第01篇_Java基础
第01章_基础语法
第一节 快速入门
1. Java语言简介
Java语言是美国Sun公司在1995年推出的高级编程语言,主要应用于企业应用开发,如商城系统、物流系统、网银系统等。
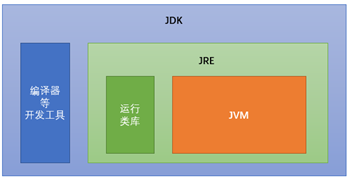
2. JDK/JRE与JVM
JDK (Java Development Kit):指Java程序开发工具包,包含JRE和开发人员使用的一些工具(如:javac、javap、jconsole等)。
JRE(Java Runtime Environment):指Java程序的运行时环境,包含JVM和运行时所需要的核心类库。
JVM(Java Virtual Machine):指Java虚拟机,用于运行 Java 字节码,常见的有HotSpot JVM、GraalVM、Android Runtime (ART)等。
扩展:
HotSpot JVM 分为 Oracle HotSpot JVM 和 OpenJDK HotSpot JVM ,后者又衍生了一些发行版,如:BishengJDK。
OpenJDK 是完全开源免费的,而Oracle JDK 是商业收费的,JDK8u221 是其最后一个永久免费版本,后续版本只免费使用3年。
3. 安装JDK
x1# 1. 下载安装包2https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html3> jdk-11.0.16_linux-x64_bin.tar.gz4
5# 2. 解压到指定目录6tar -zxvf jdk-11.0.16_linux-x64_bin.tar.gz -C /usr/local7
8# 3. 配置3个系统变量9$ vim /etc/profile10export JAVA_HOME=/usr/local/jdk-11.0.1611export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar12export PATH=$PATH:$JAVA_HOME/bin13
14# 4. 加载系统变量15$ source /etc/profile16
17# 5. 验证18java -version19
4. HelloWorld案例
1) 编写源文件
新建HelloWorld.java文件,输入以下代码:
61public class HelloWorld {2 public static void main(String[] args) { 3 System.out.println("Hello World!"); 4 } 5}6
注意:
这里的文件名必须和类名一致,注意大小写。
2) 编译源文件
使用javac命令对源文件进行编译,如果编译成功,将会生成一个HelloWorld.class字节码文件。
11javac HelloWorld.java
3) 运行字节码
使用java命令进行运行,注意文件名不要加.class后缀。
11java HelloWorld
5. 面试补充
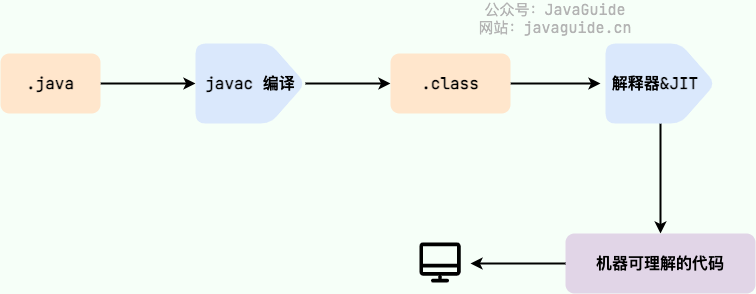
1) 编译流程
Java源文件经过javac命令编译后,生成.class字节码文件,字节码文件可被虚拟机解释执行。
扩展:
使用字节码的好处:在一定程度上解决了解释型语言执行效率低的问题,又保留了解释型语言可移植的特点。
2) JIT和AOT
JIT(Just in Time Compilation):运行时编译,在第一次编译后,将字节码对应的机器码保存下来,下次可以直接使用。
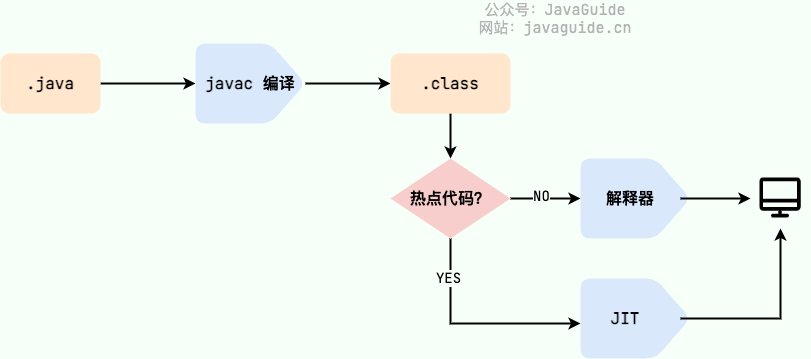
AOT(Ahead of Time Compilation):提前编译,在程序被执行前就将其编译成机器码,属于静态编译。
可以提高 Java 程序的启动速度,减少内存占用和增强 Java 程序的安全性(反编译难),特别适合云原生场景。
无法支持 Java 的一些动态特性,如反射、动态代理、动态加载、JNI(Java Native Interface)等。
3) Java vs C++
Java 和 C++ 都是面向对象的语言,都支持封装、继承和多态。
Java 有自动内存管理和垃圾回收机制,C++ 通过指针访问内存。
Java 类不支持多继承,只有接口能够支持多继承。
Java泛型的本质是“类型擦除”,而C++模板的本质是“编译时展开”。
Java 不支持操作符重载、友元、宏函数等复杂特性。
第二节 数据类型
1. 数据类型分类
在Java中,提供了四类八种基本数据类型,分别是:
整型:从小到大又可区分为
字节型(byte)、短整型(short)、整型(int)、长整型(long)四种,分别占用1、2、4、8个字节。浮点型:有
单精度浮点型(float)和双精度浮点型(double)两种,分别占用4和8个字节,默认的浮点型变量是double类型。字符型:只有
char一种,其采用unicode方式编码,占用两个字节,取值范围为0-65535。布尔型:布尔型变量(boolean)只有
true和false两种值,占用一个字节,用来表示真或假。
引用数据类型包含基本数据类型之外的所有类型,如字符串、类、数组、接口、lamda表达式等。
211// 案例:定义不同类型的变量,并使用字面量进行赋值2public class Variable {3 public static void main(String[] args){ 4 // 整型5 byte b = 100; // 字节型 6 short s = 1000; // 短整型 7 int i = 123456; // 整型 8 long l = 12345678900L; // 长整型 9 10 // 浮点型11 float f = 5.5F; // 单精度浮点型 12 double d = 8.5; // 双精度浮点型 13 14 // 布尔型15 boolean bool = false; 16 17 // 字符型18 char c = 'A'; 19 } 20}21
提示:
字面量除了上述各种基本类型的值外,还有
字符串和null值两种。成员变量具有默认值,但局部变量必须初始化后才能使用,否则会出现编译错误。
2. 数据类型转换
参与的计算的数据,必须要保证数据类型的一致性,否则将发生类型的转换,转换可分为:
自动类型转换:将取值范围小的类型自动提升为取值范围大的类型。
强制类型转换:一般是将取值范围大的类型强制转换成取值范围小的类型,但可能会造成精度损失或数据溢出等。
101public static void main(String[] args) {2 // 小类型->大类型,自动类型转换3 long l = 100;4 float n = 30L;5 double d = 2.5F;6
7 // 大类型->小类型,强制类型转换8 int i1 = (int) 1.5; // 1,精度损失9 int i2 = (int) 6000000000L; // 1705032704,发生了数据溢出10}特殊的,对于byte 、short、char类型,在赋值时,如果右边为不超过取值范围的常量,则编译器会自动补上强制类型转换,在参与运算时,至少会被提升为int类型。
141public static void main(String[] args) {2 // 赋值时的常量优化3 byte b1 = 30; // 不超过范围,自动补充强制类型转换4 byte b2 = 128; // 编译错误,超过范围5 byte b6 = b1 + 1; // 编译错误,右边不是常量6
7 // 运算时提升为int8 short s1 = 1;9 short s2 = 2;10 short s3 = s1 + s2; // 编译失败,因为运算结果为int,不能赋值给更小的类型11 int i = s1 + s2; // 编译成功12 s3 = (short) (s1 + s2); // 编译成功13}14
3. 关于字符编码问题
字符编码大致可分为Unicode编码和非Unicode编码,不同编码对应了不同的存储格式:
1) Unicode编码
Unicode编码为全球约110万字符分配的的唯一数字编号,编号范围为ox0000~0x10FFFF。
大部分常见的字符都在ox0000~0xFFFF之间,大部分常见的中文字符在ox4E00~ox9FFF之间,如"马"的Unicode编码为U+9A6C。
Unicode编码只是给字符编号,但未说明其二进制形式的编号如何存储,存储方式主要有如下三种:
UTF-32:所有字符以 4 字节存储,非常浪费空间,使用较少。
UTF-16:小编号字符(U+0000~U+FFFF)使用两字节存储,大编号字符(U+10000~U+10FFFF)使用四字节存储,但依然浪费空间。
UTF-8:灵活采用1~4个字节进行存储,使用最为广泛。例如"马"的Unicode编号为U+9A6C,对应的二进制值是1001 101001 101100,格式为三字节格式,因此UTF-8编码为11101001 10101001 10101100,十六进制表示为0xE9A9AC。
编号在0x00~0x7F(0~127)之间的使用单字节存储,兼容ASCII码,格式为0xxxxxxx;
编号在0x80~0x7FF(128~2047)之间的使用双字节存储,格式为110xxxxx 10xxxxxx;
编号在0x800~0xFFFF(2048~65535)之间的使用三字节存储,格式为1110xxxx 10xxxxxx 10xxxxxx;
编号在0x10000~0x10FFFF(65536及以上)之间的使用四字节存储,格式为11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。
提示:
如果第一个字节存储二进制编号的最高位则称为"大端"字节序,如果存储最低位则称为"小端"字节序。
UTF-8-BOM:默认情况下,文件不会声明自身的编码格式,但UTF-8编码的文本文件,可以设置前三个字节为
0xEF0xBB0xBF来表示当前文件为UTF-8文件,这三个字节被称为BOM(ByteOrder Mark)头,支持UTF-8-BOM格式的文件编辑器可自动识别。
2) 非Unicode编码
ASCII:中文名称为“美国信息互换标准代码”,单字节编码,最高位固定为0,剩余7位可表示127个符号。其中用第32-126位表示可打印字符,第0-31和127位表示不可打印字符(一般用于控制目的)。ASCII码是最基本的编码,其它非Unicode编码和UTF-8编码都兼容它。
ISO-8859-1(Latin-1):单字节编码,256个字符,第0-127与ASCII码兼容,第128-159表示一些控制字符,160-255表示一些西欧字符。
Windows-1252:单字节编码,是ISO-8859-1的替代版本,将128-159位修改为了一些常用的可打印字符。注意:平时所说的ISO-8859-1编码实际上就是Windows-1252编码。
GB2312:双字节编码,如果两个字节最高位都为0则表示ASCII码,如果都为1则表示中文字符,高位字节范围是
0xA1~0xF7,低位字节范围是0xA1~0xFE,包括约7000个汉字和一些罕用词和繁体字。GBK:双字节编码,在GB2312的基础上发展而来,高位字节范围是
0x81~0xFE,低位字节范围是0x40~0x7E和0x80~0xFE,额外添加了14000多个中文字符(注意:低字节从0x40开始的,中文字符的低字节最高位有可能为0,因此解析二进制时如果碰到最高位为1的字符,则将连续的两个字节视为一个字符,下一个字符从第三个字节开始解析)。GB18030:二/四字节编码,在GBK的基础上发展而来,额外添加了55000多个字符,包括了很多少数民族字符以及中日韩统一字符。它的二字节编码与GBK一致,四字节编码中,第一/三字节的值为0x81~0xFE,第二/四字节的值为0x30~0x39。在解析二进制时,如果判断第二个字节范围为0x30~0x39,则将连续的四个字节视为一个字符,下一个字符从第五个字节开始解析。
Big5:双字节编码,高位字节范围是0x81~OxFE,低位字节范围是0x40~0x7E和0xA1~0xFE,包括13000多个繁体字,广泛用于我国台湾地区和我国香港特别行政区等地。
3) 乱码原因
字符乱码主要有两种原因:
使用了错误的编码进行解析:例如使用UTF-8编码存储的文件使用GBK格式解析查看,就可能出现乱码,这时候,只需要切换正确的编码查看格式就可以解决乱码问题了。
错误的解析和编码转换:一些程序为了方便统一处理,经常会将所有编码转换为同一种格式(最常用的为UTF-8),在转换的时候需要知道原来的编码是什么,但可能会搞错,一旦搞错,就会将二进制弄乱,这时候使用任何编码查看都不管用了。
4) Java内部字符处理
在Java内部(内存中)进行字符处理时,采用的都是Unicode编码,具体编码格式是UTF-16BE。
进行字符处理时的基础类型是char,其它的Character、String、StringBuilder都是基于char类型的。
char本质上是一个固定占用两个字节的无符号正整数,这个正整数对应于Unicode编号,用于表示那个Unicode编号对应的字符。
由于char固定占用两个字节,只能表示Unicode编号在65536以内的字符,而不能表示超出范围的字符,超出范围的字符得使用两个char。
51char c = 'A'; // 将'A'的Unicode编号(0x65)赋值给变量c2char c = '马'; // 将'马'的Unicode编号(0x9a6c)赋值给变量c3char c = 0x9a6c; // 将Unicode编号0x9a6c('马')赋值给变量c4char c = 39532; // 将Unicode编号39532('马')赋值给变量c5char c = '\u9a6c'; // 将Unicode编号\u9a6c('马')赋值给变量c注意:
如果使用字面量
'马'进行赋值,使用不同的编码格式打开文件可能看到不同的显示效果。推荐JAVA文件采用UTF-8格式,并采用UTF-8格式进行编译。
4. 关于浮点数精度丢失问题
浮点数在转换为二进制时,可能出现无限循环,如 0.2 -> 001100110011...,因此存储时可能会被截断,出现精度损失:
71// 乘2取整法20.2 * 2 = 0.4 -> 030.4 * 2 = 0.8 -> 040.8 * 2 = 1.6 -> 150.6 * 2 = 1.2 -> 160.2 * 2 = 0.4 -> 0(发生循环)7...当浮点数进行运算时,就可能出现下面情况:
51float a = 2.0f - 1.9f;2float b = 1.8f - 1.7f;3System.out.printf("%.9f",a);// 0.1000000244System.out.println(b);// 0.0999999055System.out.println(a == b);// false此时,可以考虑使用 BigDecimal 或 Long 类型(放大N倍)来存储浮点数。
第三节 运算符
1. 支持的运算符
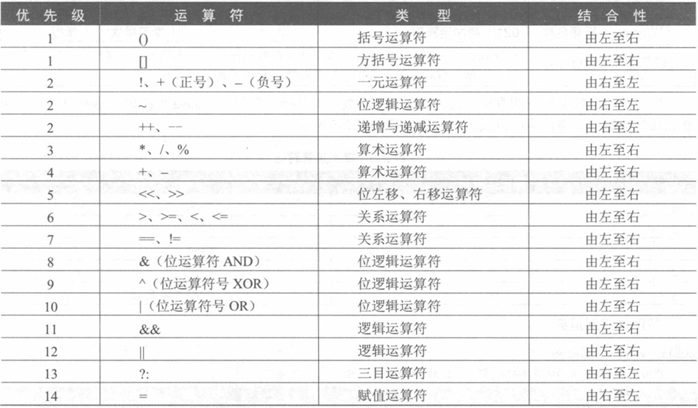
2. 移位运算符
移位运算符将被操作的数据被视为二进制数,移位就是将其向左或向右移动若干位的运算。
<<:左移运算符,向左移若干位,高位丢弃,低位补零。x << n,相当于 x 乘以 2 的 n 次方(不溢出的情况下)。>>:带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。x >> n,相当于 x 除以 2 的 n 次方。>>>:无符号右移,忽略符号位,空位都以 0 补齐。
它的优点是高效(移位操作对应硬件指令,一般只需要一个时钟周期)和节省内存(使用一个整数来存储多个布尔值或标志位),应用场景如:优化乘2或除2操作、使用 int 或 long 存储多个标志位、哈希算法等。
注意:
如果移位位数大于32位(int)/64位(long),则会对位数取余,例如:
int x = 1; x<<42;等同于x<<10。
3.注意事项
整数的除法运算,将会丢弃余数,例如
1/2=0。负数的取余运算,结果的正负始终与前一个操作数相同,例如
-3%2==-1,3%-2==1。复合赋值运算符中隐含了一个强制类型转换,例如
short s = 1; s = s + 1;会报错,而s += 1;却不会。【重要】对于&和|运算符,如果两边为
布尔型,则执行不短路的逻辑运算,如果为int型,则执行按位与和按位或。
第四节 流程控制
1. 分支语句
301//if语句2public static void main(String[] args) {3 int score = 79;4 if (score < 60) {5 System.out.println("不及格");6 } else if (score < 80) {7 System.out.println("及格");8 } else {9 System.out.println("优秀");10 }11}12
13// switch语句14public static void main(String[] args) {15 String level = "及格";16 switch (level) {17 case "不及格":18 System.out.println("score<60分");19 break;20 case "及格":21 System.out.println(" score>=60分且score<80分");22 break;23 case "优秀":24 System.out.println("score>=80分");25 default:26 System.out.println("输入错误!");27 break;28 }29}30
注意:
switch语句支持的数据类型有
整型、字符串、枚举。如果case语句的后面不写break语句,将出现穿透现象。
2. 循环语句
241// for循环2public static void main(String[] args) {3 for (int i = 0; i < 5; i++) {4 System.out.println("i = " + i);5 }6}7 8// while循环 9public static void main(String[] args) {10 int i = 0;11 while (i < 5) {12 System.out.println("i = " + i);13 i++;14 }15}16
17// do-while循环18public static void main(String[] args) {19 int i = 0;20 do {21 System.out.println("i = " + i);22 i++;23 } while (i < 5);24}提示:
do-while循环至少会被执行一次,可以用do{}while(flase)来实现goto语句。
3. break和continue
break可用于跳出本层循环或结束switch语句,continue可用于结束本次循环。
221// break2public static void main(String[] args) {3 for (int i = 1; i<=10; i++) {4 // 打印完两次HelloWorld之后结束循环5 if(i == 3){6 break;7 }8 System.out.println("HelloWorld"+i);9 }10}11
12// continue13public static void main(String[] args) {14 for (int i = 1; i <= 10; i++) {15 // 不打印第三次HelloWorld16 if(i == 3){17 continue;18 }19 System.out.println("HelloWorld"+i);20 }21}22
第五节 数组
1. 数组的基本使用
411public class ArrayTest {2 public static void main(String[] args) {3 // 1. 定义Integer数组 (int数组后面不好降序排序)4 Integer[] arr = {2, 34, 35, 4, 657, 8, 69, 9};5 Integer[] arr2 = {2, 34, 35, 4, 657, 8, 69, 9};6
7 // 2. 打印数组地址值8 System.out.println(arr); // [I@2ac1fdc49
10 // 2. toString11 System.out.println(Arrays.toString(arr)); // [2, 34, 35, 4, 657, 8, 69, 9]12
13 // 3. 排序、并行排序14 Arrays.sort(arr); // 默认升序(按字典)15 Arrays.sort(arr2, Collections.reverseOrder()); // 降序16 Arrays.sort(arr, (o1, o2) -> o2 - o1); // 降序17 Arrays.parallelSort(arr2); // 并行排序18
19 // 4. 比较数组是否相等20 // 数组元素逐个比较, 注意区分:arr.equals(arr2)比较的是地址21 boolean isSame = Arrays.equals(arr, arr2);22
23 // 5. 二分查找24 // 查到了返回索引位置(>=0),未查找返回-插入点-1(<0)25 int index = Arrays.binarySearch(arr, 3); // -226
27 // 6. 拷贝数组28 Integer[] copyArr = Arrays.copyOf(arr, arr.length + 1); // 第二个参数为新数组长度29 Integer[] copyArr1_3 = Arrays.copyOfRange(arr, 1, 3); // 拷贝索引1-3的两个元素30
31 // 7. 填充元素32 Arrays.fill(arr, 0); // arr -> [0, 0, 0, 0, 0, 0, 0, 0]33
34 // 8. 转换为List(只读)35 List<Integer> integerList = Arrays.asList(arr2);36
37 // 9. 转化为Stream38 Stream<Integer> integerStream = Arrays.stream(arr2);39 }40}41
2. 多维数组
181public static void main(String[] args) {2 // 二维数组3 int[][] arr = new int[2][3];4 for (int i = 0; i < arr.length; i++) {5 for (int j = 0; j < arr[i].length; j++) {6 arr[i][j] = i + j;7 }8 }9
10 // 三维数组11 int[][][] arr02 = new int[10][10][10];12
13 // 多维数组本质上还是一维数组,只是一位数组的元素又是一个数组,并且这些子数组的长度可以不相同14 int[][] arr03 = new int[2][];15 arr03[0] = new int[3];16 arr03[1] = new int[5];17}18
3. Arrays工具类
java.util.Arrays 类包含用来操作数组的各种方法,比如排序和搜索等。其所有方法均为静态方法,调用起来非常简单。
171public static void main(String[] args) {2 // 定义Integer数组 (int数组后面不好降序排序)3 Integer[] arr = {2, 34, 35, 4, 657, 8, 69, 9};4
5 // 打印数组地址值6 System.out.println(arr); // [I@2ac1fdc47
8 // 打印数组内容9 System.out.println(Arrays.toString(arr)); // [2, 34, 35, 4, 657, 8, 69, 9]10
11 // 排序 12 Arrays.sort(arr); // 默认升序13 Arrays.sort(arr, (o1, o2) -> o2 - o1); // 降序14
15 System.out.println("排序后:" + Arrays.toString(arr)); // 排序后:[657, 69, 35, 34, 9, 8, 4, 2]16}17
第六节 方法
1. 方法的基本使用
101// 定义 2public static void method01() {3 System.out.println("method01......"); 4}5
6public static void main(String[] args) {7 // 调用 8 method01();9}10 注意:
通过
static关键字可以定义静态方法,静态方法属于类,可通过类名或对象调用。静态方法只能访问静态方法和静态变量,而实例方法则没有这个限制。
2. 方法重载
方法重载是指在同一个类中,允许存在一个以上的同名方法,只要它们的参数列表不同即可。参数列表不同可以是参数个数不同、参数类型不同和参数的顺序不同三种形式。
41// 参数顺序不同2public void open(double a,int b){} 3public void open(int a,double b){} 4
注意:方法重载与参数的名称以及返回值类型无关。
3. 可变参数
方法的最后一个参数可以定义为可变参数,同时支持数组和可变参数形式的传参。
181public static void main(String[] args) {2 // 可变参数形式传参3 int sum01 = sum(6, 7, 2, 12, 2121);4
5 // 数组形式传参6 int[] arr = {1, 4, 62, 431, 2};7 int sum02 = sum(arr);8}9
10// 使用可变参数的方法11public static int sum(int... arr) {12 int sum = 0;13 for (int a : arr) {14 sum += a;15 }16 return sum;17}18
注意:
可变参数形式与数组形式的方法定义相互冲突,只能保留一个。
形参格式使用数组形式的方法则只能通过数组传参。
第七节 面试补充
1. 值传递 vs 引用传递
值传递:从实参拷贝一份副本给形参,基本类型拷贝的是值本身,对象类型拷贝的是对象的内存地址。
引用传递:实参共享自身地址给形参,修改会相互影响,如
int a = 1; int& p = a;,Java 不支持引用传递。
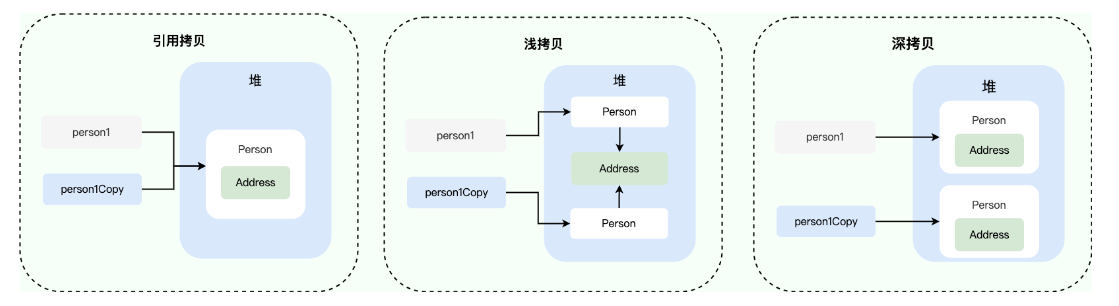
2. 引用拷贝 vs 浅拷贝 vs 深拷贝
引用拷贝:两个引用指向同一个对象实例,一般发生在函数传参;
浅拷贝:两个引用指向两个对象实例,但内部引用类型成员指向同一个实例,一般在调用默认 clone 方法时出现。
深拷贝:两个引用指向两个对象实例,且其内部的引用类型成员指向不同实例,一般在调用自定义的 clone 方法或序列化+反序列化时出现。
第02章_面向对象
第一节 类与对象
1.基本使用
类是一组相关属性和行为的集合,对象是一类事物的具体体现。
571// 定义一个类2public class Student {3 /* 成员变量 */4 private String name;5 private int age;6
7 /* 无参数构造方法 */8 public Student() {9 }10
11 /* 全参数构造方法 */12 public Student(String name, int age) {13 this.name = name;14 this.age = age;15 }16
17 /* 成员方法 */18 public void study() {19 System.out.println("好好学习,天天向上");20 }21
22 /* getter/setter方法 */23 public String getName() {24 return name;25 }26 public void setName(String name) {27 this.name = name;28 }29 public int getAge() {30 return age;31 }32 public void setAge(int age) {33 this.age = age;34 }35}36
37
38// 使用类39public class Test01_Student {40 public static void main(String[] args) {41 // 创建对象 42 Student student = new Student();43
44 // 获取成员变量45 System.out.println("姓名:" + student.getName()); //null46 System.out.println("年龄:" + student.getAge()); //047 System.out.println("‐‐‐‐‐‐‐‐‐‐");48
49 // 设置成员变量50 student.setName("赵丽颖");51 student.setAge(18);52
53 // 调用成员方法54 student.study(); // "好好学习,天天向上"55 }56}57
注意:可以通过
this关键字来显示指明需要访问成员变量,来区分同名的局部变量。
2. 权限修饰符
权限修饰符可以用来修改类、方法、属性等的访问权限,体现了面向对象的封装性。
public:公有的,对所有人开放,无访问限制。protected:被保护的,对同包和其子类开放。[default]:默认值(缺省值),对同包开放。private:私有的,仅对所属类开放。
注意:
一般将类定义为
public,此时要求文件名和类名保持一致;如果定义为[default],则仅有同包中才能访问该类。一般将成员变量定义为
private,并提供相应的Getter/Setter方法和构造器。不能对父类的private方法进行重写。
3. static修饰符
static可以用来修饰变量、方法、代码块、内部类等,被修饰的内容保存在静态区(方法区的一部分),随着类的加载而加载,且只加载一次,加载后被所有对象共享,一般用类名进行调用。
441public class Student {2 private Integer id;3 private String name;4 private static Integer stuCount; // 静态变量5
6 static {7 System.out.println("---静态代码块---");8 stuCount = 0;9 }10
11 {12 System.out.println("---构造代码块---");13 this.id = null;14 this.name = null;15 }16
17 public Student(String name) {18 System.out.println("---构造函数---");19 this.name = name;20 this.id = ++stuCount; // 通过 stuCount 给学生分配学号21 }22
23 public void showStudent() {24 {25 System.out.println("---普通代码块---");26 System.out.println("Student : id = " + id + ", name = " + name);27 }28 }29
30 public static void showStuCount() {31 System.out.println("---静态方法---");32 System.out.println("stuCount:" + stuCount);33 }34
35 public static void main(String[] args) {36 System.out.println("---Main---");37
38 Student student = new Student("张三");39 Student student2 = new Student("李四");40 student.showStudent();41 Student.showStuCount();42 }43}44
注意:
静态属性和静态方法一般使用类名来调用,虽然也可以通过对象来调用,但不推荐。
静态方法和静态代码块只能访问类中的静态变量,不能直接访问普通成员变量或成员方法。
除静态代码块外,Java中还有构造代码块,它们的执行顺序为:静态代码块->Main函数->构造代码块->构造函数->普通代码块。
在Java1.7后,静态代码块不能存在于主类中,防止干扰main函数的执行。
关于静态内部类的使用请参考内部类章节。
4. final修饰符
final表示不可改变,可以用于修饰类、方法和变量等,分别具有不同的含义。
161// 1) finnal修饰的类不能被继承2final public class FinalClass {3
4 // 2) final修饰的变量不能被重新赋值,必须在声明时或构造函数中初始化5 final public Integer id;6
7 public FinalClass(Integer id) {8 this.id = id; // 初始化final变量9 }10
11 // 3) finnal修饰的方法不能被重写12 final public void finalMethod() {13
14 }15}16
注意:
被final修饰的静态变量一般称为常量,通常使用大写字母+下划线的形式命名。
必须保证类当中所有重载的构造方法,最终都会对final变量进行赋值。
5. 面试补充
面向对象的三大基本特征:封装、继承、多态。
面向对象与面向过程的主要区别如下:
面向过程:把解决问题的过程拆成一个个方法,通过调用方法来解决问题,如:吃(我,饭)。
面向对象:先抽象出对象,然后使用对象解决问题,这种方式开发效率更高,代码也好维护,如 我.吃(饭)。
第二节 继承与多态
1. 继承的基本使用
继承指子类继承父类的特征和行为,使子类对象具有父类的实例域和方法,不仅复用了代码,而且使不同子类的对象能够被统一处理。
361public class Base {2 String name; // 父类变量3
4 public Base(String name) {5 this.name = name;6 }7
8 public void parentShow() {9 System.out.println("I am " + name + ".");10 }11}12
13
14public class ChildA extends Base {15 String name; // 子类同名变量16
17 public ChildA(String parentName, String childName) {18 // 调用父类构造19 super(parentName);20 this.name = childName;21 }22
23 public void childShow() {24 // 使用super关键字调用父类同名变量25 System.out.println("I am " + name + ", parent is " + super.name);26 }27}28
29
30public class Test {31 public static void main(String[] args) {32 ChildA childA = new ChildA("小头爸爸", "大头儿子");33 childA.parentShow(); // I am 小头爸爸.34 childA.childShow(); // I am 大头儿子, parent is 小头爸爸35 }36}注意:
Java只支持单继承,一个类只能有一个父类,并且最终都继承自
java.lang.Object类。构造子类对象前必须先构造父类对象,如果父类没有无参构造,则必须在子类构造器的首行通过
super显式调用有参构造。不建议在构造方法中调用非private方法,特别是可被子类重写的方法,这将带来不必要的麻烦。
在子类中,可以使用
super关键字来显式调用父类属性或方法。子类初始化顺序为:基类静态代码块->子类静态代码块->基类实例代码块->基类构造方法->子类实例代码块->子类构造方法。
2. 方法重写与动态绑定
方法重写指在子类中覆盖父类的实例方法,以此来实现子类的特异性功能,其要求方法名、参数列表和返回值完全一致,一般使用@Override注解标识。由于实例方法可能被重写,因此采用动态绑定方式,实际调用的方法取决于对象的动态类型。
371public class Base {2 public Base(String name) {3 this.name = name;4 }5
6 // 父类待重写方法7 public void print(){8 System.out.println("--- Base print() ---");9 }10}11
12
13public class ChildA extends Base {14 public ChildA(String parentName, String childName) {15 super(parentName);16 this.name = childName;17 }18 19 // 子类重写方法20 21 public void print() {22 System.out.println("--- ChildA print() ---");23 }24}25
26
27public class Test {28 public static void main(String[] args) {29 ChildA childA = new ChildA("小头爸爸", "大头儿子");30 Base base = childA;31 32 // 动态绑定(取决于动态类型,即为.号右边的类型)33 base.print(); // --- ChildA print() ---34 childA.print(); // --- ChildA print() ---35 }36}37
注意:
使用final修饰的类不能被继承,使用final修饰的方法不能被重写,可用于加强封装性。
使用向下转型时可以先用
instanceof关键字进行判断是否是某个类的子类,避免ClassCastException。
3. 重名与静态绑定
子类还可以定义与父类重名的变量或静态方法,其采用静态绑定(编译期绑定)方式,实际调用取决于对象的静态类型。
441public class Base {2 // 父类公有变量3 public String name;4
5 public Base(String name) {6 this.name = name;7 }8
9 // 父类静态方法10 public static void staticShow() {11 System.out.println("--- Base staticShow() ---");12 }13}14
15
16public class ChildA extends Base {17 // 子类同名的公有变量18 public String name;19
20 public ChildA(String parentName, String childName) {21 super(parentName);22 this.name = childName;23 }24
25 // 子类同名的静态方法26 public static void staticShow() {27 System.out.println("--- ChildA staticShow() ---");28 }29}30
31
32public class Test {33 public static void main(String[] args) {34 ChildA childA = new ChildA("小头爸爸", "大头儿子");35 Base base = childA;36
37 // 静态绑定(取决于静态类型,即为.号左边的类型)38 System.out.println(base.name); // 小头爸爸39 System.out.println(childA.name); // 大头儿子40 Base.staticShow(); // --- Base staticShow() ---41 ChildA.staticShow(); // --- ChildA staticShow() ---42 }43}44
注意:
此处所说的重名指方法名(变量名)与参数列表皆相同,而非方法重载的情形(重载始终优先于重写)。
第三节 接口
1. 定义接口
接口是Java提供的一种的引用类型,其中可以定义常量、抽象方法、默认方法和静态方法(JDK 8)以及私有方法(JDK 9)等。
221public interface InterfaceA {2 // 常量3 public static final int NUM_OF_MY_CLASS = 12; //必须进行初始化4 5 // 抽象方法(使用 public abstract 修饰,可以省略,没有方法体,非抽象子类必须实现该方法)6 void abstractMethod();7
8 // 默认方法(使用 default 修饰,default不可省略,供子类调用或者子类选择性重写)9 // JDK8之前一般通过抽象类实现10 default void defaultMethod() {11 }12
13 // 静态方法(使用 static 修饰,通过接口直接调用,注:接口的静态方法不会被子类继承)14 // JDK之前,相关的静态方法往往定义在单独的类中,比如,Collection接口有一个对应的单独的类Collections15 static void staticMethod() {16 }17
18 // 私有方法(JDK9)(使用 private 修饰,供接口中的其它方法调用)19 private void privateMethod() {20 }21}22
接口也可以继承其它接口,并且能够同时继承多个,如果父接口中有重名的方法,那么子接口中只需要重写一次。
181// 接口12public interface A1 {3 void compare();4}5
6// 接口27public interface A2 {8 void compare();9}10
11// 类B继承接口1和接口212public interface B extends A1, A2 {13 14 default void compare() {15
16 }17}18
注意:
接口中只可以定义
public static final修饰的常量,且不可以定义任何变量。接口中没有静态代码块、构造方法,不能实例化对象。
2. 实现接口
一个类可以实现多个接口,一个接口也可以被多个类实现。
81// 类C实现接口1和接口22public class C implements A1, A2 {3 4 public void compare() {5 6 }7}8
类在继承基类的同时,也可以实现一个或多个接口,但要求extends关键字在implements之前。
31public class Child extends Base implements IChild {2}3
注意:
如果实现类不是抽象类,则必须实现接口的所有抽象方法。
子接口在重写默认方法时,default关键字可以保留,而子类重写默认方法时,不可以保留,因为类中不存在默认方法。
如果继承来的方法和接口的默认方法重名,则子类会优先使用继承来的方法,即继承优于实现。
3. 使用接口
111public static void main(String[] args) {2 // 调用接口声明的方法3 InterfaceAImpl interfaceA = new InterfaceAImpl();4 interfaceA.abstractMethod();5
6 // 判断是否为接口实例7 if (interfaceA instanceof InterfaceA) {8 System.out.println("instanceof InterfaceA");9 }10}11
4. 接口+组合替代继承
继承至少有两个好处:一个是复用代码;另一个是利用多态和动态绑定统一处理多种不同子类的对象。使用组合替代继承,可以复用代码,但不能统一处理。使用接口替代继承,针对接口编程,可以实现统一处理不同类型的对象,但接口没有代码实现,无法复用代码。将组合和接口结合起来替代继承,就既可以统一处理,又可以复用代码了。
如下例,Child复用了Base的代码,又都实现了IAdd接口,这样,既复用代码,又可以统一处理,还不用担心破坏封装。
261public interface IAdd {2 void add(int number);3}4
5
6public class Base implements IAdd {7 8 public void add(int number) {9 System.out.println("---Base.add()---");10 }11}12
13
14public class Child implements IAdd {15 private Base base; // 组合16
17 public Child() {18 base = new Base();19 }20
21 22 public void add(int number) {23 base.add(number); // 复用24 }25}26
第四节 抽象类
1. 抽象类的定义和使用
抽象类指使用abstract修饰的类,一般存在抽象方法。抽象方法指只有方法声明,但没有方法体的方法。
261// 抽象类2public abstract class Shape {3 // 抽象方法4 public abstract void draw();5}6
7// 子类8public class Circle extends Shape {9 // 实现抽象方法10 11 public void draw() {12 System.out.println("---画圆---");13 }14}15
16// 测试17public class Test {18 public static void main(String[] args) {19 // 创建子类对象20 Shape shape = new Circle();21
22 // 调用子类方法23 shape.draw();24 }25}26
注意:
抽象类的子类,必须重写抽象父类中所有的抽象方法,除非该子类也是抽象类。
抽象类中,可以有构造方法,是供子类创建对象时,初始化父类成员使用的。
抽象类中,不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
2. 抽象类和接口
抽象类和接口经常配合使用,其主要区别如下:
用途不同:接口定义能力,抽象类提供默认实现,方便子类实现接口,如List接口对应AbstractList,Map接口对应AbstractMap等。
成员不同:除常量、抽象方法、默认方法、静态方法外,但抽象类可额外定义变量和构造方法。
权限不同:接口的所有成员必须是 public 的,但抽象类则没有限制。
限制不同:一个子类只能继承一个抽象类,但一个子类可以实现多个接口,且一个子接口也可继承多个接口。
第五节 内部类
1. 成员内部类
成员内部类指定义在其它类内部的类,如List返回的Iterator对象等,适用于与外部类关系密切且需要访问外部类实例的变量或方法的类。
341public class Outer {2 private int a = 100;3
4 // 成员内部类5 public class Inner {6 public void innerMethod() {7 System.out.println("outer a " + a);8
9 // 访问外部类变量或方法 Outer.this.xxx10 Outer.this.action();11 }12 }13
14 private void action() {15 System.out.println("action");16 }17
18 public void test() {19 // 在外部类中使用成员内部类20 Inner inner = new Inner();21 inner.innerMethod();22 }23}24
25
26public class Test {27 public static void main(String[] args) {28 // 在其他类中使用成员内部类29 Outer.Inner inner = new Outer().new Inner();30 inner.innerMethod();31 }32}33
34
注意:
如需创建成员内部类对象,则必须先创建外部类对象,成员内部类会保存外部类对象的引用。
内部类在编译后会生成独立的.class文件,类名用
$进行分隔,如Body$Heart.class。如果在内部类中访问了外部类的私有变量或方法,则在编译时会被替换为[default]权限的
access$0系列方法。外部类只可以用public或[default]修饰,但内部类还额外支持private和protected修饰符。
接口也可以定义内部接口和内部抽象类等,了解即可。
2. 静态内部类
静态内部类指定义在其它类内部的静态类,如LinkedList类内部的Node类等,适用于与外部类关系密切但不依赖于外部类实例的类。
251public class Outer {2 private static int shared = 100;3
4 // 静态内部类5 public static class StaticInner {6 public void innerMethod() {7 System.out.println("inner " + shared);8 }9 }10
11 public void test() {12 // 在外部类使用静态内部类13 StaticInner si = new StaticInner();14 si.innerMethod();15 }16}17
18public class Test {19 public static void main(String[] args) {20 // 在其他类使用静态内部类21 Outer.StaticInner staticInner = new Outer.StaticInner();22 staticInner.innerMethod();23 }24}25
注意:
创建静态内部类对象时不依赖外部类对象,因此它只能访问外部类的静态变量和方法,不可以访问实例变量和方法。
静态内部类除了可以定义成员方法、成员变量、构造方法、静态final变量等,还额外支持静态变量和静态方法。
3. 方法内部类
方法内部类指定义在方法内部的类,方法可以是成员方法或静态方法,适用于只在当前方法中使用该类的场景。
241ppublic class Outer {2 private int a = 100;3
4 public void test(final int param) {5 final String str = "hello";6
7 // 方法内部类8 class Inner {9 public void innerMethod() {10 // 访问外部类变量或方法11 System.out.println("outer a " + a);12
13 // 访问方法参数或局部变量14 System.out.println("param " + param);15 System.out.println("local var " + str);16 }17 }18
19 // 在方法内部使用方法内部类20 Inner inner = new Inner();21 inner.innerMethod();22 }23}24
注意:
如需在方法内部类中访问方法参数或局部变量,则该变量必须是final的,或等效final的(因为该变量是通过构造参数直接传入)。
方法内部类不能写任何权限修饰符。
4. 匿名内部类
匿名内部类指定义在方法内部的匿名类,它没有类名和构造方法,且只能在定义类时创建对象,适用于接口回调的场景。
131public class Outer {2 public void sortIgnoreCase(String[] strs) {3 // 使用匿名内部类创建的对象4 Arrays.sort(strs, new Comparator<String>() {5 6 public int compare(String o1, String o2) {7 return o1.compareToIgnoreCase(o2);8 }9 });10 }11}12
13
注意:
匿名内部类可以定义实例变量、实例方法、初始化代码块、参数列表等,其中参数列表将会传递给父类的构造方法。
与方法内部类一样,匿名内部类也可以访问外部类的变量和方法,可以访问等效final的方法参数和局部变量。
第六节 枚举类
枚举(enum)是一种特殊的类,它只有类中声明的有限个对象,对象名称一般大写。
1. 基本枚举类
431// 定义枚举2public enum Size {3 // 该枚举有三个对象4 SMALL, MEDIUM, LARGE5}6
7// 使用枚举8public class Test {9 public static void main(String[] args) {10 // 获取单个枚举对象11 Size size = Size.SMALL; // 直接获取12 Size size2 = Size.valueOf("SMALL"); // 使用字面值获取13
14 // 枚举对象的字面值、序号15 System.out.println(size.toString()); // SMALL,等同name()16 System.out.println(size.name()); // SMALL17 System.out.println(size.ordinal()); // 018
19 // 枚举对象进行比较20 System.out.println(size == Size.SMALL); // true21 System.out.println(size.equals(Size.SMALL)); // true22 System.out.println(size.compareTo(Size.MEDIUM)); // -1 比较ordinal值23
24 // 获取所有枚举对象 .values()25 for (Size item : Size.values()) {26 System.out.println(item);27 }28
29 // switch使用枚举30 switch (size) {31 case SMALL:32 System.out.println("chosen small");33 break;34 case MEDIUM:35 System.out.println("chosen medium");36 break;37 case LARGE:38 System.out.println("chosen large");39 break;40 }41 }42}43
2. 带成员的枚举类
枚举类可以定义自己的成员变量、成员方法以及继承接口等。
481// 接口2public interface ExceptionMessage {3 String getCode();4 String getMessage();5 ExceptionLevel getLevel();6}7
8// 继承接口的枚举9public enum KfmsExceptionMessage implements ExceptionMessage {10 // 枚举对象11 ERR_NOT_SUPPORTED("-99", "暂不支持", ExceptionLevel.NORMAL),12 ERR_DEFAULT("-1", "未知异常", ExceptionLevel.NORMAL),13 ERR_RTMSG_OK("0", "业务程序运行正常", ExceptionLevel.NORMAL);14
15 // 定义的变量16 private String code;17 private String message;18 private ExceptionLevel level;19
20 // 构造器,用于上述枚举对象的构造21 KfmsExceptionMessage(String code, String message, ExceptionLevel level) {22 this.code = code;23 this.message = message;24 this.level = level;25 }26
27 // 实现接口方法28 29 public String getCode() {30 return this.code;31 }32 33 public String getMessage() {34 return this.message;35 }36 37 public ExceptionLevel getLevel() {38 return this.level;39 }40
41 // 重写抽象类Enum<T>中的方法42 43 public String toString() {44 return this.message;45 }46 47}48
注意:
枚举对象必须定义在类的前面,并且以分号结尾,再写其它代码。
不需要提供Setter方法,枚举对象不允许修改。
3. 枚举的本质
枚举本质上还是一个类,上述案例转换为普通类如下:
491// 枚举类 ==> final修饰的普通类,继承Enum<E extends Enum<E>>2public final class KfmsExceptionMessage extends Enum<KfmsExceptionMessage> implements ExceptionMessage {3 // 枚举对象 ==> public final修饰的静态对象4 public static final KfmsExceptionMessage ERR_NOT_SUPPORTED = new KfmsExceptionMessage("ERR_NOT_SUPPORTED", 0, "-99", "暂不支持", ExceptionLevel.NORMAL);5 public static final KfmsExceptionMessage ERR_DEFAULT = new KfmsExceptionMessage("ERR_DEFAULT", 1, "-1", "未知异常", ExceptionLevel.NORMAL);6 public static final KfmsExceptionMessage ERR_RTMSG_OK = new KfmsExceptionMessage("ERR_RTMSG_OK", 2, "0", "业务程序运行正常", ExceptionLevel.NORMAL);7 8 // VALUES9 private static KfmsExceptionMessage[] VALUES = new KfmsExceptionMessage[]{ERR_NOT_SUPPORTED, ERR_DEFAULT, ERR_RTMSG_OK};10
11 // 成员变量12 private String code;13 private String message;14 private ExceptionLevel level;15
16 // 构造方法私有,方式创建其它对象17 private KfmsExceptionMessage(String name, int ordinal, String code, String message, ExceptionLevel level) {18 super(name, ordinal);19 this.code = code;20 this.message = message;21 this.level = level;22 }23
24 public static KfmsExceptionMessage[] values() {25 KfmsExceptionMessage[] values = new KfmsExceptionMessage[VALUES.length];26 System.arraycopy(VALUES, 0, values, 0, VALUES.length);27 return values;28 }29 public static KfmsExceptionMessage valueOf(String name) {30 return Enum.valueOf(KfmsExceptionMessage.class, name);31 }32 33 public String getCode() {34 return this.code;35 }36 37 public String getMessage() {38 return this.message;39 }40 41 public ExceptionLevel getLevel() {42 return this.level;43 }44 45 public String toString() {46 return this.message;47 }48}49
第七节 常用类
1. 包装类
1) 包装类介绍
Java中提供了四类八种基础类型,为了适应不同场合,又分别提供了对应的包装类。

2) 装箱与拆箱
基本类型与对应的包装类对象之间,来回转换的过程称为”装箱“与”拆箱“。从JDK1.5开始,该动作可以自动完成。
131// 装箱:基本类型 -> 包装类型2Integer i = new Integer(4); // 使用构造函数3Integer ii = Integer.valueOf(4); // 使用包装类中的valueOf方法4Integer i = 4; // 自动装箱5
6// 拆箱:包装类型 -> 基本类型7int num = i.intValue();8i = i + 5;9
10// 自动装箱与拆箱11Integer i = 4; // 相当于Integer i = Integer.valueOf(4);12i = i + 5; // 等号右边:将i对象转成基本数值(自动拆箱),相当于i.intValue() + 5, 加法运算完成后,再次装箱,把基本数值转成对象。13
3) 包装类与字符串转换
161// 包装类 -> 字符串2Integer i = 0;3Boolean b = true;4String str1 = i + ""; // "0"5String str2 = String.valueOf(i); // "0" String.valueOf()兼容null值,null->"null"6String str3 = i.toString(); // "0"7String str4 = b.toString(); // "true"8
9// 字符串 -> 包装类10Boolean b = Boolean.parseBoolean("true"); // true 只有"true"转换为true,null和其它都是false11Integer i = Integer.parseInt("666"); // 666 如果是小数或其它无法转换的数字字符串,则报错12Double d = Double.parseDouble("666"); // 666.0 13
14// 字符串 -> Charset15Character c = "abcd".charAt(0); // a 特殊的,Charset.parseCharset()方法不存在16
4) 面试补充
包装类型 vs 基本类型
包装类型可以存储 null 值,可以用作泛型参数,但是更占用空间。
包装类型的默认值为 null,而基本类型有各自的默认值。
包装类型 == 时比较的时对象的内存地址,而基本类型比较的是值。
包装类型实例大多存放在堆中,但基于 JIT 逃逸分析判断只在方法内使用的变量除外。
包装类型的缓存机制
包装类内部建有缓存机制,以降低包装类对象的创建消耗,如:
整型包装类型(Byte/Short/Integer/Long)默认缓存了[-128,127],
字符型(Character)默认缓存了[0,127],
布尔型(Boolean)缓存了 True 和 False,
但浮点型(Float/Double)未进行缓存。
在使用自动装箱/拆箱或调用包装类的 valueOf() 和 xxxValue() 方法时,如果在缓存范围内,就会用到缓存对象。
则会自动取池中对象,可用==进行地址比较,否则需要用equals比较。
171public static void main(String[] args) {2 // 始终创建新对象3 Integer i1 = 0;4 Integer i2 = new Integer(0);5 System.out.println(i1 == i2); // false6
7 // 自动装箱,复用池中对象8 Integer i3 = 127;9 Integer i4 = 127;10 System.out.println(i3 == i4); // true11
12 // 自动装箱,无池中对象可复用13 Integer i5 = 128;14 Integer i6 = 128;15 System.out.println(i5 == i6); // false16}17
注意:
特别注意:建议包装类对象之间值的比较,全部使用 equals 方法比较,即使在缓存区间内。
2. 字符串(String)
1) String类基本使用
Java中使用java.lang.String类代表字符串,创建字符串的方式如下:
141// 1. 通过字符串字面量构造2String str = "ABCD"; //存入常量池3
4// 2. 无参构造5String str = new String(); //空字符串""6
7// 3. 通过字符数组构造8char chars[] = {'a', 'b', 'c'}; 9String str2 = new String(chars);10
11// 4. 通过字节数组构造12byte bytes[] = { 97, 98, 99 }; 13String str3 = new String(bytes); // 使用系统默认编码 ,其它可用"UTF-8"、"GBK"、"GB18030"等14
String类在创建后不可修改,并且对字符串常量进行入池共享。
131// 1. 不可变性:字符串创建后不能被修改2String s = "abc";3s += "d"; // 尝试修改字符串,会创建新对象"abcd"4
5// 2. 常量共享:通过字面量创建的String对象会被加入到“字符串常量池”中进行复用6String name1 = new String("abc");7String name2 = new String("abc"); // name1!= name2 8String s1 = "abc";9String s2 = "abc"; // s2 == s1 10
11// 3. 基于字符数组char[]实现(JDK9及以后基于字节数组byte[])12String str = "abc"; // String内部实际为 char data[] = {'a', 'b', 'c'}; 13
注意:
通过字符串字面量构造也会创建String类对象,并且会自动入池,推荐使用。
String类与字节数组之间的转换依赖字符编码,如未指明则使用系统默认字符编码:
Charset.defaultCharset().name()。在 JDK8 及之前,String内部采用 char[] 实现,但在JDK9及之后,使用 byte[] + coder 实现;
2) String的常用方法

3) 字符串常量池
字符串常量池是 JVM 为 String 类开辟的一块内存区域,主要用于 String 类对象的共享,以提升性能和减小内存占用。
对于编译期可以确定值的字符串,也就是常量字符串 ,JVM 会自动将其存入字符串常量池。
131String str1 = "str";2String str2 = "ing";3String str3 = "str" + "ing"; // 发生常量折叠,等效:String str3 = "string";4String str4 = "string"; 5String str5 = str1 + str2; // 等效:String str5 = new StringBuilder().append(str1).append(str2).toString();6System.out.println(str3 == str4); //true7System.out.println(str3 == str5); //false8System.out.println(str4 == str5); //false9
10final String stra = "str";11final String strb = "ing";12String strc = stra + strb; // 发生常量折叠,等效:String strc = "string";13System.out.println(str4 == strc); // true也可通过String#intern 方法将字符串手动入池,返回值是调用字符串或池中相同字符串(通过equals比较)的引用;
41String s1 = "Java";2String s2 = s1.intern(); // s2 == s13String s3 = new String("Java"); // 在堆中创建一个新的 "Java" 对象,s3 指向它4String s4 = s3.intern(); // 注意:s4 指向字符串常量池中的 "Java" 对象,和 s1 是同一个对象,而不是和 s3 是一个对象注意:
String#intern 方法返回的引用不一定是调用 intern 方法对象的引用,入池不一定能成功!
