 。
下面是是一个引了了Schema约束的XML文件:
121 2<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"3 xmlns="http://www.itcast.cn/xml"4 xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"5>6 <student number="heima_0001">7 <name>tom</name>8 <age>18</age>9 <sex>male</sex>10 </student>11
12</students>在同目录下的student.xsd文件如下:
361<?xml version="1.0"?>2<xsd:schema xmlns="http://www.itcast.cn/xml"3 xmlns:xsd="http://www.w3.org/2001/XMLSchema"4 targetNamespace="http://www.itcast.cn/xml" elementFormDefault="qualified">5 <xsd:element name="students" type="studentsType"/>6 <xsd:complexType name="studentsType">7 <xsd:sequence>8 <xsd:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>9 </xsd:sequence>10 </xsd:complexType>11 <xsd:complexType name="studentType">12 <xsd:sequence>13 <xsd:element name="name" type="xsd:string"/>14 <xsd:element name="age" type="ageType" />15 <xsd:element name="sex" type="sexType" />16 </xsd:sequence>17 <xsd:attribute name="number" type="numberType" use="required"/>18 </xsd:complexType>19 <xsd:simpleType name="sexType">20 <xsd:restriction base="xsd:string">21 <xsd:enumeration value="male"/>22 <xsd:enumeration value="female"/>23 </xsd:restriction>24 </xsd:simpleType>25 <xsd:simpleType name="ageType">26 <xsd:restriction base="xsd:integer">27 <xsd:minInclusive value="0"/>28 <xsd:maxInclusive value="256"/>29 </xsd:restriction>30 </xsd:simpleType>31 <xsd:simpleType name="numberType">32 <xsd:restriction base="xsd:string">33 <xsd:pattern value="heima_\d{4}"/>34 </xsd:restriction>35 </xsd:simpleType>36</xsd:schema>
3. XML解析(Jsoup)
XML解析主要有两种方式:
1)DOM方式:一次性加载进内存,生成DOM树,基于DOM树进行CURD操作,优点是操作方便,缺点是特别占内存。
2)SAX方式:逐行读取,基于事件驱动,优点是基本不占内存,但只能进行查询,不能执行增删改操作。
上述两种解析方式分别有一些代表性的解析器工具:
| 解析器 | 说明 | 解析方式 |
|---|---|---|
| JAXP | 由sun公司提供,支持dom和sax两种解析方式 | DOM/SAX |
| DOM4J | 一个非常优秀的解析器 | DOM |
| Jsoup | 一款HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API, 可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 | DOM |
| PULL | Android操作系统内置的解析器,sax方式的 | SAX |
下面我们以JSoup为例介绍下XML文件的解析。
1) Jsoup的基本使用
JSoup使用前需要先导入相关依赖:
51<dependency>2 <groupId>org.jsoup</groupId>3 <artifactId>jsoup</artifactId>4 <version>1.7.2</version>5</dependency>解析XML文件的简单示例如下:
131// 1. 获取Document对象2String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath();3Document document = Jsoup.parse(new File(path), "utf-8");4
5// 2. 获取Elements/Element对象6Elements elements = document.getElementsByTag("name");7System.out.println(elements.size());8Element element = elements.get(0);9
10// 3. 获取元素的数据11String name = element.text(); // 文本12System.out.println(name);13
也可以从字符串或URL进行解析:
241// 1. 从字符串中解析XML2String str = "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +3 "\n" +4 "<students>\n" +5 "\t<student number=\"heima_0001\">\n" +6 "\t\t<name>tom</name>\n" +7 "\t\t<age>18</age>\n" +8 "\t\t<sex>male</sex>\n" +9 "\t</student>\n" +10 "\t<student number=\"heima_0002\">\n" +11 "\t\t<name>jack</name>\n" +12 "\t\t<age>18</age>\n" +13 "\t\t<sex>female</sex>\n" +14 "\t</student>\n" +15 "\n" +16 "</students>";17Document document = Jsoup.parse(str);18System.out.println(document);19
20// 2. 从URL中解析XML21URL url = new URL("https://baike.baidu.com/item/jsoup/9012509?fr=aladdin"); // 代表网络中的一个资源路径22Document document = Jsoup.parse(url, 10000);23System.out.println(document);24
2) Document对象
Document(文档对象)表示内存中的DOM树,一般用来获取Element对象,常用方法有:
41getElementById(String id) // 根据id属性值获取唯一的element对象2getElementsByTag(String tagName) // 根据标签名称获取元素对象集合3getElementsByAttribute(String key) // 根据属性名称获取元素对象集合4getElementsByAttributeValue(String key, String value) // 根据对应的属性名和属性值获取元素对象集合使用示例如下:
231// 1.获取student.xml的path2String path = JsoupDemo3.class.getClassLoader().getResource("student.xml").getPath();3
4// 2.获取Document对象5Document document = Jsoup.parse(new File(path), "utf-8");6
7// 3. 通过Document对象获取元素对象8// 3.1 获取id属性值为hyx的元素对象(id属性是唯一的)9Element itcast = document.getElementById("hyx");10System.out.println(itcast);11
12// 3.2 获取所有student标签13Elements elements = document.getElementsByTag("student");14System.out.println(elements);15
16// 3.3 获取存在id属性的元素对象们17Elements elements1 = document.getElementsByAttribute("id");18System.out.println(elements1);19
20// 3.4 获取number属性值为heima_0001的元素对象们21Elements elements2 = document.getElementsByAttributeValue("number", "heima_0001");22System.out.println(elements2);23