4) StringBuilder
如果对字符串操作很频繁或者在循环中使用字符串,则推荐使用StringBuilder类或其线程安全版本的StringBuffer类来处理。
81public static void main(String[] args) {2 // 基本使用3 StringBuilder sb = new StringBuilder();4 sb.append("Hello ");5 sb.append("World!");6 System.out.println(sb.toString()); // Hello World!7}8 注意:
StringBuilder内部采用非final修饰的字符数组,可以根据字符串的修改来进行动态扩容,而不会创建很多中间字符串对象。
如果不是在循环中使用,则编译器一般可以自动优化为StringBuilder操作,而在循环中,可能会创建多个StringBuilder对象。
5) StringJoiner
在JDK1.8+版本,添加了更适合进行字符串拼接操作的类StringJoiner,同时在String类中加了一个静态方法String.join()。
141public static void main(String[] args) {2 String[] strs = new String[]{"abc", "def", "xyz"};3
4 // 使用 StringJoiner 拼接5 StringJoiner sj = new StringJoiner("', '", "['", "']");6 for (int i = 0; i < strs.length; i++) {7 sj.add(strs[i]);8 }9 System.out.println(sj.toString()); // ['abc', 'def', 'xyz']10
11 // 调用 String.join()封装方法(不支持前后缀)12 System.out.println(String.join("|", strs)); // abc|def|xyz13}14
6) 面试补充
String类如何保证不可变性?
内部的字符数组被 private static 修饰,且未暴漏修改该字符串的方法。
String 类被 final 修饰,不可被继承,防止通过子类破坏不可变性。
优点:简化 String 类的使用;通过字符串常量池进行对象共享,减少内存占用;
3. 日期和时间
1) 相关基本概念
关于日期和时间,有一些基本概念,包括纪元时、时刻、时区、年历等。
纪元时(Epoch Time):一个特殊的时刻(零点),指格林尼治标准时间1970年1月1日0时0分0秒。
时刻:相对于纪元时的毫秒数(允许负数)。这个毫秒数在世界各地都相同,但是不同地区对其解读不一样(与时区和年历有关)。
时区:全球一共有24个时区,英国格林尼治是0时区(GMT+0),北京是东八区(GMT+8:00),也就是说格林尼治凌晨1点,北京是早上9点。
年历:描述了一年有多少月,每月有多少天,甚至一天有多少小时,在中文系统中,一般使用公历。
注意:时刻是一个绝对时间,但对时刻的解读,则是相对的,与时区和年历相关。
2) Date(时刻)
java.util.Date是早期引入的日期API,主要用于表示时刻的概念,同时承担了年历的作用,但由于不支持国际化,许多方法被标记过时了,我们只需学习未过时的方法即可。
161public static void main(String[] args) {2 // 当前时刻3 Date date01 = new Date(); // Tue Nov 01 18:46:36 CST 20224 5 // 根据毫秒值获取时刻6 Date date02 = new Date(0); // Thu Jan 01 08:00:00 CST 1970 注意:0时刻在东八区要+8小时7
8 // 获取毫秒值9 System.out.println(date01.getTime()); // 166729959686710
11 // 时刻之间进行比较12 System.out.println(date01.compareTo(date02)); // 1 正数表示大于13 System.out.println(date01.before(date02)); // false14 System.out.println(date01.after(date02)); // true15}16
3) TimeZone(时区)
java.util.TimeZone(抽象类)表示时区,默认时区由系统属性`user.timezone属性决定。
111public static void main(String[] args) {2 // 系统默认时区3 TimeZone tz01 = TimeZone.getDefault(); // Asia/Shanghai4 5 // 美国东部时区6 TimeZone tz02 = TimeZone.getTimeZone("US/Eastern"); // US/Eastern7 8 // GMT形式的时区9 TimeZone tz03 = TimeZone.getTimeZone("GMT+08:00"); // GMT+08:0010}11 注意:
系统属性可通过System.getProperty("")获取,并在启动时通过java -Duser.timezone=Asia/Shanghai xxxx参数进行调整。
4) Locale(地区和语言)
java.util.Locale表示国家(或地区)和语言,中国内地的代码是CN,中国台湾地区的代码是TW,美国的代码是US,中文语言的代码是zh,英文语言的代码是en等。
181public static void main(String[] args) {2 // 默认地区和语言3 System.out.println(Locale.getDefault()); // zh_CN4
5 // 内置的地区和语言常量6 System.out.println(Locale.US); // en_US 美国英语7 System.out.println(Locale.ENGLISH); // en 所有英语8 System.out.println(Locale.TAIWAN); // zh_TW 中国台湾地区所用的中文9 System.out.println(Locale.CHINESE); // zh 所有中文10 System.out.println(Locale.SIMPLIFIED_CHINESE); // zh_CN 中国内地所用的中文11 12 // 自定义地区和语言13 System.out.println(new Locale("zh", "CN")); // zh_CN14
15 // 获取所有可用地区和语言16 System.out.println(Arrays.toString(Locale.getAvailableLocales())); //17}18
5) Calendar(日历)
实例化
java.util.Calendar(抽象类)表示与年月日相关的日历信息,可以对日期和时间进行设置和修改。
81public static void main(String[] args) {2 // 默认Calendar实例3 Calendar instance01 = Calendar.getInstance(); // java.util.GregorianCalendar[...]4
5 // 根据TimeZone和Locale获取对应日历6 Calendar instance02 = Calendar.getInstance(TimeZone.getTimeZone("GMT+08:00"), Locale.CHINESE); 7}8
获取日历信息
其内部有一个与Date中类似的长整型变量protected long time,用于记录时刻(默认为当前时间),并且还有一个数组protected int fields[],表示日历中各个字段的值。这个数组的长度为17,能够表示的字段主要有:
| 字段 | 含义 |
|---|---|
| Calendar.MONTH | 月(0~11) |
| Calendar.DAY_OF_MONTH | 当前月的第N日(1~xx) |
| Calendar.HOUR_OF_DAY | 当前日的第N时(0~23) |
| Calendar.MINUTE | 分钟(0~59) |
| Calendar.SECOND | 秒(0~59) |
| Calendar.MILLISECOND | 毫秒(0~999) |
| Calendar.DAY_OF_WEEK | 当前周的第N天(1~7,1为周日) |
161public static void main(String[] args) {2 // 获取默认日历实例3 Calendar calendar = Calendar.getInstance();4 System.out.println("time: " + calendar.getTime().getTime()); // time: 16674622126395 6 // 查看年月日等日历信息7 System.out.println("year: " + calendar.get(Calendar.YEAR)); // year: 20228 System.out.println("month(0-11): " + calendar.get(Calendar.MONTH)); // month(0-11): 109 System.out.println("day: " + calendar.get(Calendar.DAY_OF_MONTH)); // day: 310 System.out.println("hour: " + calendar.get(Calendar.HOUR_OF_DAY)); // hour: 1511 System.out.println("minute: " + calendar.get(Calendar.MINUTE)); // minute: 5612 System.out.println("second: " + calendar.get(Calendar.SECOND)); // second: 5213 System.out.println("millisecond: " + calendar.get(Calendar.MILLISECOND)); // millisecond: 014 System.out.println("day_of_week(周日为第1天): " + calendar.get(Calendar.DAY_OF_WEEK)); // day_of_week(周日为第1天): 515}16
注意:
Calendar中定义了表示各个星期、各个月的静态变量,如Calendar.SUNDAY表示周日、Calendar.JULY表示7月。
直接设置时间
Calendar支持根据Date或毫秒数设置时间,也支持根据年月日等日历字段设置时间。
121public static void main(String[] args) {2 // 根据Date或毫秒数设置时间3 Calendar calendar = Calendar.getInstance();4 calendar.setTime(new Date());5 calendar.setTimeInMillis(System.currentTimeMillis());6
7 // 根据年月日等日历字段设置时间8 calendar.set(2022, 11, 20); // 2022年11月20日9 calendar.set(2022, 11, 20, 15, 48, 59); // 2022年11月20日15时48分59秒10 calendar.set(Calendar.YEAR, 2021); // 2021年11}12
增加或减少时间
除了直接设置,也支持根据字段增加和减少时间,正数表示增加,负数表示减少,增减支持自动调整。
221public static void main(String[] args) {2 // 设置为昨天下午2点153 Calendar calendar = Calendar.getInstance();4 calendar.add(Calendar.DAY_OF_MONTH, -1); // 昨天5 calendar.set(Calendar.HOUR_OF_DAY, 14);6 calendar.set(Calendar.MINUTE, 15);7 calendar.set(Calendar.SECOND, 0);8 calendar.set(Calendar.MILLISECOND, 0);9 10 // add方法支持自动调整11 Calendar calendar = Calendar.getInstance();12 calendar.set(Calendar.HOUR_OF_DAY, 13); // 13点13 calendar.set(Calendar.MINUTE, 59); // 59分14 calendar.add(Calendar.MINUTE, 3); // +3分,自动调整为14点02分15
16 // roll方法不支持自动调整17 calendar = Calendar.getInstance();18 calendar.set(Calendar.HOUR_OF_DAY, 13);19 calendar.set(Calendar.MINUTE, 59);20 calendar.roll(Calendar.MINUTE, 3); // 13点02分21}22
转换为Date或毫秒数
91public static void main(String[] args) {2 Calendar calendar = Calendar.getInstance();3 4 // 转化为Date5 Date date = calendar.getTime();6 7 // 转换为毫秒数8 long time =calendar.getTimeInMillis();9}
与其它Calendar进行比较
101public static void main(String[] args) {2 Calendar calendar = Calendar.getInstance();3 Calendar otherCalendar = Calendar.getInstance();4
5 // 与其它Calendar进行比较6 System.out.println(calendar.equals(otherCalendar)); // false7 System.out.println(calendar.compareTo(otherCalendar)); // -18 System.out.println(calendar.before(otherCalendar)); // true9 System.out.println(calendar.after(otherCalendar)); // false10}
6) DateFormat(格式化)
java.text.DateFormat(抽象类)用于Date与字符串之间的相互转换。我们一般用它的实现类SimpleDateFormat,它接受一个pattern作为构造参数,pattern中的英文字符(a~z|A~Z)表示特殊含义,其他字符原样输出。部分特殊字符含义如下:
| 格式字符串 | 含义 | 格式字符串 | 含义 |
|---|---|---|---|
| yyyy | 年份 | mm | 分钟 |
| MM | 月份 | ss | 秒 |
| HH | 小时(24小时制) | E | 星期几 |
| hh | 小时(12小时制) | a | 上午或下午(仅12小时制有效) |
特殊的,如果想原样输出英文字符,可以将其用单引号括起来。
241public static void main(String[] args) {2 // 格式一3 SimpleDateFormat simpleDateFormat01 = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");4 System.out.println(simpleDateFormat01.format(new Date())); // 2022年11月04日 17时35分59秒5 try {6 System.out.println(simpleDateFormat01.parse("2022年11月04日 17时35分59秒")); 7 } catch (ParseException e) {8 e.printStackTrace();9 }10
11 // 格式二12 SimpleDateFormat simpleDateFormat02 = new SimpleDateFormat("yyyy/MM/dd E hh:mm:ss a");13 System.out.println(simpleDateFormat02.format(new Date())); // 2022/11/04 星期五 05:35:59 下午14 try {15 System.out.println(simpleDateFormat02.parse("2022/11/04 星期五 05:35:59 下午")); 16 } catch (ParseException e) {17 e.printStackTrace();18 }19 20 // 原样输出英文字符、双引号等21 SimpleDateFormat simpleDateFormat03 = new SimpleDateFormat("\"yyyy'year'MM'month'dd'day' HH'hour'mm'minute'ss'second'\"");22 System.out.println(simpleDateFormat03.format(new Date())); // "2022year11month04day 17hour40minute58second"23}24
4. 日期和时间(JDK8+)
JDK8对日期和时间进行了增强,位于java.time包下。
1) Instant(时刻)
111public static void main(String[] args) {2 // 当前时刻3 Instant now01 = Instant.now(); // 2022-11-04T10:07:06.068Z4
5 // 根据毫秒值获取时刻6 Instant now02 = Instant.ofEpochMilli(System.currentTimeMillis());7
8 // 获取毫秒数9 long time = now02.toEpochMilli(); // 166780491764110}11
2) ZoneId/ZoneOffset(时区/时区偏移)
111public static void main(String[] args) {2 // 默认时区3 ZoneId defaultZoneId = ZoneId.systemDefault(); // Asia/Shanghai4
5 // 北京时区6 ZoneId bjZone = ZoneId.of("GMT+08:00"); // Asia/Shanghai7 8 // 时区偏移8小时9 ZoneOffset zoneOffset = ZoneOffset.of("+08:00");10}11
3) LocalDateTime(时区无关日期时间)
基本使用
291public static void main(String[] args) {2 // 使用默认毫秒值与时区构造3 LocalDateTime ldt01 = LocalDateTime.now();4
5 // 指定毫秒值和时区构造6 LocalDateTime ldt03 = LocalDateTime.ofEpochSecond(2030201403, 0, ZoneOffset.of("+08:00")); // 2034-05-03T00:50:037
8 // 直接指定日期时间9 LocalDateTime ldt02 = LocalDateTime.of(2022, 7, 11, 20, 45, 5); // 2022年7月11日20时45分5秒10
11 // 指定Instant时刻和时区构造12 LocalDateTime ldt04 = LocalDateTime.ofInstant(Instant.now(), ZoneId.systemDefault()); // 2022-11-07T15:42:33.03513
14 // 获取年月日等日历信息15 int year = ldt02.getYear(); // 202216 int monthValue = ldt02.getMonthValue(); // 717 int dayOfMonth = ldt02.getDayOfMonth(); // 1118 int hour = ldt02.getHour(); // 2019 int minute = ldt02.getMinute(); // 4520 int second = ldt02.getSecond(); // 521 DayOfWeek dayOfWeek = ldt02.getDayOfWeek(); // MONDAY22
23 // 转换为指定时区的Instant时刻24 Instant instant = ldt02.toInstant(ZoneOffset.of("+08:00")); // 2022-11-04T10:20:42.158Z25
26 // 转换为指定时区的毫秒值27 long epochSecond = ldt02.toEpochSecond(ZoneOffset.of("+08:00")); // 165754350528}29
注意:
DayOfWeek是一个枚举,有7个取值,从DayOfWeek.MONDAY到DayOfWeek.SUN-DAY。
LocalDate和LocalTime
LocalDateTime由两部分组成,一部分是日期(LocalDate),另一部分是时间(LocalTime),它们三者之间可以相互转换。
231public static void main(String[] args) {2 // 当前日期3 LocalDate ld01 = LocalDate.now();4
5 // 指定日期6 LocalDate ld02 = LocalDate.of(2017, 7, 11); // 2017年7月11日7
8 // 当前时间9 LocalTime lt01 = LocalTime.now();10
11 // 指定时间12 LocalTime lt02 = LocalTime.of(21, 10, 34); // 21时10分34秒13
14 // LocalDateTime拆分为LocalDate和LocalTime15 LocalDateTime ldt = LocalDateTime.of(2017, 7, 11, 20, 45, 5);16 LocalDate ld = ldt.toLocalDate(); //2017-07-1117 LocalTime lt = ldt.toLocalTime(); // 20:45:0518
19 // LocalDate和LocalTime合并为LocalDateTime20 LocalDateTime ldt01 = ld.atTime(21, 18, 39); // LocalDate + 时间 21 LocalDateTime ldt02 = lt.atDate(LocalDate.of(2016, 3, 24)); // LocalTime + 日期22}23
4) ZonedDateTime(时区相关日期时间)
261public static void main(String[] args) {2 // 使用默认毫秒值与时区构造3 ZonedDateTime zdt01 = ZonedDateTime.now();4
5 // 使用LocalDateTime+时区构造6 ZonedDateTime zdt02 = ZonedDateTime.of(LocalDateTime.now(), ZoneId.systemDefault());7
8 // 使用Instant+时区构造9 ZonedDateTime zdt03 = ZonedDateTime.ofInstant(Instant.now(), ZoneId.systemDefault()); // 方式一10 ZonedDateTime zdt03_ = Instant.now().atZone(ZoneId.systemDefault()); // 方式二11
12 // 指定日期时间+时区构造13 ZonedDateTime zdt04 = ZonedDateTime.of(2022, 11, 7, 15, 59, 30, 0, ZoneId.systemDefault());14
15 // 获取年月日等日历信息(与LocalDateTime类似,略......)16 int year = zdt04.getYear(); // 202217
18 // 转换为LocalDateTime19 LocalDateTime ldt = zdt04.toLocalDateTime();20
21 // 转换为Instant22 Instant instant = zdt04.toInstant();23
24 // 转换为毫秒值25 long epochSecond = zdt04.toEpochSecond();26}注意:
LocalDateTime只记录了年月日等相关信息,不记录时区信息,其它方法一般都要传递时区。
ZonedDateTime不仅记录了时刻,还记录了时区,ZonedDateTime ≈ LocalDateTime + 时区。
5) DateTimeFormatter
131public static void main(String[] args) {2 // 构造DateTimeFormatter实例(线程安全)3 DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");4
5 // 格式化6 String format = formatter.format(LocalDateTime.now());7
8 // 解析9 TemporalAccessor parse = formatter.parse("2016-08-18 14:20:45"); // 不常用10 Instant instant = Instant.parse("2016-08-18 14:20:45"); // 解析为Instant11 LocalDateTime localDateTime = LocalDateTime.parse("2016-08-18 14:20:45"); // 解析为LocalDateTime12 ZonedDateTime zonedDateTime = ZonedDateTime.parse("2016-08-18 14:20:45"); // 解析为ZonedDateTime13}
6) 修改日期和时间
直接设置或增减方式
修改日期和时间有两种方式,一种是直接设置绝对值,另一种是在现有值的基础上进行相对增减操作。
301public static void main(String[] args) {2 LocalDateTime ldt = LocalDateTime.now();3
4 // 设置为“下午3点20分”5 ldt = ldt.withHour(15).withMinute(20).withSecond(0).withNano(0); // 方式一:withXxx6 ldt = ldt.toLocalDate().atTime(15, 20); // 方式二:使用之前介绍的API,先转换为LocalDate,再加上指定时间7
8 // 加上“小时5分钟”9 ldt = ldt.plusHours(3).plusMinutes(5); // plusXxx10
11 // 今日0点12 ldt = ldt.with(ChronoField.MILLI_OF_DAY, 0); // 方式一:with(ChronoField.Xxx, 数值)13 ldt = LocalDateTime.of(LocalDate.now(), LocalTime.MIN); // 方式二14 ldt = LocalDate.now().atTime(0, 0); // 方式三15
16 // 下周二10点整17 ldt = ldt.plusWeeks(1).with(ChronoField.DAY_OF_WEEK, 2).with(ChronoField.MILLI_OF_DAY, 0).withHour(10);18
19 // 下一个周二10点整(针对今天是周一的特殊情形)20 LocalDate ld = LocalDate.now();21 if (!ld.getDayOfWeek().equals(DayOfWeek.MONDAY)) {22 ld = ld.plusWeeks(1);23 }24 ldt = ld.with(ChronoField.DAY_OF_WEEK, 2).atTime(10, 0);25
26 // 明天最后一刻27 ldt = LocalDateTime.of(LocalDate.now().plusDays(1), LocalTime.MAX); // 方式一28 ldt = LocalTime.MAX.atDate(LocalDate.now().plusDays(1)); // 方式二29}30
注意:
ChronoField是一个枚举,里面定义了很多表示日历的字段,MILLI_OF_DAY表示在一天中的毫秒数,值从0到(246060*1000) -1。
TemporalAdjuster接口方式
针对复杂的时间调整,JDK8专门定义了一个函数式接口TemporalAdjuster,Instant、LocalDateTime和LocalDate等都实现了它。与此相关的还有TemporalAdjusters类,里面提供了很多TemporalAdjuster的实现。
331// TemporalAdjuster接口2public interface TemporalAdjuster {3 Temporal adjustInto(Temporal temporal);4}5
6// TemporalAdjusters及测试7public static void main(String[] args) {8 LocalDateTime ldt = LocalDateTime.now();9 LocalDate ld = LocalDate.now();10 11 // 下一个周二10点整(针对今天是周一的特殊情形)12 ldt = ld.with(TemporalAdjusters.next(DayOfWeek.TUESDAY)).atTime(10, 0);13
14 // 本月最后一天的最后一刻15 ldt = LocalDate.now().with(TemporalAdjusters.lastDayOfMonth()).atTime(LocalTime.MAX);// 方式一16 long maxDayOfMonth = LocalDate.now().range(ChronoField.DAY_OF_MONTH).getMaximum();17 ldt = LocalDate.now().withDayOfMonth((int) maxDayOfMonth).atTime(LocalTime.MAX); // 方式二18
19 // 下个月第一个周一的下午5点整20 ldt = LocalDate.now().plusMonths(1).with(TemporalAdjusters.firstInMonth(DayOfWeek.MONDAY)).atTime(17, 0);21
22 23 /*24 // 其它方法举例25 public static TemporalAdjuster firstDayOfMonth()26 public static TemporalAdjuster lastDayOfMonth()27 public static TemporalAdjuster firstInMonth(DayOfWeek dayOfWeek)28 public static TemporalAdjuster lastInMonth(DayOfWeek dayOfWeek)29 public static TemporalAdjuster previous(DayOfWeek dayOfWeek)30 public static TemporalAdjuster nextOrSame(DayOfWeek dayOfWeek)31 */32}33
7) 计算时间段
JDK8中用Period表示日期差,差值为N年N月N日;用Duration表示时间差,单位可以为天(1天24小时)、时、分、秒、毫秒等。
121public static void main(String[] args) {2 // 两个日期之间的年月天数3 LocalDate ld1 = LocalDate.of(2016, 3, 24);4 LocalDate ld2 = LocalDate.of(2017, 7, 12);5 Period period = Period.between(ld1, ld2);6 System.out.println(period.getYears() + "年" + period.getMonths() + "月" + period.getDays() + "天"); // 1年3月18天7
8 // 两个时间之间的分钟数9 Duration duration = Duration.between(LocalTime.of(9, 0), LocalTime.now());10 System.out.println(duration.toDays() + "天|" + duration.toHours() + "时|" + duration.toMinutes() + "分|" + duration.toMillis() + "毫秒"); // 0天|7时|457分|27475454毫秒11}12
8) 与Date/Calendar对象的转换
581// Date -> EpochMilli -> Instant2public static Instant toInstant(Date date) {3 long epochMilli = date.getTime();4 return Instant.ofEpochMilli(epochMilli);5}6
7// Instant -> EpochMilli -> Date8public static Date toDate(Instant instant) {9 long epochMilli = instant.toEpochMilli();10 return new Date(epochMilli);11}12
13// Date -> EpochMilli-> Instant -(defaultZoneId)-> LocalDateTime14public static LocalDateTime toLocalDateTime(Date date) {15 long epochMilli = date.getTime();16 Instant instant = Instant.ofEpochMilli(epochMilli);17 return LocalDateTime.ofInstant(instant, ZoneId.systemDefault());18}19
20// LocalDateTime -(defaultZoneId)-> ZonedDateTime -> instant -> EpochMilli -> Date21public static Date toDate(LocalDateTime ldt) {22 ZonedDateTime zdt = ldt.atZone(ZoneId.systemDefault());23 Instant instant = zdt.toInstant();24 long epochMilli = instant.toEpochMilli();25 return new Date(epochMilli);26}27
28// ZonedDateTime -> Calendar29public static Calendar toCalendar(ZonedDateTime zdt) {30 // ZonedDateTime -> instant -> EpochMilli31 Instant instant = zdt.toInstant();32 long epochMilli = instant.toEpochMilli();33
34 // ZonedDateTime -> TimeZone35 TimeZone tz = TimeZone.getTimeZone(zdt.getZone());36
37 // TimeZone + EpochMilli -> Calendar38 Calendar calendar = Calendar.getInstance(tz);39 calendar.setTimeInMillis(epochMilli);40
41 return calendar;42}43
44// Calendar -> ZonedDateTime45public static ZonedDateTime toZonedDateTime(Calendar calendar) {46 // Calendar -> EpochMilli-> Instant47 long epochMilli = calendar.getTimeInMillis();48 Instant instant = Instant.ofEpochMilli(epochMilli);49
50 // Calendar -> TimeZone -> ZoneId51 ZoneId zoneId = calendar.getTimeZone().toZoneId();52
53 // Instant + ZoneId -> ZonedDateTime54 ZonedDateTime zdt = ZonedDateTime.ofInstant(instant, zoneId);55
56 return zdt;57}58
5. 其它常用类
1) 根类(Object/Objects)
java.lang.Object类是Java语言中的根类,即所有类的父类,java.util.Objects是与之配套的工具类。
| 方法名 | 说明 |
|---|---|
| protected Object clone() | 创建并返回对象的浅拷贝 |
boolean equals(Object obj) | 比较两个对象是否相等,默认按地址进行比较,可进行重写 |
| protected void finalize() | 在对象被回收前由垃圾回收器调用 |
| Class<?> getClass() | 获取对象的运行时对象的类 |
int hashCode() | 获取对象的 hash 值(Int类型) |
| void notify() | 唤醒在该对象上等待的某个线程 |
| void notifyAll() | 唤醒在该对象上等待的所有线程 |
String toString() | 返回对象的字符串表示形式 |
| void wait() | 让当前线程进入无限等待状态,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法 |
| void wait(long timeout) | 让当前线程进入超时等待状态 |
| void wait(long timeout, int nanos) | 让当前线程进入超时等待状态,支持纳秒级别控制(0-999999) |
281// Person默认继承Object,可对继承的方法进行重写2public class Person { 3 private String name;4 private int age;5
6 // 重写equals7 8 public boolean equals(Object o) {9 // 如果对象地址一样,则认为相同10 if (this == o)11 return true;12 // 如果参数为空,或者类型信息不一样,则认为不同13 if (o == null || getClass() != o.getClass())14 return false;15 16 // 转换为当前类型17 Person person = (Person) o;18 // 要求基本类型相等,并且将引用类型交给java.util.Objects类的equals静态方法取用结果19 return age == person.age && Objects.equals(name, person.name);20 }21 22 // 重写toString()23 24 public String toString() {25 return "Person{" + "name='" + name + '\'' + ", age=" + age + '}';26 }27}28
注意:
重写 equals 的同时一般也重写
hashcode(),用于初步判断对象是否相等,可在 HashSet、HashMap 等容器中优化性能。对象比较推荐使用
Objects.equals(Object obj1, Object obj2)方法,支持NULL值比较。
2) 系统与运行时(System/Runtime)
java.lang.System类中提供了大量的静态方法,可以获取与系统相关的信息或进行系统级操作。java.lang.Runtime描述的是运行时状态,在每一个JVM进程中都会提供唯一的一个Runtime类实例化对象,开发者可以通过Runtime类对象获取与JVM有关的运行时状态。
401public static void main(String[] args) {2 // 输入流、输出流、错误流3 // System.in // 输入流可以配合文本扫描器使用4 System.out.println(System.in); // 输出流,内部调用了String.valueOf()进行输出5 System.err.println("这是一些错误信息"); // 错误流6
7 // 当前毫秒数8 System.out.println(System.currentTimeMillis()); // 16672016311909
10 // 数组拷贝(高性能,支持源段和目标段重叠)11 int[] arr = new int[]{1, 2, 3, 4, 5};12 System.arraycopy(arr, 1, arr, 0, 3);13 System.out.println(Arrays.toString(arr)); // [2, 3, 4, 4, 5]14
15 // 获取内存、处理器相关信息16 System.out.println(Runtime.getRuntime().availableProcessors()); // 1617 System.out.println(Runtime.getRuntime().maxMemory()); // 749784268818 System.out.println(Runtime.getRuntime().totalMemory()); // 53215232019 System.out.println(Runtime.getRuntime().freeMemory()); // 52685439220
21 // 执行系统命令22 try {23 Process process = Runtime.getRuntime().exec("cmd /C mkdir java-test");24 } catch (IOException e) {25 e.printStackTrace();26 }27
28 // 关闭钩子29 Runtime.getRuntime().addShutdownHook(new Thread() {30 31 public void run() {32 System.out.println("----hook----");33 }34 });35
36 // 手动GC37 System.gc();38 Runtime.getRuntime().gc();39}40
注意:
System和Runtime都可以调用gc方法,但不建议在代码中手动干预,并且代码中的gc操作是可以通过JVM的运行参数来屏蔽的。
3) 随机数(Random)
Random类的实例用于生成伪随机数流。下面是一个生成范围1-n随机数的示例:
131public static void main(String[] args) {2 // 创建对象3 // Random r = new Random(); // 默认构造使用“真随机数”作为随机数种子4 Random r = new Random(System.currentTimeMillis()); // 使用当前时间作为随机数种子5
6 // 输出随机数7 for (int i = 0; i < 10; i++) {8 // [0,5)9 System.out.print(r.nextInt(5) + " "); // 4 3 0 3 3 0 0 1 2 1 10 }11
12}13
注意:
如果随机数种子相同,那么它们将生成并返回相同的数字序列。
Random类是线程安全的,但如果并发太高,会产生竞争,这时候可以考虑
ThreadLocalRandom类或Math.random()方法。Java类库中还有一个随机类
SecureRandom,可以产生安全性更高、随机性更强的随机数,用于安全加密等领域。
4) 数学运算(Math)
java.lang.Math类包含了一些数学常量和基本数学运算,如初等指数、对数、平方根和三角函数等。
221public static void main(String[] args) {2 // 绝对值3 System.out.println(Math.abs(-5.1)); // 5.14
5 // 向上/向下取整6 System.out.println(Math.ceil(1.2) + " " + Math.ceil(-1.2)); // 2.0 -1.07 System.out.println(Math.floor(1.2) + " " + Math.floor(-1.2)); // -1.0 -2.08 9 // 四舍五入10 System.out.println(Math.round(0.4) + " " + Math.round(0.5)); // 0 111 12 // 随机13 System.out.println(Math.random()); // [0,1) 0.2815391769059276714 15 // 最大值/最小值16 System.out.println(Math.max(1, 2)); // 217 System.out.println(Math.min(1, 2)); // 118 19 // 常量PI20 System.out.println(Math.PI); // 3.14159265358979321}22
5) 大数运算(BigDecimal)
java.math.BigDecimal用于对浮点数进行精确的运算,一般用于金额、利率计算等场景。
151public static void main(String[] args) {2 // BigDecimal(int)/BigDecimal(long) 基于整数构建BigDecimal对象3 BigDecimal bigDecimalByLong = new BigDecimal(18974865155L);4 System.out.println(bigDecimalByLong); // 189748651555
6 // BigDecimal(double) 基于浮点数构建BigDecimal对象7 // 极不推荐,不精确,可替换为:BigDecimal.valueOf(double val) 或 BigDecimal.valueOf(Double.toString(double))8 BigDecimal bigDecimalByDouble = new BigDecimal(1.2);9 System.out.println(bigDecimalByDouble); // 1.199999999999999955591079014993738383054733276367187510
11 // BigDecimal(String) 基于数值字符串构建BigDecimal对象(推荐)12 BigDecimal bigDecimalByString = new BigDecimal("1.2");13 System.out.println(bigDecimalByString); // 1.214}15
BigDecimal是对象类型,不能使用传统的+-*/等算术运算符直接对其对象进行数学运算,而必须调用其相对应的方法,方法中的参数也必须是BigDecimal的对象。
211public static void main(String[] args) {2 BigDecimal left = new BigDecimal("1.2");3
4 // 加减乘除5 System.out.println(left.add(new BigDecimal("1.3"))); // 2.56 System.out.println(left.subtract(new BigDecimal("1.3"))); // -0.17 System.out.println(left.multiply(new BigDecimal("1.3"))); // 1.568 // System.out.println(left.divide(new BigDecimal("1.3"))); // java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.9 System.out.println(left.divide(new BigDecimal("0.13"), 2, BigDecimal.ROUND_HALF_UP)); // 9.23 四舍五入保留2位小数10
11 // 比较(compareTo忽略精度,只比较数值,equals则精度和数值都要求相同)12 System.out.println(left.compareTo(new BigDecimal("1.3"))); // -1 小于时返回负数13 System.out.println(left.compareTo(new BigDecimal("1.20"))); // 0 等于时返回014 System.out.println(left.equals(new BigDecimal("1.2"))); // true15 System.out.println(left.equals(new BigDecimal("1.20"))); // false 精度不一致16
17 // 转化为基本类型18 System.out.println(new BigDecimal("1.23").toString()); // 1.2319 System.out.println(new BigDecimal("1.23").longValue()); // 120 System.out.println(new BigDecimal("1.23").doubleValue()); // 1.2321}注意:
不推荐基于浮点数直接构建BigDecimal对象,应先转换为字符串,再基于数值字符串构建BigDecimal对象。
如果进行除法运算的时候,结果不能整除(有余数),这个时候会报java.lang.ArithmeticException,需要设置精度和舍入模式。
BigDecimal 的等值比较应使用
compareTo()方法,而不是 equals() 方法,防止1.0 != 1.00。如果需要处理的数为大整数,可以使用
java.math.BigInteger来替代。
6) 文本扫描器(Scanner)
java.util.Scanner类是一个可以使用正则表达式来解析基本类型和字符串的简单文本扫描器。
121public static void main(String[] args) {2 // 定义扫描器3 Scanner sc = new Scanner(System.in); // System.in表示从键盘扫描4
5 // 阻塞等待键盘输入6 System.out.print("请录入一个整数:");7 int i = sc.nextInt(); // 读取一个整数8
9 // 回显10 System.out.println("你输入的整数是:" + i);11}12
7) 比较器(Comparator)
java.util.Comparator接口用于比较两个对象的大小,小于时返回负数,等于时返回0,大于时返回正数。
201// 比较器接口2public interface Comparator<T> {3 int compare(T o1, T o2);4 boolean equals(Object obj);5}6
7// String内部有一个忽略大小写的比较器8public static final Comparator<String> CASE_INSENSITIVE_ORDER = new CaseInsensitiveComparator();9
10// 包装类、String中一般都有compareTo方法11Integer integer = new Integer(0);12System.out.println(integer.compareTo(1)); // -113
14// 比较器反转15Comparator<Object> objectComparator = Collections.reverseOrder(); // 倒序16Comparator<String> stringComparator = Collections.reverseOrder(String.CASE_INSENSITIVE_ORDER); // 将String.CASE_INSENSITIVE_ORDER比较器反转17
18// 构建比较器,然后反转,再引入次要比较器19students.sort(Comparator.comparing(Student::getScore).reversed().thenComparing(Student::getName)); // 将学生列表按照分数倒序排(高分在前),分数一样的,按照名字进行排序20
8) 关闭钩子(AutoCloseAble)
JDK1.7引入了AutoCloseAble接口,配合try(获取资源){}语法进行使用,这样获取的资源可以自动关闭,无需手动释放。
451// AutoCloseable接口2public interface AutoCloseable {3 void close() throws Exception;4}5
6// 实现AutoCloseable接口7public class TransactionManager implements AutoCloseable {8 private boolean rollback = true;9
10 public TransactionManager() {11 // 开启事务,并将事务状态存在线程变量中12 TransManager.startTrans();13 }14
15 public void doSuccess() {16 // 提交当前线程事务17 TransManager.commitTrans();18 rollback = false;19 }20
21 22 public void close() {23 // 如果事务没有提交,则默认执行回滚24 if (rollback) {25 TransManager.rollbackTrans();26 }27 }28}29
30// 测试31public static void main(String[] args) {32 // 在try()中获取实现了AutoCloseable接口的资源33 // try代码块执行完毕后自动调用其close()方法34 try (TransactionManager transactionManager = new TransactionManager()) {35 // 业务处理36 System.out.println("业务处理中...");37
38 // 手动提交事物39 transactionManager.doSuccess();40 } catch (Exception e) {41 // 异常处理42 e.printStackTrace();43 }44}45
9) 空值处理(Optional)
java.util.Optional是Java 8引入的一个泛型容器类,内部只有一个类型为T的单一变量value,可能为null,也可能不为null。
Optional有什么用呢?它用于准确地传递程序的语义,它清楚地表明,其代表的值可能为null,程序员应该进行适当的处理。
91// 构建Optional2public static<T> Optional<T> empty() // 构建一个空的Optional,value为null3public static <T> Optional<T> of(T value) // 构建一个非空的Optional, 参数value不能为null4public static <T> Optional<T> ofNullable(T value) // 构建一个Optional,参数value可以为null,也可以不为null5
6// 使用Optional7public boolean isPresent() // value不为null时返回true8public T get() // 返回实际的值,如果为null,抛出异常NoSuchElementException9public T orElse(T other) // 如果value不为null,返回value,否则返回other
10) Unsafe类
Unsafe 是
sun.misc包下的一个类,用于执行一些低级别的,不安全的操作,如直接内存访问。Unsafe 是一个单例类,且只能被引导类加载器
BootstrapClassLoader加载的类使用,否则会抛SecurityException异常。业务类可以通过反射获取实例,或者将业务类配置为通过引导类加载器加载:
java -Xbootclasspath/a: ${path}。
101private static Unsafe reflectGetUnsafe() {2 try {3 Field field = Unsafe.class.getDeclaredField("theUnsafe");4 field.setAccessible(true);5 return (Unsafe) field.get(null);6 } catch (Exception e) {7 log.error(e.getMessage(), e);8 return null;9 }10}
第03章_泛型
第一节 泛型简介
1. 什么是泛型?
泛型是计算机编程中一种重要的思维方式,它将程序算法与数据类型相分离,使得同一套程序算法能够应用于各种数据类型,并且可以保证类型安全,提高可读性。
通俗来说,泛型就是类型参数化,即通过参数的形式传入类型,将代码与具体的数据类型解绑,同一套代码可用于多种数据类型。
341/* 泛型类 Pair,拥有两个泛型 U 和 V */2public class Pair<U, V> {3 U first;4 V second;5
6 public Pair(U first, V second) {7 this.first = first;8 this.second = second;9 }10
11 public U getFirst() {12 return first;13 }14
15 public V getSecond() {16 return second;17 }18
19 public static void main(String[] args) {20 // 泛型类实例化01 传入泛型参数 <String, String> => <U,T>21 Pair<String, String> pair01 = new Pair<String, String>("老马", "说编程");22
23 // 泛型类实例化02 传入泛型参数 <String, Integer> => <U,T>24 Pair<String, Integer> pair02 = new Pair<String, Integer>("老马", 100);25
26 // 使用泛型类对象, 无需强制类型转换27 String first = pair01.getFirst();28 String second = pair01.getSecond();29
30 // 提示:JDK7+版本,new后面的类型参数可以省略,会自动推断31 Pair<String, Integer> pair02_ = new Pair<>("老马", 100);32 }33}34
2. 泛型的本质
泛型的本质是类型擦除(这对后面理解泛型非常重要)。在编译过程中,所有的泛型都将会被替换为Object类(或其上界类),并在合适的位置插入必要的强制类型转换,虚拟机只能执行这种转换后的非泛型代码。
271// 编译后:泛型被擦除,泛型类型被替换为Object(或其上界类)2public class ErasedPair {3 Object first;4 Object second;5
6 public ErasedPair(Object first, Object second) {7 this.first = first;8 this.second = second;9 }10
11 public Object getFirst() {12 return first;13 }14
15 public Object getSecond() {16 return second;17 }18
19 public static void main(String[] args) {20 ErasedPair pair01 = new ErasedPair("老马", 100);21
22 // 编译后:在使用处插入强制类型转换23 String first = (String) pair01.getFirst(); // "老马"24 Integer second = (Integer) pair01.getSecond(); // 10025 }26}27
3. 泛型的好处
前面得知,泛型类最后依旧会被转换为非泛型类,那么我们使用泛型类有什么好处呢? 主要有两点:
避免强制类型转换,做到在编译期进行类型安全检查,防止类型转换异常(ClassCastException)。
精简代码,增强代码的健壮性和可维护性。
第二节 泛型的基本使用
泛型根据定义的位置不同,分为泛型类、泛型接口、泛型方法三类。
1. 泛型类
601// 1. 泛型类:在类名后声明泛型,后面将在实例化泛型类时具体化泛型(E)2public class DynamicArray<E> {3 private static final int DEFAULT_CAPACITY = 10;4 private int size;5 private Object[] elementData;6
7 public DynamicArray() {8 this.elementData = new Object[DEFAULT_CAPACITY];9 }10
11 // 动态扩容12 private void ensureCapacity(int minCapacity) {13 int oldCapacity = elementData.length;14 if (oldCapacity >= minCapacity) {15 return;16 }17 int newCapacity = oldCapacity * 2;18 if (newCapacity < minCapacity) {19 newCapacity = minCapacity;20 }21 elementData = Arrays.copyOf(elementData, newCapacity); // 拷贝到newCapacity长度的新数组22 }23
24 public void add(E e) {25 ensureCapacity(size + 1);26 elementData[size++] = e;27 }28
29 public E get(int index) {30 return (E) elementData[index];31 }32
33 public int size() {34 return size;35 }36
37 public E set(int index, E element) {38 E oldValue = get(index);39 elementData[index] = element;40 return oldValue;41 }42
43 public static void main(String[] args) {44 // 2. 在实例化泛型类时具体化泛型(E)45 // 2.1 具体化为具体类型,此时具体化为Double类型46 DynamicArray<Double> doubleDynamicArray = new DynamicArray<>();47 doubleDynamicArray.add(1.23);48
49 // 2.2 具体化为具体类型中的Object类型(不推荐这样使用,因为后面使用时需要强制类型转换,违背了泛型的本意)50 DynamicArray<Object> objectDynamicArray = new DynamicArray<>();51 DynamicArray defaultDynamicArray = new DynamicArray(); // 具体化过程<xxx>可以省略,默认为<Object>52 defaultDynamicArray.add("老马");53 defaultDynamicArray.add(100);54
55 // 2.3 具体化为其它泛型类,此时具体化为Pair<String, Integer>类型(其中Pair的泛型U,V分别具体化为String, Integer类型)56 DynamicArray<Pair<String, Integer>> pairDynamicArray = new DynamicArray<>();57 pairDynamicArray.add(new Pair<>("老马", 100));58 } 59}60
2. 泛型接口
491// 1. 泛型接口:在接口名后声明泛型,后续将在实现接口时具体化泛型(T)2public interface Comparable<T> {3 int compareTo(T o);4}5
6// 2. 在实现接口时具体化泛型(T)7// 2.1 具体化为具体类型,此处为Integer8public class MyInteger implements Comparable<Integer> {9 private Integer num;10
11 12 public int compareTo(Integer o) { // 可以与Integer类型的其它对象比较13 return this.num - o;14 }15}16
17// 2.2 具体化为具体类型,此处为Object18public class MyObject implements Comparable<Object> {19 private Object num;20
21 22 public int compareTo(Object o) { // 可以与Object类型的其它对象比较23 return this.num.hashCode() - o.hashCode();24 }25}26
27// 2.3 具体化为新声明的泛型(泛型传递),此时具体化为子类新声明的(TT) 28// 注意:这里为了区分Comparable的泛型名称T,取名为TT;实际上,新声明的泛型也可以叫T;29public class MyInfo<TT> implements Comparable<TT> {30 private TT info;31
32 public MyInfo(TT info) {33 this.info = info;34 }35
36 37 public int compareTo(TT o) {38 return info.hashCode() - o.hashCode(); // 可以与TT类型的其它对象比较39 }40
41 public static void main(String[] args) {42 // 2.3 在实例化子类时,将具体化子类的泛型TT,此时TT具体化为String类型43 // 进而,将已知的TT类型(String)传递给Comparable接口的泛型T(泛型传递)44 MyInfo<String> stringMyInfo = new MyInfo<>("hyx");45 int compare = stringMyInfo.compareTo("hyx2");46
47 }48}49
3. 泛型方法
251// 1. 泛型方法:在返回值之前声明泛型2public static <T> int indexOf(T[] arr, T elm) {3 for (int i = 0; i < arr.length; i++) {4 if (arr[i].equals(elm)) {5 return i;6 }7 }8 return -1;9}10
11// 扩展:多个泛型参数的泛型方法12public static <U, V> Pair<U, V> makePair(U first, V second) {13 Pair<U, V> pair = new Pair<>(first, second);14 return pair;15}16
17public static void main(String[] args) {18 // 2. 在使用方法时具体化泛型(T)19 int indexOf01 = indexOf(new Integer[]{1, 3, 5}, 10); // 此时具体化为具体类型Integer20 int indexOf02 = indexOf(new String[]{"hello", "老马", "编程"}, "老马"); // 此时具体化为具体类型String21
22 // 注意:和泛型类/泛型接口不同,泛型方法在使用时一般并不需要特意指定泛型的具体类型,它会根据实参自动推断23 Pair<Integer, String> pair = makePair(1, "老马");24}25 注意:
如果方法为静态方法,那么将不能够使用类上声明的泛型(静态变量同理),因为他们是类级别共享的。
一个方法是不是泛型的,与它所在的类是不是泛型没有任何关系,可以使用类上的泛型,也可以新定义方法的泛型。
4. 泛型的类型信息
虽然泛型在编译时被擦除为Object或上界类,但是在运行时,泛型引用的对象是实际的不同具体类型,并且可以获取和使用该类型信息。
311public class MyWrapper<T> {2 private T data;3
4 public MyWrapper(T data) {5 this.data = data;6 }7
8 public Class<?> getDataType() {9 // 具体化类型的Class信息10 return data.getClass();11 }12
13 public T create() throws IllegalAccessException, InstantiationException {14 return (T) getDataType().newInstance();15 }16
17 public static void main(String[] args) throws InstantiationException, IllegalAccessException {18 // 1. 使用不同的类型具体化泛型19 MyWrapper<String> strWrapper = new MyWrapper<>("abc");20 MyWrapper<Date> dateWrapper = new MyWrapper<>(new Date());21
22 // 2. 获取具体化类型的Class信息23 System.out.println(strWrapper.getDataType()); // class java.lang.String24 System.out.println(dateWrapper.getDataType()); // class java.lang.Integer25
26 // 3. 使用“具体化类型的Class信息”创建“具体化类型对象”27 Date date = dateWrapper.create();28 System.out.println(date); // Wed Feb 08 16:53:14 CST 202329 }30}31
第三节 限定泛型
1. 无限定泛型的使用限制
在上述案例中,声明泛型时未做任何额外的限制,因此在泛型具体化时,可以使用任意类型,这种未被限制的泛型称为无限定泛型。也正是因为在具体化时没有限制类型的取值范围,因此无限定泛型在使用时将会受到一些限制。
例如,在通过泛型引用E e操作指向的对象时,由于E可能是任意类型,因此只能调用任意类型的根类Object的属性或方法。
101public void method01(E e) {2 // 1. 只能调用任意类型的根类Object的属性或方法3 e.hashCode(); // Object的方法,OK4 //e.childClassMethod(); // 非Object方法,ERR5
6 // 2. 只能赋值给Object或同类型引用E7 Object o = e;8 E ee = e;9 //Number n = e; // Error: 不兼容的类型: E无法转换为java.lang.Number10}为了减弱上述限制,我们可以在声明泛型时进一步限定泛型可具体化的类型范围,要求其必须继承某类或实现某个接口,这样就可以在保证类型安全的前提下使用该类(接口)的一系列方法了,这种被限制可具体化类型范围的泛型称为限定泛型。
2. 限定为某类(接口)或其子类
上文提到的Pair<U,V>类,对其进行扩展,限定泛型可具体化的类型必须是Number或其子类,格式为:<泛型名 extends 上界类名>。
191// 1. 泛型类NumberPair,声明了泛型U,V,并限定必须为Number或其子类2public class NumberPair<U extends Number, V extends Number> extends Pair<U, V> {3 public NumberPair(U first, V second) {4 super(first, second);5 }6
7 // 2. 泛型进行限定后,就可以使用上界类的一系列属性和方法了8 public double sum() {9 return getFirst().doubleValue() + getSecond().doubleValue(); // 使用Number的doubleValue()方法10 }11
12 public static void main(String[] args) {13 // 3. 在实例化时,泛型的具体化类型必须为Number或其子类14 // NumberPair<String, Long> pair = new NumberPair<String, Long>(1, 2L); // Type parameter 'java.lang.String' is not within its bound; should extend 'java.lang.Number'15 NumberPair<Integer, Long> pair = new NumberPair<>(1, 2L); // Integer, Long都是Number的子类16 double sum = pair.sum();17 }18}19
注意:
对于限定泛型,在进行类型擦除时,将转换为它的上界类。
上界接口可以存在多个,如:
T extends Base & Comparable & Serializable,其中Base为上界类,其它为上界接口。
2. 上界类为泛型类
上界类也可以是一个带泛型的泛型类,那么在声明限定泛型时,必须对上界类的泛型进行具体化:
661import java.lang.Comparable;2
3public class MainTest {4 // 1. 上界类的泛型具体化为某个具体类型(由于该具体类型难以和原限定泛型T有交互,因此使用极少)5 // 调用要求:限定泛型T的具体化类型必须实现Comparable<String>接口6 public static <T extends Comparable<String>> T maxInString(T[] arr) {7 T max = arr[0];8 for (int i = 1; i < arr.length; i++) {9 if (arr[i].compareTo(max.toString()) > 0) { // compareTo的形参类型为String10 max = arr[i];11 }12 }13 return max;14 }15
16 // 2. 上界类的泛型具体化为原限定类型T(递归类型限制,常用)17 // 调用要求:限定泛型T的具体化类型必须实现Comparable<T>接口18 public static <T extends Comparable<T>> T maxInT(T[] arr) {19 T max = arr[0];20 for (int i = 1; i < arr.length; i++) {21 if (arr[i].compareTo(max) > 0) { // compareTo的形参类型为T22 max = arr[i];23 }24 }25 return max;26 }27
28 // 3.上界类的泛型具体化为Object(使用极少)29 // 调用要求:限定泛型T的具体化类型必须实现Comparable<Object>接口30 public static <T extends Comparable<Object>> T maxInObject(T[] arr) {31 T max = arr[0];32 for (int i = 1; i < arr.length; i++) {33 if (arr[i].compareTo(max) > 0) { // compareTo的形参类型为Object34 max = arr[i];35 }36 }37 return max;38 }39
40 // 4. 上界类的泛型具体化类型省略(这里不是默认为Object类型,而是为?类型,后文将会讲解)41 // 调用要求:限定泛型T的具体化类型必须实现Comparable<?>接口,?表示任意类型42 public static <T extends Comparable> T maxInAnyone(T[] arr) {43 T max = arr[0];44 for (int i = 1; i < arr.length; i++) {45 if (arr[i].compareTo(max) > 0) { // compareTo的形参类型为Object46 max = arr[i];47 }48 }49 return max;50 }51
52 public static void main(String[] args) {53 // 定义一个String类型的数组,String实现了java.lang.Comparable<String>接口54 String[] stringArr = {"a", "b", "c"};55
56 // 可以使用maxInString、maxInT、maxInAnyone方法57 maxInString(stringArr); 58 maxInT(stringArr); 59 maxInAnyone(stringArr);60
61 // 不允许使用maxInObject方法,因为String并未实现Comparable<Object>接口62 // maxInObject(stringArr);63 }64}65
66
注意:
在实例化泛型类时,如果泛型的具体类型省略,将默认为Object类型,但是在具体化上界类时,并非如此。
3. 上界类为其它泛型
上界类还可以是已声明的其它泛型,当该泛型被具体化时,才会确定上界类的具体类型。如上述的DynamicArray的addAll()方法:
131// 1. 上界类的类型为类上声明的泛型E,即限定泛型T的上界为E2public <T extends E> void addAll(DynamicArray<T> c) {3 for (int i = 0; i < c.size; i++) {4 add(c.get(i)); // 解释:由于T是E或其子类,因此可以调用add(E e)方法5 }6}7
8public static void main(String[] args) {9 // 通过 T extends E 使DynamicArray<Number>容器允许添加DynamicArray<Integer>容器中的对象10 DynamicArray<Number> numberArr = new DynamicArray<>();11 numberArr.addAll(new DynamicArray<Integer>());12}13
如果不使用T extends E将会怎样?即addAll()方法定义如下所示,可以看到,将会出现编译错误。
141// 直接使用类上的泛型E2public void addAll2(DynamicArray<E> c) { // 只能接收DynamicArray<E>类型3 for (int i = 0; i < c.size; i++) {4 add(c.get(i)); 5 }6}7
8public static void main(String[] args) {9 DynamicArray<Number> numberArr = new DynamicArray<>();10 11 // err 提示需要一个DynamicArray <Number>类型,但是提供了一个DynamicArray <Integer>类型12 numberArr.addAll2(new DynamicArray<Integer>()); 13}14
为什么会出现编译错误呢?我们分析下,如果DynamicArray<Integer>能给DynamicArray<Number>赋值将会怎么样?
71// 如果上述DynamicArray<Integer>类型可以赋值给DynamicArray<Number>类型2DynamicArray<Integer> integerArray = new DynamicArray<>();3DynamicArray<Number> numberArray = integerArray; // 假设成立4
5// 由于numberArray的泛型的具体类型为Number,那么将可以通过add(E e)方法添加Double类型的数据到之前的integerArray之中!6numberArray.add(new Double(1.2)); // 如果上述假设成立那么将会出现该非法操作7
注意:
在add()方法中,形参为E,类型擦除后转换为Number,可以传入Number及Integer等子类;
但是在addAll()方法中,形参为DynamicArray<E>,类型擦除后为DynamicArray<Number>,而DynamicArray<Integer>是不允许传给DynamicArray<Number>的,否则将会出现上述隐患;
第四节 泛型通配符
在泛型具体化时(而非声明时),支持一些通配符的使用,它可以通配多种具体类型,但同时也带来了一些限制,下面将会详细介绍。
1. 通用泛型通配符
通用泛型通配符用于在具体化泛型时通配所有的具体类型,它简化了泛型的声明和使用,格式为:?。
101// 在具体化类泛型E时,使用?通配所有的具体类型2public static int indexOf(DynamicArray<?> arr, Object elm) {3 for (int i = 0; i < arr.size(); i++) {4 if (arr.get(i).equals(elm)) { // 由于arr.get(i)的具体类型是?,因此只能调用Object对应的方法5 return i;6 }7 }8 return -1;9}10 相应的,由于具体类型未知,因此在使用被通配的泛型对象时,也有一些限制。
81// 1. 只能使用Object类型作为引用2Object o = arr.get(0);3
4// 2. 只能调用任意类型的根类Object的属性和方法5arr.get(0).hashCode();6
7// 3. 不能当作任何对象的引用,即不能被赋值8arr.get(0) = new Object() // err为减弱上述限制,根据不同的使用场景,提供了两种特定通配范围的泛型通配符:子类型泛型通配符和超类型泛型通配符。
2. 子类型泛型通配符
子类型泛型通配符对通配的具体类型范围做出了一些限制,用于通配ParentClass其子类,格式为:? extends ParentClass。
171// 在具体化类泛型E时,通配E及其子类2public void addAll(DynamicArray<? extends E> c) { 3 for (int i = 0; i < c.size; i++) {4 add(c.get(i)); 5 }6}7
8public static void main(String[] args) {9 // Number容器添加Integer容器的所有数据10 DynamicArray<Number> numbers = new DynamicArray<>();11 DynamicArray<Integer> ints = new DynamicArray<>();12 ints.add(100);13 numbers.addAll(ints); // 这里类泛型E为Number,由于addAll方法在实例化E时通配了所有Number的子类,因此可以正确传参14}15
16// adAll方法的泛型具体化为什么不是<E>:虽然可以调用add(E e),但是采用严格匹配,Number容器无法添加Integer容器数据17// adAll方法的泛型具体化为什么不是<?>:虽然可以传参进来,但是add(E e)无法调用,因为?不一定是E或其子类在得知子类型泛型通配符只通配某个类及其子类后,那么就可以确定它的上界类了,上界类确定后就可以使用上界类的属性和方法,并且可以赋值给上界类。(注意:该例中上界类为E,同样是一个未知类型,因此没有其它额外的方法可以调用,同样也只能够赋值给E)
3. 超类型泛型通配符
超类型泛型通配符和子类型泛型通配符相反,它用于通配ChildClass及其父类,格式为:? super ChildClass。
191// 在具体化类泛型E时,通配E及其父类2public void copyTo(DynamicArray<? super E> dest) {3 for (int i = 0; i < size; i++) {4 dest.add(get(i)); // get(i)的类型为E;dest容器的类型为E或其父类;5 }6}7
8public static void main(String[] args) {9 // Integer容器数据拷贝到另外的Number容器中10 DynamicArray<Integer> ints2 = new DynamicArray<Integer>();11 ints.add(100);12 ints.add(34);13 DynamicArray<Number> numbers2 = new DynamicArray<Number>();14 ints.copyTo(numbers);15}16
17// copyTo方法的泛型具体化为什么不是<E>:虽然可以调用add(E e),但是采用严格匹配,Number容器数据无法添加到Integer容器18// copyTo方法的泛型具体化为什么不是<?>:虽然可以传参进来,但是add(E e)无法调用,因为?不一定是E或其父类19// copyTo方法的泛型具体化为什么不是<? extends E>:add(E e)无法调用,虽然?一定是E或其子类,但不一定是E或其父类在得知超类型泛型通配符只通配某个类及其父类后,那么就可以确定它的下界类了,下界类确定后就可以使用下界类作为引用。
注意:关于限定泛型、子类型通配符、超类型通配符的赋值兼容
91// 限定泛型<T extends Number>,表示限定具体化类型只能是Number或其子类2// 通配Number及其子类,由于Integer是Number的子类,所以可以赋值4DynamicArray<? extends Number> numberArray = new DynamicArray<Integer>();5// 通配Number及其父类,由于Integer不是Number的父类,所以不可以赋值7DynamicArray<? super Number> numberArray = new DynamicArray<Integer>(); // err8DynamicArray<? super Number> numberArray2 = new DynamicArray<Object>(); // OK,Object是Number的父类,可以通配9
再来看另外一个关于超类型通配符的使用场景:
601// 普通类Base继承了Comparable<Base>2class Base implements Comparable<Base> {3 private int sortOrder;4
5 public Base(int sortOrder) {6 this.sortOrder = sortOrder;7 }8
9 10 public int compareTo(Base o) {11 if (sortOrder < o.sortOrder) {12 return -1;13 } else if (sortOrder > o.sortOrder) {14 return 1;15 } else {16 return 0;17 }18 }19}20
21// Child继承了Base,相当于间接继承了Comparable<Base>,因此继承了int compareTo(Base o)方法22class Child extends Base {23 public Child(int sortOrder) {24 super(sortOrder);25 }26
27 // max方法声明方式128 public static <T extends Comparable<T>> T max(DynamicArray<T> arr) {29 if (arr == null || arr.size() == 0) {30 return null;31 }32
33 T max = arr.get(0);34 for (int i = 1; i < arr.size(); i++) {35 if (arr.get(i).compareTo(max) > 0) {36 max = arr.get(i);37 }38 }39
40 return max;41 }42 43 // max方法声明方式2:引入超类型通配符44 public static <T extends Comparable<? super T>> T max(DynamicArray<T> arr) {45 // ...46 }47 48 // 如下为测试代码49 public static void main(String[] args) {50 DynamicArray<Child> childs = new DynamicArray<Child>();51 childs.add(new Child(20));52 childs.add(new Child(80));53 54 // 调用max,其中T为Child55 // 方式1:要求T(Child)必须实现Comparable<Child>接口,但是Child实现的是Comparable<Base>接口,错误!56 // 方式2:要求T(Child)必须实现Comparable<? super Child>接口,其中Comparable的泛型可以通配Child及其父类,自然也可以是base,OK!57 Child maxChild = max(childs); 58 }59}60
4. 限定泛型和泛型通配符对比
限定泛型在声明泛型时使用,泛型通配符在具体化泛型时使用,它们的使用时机不同。
泛型通配符形式和限定泛型往往配合使用,如下面的swap()方法。
191// 1. 通配所有类型,用户阅读和使用更加方便2// 注意:由于arr使用了通用泛型通配符,未知类型(arr.get(j))不能给set()方法的第二个形参(也是未知类型的引用)赋值3public static void swap(DynamicArray<?> arr, int i, int j) {4swapInternal(arr, i, j); // 内部调用泛型方法5}67// 2. 私有的泛型方法,内部能够使用set()方法8private static <T> void swapInternal(DynamicArray<T> arr, int i, int j) {9T tmp = arr.get(i);10arr.set(i, arr.get(j));11arr.set(j, tmp);12}1314// 3. 其它综合使用案例15public static <T extends Comparable<? super T>> void sort(List<T> list)16public static <T> void sort(List<T> list, Comparator<? super T> c)17public static <T> void copy(List<? super T> dest, List<? extends T> src)18public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp)19通常子类型泛型通配符可以使用限定泛型来实现,但是方法返回值依赖于泛型等特殊情况除外。
341// 拷贝容器数据,方式1:2public static <D, S extends D> void copy(DynamicArray<D> dest, DynamicArray<S> src) {3for (int i = 0; i < src.size(); i++) {4dest.add(src.get(i));5}6}7// 拷贝容器数据,方式2:8public static <D> void copy(DynamicArray<D> dest, DynamicArray<? extends D> src) {9for (int i = 0; i < src.size(); i++) {10dest.add(src.get(i));11}12}1314// 添加容器数据,方式1:15public <T extends E> void addAll(DynamicArray<T> c){}16// 添加容器数据,方式2:17public void addAll(DynamicArray<? extends E> c){}1819// indexOf,方式1:20public static <T> int indexOf(DynamicArray<T> arr, Object elm)21// indexOf,方式2:22public static int indexOf(DynamicArray<?> arr, Object elm)2324// 返回值依赖于泛型:返回类型无法用通配符替代25public static <T extends Comparable<T>> T max(DynamicArray<T> arr) {26T max = arr.get(0);27for (int i = 1; i < arr.size(); i++) {28if (arr.get(i).compareTo(max) > 0) {29max = arr.get(i);30}31}32return max;33}34
第五节 泛型的局限性
前面提到,Java中的泛型是通过类型擦除来实现的,所有的泛型在编译时都会被替换为Object或上界类,运行时Java虚拟机不知道泛型这回事,这带来了很多局限性,其中有的部分是比较容易理解的,有的则是非常违反直觉的 。
1. 泛型的具体化类型不能是基本类型
泛型的具体化类型不能是基本类型,应该使用它的包装类。
31// 不能使用int去具体化泛型,因为int没有根类Object2Pair<int> intPair = new Pair<int>(1,100);3
2. 不能通过泛型直接创建对象
不能通过泛型直接创建对象,需要传入泛型对应的类型信息,通过反射创建。
191// 1. 由于类型擦除,使用new T()创建的对象也只能当Object使用,并且容易引起使用者误解,所以Java干脆禁止2T elm = new T(); // err3
4// 同样,泛型数组也是不允许创建的(容器的元素类型一般为Object而非泛型E与此相关)5T[] arr = new T[10]; // err 不能创建泛型数组6
7
8// 2. 如果希望创建具体化类型的对象,则可传入具体化类型的Class对象,根据反射创建9public static <T> T create(Class<T> type) {10 try {11 return type.newInstance(); // 反射12 } catch (Exception e) {13 return null;14 }15}16
17// 创建Date对象18Date date = Pair.create(Date.class);19
提示:
实际上,可以参考第二节中,通过泛型引用的对象获取Class信息,进而创建对象。
3. 泛型类的不同具体化本质上还是同一个类
泛型在编译时将会被擦除为Object(或上界类),不同的具体化类型只是在编译时自动插入了不同的强制类型转换,本质上还是同一个类。
由于是同一个类,因此它们的类型信息完全一致,并且类上所具有的静态资源也是共享的。
251// 1. 不同具体化类型的两个Pair对象2Pair<String, String> pair01 = new Pair<String, String>("老马", "说编程");3Pair<String, Integer> pair02 = new Pair<String, Integer>("老马", 100);4
5// 类型信息是完全一致的6System.out.println(Pair.class); // class com.huangyuanxin.notes.javabase.generics.Pair7System.out.println(Pair.class == pair01.getClass()); // true8System.out.println(pair01.getClass() == pair02.getClass()); // true9System.out.println(Pair<?, ?>.class); // err10System.out.println(Pair<String, Integer>.class); // err 11
12// 类型也可以使用instanceof关键字进行判断13if (pair01 instanceof Pair){} // OK14if (pair01 instanceof Pair<?, ?>){} // OK,特殊情形15if (pair01 instanceof Pair<Integer>){} // err16
17
18// 2. 定义如下静态变量19public static String STATIC_NAME = "PAIR";20
21// 打印静态变量,发现也是共享的22Pair.STATIC_NAME = "STATIC_NAME_MODIFY";23System.out.println(Pair.STATIC_NAME); // STATIC_NAME_MODIFY24System.out.println(pair01.STATIC_NAME); // STATIC_NAME_MODIFY25
注意:
内部的first/second编译时都被擦除为Object类型,但是运行时分别指向不同的具体化类型对象。
4. 类上的泛型不能用于静态变量或静态方法
泛型类的泛型不能用于静态变量或静态方法,应为静态方法单独声明泛型,而静态变量不允许为泛型。
121// 声明泛型T,仅适用于成员变量和成员方法2public class Singleton<T> {3 private static T instance; // err 静态变量不能为泛型4
5 public synchronized static T getInstance() { // err 不能用于静态方法6 if (instance == null) {7 //创建实例8 }9 return instance;10 }11}12
5. 类型擦除可能会引发一些冲突
241// 1. 案例一:如下,Base实现了Comparable<Base>接口 2class Base implements Comparable<Base>{} 3
4// Child继承Base,间接实现了Comparable<Base>接口,OK!5class Child extends Base{} 6
7// 如果Child想自定义compareTo()方法,发现不能实现Comparable<Child>接口8class Child extends Base implements Comparable<Child>{} // err,重复实现了9
10// 此时只能重写Base中的方法来自定义Child中的该方法11public int compareTo(Base o) {13 if (!(o instanceof Child)) {14 throw new IllegalArgumentException();15 }16 Child c = (Child) o;17 return 0;18}19
20
21// 2. 案例二:看起来很像方法重载,但是由于类型擦除后都是Object,因此也是不允许的22public static void test(DynamicArray<Integer> intArr){}23public static void test(DynamicArray<String> strArr){}24
6. 不能直接创建泛型数组
如下创建泛型数组的代码是禁止的:
41Pair<Object, Integer>[] options = new Pair<Object, Integer>[]{2 new Pair("1元", 7), new Pair("2元", 2), new Pair("10元", 1)3};4
因为数组是Java直接支持的概念,它知道数组元素的实际类型,在类型不对时可快速触发运行时异常,因此编译时允许赋值给父类数组。
51// 创建普通类型数组2Integer[] ints = new Integer[10];3Number[] numbers = ints; // 子类数组赋值给父类数组 ok4numbers[0] = 1.2; // 类型不对,触发运行时异常:java.lang.ArrayStoreException: java.lang.Double5
但是如果允许创建泛型数组,如下:
51// 创建泛型数组2Pair<Object, Integer>[] options = new Pair<Object, Integer>[3];3Object[] objs = options; // 子类数组赋值给父类数组4objs[0] = new Pair<Double, String>(12.34, "hello"); // 隐患代码5
由于Pair<Double, String>和Pair<Object, Integer>的类型都是Pair,因此第二行赋值时即不会编译报错,也不会立即触发运行时异常,埋下了隐患,因此Java禁止创建泛型数组。
如果我们非要创建泛型类型的数组,可以使用原始类型来创建,这样可以跳过编译检查,但是问题还是存在的。
71Pair[] options = new Pair[]{2 new Pair<String, Integer>("1元", 7),3 new Pair<String, Integer>("2元", 2),4 new Pair<String, Integer>("10元", 1),5 new Pair<String, String>("10元", "1") // 注意:数组元素类型不一致。6};7
最好的解决办法是,使用泛型容器来代替泛型数组:
61DynamicArray<Pair<String, Integer>> options = new DynamicArray<>();2options.add(new Pair<String, Integer>("1元", 7));3options.add(new Pair<String, Integer>("2元", 2));4options.add(new Pair<String, Integer>("10元", 1));5options.add(new Pair<String, String>("10元", "1")); // err 不兼容的类型在编译时报错6
7. 泛型容器不能直接转换为数组
有时候我们希望将泛型容器直接转化为一个泛型数组,如下:
51DynamicArray<Integer> ints = new DynamicArray<Integer>();2ints.add(100);3ints.add(34);4Integer[] arr = ints.toArray(); // 泛型容器 -> 泛型数组5
实现toArray()方法时,一般是先创建一个泛型数组,然后拷贝数据再返回该数组。
由于前面已经提到,直接创建泛型数组是行不通的:E[] arr = new E[size]; // err,因此,可能会想到如下两种方式:
111// 2public E[] toArray() {3 Object[] copy = new Object[size]; // 创建Object数组4 System.arraycopy(elementData, 0, copy, 0, size);5 return (E[]) copy; // 强转报错6}7
8public E[] toArray() {9 return (E[])Arrays.copyOf(elementData, size); // copyOf返回Object数组,强转报错10}11
虽然这两者方式没有编译错误,但是在运行时都会抛出如下异常:
11java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.Integer;
要想实现上述需求,必须知道数组元素的类型信息,才能创建泛型数组,可以修改实现如下:
101// 接收数组元素的类型信息2public E[] toArray(Class<E> type) {3 Object copy = Array.newInstance(type, size); // 创建type类型的数组对象4 System.arraycopy(elementData, 0, copy, 0, size);5 return (E[]) copy;6}7
8// 使用时传入类型信息9Integer[] arr = ints.toArray(Integer.class);10
提示:
实际上,可以通过一些运行时类型信息来获取元素的类型信息,从而传入Array.newInstance创建数组,可以对比第二节相关案例。
21elementData.getClass().getComponentType()2elementData[0].getClass()
第04章_容器
第一节 容器类概述
1. 容器体系简介
容器类主要分为集合类容器(Collection)和映射类容器(Map)。集合类容器包括列表(List)、队列(Queue)、集合(Set)三大类,其中队列又衍生出双端队列(Deque),它们都是容器类的超级接口,并且一般都定义了对应的抽象类。
在日常开发中,我们一般使用上述接口或抽象类的具体子类,常用的容器如下:
| 容器 | 容器类 | 说明 |
|---|---|---|
| 数组列表 | ArrayList | 基于数组实现的列表 |
| 链式列表 | LinkedList | 基于链表实现的列表,也可作为链式双端队列 |
| 数组双端队列 | ArrayDeque | 基于循环数组实现的双端队列 |
| 链式双端队列 | LinkedList | 基于链表实现的双端队列,也可作为链式列表 |
| 优先级队列 | PriorityQueue | 基于堆实现的单端队列,元素可以按优先级出列 |
| 哈希集合 | HashSet | 基于哈希表+链表(或红黑树)实现的无序集合 |
| 带链的哈希集合 | LinkedHashSet | 继承自HashSet,在其基础上通过额外的链来维护插入有序 |
| 树状集合 | TreeSet | 基于红黑树实现的规则有序集合 |
| 枚举集合 | EnumSet | 基于数组实现的高效集合,只适用于枚举类型元素 |
| 哈希映射 | HashMap | 基于哈希表+链表(或红黑树)实现的无序映射 |
| 带链的哈希映射 | LinkedHashMap | 继承自HashMap,在其基础上通过额外的链来维护存取有序 |
| 树状映射 | TreeMap | 基于红黑树实现的规则有序映射 |
| 枚举映射 | EnumMap | 基于位向量实现的高效映射,只适用于枚举元素 |
注意:
容器一般会继承对应的抽象类及直接实现对应的超级接口,如ArrayList继承了AbstractList,并且还直接实现了List接口。
但是也有些例外,如ArrayDeque没有对应的AbstractDeque,EnumSet和EnumMap没有直接实现对应的Set和Map接口等。
2. 常见接口和抽象类简介
1) Iterable<T>和Iterator<E>
Iterable<T>接口表示“可迭代的”,它提供了获取迭代器(Iterator<E>)的方法,通过迭代器可以进行遍历操作,并且支持ForEach语法。
ListIterator<E>扩展了Iterator接口,增加了一些向前遍历、添加元素、修改元素、返回索引位置等方法。
171// Iterable<T>2Iterator<T> iterator() // 返回Iterator对象3default void forEach(Consumer<? super T> action) 4
5// Iterator<E>6boolean hasNext() // 判断是否还有元素未访问7E next() // 返回下一个元素8default void remove() // 删除最后返回的元素9
10// ListIterator<E> 11boolean hasPrevious()12E previous()13int nextIndex()14int previousIndex()15void set(E e)16void add(E e)17
提示
只要对象实现了Iterable接口,就可以使用foreach语法,编译器会转换为调用Iterable和Iterator接口的方法。
2) Collection<E>与AbstractCollection<T>
Collection<E>表示单列集合,只定义了基本的增删改查和遍历等方法,没有定义元素间的顺序或位置,也没有规定是否有重复元素。
171// Collection<E>2int size()3boolean isEmpty()4boolean contains(Object o)5Object[] toArray()6<T> T[] toArray(T[] a)7boolean add(E e) 8boolean remove(Object o)9boolean containsAll(Collection<?> c)10boolean addAll(Collection<? extends E> c)11boolean removeAll(Collection<?> c)12default boolean removeIf(Predicate<? super E> filter)13boolean retainAll(Collection<?> c) // 交集14void clear()15default Stream<E> stream()16default Stream<E> parallelStream()17
注意:
Collection的add方法默认为抛出UnsupportedOperationException异常。
3) 列表相关接口和抽象类
List<E> 是 Collection<E> 的子接口,表示有顺序和位置的集合,增加了根据索引位置进行操作的方法。
141// List<E>2boolean addAll(int index, Collection<? extends E> c)3default void replaceAll(UnaryOperator<E> operator)4default void sort(Comparator<? super E> c)5E get(int index)6E set(int index, E element)7void add(int index, E element)8E remove(int index)9int indexOf(Object o)10int lastIndexOf(Object o)11ListIterator<E> listIterator()12ListIterator<E> listIterator(int index)13List<E> subList(int fromIndex, int toIndex)14
4) 队列相关接口和抽象类
Queue<E>是Collection<E>的子接口,表示先进先出的队列,在尾部添加,从头部查看或删除。
Deque<E>是Queue<E>的子接口,表示更为通用的双端队列,有明确的在头或尾进行查看、添加和删除的方法。
261// Queue<T>2boolean offer(E e)3E remove()4E poll()5E element()6E peek()7
8// Deque<E>9void addFirst(E e)10void addLast(E e)11boolean offerFirst(E e)12boolean offerLast(E e)13E removeFirst()14E removeLast()15E pollFirst()16E pollLast()17E getFirst()18E getLast()19E peekFirst()20E peekLast()21boolean removeFirstOccurrence(Object o)22boolean removeLastOccurrence(Object o)23void push(E e)24E pop()25Iterator<E> descendingIterator()26
5) 集合相关接口和抽象类
Set<E>是Collection<E>的子接口,它没有增加新的方法,但保证不含重复元素。SortedSet<E>和NavigableSet<E>在Set的基础上进行了扩充,方便实现TreeSet子类。
231// Set<E> 不含重复元素2
3// SortedSet<E> 不含重复元素且有序4Comparator<? super E> comparator()5SortedSet<E> subSet(E fromElement, E toElement)6SortedSet<E> headSet(E toElement)7SortedSet<E> tailSet(E fromElement)8E first()9E last()10
11// NavigableSet<E> // 不含重复元素且有序且可导航的12E lower(E e)13E floor(E e)14E ceiling(E e)15E higher(E e)16E pollFirst()17E pollLast()18NavigableSet<E> descendingSet();19Iterator<E> descendingIterator()20NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive)21NavigableSet<E> headSet(E toElement, boolean inclusive)22NavigableSet<E> tailSet(E fromElement, boolean inclusive)23
6) 映射相关接口和抽象类
Map<K,V>表示键值对集合(映射),它的元素为Entry<K,V>类型,经常根据键进行操作。SortedMapMap<K,V>和NavigableMapMap<K,V>在Map的基础上进行了扩充,方便实现TreeMap子类。
621// Entry<K,V>2K getKey()3V getValue()4V setValue(V value)5public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey()6public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue()7public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp)8public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp)9
10// Map<K,V>11int size()12boolean isEmpty()13boolean containsKey(Object key)14boolean containsValue(Object value)15V get(Object key)16V put(K key, V value)17V remove(Object key)18void putAll(Map<? extends K, ? extends V> m)19void clear()20Set<K> keySet() // key视图21Collection<V> values() // value视图22Set<Map.Entry<K, V>> entrySet() // entry视图23default V getOrDefault(Object key, V defaultValue)24default void forEach(BiConsumer<? super K, ? super V> action)25default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function)26default V putIfAbsent(K key, V value)27default boolean remove(Object key, Object value)28default boolean replace(K key, V oldValue, V newValue)29default V replace(K key, V value)30default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)31default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction)32default V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction)33default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction)34