3) Elements/Element对象
Elements表示Element的集合,常用方法与ArrayList<Element>类似,其中Element表示元素对象,常用方法如下:
131// 第一类:获取子元素对象2getElementById•(String id) // 根据id属性值获取唯一的element对象3getElementsByTag•(String tagName) // 根据标签名称获取元素对象集合4getElementsByAttribute•(String key) // 根据属性名称获取元素对象集合5getElementsByAttributeValue•(String key, String value) // 根据对应的属性名和属性值获取元素对象集合6
7// 第二类 获取属性值8String attr(String key) // 根据属性名称获取属性值9
10// 第三类 获取文本内容11String text() // 获取文本内容12String html() // 获取标签体的所有内容(包括字标签的字符串内容)13
简单示例如下:
231
2// 1. 获取Document3String path = JsoupDemo4.class.getClassLoader().getResource("student.xml").getPath();4Document document = Jsoup.parse(new File(path), "utf-8");5
6// 2. 通过Document对象获取name标签7Elements elements = document.getElementsByTag("name");8System.out.println(elements.size());9
10// 3. 通过Element对象获取子标签对象11Element element_student = document.getElementsByTag("student").get(0);12Elements ele_name = element_student.getElementsByTag("name");13System.out.println(ele_name.size());14
15// 4. 获取student对象的属性值16String number = element_student.attr("NUMBER");17System.out.println(number);18
19// 5. 获取文本内容20String text = ele_name.text();21String html = ele_name.html();22System.out.println(text);23System.out.println(html);
4) Node对象
Node表示节点对象,是Document和Element的父类。
5) selector快捷查询
Jsoup的快捷查询有两种,一种为selector选择器方式,直接调用Document的成员方法Elements select(String cssQuery)即可。
191// 1. 获取Document对象2String path = JsoupDemo5.class.getClassLoader().getResource("student.xml").getPath();3Document document = Jsoup.parse(new File(path), "utf-8");4
5// 2. 查询name标签6Elements elements = document.select("name");7System.out.println(elements);8
9// 3. 查询id值为itcast的元素10Elements elements1 = document.select("#itcast");11System.out.println(elements1);12
13// 4. 获取student标签并且number属性值为heima_000114Elements elements2 = document.select("student[number=\"heima_0001\"]");15System.out.println(elements2);16
17// 5. 获取student标签并且number属性值为heima_0001的age子标签18Elements elements3 = document.select("student[number=\"heima_0001\"] > age");19System.out.println(elements3);
6) XPath快捷查询
JSoup的另一种快捷查询的方式为XPath,即XML路径语言,它是一种用来确定XML文档中某部分位置的语言。使用前需要导入相关依赖:
51<dependency>2 <groupId>cn.wanghaomiao</groupId>3 <artifactId>JsoupXpath</artifactId>4 <version>2.2</version>5</dependency>使用示例如下:
311// 1. 获取Document对象2String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath();3Document document = Jsoup.parse(new File(path), "utf-8");4
5// 2. 根据document对象,创建JXDocument对象6JXDocument jxDocument = new JXDocument(document);7
8// 3. 查询所有student标签9List<JXNode> jxNodes = jxDocument.selN("//student");10for (JXNode jxNode : jxNodes) {11 System.out.println(jxNode);12}13
14// 4. 查询所有student标签下的name标签15List<JXNode> jxNodes2 = jxDocument.selN("//student/name");16for (JXNode jxNode : jxNodes2) {17 System.out.println(jxNode);18}19
20// 5. 查询student标签下带有id属性的name标签21List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id]");22for (JXNode jxNode : jxNodes3) {23 System.out.println(jxNode);24}25
26// 6. 查询student标签下带有id属性的name标签 并且id属性值为itcast27List<JXNode> jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");28for (JXNode jxNode : jxNodes4) {29 System.out.println(jxNode);30}31
第六节 Json解析
1. Json的基本概念
1) 什么是Json?
Json(JavaScript Object Notation)译为JavaScript对象表示法,多用于存储和交换文本信息,比XML更小更快更易解析。基本语法如下:
Json是由花括号内括键值对构成的,键用引号(单双都行)引起来,一般情况下不省略。
Json的值可以是数字(整数和浮点数)、字符串(在双引号中)、逻辑值(true或false)以及null。
Json可以嵌套,即Json的值可以是另一个Json。
Json的值可以是以上类型的数组,如:
{"persons":[{},{}]}键和值用冒号分隔,不同键值对之间用逗号分隔。
11var p = {"name":"张三","age":23,"gender":"男"};
2) 从Json中获取数据(JS)
231<script>2 //1.Json基本格式3 var person = {"name": "张三", age: 23, 'gender': true};4 var name = person.name; // 方式一:json1.键名 ==> p.name5 var name = person["name"]; // 方式二:json1["键名"] ==> p["age"]6
7 //2.Json数组:Json做元素组成的数组8 var ps = [{"name": "张三", "age": 23, "gender": true},9 {"name": "李四", "age": 24, "gender": true},10 {"name": "王五", "age": 25, "gender": false}11 ];12 var name1 = ps[1].name;13 14 //3.Json的值为数组15 var persons = {16 "persons": [17 {"name": "张三", "age": 23, "gender": true},18 {"name": "李四", "age": 24, "gender": true},19 {"name": "王五", "age": 25, "gender": false}20 ]21 };22 var name1 = persons.persons[2].name; 23</script>