35// SortedMap<K,V> 36Comparator<? super K> comparator()37SortedMap<K,V> subMap(K fromKey, K toKey)38SortedMap<K,V> headMap(K toKey)39SortedMap<K,V> tailMap(K fromKey)40K firstKey()41K lastKey()42
43// NavigableMap<K,V>44Map.Entry<K,V> lowerEntry(K key)45K lowerKey(K key)46Map.Entry<K,V> floorEntry(K key)47K floorKey(K key)48Map.Entry<K,V> ceilingEntry(K key)49K ceilingKey(K key)50Map.Entry<K,V> higherEntry(K key)51K higherKey(K key)52Map.Entry<K,V> firstEntry()53Map.Entry<K,V> lastEntry()54Map.Entry<K,V> pollFirstEntry()55Map.Entry<K,V> pollLastEntry()56NavigableMap<K,V> descendingMap()57NavigableSet<K> navigableKeySet()58NavigableSet<K> descendingKeySet()59NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)60NavigableMap<K,V> headMap(K toKey, boolean inclusive)61NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)62
3. 容器使用注意事项
1) 根据容器特性选择合适的容器
不同类型的容器有不同的适用场景,如数组类容器适合随机访问,链式容器适合头尾存取,堆类型容器适合TopN问题,树状容器适合元素按规则排序的场景等,应该根据使用场景选用合适的容器。
2) 本章节介绍的容器都是线程不安全的
除了Hashtable、Vector和Stack外,我们本章介绍的各种容器类都是线程不安全的。如需多线程操作同一个容器,可以使用Collections工具类提供的synchronizedXXX方法对容器对象进行同步,或者使用专门的线程安全容器类。
3) 容器在通过迭代器遍历时会检测结构性变化
容器类提供的迭代器都有一个特点,会在迭代时检测容器的结构性变化(通过modCount来实现),如通过容器引用去添加或删除元素等,将会抛出ConcurrentModificationException。如确实需要增删元素,可以通过迭代器的add和remove方法操作。
第二节 列表(List)
1. 数组列表(ArrayList)
ArrayList<E>是List<E>的子类,基于数组实现,它的随机访问效率很高,但从中间插入和删除元素需要移动元素,效率比较低。
注意:
ArrayList 在头部插入/删除时,由于需要移动后面所有元素,因此时间复杂度是O(n),但在尾部插入/删除时,复杂度是O(1)。
特殊的。如果在插入时触发了扩容,则不管是在头部还是尾部,时间复杂度都是O(n)。
1) ArrayList常用方法
501// 构造方法2ArrayList()3ArrayList(Collection<? extends E> c) // 构造后调用addAll添加所有元素4ArrayList(int initialCapacity) // 指定初始容量5
6// 基本增删改查7int size() // 列表长度,即元素个数8boolean isEmpty() // 列表是否为空9boolean contains(Object o) // 是否包含指定元素,依据是equals方法的返回值10boolean add(E e) // 添加元素到末尾11void add(int index, E element) // 在指定位置处添加元素(index为0表示插入最前面,index为size()表示插到最后面12boolean addAll(Collection<? extends E> c) // 添加多个元素13boolean addAll(int index, Collection<? extends E> c) // 指定位置添加多个元素14E get(int index) // 访问指定位置的元素15E set(int index, E element) // 修改指定位置的元素内容16E remove(int index) // 删除指定位置的元素,返回值为被删对象17boolean remove(Object o) // 按值删除,删除从0索引开始比较遇到的第一个相等元素(参数可以为null)18boolean removeAll(Collection<?> c) // 删除多个元素19boolean removeIf(Predicate<? super E> filter) // 按条件删除20void replaceAll(UnaryOperator<E> operator) // 操作所有元素,如将元素全部转为大写:strList01.replaceAll(e -> e.toUpperCase())21boolean retainAll(Collection<?> c) // 只保留参数容器中的元素,即取两集合交集22void clear() // 清空列表,即删除所有元素23int indexOf(Object o) // 查找元素,如果找到,返回索引位置,否则返回-124int lastIndexOf(Object o) // 从后往前找25
26// 遍历27Iterator<E> iterator() // 普通后向迭代器28ListIterator<E> listIterator() // 列表迭代器(支持双向)29ListIterator<E> listIterator(int index) // 指定迭代器开始位置,默认为0,表示从头开始遍历,可以指定为size(),配合hasPrevious()从后遍历30Spliterator<E> spliterator() 31void forEach(Consumer<? super E> action)32
33// 排序34void sort(Comparator<? super E> c)35
36// 转换37String toString() // 返回字符串形式,如[1, 2, 3]、[a, b, c]38Object[] toArray() // 返回Object数组39<T> T[] toArray(T[] arr) // 返回对应类型的数组,如果参数数组容量足以容纳所有元素,就使用该数组,否则就新建一个数组(如果数组类型不对,将会抛出ArrayStoreException)40List<E> subList(int fromIndex, int toIndex) // 返回一个子列表(SubList),并引用原列表元素(会直接影响原列表)41Arrays.asList(new Integer[]{1, 2, 3} // 数组转换为只读List,支持可变参数形式:Arrays.asList(1, 2, 3)42List<Integer> list = new ArrayList<Integer>(Arrays.asList(arr)) // 数组转换为完整List43
44// 动态分配45void ensureCapacity(int minCapacity) // 确保数组的大小至少为minCapacity,如果不够,会进行扩展46void trimToSize() // 重新分配一个数组,大小刚好为实际内容的长度。调用这个方法可以节省数组占用的空间。47
48// 其它方法49Object clone()50
注意:
基于索引操作的方法,在操作节点前都会检查索引是否越界,如果越界将会抛出IndexOutOfBoundsException。
基于索引操作的插入类方法,当索引为0时,插入到头部,索引为size()时,插入到尾部;
基于索引操作的删除和查看方法,索引范围必须为0~size()-1;
集合转数组,使用
list.toArray(new String[0]),其中 new String[0] 用来指定返回数组的类型。数组转集合,使用
Arrays.asList(myArray)获取的是不可变子集合,可再套一层移除这个限制:new ArrayList<>(arr)。
2) ArrayList实现原理
ArrayList内部使用数组elementData来存储元素,默认长度为10,长度会随着元素个数的变化动态分配(1.5倍),一般会有一些预留的空间,由另外一个整数size来记录实际的元素个数。
21transient Object[] elementData; // 存储元素的数组2private int size; // 元素实际个数
3) 注意事项:并发修改异常
由于迭代器内部会维护一些索引位置相关的数据,因此要求在迭代过程中,容器不能发生结构性变化,否则这些索引位置就失效了,就会抛出ConcurrentModificationException。所谓结构性变化,就是添加和删除元素等,只是修改元素内容不算结构性变化。
71public static void remove(ArrayList<Integer> list) {2 for (Integer a : list) { // 迭代3 if (a <= 100) {4 list.remove(a); // 结构性变化5 }6 }7}如何避免异常呢?可以使用迭代器的remove方法,或直接通过list.removeIf来实现相同功能。
151// 使用迭代器的remove方法2public static void remove(ArrayList<Integer> list) {3 Iterator<Integer> it = list.iterator();4 while (it.hasNext()) {5 if (it.next() <= 100) {6 it.remove(); // 使用迭代器it的remove()方法7 }8 }9}10
11// List的按条件删除方法(remove的特殊场景,add并没有对应方法)12public static void remove(ArrayList<Integer> list) {13 list.removeIf(a -> a <= 100);14}15
4) 扩展:迭代器的实现原理
为什么上面可以使用迭代器的remove方法来删除呢?这涉及到迭代器的实现原理,它内部维护了三个成员变量:
31int cursor; // 下一个要返回的元素位置2int lastRet = -1; // 最后一个返回的索引位置,如果没有,为 -13int expectedModCount = modCount; // 期望的修改次数,初始化为外部类当前的修改次数modCount当外部类调用add、remove等影响结构性的方法时,modCount都会自增,而每次迭代器操作的时候都会检查expectedModCount是否与外部类的modCount相同,这样就能检测出结构性变化。
如果使用迭代器的remove方法,它在调用ArrayList的remove方法时,可以同步更新内部的cursor、lastRet和expectedModCount的值,因此可以正确删除。不过,需要注意的是,调用迭代器的remove方法前必须先调用next,否则会抛出IllegalStateException。
91// 删除所有元素2public static void removeAll(ArrayList<Integer> list) {3 Iterator<Integer> it = list.iterator();4 while (it.hasNext()) {5 it.next(); // 在调用remove()前必须调用next()方法6 it.remove();7 }8}9
注意:
迭代器是一种关注点分离的思想,将数据的实际组织方式与数据的迭代遍历相分离,是一种常见的设计模式。
迭代器语法更加简洁,并且对于部分容器,性能更加高效,推荐优先使用。
2. 链式列表(LinkedList)
LinkedList<E>是List<E>的间接子类,基于链表实现,随机访问效率比较低,但增删元素只需要调整邻近节点的链接。此外,它还继承了Deque\<E\>接口,可以用作双端队列、先进先出队列、栈等。
注意:
在头部或尾部插入/删除。复杂度都为O(1),但在中间插入/删除/查找,需要指针寻址,复杂度是O(n)。
LinkedList底层是链表,随机访问的复杂度为O(n),基于性能考虑,所以没有实现随机访问接口(RandomAccess)。
1) LinkedList常用方法
531// 构造方法2LinkedList() // 无初始容量3LinkedList(Collection<? extends E> c)4
5// 用作链式列表6int size() // 列表长度,即元素个数7boolean isEmpty() // 列表是否为空8boolean contains(Object o) // 是否包含指定元素,依据是equals方法的返回值9boolean add(E e) // 添加元素到末尾10void add(int index, E element) // 在指定位置处添加元素(index为0表示插入最前面,index为size()表示插到最后面11boolean addAll(Collection<? extends E> c) // 添加多个元素12boolean addAll(int index, Collection<? extends E> c) // 在指定位置添加多个元素13E get(int index) // 访问指定位置的元素14E set(int index, E element) // 修改指定位置的元素内容15E remove(int index) // 删除指定位置的元素,返回值为被删对象16boolean remove(Object o) // 从头部开始比较,移除第一个值为参数o的元素,值可以为null17void clear() // 清空列表,即删除所有元素18int indexOf(Object o) // 查找元素,如果找到,返回索引位置,否则返回-119int lastIndexOf(Object o) // 从后往前找20
21// 用作先进先出队列(尾进头出)22boolean add(E e) boolean offer(E e)23E remove() E poll()24E element() E peek()25
26// 用作双端队列27void addFirst(E e) boolean offerFirst(E e)28void addLast(E e) boolean offerLast(E e)29E removeFirst() E pollFirst()30E removeLast() E pollLast()31E getFirst() E peekFirst()32E getLast() E peekLast()33boolean removeFirstOccurrence(Object o) // 头部开始比较,移除第一个值为参数o的元素,值可以为null34boolean removeLastOccurrence(Object o) // 从尾部开始比较,移除第一个值为参数o的元素,值可以为null35
36// 用作栈(头部为栈顶)37void push(E e)38E pop()39E peek()40
41// 遍历相关方法42Iterator<E> descendingIterator() // 反向迭代器43ListIterator<E> listIterator(int index) // 列表迭代器(支持双向迭代和指定迭代开始位置)44Spliterator<E> spliterator() 45
46// 转换方法47String toString() // 返回字符串形式,如[1, 2, 3]、[a, b, c]48Object[] toArray() // 返回Object数组49<T> T[] toArray(T[] a) // 返回对应类型的数组,如果参数数组长度足以容纳所有元素,就使用该数组,否则就新建一个数组(如果数组类型不对,将会抛出ArrayStoreException)50
51// 其它方法52Object clone()53
注意:
栈/队列是双端队列的特殊情况,它们的方法都可以使用双端队列的方法替代,不过使用不同的名称和方法,概念上更为清晰。
offer/poll/peek开头的方法在已满或为空时返回false或null(虽然LinkedList没有”已满“的概念,但其它队列/栈可能会有)。
add/remove/get和push/pop/element开头的方法在已满或为空时会抛出IllegalStateException或NoSuchElementException。
2) LinkedList实现原理
LinkedList是一个双端链表,每个元素(节点)在内存中单独存放,元素之间通过前驱指针和后继指针进行链接。
121// LinkedList的元素节点2private static class Node<E> {3 E item; // 元素值4 Node<E> next; // 前驱指针5 Node<E> prev; // 后继指针6
7 Node(Node<E> prev, E element, Node<E> next) {8 this.item = element;9 this.next = next;10 this.prev = prev;11 }12}而LinkedList内部只需保存一个头指针和一个尾指针即可,分别指向第一个节点和最后一个节点,通过指针寻址操作,关联所有元素,构成逻辑上的双端链表。
31transient Node<E> first; // 头指针2transient Node<E> last; // 尾指针3transient int size = 0; // 元素个数
第三节 队列(Queue/Deque)
1. 数组队列(ArrayDeque)
ArrayDeque<E>是Deque<E>的子类,基于循环数组实现,它可以用作双端队列、先进先出队列、栈等。和链式双端队列相比,从两端操作的效率会更高一些,但是不支持索引操作,并且在中间插入和删除很慢。
1) ArrayDeque常用方法
构造方法如下,其它常用方法和LinkedList中介绍的类似,不再赘述。
31ArrayDeque() // 默认容量为16,每次扩容为之前的2倍2ArrayDeque(int numElements) // 指定队列初始容量,一般为2^n-1(如numElements为31,则实际初始容量为32,如numElements为32,实际初始容量为64)。3ArrayDeque(Collection<? extends E> c)
2) ArrayDeque实现原理
下面重点看下ArrayDeque的循环数组是如何实现的,ArrayDeque内部主要有如下实例变量:
31private transient E[] elements; // 存储元素的数组2private transient int head; // 头指针3private transient int tail; // 尾指针通过引入头指针和尾指针使物理上的简单数组(从头到尾)变为了一个逻辑上循环的数组,避免了在头尾操作时的移动。头尾有四种分布:
head=tail:队列为空(即size=0,由于数组长度为最大容量+1,因此不会是已满情形)。
head<tail:队列无循环,元素索引从head~tail-1。
0=tail<head:队列也无循环,但是处于数组最右端,元素索引从head~elements.length-1。
0<tail<head:队列会形成循环,元素索引分为两段,第一段从head~elements.length-1,第二段从0~tail-1。
队列的长度始终可以通过(tail - head) & (elements.length - 1)算出。而在添加新元素时,如在尾部添加,则tail = (tail + 1) & (elements.length - 1),如在头部添加,则head = ( head-1 ) & ( elements.length-1 ),如果出现head==tail,则表示容器已满,需要将容量扩为之前的2倍。
注意:
ArrayDeque中,有效元素不允许为null,contains等方法在内部遍历时也将null视为结尾。
通过位与运算,可以有效提高计算下标的效率,并且可以确保索引不会越界,这在循环数组中的应用非常常见。
2. 链式队列(LinkedList)
LinkedList<E>还继承了Deque<E>接口,可以用作双端队列、先进先出队列、栈等,在链式列表章节已有介绍。
3. 优先级队列(PriorityQueue)
PriorityQueue<E>是Queue\<E\>的子类,表示优先级队列,基于二叉堆实现的。常见的应用场景有“求前K个最大的元素”、“求实时中值”等。
1) PriorityQueue常用方法
351// 构造方法(元素需实现Comparable接口或构造时传入Comparator)2PriorityQueue() // 默认容量为11,小顶堆3PriorityQueue(int initialCapacity)4PriorityQueue(Comparator<? super E> comparator)5PriorityQueue(int initialCapacity, Comparator<? super E> comparator)6PriorityQueue(Collection<? extends E> c)7PriorityQueue(PriorityQueue<? extends E> c)8PriorityQueue(SortedSet<? extends E> c)9
10// 基本增删改查11int size()12boolean isEmpty()13boolean contains(Object o)14boolean containsAll(Collection<?> c)15boolean add(E e) boolean offer(E e) // 添加到合适位置16boolean addAll(Collection<? extends E> c) // 添加多个元素17boolean remove(Object o) E poll() // 取出头部元素(头部元素一定是最小/最大的那个,连续取出时的顺序是有序的)18boolean removeAll(Collection<?> c) // 删除多个元素19boolean removeIf(Predicate<? super E> filter) // 按条件删除20boolean retainAll(Collection<?> c) // 只保留参数容器中的元素,即取两集合交集21E element() E peek()22void clear()23 24// 迭代25Iterator<E> iterator()26final Spliterator<E> spliterator() // 特殊迭代器27 28// 转换29String toString() // 返回原始数组的字符串形式,是无序的,如[a, s, c, t]30Object[] toArray() // 注意是原始数组,是无序的31<T> T[] toArray(T[] a) // 注意是原始数组,是无序的32 33// 其它方法34Comparator<? super E> comparator() // 返回内部比较器35
2) PriorityQueue实现原理
优先级队列基于堆实现,而堆是一颗完全二叉树,在从左到右并分层进行编号后,可以直接计算出任意节点的父节点和左右子节点的编号,如编号为i的节点,其父节点编号为i/2,左右子节点的编号分别为2\*i和2\*i+1,可以将这个编号作为数组的索引,将每个节点按编号存储在一个连续的数组中,不仅节省空间,而且访问效率非常高。
但在插入和删除(即将尾部元素覆盖头部元素)元素时,需要进行向上调整(siftup)或向下调整(siftdown)来维持堆的性质,效率都为Olog2N。
41private transient Object[] queue; // 存储元素的数组2private int size = 0; 3private final Comparator<? super E> comparator; // 比较器,在元素实现了Comparable接口时可以为null4private transient int modCount = 0; // 修改次数注意:
堆分为小顶堆和大顶堆,大顶堆指每个元素不大于其父元素,根节点就是最大节点,元素之间可以重复,小顶堆与之类似。
第四节 映射(Map)
1. 哈希映射(HashMap)
HashMap<K,V>是Map<K,V>的子接口,基于哈希表实现(哈希表+链表/红黑树),要求元素的键(key)重写hashCode和equals方法,操作效率很高,但元素间没有顺序。
1) HashMap常用方法
421// 构造方法2HashMap() // 默认初始容量为16(必须为2^n次方),负载因子为0.75f3HashMap(int initialCapacity)4HashMap(int initialCapacity, float loadFactor)5HashMap(Map<? extends K, ? extends V> m)6 7// 基本增删改查8int size()9boolean isEmpty()10boolean containsKey(Object key)11boolean containsValue(Object value)12V get(Object key)13V getOrDefault(Object key, V defaultValue) // get,key不存在则取默认值14V put(K key, V value) // 会覆盖旧元素15V putIfAbsent(K key, V value) // 不覆盖旧元素16void putAll(Map<? extends K, ? extends V> m)17V remove(Object key)18boolean remove(Object key, Object value)19void clear()20V replace(K key, V value)21boolean replace(K key, V oldValue, V newValue)22void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) 23V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) // put计算后的新值并返回;如果新值为null,则进行删除该key并返回null24V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) // 仅在key不存在时compute,key存在直接返回旧value25V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) // 仅在key存在时compute,key不存在直接返回null26V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) // 归并旧值和新值27
28// 遍历 29// map.keySet().Xxx30void forEach(BiConsumer<? super K, ? super V> action)31
32// 特殊视图33Set<K> keySet()34Collection<V> values()35Set<Map.Entry<K,V>> entrySet()36 37// 转换38String toString() // 字符串形式如:{a=97, b=98, c=99}39 40// 其它方法41Object clone()42
2) HashMap实现原理
HashMap内部有一个Node类型的数组table,称为哈希表(哈希桶),每个元素(table[i])指向一个单向链表(或红黑树)。
131transient Node<K,V>[] table; // 哈希表(哈希桶),默认为空数组{}2transient int size; // 元素的实际个数3int threshold; // 扩容阈值(一般等于容量*负载因子),当szie>threshold时,扩容为之前的两倍4final float loadFactor; // 负载因子5static final int TREEIFY_THRESHOLD = 8; // 链表树化的阈值6static final int UNTREEIFY_THRESHOLD = 6; // 树退化为链表的阈值7
8static class Node<K,V> implements Map.Entry<K,V> {9 final int hash;10 final K key;11 V value;12 Node<K,V> next;13}当put新元素时,先计算key对应的hash值,再通过取余( h%(length-1),可优化为h&(length-1) )得到数组中的索引位置buketIndex,然后将value存放在该位置或该位置指向的链表(或红黑树)中。
注意:
长度大于等于8时,并非直接转换为红黑树,而是先判断如果数组长度小于64,则先进行数组扩容,以优化查询速度。
2. 带链的哈希映射(LinkedHashMap)
LinkedHashMap<K,V>继承自HashMap<K,V>,在其哈希表+链表(或红黑树)的基础上额外添加了一条用于维护元素顺序的双向链表,这个链表可以按插入顺序排序,也可以按访问顺序排序。
1) LinkedHashMap常用方法
构造方法如下,其它方法和HashMap类似,但是get/put等方法内部会额外维护一个插入或访问顺序,同时遍历时按照该顺序进行。
71// 构造方法2LinkedHashMap()3LinkedHashMap(int initialCapacity) // initialCapacity-初始容量4LinkedHashMap(int initialCapacity, float loadFactor) // loadFactor-负载因子,当szie>initialCapacity*loadFactor时进行哈希表的扩容5LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) // accessOrder-是否按访问有序6LinkedHashMap(Map<? extends K, ? extends V> m)7
提示:
如果键本来就是有序的,使用LinkedHashMap比TreeMap效率更高。
2) LinkedHashMap实现原理
LinkedHashMap是HashMap的子类,内部增加了如下实例变量:
41final boolean accessOrder; // 是否按访问有序2transient LinkedHashMap.Entry<K,V> head; // 双向链表的头部3transient LinkedHashMap.Entry<K,V> tail; // 双向链表的尾部4
其中Entry继承了HashMap.Node,增加了两个变量before和after, 分别指向前驱节点和后继节点。
71static class Entry<K,V> extends HashMap.Node<K,V> {2 Entry<K,V> before, after;3 Entry(int hash, K key, V value, Node<K,V> next) {4 super(hash, key, value, next);5 }6}7
当处于“插入有序”模式时,哈希表新增元素的同时,也会添加到链表的末尾。当处于“访问有序”模式时,无论是插入、修改或访问,都会将该节点移到链表的末尾。
3) 应用:LRU缓存
231// 最近最少使用缓存2public class LRUCache<K, V> extends LinkedHashMap<K, V> {3 private int maxEntries;4
5 public LRUCache(int maxEntries) {6 super(16, 0.75f, true);7 this.maxEntries = maxEntries;8 }9
10 11 protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {12 return size() > maxEntries;13 }14
15 public static void main(String[] args) {16 LRUCache<String, String> lruCache = new LRUCache<>(2);17 lruCache.put("str01", "str01");18 lruCache.put("str02", "str02");19 lruCache.put("str03", "str03");20 System.out.println(lruCache); // {str02=str02, str03=str03}21 }22}23
3. 树状映射(TreeMap)
TreeMap<K,V>是Map<K,V>的间接子接口,基于排序二叉树(红黑树)实现,要求键(key)实现Comparable<E>接口,或者创建TreeSet时提供一个Comparator<E>对象,其操作效率稍低,但键(key)可以按比较有序。
1) TreeMap常用方法
构造方法如下,其它方法和HashMap类似。此外,还有一些继承自SortedMap和NavigableMap的方法,由于使用较少,请查阅API文档。
61// 构造方法2TreeMap() 3TreeMap(Comparator<? super K> comparator)4TreeMap(Map<? extends K, ? extends V> m)5TreeMap(SortedMap<K, ? extends V> m)6
注意:
TreeMap使用键的比较结果(而非equals)对键进行排重,即使键实际上不同,但只要比较结果相同,就会被认为相同。
2) TreeMap实现原理
TreeMap是基于红黑树实现的,主要成员变量如下:
31private transient Entry<K,V> root = null; // 红黑树的根节点2private transient int size = 0; // 当前节点的个数3private final Comparator<? super K> comparator; // Key的比较器(优先使用),用于比较Key的大小和判断Key是否相等
4. 枚举映射(EnumMap)
EnumMap<K,V>是Map<K,V>的子接口,使用比哈希表效率更高的静态数组实现,但是要求元素必须为枚举类型。
1) EnumMap常用方法
构造方法如下,需要通过枚举类的Class信息进行构造,同时key必须为枚举类型。
51// 构造方法2EnumMap(Class<K> keyType) // 使用枚举类型构造3EnumMap(EnumMap<K, ? extends V> m)4EnumMap(Map<K, ? extends V> m)5
下面是一个简单的使用示例:
141// 枚举类2public enum Size {3 SMALL, MEDIUM, LARGE4}5
6// 使用示例:7public static void main(String[] args) {8 EnumMap<Size, String> enumMap = new EnumMap<>(Size.class);9 enumMap.put(Size.MEDIUM, "中");10 enumMap.put(Size.SMALL, "小");11 enumMap.put(Size.LARGE, "大");12 System.out.println(enumMap); // {SMALL=小, MEDIUM=中, LARGE=大} 按枚举定义顺序排序13}14
注意:
EnumMap是有顺序的,为枚举元素定义的顺序。
当put的值为null时,将会被替换为
EnumMap.NULL存储,而值为真正的null表示该key不存在。上述两种场景在get时都会返回null,但是在遍历时,不存在的key将会被跳过,如:{SMALL=null, MEDIUM=中}。
虽然使用普通的HashMap可以实现相同的功能,但是使用EnumMap更加简洁安全和高效。
2) EnumMap实现原理
EnumMap内部有两个长度相等的静态数组,一个表示所有可能的键, 一个表示对应的值,值为 null 表示没有该键值对,键都有一个对应的索引,根据索引可直接访问和操作其键和值,效率很高。
41private final Class<K> keyType; // 枚举类型信息2private transient K[] keyUniverse; // keys,初始化为所有可能的键3private transient Object[] vals; // 键对应的值,为null表示key不存在,为EnumMap.NULL表示值为null4private transient int size = 0; // 元素个数
第五节 集合(Set)
1. 哈希集合(HashSet)
HashSet<E>是Set<E>的子接口,基于HashMap<E,Object>实现,因此同样要求元素的键(key)重写hashCode和equals方法, 特性也基本类似,如访问效率高,元素间没有顺序等;
1) HashSet常用方法
271// 构造方法(常用于去重、保存特殊值、集合运算等场景)2HashSet() 3HashSet(int initialCapacity)4HashSet(int initialCapacity, float loadFactor)5HashSet(Collection<? extends E> c)6 7// 基本增删改查8int size()9boolean isEmpty()10boolean contains(Object o)11boolean add(E e)12boolean addAll(Collection<? extends E> c)13boolean remove(Object o)14boolean removeIf(Predicate<? super E> filter)15boolean removeAll(Collection<?> c)16boolean retainAll(Collection<?> c)17void clear();18
19// 遍历20Iterator<E> iterator()21Spliterator<E> spliterator()22 23// 转换24String toString()25Object[] toArray()26<T> T[] toArray(T[] a)27
提示:
推荐使用
new HashSet<>(data)去重,因为 HashSet 的 contains() 方法比 ArrayList 的更高效。
2) HashSet实现原理
HashSet的内部有一个HashMap,操作基本都是委托其完成的。
21private transient HashMap<E,Object> map; // 内部的HashMap2private static final Object PRESENT = new Object(); // 值都用new Object()填充
2. 带链的哈希集合(LinkedHashSet)
LinkedHashSet<E>继承自HashSet<E>,基于LinkedHashMap<K,V>实现,默认支持插入有序,不支持访问有序。
1) LinkedHashSet常用方法
构造方法如下,其它常用方法和HashSet的使用类似,但add等方法内部会额外维护一个插入顺序,同时遍历时按照该顺序进行。
61// 构造方法2LinkedHashSet()3LinkedHashSet(int initialCapacity)4LinkedHashSet(int initialCapacity, float loadFactor)5LinkedHashSet(Collection<? extends E> c)6
2) LinkedHashSet实现原理
LinkedHashSet继承自HashSet,构造时内部的map被初始化为LinkedHashMap,因此支持按插入有序:
81// HashSet内部的map对象2private transient HashMap<E,Object> map;3
4// 在构造LinkedHashSet时被初始化为LinkedHashMap5HashSet(int initialCapacity, float loadFactor, boolean dummy) {6 map = new LinkedHashMap<>(initialCapacity, loadFactor); // 默认为按插入有序7}8
3. 树状集合(TreeHashSet)
TreeSet<E>是Set<E>的间接子接口,基于TreeMap<E,Object>实现,, 特性也基本类似,同样也要求元素的键实现Comparable<E>接口,或者创建TreeMap时提供一个Comparator<E>对象。
1) TreeHashSet常用方法
构造方法如下,其它常用方法和HashSet中介绍的类似,不再赘述。此外,有一些继承自SortedSet和NavigableSet的方法,由于使用较少,请查阅API文档。
51// 构造方法2TreeSet()3TreeSet(Comparator<? super E> comparator)4TreeSet(Collection<? extends E> c)5TreeSet(SortedSet<E> s)
2) TreeSet实现原理
TreeSet的内部有一个NavigableMap,操作基本都是委托其完成的。
21private transient NavigableMap<E,Object> m; // TreeMap或传入的NavigableMap子类2private static final Object PRESENT = new Object(); // 值都用new Object()填充
4. 枚举集合(EnumSet)
EnumSet<E>是Set<E>的子接口,基于位向量实现,效率非常高,但是元素要求必须为枚举类型。
1) EnumSet常用方法
构造函数如下,其它方法和HashSet使用类似。
141// 工厂方法2public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) // 初始集合不包括任何元素3< E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) // 初始集合包括指定枚举类型的所有枚举值4< E extends Enum<E>> EnumSet<E> range(E from, E to) // 初始集合包括枚举值中指定范围的元素5< E extends Enum<E>> EnumSet<E> complementOf(EnumSet<E> s) // 初始集合包括指定集合的补集6< E extends Enum<E>> EnumSet<E> of(E e) // 初始集合包括参数中的所有元素7< E extends Enum<E>> EnumSet<E> of(E e1, E e2)8< E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3)9< E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4)10< E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4, E e5)11< E extends Enum<E>> EnumSet<E> of(E first, E... rest)12< E extends Enum<E>> EnumSet<E> copyOf(EnumSet<E> s) // 初始集合包括参数容器中的所有元素13< E extends Enum<E>> EnumSet<E> copyOf(Collection<E> c)14 一个简单的使用示例如下:
111enum Day {2 MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY3}4
5public static void main(String[] args) {6 Set<Day> weekend = EnumSet.noneOf(Day.class);7 weekend.add(Day.SATURDAY);8 weekend.add(Day.SUNDAY);9 System.out.println(weekend); // [SATURDAY, SUNDAY]10}11
2) EnumSet实现原理
EnumSet与之前介绍的Set实现类不同,它内部没有用对应的Map类EnumMap,而是使用了一种极为高效的位向量方式。
位向量就是用一个位表示一个元素的状态(是否存在),用一组位表示一个集合的状态。如前面的枚举类型Day,它有7个枚举值,可以用一个字节的低7位表示,最高位补0,当对应元素存在时,则置为1,否则为0。

当枚举类型的枚举值个数<=64时,将创建RegularEnumSet实现类,内部采用64位的long类型存储元素是否存在的信息。否则将创建JumboEnumSet实现类,采用long类型的数组存储,并用size记录元素的个数。
131// EnumSet共有成员2final Class<E> elementType; // 枚举类型3final Enum<?>[] universe; // 枚举类的所有枚举值4
5// RegularEnumSet6private long elements = 0L;7public int size() {8 return Long.bitCount(elements);9}10
11// JumboEnumSet12private long elements[];13private int size = 0;在进行一些增删改查时,基本都是使用位操作来进行的,因此效率非常高,部分操作如下:
161// 添加元素(置1)2elements |= (1L << ((Enum)e).ordinal()) // 其中(1L << ((Enum)e).ordinal())表示将元素 e 对应的位设为 13
4// 删除元素(置0)5elements &= ~(1L << ((Enum)e).ordinal()) // ~(1L << ((Enum)e).ordinal())表示将元素 e 对应的位设为了 06
7// 是否包含8(elements & (1L << ((Enum)e).ordinal())) != 09
10// 取补集11elements = ~elements // 按位取反,相当于就是取补集12elements &= -1L >>> -universe.length // 移除高位多余的1 13 14// JumboEnumSet:需定位数组中要操作的long类型15e.ordinal() >>> 6 // 等效于除以64,得到操作第n个long类型16 扩展:取补集时为什么要移除高位多余的1?
因为elements是64位的,当前枚举类可能没有用那么多位,取反后高位部分都变为了1,因此需将超出universe.length的部分设为0。
在移动位数为负数的情况下,上述代码相当于:elements &= -1L >>> (64-universe.length)。如universe.length 为 7,则 -1L>>> ( 64-7 ) 就是二进制的 1111111,与 elements 相与,就会将超出universe.length部分的高 57 位都变为0。
第六节 相关工具类
1. Collections
Collections工具类以静态方法的方式提供了很多通用算法和功能。
1) 对容器进行操作
针对容器接口的通用操作,这是面向接口编程的一种体现,是接口的典型用法。
561// 1. 查找和替换2// 1.1 二分查找(前提是List中的元素是从小到大排序的,如果是从大到小排序,则需要传递一个逆序Comparator对象)3// 如果List实现了RandomAccess接口或size<5000,则使用indexedBinarySearch,否则使用iteratorBinarySearch4static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key) // 要求元素实现Comparable接口,下同5static <T> int binarySearch(List<? extends T> list, T key, Comparator<? super T> c) // 要求提供Comparator,下同6
7// 1.2 最大值和最小值8static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)9static <T> T max(Collection<? extends T> coll, Comparator<? super T> comp)10static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll)11static <T> T min(Collection<? extends T> coll, Comparator<? super T> comp)12
13// 1.3 元素出现的次数(参数o可以为null)14static int frequency(Collection<?> c, Object o)15
16// 1.4 子列表位置(找到返回索引位置,未找到返回-1)17static int indexOfSubList(List<?> source, List<?> target)18static int lastIndexOfSubList(List<?> source, List<?> target)19
20// 1.5 查看两个集合是否不相交(true-不相交,false-有交集)21static boolean disjoint(Collection<?> c1, Collection<?> c2)22
23// 1.6 替换所有oldVal为newVal(如果发生了替换,返回值为true,否则为 false)24static <T> boolean replaceAll(List<T> list, T oldVal, T newVal)25
26
27// 2. 排序和调整顺序28// 2.1 列表排序29static <T extends Comparable<? super T>> void sort(List<T> list)30static <T> void sort(List<T> list, Comparator<? super T> c)31
32// 2.2 元素交换33static void swap(List<?> list, int i, int j)34
35// 2.3 元素翻转36static void reverse(List<?> list)37
38// 2.4 洗牌(遍历列表,依次将当前位置元素与剩余未处理元素中的随机一个进行交换)39static void shuffle(List<?> list)40static void shuffle(List<?> list, Random rnd) // rnd-随机数生成类41
42// 2.5 循环移位43static void rotate(List<?> list, int distance) // distance-正数表示右移,负数表示左移44Collections.rotate(list.subList(1, 5), 2) // 支持子列表形式,如[8, 5, 3, 6, 2, 19, 21] -> [8, 6, 2, 5, 3, 19, 21]45
46
47// 3. 添加和修改 48// 3.1 批量添加49static <T> boolean addAll(Collection<? super T> c, T... elements)50
51// 3.2 批量填充固定值52static <T> void fill(List<? super T> list, T obj)53
54// 3.3 批量复制(将src列表中的每个元素复制到dest列表的对应位置处,覆盖dest中原来的值,dest的列表长度不能小于src,dest中超过src长度部分的元素不受影响)55static <T> void copy(List<? super T> dest, List<? extends T> src)56
2) 返回一个容器
目的是为了使更多类型的数据更为方便和安全地参与到容器类协作体系中。
581// 1. 适配器:将其他类型的数据转换为容器接口对象2// 1.1 空容器(是一个静态不可变对象,不支持修改操作,可以节省创建新对象的内存和时间开销,经常用作方法返回值,等效于Java9中的List.of()方法)3static <T> Enumeration<T> emptyEnumeration()4static <T> Iterator<T> emptyIterator()5static final <T> List<T> emptyList()6static <T> ListIterator<T> emptyListIterator()7static final <K,V> Map<K,V> emptyMap()8static final <K,V> NavigableMap<K,V> emptyNavigableMap()9static <E> NavigableSet<E> emptyNavigableSet()10static final <T> Set<T> emptySet()11static final <K,V> SortedMap<K,V> emptySortedMap()12static <E> SortedSet<E> emptySortedSet()13
14// 1.2 单对象容器(将一个单独的对象转换为一个标准的容器接口对象,也是不可变对象,不支持修改操作)15// 经常用于构建方法参数或返回值,如list.removeAll(Collections.singleton("b"))表示删除list中的所有值为"b"的元素16// 注:list.remove("b")只会删除第一个"b"元素17static <T> Set<T> singleton(T o) // SingletonSet,等效于Java9中的Set.of("b")18static <T> List<T> singletonList(T o) // List.of("b")19static <K,V> Map<K,V> singletonMap(K key, V value) // Map.of("b")20
21// 1.3 容器转换22static <E> Set<E> newSetFromMap(Map<E, Boolean> map) // Map->Set23static <T> Queue<T> asLifoQueue(Deque<T> deque) // Deque->后进先出队列24static <T> List<T> nCopies(int n, T o) // 返回包含n个相同对象的List接口25
26
27// 2. 装饰器:修饰一个给定容器接口对象,增加某种性质 28// 2.1 写安全(使容器对象变为只读的,写入会抛出UnsupportedOperationException 异常)29static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c)30static <T> List<T> unmodifiableList(List<? extends T> list)31static <K,V> Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m)32static <K,V> NavigableMap<K,V> unmodifiableNavigableMap(NavigableMap<K, ? extends V> m)33static <T> NavigableSet<T> unmodifiableNavigableSet(NavigableSet<T> s)34static <T> Set<T> unmodifiableSet(Set<? extends T> s)35static <K,V> SortedMap<K,V> unmodifiableSortedMap(SortedMap<K, ? extends V> m)36static <T> SortedSet<T> unmodifiableSortedSet(SortedSet<T> s)37
38// 2.2 类型安全(指确保容器中不会保存错误类型的对象)39static <E> Collection<E> checkedCollection(Collection<E> c, Class<E> type)40static <E> List<E> checkedList(List<E> list, Class<E> type)41static <K, V> Map<K, V> checkedMap(Map<K, V> m, Class<K> keyType, Class<V> valueType)42static <K,V> NavigableMap<K,V> checkedNavigableMap(NavigableMap<K, V> m, Class<K> keyType, Class<V> valueType)43static <E> NavigableSet<E> checkedNavigableSet(NavigableSet<E> s, Class<E> type)44static <E> Queue<E> checkedQueue(Queue<E> queue, Class<E> type) 45static <E> Set<E> checkedSet(Set<E> s, Class<E> type)46static <K,V> SortedMap<K,V> checkedSortedMap(SortedMap<K, V> m, Class<K> keyType, Class<V> valueType)47static <E> SortedSet<E> checkedSortedSet(SortedSet<E> s, Class<E> type) 48
49// 2.3 线程安全50static <T> Collection<T> synchronizedCollection(Collection<T> c)51static <T> List<T> synchronizedList(List<T> list)52static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)53static <K,V> NavigableMap<K,V> synchronizedNavigableMap(NavigableMap<K,V> m)54static <T> NavigableSet<T> synchronizedNavigableSet(NavigableSet<T> s)55static <T> Set<T> synchronizedSet(Set<T> s)56static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m)57static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s)58
注意:为什么使用了泛型后还会有类型安全问题呢? 因为Java是通过擦除来实现泛型的,类型参数是可选的,并且JDK5前的老代码都没有泛型。
111// 类型安全检查前2List list = new ArrayList<Integer>();3list.add("hello"); // 不报错,但是有隐患4List<Integer> list2 = list;5System.out.println(list2.get(0).intValue()); // ClassCastException: java.lang.String cannot be cast to java.lang.Integer6// 类型安全检查后8List list = new ArrayList<Integer>();9list = Collections.checkedList(list, Integer.class);10list.add("hello"); // ClassCastException11
3) 其它
41// 1. 比较器2Collections.reverseOrder()3Collections.reverseOrder(String.CASE_INSENSITIVE_ORDER)4
第七节 面试补充
1. List相关
1) ArrayList与Array(数组)的区别?