3) Json遍历获取所有值(JS)
191//1.定义Json和Json数组2var person = {"name": "张三", age: 23, 'gender': true};3var ps = [{"name": "张三", "age": 23, "gender": true},4 {"name": "李四", "age": 24, "gender": true},5 {"name": "王五", "age": 25, "gender": false}];6
7//2. 从单个Json对象获取值8for(var key in person){9 alert(key+":"+person[key]); 10 alert(key + ":" + person.key); //这样的方式获取不行。因为相当于 person."name"11}12
13//3. 从Json数组获取值14for (var i = 0; i < ps.length; i++) {15 var p = ps[i];16 for(var key in p){17 alert(key+":"+p[key]);18 }19}
2. Json解析器(Jackson)
1) Jackson简介
Jackson 是一个 Java 语言编写的,可以进行 JSON 处理的开源工具库。它有三个核心包:
Streaming:在 jackson-core 模块,定义了一些流处理相关的 API 以及特定的 JSON 实现。
Annotations:在 jackson-annotations 模块,包含了 Jackson 中的注解。
Databid:在 jackson-databind 模块, 在 Streaming 包的基础上实现了数据绑定,依赖于 Streaming 和 Annotations 包。
大多数情况下我们只需要添加 jackson-databind 依赖项即可,它会同时引入另外两个依赖:
61<dependency>2 <groupId>com.fasterxml.jackson.core</groupId>3 <artifactId>jackson-databind</artifactId>4 <version>2.13.3</version>5</dependency>6
2) 基本使用
Jackson的常用API如下:
221// 1. 构造方法2ObjectMapper mapper = new ObjectMapper(); // 创建核心对象ObjectMapper,用于Json文本序列化和反序列化3mapper.enable(SerializationFeature.INDENT_OUTPUT); // 配置格式化输出4mapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES); // 忽略流中的未知属性5
6// 2. 适用于XML/MessagePack的构造方法7ObjectMapper mapper = new XmlMapper(); 8ObjectMapper mapper = new ObjectMapper(new MessagePackFactory()); 9
10// 3. 序列化(输出所有声明为 public 的字段,或者有 public getter 方法的字段)11public byte[] writeValueAsBytes(Object value)12public String writeValueAsString(Object value)13public void writeValue(OutputStream out, Object value)14public void writeValue(Writer w, Object value)15public void writeValue(File resultFile, Object value)16 17// 4. 反序列化(默认情况下 , Jackson 假定对象类型有一个无参的构造方法 , 它会先调用该构造方法创建对象 , 然后解析输入源进行反序列化)18public <T> T readValue(String content, Class<T> valueType)19public <T> T readValue(InputStream src, Class<T> valueType)20public <T> T readValue(Reader src, Class<T> valueType)21public <T> T readValue(byte[] src, Class<T> valueType)22 下面是一些使用案例:
691// 1. 普通对象序列化2public class Person {3 private Integer id;4 private String name;5 private Integer age;6 private Date birthday;7
8 public static void main(String[] args) throws IOException {9 Person person = new Person();10 person.setName("张三");11 person.setAge(30);12 person.setId(20);13 person.setBirthday(new Date());14
15 // 序列化16 ObjectMapper mapper = new ObjectMapper();17 String jsonString = mapper.writeValueAsString(person); // 序列化到字符串18 mapper.writeValue(new File("d://a.txt"), person); // 序列化到文件19 System.out.println(jsonString); // {"id":20,"name":"张三","age":30,"birthday":1672220987733}20
21 // 反序列化22 Person out = mapper.readValue(jsonString, Person.class);23 System.out.println(out); // Person{id=20, name='张三', age=30, birthday=Wed Dec 28 17:49:47 CST 2022}24 }25
26 // getter/setter/toString27}28
29
30
31// 2. Map对象序列化32public static void main(String[] args) throws IOException {33 // 1.创建map对象34 Map<String, Object> srcMap = new HashMap<>();35 srcMap.put("name", "张三");36 srcMap.put("age", 23);37 srcMap.put("gender", "男");38
39 // 2. 序列化为Json对象40 ObjectMapper mapper = new ObjectMapper();41 String json = mapper.writeValueAsString(srcMap);42 System.out.println(json); // {"gender":"男","name":"张三","age":23}43
44 // 3. 反序列化45 Map<String, Object> map = mapper.readValue(json, new TypeReference<Map<String, Object>>() { });46 System.out.println(map.toString()); // {gender=男, name=张三, age=23}47}48
49
50
51// 3. List对象序列化52public static void main(String[] args) throws IOException {53 //1.准备Person列表54 List<Person> personList = new ArrayList<>();55 personList.add(new Person(1, "张三", 23, new Date()));56 personList.add(new Person(2, "李四", 60, new Date()));57 personList.add(new Person(3, "王五", 80, new Date()));58
59 //2.序列化为Json数组 [{},{},{}]60 ObjectMapper mapper = new ObjectMapper();61 String json = mapper.writeValueAsString(personList);62 System.out.println(json); // [{"id":1,"name":"张三","age":23,"birthday":1672221349837},{"id":2,"name":"李四","age":60,"birthday":1672221349837},{"id":3,"name":"王五","age":80,"birthday":1672221349837}]63
64 // 3. 反序列化65 List<Person> list = mapper.readValue(json, new TypeReference<List<Person>>() {});66 System.out.println(list.toString());67}68
69
3) 自定义扩展
忽略某些属性
在标准JDK序列化中,会忽略被 transient标记的字段。而在 Jack-son 中, 也可以使用@JsonIgnore/@JsonIgnoreProperties注解进行标记,被标记的字段或属性将不会被序列化,同时,反序列化时也不会赋值(即使输入源存在字段值)。
131// 作用于字段2double score;4
5// 作用于属性6public double getScore() {8 return score;9}10
11// 作用于类12("score")13public class Student {}
忽略未知字段
在标准JDK反序列化时,如果流中存在类中没有的字段,将会被忽略,而Jackson默认情况下抛异常:
11com.fasterxml.jackson.databind.exc.UnrecognizedPropertyException: Unrecognized field "other".....
可以通过配置ObjectMapper或在类上添加注解来忽略该情形:
101// 方式一:配置ObjectMapper2ObjectMapper mapper = new ObjectMapper();3mapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES); // 忽略流中的未知属性4Student s = mapper.readValue(new File("student.json"), Student.class);5
6// 方式二:在类上声明7(ignoreUnknown=true)8public class Student {9 //...10}
修改字段名称
有时,我们希望修改输出的名称,可以使用@JsonProperty注解进行配置。
81("student") // 根元素名称,对XML格式有效2public class Student {3 ("名称") // 字段名称4 String name;5 ("年龄")6 int age;7}8
日期格式化
默认情况下,日期的序列化格式为一个长整数,可以使用@JsonFormat注解配置日期格式。
31(pattern = "yyyy-MM-dd")2// @JsonFormat(pattern="yyyy-MM-dd HH:mm:ss", timezone="GMT+8")3private Date birthday;
指定构造方法
如果类中没有默认构造方法,则反序列化时会抛异常,此时可以使用@JsonCreator和@Json-Property指定一个构造方法。
101public Student(3 ("name") String name,4 ("age") int age,5 ("score") double score) {6 this.name = name;7 this.age = age;8 this.score = score;9}10
其它配置
301// 1. 如果序列化前引用同一个对象,要求反序列化后依然引用同一个对象2(3 generator = ObjectIdGenerators.IntSequenceGenerator.class, // generator表示对象唯一ID的产生方法,这里是使用整数顺序数产生器IntSequenceGenerator4 property = "id") // 在序列化输出中新增一个属性"id"以表示对象的唯一标示5static class Common {6 public String name;7}8
9// 2. 如果两个对象循环引用,Jackson会抛异常,可以指定父子引用关系10static class Parent {11 public String name;12 13 // 14 public Child child;15}16static class Child {17 public String name;18 19 // 20 public Parent parent;21}22
23// 3. 处理继承和多态:Jackson序列化时不带类型信息,如果某个字段是一个接口集合,保存了不同类型的子类实现,Jackson在反序列化时无法得知创建哪种子类24(use = Id.NAME, include = As.PROPERTY, property = "type") // 在输出中增加属性"type”,表示对象的实际类型25({26 .Type(value = Circle.class, name = "circle"), // 对子类Circle,输出类型为"circle"27 .Type(value = Square.class, name = "square")}) // 对子类Square,输出类型为"square”28static class Shape {29}30
3. Json解析器(FastJson)
1) FastJson简介
FastJson是阿里巴巴的的开源库,用于对JSON格式的数据进行解析和打包,Maven依赖如下。
61<!-- http://repo1.maven.org/maven2/com/alibaba/fastjson/ -->2<dependency>3 <groupId>com.alibaba</groupId>4 <artifactId>fastjson</artifactId>5 <version>1.2.48</version>6</dependency>
2) 常用API简介
231// 序列化方法2public static final String toJSONString(Object object); // 将JavaBean序列化为JSON文本 3public static final String toJSONString(Object object, boolean prettyFormat); // 将JavaBean序列化为带格式的JSON文本 4
5// 反序列化方法6public static final Object parse(String text); // 把JSON文本parse为JSONObject或者JSONArray7public static final JSONObject parseObject(String text); // 把JSON文本parse成JSONObject 8public static final <T> T parseObject(String text, Class<T> clazz); // 把JSON文本parse为JavaBean 9public static final JSONArray parseArray(String text); // 把JSON文本parse成JSONArray 10public static final <T> List<T> parseArray(String text, Class<T> clazz); //把JSON文本parse成JavaBean集合 11
12// Java对象/Java列表 <--> JSON对象或JSON数组13public static final Object toJSON(Object javaObject); //将JavaBean转换为JSONObject/JSONArray/字符串/基本类型/null等。14public static <T> T toJavaObject(JSON json, Class<T> clazz)15
16// JSONObject(JSON对象):实现了Map接口,其中的数据都是以key-value形式17public String getString(String key)18public Integer getInteger(String key)19public Object remove(Object key)20 21// JSONArray(JSON数组):实现了List接口,存储的是多个JSONObject22public JSONObject getJSONObject(int index)23
3) 常用注解
@JSONField注解可以对序列化和反序列化进行一些配置,常用的属性如下:
ordinal:序列化后的顺序。
name:序列化后的列名称。
serialize:是否序列化该属性,默认为true。
deserialize:是否反序列化该属性,默认为true。
format:日期格式。
defaultValue:默认值
231public class Person {2 (ordinal = 0, name = "ID")3 private Integer id;4 (ordinal = 1, name = "姓名")5 private String name;6 (ordinal = 2, name = "年龄", serialize = false, deserialize = false)7 private Integer age;8 (ordinal = 3, name = "生日", format = "yyyy-MM-dd hh:mm:ss", defaultValue = "1999-09-13 12:12:12")9 private Date birthday;10
11 public static void main(String[] args) {12 Person person = new Person();13 person.setName("张三");14 person.setAge(30);15 person.setId(20);16 person.setBirthday(new Date());17 String jsonString = JSON.toJSONString(person);18 System.out.println(jsonString); // {"ID":20,"姓名":"张三","生日":"2022-12-28 05:08:03"}19 }20