Array 是一种基本数据结构,在创建时指定长度且不能修改,要求元素类型必须一致,但其内存占用小,访问效率高。
ArrayList 是 java.util 中实现的动态数组,只能存储对象类型数据,但支持动态扩容,且提供了丰富的API操作。
2) ArrayList与LinkedList的区别?
ArrayList 是基于静态数组实现的,访问效率高,尾部插入/删除较快,但头部和中间插入/删除较慢。
LinkedList 是基于链表实现的,头部和尾部插入/删除较快,但中间插入/删除或访问效率较慢。
3) ArrayList能存储null值吗?
ArrayList 、LinkedList 、HashSet、HashMap 等常用容器都可以存储 null 值,但HashSet 只能存储一个 null 值。
虽然 HashMap 的键和值都可以为 null 值,但 ConcurrentHashMap 为了避免 get(key) 为 null 时的二义性,不能将 null 作为键或值。
此外,PriorityQueue、TreeMap 等需要对元素进行排序的容器,也不能存储 null 值,或将 null 值作为 key。
4) 关于Vector和Stack
Vector 是一个通过
synchronized实现线程安全的动态数组, Stack 是其子类,表现为一个后进先出的栈,现在都很少使用。
2. Set相关
1) HashSet vs LinkedHashSet vs TreeSet
HashSet 是最常用的Set实现,底层是一个哈希表,它的元素无序且唯一。
LinkedHashSet 在 HashSet 的基础上加了一个链表,保证元素支持插入有序,即先进先出。
TreeSet 底层是红黑树,可以自定义元素的排序规则。
3. Queue相关
1) ArrayDeque 与 LinkedList 的区别
两者都实现了 Deque 接口,都具有队列的功能。
ArrayDeque 底层是动态数组+双指针,LinkedList 底层是链表,前者性能更好。
ArrayDeque 不支持存储 null 值,但 LinkedList 可以。
4. Map相关
1) HashMap的长度为什么是 2 的幂次方?
在对哈希值进行取余时,可用位运算替代,效率更高。
简化扩容机制,并使哈希值分布的更加均匀。
2) HashMap多线程操作会导致死循环?
JDK1.7之前在多线程环境下进行扩容操作时,使用的是头插法,可能会出现循环链表导致死循环。
JDK1.8及之后使用尾插法避免了这个问题,但是多线程环境下还是推荐优先使用 ConcurrentHashMap。
3) ConcurrentHashMap 能保证复合操作的原子性吗?
不能。如先判断元素不存在再进行插入是不行的,需要使用原子操作方法:
21map.putIfAbsent(key, value)2map.computeIfAbsent(key, k -> value)
5. 其它
1) 正确判断集合是否为空
判断所有集合内部的元素是否为空,使用 isEmpty() 方法,而不是 size()==0 的方式。
因为部分容器,特别是并发容器,size() 的时间复杂度并不是O(1)的,如 ConcurrentHashMap 需要判断每一个分段的size,而 isEmpty 只需要找到一个不为空的元素即可。
第05章_异常
第一节 异常类
1. 异常类简介
异常指程序运行过程中出现的错误,以java.lang.Throwable为根,Java定义了非常多的异常:

Throwable:是所有异常的基类。它有两个主要子类:java.lang.Error和java.lang.Exception。
Error:表示系统错误或资源耗尽。如图中列出的
虚拟机错误(VirtualMacheError)及其子类内存溢出错误(OutOfMemory-Error)和栈溢出错误(StackOverflowError)等。该类异常由Java系统自己使用,应用程序不应抛出和处理。Exception:表示应用程序错误。如图中的
IOException (输入输出I/O异常)、RuntimeException (运行时异常)、SQLException (数据库SQL异常)等。应用程序也可以通过继承Exception或其子类创建自定义异常。RuntimeException:Exception的一个特殊子类,表示未受检异常(unchecked exception),相对而言,Exception的其它子类称为受检异常(checked exception)。 未受检异常不要求程序对可能抛出的异常进行处理,使用更加方便。
2. 自定义异常类
应用程序可以通过继承Exception或其子类创建自定义异常。特别的,如果继承的是RuntimeException,那么创建的将会是未受检异常。
181// 继承自RuntimeException的未受检异常2public class BizException extends RuntimeException /*Exception*/ {3 public BizException() {4 }5
6 public BizException(String message) {7 super(message);8 }9
10 public BizException(Throwable cause) {11 super(cause); // cause是异常的底层原因,可以用于构建异常链12 }13
14 public BizException(String message, Throwable cause) {15 super(message, cause);16 }17}18
第二节 异常处理
1. 抛出异常(throw)
throw用来抛出一个异常对象,并将这个异常对象传递到调用者处,并结束当前方法的执行。
181public static void main(String[] args) {2 String[] arr = {"a", "b", "c"};3
4 // 查找数组元素5 String element = getElement(arr, 3);6 System.out.println("element = " + element);7}8
9public static String getElement(String[] arr, int index) {10 // 判断索引是否越界11 if (index < 0 || index > arr.length - 1) {12 // 越界,创建异常对象并抛出13 throw new ArrayIndexOutOfBoundsException("哥们,下标越界了~~~");14 }15
16 return arr[index];17}18
2. 捕获异常(try…catch)
异常抛出后,会沿着方法栈往调用者传递,我们可以对其进行捕捉和处理。
91public static void main(String[] args) {2 try {3 int anInt = Integer.parseInt("a");4 } catch (NumberFormatException exception) {5 // 处理异常6 exception.printStackTrace(); // java.lang.NumberFormatException: For input string: "a"7 }8}9
异常捕捉后,可以获取异常相关的信息,如下:
151// 异常描述信息2String message = exception.getMessage(); // For input string: "a"3
4// 异常的底层原因5Throwable cause = exception.getCause(); // null或其它异常6
7// 异常的字符串形式(不常用)8String toString = exception.toString(); // java.lang.NumberFormatException: For input string: "a"9
10// 异常的堆栈信息11StackTraceElement[] stackTrace = exception.getStackTrace(); 12
13// 打印堆栈信息到标准错误流14exception.printStackTrace(); // java.lang.NumberFormatException: For input string: "a" ...15
如需捕捉多个异常,则可以按照如下格式书写,注意越明确的类型应越先捕捉。
121try {2 // 业务代码3} catch (ArrayIndexOutOfBoundsException | StringIndexOutOfBoundsException exception) {4 System.out.println("数组索引越界异常|字符串索引越界异常");5} catch (IndexOutOfBoundsException exception) {6 System.out.println("索引越界异常");7} catch (RuntimeException exception) {8 System.out.println("运行时异常");9} catch (Exception exception) {10 System.out.println("异常");11}12 注意:
如果异常一直未被捕捉,最后会被Java虚拟机处理,默认行为是打印堆栈信息,然后退出线程。
3. 声明异常(throws)
对于受检异常,如果未在当前方法进行捕捉,则必须通过throws关键字在方法上进行声明,提醒调用者处理异常。
71public static void main(String[] args) throws ParseException {2 DateFormat dateTimeInstance = DateFormat.getDateTimeInstance();3
4 // parse方法可能抛出受检异常ParseException(已在方法进行声明)5 Date date = dateTimeInstance.parse("2022-12-21 15:23:32");6}7
注意:
子类方法不能声明或抛出父类方法中未声明的异常。
你可以声明抛出异常,但实际并不抛出,这一般用在在父类方法,方便子类进行扩展。
4. finally代码块
try后面还可以跟finally语句,finally内的代码不管有无异常发生,都会执行,一般用于释放资源,如数据库连接、文件流等。
111public static void main(String[] args) throws ParseException {2 DateFormat dateTimeInstance = DateFormat.getDateTimeInstance();3
4 try {5 Date date = dateTimeInstance.parse("2022-12-21 15:23:32");6 } finally {7 // 虚拟机正常运行时,该代码一定会被执行8 System.out.println("---finally---");9 }10}11
注意:
如果程序被突然终止(宕机、断电等)或在try/catch中调用了退出JVM相关的方法,则finally代码块不会被执行。
如果某些资源即使在程序退出后也不能自动释放,则不能依赖finally代码块,如持久化存储的业务标记。
如果finally代码块中有return语句或抛出异常,则会覆盖try代码块中的返回结果,应避免该情况。
5. try-with-resources(JDK7+)
try-with-resources语句配合java.lang.AutoCloseable接口,可以实现资源的自动关闭(基于finally代码块实现)。
331// 传统写法2public static void useResource() throws Exception {3 //创建资源4 AutoCloseable r = new FileInputStream("hello");5
6 try {7 //使用资源8 9 } finally {10 // 释放资源11 r.close();12 }13}14
15// try-with-resources写法(资源可以定义多个,以分号分隔)16public static void useResource() throws Exception {17 // 创建资源(退出try后可自动调用close()方法释放资源)18 try (AutoCloseable r = new FileInputStream("hello")) {19 // 使用资源20 }21}22
23// try-with-resources写法(引入方式,创建新的变量保存)24public static void useResource() throws Exception {25 final Resource resource1 = new Resource("resource1");26 Resource resource2 = new Resource("resource2");27 28 // 引入方式29 try (Resource r1 = resource1; Resource r2 = resource2) {30 // 使用资源31 }32}33
6. try-with-resources(JDK9+)
在Java 9之前,资源必须声明和初始化在try语句块内,Java 9去除了这个限制,资源可以在try语句外被声明和初始化,但必须是final的或者是事实上final的(即虽然没有声明为final但也没有被重新赋值)。
101// try-with-resources写法(引入方式, JDK9+简写)2public static void useResource() throws Exception {3 final Resource resource1 = new Resource("resource1");4 Resource resource2 = new Resource("resource2");5
6 // 引入方式7 try (resource1; resource2) {8 // 使用资源9 }10}
第三节 异常相关扩展
1. 异常链
在catch代码块中可重新抛出异常,异常可以是原来的,也可以是新建的,并且可以关联原来的异常形成异常链。
71try {2 // 业务代码3} catch (NumberFormatException exception) {4 System.out.println("not valid number");5 throw new BizException("输入格式不正确", exception);6}7
上述案例中,捕捉到NumberFormatException异常后,转化为统一的BizException重新抛出,并将exception作为cause传递给了新建的BizException,这样就形成了一个异常链,捕获到BizException的代码可以通过getCause()得到底层的NumberFormatException。
某些Java的异常类并没有定义带cause的构造方法,但可以通过Throwable的Throwable initCause(Throwable cause)方法来设置cause,但是必须注意,该方法只能被调用一次。
2. 异常与枚举结合
3. 特殊情况下的finally
如果在try或者catch语句内有return语句,则return语句执行后的结果先会缓存,待finally语句执行结束后才返回(但是该值不能被改变)。
151public class Demo {2 public static void main(String[] args) throws ParseException {3 System.out.println(test()); // 返回值是0,而不是24 }5
6 public static int test() {7 int ret = 0;8 try {9 return ret; // 返回值10 } finally {11 ret = 2; // 返回值已确定,无法修改12 }13 }14}15
如果在finally中也有return语句呢? 那么try和catch内的return会丢失,实际会返回finally中的返回值。finally中有return不仅会覆盖try和catch内的返回值,还会掩盖try和catch内的异常,就像异常没有发生一样。
161public class Demo {2 public static void main(String[] args) throws ParseException {3 System.out.println(test()); // 正常返回2,而非抛异常4 }5
6 public static int test() {7 int ret = 0;8 try {9 int a = 1 / 0; // ArithmeticException10 return ret;11 } finally {12 return 2; // 实际返回13 }14 }15}16
同理,如果finally代码块中抛出了异常,则原返回值或异常也将会被掩盖。
151public class Demo {2 public static void main(String[] args) throws ParseException {3 System.out.println(test()); // 抛RuntimeException异常而非ArithmeticException4 }5
6 public static int test() {7 try {8 int a = 1 / 0; // ArithmeticException9 return a;10 } finally {11 throw new RuntimeException("hello"); // RuntimeException12 }13 }14}15
因此,应该尽量避免在finally中使用return语句或者抛出异常,如果调用的其他代码可能抛出异常,则应该捕获异常并进行处理。
第06章_文件
第一节 文件概述
1. 基础概念
文件:文件是操作系统对磁盘数据的抽象,方便用户进行数据管理。
文件存储:文件在磁盘上以二进制形式进行存储,根据解读方式的不同,可分为UTF-8文本文件、JPG图片文件、MP4视频文件、ZIP压缩文件等多种类型,一般以后缀名进行标识。
文本文件:如果文件能以某种编码(UTF-8、GBK等)映射为可读的字符形式,那么该类文件称为文本文件。文本文件具有换行的概念,在Windows系统中使用\r\n这2个字节表示换行符(Linux为\n,MAC系统为\r)。
注意:
在Windows系统中,文件名是大小写不敏感的,即同目录下的a.txt和A.txt是同一个文件。
文件IO比较慢,且需经过内核态和用户态的两次复制,因此文件操作时一般按块进行,并设置一定大小的缓冲区。
2. 文件与目录(File)
1) File类
java.io.File 类封装了操作系统和文件系统的差异,提供了统一的文件和目录API。它可以表示文件,也可以表示目录,构造方法如下:
91// 1. 构造方法。创建一个表示文件或目录的不可变对象。文件或目录可以存在,也可以不存在,并不会实际打开文件。2public File(String pathname) // pathname-完整路径[+文件名](可以是相对路径,也可以是绝对路径)3public File(String parent, String child) // parent-父目录 child-表示子目录[+文件名]4public File(File parent, String child)5
6// 2. 获取构造参数7public String getPath() // 构造File对象时的原始路径和文件名8public String getName() // 仅文件或目录名称9
File 类中有 4 个静态变量, 表示路径或目录的分隔符:
91// 1. 文件路径分隔符(Linux为正斜杠/,windows为反斜杠\)2public static final String separator3public static final char separatorChar4
5// 2. 多个文件路径中的分隔符,如环境变量PATH中的分隔符,Java类路径变量classpath中的分隔符(Linux为:,windows为;)6public static final String pathSeparator7public static final char pathSeparatorChar8
9// 3. 特别提示:特定于平台的换行符可以使用System.lineSeparator()获取,或使用BufferedReader.newLine()输出
2) 文件基本信息
271// 1. 父目录2public String getParent()3public File getParentFile()4
5// 2. 绝对路径6public boolean isAbsolute() // 判断File中的路径是否是绝对路径7public String getAbsolutePath() // 完整的绝对路径名8public File getAbsoluteFile() 9 10// 3. 简洁的绝对路径(去掉路径中的"."或".."以及跟踪软链接等)11public String getCanonicalPath() throws IOException12public File getCanonicalFile() throws IOException 13 14// 4. 文件或目录是否存在15public boolean exists()16 17// 5. 是否为文件或目录18public boolean isDirectory() 19public boolean isFile() 20
21// 6. 文件长度(字节数),对目录没有意义22public long length() 23
24// 7. 文件修改时间25public long lastModified() // 最后修改时间,从纪元时开始的毫秒数26public boolean setLastModified(long time) // 设置最后修改时间,返回是否修改成功27
注意, File 对象没有返回创建时间的方法 , 因为创建时间不是一个公共概念 , Linux/Unix 就没有创建时间的概念。
3) 文件安全与权限
File 类中与安全和权限相关的主要方法有:
161public boolean isHidden() // 是否为隐藏文件(Linux中文件无隐藏属性,以.开头的文件表示隐藏文件)2public boolean canExecute() // 是否可执行3public boolean canRead() // 是否可读4public boolean canWrite() // 是否可写5public boolean setReadOnly() // 设置文件为只读文件,修改成功返回true,否则返回false,下亦同6 7// 修改文件读权限(ownerOnly表示是否仅对文件拥有者生效,如果false,等效于chmod a+r )8public boolean setReadable(boolean readable, boolean ownerOnly) 9public boolean setReadable(boolean readable) // ownerOnly默认为true,等效chmod o+r10// 修改文件写权限11public boolean setWritable(boolean writable, boolean ownerOnly)12public boolean setWritable(boolean writable) // chmod o+w13// 修改文件可执行权限14public boolean setExecutable(boolean executable, boolean ownerOnly)15public boolean setExecutable(boolean executable) // chmod o+x16
4) 常用文件操作
当 File 对象代表文件时,主要操作有创建 、 删除 、 重命名等。
161// 1. 实际创建文件。创建成功返回true,否则返回false。如果文件已存在,则不会重新创建。2public boolean createNewFile() throws IOException3
4// 2. 创建临时文件(静态方法)5// 只可以指定临时文件的前缀、后缀和目录,而完整得路径名是由系统生成的,具有唯一性6// prefix-前缀,至少3个字符 suffix-后缀名,默认为.tmp directory-临时文件所在目录,为null或不指定则为系统默认目录7public static File createTempFile(String prefix, String suffix) throws IOException8public static File createTempFile(String prefix, String suffix, File directory) throws IOException9
10// 3. 删除文件11public boolean delete() // 删除文件或空目录,删除成功返回true,否则返回false(注意:删除非空目录将失败,返回false)12public void deleteOnExit() // 在 Java 虚拟机正常退出的时候进行删除13
14// 4. 重命名文件15public boolean renameTo(File dest) // 重命名成功返回true16
5) 常用目录操作
当 File 对象代表目录时,可以执行目录相关的操作,如创建、遍历等。
191// 创建目录。成功返回true , 失败返回false,如果目录已存在,返回值是false。2public boolean mkdir() // 中间目录要求存在,否则返回false,类似于:mkdir p-dir/a13public boolean mkdirs() // 创建中间目录,类似于:mkdir -p p-dir/a14
5// 列举目录下的所有文件和目录(. .. 除外),但不进行递归6public String]] list()7public String]] list(FilenameFilter filter) // FilenameFilter 传入目录和文件名进行过滤,返回true表示可列举8public File]] listFiles()9public File[] listFiles(FileFilter filter) // FileFilter 传入完整文件名进行过滤,返回true表示可列举10public File[] listFiles(FilenameFilter filter)11 12public interface FileFilter {13 boolean accept(File pathname);14}15
16public interface FilenameFilter {17 boolean accept(File dir, String name);18}19
6) 文件和目录操作案例
831// 列出当前目录下的所有扩展名为 .txt 的文件2public static void main(String[] args) {3 File f = new File(".");4 // 列举目录下的文件或目录并执行过滤5 File[] files = f.listFiles(new FilenameFilter() {6 7 public boolean accept(File dir, String name) {8 if (name.endsWith(".txt")) {9 return true; // 仅列举txt文件10 }11 return false;12 }13 });14}15
16// 递归遍历:列举目录下的所有文件(不包括目录)17public static List<File> listAllFiles(final File directory) {18 ArrayList<File> files = new ArrayList<>();19
20 if (directory.isFile()) {21 // 文件,直接处理22 files.add(directory);23 } else {24 // 目录,列举后循环处理25 for (File file : directory.listFiles()) {26 if (file.isFile()) {27 // 子文件,直接处理28 files.add(directory);29 } else {30 // 子目录,递归31 files.addAll(listAllFiles(file));32 }33 }34 }35
36 return files;37}38
39
40// 递归遍历:计算一个目录下的所有文件的大小41public static long sizeOfDirectory(final File directory, String suffix) {42 long size = 0;43 if (directory.isFile()) {44 // 文件,直接处理45 if (directory.getName().endsWith(suffix)) {46 size = directory.length();47 }48 } else {49 // 目录,列举后循环处理50 for (File file : directory.listFiles()) {51 if (file.isFile()) {52 // 子文件,直接处理53 if (file.getName().endsWith(suffix)) {54 size += file.length();55 }56 } else {57 // 子目录,递归58 size += sizeOfDirectory(file, suffix);59 }60 }61 }62 return size;63}64
65// 递归遍历:删除非空目录66public static void deleteRecursively(final File file) throws IOException {67 if (file.isFile()) {68 // 文件,直接处理69 if (!file.delete()) {70 throw new IOException("Failed to delete " + file.getCanonicalPath());71 }72 } else if (file.isDirectory()) {73 // 目录,列举后循环处理每个子文件或子目录74 for (File child : file.listFiles()) {75 deleteRecursively(child);76 }77
78 // 再处理当前目录79 if (!file.delete()) {80 throw new IOException("Failed to delete " + file.getCanonicalPath());81 }82 }83}
第二节 字节流
在Java中,将文件及其它输入输出设备抽象为流,并构建了基于流的相关协作体系,默认情况下,流为字节形式,称为字节流。
1. InputStream/OutputStream
InputStream/OutputStream(抽象类)表示最顶层的字节输入流和字节输出流,其中定义了它们的一些共性方法:
321---------------------- InputStream --------------------------2// 1. 读1个字节3// 如果有数据,则返回0~255;如果无数据,则阻塞直到数据到来或流关闭或出现异常;如果读到结尾,则返回-1。4public abstract int read() throws lOException 5
6// 2. 读n个字节7// 最多读n个字节到字节数组中,返回值为实际读入的字节个数。如果流中无数据则会阻塞;如果刚开始读取时已到流结尾,则返回-1; 8public int read(byte b[]) throws IOException 9public int read(byte b[], int off, int len) throws lOException // off-起始索引,len-读取长度10
11// 3. 关闭流12public void close() throws lOException // 一般在finlly代码块中调用,并且对close()抛出的异常进行忽略13
14// 4. 高级方法(跳读/重读)15public long skip(long n) throws IOException // 尽力跳过输入流中n个字节,返回实际跳过的字节数16public int available() throws IOException // 返回下一次不需要阻塞就能读取到的大概字节个数,InpuStream默认为017public synchronized void mark(int readlimit) // 标记流,此后可以使用reset()方法回到该位置,readlimit为最大可回退的字节数18public boolean markSupported() // 判断是否支持mark()方法,FileInpuStream不直接支持,BufferedInput-Stream/ByteArrayInputStream可以支持19public synchronized void reset() throws IOException // 回退流到mark()方法标记处20
21---------------------- OutputStream --------------------------22// 1. 写1个字节(取int参数的低8位)23public abstract void write(int b) throws IOException24
25// 2. 写n个字节26public void write(byte b[]) throws IOException27public void write(byte b[], int off, int len) throws IOException // off-起始索引,len-写入长度28 29// 3. 刷新流/关闭流30public void flush() throws IOException // 将缓冲而未实际写的数据进行实际写入(应用->操作系统)31public void close() throws IOException // 先调用flush方法,再释放流占用的系统资源。一般也要求在finlly代码块调用。32
2. FileInputStream/FileOutputStream
FileInputStream/FileOutputStream继承自InputStream/OutputStream, 表示文件输入流和文件输出流,即输入输出目的地为文件。
221---------------------- FileInputStream --------------------------2// 1. 构造方法。打开文件并构造FileInputStream3// 如果文件不存在,则报错:FileNotFoundException: D:\video.txt (系统找不到指定的文件。)4// 如果指定的文件是一个已存在的目录,则报错:FileNotFoundException: D:\video (拒绝访问。)5// 如果当前用户没有读权限,会抛出异常SecurityException(RuntimeException)6public FileInputStream(String name) throws FileNotFoundException7public FileInputStream(File file) throws FileNotFoundException8
9
10---------------------- FileOutputStream --------------------------11 12// 1. 构造方法。打开文件并构造FileOutputStream13// 如果文件存在,则进行覆盖;如果文件不存在,则创建新文件。14// 如果指定的文件是一个已存在的目录,或者由于其他原因不能打开文件,会抛出异常FileNotFoundException(IOException)15// 如果当前用户没有写权限,会抛出异常SecurityException(RuntimeException)16public FileOutputStream(File file, boolean append) throws FileNotFoundException // append-是否追加方式打开17public FileOutputStream(String name) throws FileNotFoundException18
19// 2. 高级方法20public final FileDescriptor getFD() // 获取文件描述符(保存与操作系统相关的一些文件内存结构,同时提供了sync()方法)21public native void sync() throws SyncFailedException // 刷新缓存区(操作系统->硬盘)22 下面是一些按字节读写文件的示例:
461// 批量写文件示例2public static void main(String[] args) throws FileNotFoundException {3 // 1. 打开文件4 OutputStream output = new FileOutputStream("hello.txt"); // FileNotFoundException5
6 // 2. 写字节数据7 try {8 String data = "hello, 黄原鑫";9 byte[] bytes = data.getBytes(StandardCharsets.UTF_8);10 output.write(bytes);11 } catch (IOException e) {12 e.printStackTrace();13 } finally {14
15 // 3. 关闭文件16 try {17 output.close();18 } catch (IOException e) {19 e.printStackTrace();20 }21 }22}23
24// 批量读文件示例25public static void main(String[] args) throws FileNotFoundException {26 // 1. 打开文件27 InputStream input = new FileInputStream("hello.txt"); // FileNotFoundException28
29 // 2. 按字节读取数据30 try {31 byte[] buf = new byte[1024];32 int bytesRead = input.read(buf); // 最多读1024字节33 String data = new String(buf, 0, bytesRead, StandardCharsets.UTF_8);34 System.out.println(data);35 } catch (IOException e) {36 e.printStackTrace();37 } finally {38
39 // 3. 关闭文件40 try {41 input.close();42 } catch (IOException e) {43 e.printStackTrace();44 }45 }46}
3. ByteArrayInputStream/ByteArrayOutputStream
ByteArrayInputStream/ByteArrayOutputStream也继承自InputStream/OutputStream, 表示字节数组输入流和字节数组输出流,即输入输出目的地为字节数组。
221---------------------- ByteArrayInputStream --------------------------2// 1. 构造方法。将字节数组包装为一个字节输入流,是一种适配器模式。3// 字节数组输入流的所有数据都在内存,支持mark/reset重复读取4public ByteArrayInputStream(byte buf[])5public ByteArrayInputStream(byte buf[], int offset, int length) // offset-起始索引 length-使用的长度6
7---------------------- ByteArrayOutputStream --------------------------8// 1. 构造方法。内部为一个字节数组,数组长度根据流输出的内容动态扩展。9public ByteArrayOutputStream()10public ByteArrayOutputStream(int size) // size-初始尺寸大小,默认为32,不足时进行指数扩展11
12// 2. 转换为字节数组或字符串13public synchronized byte[] toByteArray()14public synchronized String toString() // 使用系统默认编码15public synchronized String toString(String charsetName) // 使用指定编码16
17// 3. 写到另一个OutputStream18public synchronized void writeTo(OutputStream out) throws IOException19
20// 4. 其它方法21public synchronized int size() // 当前写入的字节个数22public synchronized void reset() // 重置字节个数为0 下面示例将从文件输入流读取数据到字节数组输出流,然后转化为字符串输出。
361public static void main(String[] args) throws FileNotFoundException {2 // 1. 打开输入流(FileInputStream)3 InputStream input = new FileInputStream("hello.txt");4 ByteArrayOutputStream output = null;5
6 try {7 // 2. 打开输出流(ByteArrayOutputStream)8 output = new ByteArrayOutputStream();9
10 // 3. 每次最多读取1024字节,读到结尾时(-1)退出11 byte[] buf = new byte[1024];12 int bytesRead = 0;13 while ((bytesRead = input.read(buf)) != -1) {14 // 4. 写到输出流15 output.write(buf, 0, bytesRead); // 由于最后一次读取可能<1024字节,因此需指定本次读取的字节长度16 }17
18 // 5. 字节数组输出流转换为字符串19 String data = output.toString("UTF-8");20 System.out.println(data);21 } catch (IOException e) {22 e.printStackTrace();23 } finally {24 // 6. 关闭输出流和输入流25 try {26 output.close();27 } catch (IOException ioException) {28 ioException.printStackTrace();29 }30 try {31 input.close();32 } catch (IOException ioException) {33 ioException.printStackTrace();34 }35 }36}
4. DataInputStream/DataOutputStream
DataInputStream/DataOutputStream是装饰类基类FilterInputStream/FilterOutputStream的子类,并且实现了DataInput/DataOutput接口,可以以各种基本类型和字符串读取或写入数据。
191---------------------- DataInputStream --------------------------2// 1. 构造方法。装饰一个InputStream(接口+组合)3public DataInputStream(InputStream in)4
5// 2. 读数据6boolean readBoolean() throws lOException;7int readInt() throws IOException;8String readUTF() throws IOException;9
10
11---------------------- DataOutputStream --------------------------12// 1. 构造方法。装饰一个OutputStream(接口+组合)13public DataOutputStream(OutputStream out)14
15// 2. 写数据16void writeBoolean(boolean v) throws IOException; // 写入1个字节,如果值为true,则写入1,否则017void writeInt(int v) throws IOException; // 写入4个字节,最高位字节先写入,最低位最后写入18void writeUTF(String s) throws IOException; // 将字符串的UTF-8编码字节写入19
下面是一个使用DataInputStream/DataOutputStream装饰FileInputStream/FileOutputStream后,用来序列化对象的使用示例:
601public class Student {2 String name;3 int age;4 double score;5
6 // 无参构造、全参构造、Getter/Setter、toString7
8 public static void main(String[] args) throws IOException {9 List<Student> students = Arrays.asList(new Student[]{10 new Student("张三", 18, 80.9d),11 new Student("李四", 17, 67.5d)12 });13
14 writeStudents(students);15
16 List<Student> readStudents = readStudents();17 System.out.println(readStudents);18 }19
20 public static void writeStudents(List<Student> students) throws IOException {21 // 1. 装饰FileOutputStream22 DataOutputStream output = new DataOutputStream(new FileOutputStream("students.dat"));23
24 try {25 // 2. 写数据26 output.writeInt(students.size());27 for (Student s : students) {28 output.writeUTF(s.getName());29 output.writeInt(s.getAge());30 output.writeDouble(s.getScore());31 }32 } finally {33 // 3. 关闭流34 output.close();35 }36 }37
38 public static List<Student> readStudents() throws IOException {39 // 1. 装饰FileInputStream40 DataInputStream input = new DataInputStream(new FileInputStream("students.dat"));41
42 try {43 // 2. 读数据44 int size = input.readInt();45 List<Student> students = new ArrayList<>(size);46 for (int i = 0; i < size; i++) {47 Student s = new Student();48 s.setName(input.readUTF());49 s.setAge(input.readInt());50 s.setScore(input.readDouble());51 students.add(s);52 }53 return students;54 } finally {55 // 3. 关闭流56 input.close();57 }58 }59}60
5. ObjectInputStream/ObjectOutputStream
ObjectInputStream/ObjectOutputStream继承自InputStream/OutputStream,并实现了ObjectInput/ObjectOutput接口,可以读取和写入实现了java.io.Serializable接口的对象。
141---------------------- ObjectInputStream --------------------------2// 1. 构造方法3public ObjectInputStream(InputStream in) throws IOException4 5// 2. 读数据:字节、整型、字符串、对象等6// 如果反序列化的数据没有匹配的类信息,将会报ClassNotFoundException7public final Object readObject() throws IOException, ClassNotFoundException8 9---------------------- ObjectOutputStream --------------------------10// 1. 构造方法11public ObjectOutputStream(OutputStream out) throws IOException12
13// 2. 写数据:字节、整型、字符串、对象等14public final void writeObject(Object obj) throws IOException下面是一个使用ObjectInputStream/ObjectOutputStream来写入和读取对象的示例:
531public class Student implements Serializable {2 String name;3 int age;4 double score;5
6 public static void main(String[] args) throws IOException, ClassNotFoundException {7 List<Student> students = Arrays.asList(new Student[]{8 new Student("张三", 18, 80.9d),9 new Student("李四", 17, 67.5d)10 });11
12 writeStudents(students);13
14 List<Student> readStudents = readStudents();15 System.out.println(readStudents);16 }17
18 public static void writeStudents(List<Student> students) throws IOException {19 // 1. 对象输出流20 ObjectOutputStream out = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream("students.dat")));21
22 try {23 // 2. 写数据24 out.writeInt(students.size());25 for (Student s : students) {26 out.writeObject(s); // 一次写一个对象27 }28 } finally {29 // 3. 关闭流30 out.close();31 }32 }33
34 public static List<Student> readStudents() throws IOException, ClassNotFoundException {35 // 1. 对象输入流36 ObjectInputStream in = new ObjectInputStream(new BufferedInputStream(new FileInputStream("students.dat")));37
38 try {39 // 2. 读数据40 int size = in.readInt();41 List<Student> list = new ArrayList<>(size);42 for (int i = 0; i < size; i++) {43 list.add((Student) in.readObject()); // 一次读一个对象44 }45 return list;46 } finally {47 // 3. 关闭流48 in.close();49 }50 }51
52}53
实际上,List以及之前介绍的String、Date、Double、Map等, 都实现了Serializable接口,上述示例可以再次简化:
201 public static void writeStudentList(List<Student> students) throws IOException {2 ObjectOutputStream out = new ObjectOutputStream(new BufferedOutputStream(new FileOutputStream("students.dat")));3 try {4 // 直接序列化Student数组5 out.writeObject(students);6 } finally {7 out.close();8 }9 }10
11 public static List<Student> readStudentList() throws IOException, ClassNotFoundException {12 ObjectInputStream in = new ObjectInputStream(new BufferedInputStream(new FileInputStream("students.dat")));13 try {14 // 反序列化Student数组15 return (List<Student>) in.readObject();16 } finally {17 in.close();18 }19 }20
扩展:
ObjectInput/ObjectOutput是DataInput/DataOutput的子接口,增加了Object readObject()和void writeObject(Object obj)方法。
6. BufferedInputStream/BufferedOutputStream
BufferedInputStream/BufferedOutputStream也是装饰类基类FilterInputStream/FilterOutputStream的子类,它提供了对流进行缓冲的作用,提升操作流的性能。
131---------------------- BufferedInputStream --------------------------2// 1. 构造方法。装饰一个InputStream,并且支持其mark/reset方法3public BufferedInputStream(InputStream in)4public BufferedInputStream(InputStream in, int size) // size-缓冲区大小,默认为81925
6---------------------- BufferedOutputStream --------------------------7// 1. 构造方法。装饰一个OutputStream8public BufferedOutputStream(OutputStream out)9public BufferedOutputStream(OutputStream out, int size) // size-缓冲区大小,默认为819210
11// 2. 刷新流12public synchronized void flush() throws IOException // 将缓冲区的内容写到包装的流中,并调用包装流的flush()方法13
在使用FileInputStream/FileOutputStream时,应该几乎总是在它的外面包上对应的缓冲类,如下所示:
81// 使用BufferedInputStream/BufferedOutputStream装饰FileInputStream/FileOutputStream,使其具有缓冲功能2Inputstream input = new BufferedInputStream(new FileInputStream("hello.txt"));3Outputstream output = new BufferedOutputStream(new FileOutputStream("hello.txt"));4
5// 被BufferedInputStream/BufferedOutputStream装饰后的流依然可以被其它装饰类装饰6DataOutputStream output = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("students.dat")));7DataInputStream input = new DataInputStream(new BufferedInputStream(new FileInputStream("students.dat")));8
提示:
BufferedInputStream/BufferedOutputStream是对InputStream/OutputStream的装饰,使用了装饰器模式。
7. RandomAccessFile
如果需要对文件进行随机读写或重复读,可以使用RandomAccessFile,它一个更接近于操作系统API的封装类。
411// 1. 构造方法2// mode取值有四种,分别为 r-只读、rw-读写、rwd-读写并同步刷新文件内容、rws-读写并同步刷新文件内容及元数据)3public RandomAccessFile(String name, String mode) throws FileNotFoundException 4public RandomAccessFile(File file, String mode) throws FileNotFoundException5
6// 2. 操作文件指针7// RandomAccessFile内部有一个文件指针,指向当前读写的位置,各种read/write操作都会自动更新该指针8public native long getFilePointer() throws IOException; //获取当前文件指针9public native void seek(long pos) throws IOException; //更改当前文件指针到pos10public int skipBytes(int n) throws IOException // 文件指针位移n11public native long length() throws IOException; // 文件字节数12public native void setLength(long newLength) throws IOException; // 修改文件长度(文件将会截断或扩展,扩展内容未定义)13
14// 3. 读方法15public int read() throws IOException //读一个字节,取最低八位,0到25516public int read(byte b[]) throws IOException17public int read(byte b[], int off, int len) throws IOException18public final double readDouble() throws IOException19public final int readInt() throws IOException20public final String readUTF() throws IOException21
22// 4. 读满字节数组 23// 读够期望的长度,如果到了文件结尾也没读够,它们会抛出EOFException异常24public final void readFully(byte b[]) throws IOException // 读满字节数组25public final void readFully(byte b[], int off, int len) throws IOException26
27// 5. 写方法28public void write(int b) throws IOException29public final void writeInt(int v) throws IOException30public void write(byte b[]) throws IOException31public void write(byte b[], int off, int len) throws IOException32public final void writeUTF(String str) throws IOException33
34// 6. 关闭文件35public void close() throws IOException36
37// 7. 有问题的方法38// RandomAccessFile没有编码的概念,假定一个字节代表一个字符,无法处理多字节字符(中文),应避免使用39public final void writeBytes(String s) throws IOException // 写字符串(要求输入字符串无多字节字符)40public final String readLine() throws IOException // 读一行(要求文件无多字节字符)41
注意:
虽然RandomAccessFile有类似于读写字节流的方法,但大多是实现DataInput/DataOutput接口而来,并不是InputStream/OutputStream的子类。
8. MappedByteBuffer
如果需要处理大型文件或在不同应用程序之间共享数据,可以使用MappedByteBuffer,它是文件映射到内存的字节数组,操作该字节数组即可操作文件,大多数操作系统都支持该机制,称为内存映射文件。
内存映射文件基于FileInputStream/FileOutputStream或RandomAccessFile,它们都有一个获取FileChannel方法,而FileChannel可以将文件映射到内存,映射完成后,文件就可以关闭了,后续对文件的读写可以通过MappedByteBuffer完成。
91// 1. 获取FileChannel2public FileChannel getChannel() 3
4// 2. 映射文件到内存5// mode-映射模式(MapMode.READ_ONLY-只读、MapMode.READ_WRITE-读写、MapMode.PRIVATE-私有模式,更改不反映到文件,也不被其他程序看到 )6// position-映射起始位置 size-映射长度,如果映射的区域超过了现有文件的范围,则文件会自动扩展,扩展出的区域字节内容为07public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException8
9
注意:
映射模式受限于文件打开的方式,若是输入流或写模式打开文件,则不能设置为READ_WRITE映射模式。
内存映射文件仅在发生实际读写时,才会将要读写的部分按页映射到内存。数据读写完毕后,由操作系统进行同步,只要操作系统不崩溃,一定可以同步到磁盘上,即使应用程序已经退出。
在该种方式下,程序直接访问内核内存空间,仅需一次数据拷贝过程,比普通文件读写的性能更高。
内存映射文件也有局限性,比如,它不太适合处理小文件,它是按页分配内存的,对于小文件,会浪费空间,另外,映射文件要消耗一定的操作系统资源,初始化比较慢。
MappedByteBuffer代表内存中的字节数组,是 ByteBuffer(Buffer) 的子类,它可以简单理解为一个字节数组包装类,这个字节数组的长度是不可变的,在内存映射文件中,这个长度由map方法中的参数size决定。
231// 1. 获取和修改读写位置指针2public final int position() // 获取当前读写位置3public final Buffer position(int newPosition) // 修改当前读写位置4
5// 2. 读写数据(这些方法在读写后,都会自动增加position)6public abstract byte get(); // 从当前位置获取一个字节7public ByteBuffer get(byte[] dst) // 从当前位置拷贝dst.length长度的字节到dst8public abstract int getInt(); // 从当前位置读取一个int9public abstract double getDouble(); // 从当前位置读取一个double10public final ByteBuffer put(byte[] src) // 将字节数组src写入当前位置11public abstract ByteBuffer putLong(long value); // 将long类型的value写入当前位置12
13// 3. 指定位置读写数据(这些方法在读写时,不会改变当前读写位置position)14public abstract int getInt(int index); // 从index处读取一个int15public abstract double getDouble(int index); //从index处读取一个double16public abstract ByteBuffer putDouble(int index, double value); // 在index处写入一个double17public abstract ByteBuffer putLong(int index, long value); // 在index处写入一个long18