21 // getter/setter/toString22}23
第七节 正则表达式
正则表达式是一串字符,它描述了一个文本模式,利用它可以方便的处理文本,包括文本的查找、替换、验证、切分等。
1. 匹配字符
1) 普通字符
普通字符就是用字符本身表示,比如字符0、3、a、马等。
2) 特殊字符
特殊字符一般以反斜杠\开头,有如下一些:
| 特殊字符 | 说明 |
|---|---|
| 元字符 | 为正则语法中的特殊字符,如:斜杠\,用\\表示,其它还有\.、\*、\?、\+等。 |
| ASCII码转义字符 | ASCII码表定义的转义字符,如:制表符\t、换行符\n、回车符\r等。 |
| 八进制字符 | 以\0开头,后跟1~3位八进制数字表示一个字符,如:\0141,ASCII码为97,表示字符 'a'。 |
| 十六进制字符 | 以\x开头,后跟两位十六进制数字表示一个字符,如:\x6A,ASCII码为106,表示字符 'j'。 |
| Unicode字符 | 以\u开头,后跟四位十六进制数字表示一个字符,如:\u9A6C,表示中文字符“马”。特殊的,对于编号在0xFFFF以上的Unicode字符,使用\x{....}形式,如: \x{1f48e}表示字符'💎'。 |
3) 字符组
字符组是多个字符的集合,使用[]、[^]、-等定义,主要有如下两种:
可选字符组:用于匹配组中的任意一个字符,如:
[abcd]匹配abcd中的任意一个字符,[0123456789]匹配一个数字字符。排除字符组:用于匹配不在组中的任意一个字符,如
[^abcd]匹配abcd之外的任意一个字符,[^0-9]匹配一个非数字字符。
在字符组中,如果字符是连续的,可以使用连字符-表示,如:[0-9]、[a-z]、[0-9a-zA-Z_]。
在字符组中,-是一个元字符,如果要匹配它自身,可以使用转义,即\-,或者把它放在字符组的最前面,如[-0-9]。
在字符组中,除了[、]、^、-、\外,其它元字符不再具备特殊含义,变成了普通字符,比如[.*]就是匹配.或者*本身。
在字符组中,^只有在字符组的开头才是元字符,如果不在开头,就是普通字符,匹配它自身,如[a^b]就是匹配字符a, ^或b。
在字符组中,还可以包含其它字符组,如:[[abc][def]]等同于[abcdef],[a-z&&[^de]]表示匹配的字符是a到z,且不能是d或e。
注意:
排除字符组表示匹配组外的任意一个字符,而不是不能匹配,要表达不能匹配的含义,需要使用后文介绍的环视语法。
4) 预定义字符组
正则语法预定义了一些常用的字符组,简化了其书写,一般以\开头:
| 字符组类型 | 预定义字符组 | 含义 |
|---|---|---|
| 可选字符组 | . | 在默认匹配模式下,匹配除\r、\n外的任意一个字符,如a.f可匹配abf,acf等,但不能匹配a\nf |
\d | d表示digit,匹配任意一个数字字符,等同于[0-9]; | |
\w | w表示word,匹配任意一个单词字符,等同于[a-zA-Z_0-9],类似于Java语言的标识符 | |
\s | s表示space,匹配任意一个空白字符,等同于[ \t\n\x0B\f\r] | |
| 排除字符组 | \D | 匹配任意一个非数字字符,等同于[^0-9]或[^\d] |
\W | 匹配任意一个非单词字符,等同于[^\w] | |
\S | 匹配任意一个非空白字符,等同于[^\s] |
5) POSIX字符组
POSIX字符组是POSIX标准定义的一些字符组,在Java中,这些字符组的形式是\p{...},比如:
| POSIX字符组 | 含义 |
|---|---|
\p{Lower} | 小写字母,等同于[a-z] |
\p{Upper} | 大写字母,等同于[A-Z] |
\p{Digit} | 数字,等同于[0-9] |
\p{Punct} | 标点符号,匹配!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~中的一个 |
POSIX字符组比较多,本文就不列举了。
2. 字符量词
1) 通用量词
字符量词表示左边的字符/字符组/字符分组出现的次数,格式为{m,n},表示最少出现m次,最多出现n次。特殊的,如果n没有限制,可以省略为{m,},如果m和n一样,可以简写为{m}。
| 通用量词 | 含义 |
|---|---|
ab{1,10}c | b可以出现1~10次 |
ab{3}c | b必须是出现3次,即只能匹配abbbc |
ab{0,1}c | b最多出现1次 |
ab{1,}c | b最少出现一次 |
ab{0,}c | b可以出现任意次 |
注意:
字符量词语法必须是严格的{m,n}形式,逗号左右不能有空格。
2) 预定义量词
正则语法预定义了一些常用的量词:
| 预定义量词 | 含义 |
|---|---|
? | 表示最多出现1次,等同于ab{0,1}c,如ab?c,既能匹配abc,也能匹配ac,但不能匹配abbc |
+ | 表示最少出现1次,等同于ab{1,}c,如ab+c,既能匹配abc,也能匹配abbc,但不能匹配ac |
* | 表示出现任意次,等同于ab{0,}c,如ab*c,既能匹配abc,能匹配ac,也能匹配abbbc |
注意:
如果要匹配
?、*、+、{等元字符,需要使用\转义,比如a\*b匹配字符串"a*b"。如果这些量词出现在字符组中,就不是元字符,比如表达式
[?*+{]就是匹配其中一个字符本身。
3) 贪婪与懒惰原则
字符量词默认是贪婪匹配的,即每次尽可能的匹配更多的字符,如<a>.*</a>会匹配整个<a>first</a><a>second</a>字符串,而不是先匹配前面的<a>first</a>部分,再匹配后面的<a>second</a>部分。
如果希望匹配时一旦满足就立即停止,开始新的下一次匹配,应该使用懒惰量词,格式为在量词的后面加一个问号?,即<a>.*?</a>。
其它量词也是类似,都有对应的懒惰形式,如:x??、x*?、 x+?、 x{m,n}?等。
3. 字符分组
1) 分组语法
可以将若干个字符/字符组使用小括号()括起来,表示一个字符分组,如a(bc)d,其中bc就是一个字符分组。它具有以下一些特性:
字符分组可以嵌套,如
a(de(fg)),其中defg字符分组包含fg字符分组。字符分组支持量词,如
a(bc)+d表示bc分组最少出现1次。字符分组拥有编号,如
a(bc)((de)(fg)),按括号出现的顺序,捕获第1~4个分组分别为bc、defg、de和fg,特殊的,第0个分组表示整个字符串abcd。如果分组后续不需要被引用,为了提高性能,可以改为非捕获分组,格式为(?:字符),如(?:abc|def)。字符分组可以命名,命名的格式为
(?<名称>字符),引用的格式为\k<名称>,如<(?<tag>\w+)>(.*)</\k<tag>>,其中第1个分组为\w+,命名为tag,后面使用\k<tag>进行回溯引用。
2) 分组选项
前面章节介绍,使用中括号[]定义字符组,用于匹配可选列表中的任意一个字符。与之类似,也可以定义分组内的多个可选项,匹配其中的任意一个,如(http|ftp|file),使用竖线|分隔后,表示可匹配http或ftp或file。
注意:
注意区分分组选项和字符组,中括号[]和竖线|一起使用并没有特殊含义,如
[a|b]的含义不是匹配a或b,而是a或|或b。特殊的,整个字符串代表第0个分组,因此
ab|cd可匹配ab或cd,无需小括号。
3) 回溯引用
在正则表达式中,可以使用斜杠\加分组编号引用前面捕获的分组,称之为回溯引用,如<(\w+)>(.*)</\1>,其中\1匹配之前的第一个分组(\w+),这个表达式可以匹配类似如下字符串:<title>bc</title>,这里的第一个分组为title。
4. 字符边界
1) 特殊边界匹配(边界符)
在正则表达式中,除了可以匹配字符,还可以匹配字符的边界。如下字符串a cat\n,在每个字符的两边都是边界,在整个字符串两边也有字符串边界,即字符串的开始边界和字符串的结束边界。
对于不匹配特定边界的表达式abc,可两次匹配字符串abcabc,分别为前三个字符和后三个字符,我们可以为它加上一些边界匹配:
| 边界符 | 含义 |
|---|---|
^、\A | 默认匹配模式下,表示整个字符串的开始,如^abc匹配字符串开头处的abc,对于字符串abcabc可匹配前三个字符 |
\z | 默认匹配模式下,表示整个字符串的结束,如abc$匹配字符串结束处的abc,对于字符串abcabc可匹配后三个字符。 |
$、\Z | 与\z类似,但是对回车换行符有一些兼容处理,如abc$也可匹配abcabc\r\n或abcabc\n的后三个abc字符。(注意:如需匹配abcabc\r\n的后5个字符,请使用 abc\r\n$) |
\b | 表示单词边界,其中单词包括\w(a-zA-Z_0-9)和中文字符,如\bcat\b,可匹配cat,但不能匹配category |
注意:
^在字符组开头,表示排除字符组;在表达式开头,用于匹配字符串开始,如^[^abc],表示以一个不是a,b或c的字符开始。
2) 环视边界匹配
环视边界匹配是一种比边界符更为通用的边界匹配方式,要求边界左右必须满足指定的条件,主要分为如下四类:
肯定顺序环视:表示边界右边必须匹配指定的表达式,格式为
(?=表达式)。如abc(?=def)要求该边界右边必须是def,即可匹配abcdef中abc,但不可匹配abcd中的abc。又如(?=.*[A-Z])\w+要求该边界右边存在1个大写字母,如可匹配hello,World,zhangsan中的hello和World。否定顺序环视:表示边界右边不能匹配指定的表达式,格式为
(?!表达式)。如s(?!ing)要求该边界右边不能是ing,即可匹配s和si中的s,但不可匹配sing中的s。肯定逆序环视:表示边界左边必须匹配指定的表达式,格式为
(?<=表达式)。如(?<=\s)abc要求该边界左边必须是空白字符。又如[\w.]+(?<!\.)要求该边界左边不能是点号,即可匹配hello.ma.中的hello.ma,但不包括最后的点号。否定逆序环视:表示边界左边不能匹配指定的表达式,格式为
(?<!表达式)。如(?<!\w)cat要求该边界左边不能是单词字符。
对同一个边界,可以写多个环视匹配,如(?=.*[A-Z])(?=.*[0-9])\w+要求该边界右边至少有一个大写字母和1个数字。
注意:
环视边界匹配使用小括号
(?),不过它不是分组,不占用分组编号。环视边界匹配也被称为边界断言,断言的对象是边界,又因为其不占用字符,没有宽度,因此也被称为零宽度断言。
5. 特殊匹配模式
1) 单行匹配模式(点号匹配模式)
在默认匹配模式下,预定义字符组.匹配除\r、\n外的任意一个字符,如a.f可匹配abf,acf等,但是不能匹配a\nf。
可以通过(?s)前缀,指定点号匹配模式,该模式下,可额外匹配\r和\n,即(?s)a.f可匹配a\nf。
注意:
注意文本换行的格式,
(?s)a.f是不能匹配a\r\nf的,因为它是两个字符。
2) 多行匹配模式(行匹配模式)
在默认匹配模式下,边界符^和$表示整个字符串的开始和结束,如^abc$可匹配abc、abc\r\n等,但是不能匹配abc\r\nabc。
可以通过(?m)前缀,指定多行匹配模式,该模式下,^和$表示行的开始和结束,对于字符串abc\r\nabc,(?m)^abc$就会有两个匹配。
注意:
多行匹配模式和单行匹配模式没有任何的关系。
单行模式影响的是字符组
.的匹配规则,使其可以匹配换行符;多行模式影响的是边界符
^和$的匹配规则,使它们可以匹配行的开始和结束。
3) 大小写匹配模式
在默认匹配模式下,匹配字符时是大小写敏感的,即the只能匹配the,不能匹配The等。
可以通过(?i)前缀,指定大小写不敏感匹配模式,如(?i)the也可以匹配The等。
注意:
上述一些匹配模式不是互斥的关系,可以一起使用,比如
(?smi)表示开启点号匹配、多行匹配、大小写不敏感匹配。
6. 正则语法补充
1) 关于字符转义
字符转义有两种,一种是将普通字符转义,使用具备特殊含义,如'\t', '\n', '\d', '\w', '\b', '\A'等;另一种是将元字符转义,使其变为普通字符,如'.', '*', '\?','(', '\'等。
记住所有的元字符,并在需要的时候进行转义,这是比较困难的,有一个简单的办法,可以将所有元字符看做普通字符,就是在开始处加上\Q,在结束处加上\E,如:\Q(.*+)\E表示匹配(.*+)字符本身。
注意:
正则语法中
\是一个元字符,要匹配斜杠本身,需要转义写成:\\。而在Java字符串中,
\也是一个特殊字符,因此通过字符串字面量写正则表达式时,匹配一个斜杠字符\需要写成:\\\\。
2) 运算符优先级
正则表达式中的运算符具有优先级的概念,优先级高的先处理,相同优先级的从左到右处理,优先级列表从高到低如下:
| 运算符 | 描述 |
|---|---|
\ | 转义符 |
()、(?:)、(?=)、[] | 圆括号,方括号 |
*、+、?、{n}、{n,}、{n,m} | 字符量词 |
^、$、\w等、a等 | 边界符,转义字符,普通字符 |
| | 字符分组中的”或“操作,如ab|cd、(m|f)ood |
7. Java正则API
1) 正则API概述
正则表达式编译和匹配相关的类位于java.util.regex包下,主要为Pattern和Matcher两个类。
Pattern:表示正则表达式对象,它与要处理的具体字符串无关;
Matcher:表示一个匹配,它将正则表达式应用于一个具体字符串,通过它对字符串进行处理。
121// 正则表达式(字符串形式)2String regex = "<(\\w+)>(.*)</\\1>";3
4// 预编译正则表达式:字符串形式 -> 对象形式(有穷自动机)5Pattern pattern = Pattern.compile(regex);6
7// 指定匹配模式8Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE | Pattern.DOTALL | Pattern.MULTILINE)9
10// Pattern.LITERAL模式:元字符将失去特殊含义,被看做普通字符,等效于左右两边分别加上\Q和\E11String quote = Pattern.quote("\\d{6}"); // \Q\d{6}\E12
注意:
在Java中,没有什么特殊的语法能直接表示正则表达式,需要用字符串表示。
特殊的,反斜杠
\在正则语法中和Java字符串中都是特殊字符,因此匹配\本身需要使用"\\"字符串。Pattern是线程安全的,为节省编译成本,推荐将正则表达式对象通过预编译的方式进行共享。
2) 字符串切分
String类中有split方法可切分字符串,传入的是一个正则表达式:
321// 1. 方法声明2public String[] split(String regex) // 返回切分后的字符串数组,如果找不到匹配regex的分隔符,则返回原字符串(szie=1)3public String[] split(String regex, int limit) // limit-限定切分的数目4
5// 2. 通过普通字符切分6String str = "abc,def,hello";7String[] fields = str.split(","); // [abc, def, hello]8
9// 3. 通过正则表达式切分10String str = "abc def hello.\n world";11String[] fields = str.split("[\\s.]+"); // [abc, def, hello, world]12
13// 4. 注意转义元字符(如. $ | ( ) [ { ^ ? * + \等)14// 注意:如果分隔符是用户指定的,程序事先不知道,可以通过Pattern.quote()将其看做普通字符串15String[] fields = str.split("\\."); 16
17// 5. 注意尾部空白字符(尾部的空白字符串不会包含在返回的结果数组中,但头部和中间的空白字符串会被包含在内)18String str = ",abc,,def,,";19String[] fields = str.split(","); // [, abc, , def]20
21// 6. 关于limit参数的使用22String str = "a:b:c:";23String[] fields = str.split(":", 0); // 默认值,切分为[a, b, c],数组长度为3,丢弃尾部空白字符串24String[] fields = str.split(":", 2); // 切分为[a, b:c:],先切分limit-1个,最后一个元素包含剩余的所有内容25String[] fields = str.split(":", 3); // 切分为[a, b, c:],先切分limit-1个,最后一个元素包含剩余的所有内容26String[] fields = str.split(":", 4); // >=4或<0时,切分为[a, b, c, ],包含尾部空白字符串。27
28// 7. Pattern的split方法29// 接受CharSequence类型参数,更为通用(String/StringBuilder/StringBuffer/CharBuffer都实现了该接口)30public String[] split(CharSequence input)31public String[] split(CharSequence input, int limit)32
注意:
如果regex是一个普通字符(非元字符),优先选用String的split方法,它会采用更为简单高效的实现。
如果regex是多个字符或包含元字符,优先选用Pattern的split方法,并进行预编译节省编译成本。
3) 字符串验证
字符串验证就是检验输入文本是否完整匹配预定义的正则表达式,经常用于检验用户的输入是否合法。
141// 1. String类的matches方法2public boolean matches(String regex) 3
4// 示例:检测是否为8位数字5String str = "12345678";6System.out.println(str.matches("\\d{8}")); // true7
8// 2. Pattern的matches方法(静态)9public static boolean matches(String regex, CharSequence input) {10 Pattern p = Pattern.compile(regex); // 编译11 Matcher m = p.matcher(input); // 获取匹配器Matcher12 return m.matches(); // 匹配13}14
4) 字符串查找
字符串查找就是在文本中寻找匹配正则表达式的子字符串。