19// 4. 与文件内容同步相关的方法20public final boolean isLoaded() // 检查文件内容是否真实加载到了内存,这个值是一个参考值,不一定精确21public final MappedByteBuffer load() // 尽量将文件内容加载到内存22public final MappedByteBuffer force() // 将对内存的修改强制同步到硬盘上23
内存映射文件的另一个重要特点是,它可以被多个不同的应用程序共享,多个程序可以映射同一个文件,映射到同一块内存区域,一个程序对内存的修改,可以让其他程序也看到,这使得它特别适合用于不同应用程序之间的通信。
9. 字节流操作实用方法
381/**2 * 拷贝字节流。类似于JDK9中的InputStream.transferTo()方法3 */4public static void copy(InputStream input, OutputStream output) throws IOException {5 byte[] buf = new byte[4096];6 int bytesRead = 0;7 while ((bytesRead = input.read(buf)) != -1) {8 output.write(buf, 0, bytesRead);9 }10}11
12/**13 * 将文件读入字节数组14 */15public static byte[] readFileToByteArray(String fileName) throws IOException {16 InputStream input = new FileInputStream(fileName);17 ByteArrayOutputStream output = new ByteArrayOutputStream();18 try {19 copy(input, output);20 return output.toByteArray();21 } finally {22 input.close();23 }24}25
26/**27 * 将字节数组写入文件28 *29 */30public static void writeByteArrayToFile(String fileName, byte[] data) throws IOException {31 OutputStream output = new FileOutputStream(fileName);32 try {33 output.write(data);34 } finally {35 output.close();36 }37}38
第三节 字符流
字符流指以字符为单位读取和解读流中的字节,一个字符可能包含多个字节,这取决解读时使用的字符编码。
注意:对于增补字符集,一个完整的字符内容可能需要两个字符(char)来表示。
1. Reader/Writer
Reader/Writer(抽象类)表示最顶层的字符输入流和字符输出流,其中定义了它们的一些共性方法:
321---------------------- Reader --------------------------2// 1. 读1个字符(0~65535)3public int read() throws lOException4
5// 2. 读N个字符6public int read(char cbuf[]) throws lOException7abstract public int read(char cbuf[], int off, int len) throws IOException8
9// 3. 关闭流10abstract public void close() throws IOException11
12// 4. 高级方法13public long skip(long n) throws IOException // 跳过n个字符14public boolean ready() throws IOException // 返回下一次不需要阻塞就能读取到的大概字符个数。类似于字节流的有available()方法15
16
17---------------------- Writer --------------------------18// 1. 写1个字符19public void write(int c)20
21// 2. 写n个字符22public void write(char cbuf[])23abstract public void write(char cbuf[], int off, int len) throws IOException24
25// 3. 写字符串26public void write(String str) throws IOException27
28// 4. 刷新/关闭流29abstract public void close() throws IOException;30abstract public void flush() throws IOException;31
32
2. InputStreamReader/OutputStreamWriter
InputStreamReader/OutputStreamWriter是适配器类,继承自Reader/Writer,能将字节流(InputStream/OutputStream)转换为字符流(Reader/Writer)。
101---------------------- InputStreamReader --------------------------2// 1. 构造方法。将字节输入流适配为字符输入流3public InputStreamReader(InputStream in) // 使用系统默认编码:Charset.defaultCharset()4public InputStreamReader(InputStream in, String charsetName) // charsetName-字符编码5
6---------------------- OutputStreamWriter --------------------------7// 1. 构造方法。将字节输出流适配为字符输出流8public OutputStreamWriter(OutputStream out) // 使用系统默认编码:Charset.defaultCharset()9public OutputStreamWriter(OutputStream out, String charsetName) // charsetName-字符编码10
下面是一个将字节流适配为字符流并进行字符读写的示例:
291public static void main(String[] args) throws IOException {2 // 1. 将字节输出流适配为GB2312编码的字符输出流3 Writer writer = new OutputStreamWriter(new FileOutputStream("hello.txt"), "GB2312");4
5 try {6 // 2. 按字符写数据7 String str = "hello, 123,老马";8 writer.write(str);9 } finally {10 11 // 3. 关闭流12 writer.close();13 }14
15 // 1. 将字节输入流适配为GB2312编码的字符输入流16 Reader reader = new InputStreamReader(new FileInputStream("hello.txt"), "GB2312");17 try {18
19 // 2. 按字符读数据20 char[] cbuf = new char[1024]; // 最大读1024字节21 int charsRead = reader.read(cbuf);22 System.out.println(new String(cbuf, 0, charsRead));23 } finally {24 25 // 3. 关闭流26 reader.close();27 }28}29
提示:
InputStreamReader和OutputStreamWriter分别是字节流和字符流之间的适配器,使用了适配器模式。
3. FileReader/FileWriter
FileReader/FileWriter继承自Reader/Writer, 表示文件字符输入流和文件字符输出流,即输入输出目的地为文件。
111---------------------- FileReader --------------------------2// 1. 构造方法3public FileReader(File file) throws FileNotFoundException4public FileReader(String fileName) throws FileNotFoundException5
6
7---------------------- FileWriter --------------------------8// 1. 构造方法9public FileWriter(File file) throws IOException10public FileWriter(String fileName, boolean append) throws IOException // append-是否追加方式打开11 注意:
FileReader和FileWriter以及下面介绍的几种字符流操作类,都不能直接指定编码类型,只能使用默认编码。
如需指定字符流的编码类型,可以使用适配器InputStreamReader/OutputStreamWriter将字节流转换为指定编码的字节流。
4. CharArrayReader/CharArrayWriter
CharArrayReader/CharArrayWriter也继承自Reader/Writer, 表示字符数组输入流和字符数组输出流,即输入输出目的地为字符数组。
141---------------------- CharArrayReader --------------------------2// 1. 构造方法3public CharArrayReader(char buf[])4public CharArrayReader(char buf[], int offset, int length)5
6---------------------- CharArrayWriter --------------------------7// 1. 构造方法8public CharArrayWriter()9public CharArrayWriter(int initialSize)10 11// 2. 转换为字符数组或字符串12public char[] toCharArray()13public String toString() 14
下面是一个从文件字符流中读数据到字节数组输出流的示例:
251public static void main(String[] args) throws IOException {2 // 1. 将文件字节流适配为GB2312编码的字符流3 Reader reader = new InputStreamReader(new FileInputStream("hello.txt"), "GB2312");4 CharArrayWriter writer = null;5
6 try {7 // 2. 创建默认编码的字符数组输出流8 writer = new CharArrayWriter();9
10 // 3. 读取输入流数据写到输出流11 char[] cbuf = new char[1024];12 int charsRead = 0;13 while ((charsRead = reader.read(cbuf)) != -1) {14 writer.write(cbuf, 0, charsRead);15 }16
17 // 4. 将字符数组输出流转换为字符串18 System.out.println(writer.toString());19 } finally {20
21 // 5. 关闭流 22 reader.close();23 writer.close();24 }25}
5. StringReader/StringWriter
StringReader/StringWriter也继承自Reader/Writer, 表示字符串输入流和字符串输出流,即输入输出目的地为字符串。它与CharArrayReader/CharArrayWriter类似,只是输入源为String,输出目标为StringBuffer。实际上,String和StringBuffer内部是由char数组组成的,所以它们本质上是一样的。
141---------------------- StringReader --------------------------2// 1. 构造方法3public CharArrayReader(char buf[])4public CharArrayReader(char buf[], int offset, int length)5
6---------------------- StringWriter --------------------------7// 1. 构造方法8public StringWriter()9public StringWriter(int initialSize)10 11// 2. 其它方法12public String toString() // 转换为字符串13public StringBuffer getBuffer() // 获取内部的StringBuffer14
6. BufferedReader/BufferedWriter
BufferedReader/BufferedWriter是装饰类,直接继承自Reader/Writer,提供缓冲以及按行读写的功能。
171---------------------- BufferedReader --------------------------2// 1. 构造方法。装饰一个Reader,使其具有缓冲和按行读写的功能3public BufferedReader(Reader in)4public BufferedReader(Reader in, int sz) // sz-缓冲区大小,默认为81925 6// 2. 特殊方法7public String readLine() throws IOException // 读入1行字符(不包括换行符),当读到流结尾时,返回null 8
9 10---------------------- BufferedWriter --------------------------11 // 1. 构造方法。装饰一个Writer,使其具有缓冲和按行读写的功能12public BufferedWriter(Writer out)13public BufferedWriter(Writer out, int sz) // sz-缓冲区大小,默认为819214
15// 2. 特殊方法 16public void newLine() throws IOException // 输出平台特定的换行符,来自于line.separator属性17
注意:
通过
System.lineSeparator()也可以获取平台特定的换行符。FileReader/FileWriter是没有缓冲的,也不能按行读写, 因此一般应该在它们的外面包上对应的缓冲类。
BufferedReader/BufferedWriter是Reader/Writer的装饰,使用了装饰器模式。
下面是一个带缓冲的文件字符流的读写示例:
671public class Student {2 String name;3 int age;4 double score;5 6 // 无参构造、全参构造、Getter/Setter、toString7
8 public static void main(String[] args) throws IOException {9 List<Student> students = Arrays.asList(new Student[]{10 new Student("张三", 18, 80.9d),11 new Student("李四", 17, 67.5d)12 });13
14 writeStudents(students);15
16 List<Student> readStudents = readStudents();17 System.out.println(readStudents);18 }19
20
21 public static void writeStudents(List<Student> students) throws IOException {22 BufferedWriter writer = null;23 try {24 // 1. 装饰FileWriter,使其具有缓冲和按行读写的功能25 writer = new BufferedWriter(new FileWriter("students.txt"));26
27 // 2. 写字符流28 for (Student s : students) {29 writer.write(s.getName() + "," + s.getAge() + "," + s.getScore());30 writer.newLine(); // 写换行符31 }32 } finally {33 // 3. 关闭流34 if (writer != null) {35 writer.close();36 }37 }38 }39
40 public static List<Student> readStudents() throws IOException {41 List<Student> students = new ArrayList<>();42 BufferedReader reader = null;43 try {44 // 1. 装饰FileReader,使其具有缓冲和按行读写的功能45 reader = new BufferedReader(new FileReader("students.txt"));46
47 // 2. 按行读取字符流48 String line = reader.readLine();49 while (line != null) {50 String[] fields = line.split(",");51 Student s = new Student();52 s.setName(fields[0]);53 s.setAge(Integer.parseInt(fields[1]));54 s.setScore(Double.parseDouble(fields[2]));55 students.add(s);56 line = reader.readLine();57 }58 59 return students;60 } finally {61 // 3. 关闭流62 if (reader != null) {63 reader.close();64 }65 }66 }67}
7. PrintWriter/PrintStream
PrintWriter继承自Writer,是一个非常方便的类,可以直接指定文件名/File/OutputStream/Writer等作为构造参数,还可以指定编码类型,支持自动缓冲,可以自动将多种类型转换为字符串,在输出到文件时 ,可以优先选择该类。
211// 1. 构造函数2public PrintWriter(String fileName) throws FileNotFoundException 3public PrintWriter(String fileName, String csn) throws FileNotFoundException, UnsupportedEncodingException4public PrintWriter(File file) throws FileNotFoundException5public PrintWriter(File file, String csn) throws FileNotFoundException, UnsupportedEncodingException 6public PrintWriter(OutputStream out) 7public PrintWriter(OutputStream out, boolean autoFlush) // autoFlush-是否在调用println/printf/format方法的时候同步缓冲区,默认为false8public PrintWriter(Writer out)9public PrintWriter(Writer out, boolean autoFlush)10 11// 2. 输出数据12public void print(int i)13public void print(Object obj)14public void println() // 输出换行符15public void println(int x)16public void println(Object x) 17 18// 3. 类似C语言中的格式化输出19public PrintWriter printf(String format, Object ... args)20PrintWriter writer = writer.format("%.2f", 123.456f); // 保留小数点后2位21
注意:
如果以Writer为参数的构造方法,则PrintWriter就不会包装BufferedWriter了,其它类型参数则会。
下面是使用PrintWriter改造上面写学生信息的示例:
131public static void writeStudents2(List<Student> students) throws IOException {2 // 1. 创建PrintWriter3 PrintWriter writer = new PrintWriter("students.txt");4 try {5 // 2. 格式化输出到流6 for (Student s : students) {7 writer.println(s.getName() + "," + s.getAge() + "," + s.getScore());8 }9 } finally {10 // 3. 关闭流11 writer.close();12 }13}PrintStream继承自FilterOutputStream,属于字节流,但其功能与PrintWriter非常的相似。一些差异点如下:
PrintStream不支持Writer作为构造方法参数。
PrintStream在碰到换行符'\n'时自动刷新缓冲区。
write(int b)方法的实现不同,正常的字符流PrintWriter写一个字符(2个低字节),而PrintStream只写一个字节。
8. Scanner
Scanner是一个单独的类,它是一个简单的文本扫描器,能够从流中提取基本类型和字符串。
221// 1. 构造方法2public Scanner(String source)3public Scanner(Path source)4public Scanner(Path source, String charsetName) 5public Scanner(File source) throws FileNotFoundException 6public Scanner(File source, String charsetName) throws FileNotFoundException7public Scanner(InputStream source)8public Scanner(InputStream source, String charsetName)9public Scanner(Readable source)10public Scanner(ReadableByteChannel source)11public Scanner(ReadableByteChannel source, String charsetName)12 13// 2. 设置分隔符(Scanner工作时需要一个分隔符来将不同数据区分开来,默认是使用空白符)14public Scanner useDelimiter(Pattern pattern) 15public Scanner useDelimiter(String pattern)16 17// 3. 扫描数据18public String next() 19public String nextLine()20public int nextInt()21public float nextFloat() 22
使用Scanner改造上面解析每行学生信息的示例如下:
271public static List<Student> readStudents2() throws IOException {2 List<Student> students = new ArrayList<>();3
4 // 1. 装饰FileReader5 BufferedReader reader = new BufferedReader(new FileReader("students.txt"));6 try {7 // 2. 按行读取字符流8 String line = reader.readLine();9 while (line != null) {10 Student s = new Student();11
12 // 使用扫描器扫描每行数据,分隔符为,13 Scanner scanner = new Scanner(line).useDelimiter(",");14 s.setName(scanner.next()); 15 s.setAge(scanner.nextInt());16 s.setScore(scanner.nextDouble());17 students.add(s);18
19 line = reader.readLine();20 }21
22 return students;23 } finally {24 // 3. 关闭流25 reader.close();26 }27}
9. 标准流
操作系统在启动时通常会打开三个标准流:
System.in:标准输入流(InputStream),一般指键盘,可以和Scanner配合使用,从键盘输入数据。
System.out:标准输出流(PrintStream),一般指控制台,输出提示信息。
System.err:标准错误流(PrintStream),一般也是控制台,输出错误信息,如使用e.printStackTrace()打印异常信息。
71// 从标准输入流(键盘)提取数据2Scanner in = new Scanner(System.in);3int num = in.nextInt();4
5// 输出到标准输出流(控制台)6System.out.println(num)7 标准流可以重定向,如将标准输入流重定向到文件,从文件中接受输入,或将标准输出流(错误流)重定向到文件,将输出写到文件。
211public static void main(String[] args) throws UnsupportedEncodingException, FileNotFoundException {2 // 重定向标准输入流到字节数组3 System.setIn(new ByteArrayInputStream("hello".getBytes("UTF-8")));4
5 // 重定向标准输出流和标准错误流到文件6 System.setOut(new PrintStream("out.txt"));7 System.setErr(new PrintStream("err.txt"));8
9 try {10 // 从标准输入流(字节数组)扫描数据11 Scanner in = new Scanner(System.in);12
13 // 标准输出流输出数据(到文件)14 System.out.println(in.nextLine());15 System.out.println(in.nextLine()); // java.util.NoSuchElementException: No line found16 } catch (Exception e) {17 // 标准错误流输出数据(到文件)18 System.err.println(e.getMessage()); // No line found19 }20}21
标准输入输出流也是操作系统的重要协作机制,命令从标准输入接受参数,处理结果写到标准输出,这个标准输出可以连接到下一个命令作为标准输入,构成管道式的处理链条。
31# 查找一个日志文件access.log中127.0.0.1出现的行数2cat access.log | grep 127.0.0.1 | wc -l3
10. 字符流操作实用方法
821/**2* 拷贝字符流(Reader->Writer)3*/4public static void copy(final Reader input, final Writer output) throws IOException {5 char[] buf = new char[4096];6 int charsRead = 0;7 while ((charsRead = input.read(buf)) != -1) {8 output.write(buf, 0, charsRead);9 }10}11
12
13/**14* 读文件到字符串15*/16public static String readFileToString(final String fileName, final String encoding) throws IOException {17 BufferedReader reader = null;18 try {19 reader = new BufferedReader(new InputStreamReader(new FileInputStream(fileName), encoding));20 StringWriter writer = new StringWriter();21 copy(reader, writer);22 return writer.toString();23 } finally {24 if (reader != null) {25 reader.close();26 }27 }28}29
30/**31* 将字符串写入文件32*/33public static void writeStringToFile(final String fileName, final String data, final String encoding) throws IOException {34 Writer writer = null;35 try {36 writer = new OutputStreamWriter(new FileOutputStream(fileName), encoding);37 writer.write(data);38 } finally {39 if (writer != null) {40 writer.close();41 }42 }43}44
45/**46* 按行将多行数据写到文件47*/48public static void writeLines(final String fileName, final String encoding, final Collection<?> lines) throws IOException {49 PrintWriter writer = null;50 try {51 writer = new PrintWriter(fileName, encoding);52 for (Object line : lines) {53 writer.println(line);54 }55 } finally {56 if (writer != null) {57 writer.close();58 }59 }60}61
62/**63* 按行读取文件到List64*/65public static List<String> readLines(final String fileName, final String encoding) throws IOException {66 BufferedReader reader = null;67 try {68 reader = new BufferedReader(new InputStreamReader(new FileInputStream(fileName), encoding));69 List<String> list = new ArrayList<>();70 String line = reader.readLine();71 while (line != null) {72 list.add(line);73 line = reader.readLine();74 }75 return list;76 } finally {77 if (reader != null) {78 reader.close();79 }80 }81}82
第四节 常见文件类型处理
1. Properties
Properties文件一般用于配置程序的属性参数,每一行表示一个属性,属性是以等号(=)或冒号(:)分隔的键值对,如下例所示:
61# config.properties2db.host = 192.168.10.1003db.port : 33064db.username = zhangsan5db.password = mima12346
Java中有一个专门的类Properties来处理该类属性文件,它会自动忽略文件中的空行和注释行(#或!开头)以及分隔符前后的空格。
141// 1. 构造方法2public Properties()3public Properties(Properties defaults)4
5// 2. 从流中加载属性6public synchronized void load(InputStream inStream) 7
8// 3. 获取属性值9public String getProperty(String key) 10public String getProperty(String key, String defaultValue) // 没有找到配置的值,则返回默认值11public Set<String> stringPropertyNames() // 所有属性12 13// 4. 设置属性值14public Object setProperty(String key, String value)一个使用Properties加载属性文件并获取属性的示例如下:
111public static void main(String[] args) throws IOException {2 // 构造和加载属性3 Properties prop = new Properties();4 prop.load(new FileInputStream("config.properties"));5 6 // 获取属性和使用7 String host = prop.getProperty("db.host");8 int port = Integer.valueOf(prop.getProperty("db.port", "3306"));9 System.out.println(host + " " + port); // 192.168.10.100 330610}11
值得注意的是,Properties不能直接处理中文,在配置文件中,所有非ASCII字符需要使用Unicode编码,如name=老马需替换为name=\u8001\u9A6c。如果你使用IDE进行编辑,或许它会帮你自动转换,不过,你也可以使用JDK命令:native2ascii -encoding UTF-8 native.properties ascii.properties进行转换。
2. CSVFormat/CSVPrinter
CSV(Comma-Separated Values)文件一般用于表示表格类型的数据,每一行表示一条记录,记录包含多个字段,字段之间用逗号、制表符、冒号、分号等分隔。
21张三,18,80.92李四,17,67.5如果字段内容包含分隔符或换行符等特殊字符,主要有两种方式处理:
方式一:使用特殊符号如双引号(")将字段内容括起来,如果字段内容有",则用两个"表示。
方式二:使用转义字符如反斜杠()对特殊字符进行转义,如果字段内容有\,则用两个\表示,如
hello\, world \\ abc'n"老马"。
CSV文件需要处理转义字符、空格、null值以及注释等复杂情形,可以采用Apache Commons CSV库来解析CSV文件,导入依赖如下:
71<!-- https://commons.apache.org/proper/commons-csv/index.html -->2<dependency>3 <groupId>org.apache.commons</groupId>4 <artifactId>commons-csv</artifactId>5 <version>1.9.0</version>6</dependency>7 解析CSV文件主要依赖CSVFormat类,有一些预定义的格式,如CSVFormat.DEFAULT和CSVFormat.RFC4180等,也可以通过如下一些方法自定义CSVFormat对象。
251// 构造函数(静态方法)2public static CSVFormat newFormat(final char delimiter) // delimiter-字段之间的分隔符3
4// 自定义方法5public CSVFormat withDelimiter(final char delimiter) // 定义分隔符6public CSVFormat withQuote(final char quoteChar) // 定义引号符7public CSVFormat withEscape(final char escape) // 定义转义符8public CSVFormat withNullString(final String nullString) // 定义值为null的对象对应的字符串值9public CSVFormat withRecordSeparator(final char recordSeparator) // 定义记录之间的分隔符10public CSVFormat withIgnoreSurroundingSpaces(final boolean ignoreSurroundingSpaces) // 定义是否忽略字段之间的空白11
12// 解析CSV字符流13public CSVParser parse(final Reader in) throws IOException // 解析CSV字符流,返回CSVParser对象14
15// 使用 CSVParser 获取记录信息16public long getRecordNumber() // 记录数17public Iterator<CSVRecord> iterator() // 记录的迭代器(意味着CSVParser对象本身可以通过FOR-EACH遍历)18public List<CSVRecord> getRecords() throws IOException // 返回所有记录19
20// 使用 CSVRecord 获取字段信息21public int size() // 字段个数22public String get(final int i) // 根据字段列索引获取值,索引从0开始23public String get(final String name) // 根据列名获取值24public Iterator<String> iterator() // 字段的迭代器(意味着CSVRecord对象本身可以通过FOR-EACH遍历)25
写CSV文件,可以使用 CSVPrinter 类,它有许多打印相关的方法:
71// 构造方法 2public CSVPrinter(final Appendable appendable, final CSVFormat format) throws IOException appendable-可以使用Writer format-可以使用CSVFormat.DEFAULT3
4// 写CSV文件5public void printRecord(final Object... values) throws IOException // 输出一条记录,参数可变,每个参数是一个字段值6public void printRecord(final Iterable<?> values) throws IOException // 输出一条记录7
下面是一个读取和写入CSV文件的示例:
551public static void main(String[] args) throws IOException {2 // 自定义CSVFormat解析器3 // 字段之间用逗号分隔,使用双引号作为引号符,使用反斜杠作为转义符,将字符串N/A视为NULL值,并忽略字段之间的空格4 CSVFormat format = CSVFormat.newFormat(',').withQuote('"').withEscape('\\').withNullString("N/A").withIgnoreSurroundingSpaces(true);5
6 // 读CSV文件7 Reader reader = new BufferedReader(new InputStreamReader(new FileInputStream("student.csv"), Charset.forName("GBK")));8 try {9 // 解析CSV文件,并遍历CSVParser(实现了Iterable接口)10 for (CSVRecord record : format.parse(reader)) {11 int fieldNum = record.size(); // 字段数12 // 遍历所有字段13 for (int i = 0; i < fieldNum; i++) {14 System.out.print(record.get(i) + "|"); // 打印字段15 }16 System.out.println("\n---------------------------");17 }18 } finally {19 reader.close();20 }21
22 // 写CSV文件23 BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("student-out.csv")));24 CSVPrinter csvPrinter = new CSVPrinter(writer, CSVFormat.DEFAULT);25 csvPrinter.printRecord("张三", 12, '男');26 csvPrinter.printRecord("李四", 23, '女');27 csvPrinter.close();28}29
30测试文件内容如下:31张三,1532李四,1733错误空值,NULL34正确空值,N/A35方式一,"hello, world \ abc36""老马""",12.337方式二,hello\, world \\ abc\n"老马",12.338
39
40测试输出如下:41张三|15|42---------------------------43李四|17|44---------------------------45错误空值|NULL|46---------------------------47正确空值|null|48---------------------------49方式一|hello, world \ abc50"老马"|12.3|51---------------------------52方式二|hello, world \ abc53"老马"|12.3|54---------------------------55
3. Workbook(Excel)
Excel是广泛使用的表格文档格式,通常使用POI类库来进行处理,主要的类如下:
| 类名 | 说明 |
|---|---|
| Workbook | Excel文件(接口),HSSFWork-book和XSSFWorkbook实现类分别表示.xls文件和.xlsx文件 |
| Sheet | 工作表 |
| Row | 数据行 |
| Cell | 单元格 |
使用POI类库前先导入对应的依赖如下:
131<!-- HSSFWorkbook -->2<dependency>3 <groupId>org.apache.poi</groupId>4 <artifactId>poi</artifactId>5 <version>3.17</version>6</dependency>7<!-- XSSFWorkbook -->8<dependency>9 <groupId>org.apache.poi</groupId>10 <artifactId>poi-ooxml</artifactId>11 <version>3.17</version>12</dependency>13 下面是一个简单的Excel文件读取和写入示例:
611public class Student {2 String name;3 int age;4 double score;5
6 // 全参构造/Getter/Setter/ToString()7
8 public static void main(String[] args) throws Exception {9 List<Student> students = Arrays.asList(new Student[]{10 new Student("张三", 18, 80.9d),11 new Student("李四", 17, 67.5d)12 });13
14 writeToExcel(students, "student.xlsx");15 List<Student> studentList = readFromExcel("student.xlsx");16 System.out.println(studentList);17 }18
19
20 /**21 * 保存Student列表到Excel22 */23 public static void writeToExcel(List<Student> list, String file) throws IOException {24 // 构建Excel文件25 // Workbook wb = new HSSFWorkbook(); // xls文件26 Workbook wb = new XSSFWorkbook(); // xlsx文件27 Sheet sheet = wb.createSheet(); // 工作表28 for (int i = 0; i < list.size(); i++) {29 Student student = list.get(i);30 Row row = sheet.createRow(i); // 行31 row.createCell(0).setCellValue(student.getName()); // 单元格32 row.createCell(1).setCellValue(student.getAge());33 row.createCell(2).setCellValue(student.getScore());34 }35
36 // 写入到文件37 OutputStream out = new FileOutputStream(file);38 wb.write(out);39 out.close();40 wb.close();41 }42
43 /**44 * 读Excel文件45 */46 public static List<Student> readFromExcel(String file) throws Exception {47 Workbook wb = WorkbookFactory.create(new File(file));48 List<Student> list = new ArrayList<>();49 for (Sheet sheet : wb) { // 遍历所有工作表50 for (Row row : sheet) { // 遍历所有行51 String name = row.getCell(0).getStringCellValue(); // 取单元格值52 int age = (int) row.getCell(1).getNumericCellValue();53 double score = row.getCell(2).getNumericCellValue();54 list.add(new Student(name, age, score));55 }56 }57 wb.close();58 return list;59 }60}61
4. Jsoup(HTML)
Jsoup是一种常用的HTML分析器,Maven依赖如下:
61<dependency>2 <groupId>org.jsoup</groupId>3 <artifactId>jsoup</artifactId>4 <version>1.10.2</version>5</dependency>6
下面是使用Jsoup解析URL的示例:
171public static void main(String[] args) throws Exception {2 // 解析本地HTML文件3 // Document doc = Jsoup.parse(new File("articles.html"), "UTF-8");4
5 // 从URL解析6 String url = "http://www.cnblogs.com/swiftma/p/5631311.html";7 Document doc = Jsoup.connect(url).get();8
9 // 使用”CSS选择器“选择元素并遍历10 Elements elements = doc.select("#cnblogs_post_body p a");11 for (Element e : elements) {12 String title = e.text(); // 获取标签体13 String href = e.attr("href"); // href属性14 System.out.println(title + ", " + href);15 }16}17
5. GZIPOutputStream/GZIPInputStream
Java内置了gzip和zip两种压缩格式的支持,其中gzip只能压缩一个文件,而zip文件中可以包含多个文件。
压缩和解压gzip文件使用GZIPOutputStream和GZIPInputStream装饰类,它们分别继承自DeflaterOutputStream(FilterOutputStream)和InflaterInputStream(FilterInputStream)。
651public static void main(String[] args) throws Exception {2 gzip("D:\\mybatis-sql.log");3 gunzip("D:\\mybatis-sql.log.gz", "D:\\mybatis-sql2.log");4}5
6/**7 * gzip压缩8 */9public static void gzip(String fileName) throws IOException {10 String gzipFileName = fileName + ".gz";11 InputStream in = null;12 OutputStream out = null;13
14 try {15 // 正常的输入流、被GZIPOutputStream包装的输出流16 in = new BufferedInputStream(new FileInputStream(fileName));17 out = new GZIPOutputStream(new BufferedOutputStream(new FileOutputStream(gzipFileName)));18
19 // 拷贝字节流20 copy(in, out);21 } finally {22 if (out != null) {23 out.close();24 }25 if (in != null) {26 in.close();27 }28 }29}30
31/**32 * gzip解压33 */34public static void gunzip(String gzipFileName, String unzipFileName) throws IOException {35 InputStream in = null;36 OutputStream out = null;37
38 try {39 // 被GZIPInputStream包装的输入流、正常的输出流40 in = new GZIPInputStream(new BufferedInputStream(new FileInputStream(gzipFileName)));41 out = new BufferedOutputStream(new FileOutputStream(unzipFileName));42
43 // 拷贝字节流44 copy(in, out);45 } finally {46 if (out != null) {47 out.close();48 }49 if (in != null) {50 in.close();51 }52 }53}54
55/**56 * 拷贝字节流57 */58public static void copy(InputStream input, OutputStream output) throws IOException {59 byte[] buf = new byte[4096];60 int bytesRead = 0;61 while ((bytesRead = input.read(buf)) != -1) {62 output.write(buf, 0, bytesRead);63 }64}65
6. ZipOutputStream/ZipInputStream
压缩和解压zip文件使用ZIPOutputStream和ZIPInputStream装饰类,也继承自DeflaterOutputStream(FilterOutputStream)和InflaterInputStream(FilterInputStream),但是使用起来稍微复杂些。
1181public static void main(String[] args) throws Exception {2 zip(new File("D:\\var\\log\\fs\\FS-FMS\\8088"), new File("D:\\var\\log\\fs\\FS-FMS\\8888.zip"));3 unzip(new File("D:\\var\\log\\fs\\FS-FMS\\8888.zip"), "D:\\var\\log\\fs\\FS-FMS\\out");4}5
6/**7 * zip压缩目录8 */9public static void zip(File inFile, File zipFile) throws IOException {10 // 被ZipOutputStream装饰的输出流(zip文件)11 ZipOutputStream out = new ZipOutputStream(new BufferedOutputStream(new FileOutputStream(zipFile)));12
13 try {14 if (!inFile.exists()) {15 throw new FileNotFoundException(inFile.getAbsolutePath());16 }17
18 // 获取父目录19 inFile = inFile.getCanonicalFile();20 String rootPath = inFile.getParent(); // 父目录,用于计算每个文件的相对路径21 if (!rootPath.endsWith(File.separator)) {22 rootPath += File.separator;23 }24
25 // 添加根目录到压缩文件26 addFileToZipOut(inFile, out, rootPath);27 } finally {28 out.close();29 }30}31
32/**33 * 添加当前文件(目录)到压缩文件34 */35private static void addFileToZipOut(File file, ZipOutputStream out, String rootPath) throws IOException {36 // 获取相对路径37 String relativePath = file.getCanonicalPath().substring(rootPath.length());38
39 if (file.isFile()) {40 // 在写入每一个文件前,必须要先调用该方法,表示准备写入一个压缩条目ZipEntry41 out.putNextEntry(new ZipEntry(relativePath)); // 每个压缩条目有个名称,这个名称是压缩文件的相对路径42
43 // 拷贝当前文件到压缩文件44 InputStream in = new BufferedInputStream(new FileInputStream(file));45 try {46 copy(in, out);47 } finally {48 in.close();49 }50 } else {51 // 在写入每一个目录前,也必须要先调用该方法,表示准备写入一个压缩条目ZipEntry52 // 注意:这里不能用File.separator,因为解压时写死的以/结尾作为目录,而windows平台是\53 out.putNextEntry(new ZipEntry(relativePath + "/")); // 每个压缩条目有个名称,这个名称是压缩文件的相对路径,如果名称以字符'/'结尾,表示目录54
55 // 循环递归处理每个文件56 for (File f : file.listFiles()) {57 addFileToZipOut(f, out, rootPath);58 }59 }60}61
62public static void unzip(File zipFile, String destDir) throws IOException {63 // 被 ZipInputStream 装饰的输入流(zip文件)64 ZipInputStream zin = new ZipInputStream(new BufferedInputStream(new FileInputStream(zipFile)));65
66 // 目标目录必须以目录分隔符结尾67 if (!destDir.endsWith(File.separator)) {68 destDir += File.separator;69 }70
71 try {72 // 循环处理每个压缩条目73 ZipEntry entry = zin.getNextEntry();74 while (entry != null) {75 extractZipEntry(entry, zin, destDir);76 entry = zin.getNextEntry();77 }78 } finally {79 zin.close();80 }81}82
83/**84 * 提取ZIP压缩条目85 */86private static void extractZipEntry(ZipEntry entry, ZipInputStream zin, String destDir) throws IOException {87 if (!entry.isDirectory()) {88 // 创建文件的父目录89 File parent = new File(destDir + entry.getName()).getParentFile();90 if (!parent.exists()) {91 parent.mkdirs();92 }93
94 // 目标文件95 OutputStream entryOut = new BufferedOutputStream(new FileOutputStream(destDir + entry.getName()));96 try {97 // 拷贝字节流98 copy(zin, entryOut);99 } finally {100 entryOut.close();101 }102 } else {103 // 创建目录及其父目录104 new File(destDir + entry.getName()).mkdirs();105 }106}107
108/**109 * 拷贝字节流110 */111public static void copy(InputStream input, OutputStream output) throws IOException {112 byte[] buf = new byte[4096];113 int bytesRead = 0;114 while ((bytesRead = input.read(buf)) != -1) {115 output.write(buf, 0, bytesRead);116 }117}118
第五节 扩展:关于JDK序列化
1. JDK序列化简介
序列化就是将对象转化为字符流/字节流, 反序列化就是将字符流/字节流转化为对象,主要有两个用途:一个是对象持久化;另一个是跨网络的数据交换和远程过程调用。
在标准JDK中,通过ObjectInputStream和`ObjectOutputStream流提供了基于java.io.Serializable接口的序列化机制。 它有很多优点,使用简单,可自动处理对象引用和循环引用,也可以方便地进行定制,处理版本问题等,但它也有一些重要的局限性:
序列化格式是一种私有格式,是一种 Java 特有的技术,不能被其他语言识别,不能实现跨语言的数据交换 。
序列化字节中保存了很多描述信息,使得序列化格式比较大,并且是二进制的,不方便查看和修改。
使用反射分析遍历对象结构,性能比较低 (ASM)。
由于这些局限性,在跨语言的数据交换格式中,经常采用XML或JSON格式,它们清晰易读,各种语言基本都支持,缺点是性能和序列化大小。在性能和序列化大小敏感的领域,往往会采用更为精简高效的二进制方式,如ProtoBuf、Thrift、MessagePack等 。
注意:
如果尝试序列化未实现Serializable接口的对象,那么将会抛出
java.io.NotSerializableException。如果 a、b 两个对象都引用同一个对象 c ,序列化后c 只会保存一份 , 并且反序列化后依然指向相同对象。
如果 a 、 b 两个对象有循环引用,即 a 引用了 b , 而 b 也引用了 a,反序列化后依然 可以保持引用关系。
2. 配置JDK序列化
默认的序列化机制将对象中的所有字段保存和恢复,但某些字段信息,如对象的创建时间,默认hashcode()返回值等并不需要保存,我们可以将字段声明为 transient,则默认的序列化机制将会忽略它。如 LinkedList 中的这些字段:
31transient int size = 0;2transient Node<E> first;3transient Node<E> last;之后,我们可以在类中定义 writeObject/readObject 方法来自己保存该字段。
61// 自定义序列化(注意:方法声明要一致)2private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException3
4// 自定义反序列化(注意:方法声明要一致)5private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException6 如 LinkedList 的序列化和反序列化代码如下:
251// 序列化2private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {3 // 调用默认的序列化机制,保存所有非 transient 的字段,以及一些元数据描述等隐藏信息4 s.defaultWriteObject();5
6 // 写元素个数7 s.writeInt(size);8
9 // 循环写每个元素10 for (Node<E> x = first; x != null; x = x.next)11 s.writeObject(x.item);12}13
14// 反序列化15private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {16 // 调用默认的序列化机制17 s.defaultReadObject();18
19 // 读元素个数20 int size = s.readInt();21
22 // 循环读入每个元素23 for (int i = 0; i < size; i++)24 linkLast((E) s.readObject());25}
3. 关于类的版本
默认情况下,Java根据类中一系列的信息自动生成一个版本号, 如果类的定义发生了变化 , 版本号就会变化,如果反序列化时的版本号不一致,则会抛出java.io.InvalidClassException。
我们可以手动在类中添加如下静态变量来标识类的版本,而非由Java自动生成,以便更好地控制序列化的版本和节省性能。
31// 手动指定当前类的序列化版本2private static final long serialVersionUID = 1L; 3
如果版本号一致,但实际的字段不匹配,Java 会分情况自动进行处理 , 以尽量保持兼容性。
字段删掉了: 即流中有该字段, 而类定义中没有, 该字段会被忽略 ;
新增了字段: 即类定义中有, 而流中没有, 该字段会被设为默认值 ;
字段类型变了: 对于同名的字段, 类型变了, 会抛出 InvalidClassException。
第07章_注解
第一节 注解简介
1. 什么是注解?