121public static void find() {2 String regex = "\\d{4}-\\d{2}-\\d{2}"; // 格式为“4位数字-2位数字-2位数字”,如2017-06-023 Pattern pattern = Pattern.compile(regex); // 编译4 String str = "today is 2017-06-02, yesterday is 2017-06-01"; // 原字符串5 Matcher matcher = pattern.matcher(str); // 获取匹配器6
7 // 遍历匹配器8 while (matcher.find()) {9 System.out.println("find " + matcher.group() + " position: " + matcher.start() + "-" + matcher.end()); // find 2017-06-02 position: 9-19 \n find 2017-06-01 position: 34-4410 }11}12
上述示例中的Matcher为正则匹配器,内部记录有一个位置,起始为0,find()方法从这个位置查找匹配正则表达式的子字符串,找到后,返回true,并更新这个内部位置,匹配到的子字符串信息可以通过如下方法获取:
31public String group() // 匹配到的完整子字符串2public int start() // 子字符串在整个字符串中的起始位置3public int end() // 子字符串在整个字符串中的结束位置加1其中group()其实调用的是group(0),表示获取匹配的第0个分组的内容。我们在上节介绍过捕获分组的概念,分组0是一个特殊分组,表示匹配的整个子字符串。除了分组0,Matcher还有如下方法,获取分组的更多信息:
51public int groupCount() // 分组个数2public String group(int group) // 分组编号为group的内容3public String group(String name) // 分组命名为name的内容4public int start(int group) // 分组编号为group的起始位置5public int end(int group) // 分组编号为group的结束位置加1示例代码如下:
121public static void findGroup() {2 String regex = "(\\d{4})-(\\d{2})-(\\d{2})"; // 具有3个分组的正则表达式3 Pattern pattern = Pattern.compile(regex);4 String str = "today is 2017-06-02, yesterday is 2017-06-01";5 Matcher matcher = pattern.matcher(str);6
7 // 遍历匹配器8 while (matcher.find()) {9 System.out.println("year:" + matcher.group(1) + ",month:" + matcher.group(2) + ",day:" + matcher.group(3)); // year:2017,month:06,day:02 \n year:2017,month:06,day:0110 }11}12
5) 字符串替换
查找到子字符串后,一个常见的后续操作是替换。
131// 1. String类的普通替换方法2public String replace(char oldChar, char newChar) // 替换单个字符(无正则参数)3public String replace(CharSequence target, CharSequence replacement) // 替换CharSequence(无正则参数)4 5// 2. String类的正则替换方法6public String replaceAll(String regex, String replacement) // 替换所有找到的子字符串7public String replaceFirst(String regex, String replacement) // 只替换第一个找到的子字符串8
9// 示例10String regex = "\\s+";11String str = "hello world good";12System.out.println(str.replaceAll(regex, " ")); // hello world good13System.out.println(str.replaceFirst(regex, " ")); // hello world good在replaceAll和replaceFirst中,参数replacement也不是被看做普通的字符串,可以使用美元符号加数字的形式,比如$1,引用捕获分组。
31String regex = "(\\d{4})-(\\d{2})-(\\d{2})"; // 具有3个分组的正则表达式2String str = "today is 2017-06-02.";3System.out.println(str.replaceFirst(regex, "$1/$2/$3")); // today is 2017/06/02.如果需要替换为字符'$'本身,需要使用转义:
31String regex = "#";2String str = "#this is a test";3System.out.println(str.replaceAll(regex, "\\$")); // $this is a test如果替换字符串是用户提供的,为避免元字符的的干扰,可以使用Matcher的如下静态方法将其视为普通字符串:
11public static String quoteReplacement(String s)String的replaceAll和replaceFirst调用的其实是Pattern和Matcher中的方法,比如,replaceAll的代码为:
41public String replaceAll(String regex, String replacement) {2 return Pattern.compile(regex).matcher(this).replaceAll(replacement);3}4
6) 边查找边替换
replaceAll和replaceFirst都定义在Matcher中,除了一次性的替换操作外,Matcher还定义了边查找、边替换的方法:
21public Matcher appendReplacement(StringBuffer sb, String replacement)2public StringBuffer appendTail(StringBuffer sb)这两个方法用于和find()一起使用,我们先看个例子:
181public static void replaceCat() {2 Pattern p = Pattern.compile("cat");3 Matcher m = p.matcher("one cat, two cat, three cat");4 StringBuffer sb = new StringBuffer();5 int foundNum = 0;6
7 // 遍历匹配器8 while (m.find()) {9 m.appendReplacement(sb, "dog"); // 替换当前匹配的子字符串,并追加新扫描字符串段到sb中10 foundNum++;11 if (foundNum == 2) { // 替换两次后就退出12 break;13 }14 }15 m.appendTail(sb); // 追加剩余未扫描字符串段到sb中16 System.out.println(sb.toString()); // one dog, two dog, three cat17}18
上述示例中,Matcher内部除了有一个查找位置,还有一个append位置,初始为0,当找到一个匹配的子字符串后,appendReplacement方法做了三件事情:
将append位置到当前匹配之前的子字符串append到sb中,在第一次操作中,为"one ",第二次为", two ";
将替换字符串append到sb中;
更新append位置为当前匹配之后的位置。
appendTail将append位置之后所有的字符append到sb中。
7) 模板引擎
利用正则表达式,我们可以实现一个简单的模板引擎:
271// 预编译2private static Pattern templatePattern = Pattern.compile("\\{(\\w+)\\}"); // 如{userId}3
4// 模板引擎(正则替换指定格式字符串)5public static String templateEngine(String template, Map<String, Object> params) {6 StringBuffer sb = new StringBuffer();7 Matcher matcher = templatePattern.matcher(template);8
9 // 遍历匹配器10 while (matcher.find()) {11 String key = matcher.group(1); // 分组112 Object value = params.get(key);13 matcher.appendReplacement(sb, value != null ? Matcher.quoteReplacement(value.toString()) : "");14 }15 matcher.appendTail(sb);16 return sb.toString();17}18