注解就是给程序添加一些信息,用字符@开头,这些信息用于修饰它后面紧挨着的其他代码元素,比如类、接口、字段、方法、方法中的参数、构造方法等,注解可以被编译器、程序运行时、和其他工具使用,用于增强或修改程序行为等。
2. 注解的本质
注解本质上就是一个接口,该接口默认继承Annotation接口,我们使用javap将生成的注解class文件反编译后,可以看到如下内容:
101// Annotation接口2public interface Annotation {3 boolean equals(Object obj);4 int hashCode();5 String toString();6 Class<? extends Annotation> annotationType(); // 返回真正的注解类型7}8
9// MyAnno接口继承自Annotation10public interface MyAnno extends java.lang.annotation.Annotation {}
3. 元注解
元注解是一种用于修饰注解的注解,常用的元注解如下:
1) @Target
@Target表示注解的目标,取值为一个或多个ElementType枚举值。如果没有声明@Target,默认为适用于所有类型。
121public enum ElementType {2 TYPE, // 类,接口、注解、枚举3 FIELD, // 字段、枚举常量4 METHOD, // 方法5 PARAMETER, // 方法中的参数6 CONSTRUCTOR, // 构造方法7 LOCAL_VARIABLE, // 本地变量8 ANNOTATION_TYPE, // 注解类型 9 PACKAGE, // 包10 TYPE_PARAMETER, // 类型参数11 TYPE_USE12}
2) @Retention
@Retention表示注解信息保留到什么时候,取值为一个RetentionPolicy枚举值。如果没有声明@Retention,默认为CLASS。
51public enum RetentionPolicy {2 SOURCE, // 只在源代码中保留,编译器将代码编译为字节码文件后就会丢掉3 CLASS, // 保留到字节码文件中,但Java虚拟机将class文件加载到内存时不一定会在内存中保留4 RUNTIME // 一直保留到运行时5}
3) @Inherited
@Inherited表示注解将会被子类继承。如下示例中,Child类并没有直接声明Test注解,但依然检测其存在。
281public class InheritDemo {2 // 定义一个Anno01注解,并添加@Inherited元注解3 4 (RetentionPolicy.RUNTIME)5 static @interface Anno01 {6 }7
8 // 定义一个Anno02注解,不添加@Inherited元注解9 (RetentionPolicy.RUNTIME)10 static @interface Anno02 {11 }12
13 // Base类同时添加@Anno01和@Anno02注解14 15 16 static class Base {17 }18
19 // Child类继承Base类,预期应继承父类中添加了@Inherited的注解20 static class Child extends Base {21 }22
23 // 验证24 public static void main(String[] args) {25 System.out.println(Child.class.isAnnotationPresent(Anno01.class)); // true26 System.out.println(Child.class.isAnnotationPresent(Anno02.class)); // false27 }28}
4) @Documented
@Documented表示将注解信息包含到Javadoc中。
5) Repeatable
@Repeatable表示可以在同一个地方多次应用该注解。
181(RetentionPolicy.RUNTIME)3(ElementType.METHOD)4(Select.List.class) // 配置可重复使用,并指定对应的List注解5public @interface Select {6 String[] value();7 String databaseId() default "";8 boolean affectData() default false;9
10 // 对应的List注解11 12 (RetentionPolicy.RUNTIME)13 (ElementType.METHOD)14 @interface List {15 Select[] value();16 }17
18}
4. 内置注解
1) @FunctionInterface
可修饰接口,用于检查被标注的接口是否为函数式接口(只有一个抽象方法的接口)。
51(RetentionPolicy.RUNTIME)3(ElementType.TYPE)4public @interface FunctionalInterface {5}
2) @Override
可修饰方法,表示该方法是“重写”方法,可以减少编程错误(如父类方法名修改后,若子类方法名忘记修改,存在注解时将报错)。
41(ElementType.METHOD)2(RetentionPolicy.SOURCE)3public @interface Override {4}
3) @Deprecated
可修饰类、方法、字段、参数等,表示对应的代码已经过时了,程序员不应该使用它,不过,它是一种警告,而不是强制性的。
51(RetentionPolicy.RUNTIME)3(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})4public @interface Deprecated {5}
4) @SuppressWarnings
可修饰类或方法等,用于压制Java的编译警告,通过必填参数设置压制的类型。
51({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})2(RetentionPolicy.SOURCE)3public @interface SuppressWarnings {4 String[] value();5}
第二节 自定义注解
1. 注解格式
注解的定义和接口类似,格式如下:
91// 完整格式2元注解3修饰符 @interface 注解名称{4 参数列表;5}6
7// 最简示例8public @interface Anno01 {9}
2. 注解参数
注解本质上就是一个接口,定义注解参数即在接口中定义抽象方法,其中方法名表示参数名,返回值类型表示参数的类型。
171public @interface Anno02 {2 int value(); // 基本类型3
4 String name() default "张三"; // String类型,并指定默认值5
6 Class<?> cls(); // Class类型7
8 Size size(); // 枚举类型9
10 Anno01 anno01(); // 注解类型11
12 String[] strs(); // 数组类型13}14
15enum Size {16 SMALL, MEDIUM, LARGE17}注意:
参数的类型必须为如下类型:基本类型(不包括包装类型)、String、Class、枚举、注解,以及这些类型的数组。
参数可以通过default关键字指定默认值,默认值必须为一个常量,不能为null。
如提供了参数,但未指定默认值,则必须在使用注解时提供具体的值(不能为null)。
第三节 使用和解析注解
1. 使用注解
查看元注解@Target的参数值,明确注解可使用的位置,然后在目标位置添加注解并填充参数。
51({"deprecation","unused"})2public static void main(String[] args) {3 Date date = new Date(2017, 4, 12);4 int year = date.getYear(); // 方法过时警告5}当只有一个参数,且名称为value时,提供参数值时可以省略"value="。
11({"deprecation","unused"})数组赋值时,值使用{}包裹,如果数组中只有一个值,则{}可以省略。
11("unchecked")
2. 解析注解
注解只是对程序的标识,创建注解后,我们应同时提供处理这些标识的其它代码,以使添加的注解生效。我们主要考虑@Retention为RetentionPolicy.RUNTIME的注解,利用反射机制在运行时进行查看和利用这些信息。
51public Annotation[] getAnnotations() // 获取所有的注解2public Annotation[] getDeclaredAnnotations() // 获取所有本元素上直接声明的注解,忽略inherited来的3public <A extends Annotation> A getAnnotation(Class<A> annotationClass) // 获取指定类型的注解,没有返回null4public boolean isAnnotationPresent(Class<? extends Annotation> annotationClass) // 判断是否有指定类型的注解5public Annotation[][] getParameterAnnotations() // 获取参数的注解(仅适用Method和Contructor)一个简单的示例如下:
471public class MethodAnnotations {2 // 定义QueryParam注解3 (ElementType.PARAMETER)4 (RetentionPolicy.RUNTIME)5 static @interface QueryParam {6 String value();7 }8 9 // 定义DefaultValue注解10 (ElementType.PARAMETER)11 (RetentionPolicy.RUNTIME)12 static @interface DefaultValue {13 String value() default "";14 }15 16 // 定义hello方法,参数使用了注解17 public void hello(("action") String action,18 ("sort") ("asc") String sort){19 // ...20 }21 22 // 解析注解23 public static void main(String[] args) throws Exception {24 // 获取Class->Method->ParameterAnnotations25 Class<?> cls = MethodAnnotations.class;26 Method method = cls.getMethod("hello", new Class[]{String.class, String.class});27 Annotation[][] annts = method.getParameterAnnotations();28 29 // 遍历二维数组,解析注解30 for(int i=0; i<annts.length; i++){31 System.out.println("annotations for paramter " + (i+1));32 Annotation[] anntArr = annts[i];33 // 处理第i个参数34 for(Annotation annt : anntArr){35 if(annt instanceof QueryParam){36 // 处理第i个参数的QueryParam注解37 QueryParam qp = (QueryParam)annt;38 System.out.println(qp.annotationType().getSimpleName()+":"+ qp.value());39 }else if(annt instanceof DefaultValue){40 // 处理第i个参数的DefaultValue注解41 DefaultValue dv = (DefaultValue)annt;42 System.out.println(dv.annotationType().getSimpleName()+":"+ dv.value());43 }44 }45 }46 }47}
第四节 注解应用案例
1. 定制序列化
911// @Label用于定制输出字段的名称2(RUNTIME)3(FIELD)4public @interface Label {5 String value() default "";6}7
8// @Format用于定义日期类型的输出格式9(RUNTIME)10(FIELD)11public @interface Format {12 String pattern() default "yyyy-MM-dd HH:mm:ss";13 String timezone() default "GMT+8";14}15
16// 序列化17public static String format(Object obj) {18 StringBuilder sb = new StringBuilder();19 20 try {21 // 获取Class22 Class<?> cls = obj.getClass();23 24 // 获取当前类所有字段25 for (Field f : cls.getDeclaredFields()) {26 if (!f.isAccessible()) {27 f.setAccessible(true);28 }29 // 解析属性名称 优先使用@Label注解配置的名称30 Label label = f.getAnnotation(Label.class);31 String name = label != null ? label.value() : f.getName();32 // 获取属性值33 Object value = f.get(obj);34 if (value != null && f.getType() == Date.class) {35 // 解析日期字段36 value = formatDate(f, value);37 }38 sb.append(name + ":" + value + "\n");39 }40 return sb.toString();41 } catch (IllegalAccessException e) {42 throw new RuntimeException(e);43 }44}45
46// 解析日期字段47private static Object formatDate(Field f, Object value) {48 // 获取@Format注解配置的日期格式49 Format format = f.getAnnotation(Format.class);50 if (format != null) {51 // 序列化为指定格式52 SimpleDateFormat sdf = new SimpleDateFormat(format.pattern());53 sdf.setTimeZone(TimeZone.getTimeZone(format.timezone()));54 return sdf.format(value);55 }56 return value;57}58
59// 目标类60static class Student {61 ("姓名")62 String name;63 64 ("出生日期")65 (pattern="yyyy/MM/dd")66 Date born;67 68 ("分数")69 double score;70
71 public Student() {72 }73
74 public Student(String name, Date born, Double score) {75 super();76 this.name = name;77 this.born = born;78 this.score = score;79 }80
81 82 public String toString() {83 return "Student [name=" + name + ", born=" + born + ", score=" + score + "]";84 }85}86
87// 测试88SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");89Student zhangsan = new Student("张三", sdf.parse("1990-12-12"), 80.9d);90System.out.println(SimpleFormatter.format(zhangsan)); // 姓名:张三 出生日期:1990/12/12 分数:80.991
2.DI容器
501// 修饰类中字段,表达依赖关系2(RUNTIME)3(FIELD)4public @interface SimpleInject {5}6
7// 目标类8public class ServiceA {9 // 使用注解注入10 11 ServiceB b;12 13 public void callB(){14 b.action();15 }16}17
18public class ServiceB {19 public void action(){20 System.out.println("I'm B");21 }22}23
24// 从容器获取对象并处理依赖关系25public static <T> T getInstance(Class<T> cls) {26 try {27 // 创建对象28 T obj = cls.newInstance();29 30 // 遍历所有字段31 Field[] fields = cls.getDeclaredFields();32 for (Field f : fields) {33 // 如果被SimpleInject注解,则处理依赖关系34 if (f.isAnnotationPresent(SimpleInject.class)) {35 if (!f.isAccessible()) {36 f.setAccessible(true);37 }38 Class<?> fieldCls = f.getType();39 f.set(obj, getInstance(fieldCls)); // 依赖注入(这里暂不考虑循环依赖问题)40 }41 }42 return obj;43 } catch (Exception e) {44 throw new RuntimeException(e);45 }46}47
48// 测试49ServiceA a = SimpleContainer.getInstance(ServiceA.class);50a.callB();
3. DI容器-支持单例
611// 修饰类,表示类型是单例2(RUNTIME)3(TYPE)4public @interface SimpleSingleton {5}6
7// 目标类8public class ServiceB {10 public void action(){11 System.out.println("I'm B");12 }13}14
15// 单例对象缓存16private static Map<Class<?>, Object> instances = new ConcurrentHashMap<>();17
18// 从容器获取对象并处理依赖关系(支持单例)19public static <T> T getInstance(Class<T> cls) {20 try {21 // 判断是否为单例,如果不是,则创建新实例返回22 boolean singleton = cls.isAnnotationPresent(SimpleSingleton.class);23 if (!singleton) {24 return createInstance(cls);25 }26 27 // 是单例,尝试从缓存获取对象28 Object obj = instances.get(cls);29 if (obj != null) {30 return (T) obj;31 }32 33 // 缓存没有,则创建单例对象,并存入缓存34 synchronized (cls) {35 obj = instances.get(cls);36 if (obj == null) {37 obj = createInstance(cls);38 instances.put(cls, obj);39 }40 }41 return (T) obj;42 } catch (Exception e) {43 throw new RuntimeException(e);44 }45}46
47// 创建对象,和第一版的getInstance类似48private static <T> T createInstance(Class<T> cls) throws Exception {49 T obj = cls.newInstance();50 Field[] fields = cls.getDeclaredFields();51 for (Field f : fields) {52 if (f.isAnnotationPresent(SimpleInject.class)) {53 if (!f.isAccessible()) {54 f.setAccessible(true);55 }56 Class<?> fieldCls = f.getType();57 f.set(obj, getInstance(fieldCls));58 }59 }60 return obj;61}
4. 简单测试框架
841// Check注解2(RetentionPolicy.RUNTIME)3(ElementType.METHOD)4public @interface Check {5}6
7// 目标类8public class Calculator {9 //加法10 11 public void add(){12 String str = null;13 str.toString();14 System.out.println("1 + 0 =" + (1 + 0));15 }16 //减法17 18 public void sub(){19 System.out.println("1 - 0 =" + (1 - 0));20 }21 //乘法22 23 public void mul(){24 System.out.println("1 * 0 =" + (1 * 0));25 }26 //除法27 28 public void div(){29 System.out.println("1 / 0 =" + (1 / 0));30 }31
32 public void show(){33 System.out.println("永无bug...");34 }35}36
37/**38 * 简单的测试框架39 * 执行@Check修饰的方法并记录异常40 */41public class TestCheck {42
43 public static void main(String[] args) throws IOException {44 //1.创建计算器对象45 Calculator c = new Calculator();46 //2.获取字节码文件对象47 Class cls = c.getClass();48 //3.获取所有方法49 Method[] methods = cls.getMethods();50
51 int number = 0;//出现异常的次数52 BufferedWriter bw = new BufferedWriter(new FileWriter("bug.txt"));53
54 for (Method method : methods) {55 //4.判断方法上是否有Check注解56 if(method.isAnnotationPresent(Check.class)){57 //5.有,执行58 try {59 method.invoke(c);60 } catch (Exception e) {61 //6.捕获异常62
63 //记录到文件中64 number ++;65
66 bw.write(method.getName()+ " 方法出异常了");67 bw.newLine();68 bw.write("异常的名称:" + e.getCause().getClass().getSimpleName());69 bw.newLine();70 bw.write("异常的原因:"+e.getCause().getMessage());71 bw.newLine();72 bw.write("--------------------------");73 bw.newLine();74
75 }76 }77 }78
79 bw.write("本次测试一共出现 "+number+" 次异常");80 bw.flush();81 bw.close();82 }83}84
第08章_反射
第一节 反射的概念
1. 什么是反射?
一般来说,在操作某个数据的时候,我们都是知道并且依赖于数据的类型的,并且编译器也是根据其类型,进行代码的检查和编译。如:
根据类型使用new创建对象。
根据类型定义变量,类型可能是基本类型、类、接口或数组。
将特定类型的对象传递给方法。
根据类型访问对象的属性,调用对象的方法等。
但是反射不一样,它是在运行时(而非编译时)动态获取类型的信息,如接口信息、成员信息、方法信息、构造方法信息等。这些信息使用Class<T>类进行封装,获取Class类后就可以创建对象、访问和修改成员、调用方法等。
2. 获取Class类
在Java中,每个已加载的类在内存都有一份类信息,使用Class类进行封装,每个对象都有指向它所属类信息的引用。获取方法如下:
251// 1. 类名方式2// 如果类已通过ClassLoader加载完成,但没有该类的具体对象,可以用类名获取该类的Class对象,这种方式一般用于参数的传递。3Class<Date> dateClass = Date.class;4Class<Comparable> comparableClass = Comparable.class; // 接口5Class<Month> monthClass = Month.class; // 枚举6
7// 2. 对象方式8// 如果有具体的对象,直接引用Object类中定义的 final native Class<?> getClass() 方法获取:9Class<?> objClass = new Object().getClass(); // 普通对象10Class<Map.Entry> entryClass = Map.Entry.class; // 内部类对象 interface java.util.Map$Entry11Class<? extends Comparable> comparableClass = ((Comparable<String>) o -> 0).getClass(); // lambda对象 class com.huangyuanxin.notes.javabase.Test01$$Lambda$1/80456417612
13// 3. Class.forName方式14// 如果类尚在硬盘中,未读入内存,则使用全类名将字节码文件加载进内存,返回Class对象15// 这种方式多用于配置文件,将类名定义在配置文件中,然后读取文件,加载类。16try {17 Class<?> hashMapClass = Class.forName("java.util.HashMap");18} catch (ClassNotFoundException exception) {19 exception.printStackTrace();20}21
22// 4. 类加载器方式23// 注意:这种方式不会执行静态代码块等类初始化代码。24ClassLoader.getSystemClassLoader().loadClass("cn.javaguide.TargetObject")25
特殊的,基本类型没有getClass()方法,但也都有对应的Class对象,Class的类型参数为对应的包装类型:
21Class<Integer> intClass = int.class; // int 泛型具体化类型为Integer2Class<? extends Integer> integerClass = new Integer(0).getClass(); // class java.lang.Integervoid作为特殊的返回类型,也有对应的Class:
11Class<Void> voidClass = void.class; // void对于数组,每种类型及每个维度都有对应数组类型的Class对象:
41Class<? extends String[]> arrClass1 = new String[10].getClass(); // class [Ljava.lang.String;2Class<? extends String[][]> arrClass2 = new String[10][20].getClass(); // class [[Ljava.lang.String;3Class<? extends int[]> arrClass3 = new int[10].getClass(); // class [I4Class<? extends int[][]> arrClass4 = new int[3][2].getClass(); // class [[I有了Class对象后,我们就可以了解到关于类型的很多信息,并基于这些信息采取一些行动,下面会分组进行介绍。
注意:
同一个字节码文件(*.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的Class对象都是同一个。
3.Class的种类
Class对象代表的类型既可以是普通的类,也可以是内部类,还可以是基本类型、数组等,可以通过以下方法进行区分 :
81public native boolean isArray() // 是否是数组2public native boolean isPrimitive() // 是否是基本类型3public native boolean isInterface() // 是否是接口4public boolean isEnum() // 是否是枚举5public boolean isAnnotation() // 是否是注解6public boolean isAnonymousClass() // 是否是匿名内部类7public boolean isMemberClass() // 是否是成员类,成员类定义在方法外,不是匿名类8public boolean isLocalClass() // 是否是本地类,本地类定义在方法内,不是匿名类
4. 慎用反射
反射虽然是灵活的,但一般情况下,并不是我们优先建议的,主要原因是:
反射更容易出现运行时错误。使用显式的类和接口,编译器能帮我们做类型检查,减少错误,但使用反射,类型是运行时才知道的,编译器无能为力。
反射的性能要低一些。在访问字段、调用方法前,反射先要查找对应的Field/Method,性能要慢一些。
简单的说,如果能用接口实现同样的灵活性,就不要使用反射。
另外,反射也不是万能的,有些信息无法通过反射获取,如类字段的顺序,方法的参数名称(需要手动在编译时开启 -parameters 参数)等,有些信息即使反射获得后也不能使用,如Unsafe.getUnsafe()方法,在业务代码中是不能调用的。
第二节 反射信息
1. 类信息
Class有如下方法,可以获取与类名称有关的信息:
191// 类的名称2public String getName() // 包名.类名(常用)3public String getSimpleName() // 不带包名的类名4public String getCanonicalName() // 返回的名字更为友好5public Package getPackage() // 包信息 package java.util, Java Platform API Specification, version 1.86 7// 类上的修饰符8public native int getModifiers() // 获取修饰符,返回值可通过Modifier类进行解读9 10// 父类和接口11public native Class<? super T> getSuperclass() // 获取父类,如果当前为Object,则父类为 null12public native Class<?>[] getInterfaces() // 对于类,为自己声明实现的所有接口;对于接口,为直接扩展的接口,不包括通过父类继承的13
14// 类的注解15public Annotation[] getDeclaredAnnotations() // 自己声明的注解16public Annotation[] getAnnotations() // 所有的注解,包括继承得到的17public <A extends Annotation> A getAnnotation(Class<A> annotationclass) // 获取指定类型的注解,包括继承得到18public boolean isAnnotationPresent(Class<? extends Annotation> annotationclass) // 检查指定类型的注解,包括继承得到19 类名称之间的不同可参考如下表格:

关于数组类型getName()返回值的说明:
格式为:
数组维度+数据类型,其中数组维度用[表示,有几个[表示是几维数组。数据类型可以是基本类型,有:boolean(Z), byte(B), char(C), short(S), int(I), long(J), float(F), double(D)。
数据类型也可以是引用类型(类或接口等),用
L+全类名+;表示。
2. 类字段信息
类中定义的静态变量和实例变量都被称为字段,字段信息用Field类封装,可通过Class类的如下方法获取:
41public Field[] getFields() // 返回所有的public字段,包括其父类的,如果没有字段,返回空数组2public Field[] getDeclaredFields() // 返回本类声明的所有字段,包括非public的,但不包括父类的3public Field getField(String name) // 返回本类或父类中指定名称的public字段,找不到抛出异常NoSuchFieldException4public Field getDeclaredField(String name) // 返回本类中声明的指定名称的字段,找不到抛出异常NoSuchFieldException获取Field类对象后,即可通过其方法获取字段信息及修改字段内容。
201// 获取字段信息2public String getName() //获取字段的名称3public Class<?> getType() //返回字段的类型4public int getModifiers() //返回字段的修饰符5public boolean isAccessible() //判断当前程序是否有该字段的访问权限6
7// 读写字段8public void setAccessible(boolean flag) //设为true表示忽略Java的访问检查机制,以允许读写非public的字段9public Object get(Object obj) //获取指定对象obj中该字段的值10public void set(Object obj, Object value) //将指定对象obj中该字段的值设为value11
12//以基本类型操作字段13public void setBoolean(Object obj, boolean z) 14public boolean getBoolean(Object obj)15public void setDouble(Object obj, double d)16public double getDouble(Object obj)17
18//获取字段的注解信息19public Annotation[] getDeclaredAnnotations()20public <T extends Annotation> T getAnnotation(Class<T> annotationClass) 注意:
对于静态变量,get/set方法的obj参数直接传null即可。
private字段不允许直接调用get/set方法,需要先setAccessible(true)关闭Java的检查机制,否则会抛IllegalAccessException。
如果字段值为基本类型,get/set会自动在基本类型与对应的包装类型间进行转换。
3. 类方法信息
类中定义的静态方法和实例方法都被称为方法,用Method类封装,可通过Class类的如下方法获取:
51public Method[] getMethods() //返回所有的public方法,包括其父类的,如果没有方法,返回空数组2public Method[] getDeclaredMethods() //返回本类声明的所有方法,包括非public的,但不包括父类的3public Method getMethod(String name, Class<?>... parameterTypes) //返回本类或父类中指定名称和参数类型的public方法,找不到抛出异常NoSuchMethodException4public Method getDeclaredMethod(String name, Class<?>... parameterTypes) //返回本类中声明的指定名称和参数类型的方法,找不到抛出异常NoSuchMethodException5 获取Method对象后,即可通过其方法获取方法信息及调用方法等。
161// 获取方法信息2public String getName() // 获取方法的名称3public int getModifiers() // 获取方法的修饰符(返回值可通过Modifier类进行解读)4public Class<?>[] getParameterTypes() // 获取方法的参数类型列表5public Class<?> getReturnType() // 获取方法的返回值类型6public Class<?>[] getExceptionTypes() // 获取方法声明抛出的异常类型列表7
8// invoke9public void setAccessible(boolean flag) // 设为true表示忽略Java的访问检查机制,以允许调用非public的方法10public Object invoke(Object obj, Object... args) throws IllegalAccessException, IllegalArgumentException, InvocationTargetException // 在指定对象obj上调用Method代表的方法,传递的参数列表为args11
12// 获取注解信息13public Annotation[] getDeclaredAnnotations() // 获取方法的所有注解信息14public <T extends Annotation> T getAnnotation(Class<T> annotationClass) // 获取方法的指定注解信息15public Annotation[][] getParameterAnnotations() // 获取方法参数的注解信息16
关于invoke方法的使用有如下几点注意事项:
对于静态方法,invoke时obj参数直接传null即可。
invoke方法的参数args可以为null,也可以为一个空数组,返回值被包装为Object类型。
如果目标方法调用抛出异常,将会被包装为InvocationTargetException重新抛出,可以通过getCause方法得到原异常。
下面是一个使用invoke调用静态方法的示例:
71public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {2 Class<?> integerClass = Integer.class;3
4 Method method = integerClass.getMethod("parseInt", new Class[]{String.class}); // args可以是Class数组5 System.out.println(method.invoke(null, "123")); // 调用静态方法parseInt,传递参数1236}7
4. 关于修饰符
获取修饰符时,得到的是一个int类型,可通过Modifier类的如下方法进行解析:
231class Student {2 public static final int MAX_NAME_LEN = 255;3}4
5public static void main(String[] args) throws NoSuchFieldException {6 Field field = Student.class.getField("MAX_NAME_LEN");7
8 int mod = field.getModifiers();9 System.out.println(Modifier.toString(mod)); // public static final10
11 System.out.println("isPublic: " + Modifier.isPublic(mod)); // isPublic: true12 System.out.println("isProtected: " + Modifier.isProtected(mod)); // isProtected: false13 System.out.println("isPrivate: " + Modifier.isPrivate(mod)); // isPrivate: false14 System.out.println("isStatic: " + Modifier.isStatic(mod)); // isStatic: true15 System.out.println("isFinal: " + Modifier.isFinal(mod)); // isFinal: true16 System.out.println("isVolatile: " + Modifier.isVolatile(mod)); // isVolatile: false17 System.out.println("isAbstract: " + Modifier.isAbstract(mod)); // isAbstract: false18 System.out.println("isInterface: " + Modifier.isInterface(mod)); // isInterface: false19 System.out.println("isNative: " + Modifier.isNative(mod)); // isNative: false20 System.out.println("isStrict: " + Modifier.isStrict(mod)); // isStrict: false21 System.out.println("isSynchronized: " + Modifier.isSynchronized(mod)); // isSynchronized: false22 System.out.println("isTransient: " + Modifier.isTransient(mod)); // isTransient: false23}
第三节 反射操作
1. 创建对象
获取类信息(Class)后,可以使用其获取构造器和创建对象:
191// 直接调用无参构造创建对象(要求类定义了无参构造方法)2public T newInstance() throws InstantiationException, IllegalAccessException3
4// 获取构造器(Constructor)5public Constructor<?>[] getConstructors() //获取所有的public构造器,返回值可能为长度为0的空数组6public Constructor<?>[] getDeclaredConstructors() //获取所有的构造器,包括非public的7public Constructor<T> getConstructor(Class<?>... parameterTypes) //获取指定参数类型的public构造器,没找到抛出异常NoSuchMethodException8public Constructor<T> getDeclaredConstructor(Class<?>... parameterTypes) //获取指定参数类型的构造器,包括非public的,没找到抛出异常NoSuchMethodException9
10// 通过构造器(Constructor)创建对象11public T newInstance(Object ... initargs) throws InstantiationException, IllegalAccessException, IllegalArgumentException, InvocationTargetException12
13// 构造器(Constructor)的其它方法14public Class<?>[] getParameterTypes() // 获取构造器参数的类型信息15public int getModifiers() // 构造器的修饰符,返回值可通过Modifier类进行解读16public Annotation[] getDeclaredAnnotations() // 构造器的注解信息17public <T extends Annotation> T getAnnotation(Class<T> annotationClass) // 构造器的指定注解信息18public Annotation[][] getParameterAnnotations() // 构造器中参数的注解信息19
2. 类型检查和转换
前面介绍过,instanceof关键字可以用来判断引用指向的实际对象类型,但是instanceof后面的类型是在代码中确定的,如果要检查的类型是动态的,可以使用Class类的isInstance方法,效果是一样的:
151public static void main(String[] args) throws ClassNotFoundException {2 ArrayList<String> list = new ArrayList<>();3
4 // 1. 通过instanceof关键字判断5 if (list instanceof ArrayList) {6 System.out.println("array list");7 }8
9 // 2. 通过Class的isInstance方法判断10 Class<?> listClass = Class.forName("java.util.ArrayList");11 if (listClass.isInstance(list)) {12 System.out.println("array list");13 }14}15
isInstance判断的是对象和类之间的关系,Class还有一个方法isAssignableFrom可以判断类与类之间的关系:
81// 检查参数类型cls能否赋给当前Class类型的变量2public native boolean isAssignableFrom(Class<?> cls);3
4// 示例5Object.class.isAssignableFrom(String.class) // true6String.class.isAssignableFrom(String.class) // true7List.class.isAssignableFrom(ArrayList.class) // true8
在程序中也往往需要进行强制类型转换,而强制转换到的类型要在写代码时就知道的,如果是动态的,可以封装为如下toType方法:
151// 封装toType方法2public static <T> T toType(Object obj, Class<T> cls) {3 // 通过Class的 T cast(Object obj) 方法转换4 return cls.cast(obj);5}6
7public static void main(String[] args) {8 List<String> list = new ArrayList<>();9
10 // 1. 通过强制类型转换11 ArrayList arrList01 = (ArrayList) list;12
13 // 2. 传入Class对象,转换为对应类型14 ArrayList arrList02 = toType(list, ArrayList.class);15}
3. 类的加载
Class有三个重载静态方法,可以根据类名加载类:
41public static Class<?> forName(String className) // Class.forName(className, true, currentLoader) 使用加载当前类的ClassLoader加载,加载后执行初始化代码2public static Class<?> forName(String name, boolean initialize, ClassLoader loader) // loader-类加载器 initialize-加载后是否执行类的初始化代码(如static代码块)3public static Class<?> forName(Module module, String name) // 加载指定模块中指定名称的类(JDK9)。 当找不到类的时候,它不会抛出异常,而是返回 null,它也不会执行类的初始化4
其中className与Class.getName()的返回值是一致,如加载String类型的一维数组使用[java.lang.String;。
21Class cls = Class.forName("[Ljava.lang.String;");2System.out.println(cls == String[].class);需要注意的是,基本类型不支持forName方法:
101Class.forName("int"); // ClassNotFoundException2
3// 基本类型应作特殊处理4public static Class<?> forName(String className) throws ClassNotFoundException {5 if("int".equals(className)){6 return int.class;7 }8 // 其它基本类型省略9 return Class.forName(className);10}
第四节 反射扩展
1. 反射与数组
对于数组类型的Class,有一个专门的方法,可以获取它的元素类型:
61// 获取数组的元素类型2public native Class<?> getComponentType()3
4// 示例5String[] arr = new String[]{};6System.out.println(arr.getClass().getComponentType()); // class java.lang.String另外,java.lang.reflect包中专门提供了一个针对数组反射操作的类Array,以便于统一处理多种类型的数组,主要方法有:
201// 创建数组2public static Object newInstance(Class<?> componentType, int length) // 创建指定元素类型和指定长度的数组3public static Object newInstance(Class<?> componentType, int... dimensions) // 创建指定类型的多维数组4
5// 获取数组长度6public static native int getLength(Object array) // 返回数组的长度7 8// 获取和设置元素值9public static native Object get(Object array, int index) // 获取数组array指定的索引位置index处的值10public static native void set(Object array, int index, Object value) // 修改数组array指定的索引位置index处的值为value11
12// 以各种基本类型操作数组元素13public static native double getDouble(Object array, int index)14public static native void setDouble(Object array, int index, double d)15public static native void setLong(Object array, int index, long l)16public static native long getLong(Object array, int index)17 18// 示例19int[] intArr = (int[])Array.newInstance(int.class, 10);20String[] strArr = (String[])Array.newInstance(String.class, 10);
2. 反射与枚举
对于枚举类型的Class,有一个专门方法 , 可以获取所有的枚举常量:
121// 获取所有枚举常量2public T[] getEnumConstants()3 4// 示例5enum Size {6 SMALL, MEDIUM, LARGE7}8public static void main(String[] args) {9 Class<Size> sizeClass = Size.class;10 Size[] enumConstants = sizeClass.getEnumConstants();11 System.out.println(Arrays.toString(enumConstants)); // [SMALL, MEDIUM, LARGE]12}
3. 反射与内部类
对于内部类类型的Class,也有一些特殊的方法:
51public Class<?>[] getClasses() // 获取所有的public的内部类和接口,包括从父类继承得到的2public Class<?>[] getDeclaredClasses() // 获取自己声明的所有的内部类和接口3public Class<?> getDeclaringClass() // 如果当前Class为内部类,获取声明该类的最外部的Class对象4public Class<?> getEnclosingClass() // 如果当前Class为内部类,获取直接包含该类的类5public Method getEnclosingMethod() // 如果当前Class为本地类或匿名内部类,返回包含它的方法
4. 反射与泛型
虽然泛型在运行时会被擦除,但在类信息Class中仍然有关于泛型的一些信息,可以通过反射获取。
131// Class2public TypeVariable<Class<T>>[] getTypeParameters() // 获取类的泛型参数信息3
4// Field5public Type getGenericType() // 获取泛型类型6
7// Method8public Type getGenericReturnType() // 返回值的泛型类型9public Type[] getGenericParameterTypes() // 参数的泛型类型列表10public Type[] getGenericExceptionTypes() // 异常的泛型类型列表11
12// Constructor13public Type[] getGenericParameterTypes() // 获取构造器参数的泛型类型列表其中Type是一个接口,Class实现了Type,Type的其他子接口还有:
TypeVariable:类型参数,可以有上界,比如:T extends Number。
ParameterizedType:参数化的类型,有原始类型和具体的类型参数,比如:List<String>。
WildcardType:通配符类型,比如:?、? extends Number、? super Integer。
一个简单的使用示例如下:
491public class GenericDemo {2 // 定义了一个泛型类,它有两个泛型参数U和V,其中U必须是Comparable<U>或其子类3 static class GenericTest<U extends Comparable<U>, V> {4 // 泛型引用5 U u;6 V v;7
8 // 泛型类型为String的List9 List<String> list;10
11 // 定义了一个泛型方法,它复用了类上的泛型U作为返回值,同时有一个List参数,List的泛型具体化类型为“Number或其子类”12 public U test(List<? extends Number> numbers) {13 return null;14 }15 }16
17 public static void main(String[] args) throws Exception {18 // 获取类的Class信息19 Class<?> cls = GenericTest.class;20
21 // 获取类的泛型参数信息 -> <U extends Comparable<U>, V>22 for (TypeVariable t : cls.getTypeParameters()) {23 System.out.println(t.getName() + " extends " + Arrays.toString(t.getBounds())); // U extends [java.lang.Comparable<U>] V extends [class java.lang.Object]24 }25 26 // 获取字段的泛型类型0127 // u的类型信息为TypeVariable28 Field fu = cls.getDeclaredField("u");29 System.out.println(fu.getGenericType()); // U30
31 // 获取字段的泛型类型0232 // list的类型信息为ParameterizedType33 Field flist = cls.getDeclaredField("list");34 Type listType = flist.getGenericType();35 if (listType instanceof ParameterizedType) { // 字段list是参数化类型36 ParameterizedType pType = (ParameterizedType) listType;37 // raw type: interface java.util.List, type arguments:[class java.lang.String]38 System.out.println("raw type: " + pType.getRawType() + ", type arguments:" + Arrays.toString(pType.getActualTypeArguments()));39 }40
41 // 获取方法参数的泛型类型0142 // numbers的类型信息为WildcardType43 Method m = cls.getMethod("test", List.class);44 for (Type t : m.getGenericParameterTypes()) {45 System.out.println(t); // java.util.List<? extends java.lang.Number>46 }47 }48}49
5. 反射与注解
51public Annotation[] getAnnotations() // 获取所有的注解2public Annotation[] getDeclaredAnnotations() // 获取所有本元素上直接声明的注解,忽略inherited来的3public <A extends Annotation> A getAnnotation(Class<A> annotationClass) // 获取指定类型的注解,没有返回null4public boolean isAnnotationPresent(Class<? extends Annotation> annotationClass) // 判断是否有指定类型的注解5public Annotation[][] getParameterAnnotations() // 获取参数的注解(仅适用Method和Contructor)
第五节 应用示例
1. SimpleMapper
如下示例使用反射实现一个简单的通用序列化/反序列化类SimpleMapper:
1471public class SimpleMapperDemo {2 public static void main(String[] args) {3 Student student = new Student("张三", 18, 89d);4
5 // 序列化6 String studentStr = SimpleMapper.toString(student); // demo01.SimpleMapperDemo$Student\nname=张三\nage=18\nscore=89.07
8 // 反序列化9 Student studentNew = (Student) SimpleMapper.fromString(studentStr); // Student [name=张三, age=18, score=89.0]10 }11
12 static class Student {13 String name;14 int age;15 Double score;16
17 public Student() {18 }19
20 public Student(String name, int age, Double score) {21 super();22 this.name = name;23 this.age = age;24 this.score = score;25 }26
27 28 public String toString() {29 return "Student [name=" + name + ", age=" + age + ", score=" + score + "]";30 }31 }32}33
34
35/**36 * 简单序列化器。37 * 支持最简单的类,即有默认构造方法,成员类型只有基本类型、包装类或String。38 * 序列化的格式也很简单,第一行为类的名称,后面每行表示一个字段,用字符'='分隔,表示字段名称和字符串形式的值。39 *40 * @Author: huangyuanxin41 * @Date: 2023/3/342 */43public class SimpleMapper {44 /**45 * 将对象obj转换为字符串46 */47 public static String toString(Object obj) {48 StringBuilder sb = new StringBuilder();49
50 try {51 // 获取Class信息52 Class<?> cls = obj.getClass();53
54 // 获取类名55 sb.append(cls.getName() + "\n");56
57 // 获取当前类定义的字段58 for (Field f : cls.getDeclaredFields()) {59 // 跳过权限检查60 if (!f.isAccessible()) {61 f.setAccessible(true);62 }63 // 获取字段名和字段值64 sb.append(f.getName() + "=" + f.get(obj).toString() + "\n");65 }66
67 return sb.toString();68 } catch (IllegalAccessException e) {69 throw new RuntimeException(e);70 }71 }72
73 /**74 * 将字符串转换为对象75 */76 public static Object fromString(String str) {77 try {78 // 拆分79 String[] lines = str.split("\n");80 if (lines.length < 1) {81 throw new IllegalArgumentException(str);82 }83
84 // 加载或获取Class信息85 Class<?> cls = Class.forName(lines[0]);86
87 // 创建目标对象88 Object obj = cls.newInstance();89
90 // 反序列化91 for (int i = 1; i < lines.length; i++) {92 // 拆分键值对93 String[] fv = lines[i].split("=");94 if (fv.length != 2) {95 throw new IllegalArgumentException(lines[i]);96 }97 98 // 根据字段名获取字段的反射信息99 Field f = cls.getDeclaredField(fv[0]);100 if (!f.isAccessible()) {101 f.setAccessible(true);102 }103 104 // 使用反射设置字段值105 setFieldValue(f, obj, fv[1]);106 }107 108 return obj;109 } catch (Exception e) {110 throw new RuntimeException(e);111 }112 }113
114 /**115 * 设置字段值。先根据字段的类型,将字符串形式的值转换为了对应类型的值。116 */117 private static void setFieldValue(Field f, Object obj, String value) throws Exception {118 // 获取字段类型119 Class<?> type = f.getType();120 121 // 转换为对应类型进行设置122 if (type == int.class) {123 f.setInt(obj, Integer.parseInt(value));124 } else if (type == byte.class) {125 f.setByte(obj, Byte.parseByte(value));126 } else if (type == short.class) {127 f.setShort(obj, Short.parseShort(value));128 } else if (type == long.class) {129 f.setLong(obj, Long.parseLong(value));130 } else if (type == float.class) {131 f.setFloat(obj, Float.parseFloat(value));132 } else if (type == double.class) {133 f.setDouble(obj, Double.parseDouble(value));134 } else if (type == char.class) {135 f.setChar(obj, value.charAt(0));136 } else if (type == boolean.class) {137 f.setBoolean(obj, Boolean.parseBoolean(value));138 } else if (type == String.class) {139 f.set(obj, value);140 } else {141 // 假定其它类型都有一个String类型参数的构造器142 Constructor<?> ctor = type.getConstructor(String.class);143 f.set(obj, ctor.newInstance(value));144 }145 }146}147
第六节 Unsafe类
在Java的底层源码中,存在一个sun.misc.Unsafe类,也可以用于创建对象。
101// Unsafe类2public final class Unsafe {3 private static final Unsafe theUnsafe; // 单例实例4
5 // 私有的构造方法6 private Unsafe() {7 }8 9 // ....10}由于它的构造方法是私有的,也没有暴露外部对象,因此只能通过反射来获取,示例如下:
161public class UnsafeDemo {2 public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InstantiationException {3 // 获取theUnsafe4 Field theUnsafeField = Unsafe.class.getDeclaredField("theUnsafe");5 theUnsafeField.setAccessible(true);6 Unsafe theUnsafe = (Unsafe) theUnsafeField.get(null);7
8 // 创建对象9 UnsafeDemo demo = (UnsafeDemo)theUnsafe.allocateInstance(UnsafeDemo.class);10 demo.sayHello();11 }12
13 public void sayHello(){14 System.out.println("hello, Unsafe.");15 }16}必须注意的是,他直接调用的底层C++代码,跳过了Java的对象管理和内存管理以及垃圾回收等机制,不会调用Java类的构造方法(可能突破单例模式限制),并且可能造成内存泄漏,因此请谨慎使用。
注意:
不能在业务代码中调用Unsafe.getUnsafe(),将会抛出SecurityException,因为该方法被
@CallerSensitive注解。
第09章_函数式编程
第一节 Lambda表达式
1. Lambda表达式引入
接口常作为方法的形参来传递代码,如Collections.sort方法的Comparator类型参数:
11public static <T> void sort(List<T> list, Comparator<? super T> c)它真实需要的不是一个Comparator对象,而是在对象的int compare(T o1, T o2)方法中包含的大小比较逻辑。
但由于无法直接传递代码,因此只能传递一个具有该功能的对象。在Java 8之前,最简洁的方式是使用匿名内部类构建一个对象:
71Arrays.sort(files, new Comparator<File>() {2
3 4 public int compare(File f1, File f2) {5 return f1.getName().compareTo(f2.getName());6 }7});在Java8,引入了Lambda表达式,它是一种紧凑的代码传递方式,传递代码不再有实现接口的模板代码,而是直接给出了方法的实现代码,变得更为直观。
11Arrays.sort(files, (f1, f2) -> f1.getName().compareTo(f2.getName()));注意:
虽然Lambda表达式非常简洁,但它只支持函数式接口,其它的接口类型还需使用匿名内部类。
2. Lambda表达式语法
Lambda表达式由->分隔为两部分,前面()内是方法的参数列表,后面{}内是方法的实现代码。其中参数列表由函数式接口的抽象方法决定,必须保证参数的类型和顺序完全一致,但参数名称不做要求。
31File[] files = file.listFiles((File dir, String name) -> {2 return name.endsWith(".log");3});编译器会尽可能的对Lambda表达式进行推断,以简化其书写:
对于参数列表,参数的类型可以省略。特殊的,如果只有一个参数,则
()也可以省略。对于方法实现,支持使用表达式表示,省略
{}、return和;。
91// 0个参数2executor.submit(()->System.out.println("hello")); // 方法实现直接用表达式表示3
4// 1个参数(可省略小括号)5File[] files = f.listFiles(path -> path.getName().endsWith(".txt"));6
7// 2个参数8File[] files = f.listFiles((dir, name) -> name.endsWith(".txt"));9
注意:
如需在Lambda表达式中访问局部变量,则该变量必须是final的,或等效final的(因为该变量是通过构造参数直接传入)。
Lambda表达式不是匿名内部类的语法糖,它是基于invokedynamic指令实现的,并不会生成很多类。
3. Lambda使用场景
281// 赋值给函数式接口2Comparator<String> comparator = (o1, o2) -> o1.length() - o2.length();3
4// 传递一个Lambda表达式5private static void startThread(Runnable task) {6 new Thread(task).start(); 7}8public static void main(String[] args) {9 startThread(() ‐> System.out.println("线程任务执行!")); 10}11 12// 返回一个Lambda表达式13public static Comparator<String> newComparator() {14 return (a, b) ‐> b.length() ‐ a.length(); 15}16 17// 同时传递和返回18public static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor)19{20 Objects.requireNonNull(keyExtractor);21 return (Comparator<T> & Serializable)(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));22}23
24// 调用sort25Arrays.sort(files, (f1, f2) -> f1.getName().compareTo(f2.getName()));26Arrays.sort(files, Comparator.comparing(File::getName));27
28
第二节 函数式接口
1. 什么是函数式接口?