19// 测试20public static void templateDemo() {21 String template = "Hi {name}, your code is {code}.";22 Map<String, Object> params = new HashMap<>();23 params.put("name", "老马");24 params.put("code", 6789);25 System.out.println(templateEngine(template, params)); // Hi 老马, your code is 6789.26}27
8. Java正则示例
对于同一个目的,正则表达式往往有多种写法,且大多没有唯一正确的写法,本节的写法主要是示例。
此外,写一个正则表达式,匹配希望匹配的内容往往比较容易,但让它不匹配不希望匹配的内容,则往往比较困难,也就是说,保证精确性经常是很难的。
不过,很多时候,我们也没有必要写完全精确的表达式,需要写到多精确与你需要处理的文本和需求有关,另外,正则表达式难以表达的,可以通过写程序进一步处理。
1) 邮编
161// 预编译2public static Pattern ZIP_CODE_PATTERN = Pattern.compile(3 "(?<![0-9])" // 左边不能有数字4 + "[0-9]{6}" // 6位数字5 + "(?![0-9])"); // 右边不能有数字6
7// 验证8System.out.println(ZIP_CODE_PATTERN.matcher("000222").matches()); // true9System.out.println(ZIP_CODE_PATTERN.matcher("18975865155").matches()); // false10
11// 查找12Matcher matcher = ZIP_CODE_PATTERN.matcher("邮编 100013,电话18612345678");13while (matcher.find()) {14 System.out.println(matcher.group()); // 10001315}16
2) 电话号码
141// 手机2public static Pattern MOBILE_PHONE_PATTERN = Pattern.compile(3 "(?<![0-9])" // 左边不能有数字4 + "((0|\\+86|0086)\\s?)?" // 0 +86 00865 + "1[34578][0-9]-?[0-9]{4}-?[0-9]{4}" // 186-1234-56786 + "(?![0-9])"); // 右边不能有数字7 8// 固话9public static Pattern FIXED_PHONE_PATTERN = Pattern.compile(10 "(?<![0-9])" // 左边不能有数字11 + "(\\(?0[0-9]{2,3}\\)?-?)?" // 区号,3到4位,以0开头,可能用括号包含,是可选的,与市内号码之间可能有连字符12 + "[0-9]{7,8}"// 市内号码,7到8位,13 + "(?![0-9])"); // 右边不能有数字14
3) 日期
71public static Pattern DATE_PATTERN = Pattern.compile(2 "(?<![0-9])" // 左边不能有数字3 + "\\d{4}-" // 年,年月日之间用连字符分隔4 + "(0?[1-9]|1[0-2])-" // 月,1~12,月和日可能只有一位5 + "(0?[1-9]|[1-2][0-9]|3[01])"// 日,1~316 + "(?![0-9])"); // 右边不能有数字7
4) 时间
61public static Pattern TIME_PATTERN = Pattern.compile(2 "(?<![0-9])" // 左边不能有数字3 + "([0-1][0-9]|2[0-3])" // 小时,0~23,考虑24小时制,只考虑小时和分钟,小时和分钟都用固定两位表示4 + ":" + "[0-5][0-9]"// 分钟,0~595 + "(?![0-9])"); // 右边不能有数字6
5) 身份证
身份证有一代和二代之分,一代是15位数字,二代是18位,都不能以0开头,对于二代身份证,最后一位可能为x或X,其他是数字。
61public static Pattern ID_CARD_PATTERN = Pattern.compile(2 "(?<![0-9])" // 左边不能有数字3 + "[1-9][0-9]{14}" // 一代身份证4 + "([0-9]{2}[0-9xX])?" // 二代身份证多出的部分,5 + "(?![0-9])"); // 右边不能有数字6
6) IP地址
101// 点号分隔,4段数字,每个数字范围是0到2552// 值是1位数,前面可能有0到2个0;3// 值是两位数,前面可能有一个0;4// 值是三位数,以1开头的,后两位没有限制,以2开头的,如果第二位是0到4,则第三位没有限制,如果第二位是5,则第三位取值为0到55public static Pattern IP_PATTERN = Pattern.compile(6 "(?<![0-9])" // 左边不能有数字7 + "((0{0,2}[0-9]|0?[0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}" // 前3段8 + "(0{0,2}[0-9]|0?[0-9]{2}|1[0-9]{2}|2[0-4][0-9]|25[0-5])" // 第4段,注意不能使用\2回溯引用9 + "(?![0-9])"); // 右边不能有数字10
7) URL
URL的格式比较复杂,其规范定义在https://tools.ietf.org/html/rfc1738,我们只考虑http协议,其通用格式是:
http://<host>:<port>/<path>?<searchpart>。
开始是http://,接着是主机名,主机名之后是可选的端口,再之后是可选的路径,路径后是可选的查询字符串,以?开头。
121// http://www.example.com2// http://www.example.com/ab/c/def.html3// http://www.example.com:8080/ab/c/def?q1=abc&q2=def4public static Pattern HTTP_PATTERN = Pattern.compile(5 "http://" + "[-0-9a-zA-Z.]+" // 主机名,可以是字母、数字、减号和点号6 + "(:\\d+)?" // 端口7 + "(" // 可选的路径和查询 - 开始8 + "/[-\\w$.+!*'(),%;:@&=]*" // 第一层路径9 + "(/[-\\w$.+!*'(),%;:@&=]*)*" // 可选的其他层路径10 + "(\\?[-\\w$.+!*'(),%;:@&=]*)?" // 可选的查询字符串11 + ")?"); // 可选的路径和查询 - 结束 12
8) Email
完整的Email规范比较复杂,定义在https://tools.ietf.org/html/rfc822,我们先看一些实际中常用的。
251// 新浪邮箱:用户名要求是4-16个字符,可使用英文小写、数字、下划线,但下划线不能在首尾2// abc@sina.com3public static Pattern SINA_EMAIL_PATTERN = Pattern.compile(4 "[a-z0-9]" 5 + "[a-z0-9_]{2,14}"6 + "[a-z0-9]@sina\\.com"); 7
8// QQ邮箱9public static Pattern QQ_EMAIL_PATTERN = Pattern.compile(10 "(?![-0-9a-zA-Z._]*(--|\\.\\.|__))" // 点、减号、下划线不能连续出现两次或两次以上11 + "[a-zA-Z]" // 必须以英文字母开头12 + "[-0-9a-zA-Z._]{1,16}" // 3-18位 英文、数字、减号、点、下划线组成13 + "[a-zA-Z0-9]@qq\\.com"); // 由英文字母、数字结尾 14 15// 通用邮箱:以@作为分隔符,前面是用户名,后面是域名16// 用户名一般由英文字母、数字、下划线、减号、点号组成,至少1位,不超过64位,开头不能是减号、点号和下划线17// 域名部分以点号分隔为多个部分,至少有两个部分,最后一部分是顶级域名,由2到3个英文字母组成18// 对于域名的其他点号分隔的部分,每个部分一般由字母、数字、减号组成,但减号不能在开头,长度不能超过63个字符19// h_llo-abc.good@example.com20public static Pattern GENERAL_EMAIL_PATTERN = Pattern.compile(21 "[0-9a-zA-Z][-._0-9a-zA-Z]{0,63}" // 用户名22 + "@"23 + "([0-9a-zA-Z][-0-9a-zA-Z]{0,62}\\.)+" // 域名部分24 + "[a-zA-Z]{2,3}"); // 顶级域名 25
9) 中文字符
41// 中文字符的Unicode编号一般位于\u4e00和\u9fff之间2public static Pattern CHINESE_PATTERN = Pattern.compile(3 "[\\u4e00-\\u9fff]");4