函数式接口指只有一个抽象方法的接口,一般使用@FunctionalInterface进行注解(非强制,与@Override注解类似)。
41public interface Runnable {3 public abstract void run();4}注意:
函数式接口允许有多个非抽象方法。
2. 预定义函数式接口
Java 8 预定义了大量的函数式接口,用于常见类型的代码传递,这些函数定义在java.util.function包下,主要的有:
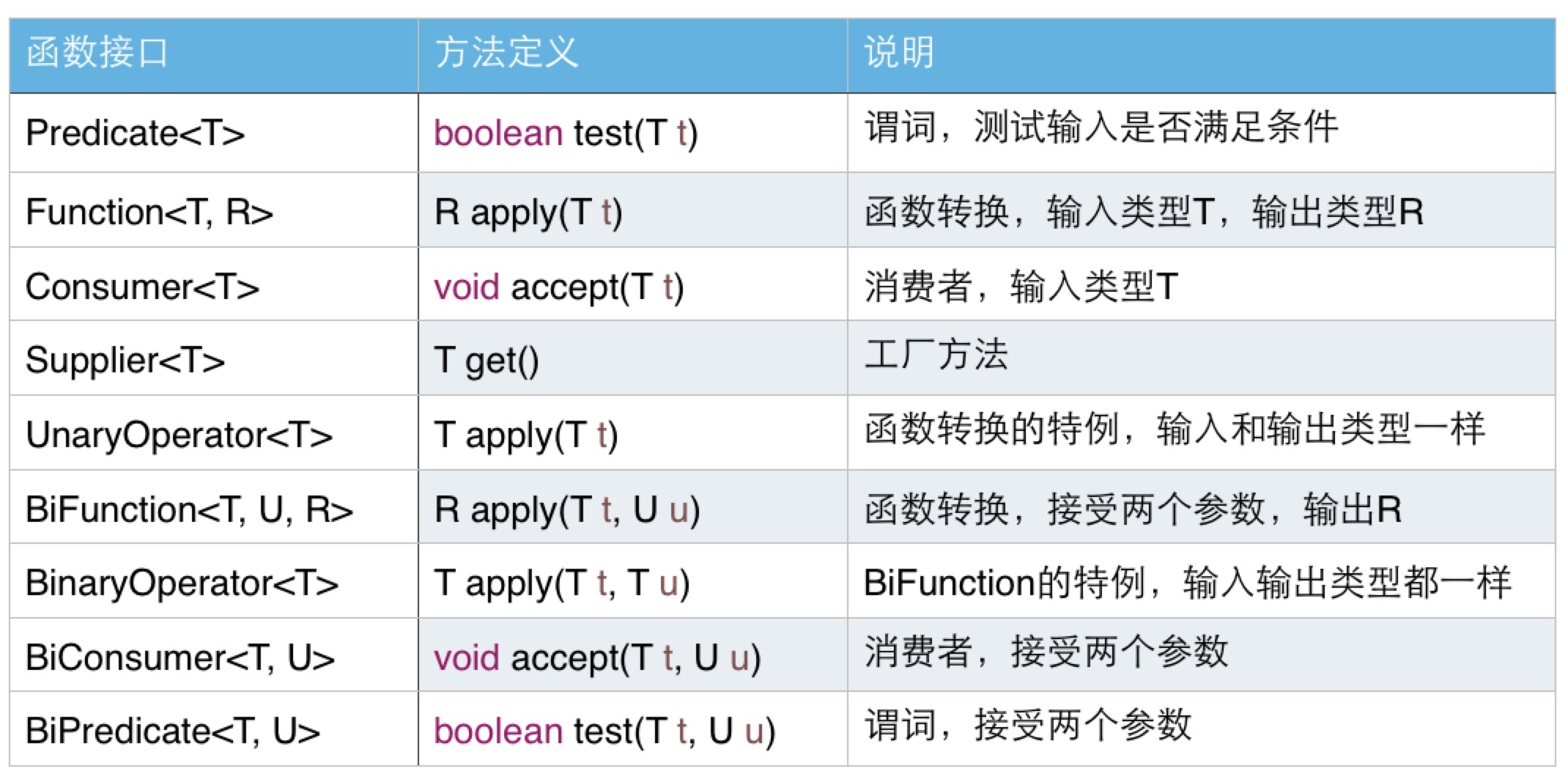
对于基本类型boolean/int/long/double,为避免装箱和拆箱,Java 8 提供了一些专门的函数。比如,int相关的主要函数有:

3. 函数式接口使用示例
为便于举例,我们定义一个简单的学生类Student,以及一个Student列表:
161// Student类2static class Student {3 String name;4 double score;5 6 public Student(String name, double score) {7 this.name = name;8 this.score = score;9 }10}11
12// Student列表13List<Student> students = Arrays.asList(new Student[] {14 new Student("zhangsan", 89d),15 new Student("lisi", 89d),16 new Student("wangwu", 98d) });
1) Predicate
基础使用
131// 列表过滤(支持不同的 列表类型、过滤条件 )2public static <E> List<E> filter(List<E> list, Predicate<E> pred) {3 List<E> retList = new ArrayList<>();4 for (E e : list) {5 if (pred.test(e)) {6 retList.add(e);7 }8 }9 return retList;10}11
12// 过滤90分以上的13students = filter(students, t -> t.getScore() > 90);
and/or/negate
Predicate接口提供了and/or/negate三个方法用于组合其它Predicate。
241// and 逻辑与操作2default Predicate<T> and(Predicate<? super T> other) {3 Objects.requireNonNull(other);4 return (t) -> test(t) && other.test(t);5}6
7// or 逻辑或操作8default Predicate<T> or(Predicate<? super T> other) {9 Objects.requireNonNull(other);10 return (t) -> test(t) || other.test(t);11}12
13// negate 取反操作14default Predicate<T> negate() {15 return (t) -> !test(t);16}17
18// 示例19Predicate<String> predicate01 = s -> s.startsWith("a");20Predicate<String> predicate02 = s -> s.endsWith("c");21System.out.println(predicate01.and(predicate02).test("abc")); // true22System.out.println(predicate01.or(predicate02).test("abc")); // true23System.out.println(predicate01.negate().test("abc")); // false24System.out.println(predicate01.and(predicate02).negate().test("abc")); // false
2) Function
基础使用
151// 列表转换(支持不同的 列表类型、源类型、目的类型 )2public static <T, R> List<R> map(List<T> list, Function<T, R> mapper) {3 List<R> retList = new ArrayList<>(list.size());4 for (T e : list) {5 retList.add(mapper.apply(e));6 }7 return retList;8}9
10// Student -> String11List<String> names = map(students, t -> t.getName());12
13// Student -> Student14students = map(students, t -> new Student(t.getName().toUpperCase(), t.getScore()));15
andThen与compose
Function提供了andThen/compose分别用于后置/前置组合其它Function。
181// andThen 后置组合:将T->R和R->V组合为T->V类型Function2default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {3 Objects.requireNonNull(after);4 return (T t) ‐> after.apply(apply(t));5}6
7// compose 前置组合:将T->R和V->T组合为V->R类型Function8default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {9 Objects.requireNonNull(before);10 return (V v) -> apply(before.apply(v));11}12
13// 示例14Function<String, Double> one = s -> Double.parseDouble(s);15Function<Double, Integer> two = d -> d.intValue();16System.out.println(one.andThen(two).apply("12.34")); // 1217System.out.println(two.compose(one).apply("12.34")); // 1218
注意:
组合后,前面函数式接口的输出必须兼容后面函数式接口的输入,如one.compose(two)是错误的,Integer不能赋值给String。
3) Consumer
基础使用
91// 列表消费(支持不同的 列表类型、源类型)2public static <E> void foreach(List<E> list, Consumer<E> consumer) {3 for (E e : list) {4 consumer.accept(e);5 }6}7
8// 将Student中的Name转为大写9foreach(students, t -> t.setName(t.getName().toUpperCase()));
andThen
Consumer提供了andThen用于后置组合其它Consumer。
111// andThen 后置组合:先消费后再转给after消费2default Consumer<T> andThen(Consumer<? super T> after) {3 Objects.requireNonNull(after);4 return (T t) -> { accept(t); after.accept(t); };5}6
7// 示例8Consumer<String> consumer01 = s -> System.out.println(s.toLowerCase());9Consumer<String> consumer02 = s -> System.out.println(s.toUpperCase());10consumer01.andThen(consumer02).accept("Hello"); // hello \n HELLO11
第三节 方法引用
1. 什么是方法引用
方法引用是Lambda表达式的进一步简化。前面说到,Lambda表达式用于传递一段代码,如果这段代码在其它地方已经存在,则可以通过类名/变量名::方法名的格式直接引用。
2. 引用静态方法
可以通过类名引用静态方法,要求被引用的方法和抽象方法的形参列表及返回值完全一致。
81// Student类的静态方法(无参且返回String)2public static String getCollegeName() {3 return "Laoma School";4}5
6// 通过类名引用静态方法7// 函数式接口Supplier<String>的抽象方法String T get()也是无参且返回String8Supplier<String> s = Student::getCollegeName; // 等效于() -> Student.getCollegeName
3. 引用构造方法
也可以通过类名引用构造方法,和引用静态方法要求相同,即被引用的方法和抽象方法的形参列表及返回值完全一致。
101// Student类的构造方法(两个类参数String和double,无返回值)2public Student(String name, double score) {3 this.name = name;4 this.score = score;5}6
7// 通过类名引用构造方法8// BiFunction<String, Double, Student> 的 Student apply(String t, Double u) 方法也是两个参数String和double,无返回值9BiFunction<String, Double, Student> bf = Student::new; // 等效于(name, score) -> new Student(name, score) 10
4. 引用实例方法
1) 通过类名
可以通过类名引用实例方法,但由于实例方法必须通过实例变量调用,因此只能引用抽象方法第一个形参类型中的实例方法,并且剩余形参列表和返回值也要求和引用方法完全一致。
101// Student类的实例方法2public String getName() {3 return name;4}5
6// 通过类名引用实例方法7// Function<Student, String> 的 String apply(Student t) 方法第一个参数为Student t,用作实例变量8// 剩余参数为无参,返回值为String和Student类的实例方法getName()一致9Function<Student, String> func = Student::getName; // 第一个参数为Student t,等效于 t -> t.getName()10
在运行时,抽象方法第一个参数不作为引用方法的参数传入,而用于调用该引用方法。
2) 通过变量名引用
通过变量名引用它的任意实例方法,它将通过该变量进行调用。
81// 变量2Student student = new Student("张三", 87.6);3
4// 通过变量名引用其实例方法5Supplier<String> s = student::getName; // 等效于() -> student.getName()6Consumer<String> consumer = student::setName; // 等效于 (name) -> student.setName(name)7Function<Student, String> func = student::getName; // 错误,已有实例变量student,第一个参数将传入引用方法getName,但引用方法并没有参数8
注意:
这个变量名也可以是
super或者this。
第四节 流式编程
流式编程通常是对集合数据进行处理,让集合中的对象像水流一样流动,分别进行去重、过滤、映射等操作,就像生产线一样。
对此,Java 8 引入了一套新的类库,位于包java.util.stream下,称之为Stream API。它有如下一些特征:
内部迭代:无需手工迭代集合中的元素,将迭代过程交给并行化机制,不仅代码可读性强,而且能利用多核处理器的优势。
声明式编程:基于提供的处理函数,声明要做什么,而非怎么做。
延迟计算:流是懒加载的,可以将流看作“延迟列表”,只在绝对必要时才计算。
无限流:由于延迟计算,因此流可以无限大。如 limit(n) 或 findFirst() 之类的短路操作允许在有限时间内完成无限流上的计算。
不修改源:如从集合中获得流然后对其进行过滤,将产生一个没有过滤元素的新流,而不是从源集合中删除元素。
非存储:流不是存储元素的数据结构,它通过计算操作的管道传递来自源(如数据结构、数组、生成器函数或I/O通道)的元素。
1. 获取流
1)从集合获取流
Stream API的主要操作定义在Stream接口中,他类似于一个功能更加丰富的迭代器,可以通过Collection接口(JKD8+)的默认方法获取:
91// 返回一个顺序流2default Stream<E> stream() {3 return StreamSupport.stream(spliterator(), false);4}5
6// 返回一个并行流7default Stream<E> parallelStream() {8 return StreamSupport.stream(spliterator(), true);9}注意:
顺序流采用单线程处理,并行流并行处理,线程个数一般与系统的CPU核数一样,以充分利用CPU的计算能力。
并行流的实现基于Java 7引入的
fork/join框架,处理由fork和join两个阶段组成,fork就是将要处理的数据拆分为小块,多线程按小块进行并行计算,join就是将小块的计算结果进行合并。
2) 从数组获取流
Arrays有一些stream方法,可以将数组或子数组转换为流,比如:
91// 获取流2public static IntStream stream(int[] array)3public static DoubleStream stream(double[] array, int startInclusive, int endExclusive)4public static <T> Stream<T> stream(T[] array)5
6// 示例:输出当前目录下所有普通文件的名字7File[] files = new File(".").listFiles();8Arrays.stream(files).filter(File::isFile).map(File::getName).forEach(System.out::println);9
3) 构建流
Stream有一些静态方法,可以构建流:
151//返回一个空流2public static<T> Stream<T> empty()3
4//返回只包含一个元素t的流5public static<T> Stream<T> of(T t)6
7//返回包含多个元素values的流8public static<T> Stream<T> of(T... values)9
10//通过Supplier生成流,流的元素个数是无限的11public static<T> Stream<T> generate(Supplier<T> s)12
13//同样生成无限流,第一个元素为seed,第二个为f(seed),第三个为f(f(seed)),依次类推14public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)15
一些简单示例如下:
51// 输出10个随机数2Stream.generate(()->Math.random()).limit(10).forEach(System.out::println);3
4// 输出100个递增的奇数5Stream.iterate(1, t->t+2).limit(100).forEach(System.out::println);
4) 合并流
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
71// 合并流2static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)3 4// 示例:5Stream<String> streamA = Stream.of("张无忌");6Stream<String> streamB = Stream.of("张翠山");7Stream<String> result = Stream.concat(streamA, streamB);
2. 中间操作
中间操作(intermediate operation) 不触发实际的执行,用于构建流水线,返回的是Stream对象。
1) filter
过滤不符合条件的元素。
111public class StreamDemo {2 private static List<Student> students = Arrays.asList(new Student[]{3 new Student("zhangsan", 89d),4 new Student("lisi", 89d),5 new Student("wangwu", 98d)});6
7 public static void main(String[] args) {8 // 返回学生列表中90分以上的9 List<Student> list01 = students.stream().filter(student -> student.getScore() > 90).collect(Collectors.toList());10 }11}
2) map
将元素转换为其它类型。
61// 根据学生列表返回名称列表2List<String> list02 = students.stream().map(Student::getName).collect(Collectors.toList());3
4// 返回90分以上的学生名称列表5List<String> list03 = students.stream().filter(student -> student.getScore() > 90).map(Student::getName).collect(Collectors.toList());6System.out.println("list03 = " + list03);map函数接受的参数是一个Function<T, R>,为避免装箱/拆箱,提高性能,Stream还有如下返回基本类型特定流的方法:
31DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)2IntStream mapToInt(ToIntFunction<? super T> mapper)3LongStream mapToLong(ToLongFunction<? super T> mapper)DoubleStream/IntStream/LongStream是基本类型特定的流,有一些专门的更为高效的方法。比如,求学生列表的分数总和,代码可以为:
11double sum = students.stream().mapToDouble(Student::getScore).sum();
3) distinct
过滤重复的元素,只留下其中一个,是否重复是根据equals方法来比较的。
31// 返回字符串列表中长度小于3的字符串、转换为小写、只保留唯一的2List<String> strList = Arrays.asList(new String[]{"abc", "def", "hello", "Abc"});3List<String> list04 = strList.stream().filter(s -> s.length() <= 3).map(String::toLowerCase).distinct().collect(Collectors.toList()); // [abc, def]虽然都是中间操作,但distinct与filter/map是不同的,filter/map都是无状态的,对于流中的每一个元素,它的处理都是独立的,处理后即交给流水线中的下一个操作。
但distinct不同,它是有状态的,在处理过程中,它需要在内部记录之前出现过的元素,如果已经出现过,即重复元素,它就会过滤掉,不传递给流水线中的下一个操作。
对于顺序流,内部实现时,distinct操作会使用HashSet记录出现过的元素,如果流是有顺序的,需要保留顺序,会使用LinkedHashSet。
4) sorted
对流中的元素进行排序,要求元素实现Comparable接口或传入一个Comparator。
91// API2Stream<T> sorted() // 要求实现Comparable接口3Stream<T> sorted(Comparator<? super T> comparator) // 使用传入的comparator进行比较4
5// 示例:过滤得到90分以上的学生,然后按分数从高到低排序,分数一样的,按名称排序6List<Student> list05 = students.stream().filter(t -> t.getScore() > 90)7 .sorted(Comparator.comparing(Student::getScore).reversed().thenComparing(Student::getName)) // 排序8 .collect(Collectors.toList());9
与distinct一样,sorted也是一个有状态的中间操作,在处理过程中,需要在内部记录出现过的元素,与distinct不同的是,每碰到流中的一个元素,distinct都能立即做出处理,要么过滤,要么马上传递给下一个操作,但sorted不能,它需要先排序,为了排序,它需要先在内部数组中保存碰到的每一个元素,到流结尾时,再对数组排序,然后再将排序后的元素逐个传递给流水线中的下一个操作。
5) skip/limit
skip跳过流中的n个元素,如果流中元素不足n个,返回一个空流。limit限制流的长度为maxSize,用它们组合可以截取第n+1 ~ n+maxSize的元素。
71// API2Stream<T> skip(long n)3Stream<T> limit(long maxSize)4
5// 将学生列表按照分数排序,返回第3名到第5名6List<Student> list06 = students.stream().sorted(Comparator.comparing(Student::getScore).reversed())7 .skip(2).limit(3).collect(Collectors.toList());skip和limit都是有状态的中间操作。对前n个元素,skip的操作就是过滤,对后面的元素,skip就是传递给流水线中的下一个操作。
limit的一个特点是,它不需要处理流中的所有元素,只要处理的元素个数达到maxSize,后面的元素就不需要处理了,这种可以提前结束的操作被称为短路操作。
6) peek
peek主要目的是支持调试,可以使用该方法观察在流水线中流转的元素。
71// API2Stream<T> peek(Consumer<? super T> action) // 返回的流与之前的流是一样的,没有变化,但它提供了一个Consumer,会将流中的每一个元素传给该Consumer3
4// 进打印流的中间状态元素5List<String> list07 = students.stream().filter(t->t.getScore()>90)6 .peek(System.out::println).map(Student::getName).collect(Collectors.toList());7
7) flatMap
接受一个函数mapper,对流中的每一个元素,mapper会将该元素转换为一个流Stream,然后把新生成流的每一个元素传递给下一个操作,完成了一个1到n的映射。
91// API2<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)3
4// 示例5List<String> lines = Arrays.asList(new String[]{"hello abc", "老马 编程"});6List<String> words = lines.stream().flatMap(line -> Arrays.stream(line.split("\\s+"))) // 将元素(一行字符串)按空白符分隔为了一个流(多个单词)7 .collect(Collectors.toList()); 8System.out.println(words); // [hello, abc, 老马, 编程]9 相应的,针对基本类型,flatMap还有如下类似方法:
31DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper)2IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper)3LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper)
3. 终端操作
终端操作(terminal operation) 触发实际执行,返回具体结果。
1) max/min
返回流中的最大值/最小值,值的注意的是,它的返回值类型是Optional<T>,而不是T,表示可能返回null(在流中不含任何元素的情况下)。
71// API2Optional<T> max(Comparator<? super T> comparator)3Optional<T> min(Comparator<? super T> comparator)4
5// 示例:返回分数最高的学生6Student student = students.stream().max(Comparator.comparing(Student::getScore).reversed()).get(); // 这里students必须不为空,否则会抛空指针异常7
2) count
返回流中元素的个数。
21// 统计大于90分的学生个数2long above90Count = students.stream().filter(t -> t.getScore() > 90).count();
3) allMatch/anyMatch/noneMatch
接受一个谓词Predicate,返回一个boolean值,用于判定流中的元素是否满足一定的条件,它们的区别是:
allMatch: 只有在流中所有元素都满足条件的情况下才返回true。
anyMatch: 只要流中有一个元素满足条件就返回true。
noneMatch: 只有流中所有元素都不满足条件才返回true。
如果流为空,这几个函数的返回值都是true。
21// 判断是不是所有学生都及格了(不小于60分)2boolean allPass = students.stream().allMatch(t -> t.getScore() >= 60);这几个操作都是短路操作,都不一定需要处理所有元素就能得出结果,比如,对于allMatch,只要有一个元素不满足条件,就能返回false。
4) findFirst/findAny
返回类型都是Optional,如果流为空,返回Optional.empty()。findFirst返回第一个元素,而findAny返回任一元素,它们都是短路操作。
101// API2Optional<T> findFirst()3Optional<T> findAny()4
5// 随便找一个不及格的学生6Optional<Student> student02 = students.stream().filter(t -> t.getScore() < 60).findAny();7if (student02.isPresent()) {8 // 不及格的学生....9}10
4) forEach/forEachOrdered
接受一个Consumer,对流中的每一个元素,传递元素给Consumer,区别在于,在并行流中,forEach不保证处理的顺序,而forEachOrdered会保证按照流中元素的出现顺序进行处理。
61// API2void forEach(Consumer<? super T> action)3void forEachOrdered(Consumer<? super T> action)4
5// 逐行打印大于90分的学生6students.stream().filter(t -> t.getScore() > 90).forEach(System.out::println);
5) toArray
将流转换为数组。
121// API2Object[] toArray() // 返回的数组类型为Object[]3<A> A[] toArray(IntFunction<A[]> generator) // 传递一个类型为IntFunction的generator,返回正确类型的数组。4
5// IntFunction:将int转换为R类型,这里的int是流的元素个数,R类型是A[],即元素的数组类型6public interface IntFunction<R> {7 R apply(int value);8}9
10// 示例:获取90分以上的学生数组11Student[] above90Arr = students.stream().filter(t -> t.getScore() > 90).toArray(Student[]::new); // Student[]::new就是一个类型为IntFunction<Student[]>的generator12
6) reduce
代表归约或折叠,即将流中的元素归约为一个值,完成n到1的映射。它有三个重载形式,使用它们可以实现max/min/count等函数:
31Optional<T> reduce(BinaryOperator<T> accumulator); // 将第一个元素与第二个元素进行双元操作,并返回元素类型;将前一次的返回值与下一个元素再进行双元操作,依次循环2T reduce(T identity, BinaryOperator<T> accumulator); // 传入初始值identity,与第一个元素进行双元操作,后续类似3<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner); // 初始值类型和返回值类型自定义第一个基本等同于调用:
151boolean foundAny = false;2T result = null;3
4for (T element : this stream) {5 // 挑选第一个元素作为初始值6 if (!foundAny) {7 foundAny = true;8 result = element;9 }10 else11 // 后续元素进行规约操作12 result = accumulator.apply(result, element);13}14
15return foundAny ? Optional.of(result) : Optional.empty(); // 空流时返回Optional.empty()比如,使用reduce求分数最高的学生(max),代码可以为:
71Student topStudent = students.stream().reduce((accu, t) -> {2 if (accu.getScore() >= t.getScore()) {3 return accu;4 } else {5 return t;6 }7}).get();第二个reduce函数多了一个identity参数,表示初始值,它基本等同于调用:
81// 初始值2T result = identity;3
4// 规约操作5for (T element : this stream)6 result = accumulator.apply(result, element)7
8return result;第一个和第二个reduce的返回类型只能是流中元素的类型,而第三个更为通用,它的归约类型可以自定义。
另外,它多了一个combiner参数,combiner用在并行流中,用于合并子线程的结果,对于顺序流,它基本等同于调用:
81// 初始值(注意类型为U,而非T)2U result = identity;3
4// 规约操作5for (T element : this stream)6 result = accumulator.apply(result, element)7 8return result;注意与第二个reduce函数相区分,它的结果类型不是T,而是U。
21// 使用reduce函数计算学生分数的和(Student...->Double)2double sumScore = students.stream().reduce(0d, (sum, t) -> sum += t.getScore(), (sum1, sum2) -> sum1 += sum2);以上,可以看出,reduce虽然更为通用,但比较费解,难以使用,一般情况,应该优先使用其他函数。
4. 收集器
1) 基本原理
在之前的代码中,如过滤得到90分以上的学生列表:
21List<Student> above90List = students.stream().filter(t->t.getScore()>90)2 .collect(Collectors.toList()); // Stream -> List<Student>最后的collect方法是如何将Stream转换为List<Student>的呢?先看下collect方法相关的定义:
111// 收集方法2<R, A> R collect(Collector<? super T, A, R> collector)3
4// 收集器5public interface Collector<T, A, R> {6 Supplier<A> supplier(); // 工厂方法7 BiConsumer<A, T> accumulator(); // 累加器8 BinaryOperator<A> combiner(); // 只在并行流中有用,用于合并部分结果9 Function<A, R> finisher(); // 调整和类型转换10 Set<Characteristics> characteristics(); // 用于标示收集器的特征,Collector接口的调用者可以利用这些特征进行一些优化,有三个值:CONCURRENT, UNORDERED和IDENTITY_FINISH。11}对于顺序流,collect内部与这些接口方法的交互大概是这样的:
101// 1. 首先调用工厂方法supplier创建一个存放处理状态的容器container,类型为A2A container = collector.supplier().get();3
4// 2. 然后对流中的每一个元素t,调用累加器accumulator,参数为累计状态container和当前元素t5for (T t : data)6 collector.accumulator().accept(container, t);7
8// 3. 最后调用finisher对累计状态container进行可能的调整,类型转换(A转换为R),并返回结果9return collector.finisher().apply(container);10
Collectors.toList()具体是什么呢?看下代码:
131public static <T> Collector<T, ?, List<T>> toList() {2
3 // 返回CollectorImpl对象:Collectors内部的一个私有类4 return new CollectorImpl<>(5 (Supplier<List<T>>) ArrayList::new, // supplier => ArrayList::new,即创建一个ArrayList作为容器6 List::add, // accumulator => List::add,即将碰到的每一个元素加到列表中7 (left, right) -> {8 left.addAll(right);9 return left;10 }, // combiner => 合并结果11 CH_ID); // CH_ID => 一个静态变量,只有一个特征IDENTITY_FINISH,表示finisher没有什么事情可以做,就是把累计状态container直接返回12}13
也就是说,collect(Collectors.toList())背后的伪代码如下所示:
91// 创建容器2List<T> container = new ArrayList<>();3
4// 收集元素5for (T t : data)6 container.add(t);7 8// 返回9return container;
2) 容器收集器
单列容器
91// 1. toList(ArrayList)2List<Student> toList = students.stream().filter(t -> t.getScore() > 90).collect(Collectors.toList());3
4// 2. toSet(HashSet)5Set<Student> toSet = students.stream().filter(t -> t.getScore() > 90).collect(Collectors.toSet());6
7// 3. toCollection(自定义单列容器)8Collection<Student> toCollection = students.stream().filter(t -> t.getScore() > 90)9 .collect(Collectors.toCollection(LinkedHashSet::new)); // LinkedHashSet::new,收集的元素去重且有序
双列容器
141// 1. toMap(HashMap)2Map<String, Double> nameMapScore = students.stream().collect(Collectors.toMap(Student::getName, Student::getScore)); // name->score3Map<String, Student> nameMapThis01 = students.stream().collect(Collectors.toMap(Student::getName, t -> t)); // name -> this4Map<String, Student> nameMapThis02 = students.stream().collect(Collectors.toMap(Student::getName, Function.identity())); // name -> this,其中Function.identity()与t->t等效5
6// 注意:如果key出现重复元素,不是覆盖,而是直接报错!7Map<String, Integer> strLenMapErr = Stream.of("abc", "hello", "abc").collect(Collectors.toMap(Function.identity(), t -> t.length())); // java.lang.IllegalStateException: Duplicate key 38Map<String, Integer> strLenMap = Stream.of("abc", "hello", "abc").collect(Collectors.toMap(Function.identity(), t -> t.length(), (oldValue, value) -> value)); // 传入mergeFunction处理重复元素9
10// 2. toMap(自定义双列容器)11Map<String, Double> linkednameMapScore = students.stream().collect(Collectors.toMap(Student::getName, Student::getScore, (oldValue, value) -> value, LinkedHashMap::new)); // LinkedHashMap::new12
13// 3. toConcurrentMap(ConcurrentHashMap)14Map<String, Double> nameMapScoreByParallel = students.parallelStream().collect(Collectors.toConcurrentMap(Student::getName, Student::getScore));
3) 字符串收集器
除了将元素流收集到容器中,另一个常见的操作是收集为一个字符串。
81// 字符串收集器2public static Collector<CharSequence, ?, String> joining() // 按逗号分隔3public static Collector<CharSequence, ?, String> joining(CharSequence delimiter) // 按delimiter分隔4public static Collector<CharSequence, ?, String> joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix) // 添加前后缀,元素按delimiter分隔5 6// 示例7String strCollect = Stream.of("abc", "老马", "hello").collect(Collectors.joining(",", "[", "]")); // [abc,老马,hello]8String strCollect = Stream.of("abc", "老马", "hello").filter(t -> false).collect(Collectors.joining(",", "[", "]")); // []
5. 分组收集器
分组类似于SQL语句中的group by子句,它将元素流中的每个元素进行分组,然后针对分组进行处理和收集。
1) 简单分组
最基本的分组收集器及其示例如下:
191// classifier:分组器,类型为Function<T,K>,其中T为元素类型,K为分组值类型2// 所有分组值一样的元素会被归为同一个组,放到一个列表中,所以返回值类型是Map<K, List<T>>3public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier)4
5// 示例6public class StreamDemo2 {7 static List<Student> students = Arrays.asList(new Student[]{8 new Student("zhangsan", "1", 91d),9 new Student("lisi", "2", 89d),10 new Student("wangwu", "1", 50d),11 new Student("zhaoliu", "2", 78d),12 new Student("sunqi", "1", 59d)});13
14 public static void main(String[] args) {15 // 按Grade进行分组,默认收集到HashMap<分组值,ArrayList<T>>中16 Map<String, List<Student>> groups = students.stream().collect(Collectors.groupingBy(Student::getGrade));17 System.out.println("groups = " + groups); // groups = {1=[Student [name=zhangsan, score=91.0], Student [name=wangwu, score=50.0], Student [name=sunqi, score=59.0]], 2=[Student [name=lisi, score=89.0], Student [name=zhaoliu, score=78.0]]}18 }19}
2) 基本原理
跟踪groupingBy的源代码如下:
131// 1> groupingBy入口,传入一个分组器classifier2public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier) {3 return groupingBy(classifier, toList()); // 调用重载的groupingBy方法,传递toList收集器4}5
6// 2> 重载的groupingBy方法,传入的toList收集器作为”下游收集器“,下游收集器负责收集同一个分组内元素的结果7public static <T, K, A, D> Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream) {8 return groupingBy(classifier, HashMap::new, downstream); // 再调用重载的groupingBy方法,多传递HashMap::new方法引用9}10
11// 3> 重载的groupingBy方法,传入的HashMap::new作为Map的工厂方法mapFactory12public static <T, K, D, A, M extends Map<K, D>> Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier, Supplier<M> mapFactory, Collector<? super T, A, D> downstream)13
对最后一个重载的groupingBy方法返回的收集器,其收集元素的基本过程和伪代码为:
251//先创建一个存放结果的Map2Map map = mapFactory.get();3
4for (T t : data) {5 // 对每一个元素,先分组6 K key = classifier.apply(t);7 8 // 找存放分组结果的容器,如果没有,让下游收集器创建,并放到Map中9 A container = map.get(key);10 if (container == null) {11 container = downstream.supplier().get();12 map.put(key, container);13 }14 15 // 将元素交给下游收集器(即分组收集器)收集16 downstream.accumulator().accept(container, t);17}18
19// 调用分组收集器的finisher方法,转换结果20for (Map.Entry entry : map.entrySet()) {21 entry.setValue(downstream.finisher().apply(entry.getValue()));22}23
24return map;25
在groupingBy函数中,默认的Map工厂方法为HashMap::new,下游收集器为toList,它们都可以修改,实现更强大的功能。
3) 分组收集
通过修改Map工厂方法和下游收集器,在分组后可以进行一系列的自定义操作。
修改Map工厂方法:如将默认的HashMap::new替换为LinkedHashMap::new,可以实现分组有序。
修改下游收集器:如将默认的toList()替换为counting(),可以实现分组计数。
下面java.util.stream.Collectors包中提供的一些常用下游收集器:
201// 计数2public static <T> Collector<T, ?, Long> counting()3
4// 计算最大值5// 注意:分组收集器的结果是Optional<T>,而不是T6public static <T> Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator)7
8// 计算最小值9// 注意:分组收集器的结果是Optional<T>,而不是T10public static <T> Collector<T, ?, Optional<T>> minBy(Comparator<? super T> comparator)11 12// 求平均值,int和long也有类似方法13public static <T> Collector<T, ?, Double> averagingDouble(ToDoubleFunction<? super T> mapper)14
15// 求和,long和double也有类似方法16public static <T> Collector<T, ?, Integer> summingInt(ToIntFunction<? super T> mapper) 17
18// 求多种汇总信息,int和double也有类似方法19// LongSummaryStatistics包括个数、最大值、最小值、和、平均值等多种信息20public static <T> Collector<T, ?, LongSummaryStatistics> summarizingLong(ToLongFunction<? super T> mapper)下面是一些示例:
271// 统计每个年级的学生个数 => counting()2// gradeCountMap = {1=3, 2=2}3Map<String, Long> gradeCountMap = students.stream().collect(groupingBy(Student::getGrade, counting()));4
5// 统计一个单词流中每个单词的个数,按出现顺序排序 => counting()、LinkedHashMap::new6// wordCountMap = {hello=2, world=1, abc=1}7Map<String, Long> wordCountMap = Stream.of("hello", "world", "abc", "hello").collect(8 groupingBy(Function.identity(), LinkedHashMap::new, counting())); 9
10// 获取每个年级分数最高的一个学生 => maxBy11// topStudentMap = {1=Optional[Student [name=zhangsan, score=91.0]], 2=Optional[Student [name=lisi, score=89.0]]}12Map<String, Optional<Student>> topStudentMap = students.stream().collect(13 groupingBy(Student::getGrade, maxBy(Comparator.comparing(Student::getScore)))); 14
15// 获取每个年级分数最高的一个学生,并对其调用Optional::get方法 => collectingAndThen16// topStudentMap2 = {1=Student [name=zhangsan, score=91.0], 2=Student [name=lisi, score=89.0]}17Map<String, Student> topStudentMap2 = students.stream().collect(18 groupingBy(Student::getGrade, // 分组器19 collectingAndThen(20 maxBy(Comparator.comparing(Student::getScore)), // 下游收集器21 Optional::get))); // 下游收集器后置处理22
23// 按年级统计学生分数信息24// gradeScoreStat = {1=DoubleSummaryStatistics{count=3, sum=200.000000, min=50.000000, average=66.666667, max=91.000000}, 2=DoubleSummaryStatistics{count=2, sum=167.000000, min=78.000000, average=83.500000, max=89.000000}}25Map<String, DoubleSummaryStatistics> gradeScoreStat = students.stream().collect(26 groupingBy(Student::getGrade, summarizingDouble(Student::getScore))); 27
注意:
存在更为通用的名为reducing的归约收集器,由于比较复杂且少用,暂不介绍。
5) 收集前处理
在分组后,直接交给下游收集器处理的一般为元素本身,可通过mapping方法为下游收集器组合一个前置Function,在下游收集前,对传入的元素进行映射转换等一系列处理。
91// 组合下游收集器的前置Function2public static <T, U, A, R> Collector<T, ?, R> 3 mapping(Function<? super T, ? extends U> mapper, Collector<? super U, A, R> downstream) // mapper-前置处理Function4 5// 示例:按年级分组,得到学生名称列表6// {1=[zhangsan, wangwu, sunqi], 2=[lisi, zhaoliu]}7Map<String, List<String>> gradeNameMap = students.stream().collect(8 groupingBy(Student::getGrade, 9 mapping(Student::getName, toList()))); // 先将Student映射为Student.Name,在传给toList收集器
6) 收集后处理
相应的,也可以通过collectingAndThen方法为下游收集器组合一个后置Function,在下游收集完成后,在分组内进行排序(sort)、过滤(filter)、限制返回元素(skip/limit)等一系列操作。
111// 组合下游收集器的后置Function2public static<T,A,R,RR> Collector<T,A,RR> 3 collectingAndThen(Collector<T,A,R> downstream, Function<R,RR> finisher) { // finisher-后置处理Function4 5 // 主要代码,其它代码省略6 return new CollectorImpl<>(downstream.supplier(),7 downstream.accumulator(),8 downstream.combiner(),9 downstream.finisher().andThen(finisher), // 后置处理10 characteristics);11}
组内排序
151// 通用组合方法,收集完后在组内进行排序(当然,也可以先排序后分组,效果一样)2public static <T> Collector<T, ?, List<T>> collectingAndSort(Collector<T, ?, List<T>> downstream, 3 Comparator<? super T> comparator) {4 return Collectors.collectingAndThen(downstream, (r) -> {5 r.sort(comparator);6 return r;7 });8}9
10// 示例:按年级分组,分组内学生按照分数由高到低进行排序11Map<String, List<Student>> gradeStudentMap =12 students.stream().collect(13 groupingBy(Student::getGrade, // 按年级分组14 collectingAndSort(toList(), // 组合toList下游收集器15 Comparator.comparing(Student::getScore).reversed()))); // 和用于分组内排序的Function
组内过滤
131// 通用组合方法,收集完后在组内进行过滤(当然,也可以先过滤后分组,效果一样)2public static <T> Collector<T, ?, List<T>> collectingAndFilter( Collector<T, ?, List<T>> downstream, 3 Predicate<T> predicate) {4 return Collectors.collectingAndThen(downstream, (r) -> {5 return r.stream().filter(predicate).collect(Collectors.toList());6 });7}8
9// 示例:按年级分组,分组后,每个分组只保留不及格的学生(低于60分)10Map<String, List<Student>> gradeStudentMap =11 students.stream().collect(12 groupingBy(Student::getGrade,13 collectingAndFilter(toList(), t->t.getScore()<60)));
组内特定区间
121// 通用组合方法,收集完后只返回特定区间元素2public static <T> Collector<T, ?, List<T>> collectingAndSkipLimit(Collector<T, ?, List<T>> downstream, long skip, long limit) {3 return Collectors.collectingAndThen(downstream, (r) -> {4 return r.stream().skip(skip).limit(limit).collect(Collectors.toList());5 });6}7
8// 示例:按年级分组,分组后,每个分组只保留前两名的学生9Map<String, List<Student>> gradeStudentMap = students.stream()10 .sorted(Comparator.comparing(Student::getScore).reversed()) // 排序11 .collect(groupingBy(Student::getGrade, // 按年级分组12 collectingAndSkipLimit(toList(), 0, 2))); // 只保留组内前2个元素
7) 分区
分组的一个特殊情况是分区,就是将流按true/false分为两个组,Collectors有专门的分区函数:
61// 分区,下游收集器为toList()2public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)3
4// 分区,指定一个下游收集器5public static <T, D, A> Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate, 6 Collector<? super T, A, D> downstream) 下面是一些简单示例:
61// 将学生按照是否及格(大于等于60分)分为两组2Map<Boolean, List<Student>> byPass = students.stream().collect(partitioningBy(t->t.getScore()>=60));3
4// 按是否及格分组后,计算每个分组的平均分5Map<Boolean, Double> avgScoreMap = students.stream().collect(partitioningBy(t->t.getScore()>=60,6 averagingDouble(Student::getScore)));
8) 多级分组
groupingBy和partitioningBy都可以接受一个下游收集器,而下游收集器又可以是分组或分区。
41// 按年级对学生分组,分组后,再按照是否及格对学生进行分区2Map<String, Map<Boolean, List<Student>>> multiGroup = students.stream().collect(3 groupingBy(Student::getGrade, // 按年级分组4 partitioningBy(t -> t.getScore() >= 60))); // 再分区